MySQL进阶45讲【10】MySQL为什么有时候会选错索引?
1 前言
前面我们介绍过索引,在MySQL中一张表其实是可以支持多个索引的。但是,写SQL语句的时候,并没有主动指定使用哪个索引。也就是说,使用哪个索引是由MySQL来确定的。
大家有没有碰到过这种情况,一条本来可以执行得很快的语句,却由于MySQL选错了索引,而导致执行速度变得很慢?
我们一起来看一个例子吧。
我们先建一个简单的表,表里有a、b两个字段,并分别建上索引:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
然后,我们往表t中插入10万行记录,取值按整数递增,即:(1,1,1),(2,2,2),(3,3,3) 直到(100000,100000,100000)。
使用存储过程来插入数据,这里是存储过程的源代码
delimiter ;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
接下来,我们分析一条SQL语句:
mysql> select * from t where a between 10000 and 20000;
这句SQL毋庸置疑,a上有索引,肯定是要使用索引a。
我们来证实一下,图1显示的就是使用explain命令看到的这条语句的执行情况。

从图1看上去,这条查询语句的执行也确实符合预期,key这个字段值是’a’,表示优化器选择了索引a。
在我们已经准备好的包含了10万行数据的表上,我们再做如下操作。

这里,session A的操作已经很熟悉了,它就是开启了一个事务。随后,session B把数据都删除后,又调用了 idata这个存储过程,插入了10万行数据。
这时候,session B的查询语句select * from t where a between 10000 and 20000就不会再选择索引a了。我们可以通过慢查询日志(slowlog)来查看一下具体的执行情况。
为了说明优化器选择的结果是否正确,增加了一个对照,即:使用force index(a)来让优化器强制使用索引a(这部分内容,在这篇文章的后半部分中会提到)。
下面的三条SQL语句,就是这个实验过程。
set long_query_time=0;
select * from t where a between 10000 and 20000; /*Q1*/
select * from t force index(a) where a between 10000 and 20000;/*Q2*/
- 第一句,是将慢查询日志的阈值设置为0,表示这个线程接下来的语句都会被记录入慢查询日志中;
- 第二句,Q1是session B原来的查询;
- 第三句,Q2是加了force index(a)来和session B原来的查询语句执行情况对比。
如图3所示是这三条SQL语句执行完成后的慢查询日志。
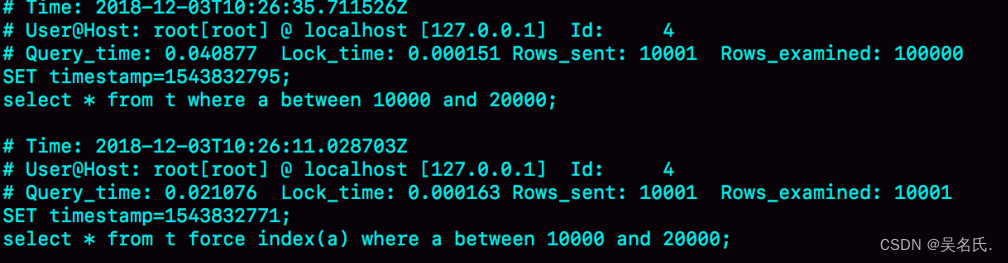
可以看到,Q1扫描了10万行,显然是走了全表扫描,执行时间是40毫秒。Q2扫描了10001行,执行了21毫秒。也就是说,我们在没有使用force index的时候,MySQL用错了索引,导致了更长的执行时间。
这个例子对应的是我们平常不断地删除历史数据和新增数据的场景。这时,MySQL竟然会选错索引,是不是有点奇怪呢?今天,我们就从这个奇怪的结果说起吧。
2 优化器的逻辑
在第一篇文章(MySQL进阶45讲【1】基础架构:一条SQL查询语句是如何执行的?)中,我们就提到过,选择索引是优化器的工作。
而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的CPU资源越少。
当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
我们这个简单的查询语句并没有涉及到临时表和排序,所以MySQL选错索引肯定是在判断扫描行数的时候出问题了。
那么,问题就是:扫描行数是怎么判断的?
MySQL在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
我们可以使用show index方法,看到一个索引的基数。如图4所示,就是表t的show index的结果。虽然这个表的每一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且其实都不准确。

