深度学习本科课程 实验3 网络优化
一、在多分类任务实验中实现momentum、rmsprop、adam优化器
1.1 任务内容
- 在手动实现多分类的任务中手动实现三种优化算法,并补全Adam中计算部分的内容
- 在torch.nn实现多分类的任务中使用torch.nn实现各种优化器,并对比其效果
1.2 任务思路及代码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import transforms
import time
from torch.nn import CrossEntropyLoss
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有gpu则在gpu上计算 加快计算速度
print(f'当前使用的device为{device}')
# 多分类任务
mnist_train = torchvision.datasets.FashionMNIST(root='./FashionMNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='./FashionMNIST', train=False, download=True, transform=transforms.ToTensor())
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=0)
# 定义绘图函数
import matplotlib.pyplot as plt
def draw(name, trainl, testl,xlabel='Epoch',ylabel='Loss'):plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题plt.figure(figsize=(8, 3))plt.title(name[-1]) # 命名color = ['g','r','b','c']if trainl is not None:plt.subplot(121)for i in range(len(name)-1):plt.plot(trainl[i], c=color[i],label=name[i])plt.xlabel(xlabel)plt.ylabel(ylabel)plt.legend()if testl is not None:plt.subplot(122)for i in range(len(name)-1):plt.plot(testl[i], c=color[i], label=name[i])plt.xlabel(xlabel)plt.ylabel(ylabel)plt.legend()# 自定义实现
class Net():def __init__(self):# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 28 * 28, 256, 10 # 十分类问题self.w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,requires_grad=True)self.b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)self.w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,requires_grad=True)self.b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)self.params=[self.w_1, self.b_1, self.w_2, self.b_2]self.w = [self.w_1,self.w_2]# 定义模型结构self.input_layer = lambda x: x.view(x.shape[0], -1)self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, self.w_1.t()) + self.b_1)self.output_layer = lambda x: nn.functional.softmax(torch.matmul(x, self.w_2.t()) + self.b_2, dim=1)self.momentum_states = [torch.zeros_like(param) for param in self.params]def my_relu(self, x):return torch.max(input=x, other=torch.tensor(0.0))# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.hidden_layer(x)x = self.output_layer(x)return xdef my_cross_entropy_loss(y_hat, labels):def log_softmax(y_hat):max_v = torch.max(y_hat, dim=1).values.unsqueeze(dim=1)return y_hat - max_v - torch.log(torch.exp(y_hat-max_v).sum(dim=1).unsqueeze(dim=1))return (-log_softmax(y_hat))[range(len(y_hat)), labels].mean()# nn实现
class MyNet_NN(nn.Module):def __init__(self,dropout=0.0):super(MyNet_NN, self).__init__()# 设置隐藏层和输出层的节点数self.num_inputs, self.num_hiddens, self.num_outputs = 28 * 28, 256, 10 # 十分类问题# 定义模型结构self.input_layer = nn.Flatten()self.hidden_layer = nn.Linear(28*28,256)self.drop = nn.Dropout(dropout)self.output_layer = nn.Linear(256,10)# 使用relu激活函数self.relu = nn.ReLU()# 定义前向传播def forward(self, x):x = self.drop(self.input_layer(x))x = self.drop(self.hidden_layer(x))x = self.relu(x)x = self.output_layer(x)return x
def train_and_test(model=Net(),init_states=None,optimizer=optim.SGD,epochs=10,lr=0.01,L2=False,lambd=0):train_all_loss = [] test_all_loss = [] train_ACC, test_ACC = [], [] begintime = time.time()criterion = CrossEntropyLoss() for epoch in range(epochs):train_l,train_acc_num = 0, 0for data, labels in train_iter:pred = model.forward(data)train_each_loss = criterion(pred, labels) # 若L2为True则表示需要添加L2范数惩罚项if L2 == True:train_each_loss += lambd * l2_penalty(model.w)train_l += train_each_loss.item()train_each_loss.backward() # 反向传播if init_states == None: optimizer(model.params, lr, 128) # 使用小批量随机梯度下降迭代模型参数else:states = init_states(model.params)optimizer(model.params,states,lr=lr)# 梯度清零train_acc_num += (pred.argmax(dim=1)==labels).sum().item()for param in model.params:param.grad.data.zero_()# print(train_each_loss)train_all_loss.append(train_l) # 添加损失值到列表中train_ACC.append(train_acc_num / len(mnist_train)) # 添加准确率到列表中with torch.no_grad():is_train = False test_l, test_acc_num = 0, 0for data, labels in test_iter:pred = model.forward(data)test_each_loss = criterion(pred, labels)test_l += test_each_loss.item()test_acc_num += (pred.argmax(dim=1)==labels).sum().item()test_all_loss.append(test_l)test_ACC.append(test_acc_num / len(mnist_test)) # # 添加准确率到列表中print('epoch: %d\t train loss:%.5f\t test loss:%.5f\t train acc: %.2f\t test acc: %.2f'% (epoch + 1, train_l, test_l, train_ACC[-1],test_ACC[-1]))endtime = time.time()print("%d轮 总用时: %.3f秒" % ( epochs, endtime - begintime))return train_all_loss,test_all_loss,train_ACC,test_ACCdef train_and_test_NN(model=MyNet_NN(),epochs=10,lr=0.01,weight_decay=0.0,optimizer=None):MyModel = modelprint(MyModel)if optimizer == None:optimizer = SGD(MyModel.parameters(), lr=lr,weight_decay=weight_decay) criterion = CrossEntropyLoss() # 损失函数criterion = criterion.to(device)train_all_loss = [] test_all_loss = [] train_ACC, test_ACC = [], []begintime = time.time()for epoch in