LangChain结合通义千问的自建知识库
LangChain结合通义千问的自建知识库
在使用了通义千问API了之后,下一步就是构建知识库文档,使用了比较有名的LangChian,最后成果将自己的txt生成了知识向量库,最后我还把自己的论文生成了一个知识向量库,然后问他我的创新点是啥,实话实说比我总结的好,我想这下回老师要是看不懂我论文的时候能不能直接,嗯,对吧,反正也是工作中用到还挺有意思的,能分享的部分我都分享出来了,然后这个是接着这个专栏的第一篇的延申文档。
文章目录
- LangChain结合通义千问的自建知识库
- 1.文本切片
- 2.读取本地Embedding模型
- 3. 保存向量数据库
- 4.检索数据库中的相似样本
- 5.使用通义千问总结归纳
- 6.额外补充 LangChain 使用通义模型进行流式输出
- 7.目前发现的LangChain使用问题总结
调用阿里通义千问大语言模型API-小白新手教程-python
1.文本切片
在构建知识库的过程中,文本切片是一项关键步骤,其目的在于将大型文档分解成更小、更易于管理的单元、提升检索效率
使用LangChian库进行文本切分,实现代码如下,之后对关键代码进行详细介和API函数的参数介绍。
from langchain_community.document_loaders import UnstructuredFileLoader
# 旧版用法
# from langchain.document_loaders import UnstructuredFileLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitter# 导入文本
loader = UnstructuredFileLoader("test.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:",len(split_docs))
print(split_docs)
langchain_community.document_loaders
官网文档地址:https://python.langchain.com/docs/modules/data_connection/document_loaders
UnstructuredFileLoader主要用于加载文件中未结构化的文本,用于对未处理的文件进行一些预处理编码识别,格式规范化等,确保文本数据识别接下来的预处理,该函数可以用于读取txt文件,不能处理csv格式文件 csv格式文件请使用langchain_community.document_loaders.csv_loader加载
# 加载文档做处理文档的准备工作
loader = UnstructuredFileLoader("test.txt")
# 调用load发开始进行预处理的过程
data = loader.load()
langchain.text_splitter.RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter将使用UnstructuredFileLoader加载之后的样本进行切分,利于对长文本的精细化处理。
其中的两个主要参数chunk_size和chunk_overlap的作用如下
chunk_size:切割的最长长度,该长度的单位是字符不是token长度
chunk_overlap:切割的重叠长度
以上两个参数均没有默认值需要手动设置
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
2.读取本地Embedding模型
考虑到使用在线OpenAI 的Embedding模型消耗的Token过高,决定使用HuggingFaceEmbeddings加载离线的Embedding模型,代码如下。
from langchain_community.embeddings import HuggingFaceEmbeddingsmodel_name = r"bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
hf = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
其中model_name指代的不是模型名称,是包含训练好的模型在内的配置文件夹名称,在配置文件夹下面包含各类配置文件,且目前需要使用官方支持的模型,如果官方的不支持该模型,虽然在指定路径下存在着模型文件pytorch_model.bin,会出现以下警告信息,虽然程序没有报错,但是其没有成功加载模型,会提示找不到模型文件然后用平均策略创造了一个新的模型。还有可能出现找不到配置文件等错误,后续评估不同Embedding模型的效果。
No sentence-transformers model found with name ernie-3.0-xbase-zh. Creating a new one with MEAN pooling.
在可用其中使用最多的是bce-embedding-vase_v1模型,其是有道公司发布的一个embedding模型,基于pytorch框架编写,支持对中文和英文生成嵌入向量,链接网址如下,下载文件内容需要注册HuggingFace账号。
网址https://huggingface.co/maidalun1020
3. 保存向量数据库
使用langchain_community.vectorstores.Chroma保存知识向量库,其保存的完整代码如下,关键行解释在后。
官方文档地址:https://api.python.langchain.com/en/latest/vectorstores/langchain_community.vectorstores.chroma.Chroma.html#
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
import sentence_transformers