那么,MySQL是怎样得到索引的基数的呢?这里简单介绍一下MySQL采样统计的方法。
为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。
采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:
- 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。
- 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16。
由于是采样统计,所以不管N是20还是8,这个基数都是很容易不准的。
但,这还不是全部。
从图4中看到,这次的索引统计值(cardinality列)虽然不够精确,但大体上还是差不多的,选错索引一定还有别的原因。
其实索引统计只是一个输入,对于一个具体的语句来说,优化器还要判断,执行这个语句本身要扫描多少行。
接下来,我们再一起看看优化器预估的,这两个语句的扫描行数是多少。

rows这个字段表示的是预计扫描行数。
其中,Q1的结果还是符合预期的,rows的值是104620;但是Q2的rows值是37116,偏差就大了。而图1中我们用explain命令看到的rows是只有10001行,是这个偏差误导了优化器的判断。
优化器为什么放着扫描37000行的执行计划不用,却选择了扫描行数是100000的执行计划呢?
这是因为,如果使用索引a,每次从索引a上拿到一个值,都要回到主键索引上查出整行数据,这个代价优化器也要算进去的。
而如果选择扫描10万行,是直接在主键索引上扫描的,没有额外的代价。
优化器会估算这两个选择的代价,从结果看来,优化器认为直接扫描主键索引更快。当然,从执行时间看来,这个选择并不是最优的。
使用普通索引需要把回表的代价算进去,在图1执行explain的时候,也考虑了这个策略的代价 ,但图1的选择是对的。也就是说,这个策略并没有问题。
所以冤有头债有主,MySQL选错索引,这件事儿还得归咎到没能准确地判断出扫描行数。
既然是统计信息不对,那就修正。使用analyze table t 命令,可以用来重新统计索引信息。我们来看一下执行效果。
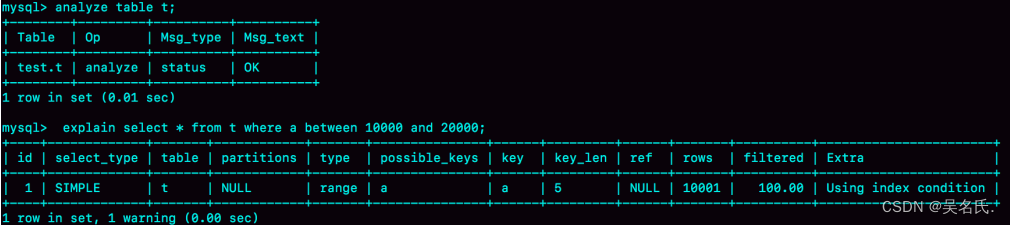
这回对了。
所以在实践中,如果发现explain的结果预估的rows值跟实际情况差距比较大,可以采用这个方法来处理。
其实,如果只是索引统计不准确,通过analyze命令可以解决很多问题,但是前面我们说了,优化器可不止是看扫描行数。
依然是基于这个表t,我们看看另外一个语句:
mysql> select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1
从条件上看,这个查询没有符合条件的记录,因此会返回空集合。
在开始执行这条语句之前,可以先设想一下,如果由大家来选择索引,会选择哪一个呢?
为了便于分析,我们先来看一下a、b这两个索引的结构图。
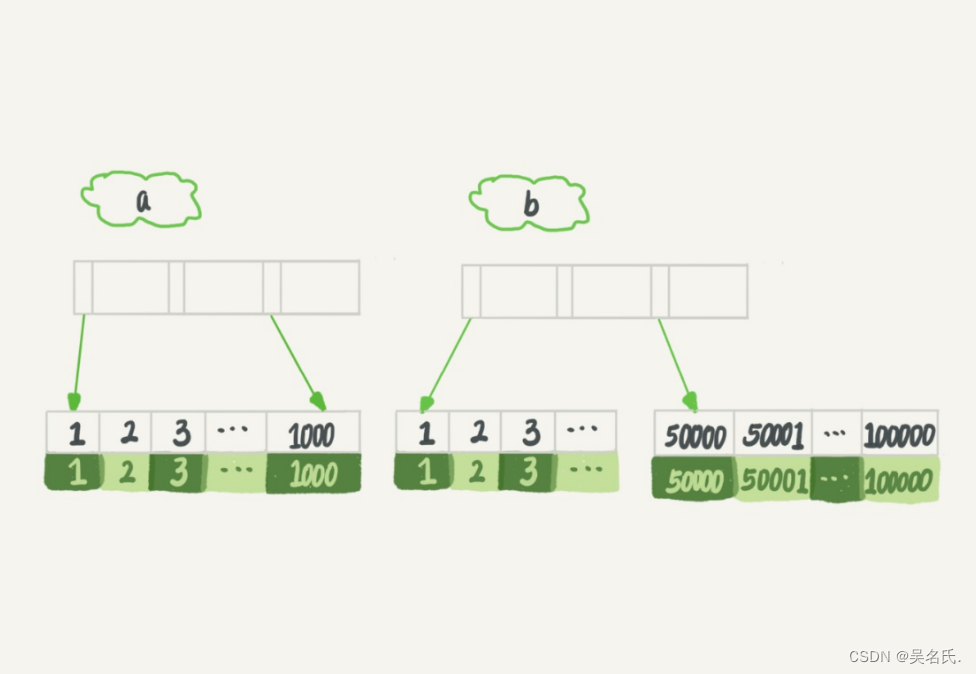
如果使用索引a进行查询,那么就是扫描索引a的前1000个值,然后取到对应的id,再到主键索引上去查出每一行,然后根据字段b来过滤。显然这样需要扫描1000行。
如果使用索引b进行查询,那么就是扫描索引b的最后50001个值,与上面的执行过程相同,也是需要回到主键索引上取值再判断,所以需要扫描50001行。
所以大家可能会想,如果使用索引a的话,执行速度明显会快很多。那么,下面我们就来看看到底是不是这么一回事儿。
图8是执行explain的结果。
mysql> explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1

