提高 NFS Azure 文件共享性能
本文内容
- 适用于
- 增加预读大小以提高读取吞吐量
- Nconnect
- 另请参阅
本文介绍如何提高 NFS Azure 文件共享的性能。
适用于
展开表
| 文件共享类型 | SMB | NFS |
|---|---|---|
| 标准文件共享 (GPv2)、LRS/ZRS |
|
|
| 标准文件共享 (GPv2)、GRS/GZRS |
|
|
| 高级文件共享 (FileStorage)、LRS/ZRS |
|
|
增加预读大小以提高读取吞吐量
Linux 中的 read_ahead_kb 内核参数表示应在顺序读取操作期间“预读”或预提取的数据量。 5.4 之前的 Linux 内核版本将预读值设置为装载的文件系统 rsize(读取缓冲区大小的客户端装载选项)的等效值 15 倍。 这会将预读值设置为足够高,以便在大多数情况下提高客户端顺序读取吞吐量。
但是,从 Linux 内核版本 5.4 开始,Linux NFS 客户端使用默认 read_ahead_kb 值 128 KiB。 此小值可能会减少大型文件的读取吞吐量。 从具有较大预读值的 Linux 版本升级到具有 128 KiB 默认值的版本的客户可能会遇到顺序读取性能下降的问题。
对于 Linux 内核 5.4 或更高版本,建议将 read_ahead_kb 设置为 15 MiB 以提高性能。
若要更改此值,请在 Linux 内核设备管理器 udev 中添加规则来设置预读大小。 执行以下步骤:
-
在文本编辑器中,通过输入并保存以下文本来创建 /etc/udev/rules.d/99-nfs.rules 文件:
输出复制
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360" -
在控制台中,通过以超级用户身份运行 udevadm 命令并重新加载规则文件和其他数据库来应用 udev 规则。 只需运行此命令一次,即可了解新文件。
Bash复制
sudo udevadm control --reload
Nconnect
Nconnect 是客户端 Linux 装载选项,通过允许在客户端与 NFSv4.1 的 Azure 高级文件服务之间使用更多 TCP 连接来大规模提高性能,同时保持平台即服务 (PaaS) 的复原能力。
nconnect 的优势
借助 nconnect,可以使用更少的客户端计算机大规模提高性能,以降低总拥有成本 (TCO)。 Nconnect 通过在一个或多个 NIC 上使用多个 TCP 通道或者使用一个或多个客户端来提高性能。 如果没有 nconnect,则需要大约 20 台客户端计算机,才能达到最大高级 Azure 文件共享预配大小提供的带宽规模限制 (10 GiB/s)。 使用 nconnect,只需使用 6-7 个客户端即可达到这些限制。 这几乎减少了 70% 的计算成本,同时大规模地提高了 IOPS 和吞吐量,(请参阅表)。
展开表
| 指标(操作) | I/O 大小 | 性能提升 |
|---|---|---|
| IOPS(写入) | 64K、1024K | 3x |
| IOPS(读取) | 所有 I/O 大小 | 2-4x |
| 吞吐量(写入) | 64K、1024K | 3x |
| 吞吐量(读取) | 所有 I/O 大小 | 2-4x |
先决条件
- 最新的 Linux 发行版完全支持