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# 导入文本
loader = UnstructuredFileLoader("test.txt")
data = loader.load()# 文本切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
split_docs = text_splitter.split_documents(data)model_name = r"bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)#保存向量数据库部分# 初始化数据库
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/news_test")
# 持久化
db.persist()
# 对数据进行加载
db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)- 初始化数据库
使用Chroma.from_documents来初始化也就生成一个词向量数据库,他对原始文档中的数据进行处理并通过模型映射成向量 ,其中split_docs为切分之后的文本,embeddings为初始化之后的模型
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/news_test")
- 持久化
在实例化了一个用于初始化向量数据库的类之后,需要调用persist函数对其进行保存,之后再使用的时候加载之前初始化得到的向量数据库即可,不需要重新初始化,也就是通过模型生成向量数据库。
db.persist()
- 对数据进行加载
persist_directory该变量为初始化数据库中指定的路径,embedding_function表示使用的embedding模型,如果不对已经生成的向量数据库添加新的文档则不需要指定。
db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)
4.检索数据库中的相似样本
在使用大语言模型对数据库中的内容进行总结归纳之前,需要去搜被切分的文本中哪些文本于问题相似,然后将搜索到的相似的样本和问题发给大模型大模型在根据相似样本和问题得到总结。在代码中使用到的是similarity_search其作用是需要对搜索到的相似文本进行输出的时候采用。
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_community.llms import Tongyimodel_name = r"bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)
question = "浩浩的科研笔记的原力等级"
# 寻找四个相似的样本
similarDocs = db.similarity_search(question,k=4)
print(similarDocs)
5.使用通义千问总结归纳
在使用LangChain的过程中,使用langchain.chains.RetrievalQA对从向量数据库中检索出来的类似样本进行总结归纳。自建的知识库文本如下:
CSDN中浩浩的科研笔记博客的作者是陈浩,博客的地址为 www.chen-hao.blog.csdn.net。
其原力等级为5级,在其学习评价中,其技术能力超过了99.6%的同码龄作者,且超过了97.9%的研究生用户。
该博客中包含了,单片机,深度学习,数学建模,优化方法等,相关的博客信息,其中访问量最多的博客是《Arduino 让小车走实现的秘密 增量式PID 直流减速编码电机》。
其个人能力主要分布在Python,和Pytorch方面,其中python相对最为擅长,希望可以早日成为博客专家。
提问问题:
浩浩的科研笔记的原力等级是多少?
代码实现:
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.llms import Tongyimodel_name = r"bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=Tongyi(), retriever=retriever)query = "浩浩的科研笔记的原力等级是多少?"
print(qa.run(query))
retriever = db.as_retriever()创建一个检索器,其作用是在数据库中于问题相似的样本片段,默认搜索的样本为4,其和配置详细参数参考官方文档.
文档地址为:
https://api.python.langchain.com/en/latest/vectorstores/langchain_community.vectorstores.chroma.Chroma.html#langchain_community.vectorstores.chroma.Chroma.as_retriever
6.额外补充 LangChain 使用通义模型进行流式输出
当前阶段,使用LangChain对通义千问的支持性仍然不高,官方文档的所有例程都是OpenAI模型,所以想使用同义前文API进行多轮对话,或者流式输出等都有各种各样的BUG,其中我找到了使用流式输出的解决办法,但是依旧需要对按照好的库文件进行更改。
这里是将官方的流式输出代码,换成Tongyi模型,官方代码里使用的模型是OpenAI,
from langchain.prompts import ChatPromptTemplate
from langchain_community.llms import Tongyillm = Tongyi(streaming=True, max_tokens=2048)prompt = ChatPromptTemplate.from_messages([("system", "你是一个专业的AI助手。"), ("human", "{query}")]
)
llm_chain = prompt | llmret = llm_chain.stream({"query": "你是谁?"})