可以看到,返回结果中key字段显示,这次优化器选择了索引b,而rows字段显示需要扫描的行数是50198。
从这个结果中,可以得到两个结论:
- 扫描行数的估计值依然不准确;
- 这个例子里MySQL又选错了索引。
3 索引选择异常和处理
其实大多数时候优化器都能找到正确的索引,但偶尔还是会碰到我们上面举例的这两种情况:原本可以执行得很快的SQL语句,执行速度却比预期的慢很多,我们应该怎么办呢?
一种方法是,像我们第一个例子一样,采用force index强行选择一个索引。MySQL会根据词法解析的结果分析出可能可以使用的索引作为候选项,然后在候选列表中依次判断每个索引需要扫描多少行。如果force index指定的索引在候选索引列表中,就直接选择这个索引,不再评估其他索引的执行代价。
我们来看看第二个例子。刚开始分析时,我们认为选择索引a会更好。现在,我们就来看看执行效果:

可以看到,原本语句需要执行2.23秒,而当使用force index(a)的时候,只用了0.05秒,比优化器的选择快了40多倍。
也就是说,优化器没有选择正确的索引,force index起到了“矫正”的作用。
不过很多程序员不喜欢使用force index,一来这么写不优美,二来如果索引改了名字,这个语句也得改,显得很麻烦。而且如果以后迁移到别的数据库的话,这个语法还可能会不兼容。
但其实使用force index最主要的问题还是变更的及时性。因为选错索引的情况还是比较少出现的,所以开发的时候通常不会先写上force index。而是等到线上出现问题的时候,才会再去修改SQL语句、加上force index。但是修改之后还要测试和发布,对于生产系统来说,这个过程不够敏捷。
所以,数据库的问题最好还是在数据库内部来解决。那么,在数据库里面该怎样解决呢?
既然优化器放弃了使用索引a,说明a还不够合适,所以第二种方法就是,我们可以考虑修改语句,引导MySQL使用我们期望的索引。比如,在这个例子里,显然把“order by b limit 1” 改成 “order by b,a limit 1” ,语义的逻辑是相同的。我们来看看改之后的效果:

之前优化器选择使用索引b,是因为它认为使用索引b可以避免排序(b本身是索引,已经是有序的了,如果选择索引b的话,不需要再做排序,只需要遍历),所以即使扫描行数多,也判定为代价更小。
现在order byb,a 这种写法,要求按照b,a排序,就意味着使用这两个索引都需要排序。因此,扫描行数成了影响决策的主要条件,于是此时优化器选了只需要扫描1000行的索引a。
当然,这种修改并不是通用的优化手段,只是刚好在这个语句里面有limit 1,因此如果有满足条件的记录, order by b limit 1和order byb,a limit 1 都会返回b是最小的那一行,逻辑上一致,才可以这么做。
如果觉得修改语义这件事儿不太好,这里还有一种改法,图11是执行效果。
mysql> select * from (select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 100 ) alias limit 1;

