爬虫实战--人民网
文章目录
- 前言
- 发现宝藏
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
http://jhsjk.people.cn/testnew/result
import os
import re
from datetime import datetime
import requests
import json
from bs4 import BeautifulSoup
from pymongo import MongoClient
from tqdm import tqdmclass ArticleCrawler:def __init__(self, catalogues_url, card_root_url, output_dir, db_name='ren-ming-wang'):self.catalogues_url = catalogues_urlself.card_root_url = card_root_urlself.output_dir = output_dirself.client = MongoClient('mongodb://localhost:27017/')self.db = self.client[db_name]self.catalogues = self.db['catalogues']self.cards = self.db['cards']self.headers = {'Referer': 'https://jhsjk.people.cn/result?','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/119.0.0.0 Safari/537.36','Cookie': '替换成你自己的',}# 发送带参数的get请求并获取页面内容def fetch_page(self, url, page):params = {'keywords': '','isFuzzy': '0','searchArea': '0','year': '0','form': '','type': '0','page': page,'origin': '全部','source': '2',}response = requests.get(url, params=params, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')return soup# 解析请求版面def parse_catalogues(self, json_catalogues):card_list = json_catalogues['list']for list in card_list:a_tag = 'article/'+list['article_id']card_url = self.card_root_url + a_tagcard_title = list['title']updateTime = list['input_date']self.parse_cards(card_url, updateTime)date = datetime.now()catalogues_id = list['article_id']+'01'# 检查重复标题existing_docs = self.catalogues.find_one({'id': catalogues_id})if existing_docs is not None:print(f'版面id: {catalogues_id}【已经存在】')continuecard_data = {'id': catalogues_id,'title': card_title,'page': 1,'serial': 1,# 一个版面一个文章'dailyId': '','cardSize': 1,'subjectCode': '50','updateTime': updateTime,'institutionnCode': '10000','date': date,'snapshot': {}}self.catalogues.insert_one(card_data)print(f'版面id: {catalogues_id}【插入成功】')# 解析请求文章def parse_cards(self, url, updateTime):response = requests.get(url, headers=self.headers)soup = BeautifulSoup(response.text, "html.parser")try:title = soup.find("div", "d2txt clearfix").find('h1').textexcept:try:title = soup.find('h1').textexcept:print(f'【无法解析该文章标题】{url}')html_content = soup.find('div', 'd2txt_con clearfix')text = html_content.get_text()imgs = [img.get('src') or img.get('data-src') for img in html_content.find_all('img')]cleaned_content = self.clean_content(text)# 假设我们有一个正则表达式匹配对象matchmatch = re.search(r'\d+', url)# 获取匹配的字符串card_id = match.group()date = datetime.now()if len(imgs) != 0:# 下载图片self.download_images(imgs, card_id)# 创建文档document = {'id': card_id,'serial': 1,'page': 1,'url' : url,'type': 'ren-ming-wang','catalogueId': card_id + '01','subjectCode': '50','institutionCode': '10000','updateTime': updateTime,'flag': 'true','date': date,'title': title,'illustrations': imgs,'html_content': str(html_content),'content': cleaned_content}# 检查重复标题existing_docs = self.cards.find_one({'id': card_id})if existing_docs is None:# 插入文档self.cards.insert_one(document)print(f"文章id:{card_id}【插入成功】")else:print(f"文章id:{card_id}【已经存在】")# 文章数据清洗def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)# content = re.sub(r'\n', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return content# 下载图片def download_images(self, img_urls, card_id):# 根据card_id创建一个新的子目录images_dir = os.path.join(self.output_dir, card_id)if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for img_url in img_urls:try:response = requests.get(img_url, stream=True)if response.status_code == 200:# 从URL中提取图片文件名image_name = os.path.join(images_dir, img_url.split('/')[-1])# 确保文件名不重复if os.path.exists(image_name):continuewith open(image_name, 'wb') as f:f.write(response.content)downloaded_images.append(image_name)print(f"Image downloaded: {img_url}")except Exception as e:print(f"Failed to download image {img_url}. Error: {e}")return downloaded_images# 如果文件夹存在则跳过else:print(f'文章id为{card_id}的图片文件夹已经存在')# 查找共有多少页def find_page_all(self, soup):# 查找<em>标签em_tag = soup.find('em', onclick=True)# 从onclick属性中提取页码if em_tag and 'onclick' in em_tag.attrs:onclick_value = em_tag['onclick']page_number = int(onclick_value.split('(')[1].split(')')[0])return page_numberelse:print('找不到总共有多少页数据')# 关闭与MongoDB的连接def close_connection(self):self.client.close()# 执行爬虫,循环获取多页版面及文章并存储def run(self):soup_catalogue = self.fetch_page(self.catalogues_url, 1)page_all = self.find_page_all(soup_catalogue)if page_all:for index in tqdm(range(1, page_all), desc='Page'):# for index in tqdm(range(1, 50), desc='Page'):soup_catalogues = self.fetch_page(self.catalogues_url, index).text# 解析JSON数据soup_catalogues_json = json.loads(soup_catalogues)self.parse_catalogues(soup_catalogues_json)print(f'======================================Finished page {index}======================================')self.close_connection()if __name__ == "__main__":crawler = ArticleCrawler(catalogues_url='http://jhsjk.people.cn/testnew/result',card_root_url='http://jhsjk.people.cn/',output_dir='D:\\ren-ming-wang\\img')crawler.run() # 运行爬虫,搜索所有内容crawler.close_connection() # 关闭数据库连接