nconnect。 对于较旧的 Linux 分发版,请确保 Linux 内核版本为 5.3 或更高版本。 - 仅当每个存储帐户通过专用终结点使用单个文件共享时,才支持按装载配置。
nconnect 的性能影响
在 Linux 客户端上将 nconnect 装载选项与 NFS Azure 文件共享大规模配合使用时,我们实现了以下性能结果。 有关如何实现这些结果的详细信息,请参阅性能测试配置。
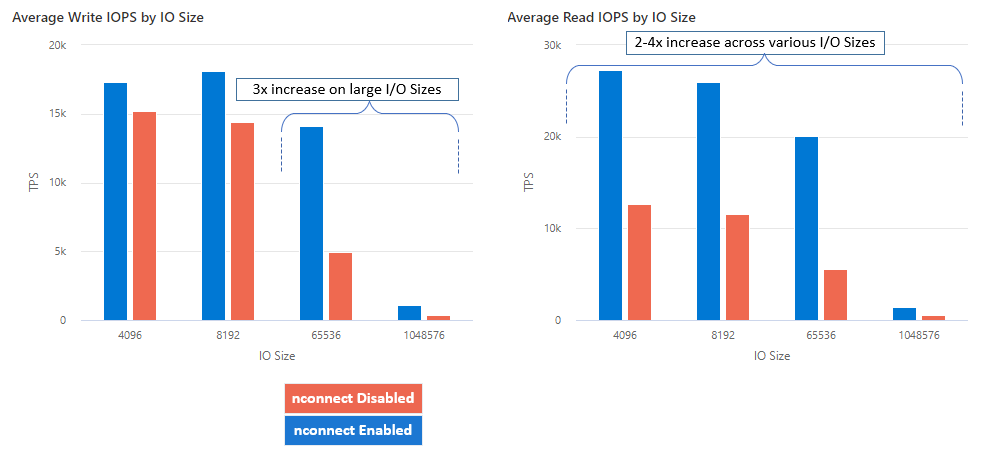
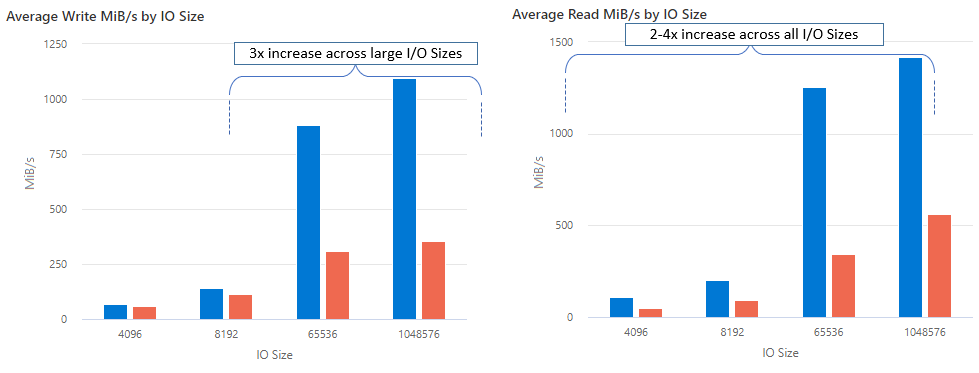
有关 nconnect 的建议
遵循这些建议,从 nconnect 中获得最佳结果。
设置 nconnect=4
虽然 Azure 文件存储支持将 nconnect 设置为最大设置 16,但我们建议使用最佳设置 nconnect=4 配置装载选项。 目前,超出四个通道后,Azure 文件存储使用 nconnect 没有增益。 事实上,由于 TCP 网络饱和,单个客户端中单个 Azure 文件共享连接的通道超过四个可能会对性能产生负面影响。
仔细调整虚拟机大小
根据工作负载要求,请务必正确调整客户端计算机的大小以避免受到预期网络带宽的限制。 无需多个 NIC 也可实现预期的网络吞吐量。 虽然通常使用具有 Azure 文件存储的常规用途 VM,但根据工作负载需求和区域可用性,可以使用各种 VM 类型。 有关详细信息,请参阅 Azure VM 选择器。
将队列深度保持小于或等于 64
队列深度是存储资源可处理的待处理 I/O 请求数。 建议不要超过最佳队列深度 64。 如果这样做,则不会再看到任何性能提升。 有关详细信息,请参阅队列深度。
Nconnect 按装载配置
如果工作负荷需要从单个客户端使用采用不同 nconnect 设置的一个或多个存储帐户装载多个共享,则我们无法保证这些设置在通过公共终结点装载时会保留。 仅当每个存储帐户通过专用终结点使用单个 Azure 文件共享时,才支持按装载配置,如方案 1 中所述。
方案 1:(支持)使用多个存储帐户通过专用终结点进行 nconnect 按装载配置
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
方案 2:(不支持)通过公共终结点进行 nconnect 按装载配置
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
备注
即使存储帐户解析为其他 IP 地址,也不能保证该地址会保留,因为公共终结点不是静态地址。
方案 3:(不支持)在单个存储帐户上使用多个共享通过专业终结点进行 nconnect 按装载配置
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
性能测试配置
我们使用以下资源和基准测试工具来实现并衡量本文中概述的结果。
- 单个客户端:具有单个 NIC 的 Azure 虚拟机(DSv4 系列)
- OS:Linux (Ubuntu 20.40)
- NFS 存储:Azure 文件存储高级文件共享(预配 30 TiB,设置
nconnect=4
展开表
| 大小 | vCPU | 内存 | 临时存储 (SSD) | 最大数据磁盘数 | 最大 NIC 数 | 预期网络带宽 |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | 仅限远程存储 | 32 | 8 | 12,500 Mbps |