在这个例子里,我们用limit 100让优化器意识到,使用b索引代价是很高的。其实是我们根据数据特征诱导了一下优化器,也不具备通用性。
第三种方法是,在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
不过,在这个例子中,没有找到通过新增索引来改变优化器行为的方法。这种情况其实比较少,尤其是经过DBA索引优化过的库,再碰到这个bug,找到一个更合适的索引一般比较难。
但其实还有一个有意思的方法就是删掉索引b,大家可能会觉得好笑。但实际上有时候会起到意想不到的作用,如果发现这个优化器错误选择的索引其实根本没有必要存在,于是就删掉了这个索引,优化器也就重新选择到了正确的索引。
4 小结
今天我们一起聊了聊索引统计的更新机制,并提到了优化器存在选错索引的可能性。
对于由于索引统计信息不准确导致的问题,可以用analyze table来解决。
而对于其他优化器误判的情况,可以在应用端用force index来强行指定索引,也可以通过修改语句来引导优化器,还可以通过增加或者删除索引来绕过这个问题。
相关文章:
MySQL进阶45讲【10】MySQL为什么有时候会选错索引?
1 前言 前面我们介绍过索引,在MySQL中一张表其实是可以支持多个索引的。但是,写SQL语句的时候,并没有主动指定使用哪个索引。也就是说,使用哪个索引是由MySQL来确定的。 大家有没有碰到过这种情况,一条本来可以执行得…...

网络安全-端口扫描和服务识别的几种方式
禁止未授权测试!!! 前言 在日常的渗透测试中,我们拿到一个ip或者域名之后,需要做的事情就是搞清楚这台主机上运行的服务有哪些,开放的端口有哪些。如果我们连开放的端口和服务都不知道,下一步针…...
【分布式】雪花算法学习笔记
雪花算法学习笔记 来源 https://pdai.tech/md/algorithm/alg-domain-id-snowflake.html概述 雪花算法是推特开源的分布式ID生成算法,以划分命名空间的方式将64位分割成多个部分,每一个部分代表不同的含义,这种就是将64位划分成不同的段&…...

6.函数表达式 - JS
函数表达式 function (someArgs) { someStatements } function name(someArgs) { someStatements } (someArgs) > { someStatements }函数表达式就是要,在一个表达式中定义一个函数;箭头函数也是一个简洁的函数表达式;执行完函数表达式&a…...

【RK3288 Android10 C30 支持sim卡拔掉不弹窗,及热插拔】
文章目录 【RK3288 Android10 C30 支持sim卡拔掉不弹窗,及热插拔】需求方案patchframework【RK3288 Android10 C30 支持sim卡拔掉不弹窗,及热插拔】 需求 由于3288 硬件上的sim卡座不支持热插拔,是没有顶针来识别sim卡是否被拔掉的。所以在sim被拔掉或者松动的时候,会弹窗…...

python生成docx文件
使用python自动生成一张想要的docx文件 在这其中有指纹和公司盖章 from PIL import Image from docx import Document from docx.oxml.ns import qn from docx.shared import Pt, Inches, Cm from docx.enum.text import WD_PARAGRAPH_ALIGNMENT from xlsxtpl.writerx import …...

网络异常案例四_IP异常
问题现象 终端设备离线,现场根据设备ip,ping不通。查看路由器。 同一个路由器显示的终端设备(走同一个wifi模块接入),包含不同网段的ip。 现场是基于三层的无线漫游,多个路由器wifi配置了相同的ssid信息&a…...

Hack The Box-Challenges-Misc-M0rsarchive
解压压缩包,里面是一张图片和一个新的zip文件 图片放大后的图案是----. 考虑到为莫斯密码,将其解密 密码为9,继续解压缩包 又是一张莫斯密码图加压缩包,写一段脚本去解密图片中的莫斯密码,并自动解压缩包 import re i…...

验证码倒计时:用户界面的小细节,大智慧
欢迎来到我的博客,代码的世界里,每一行都是一个故事 验证码倒计时:用户界面的小细节,大智慧 前言为什么需要验证码倒计时防止滥用:用户心理: 设计考量可见性:友好性:适应性ÿ…...