相关文章:
爬虫实战--人民网
文章目录 前言发现宝藏 前言 为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们…...

【Arduino】LGT8F328 UNO R3编译上传
LGT8F328 UNO R3编译上传 示例代码 这是一段示例代码,将示例代码编译打包上传到LGT8F328 UNO R3开发板。 #include <Servo.h> Servo myservo; int pos 0; void setup() {// put your setup code here, to run once:Serial.begin(9600);Serial.println(&qu…...
Python进阶----在线翻译器(Python3的百度翻译爬虫)
目录 一、此处需要安装第三方库requests: 二、抓包分析及编写Python代码 1、打开百度翻译的官网进行抓包分析。 2、编写请求模块 3、输出我们想要的消息 三、所有代码如下: 一、此处需要安装第三方库requests: 在Pycharm平台终端或者命令提示符窗口中输入以下代…...
ArcGISPro中Python相关命令总结
主要总结conda方面的相关命令 列出当前活动环境中的包 conda list 列出所有 conda 环境 conda env list 克隆环境 克隆以默认的 arcgispro-py3 环境为模版的 my_env 新环境。 conda create --clone arcgispro-py3 --name my_env --pinned 激活环境 activate my_env p…...

2024年混合云:趋势和预测
混合云环境对于 DevOps 团队变得越来越重要,主要是因为它们能够弥合公共云资源的快速部署与私有云基础设施的安全和控制之间的差距。这种环境的混合为 DevOps 团队提供了灵活性和可扩展性,这对于大型企业中的持续集成和持续部署 (CI/CD) 至关重要。 在混…...
c++入门学习④——对象的初始化和清理
目录 对象的初始化和清理: why? 如何进行初始化和清理呢? 使用构造函数和析构函数编辑 构造函数语法: 析构函数语法: 构造函数的分类: 两种分类方式: 三种调用方法: 括号法(默认构造函数调用&…...

Java-spring注解的作用
1.Qualifier:通常与Autowired搭配使用,通过指定具体的beanName来注入相应的bean 当容器中有多个类型相同的Bean时,可以使用Qualifier注解来指定需要注入的Bean。Qualifier注解可以用于字段、方法参数、构造函数参数等位置 Service public cl…...
Allegro如何把Symbols,shapes,vias,Clines,Cline segs等多种元素一起移动
Allegro如何把Symbols,shapes,vias,Clines,Cline segs等多种元素一起移动 在用Allegro进行PCB设计时,有时候需要同时移动某个区域的所有元素,如:Symbols,shapes,vias,Clines,Cline segs等元素。那么如何操作呢? 首先就是把Symbols,shapes,vias,Clines,Cline …...