基准测试工具和测试
我们使用了 Flexible I/O Tester (FIO),这是一款免费的开源磁盘 I/O 工具,用于基准和压力/硬件验证。 要安装 FIO,请参照 FIO 自述文件中的“二进制软件包”部分,为所选平台进行安装。
虽然这些测试侧重于随机 I/O 访问模式,但使用顺序 I/O 时会获得类似的结果。
高 IOPS:100% 读取
4k I/O 大小 - 随机读取 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
8k I/O 大小 - 随机读取 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
高吞吐量:100% 读取
64k I/O 大小 - 随机读取 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
1024k I/O 大小 - 100% 随机读取 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
高 IOPS:100% 写入
4k I/O 大小 - 100% 随机写入 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
8k I/O 大小 - 100% 随机写入 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
高吞吐量:100% 写入
64k I/O 大小 - 100% 随机写入 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
1024k I/O 大小 - 100% 随机写入 - 64 队列深度
Bash复制
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
nconnect 的性能注意事项
使用 nconnect 装载选项时,应密切评估具有以下特征的工作负载:
- 单线程和/或使用低队列深度(小于 16)的延迟敏感型写入工作负载
- 单线程和/或使用低队列深度与较小 I/O 大小的延迟敏感型读取工作负载
并非所有工作负载都需要大规模 IOPS 或吞吐量性能。 对于规模较小的工作负载,nconnect 可能没有意义。 使用下表来确定 nconnect 是否有益于工作负载。 建议使用绿色突出显示的方案,而红色突出显示的方案则不推荐。 黄色突出显示的方案则介于二者之间。
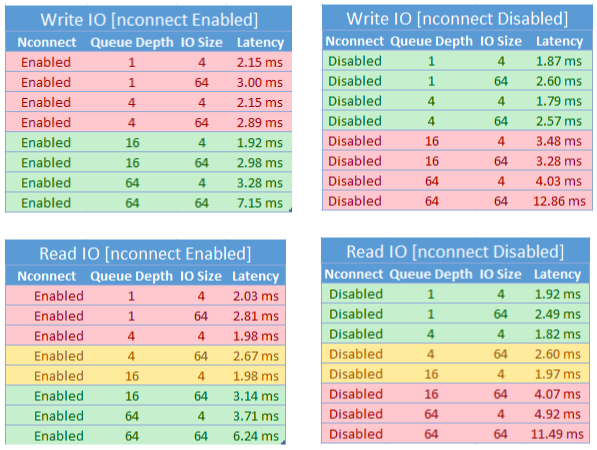
另请参阅
- 有关装载说明,请参阅将 NFS 文件共享装载到 Linux。
- 有关装载选项的完整列表,请参阅 Linux NFS 手册页。
- 有关延迟、IOPS、吞吐量和其他性能概念的信息,请参阅了解 Azure 文件存储性能。
相关文章:
提高 NFS Azure 文件共享性能
本文内容 适用于增加预读大小以提高读取吞吐量Nconnect另请参阅 本文介绍如何提高 NFS Azure 文件共享的性能。 适用于 展开表 文件共享类型SMBNFS标准文件共享 (GPv2)、LRS/ZRS 标准文件共享 (GPv2)、GRS/GZRS 高级文件共享 (FileStorage)、LRS/ZRS 增加预读大…...