for token in ret:print(token, end="", flush=True)
print()
在使用LangChain中的Tongyi模型进行流式输出时,按照官方的代码直接运行会报一个类型错误:
TypeError: Additional kwargs key output_tokens already exists in left dict and value has unsupported type <class 'int'>.
其指向的错误文件路径如下
C:\Users\Chenhao\AppData\Local\Programs\Python\Python39\lib\site-packages\langchain_core\utils\_merge.py
点开文件里面内容如下,其主要作用合并两个字典,然后处理字典中键值冲突的问题,之后将该BUG在stakflow上提问,得到了回复,根据测试直接让merge_dicts返回该字典即{'input_tokens': 530, 'output_tokens': 2, 'total_tokens': 532},该BUG目前还没有修复。
from __future__ import annotationsfrom typing import Any, Dictdef merge_dicts(left: Dict[str, Any], right: Dict[str, Any]) -> Dict[str, Any]:"""Merge two dicts, handling specific scenarios where a key exists in bothdictionaries but has a value of None in 'left'. In such cases, the method uses thevalue from 'right' for that key in the merged dictionary.Example:If left = {"function_call": {"arguments": None}} andright = {"function_call": {"arguments": "{\n"}}then, after merging, for the key "function_call",the value from 'right' is used,resulting in merged = {"function_call": {"arguments": "{\n"}}."""merged = left.copy()for k, v in right.items():if k not in merged:merged[k] = velif merged[k] is None and v:merged[k] = velif v is None:continueelif merged[k] == v:continueelif type(merged[k]) != type(v):raise TypeError(f'additional_kwargs["{k}"] already exists in this message,'" but with a different type.")elif isinstance(merged[k], str):merged[k] += velif isinstance(merged[k], dict):merged[k] = merge_dicts(merged[k], v)elif isinstance(merged[k], list):merged[k] = merged[k] + velse:raise TypeError(f"Additional kwargs key {k} already exists in left dict and value has "f"unsupported type {type(merged[k])}.")return merged 修改之后的文件如下,由于修改的是库文件中的代码,所以会有确认提示,在修改了之后在运行上流式输出的代码即可,前提是已经申请成果,且配置好了相关的API-KEY
from __future__ import annotationsfrom typing import Any, Dictdef merge_dicts(left: Dict[str, Any], right: Dict[str, Any]) -> Dict[str, Any]:merged = {'input_tokens': 530, 'output_tokens': 2, 'total_tokens': 532}return merged
7.目前发现的LangChain使用问题总结
-
LangChain对通义千问API的支持较弱,难以使用LangChain实现多轮对话,和流式输出,所有的官网文档例程都是基于OpenAI
-
LangChain在读取文件的时候时候不能保存特殊符号例如
-在被加载近文本读取器的时候被识别为非法字符转换为\n -
LangChain使用Hungingface查找相同样本的时候,使用的模型似乎需要官方的认可才可以,且并不容易找到对应的支持模型的名单,也就是需要自己尝试
-
LangChain只能读取CSV还有txt,其他的需要先转成这两个格式,无法直接输入World然后读取其内容和图片。
相关文章:
LangChain结合通义千问的自建知识库
LangChain结合通义千问的自建知识库 在使用了通义千问API了之后,下一步就是构建知识库文档,使用了比较有名的LangChian,最后成果将自己的txt生成了知识向量库,最后我还把自己的论文生成了一个知识向量库,然后问他我的…...
【证书管理】实验报告
证书管理实验 【实验环境】 ISES客户端 【实验步骤】 查看证书 查看证书详细信息 选择任意证书状态,在下方“证书列表”中出现符合要求的所有证书。在“证书列表”中点击要查看证书,在右侧“证书详细信息”栏出现被选证书信息。 上述操作如图1.2.…...