【力扣】罗马数字转整数,哈希集合+模拟
罗马数字转整数原题地址 方法一:模拟 罗马数字是字符串,其中每个字符都对应一个整数值,为了方便查找,可以预先把这种对应关系存储到哈希表中。 遍历字符串,对于每个字符, 如果该字符不是最右边的字符&a…...

从长网址到短链接:探索网址缩短的神奇世界
欢迎来到我的博客,代码的世界里,每一行都是一个故事 从长网址到短链接:探索网址缩短的神奇世界 前言网址缩短的原理和历史网址缩短的应用场景网址缩短的安全风险网址缩短的未来趋势 前言 你是否曾经在浏览网页或社交媒体时遇到过一串看起来像…...
Micro micro controller一览
https://www.microchip.com.cn/, Microchip中文网站 https://www.microchip.com.cn/newcommunity/index.php?mSearch&adosearch&moduleDownload&keyworddsPIC33&p3 Microcontrollers and microProcessors dsPIC33 Digital Signal Controllers (D…...
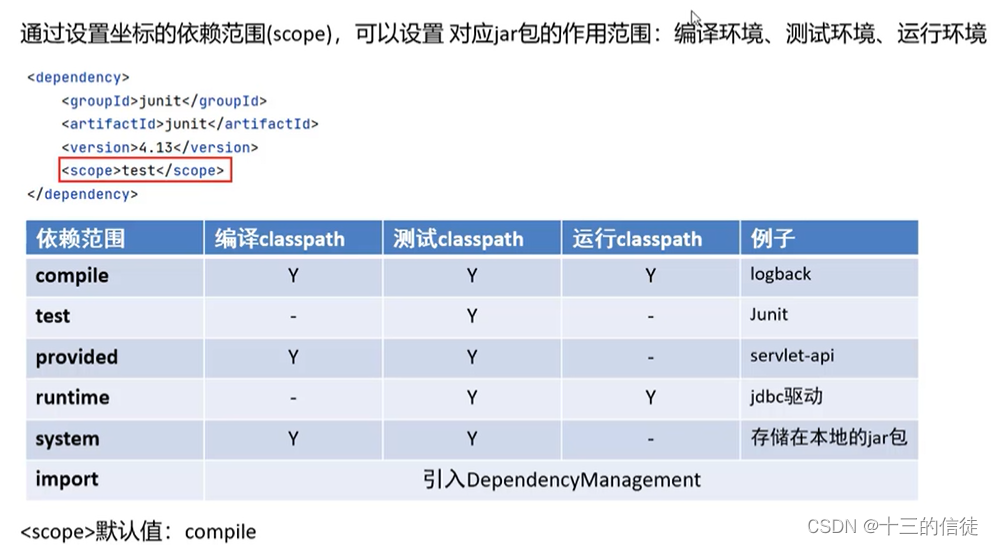
一文简介Maven初级使用