range(epochs):train_l, train_epoch_count, test_epoch_count = 0, 0, 0for data, labels in train_iter:data, labels = data.to(device), labels.to(device)pred = MyModel(data)train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值optimizer.zero_grad() train_each_loss.backward() optimizer.step() train_l += train_each_loss.item()train_epoch_count += (pred.argmax(dim=1)==labels).sum()train_ACC.append(train_epoch_count/len(mnist_train))train_all_loss.append(train_l) with torch.no_grad():test_loss, test_epoch_count= 0, 0for data, labels in test_iter:data, labels = data.to(device), labels.to(device)pred = MyModel(data)test_each_loss = criterion(pred,labels)test_loss += test_each_loss.item()test_epoch_count += (pred.argmax(dim=1)==labels).sum()test_all_loss.append(test_loss)test_ACC.append(test_epoch_count.cpu()/len(mnist_test))print('epoch: %d\t train loss:%.5f\t test loss:%.5f\t train acc:%5f test acc:%.5f:' % (epoch + 1, train_all_loss[-1], test_all_loss[-1],train_ACC[-1],test_ACC[-1]))endtime = time.time()print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3f秒" % (epochs, endtime - begintime))# 返回训练集和测试集上的 损失值 与 准确率return train_all_loss,test_all_loss,train_ACC,test_ACC
# 手动实现momentum
def init_momentum(params):w1,b1,w2,b2 = torch.zeros(params[0].shape),torch.zeros(params[1].shape),torch.zeros(params[2].shape),torch.zeros(params[3].shape)return (w1,b1,w2,b2)def sgd_momentum(params, states, lr=0.01, momentum=0.9):for p, v in zip(params, states):with torch.no_grad():v[:] = momentum * v - p.gradp[:] += lr*vp.grad.data.zero_()net11 = Net()
trainL11, testL11, trainAcc11, testAcc11 = train_and_test(model=net11,epochs=10,init_states=init_momentum, optimizer=sgd_momentum)
# nn实现Momentum
net12 = MyNet_NN()
net12 = net12.to(device)
momentum_optimizer = optim.SGD(net12.parameters(), lr=0.01, momentum=0.9)
trainL12, testL12, trainAcc12, testAcc12 = train_and_test_NN(model=net12,epochs=10,optimizer=momentum_optimizer)
# 手动实现RMSpropdef init_rmsprop(params):s_w1, s_b1, s_w2, s_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\torch.zeros(params[2].shape), torch.zeros(params[3].shape)return (s_w1, s_b1, s_w2, s_b2)def rmsprop(params,states,lr=0.01,gamma=0.9):gamma, eps = gamma, 1e-6for p, s in zip(params,states):with torch.no_grad():s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)p[:] -= lr * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()net21= Net()
trainL21, testL21, trainAcc21, testAcc21 = train_and_test(model=net21,epochs=10,init_states=init_rmsprop, optimizer=rmsprop)
# nn实现RMSprop
net22 = MyNet_NN()
net22 = net22.to(device)
optim_RMSprop = torch.optim.RMSprop(net22.parameters(), lr=0.01, alpha=0.9, eps=1e-6)
trainL22, testL22, trainAcc22, testAcc22 = train_and_test_NN(model=net22,epochs=10,optimizer=optim_RMSprop)
# 手动实现Adam
def init_adam_states(params):v_w1, v_b1, v_w2, v_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\torch.zeros(params[2].shape), torch.zeros(params[3].shape)s_w1, s_b1, s_w2, s_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\torch.zeros(params[2].shape), torch.zeros(params[3].shape)return ((v_w1, s_w1), (v_b1, s_b1),(v_w2, s_w2), (v_b2, s_b2))# 根据Adam算法思想手动实现Adam
Adam_t = 0.01
def Adam(params, states, lr=0.01, t=Adam_t):global Adam_tbeta1, beta2, eps = 0.9, 0.999, 1e-6for p, (v, s) in zip(params, states):with torch.no_grad():v[:] = beta1 * v + (1 - beta1) * p.grads[:] = beta2 * s + (1 - beta2) * (p.grad**2)v_bias_corr = v / (1 - beta1 ** Adam_t)s_bias_corr = s / (1 - beta2 ** Adam_t)p.data -= lr * v_bias_corr / (torch.sqrt(s_bias_corr + eps))p.grad.data.zero_()Adam_t += 1net31 = Net()
trainL31, testL31, trainAcc31, testAcc31 = train_and_test(model=net31,epochs=10,init_states=init_adam_states, optimizer=Adam)
# nn实现adam
net32 = MyNet_NN()
net32 = net32.to(device)optim_Adam = torch.optim.Adam(net32.parameters(), lr=0.01, betas=(0.9,0.999),eps=1e-6)
trainL32, testL32, trainAcc32, testAcc32 = train_and_test_NN(model=net32,epochs=10,optimizer=optim_Adam)
name11= ['RMSprop','Momentum','Adam','手动实现不同的优化器-Loss变化']
train11 = [trainL11,trainL21,trainL31]
test11= [testL11, testL21, testL31]
draw(name11, train11, test11)
name12= ['RMSprop','Momentum','Adam','torch.nn实现不同的优化器-Loss变化']
train12 = [trainL12,trainL22,trainL32]
test12 = [testL12, testL22, testL32]
draw(name12, train12, test12)
二、在多分类任务实验中分别手动实现和用torch.nn实现𝑳𝟐正则化
2.1 任务内容
探究惩罚项的权重对实验结果的影响(可用loss曲线进行展示)
2.2 任务思路及代码
# 定义L2范数惩罚项
def l2_penalty(w):cost = 0for i in range(len(w)):cost += (w[i]**2).sum()return cost / batch_size / 2
# 手动实现
net221 = Net()
trainL221, testL221, trainAcc221, testAcc221 = train_and_test(model=net221,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01,L2=True,lambd=0)net222 = Net()
trainL222, testL222, trainAcc222, testAcc222 = train_and_test(model=net222,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01,L2=True,lambd=2)# 可视化比较
name221 = ['lambd= 0','lambd=2','手动实现不同的惩罚权重lambd-Loss变化']