App Store外区账号分享
App Store外区账号分享及注意事项 外区苹果ID分享指南什么是外区苹果ID?为什么需要外区苹果ID?获取方法分享外区苹果ID的注意事项方式2获取步骤 外区苹果ID分享指南 在数字时代,我们的生活与各种应用和服务紧密相连。 对于苹果用户而言&#…...

判断字符串是否包含正则表达式默认的特殊字符c++
判断字符串是否包含正则表达式默认的特殊字符 业务描述: 上层配置的字符列表中,既有准确的字符串,又有可以进行正则匹配的字符串,这时候需要区分出来那些是正则匹配的字符串。 思路: 判断字符串中,是否存在正则表达…...
【蓝桥杯选拔赛真题64】python数字塔 第十五届青少年组蓝桥杯python 选拔赛比赛真题解析
python数字塔 第十五届蓝桥杯青少年组python比赛选拔赛真题 一、题目要求 (注:input()输入函数的括号中不允许添加任何信息) 提示信息: 数字塔是由 N 行数堆积而成,最顶层只有一个数,次顶层两个数,以此类推。相邻层之间的数用线连接,下一层的每个数与它上一层左上…...

javaEE - 23( 21000 字 Servlet 入门 -1 )
一:Servlet 1.1 Servlet 是什么 Servlet 是一种实现动态页面的技术. 是一组 Tomcat 提供给程序猿的 API, 帮助程序猿简单高效的开发一个 web app. 构建动态页面的技术有很多, 每种语言都有一些相关的库/框架来做这件事,Servlet 就是 Tomcat 这个 HTTP…...

【sentinel流量卫兵搭建与微服务整合】
sentinel流量卫兵搭建与微服务整合 搭建sentinel dashboard控制台微服务整合搭建sentinel dashboard控制台 1、下载 官网链接 由于官网github网络原因,导致长时间下载失败。 网盘链接 网盘提取码:dwgj 2、运行 将下载jar包放在任意非中文、不包含特殊字符的目录下,重名为…...

Linux环境下配置mysql主从复制
主从配置需要注意的地方 1、主DB server和从DB server数据库的版本一致 2、主DB server和从DB server数据库数据一致[这里就会可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录] 3、主DB server开启二进制日志,主DB server和从DB serve…...

生物素-PEG4-酪胺,Biotin-PEG4-TSA,应用于酶联免疫吸附实验
您好,欢迎来到新研之家 文章关键词:生物素-PEG4-酪胺,Biotin-PEG4-Tyramide,Biotin-PEG4-TSA 一、基本信息 产品简介:Biotin PEG4 Tyramine is a reagent used for tyramine signal amplification (TSA) through ca…...

Android:文件读写
3.10 Android读写文件 1、读写文件 Android读写文件操作,不能写入到系统根目录,只能在应用包下文件夹进行读写。 使用getCacheDir()方法,获取当前应用的Cache目录路径; 使用getFilesDir()方法,获取当前应用的files目录路径; 示例: //读取数据public void readData(){…...

2024/2/5
第四章 堆与拷贝构造函数 一 、程序阅读题 1、给出下面程序输出结果。 #include <iostream.h> class example {int a; public: example(int b5){ab;} void print(){aa1;cout <<a<<"";} void print()const {cout<<a<<endl;} …...
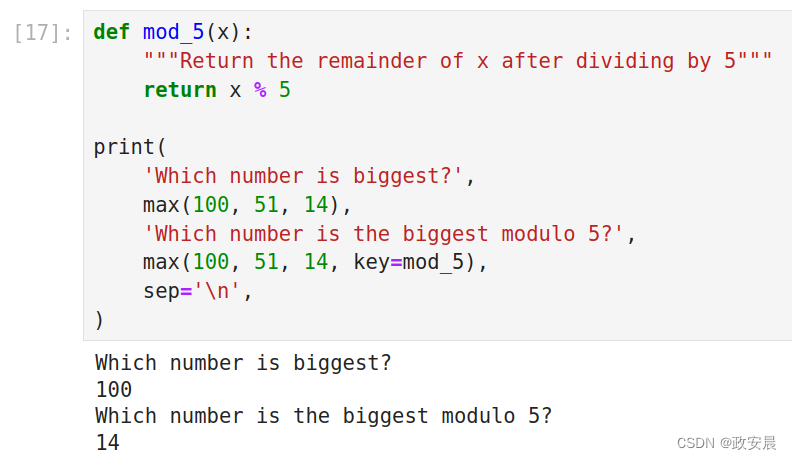
政安晨:示例演绎Python的函数与获取帮助的方法
调用函数和定义我们自己的函数,并使用Python内置的文档,是成为一位Pythoner的开始。 通过我的上篇文章,相信您已经看过并使用了print和abs等函数。但是Python还有许多其他函数,并且定义自己的函数是Python编程的重要部分。 在本…...