【Django-ninja】使用schema
在Django Ninja中,"schema"主要是指帮助描述和规范你的API的工具,以便系统能够自动生成文档并提供验证。通俗地说,它有两个主要作用: API文档生成器: Schema 让 Django Ninja 能够自动生成互动式的API文档。…...
【TCP/IP】用户访问一个购物网站时TCP/IP五层参考模型中每一层的功能
当用户访问一个购物网站时,网络上的每一层都会涉及不同的协议,具体网络模型如下图所示。 以下是每个网络层及其相关的协议示例: 物理层:负责将比特流传输到物理媒介上,例如电缆或无线信号。所以在物理层,可…...

Unity 开发注意事项
1. 空Unity消息 Unity消息被运行时事件调用,即使消息体为空也会被调用。因此,删除空消息避免不必要的处理。 例如: using UnityEngine;class Camera : MonoBehaviour {private void FixedUpdate(){}private void Foo(){} } 应该删除未使用…...

[Unity Sentis] Unity Sentis 详细步骤工作流程
文章目录 1. 导入模型文件支持的模型创建运行时模型导入错误 2. 为模型创建输入将数组转换为张量创建多个输入进行操作 3. 创建一个引擎来运行模型创建一个Worker后端类型 4. 运行模型5. 获取模型的输出获取张量输出多个输出打印输出 1. 导入模型文件 要导入 ONNX 模型文件&am…...
力扣144 二叉树的前序遍历 Java版本