trains221 = [trainL221,trainL222]
tests221= [testL221,testL222]
draw(name221, trains221, tests221)
## nn实现
net223 = MyNet_NN()
net223 = net223.to(device)
momentum_optimizer = optim.SGD(net223.parameters(), lr=0.01, momentum=0.9)
trainL223, testL223, trainAcc223, testAcc223 = train_and_test_NN(model=net223,epochs=10,optimizer=momentum_optimizer,lr=0.01,weight_decay=0.0)net224 = MyNet_NN()
net224 = net223.to(device)
momentum_optimizer = optim.SGD(net224.parameters(), lr=0.01, momentum=0.9)
trainL224, testL224, trainAcc224, testAcc224 = train_and_test_NN(model=net224,epochs=10,optimizer=momentum_optimizer,lr=0.01,weight_decay=0.01)# 可视化比较
name222 = ['weight_decay=0','weight_decay = 0.01','torch.nn实现不同的惩罚权重lambd-Loss变化']
trains222 = [trainL223,trainL224]
tests222= [testL223,testL224]
draw(name222, trains222, tests222)
三、在多分类任务实验中分别手动实现和用torch.nn实现dropout
3.1 任务内容
探究不同丢弃率对实验结果的影响(可用loss曲线进行展示)
3.2 任务思路及代码
# 为手动模型添加dropout项
class MyNet():def __init__(self,dropout=0.0):# 设置隐藏层和输出层的节点数# global dropoutself.dropout = dropoutprint('dropout: ',self.dropout)self.is_train = Nonenum_inputs, num_hiddens, num_outputs = 28 * 28, 256, 10 # 十分类问题w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,requires_grad=True)b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,requires_grad=True)b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)self.params = [w_1, b_1, w_2, b_2]self.w = [w_1,w_2]# 定义模型结构self.input_layer = lambda x: x.view(x.shape[0], -1)self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2def my_relu(self, x):return torch.max(input=x, other=torch.tensor(0.0))def train(self):self.is_train = Truedef test(self):self.is_test = Falsedef dropout_layer(self, x):dropout =self.dropoutassert 0 <= dropout <= 1 #dropout值必须在0-1之间# dropout==1,所有元素都被丢弃。if dropout == 1:return torch.zeros_like(x)# 在本情况中,所有元素都被保留。if dropout == 0:return xmask = (torch.rand(x.shape) < 1.0 - dropout).float() #rand()返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数return mask * x / (1.0 - dropout)# 定义前向传播def forward(self, x):x = self.input_layer(x)if self.is_train: # 如果是训练过程,则需要开启dropout 否则 需要关闭 dropoutx = self.dropout_layer(x) elif self.is_test:x = self.dropout_layer(x)x = self.my_relu(self.hidden_layer(x))x = self.output_layer(x)return xdef train_and_test3(model=MyNet(),init_states=None,optimizer=optim.SGD,epochs=20,lr=0.01,L2=False,lambd=0):train_all_loss = [] test_all_loss = [] train_ACC, test_ACC = [], [] begintime = time.time()criterion = CrossEntropyLoss() # 损失函数model.train() for epoch in range(epochs):train_l,train_acc_num = 0, 0for data, labels in train_iter:pred = model.forward(data)train_each_loss = criterion(pred, labels) # 计算每次的损失值if L2 == True:train_each_loss += lambd * l2_penalty(model.w)train_l += train_each_loss.item()train_each_loss.backward() # 反向传播if init_states == None: optimizer(model.params, lr, 128) # 使用小批量随机梯度下降迭代模型参数else:states = init_states(model.params)optimizer(model.params,states,lr=lr)# 梯度清零train_acc_num += (pred.argmax(dim=1)==labels).sum().item()for param in model.params:param.grad.data.zero_()train_all_loss.append(train_l) train_ACC.append(train_acc_num / len(mnist_train)) # 添加准确率到列表中model.test() with torch.no_grad():is_train = False # 表明当前为测试阶段,不需要dropout参与test_l, test_acc_num = 0, 0for data, labels in test_iter:pred = model.forward(data)test_each_loss = criterion(pred, labels)test_l += test_each_loss.item()test_acc_num += (pred.argmax(dim=1)==labels).sum().item()test_all_loss.append(test_l)test_ACC.append(test_acc_num / len(mnist_test)) # # 添加准确率到列表中print('epoch: %d\t train loss:%.5f\t test loss:%.5f\t train acc: %.2f\t test acc: %.2f'% (epoch + 1, train_l, test_l, train_ACC[-1],test_ACC[-1]))endtime = time.time()print("手动实现dropout, %d轮 总用时: %.3f" % ( epochs, endtime - begintime))return train_all_loss,test_all_loss,train_ACC,test_ACC
# 手动实现dropout
net331 = MyNet(dropout = 0.0)
trainL331, testL331, trainAcc331, testAcc331= train_and_test3(model=net331,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01)net332 = MyNet(dropout = 0.3)
trainL332, testL332, trainAcc332, testAcc332= train_and_test3(model=net332,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01)net333 = MyNet(dropout = 0.5)
trainL333, testL333, trainAcc333, testAcc333= train_and_test3(model=net333,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01)net334 = MyNet(dropout = 0.8)
trainL334, testL334, trainAcc334, testAcc334= train_and_test3(model=net334,epochs=10,init_states=init_momentum, optimizer=sgd_momentum,lr=0.01)
name331 = ['dropout=0','dropout=0.3','dropout=0.5','dropout=0.8','手动实现不同的dropout-Loss变化']
train331 = [trainL331,trainL332,trainL333,trainL334]
test331 = [testL331,testL332,testL333,testL334]
draw(name331, train331, test331)
# nn实现dropout
net341 = MyNet_NN(dropout=0)
net341 = net341.to(device)
momentum_optimizer = optim.SGD(net341.parameters(), lr=0.01, momentum=0.9)