88 docker 环境下面 前端A连到后端B + 前端B连到后端A
前言 呵呵 最近出现了这样的一个问题, 我们有多个前端服务, 分别连接了对应的后端服务, 前端A -> 后端A, 前端B -> 后端B 但是 最近的时候 却会出现一种情况就是, 有些时候 前端A 连接到了 后端B, 前端B 连接到了 后端A 我们 前端服务使用 nginx 提供前端 html, js…...

k8s学习-Service Account和RBAC授权
1.1 ServiceAccount 介绍 首先Kubernetes中账户区分为:User Accounts(用户账户) 和 Service Accounts(服务账户) 两种,它们的设计及用途如下: UserAccount是给kubernetes集群外部用户使用的&am…...

SpringMVC-响应数据
一、引子 我们在上一篇文章SpringMVC-组件解析里介绍了SpringMVC框架执行一个请求的过程,并演示了快速使用Controller承接请求。本篇我们将深入介绍SpringMVC执行请求时,如何响应客户端。 二、响应类型 SpringMVC的数据响应方式主要分为两类ÿ…...
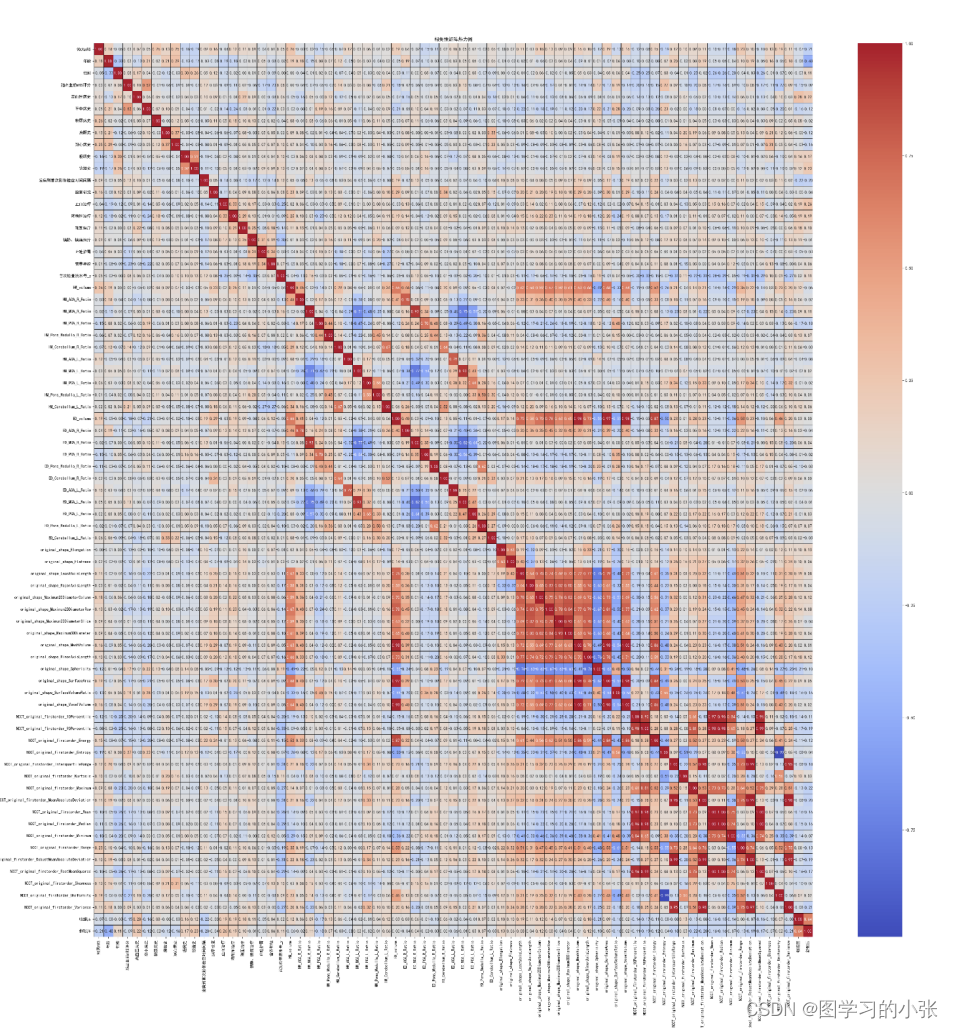
数学建模:数据相关性分析(Pearson和 Spearman相关系数)含python实现
相关性分析是一种用于衡量两个或多个变量之间关系密切程度的方法。相关性分析通常用于探索变量之间的关系,以及预测一个变量如何随着另一个变量的变化而变化。在数学建模中,这是常用的数据分析手段。 相关性分析的结果通常用相关系数来表示ÿ…...
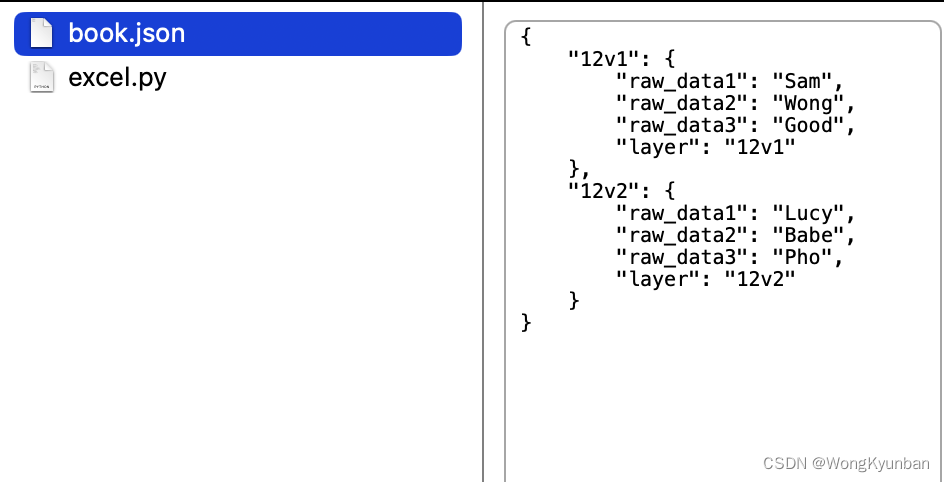
使用pandas将excel转成json格式