Web后端:CSRF攻击及应对方法
CSRF攻击是开发Web后端时需要重点解决的问题。 那么什么是CSRF攻击呢? CSRF跨站点请求伪造(Cross—Site Request Forgery),其主要利用的是Cookie的一个弱点,就是Cookie 最初被设计成了允许在第三方网站发起的请求中携带: 关于Co…...

【手写数据库toadb】toadb表对象访问操作,存储管理抽象层软件架构设计思想应用
21 表文件访问秘密 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方便…...

SpringBoot使用Rabbit详解含完整代码
点击下载《SpringBoot使用Rabbit详解含完整代码》 1. 摘要 本文将详细介绍如何在Spring Boot应用程序中集成和使用RabbitMQ消息队列。RabbitMQ是一个开源的消息代理和队列服务器,用于通过轻量级和可靠的消息在应用程序或系统之间进行异步通信。本文将通过步骤说明…...

深度学习本科课程 实验3 网络优化
一、在多分类任务实验中实现momentum、rmsprop、adam优化器 1.1 任务内容 在手动实现多分类的任务中手动实现三种优化算法,并补全Adam中计算部分的内容在torch.nn实现多分类的任务中使用torch.nn实现各种优化器,并对比其效果 1.2 任务思路及代码 imp…...
Eclipse 安装使用ABAPGit
Eclipse->Help->Install New software 添加地址 https://eclipse.abapgit.org/updatesite/ 安装完成打开 选择abapGit repositories,先添加仓库 点下图添加自己仓库 如图添加仓库地址 添加完仓库后,点击我的仓库 右键选中行,可以进行push和pu…...

std::mutex std::recursive_mutex std::shared_mutex
std::mutex C11。最简单的互斥锁,1个线程内,不支持重复加锁。 std::lock_guard<std::mutex> lock(mutex) std::recursive_mutex C11。可以替代st::mutex,但性能会下降。1个线程内,支持重复加锁(可重入&#x…...

vscode的vetur文档格式化失效
如果vscode安装了vetur插件之后,shiftAltF又无法格式化vue文件代码。 解决办法:打开文件 ---> 首选项 ---> 设置,搜索 vetur.format.defaultFormatter.html后将prettier替换勾选为js-beautify-html 注:设置下划线了并可以在…...
idea 快捷键ctrl+shift+f失效的解决方案
文章目录 搜狗输入法快捷键冲突微软输入法快捷键冲突 idea的快捷键ctrlshiftf按了没反应,理论上是快捷键冲突了,检查搜狗输入法和微软输入法快捷键。 搜狗输入法快捷键冲突 不需要简繁切换的快捷键,可以关闭它,或修改快捷键。 微…...

C++面试:数据库的连接池管理
目录 基本概念 工作原理 核心组件 实现机制 优点 缺点 实践建议 实例 场景描述 解决方案:引入数据库连接池 配置数据库连接池 使用连接池 监控和调优 效果 结论 数据库连接池管理是一个在软件开发中常见的优化策略,特别是在需要频繁访问数…...
)
React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用)
文章目录 React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用)错误使用案例案例具体解决方法 React Hook之钩子调用规则(不在循环、条件判断或者嵌套函数中调用) hooks使用规则 只能在函数最外层调用 Hook。不要在…...
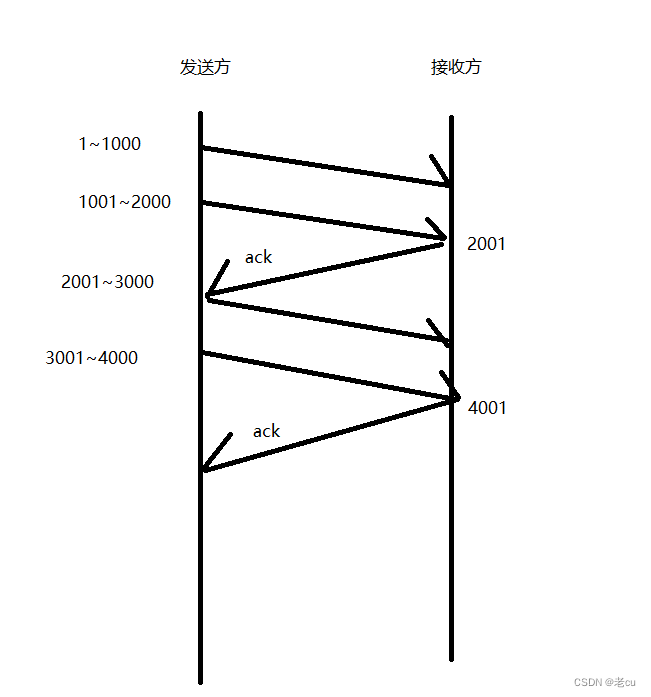
深入理解TCP网络协议(3)
目录 1.前言 2.流量控制 2.阻塞控制 3.延时应答 4.捎带应答 5.面向字节流 6.缓冲区 7.粘包问题 8.TCP异常情况 9.小结 1.前言 在前面的博客中,我们重点介绍了TCP协议的一些属性,有连接属性的三次握手和四次挥手,还有保证数据安全的重传机制和确认应答,还有为了提高效率…...