trainL341, testL341, trainAcc341, testAcc341= train_and_test_NN(model=net341,epochs=10,optimizer=momentum_optimizer,lr=0.01)net342 = MyNet_NN(dropout=0.3)
net342 = net342.to(device)
momentum_optimizer = optim.SGD(net342.parameters(), lr=0.01, momentum=0.9)
trainL342, testL342, trainAcc342, testAcc342= train_and_test_NN(model=net342,epochs=10,optimizer=momentum_optimizer,lr=0.01)net343 = MyNet_NN(dropout=0.5)
net343 = net341.to(device)
momentum_optimizer = optim.SGD(net343.parameters(), lr=0.01, momentum=0.9)
trainL343, testL343, trainAcc343, testAcc343= train_and_test_NN(model=net343,epochs=10,optimizer=momentum_optimizer,lr=0.01)net344 = MyNet_NN(dropout=0.8)
net344 = net344.to(device)
momentum_optimizer = optim.SGD(net344.parameters(), lr=0.01, momentum=0.9)
trainL344, testL344, trainAcc344, testAcc344= train_and_test_NN(model=net344,epochs=10,optimizer=momentum_optimizer,lr=0.01)
name332 = ['dropout=0','dropout=0.3','dropout=0.5','dropout=0.8','手动实现不同的dropout-Loss变化']
train332 = [trainL341,trainL342,trainL343,trainL344]
test332 = [testL341,testL342,testL343,testL344]
draw(name332, train332, test332)
四、对多分类任务实验中实现早停机制,并在测试集上测试
4.1 任务内容
选择上述实验中效果最好的组合,手动将训练数据划分为训练集和验证集,实现早停机制, 并在测试集上进行测试。训练集:验证集=8:2,早停轮数为5.
4.2 任务思路及代码
# 构建数据集
import random
index = list(range(len(mnist_train)))
random.shuffle(index)# 按照 训练集和验证集 8:2 的比例分配各自下标
train_index, val_index = index[ : 48000], index[48000 : ]train_dataset, train_labels = mnist_train.data[train_index], mnist_train.targets[train_index]
val_dataset, val_labels = mnist_train.data[val_index], mnist_train.targets[val_index]
print('训练集:', train_dataset.shape, train_labels.shape)
print('验证集:', val_dataset.shape,val_labels.shape)T_dataset = torch.utils.data.TensorDataset(train_dataset,train_labels)
V_dataset = torch.utils.data.TensorDataset(val_dataset,val_labels)
T_dataloader = torch.utils.data.DataLoader(dataset=T_dataset,batch_size=128,shuffle=True)
V_dataloader = torch.utils.data.DataLoader(dataset=V_dataset,batch_size=128,shuffle=True)
print('T_dataset',len(T_dataset),'T_dataloader batch_size: 128')
print('V_dataset',len(V_dataset),'V_dataloader batch_size: 128')def train_and_test_4(model=MyNet(0.0),epochs=10,lr=0.01,weight_decay=0.0):print(model)# 优化函数, 默认情况下weight_decay为0 通过更改weight_decay的值可以实现L2正则化。optimizer = torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9,0.999),eps=1e-6)criterion = CrossEntropyLoss() # 损失函数train_all_loss = [] # 记录训练集上得loss变化val_all_loss = [] # 记录测试集上的loss变化train_ACC, val_ACC = [], []begintime = time.time()flag_stop = 0for epoch in range(1000):train_l, train_epoch_count, val_epoch_count = 0, 0, 0for data, labels in T_dataloader:data, labels = data.to(torch.float32).to(device), labels.to(device)pred = model(data)train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值optimizer.zero_grad() # 梯度清零train_each_loss.backward() # 反向传播optimizer.step() # 梯度更新train_l += train_each_loss.item()train_epoch_count += (pred.argmax(dim=1)==labels).sum()train_ACC.append(train_epoch_count/len(train_dataset))train_all_loss.append(train_l) # 添加损失值到列表中with torch.no_grad():val_loss, val_epoch_count= 0, 0for data, labels in V_dataloader:data, labels = data.to(torch.float32).to(device), labels.to(device)pred = model(data)val_each_loss = criterion(pred,labels)val_loss += val_each_loss.item()val_epoch_count += (pred.argmax(dim=1)==labels).sum()val_all_loss.append(val_loss)val_ACC.append(val_epoch_count / len(val_dataset))# 实现早停机制# 若连续五次验证集的损失值连续增大,则停止运行,否则继续运行,if epoch > 5 and val_all_loss[-1] > val_all_loss[-2]:flag_stop += 1if flag_stop == 5 or epoch > 35:print('停止运行,防止过拟合')breakelse:flag_stop = 0if epoch == 0 or (epoch + 1) % 4 == 0:print('epoch: %d | train loss:%.5f | val loss:%.5f | train acc:%5f val acc:%.5f:' % (epoch + 1, train_all_loss[-1], val_all_loss[-1],train_ACC[-1],val_ACC[-1]))endtime = time.time()print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3fs" % (epochs, endtime - begintime))# 返回训练集和测试集上的 损失值 与 准确率return train_all_loss,val_all_loss,train_ACC,val_ACCnet4 = MyNet_NN(dropout=0.5)
net4 = net4.to(device)
trainL4, testL4, trainAcc4, testAcc4= train_and_test_4(model=net4,epochs = 10000,lr=0.1)
draw(['', '早停机制'], [trainL4], [testL4])
实验总结
实验中我们通过两种方式构建了前馈神经网络,一种是手动搭建,另一种是利用PyTorch中的torch.nn模块进行构建。在这两种网络结构的基础上,分别引入了dropout层,以有效地防止模型的过拟合现象。
-
首先,在优化器的选择上,我们尝试了不同的优化函数,并对它们在模型训练中的效果进行了比较。不同的优化器具有不同的优点,通过对比它们的性能,我们可以更好地选择适合具体任务的优化器,进一步提升模型的性能。
-
其次,我们引入了惩罚权重的概念,通过增加惩罚项来约束模型的复杂度。实验结果表明,适度增加惩罚权重可以在一定程度上增大模型输出的损失,但同时也达到了防止过拟合的效果。这进一步证实了模型复杂度与过拟合之间存在一定的权衡关系。
-
通过实验我们观察到,适当设置dropout的概率可以显著减轻模型的过拟合问题。dropout通过在训练过程中随机丢弃一部分神经元的输出,有效降低了模型对于训练数据的过度依赖,提高了模型的泛化能力,从而在测试集上表现更为鲁棒。
-
最后,为了进一步提高模型的训练效果,我们引入了早停机制。该机制通过监测在验证集上的测试误差,在发现测试误差上升的情况下停止训练,以防止网络过拟合。早停机制在一定程度上能够避免模型在训练过程中过分拟合训练数据,从而提高了模型的泛化性能。
通过以上实验,我们综合考虑了dropout、惩罚权重、不同优化器以及早停机制等因素,为构建更稳健、泛化能力强的前馈神经网络提供了有益的经验和指导。这些技术手段的灵活运用可以在实际任务中更好地平衡模型的性能和泛化能力。
相关文章:

深度学习本科课程 实验3 网络优化
一、在多分类任务实验中实现momentum、rmsprop、adam优化器 1.1 任务内容 在手动实现多分类的任务中手动实现三种优化算法,并补全Adam中计算部分的内容在torch.nn实现多分类的任务中使用torch.nn实现各种优化器,并对比其效果 1.2 任务思路及代码 imp…...
Eclipse 安装使用ABAPGit
Eclipse->Help->Install New software 添加地址 https://eclipse.abapgit.org/updatesite/ 安装完成打开 选择abapGit repositories,先添加仓库 点下图添加自己仓库 如图添加仓库地址 添加完仓库后,点击我的仓库 右键选中行,可以进行push和pu…...

std::mutex std::recursive_mutex std::shared_mutex
std::mutex C11。最简单的互斥锁,1个线程内,不支持重复加锁。 std::lock_guard<std::mutex> lock(mutex) std::recursive_mutex C11。可以替代st::mutex,但性能会下降。1个线程内,支持重复加锁(可重入&#x…...

vscode的vetur文档格式化失效
如果vscode安装了vetur插件之后,shiftAltF又无法格式化vue文件代码。 解决办法:打开文件 ---> 首选项 ---> 设置,搜索 vetur.format.defaultFormatter.html后将prettier替换勾选为js-beautify-html 注:设置下划线了并可以在…...
idea 快捷键ctrl+shift+f失效的解决方案
文章目录 搜狗输入法快捷键冲突微软输入法快捷键冲突 idea的快捷键ctrlshiftf按了没反应,理论上是快捷键冲突了,检查搜狗输入法和微软输入法快捷键。 搜狗输入法快捷键冲突 不需要简繁切换的快捷键,可以关闭它,或修改快捷键。 微…...