一.概述 Maven是专门用于管理和构建Java项目的工具,它的主要功能有: 提供了一套标准化的项目结构提供了一套标准化的项目构建流程(编译,测试,打包,发布)提供了一套依赖管理机制 一方面&…...
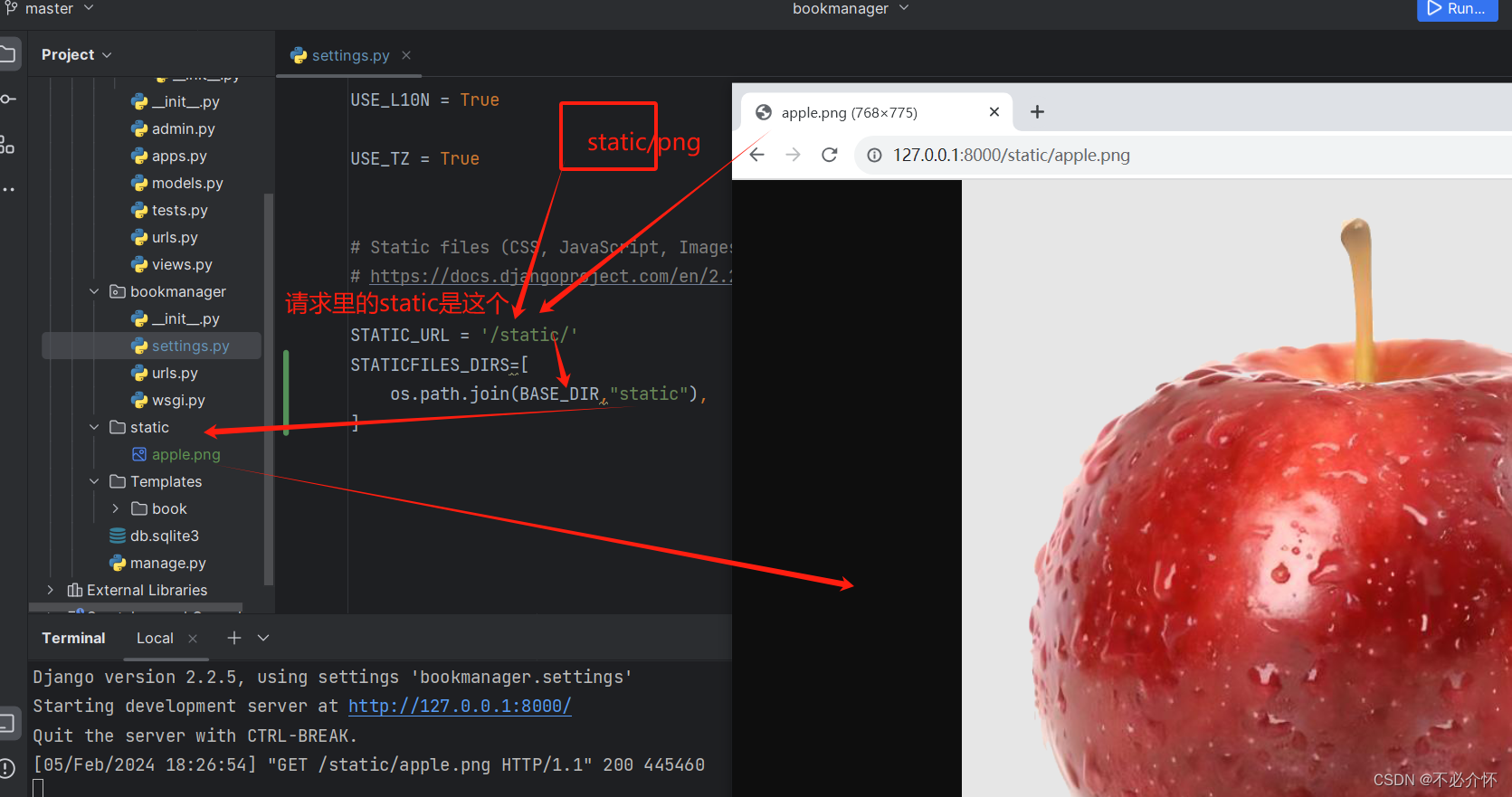
Django的配置文件setting.py
BASE_DIR 项目路径:默认是已经打开的主项目路径 BASE_DIR os.path.dirname(os.path.dirname(os.path.abspath(__file__))) SECRET_KEY 密钥 SECRET_KEY (dh&_fm2hfn9y)35!_6#$a7q%%^onoy#-a8x18r4(6*8f(aniDEBUG 帮助调试,默认…...
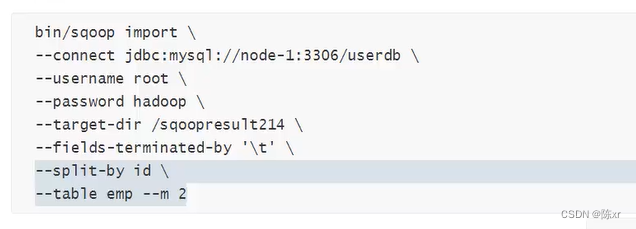
2024-02-06(Sqoop)
1.Sqoop Apache Sqoop是Hadoop生态体系和RDBMS(关系型数据库)体系之间传递数据的一种工具。 Sqoop工作机制是将导入或者导出命令翻译成MapReduce程序来实现。在翻译出的MapReduce中主要是对inputformat和outputformat进行定制。 Hadoop生态包括&#…...