文章目录 题目描述递归方法代码 非递归方法代码 题目描述 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,2,3] 示例 2: 输入:root [] 输出…...
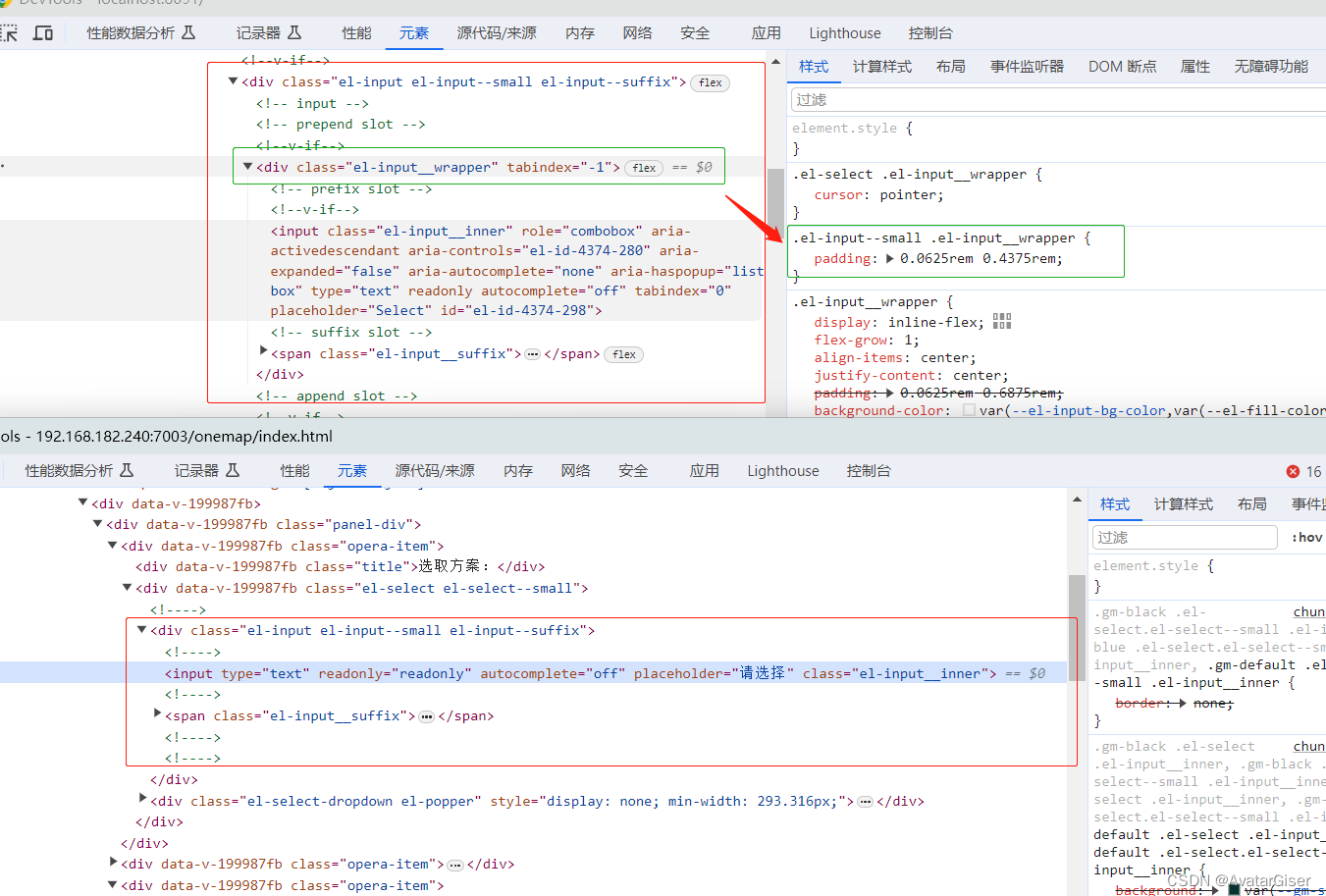
《Vue3 基础知识》 使用 GoGoCod 升级到Vue3+ElementPlus 适配处理
此篇为 《Vue2ElementUI 自动转 Vue3ElementPlus(GoGoCode)》 的扩展! Vue3 适配 Vue3 不兼容适配 Vue 3 迁移指南 在此,本章只讲述项目或组件库中遇到的问题; Vue3 移除 o n , on, on&#…...
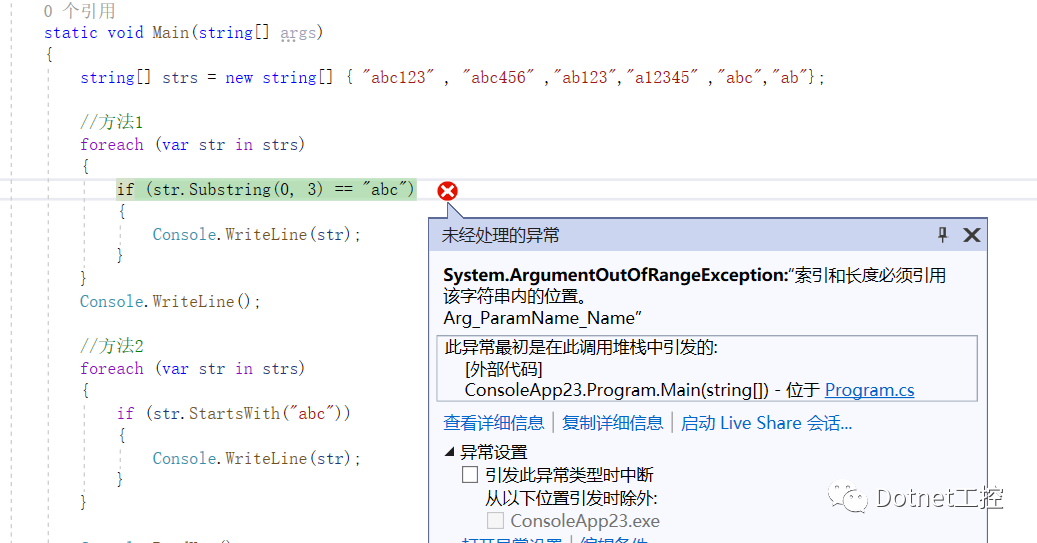
c#string方法对比
字符串的截取匹配操作在开发中非常常见,比如下面这个示例:我要匹配查找出来字符串数组中以“abc”开头的字符串并打印,我下面分别用了两种方式实现,代码如下: using System; namespace ConsoleApp23{ class Progra…...
Electron实战(一):环境搭建/Hello World/打包exe
文章目录 Electron安装Node.jsNodeJs推荐配置开始Electron项目创建index.js文件创建src目录运行打包生成exe生成安装包踩坑 下一篇Electron实战(二):将Node.js和UI能力(app/BrowserWindow/dialog)等注入html Electron Electron是一个使用JavaScript, HT…...