C++面试:数据库的连接池管理
目录 基本概念 工作原理 核心组件 实现机制 优点 缺点 实践建议 实例 场景描述 解决方案:引入数据库连接池 配置数据库连接池 使用连接池 监控和调优 效果 结论 数据库连接池管理是一个在软件开发中常见的优化策略,特别是在需要频繁访问数…...
)
React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用)
文章目录 React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用)错误使用案例案例具体解决方法 React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用) hooks使用规则 只能在函数最外层调用 Hook。不要在…...
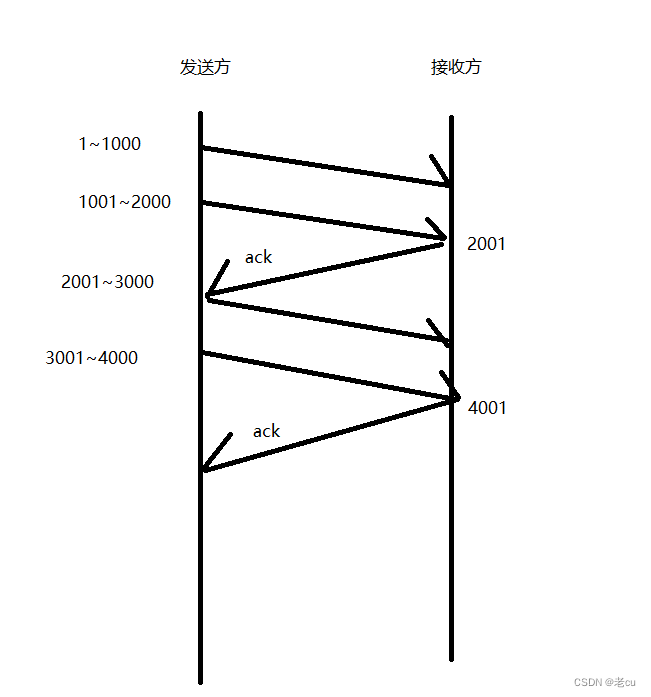
深入理解TCP网络协议(3)
目录 1.前言 2.流量控制 2.阻塞控制 3.延时应答 4.捎带应答 5.面向字节流 6.缓冲区 7.粘包问题 8.TCP异常情况 9.小结 1.前言 在前面的博客中,我们重点介绍了TCP协议的一些属性,有连接属性的三次握手和四次挥手,还有保证数据安全的重传机制和确认应答,还有为了提高效率…...