C++ 11新特性之tuple
概述 在C编程语言的发展历程中,C 11标准引入了许多开创性的新特性,极大地提升了开发效率与代码质量。其中,tuple(元组)作为一种强大的容器类型,为处理多个不同类型的值提供了便捷的手段。tuple是一种固定大…...

Spring Boot项目整合Seata AT模式
目录 1、添加依赖2.、配置Seata3、创建AT模式表4、使用Seata分布式事务 1、添加依赖 <dependency><groupId>io.seata</groupId><artifactId>seata-spring-boot-starter</artifactId></dependency>上述依赖适用于springboot项目 如果你的项…...

作业2.5
第四章 堆与拷贝构造函数 一 、程序阅读题 1、给出下面程序输出结果。 #include <iostream.h> class example {int a; public: example(int b5){ab;} void print(){aa1;cout <<a<<"";} void print()const {cout<<a<<endl;} …...
LeetCode、790. 多米诺和托米诺平铺【中等,二维DP,可转一维】
文章目录 前言LeetCode、790. 多米诺和托米诺平铺【中等,二维DP,可转一维】题目与分类思路二维解法二维转一维 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质…...

Python 的 sys 模块常用方法
sys.argv: 命令行参数 List,第一个元素是程序本身路径 sys.modules.keys(): 返回所有已经导入的模块列表 sys.exc_info() :获取当前正在处理的异常类 exc_type、exc_value、exc_traceback 当前处理的异常详细信息 sys.exit(n)&…...