SEO工具如何提供网站的整体优化建议
SEO工具如何提供网站的整体优化建议 在当今竞争激烈的互联网市场中,网站的整体优化是每一个企业和个人网站的重要任务。SEO工具在这一过程中扮演着不可或缺的角色。SEO工具如何提供网站的整体优化建议呢?本文将从问题分析、原因说明、解决方法、注意事项…...

OpenClaw性能优化:提升Kimi-VL-A3B-Thinking多模态任务执行效率
OpenClaw性能优化:提升Kimi-VL-A3B-Thinking多模态任务执行效率 1. 为什么需要性能优化? 上周我尝试用OpenClaw对接Kimi-VL-A3B-Thinking多模态模型处理一批产品截图分析任务。原本预计2小时完成的工作,实际运行了整整8小时——期间不仅消耗…...

突破性能瓶颈:Rust如何重塑数据科学与AI的未来
突破性能瓶颈:Rust如何重塑数据科学与AI的未来 在当今数据驱动的时代,数据科学与AI领域正面临着前所未有的性能挑战。随着数据集规模的爆炸式增长和模型复杂度的不断提升,传统编程语言在处理高并发、大规模数据时逐渐显露出性能瓶颈。而Rust…...

轰动全国的“327国债期货事件”的四大赢家后来都怎么样了?
轰动全国的“327国债期货事件”的四大赢家后来都怎么样了?轰动全国的“327国债期货事件”,四大赢家28岁的魏东、29岁的袁宝璟、34岁的周正毅以及30岁的刘汉,一举实现资本原始积累,称霸一方。天道好还,四人最终悲剧谢幕…...
)
基于STM32的充电桩控制器设计(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T4532205M设计简介:本设计是基于单片机的充电桩控制器设计,主要实现以下功能:1、RFID可以注册卡以及删除卡,…...

OpenClaw+SecGPT-14B:个人安全实验室自动化搭建全指南
OpenClawSecGPT-14B:个人安全实验室自动化搭建全指南 1. 为什么需要自动化安全实验室 作为一名长期从事安全研究的工程师,我深刻体会到传统手工分析的低效与局限。每次分析新样本时,都需要重复搭建环境、配置工具、收集威胁情报,…...

Phi-4-mini-reasoning效果展示:高精度数学题求解与逻辑推导实测
Phi-4-mini-reasoning效果展示:高精度数学题求解与逻辑推导实测 1. 模型核心能力概览 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,在数学解题和逻辑分析方面展现出惊人的能力。与通用聊天模型不同,它专为多步推理和精确结论而…...

Qwen-Ranker Pro入门指南:语义热力图折线趋势与得分分布解读
Qwen-Ranker Pro入门指南:语义热力图折线趋势与得分分布解读 你用过搜索引擎吗?有没有遇到过这种情况:明明输入了很具体的问题,但搜出来的结果,排在前面的总是一些“看起来”关键词匹配,但实际内容完全不沾…...

AI工程师的终极目标:技术专家还是管理者
在人工智能浪潮席卷全球的今天,AI工程师已成为技术领域最炙手可热的角色之一。对于软件测试从业者而言,随着AI测试、自动化测试平台和智能质量保障体系的兴起,职业发展的边界正在被重新定义。当我们站在职业生涯的十字路口,一个根…...

Kotlin重构与跨平台通信:Linphone的开源通信解决方案革新
Kotlin重构与跨平台通信:Linphone的开源通信解决方案革新 【免费下载链接】linphone-android Linphone.org mirror for linphone-android (https://gitlab.linphone.org/BC/public/linphone-android) 项目地址: https://gitcode.com/gh_mirrors/li/linphone-andro…...