JavaScript实现归并排序及vscode输出乱码解决
思路 归并排序思路:11.6 归并排序 - Hello 算法 总体上来讲就是 递归分解 归并排序 代码如下↓ 代码 //归并排序 function merge(left, right){console.log(flag);console.log(left);console.log(right);let result new Array();let il 0, ir 0;//左右两个数…...

Redis面试题40
人工智能如何影响医疗保健行业? 答:人工智能对医疗保健行业产生了深远的影响,为医疗保健提供了更高效、准确和个性化的服务。以下是一些人工智能在医疗保健领域的应用示例: 疾病诊断:人工智能可以利用机器学习和深度学…...

2024年危险化学品经营单位安全管理人员证考试题库及危险化学品经营单位安全管理人员试题解析
题库来源:安全生产模拟考试一点通公众号小程序 2024年危险化学品经营单位安全管理人员证考试题库及危险化学品经营单位安全管理人员试题解析是安全生产模拟考试一点通结合(安监局)特种作业人员操作证考试大纲和(质检局࿰…...
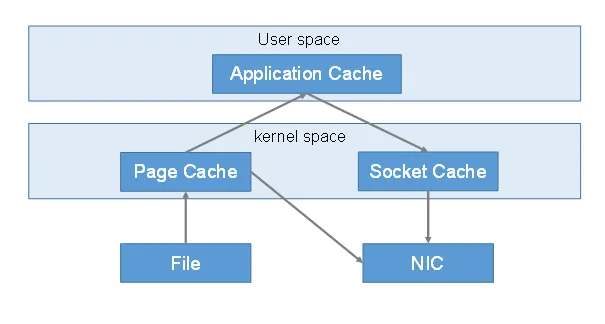
Kafka相关内容复习
为什么要用消息队列 解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 可恢复性 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队…...

JVM之Java内存区域
JVM-Java内存区域 Java内存区域是Java虚拟机(JVM)管理的内存资源的逻辑划分,用于存储程序运行时所需的数据。Java内存区域的合理划分和管理对于程序的性能和稳定性具有重要影响。本文将深入探讨Java内存区域的各个部分,包括方法区…...

几个MySQL系统调优工具
几个MySQL系统调优工具 可以使用下面几个工具来做基准测试: sysbench:一个模块化,跨平台以及多线程的性能测试工具。 https://github.com/akopytov/sysbench iibench-mysql:基于Java的MySQL / Percona / MariaDB 索引进行插入性能…...
)
Linux内核与驱动面试经典“小”问题集锦(2)
接前一篇文章:Linux内核与驱动面试经典“小”问题集锦(1) 问题2 问:spin_lock和spin_lock_irq以及spin_lock_irqsave的区别是什么?也可以说它们之间有什么区别和联系? 备注:此题是自旋锁问题的…...

windws安装mysql详细步骤
1.下载地址: https://dev.mysql.com/downloads/mysql/2.下载好mysql安装包后,将其解压到指定目录,并记下解压的目录,后续用于环境变量配置: 3. 在bin目录同级下创建一个文件,命名为my.ini [mysqld] # 设…...
Linux的库文件
目录 概述: 静态库: 静态库概述: 静态库的制作 共享库(动态库) 共享库概述 动态库制作 动态库临时生效 动态库长期生效 动态库的升级 位置无关代码 概述: 库文件一般就是编译好的二进制文件&…...
JAVA Web 学习(五)Nginx、RPC、JWT
十二、反向代理服务器——Nginx 支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。性能是 Nginx 最重要的考量,其占用内存少、并发能力强、能支持…...