【C++】运算符重载详解
💗个人主页💗 ⭐个人专栏——C学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读 1. 为什么需要运算符重载 2. 运算符重载概念 3. 运算符重载示例 3.1 运算符重载 3.2 >或<运算符 4. 运算符重…...
评论区功能的简单实现思路
评论区功能是社交类项目中的核心组成部分,它涉及到前端的交云和后端的数据处理。基于你的技术栈(前端 Vue3,后端 Java),下面是一个具体的实现思路和数据库设计建议,并探索一下知乎的评论系统。 数据库设计…...

Java自救手册
目录 访问地址 访问地址,发现不通,无法访问: 网络不通一般有两种情况: Maven 拿Maven 拿到Maven以后 Maven单独的报红 Git git注意: 目录 访问地址 访问地址,发现不通,无法访问&…...
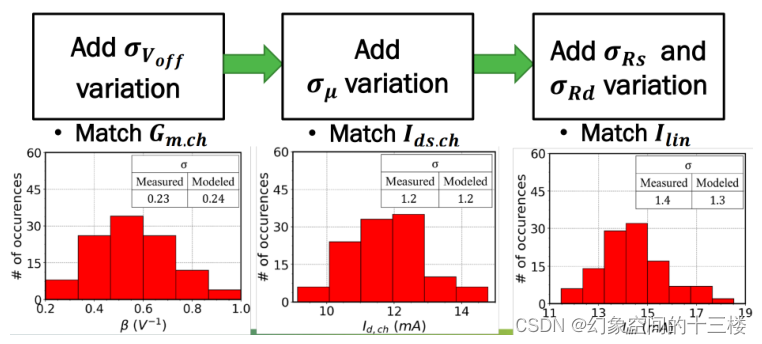
ASM-HEMT参数提取和模型验证测试
参数提取程序 直流I-V参数提取 DC模型参数提取流程对于ASM-GaN-HEMT模型可以总结在下图中。 以下步骤描述了该流程: 在模型中设置物理参数,如L(沟道长度)、W(沟道宽度)、NF(栅指数…...
浅压缩、深压缩、双引擎、计算机屏幕编码……何去何从?
专业视听领域尤其显示控制和坐席控制领域,最近几年最激动人心的技术,莫过于分布式了。 分布式从推出之日就备受关注:担心稳定性的,质疑同步性能的,怀疑画面质量的…… 诚然,我们在此前见多了带着马赛克的…...
2020年通信工程师初级专业实务真题
文章目录 一、第1章 现代通信网概述:信令网、同步网、管理网。第10章 通信业务:通信产业链,通信终端的分类,通信业务的定义及分类二、第3章 接入网:无线接入网的优点,接入网的接口(UNIÿ…...

Linux常见面试题汇总
Linux上如何查询某个端口是否被占用? 在Linux上,你可以使用以下几种方法来查询某个端口是否被占用: 使用netstat命令: netstat -tuln | grep <端口号>这个命令会列出当前正在运行的所有TCP和UDP端口,并过滤出指…...