1.Excel数据 2.我们想要的JSON格式 {"0": {"raw_data1": "Sam","raw_data2": "Wong","raw_data3": "Good","layer": "12v1"},"1": {"raw_data1": "Lucy…...
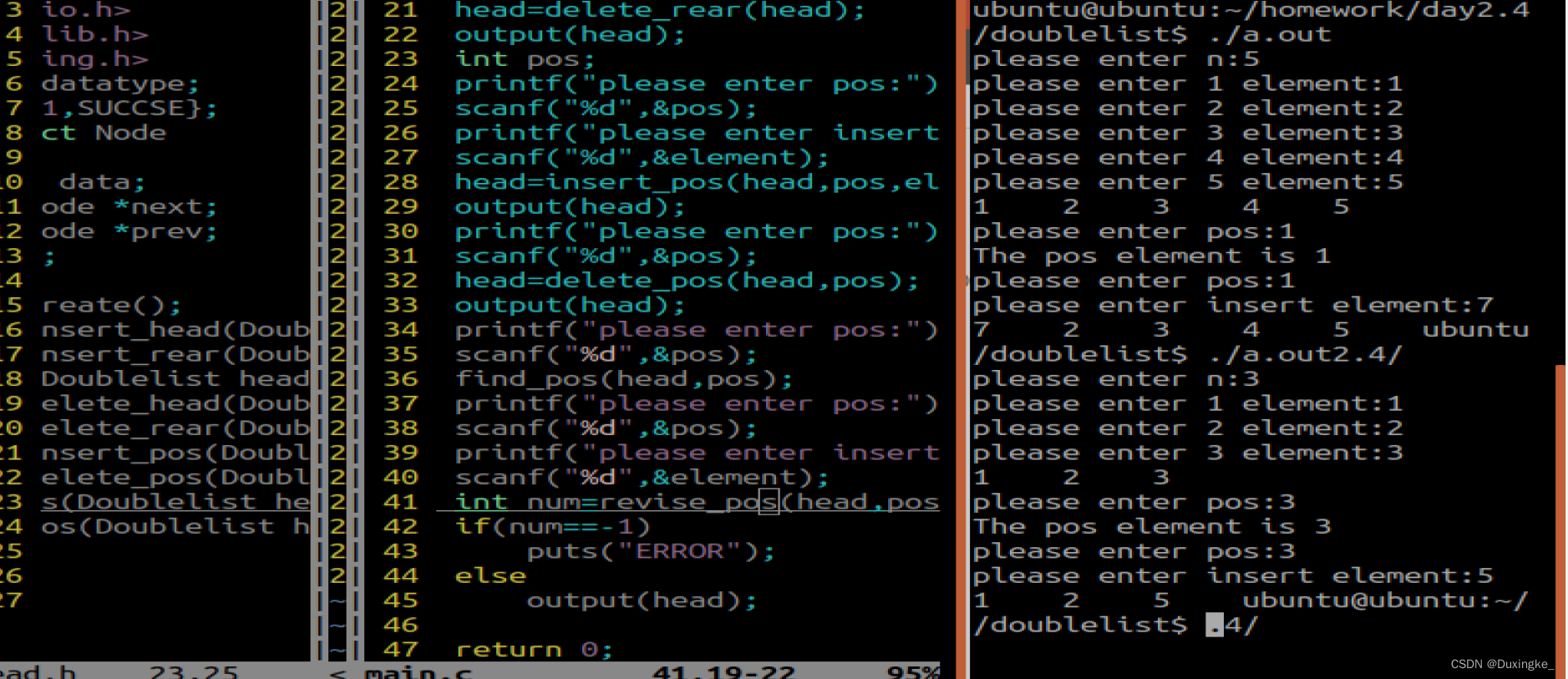
双向链表的插入、删除、按位置增删改查、栈和队列区别、什么是内存泄漏
2024年2月4日 1.请编程实现双向链表的头插,头删、尾插、尾删 头文件: #ifndef __HEAD_H__ #define __HEAD_H__ #include<stdio.h> #include<stdlib.h> #include<string.h> typedef int datatype; enum{FALSE-1,SUCCSE}; typedef str…...