Python编程的十大神奇依赖库
Python是一门广受欢迎的编程语言,其生态系统丰富多彩,拥有许多令人惊叹的依赖库,可以帮助程序员们在各种领域中创造出令人瞠目结舌的应用。在这篇文章中,我们将探讨Python编程的十大神奇依赖库,它们像魔法一样…...

Java类的继承
XHTMLMapper继承 XWPFDocumentVisitor: 由于endVisitTableCell是抽象方法,XHTMLMapper中必须要实现; existErr()子类是否重写都是自由的; public abstract class XWPFDocumentVisitor<T, O extends Options, E extends IXWPFM…...

cv_unet_image-colorization多分辨率适配实测:手机扫描件/胶片扫描图效果对比
cv_unet_image-colorization多分辨率适配实测:手机扫描件/胶片扫描图效果对比 1. 项目背景与技术原理 基于UNet架构深度学习模型开发的本地化图像上色工具,采用了阿里魔搭开源的图像上色算法。这个工具能够智能识别黑白图像中的物体特征、自然场景和人…...

资深大模型工程师详细讲解:RAG召回率优化三重微调实战
✅ 一、核心策略再解构:从“三层次”到“五维协同链路”原有“数据-索引-查询”三层结构非常精准,但为了更贴近企业级复杂场景,我们进一步抽象为 五维协同链路:维度关键目标是否可微调微调切入点1. 数据生成质量构建高质量正负样本…...

在Ubuntu 24.04上从源码编译PETSc:一个给计算科学新手的保姆级避坑指南
在Ubuntu 24.04上从源码编译PETSc:一个给计算科学新手的保姆级避坑指南 第一次在Ubuntu上编译科学计算库的经历,往往像闯进了一个满是隐藏陷阱的迷宫。作为过来人,我完全理解当看到满屏红色错误提示时的无助感——那些神秘的configure参数、突…...

解密Abaqus许可证“心跳”机制与合理超时时间设置
解密Abaqus许可证“心跳”机制跟合理超时时间设置你是不单是也碰到过这种情况:Abaqus许可证明明用不了,可系统还在继续计费?我在一家制造企业做许可证优化,就碰到了此老问题。为何许可证会“死掉”?这跟许可证的心跳&a…...

「码动四季·开源同行」go实战案例:如何保证微服务实例资源安全?
今天我和你分享的是如何保证微服务实例资源安全的案例。在前文,我们实践了如何使用Go搭建一个基本的授权服务器,它的主要功能是颁发访问令牌和验证访问令牌的有效性。在统一认证与授权服务体系中,还存在资源服务器对用户数据进行保护…...

Gerbv:免费开源Gerber文件查看器的终极指南,PCB设计验证的得力助手
Gerbv:免费开源Gerber文件查看器的终极指南,PCB设计验证的得力助手 【免费下载链接】gerbv Maintained fork of gerbv, carrying mostly bugfixes 项目地址: https://gitcode.com/gh_mirrors/ge/gerbv 你是否曾经为PCB设计文件的查看而烦恼&#…...

AI 赋能下新型网络钓鱼攻击演进与多维度防御技术研究
摘要 生成式人工智能的普及使网络钓鱼攻击进入智能化、隐蔽化新阶段,攻击周期大幅缩短、伪装精度显著提升,传统基于规则与特征库的防御机制失效。本文结合 ESET 安全研究与企业实测数据,剖析 AI 驱动钓鱼攻击的技术机理、混淆手段与传播路径&…...

AI辅助开发创意秀:让快马AI为你定制专属的antigravity式彩蛋代码
最近在尝试用AI辅助开发一些有趣的小项目,发现InsCode(快马)平台特别适合快速实现这类创意编程。今天就来分享一个用AI生成个性化编程彩蛋的完整实现过程,效果类似Python著名的antigravity彩蛋,但加入了用户自定义内容。 项目构思 这个项目的…...

Intv_ai_mk11在人工智能教育中的应用:个性化学习伙伴
Intv_ai_mk11在人工智能教育中的应用:个性化学习伙伴 1. 教育领域的新助手 最近几年,人工智能在教育领域的应用越来越广泛。作为一款专门为教育场景设计的AI助手,Intv_ai_mk11正在改变传统学习方式。它不仅能解答学生问题,还能根…...

新手零代码入门:用快马ai一键生成vmware虚拟机图文安装教程
新手零代码入门:用快马AI一键生成VMware虚拟机图文安装教程 最近在学网络安全和Linux系统,第一步就是要搭建虚拟机环境。作为完全没接触过虚拟化技术的小白,我原本以为安装VMware会很复杂,结果发现用InsCode(快马)平台的AI功能&a…...