C语言小游戏:贪吃蛇(游戏开发的环境和功能介绍)
❀❀❀ 文章由不准备秃的大伟原创 ❀❀❀ ♪♪♪ 若有转载,请联系博主哦~ ♪♪♪ ❤❤❤ 致力学好编程的宝藏博主,代码兴国!❤❤❤ 生命不停,学习不止。铁汁们,我是大伟,欢迎来到大伟的游戏时间,…...
ElementUI Form:InputNumber 计数器
ElementUI安装与使用指南 InputNumber 计数器 点击下载learnelementuispringboot项目源码 效果图 el-radio.vue (InputNumber 计数器)页面效果图 项目里el-input-number.vue代码 <script> export default {name: el_input_number,data() {re…...

apk反编译修改教程系列---修改apk的默认颜色 布局颜色 手机电脑同步演示【十】
往期教程: apk反编译修改教程系列-----修改apk应用名称 任意修改名称 签名【一】 apk反编译修改教程系列-----任意修改apk版本号 版本名 防止自动更新【二】 apk反编译修改教程系列-----修改apk中的图片 任意更换apk桌面图片【三】 apk反编译修改教程系列---简单…...

响应式开发如何设置断点,小屏幕界面该如何显示(有动图)
Hi,我是贝格前端工场,本期分享响应式开发,如何设置屏幕断点,pc页面布局到了移动端之后该如何布局的问题,微软也提供了设置屏幕断点的动图演示,非常直观。 一、什么是响应式开发,为何要设置屏幕断…...

如何利用 SEO 工具提取网站的外部链接
如何利用 SEO 工具提取网站的外部链接 在当今竞争激烈的网络环境中,外部链接(即指向你网站的其他网站的链接)已经成为提升网站搜索引擎排名的重要因素。利用 SEO 工具提取网站的外部链接,不仅能帮助你更好地了解你的网站链接情况…...

cv_unet_image-colorization图像上色入门必看:纯本地运行无网络依赖实操手册
cv_unet_image-colorization图像上色入门必看:纯本地运行无网络依赖实操手册 本文总计约3800字,完整阅读约需12分钟,包含详细的环境配置、操作步骤和实用技巧,适合零基础用户快速上手。 1. 引言:让黑白照片重现光彩 你…...

AllCells细胞原料解析:Leukopak与PBMC在CGT中的应用【曼博生物供应人原代细胞】
AllCells细胞原料体系解析:Leukopak与PBMC在CGT中的应用 摘要: AllCells作为DLS体系中的重要品牌,提供GMP与RUO级人源细胞原料,包括Leukopak与PBMC等产品类型,广泛应用于细胞与基因治疗研发及生产流程。 关键词&#x…...

Windows系统盘空间告急?Driver Store Explorer帮你轻松清理冗余驱动,快速释放10GB+
Windows系统盘空间告急?Driver Store Explorer帮你轻松清理冗余驱动,快速释放10GB 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾困惑于Windows系统盘空…...

1.3 装饰器与上下文管理器
📘 第一阶段 1.3 装饰器与上下文管理器学习目标:彻底掌握 Python 中用于代码复用和资源管理的高级特性,理解它们在 FastAPI 中的底层应用。 预计用时:2 天(每天约 3 小时) 重要程度:⭐⭐⭐⭐&a…...

BiliBiliCCSubtitle:B站字幕高效解决方案,解决字幕获取、格式转换与批量处理难题
BiliBiliCCSubtitle:B站字幕高效解决方案,解决字幕获取、格式转换与批量处理难题 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 在数字内…...


Omni-Vision Sanctuary 大模型一键部署:Python入门级环境配置实战
Omni-Vision Sanctuary 大模型一键部署:Python入门级环境配置实战 1. 开篇:为什么选择Omni-Vision Sanctuary 如果你刚接触AI大模型,可能会被各种复杂的部署流程吓到。别担心,今天我们要聊的Omni-Vision Sanctuary是个对新手特别…...

3个突破性方法让你永久掌控数字阅读自由
3个突破性方法让你永久掌控数字阅读自由 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经历过这样的窘境:在通勤途中想继续阅读昨晚未看完的小说,却发现网…...

用 DeepWiki 线索看 OpenClaw:它到底用到了哪些 AI 技术?
用 DeepWiki 线索看 OpenClaw:它到底用到了哪些 AI 技术? OpenClaw 近来在个人 AI 助手、Agent 框架和本地优先智能体领域里讨论度很高。很多人第一次看到它,会把它简单理解为“一个能接聊天渠道的大模型壳子”。但如果顺着 GitHub 文档以及项…...