Linux 驱动开发基础知识——总线设备驱动模型(七)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...
---03信号(软件中断)源码分析)
RTthread线程间通信(邮箱,消息队列,信号/软件中断)---03信号(软件中断)源码分析
信号 实际使用看这一个 #if defined(RT_USING_SIGNALS)rt_sigset_t sig_pending; /**< the pending signals 记录来了的信号 */rt_sigset_t sig_mask; /**< the mask bits of signal 记录屏蔽的信号 */rt_sigh…...
)
Python安全开发之简易Xss检测工具(详细注释)
核心代码:import requests # requests 库 - HTTP 请求处理库 # 【常用功能】: # requests.get(url) - 发送 HTTP GET 请求 # requests.post(url, data) - 发送 HTTP POST 请求 # response.text - 获取响应体内容(字符串) #…...

深入浅出Livepatch:从kprobe到ftrace的Linux热补丁实现原理
深入浅出Livepatch:从kprobe到ftrace的Linux热补丁实现原理 当你的生产环境服务器正在处理每秒数万次请求时,突然发现一个关键内核漏洞需要立即修复,传统方式要求重启系统——这无异于在高速公路上急刹车。Livepatch技术应运而生,…...

基于OpenCV的边缘梯度模板匹配:代码与分析
基于Opencv边缘梯度模板匹配源码,今天,我决定深入研究一下基于OpenCV的边缘梯度模板匹配算法。说实话,这个算法听起来有点高大上,但我觉得只要一步步来,一定能搞明白。 什么是边缘梯度模板匹配? 边缘梯度模…...
)
别再手动整理了!用Python脚本5分钟搞定ImageNet验证集标签映射(附完整代码)
5分钟极速搞定ImageNet验证集标签映射:Python自动化实战指南 每次处理ImageNet验证集时,你是否也对着那些晦涩的数字标签头疼不已?手动查表不仅效率低下,还容易出错。今天我们就来彻底解决这个痛点——用Python脚本自动完成标签映…...

私域数据安全与合规——企微引流必须注意的5个技术红线
做公域引流到企微,数据安全和合规是技术团队必须重视的问题。一旦踩红线,轻则功能受限,重则企微封禁甚至法律风险。今天梳理5个技术红线及应对方案。红线1:用户隐私数据存储企微API返回的用户信息包含ExternalUserID(外…...

嵌入式Linux接入阿里飞燕物联网平台实战指南
1. 嵌入式Linux设备接入飞燕物联网平台全流程解析作为一名在嵌入式领域摸爬滚打多年的工程师,最近刚完成了一个将智能家居设备从旧平台迁移到阿里飞燕物联网平台的项目。这个过程中踩了不少坑,也积累了一些实战经验,今天就来详细分享一下基于…...
)
React项目实战:用XGPlayer打造带封面预览的沉浸式视频播放组件(附完整代码)
React项目实战:用XGPlayer打造带封面预览的沉浸式视频播放组件(附完整代码) 在当今内容为王的时代,视频已成为Web应用中不可或缺的元素。但如何让视频组件既美观又高效,同时提供流畅的用户体验?本文将带你深…...
完整解析)
埃拉托斯特尼筛法(埃氏筛)完整解析
一、算法用途 快速找出 2 ~ n 之间的所有素数。 暴力判断每个数:O(nn) 埃氏筛:O(nloglogn),接近线性,极快。 二、核心思想 先假设所有数都是素数。 从最小素数 2 开始,把它的所有倍数标记为合数。 取下一个没被标记的数(一定是素数),继续标记它的倍数。 最后没被标记…...

ROS2编译报错CMake未找到diagnostic_updater:从诊断工具缺失到精准安装
1. 当CMake告诉你找不到diagnostic_updater时发生了什么 第一次看到这个报错的时候,我也是一头雾水。明明代码是从GitHub上clone下来的标准功能包,怎么一编译就报错呢?那个红色的"CMake Error"特别扎眼,就像开车时突然亮…...

Qwen-Image-Edit-F2P在Vue前端项目中的可视化应用
Qwen-Image-Edit-F2P在Vue前端项目中的可视化应用 1. 引言 想象一下这样的场景:用户上传一张简单的人脸照片,几秒钟后就能看到自己穿着优雅礼服站在巴黎街头,或是化身古风侠客执剑而立。这种曾经只存在于科幻电影中的体验,现在通…...