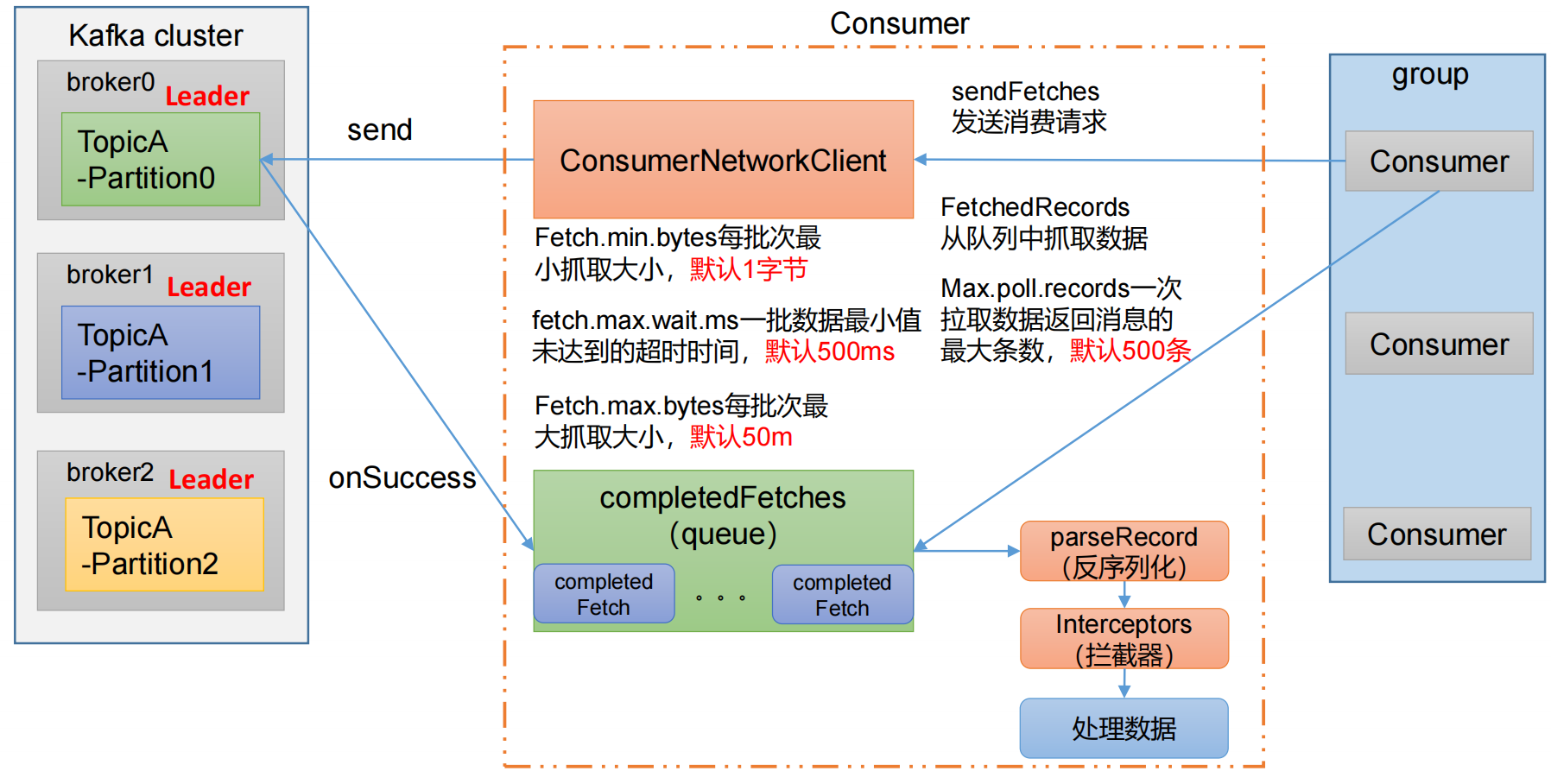
Kafka 使用手册
kafka3.0 文章目录 kafka3.01. 什么是kafka?2. kafka基础架构3. kafka集群搭建4. kafka命令行操作主题命令行【topic】生产者命令行【producer】消费者命令行【consumer】 5. kafka生产者生产者消息发送流程Producer 发送原理普通的异步发送带回调函数的异步发送同步…...
)
YOLOv8特征可视化实战:如何用一行代码查看模型内部特征图(附完整代码)
YOLOv8特征可视化实战:如何用一行代码查看模型内部特征图(附完整代码) 在计算机视觉领域,YOLO系列模型因其卓越的实时检测性能而广受欢迎。但对于开发者而言,仅仅使用模型进行预测往往不够——理解模型内部如何"思…...

ESP32-S3 开发实战:从问题排查到功能优化
1. ESP32-S3开发环境搭建与常见问题 刚拿到ESP32-S3开发板时,我最先遇到的就是环境配置问题。这里分享几个新手容易踩的坑:首先是开发工具链的选择,官方推荐使用ESP-IDF或Arduino IDE。我建议初学者先用Arduino IDE上手,因为它的库…...

成电计算机复试面试:如何用一份‘心机’简历引导老师提问,并提前准备好答案?
计算机复试策略:如何用结构化简历设计引导面试走向 站在电子科技大学计算机复试的考场外,大多数考生都在反复背诵技术概念和项目细节,却很少有人意识到——面试本质上是一场精心设计的对话博弈。那些最终获得高分的考生,往往不是知…...
)
手把手教你用TI F28P65X开发板实现LED定时闪烁(基于CPU Timer2,含完整源码)
从零玩转TI F28P65X开发板:CPU Timer2实现可调频LED闪烁实战指南 刚拿到TI F28P65X开发板时,面对密密麻麻的引脚和复杂的开发环境,很多嵌入式新手会感到无从下手。本文将带你用最直观的方式,通过控制LED闪烁这个经典入门项目&…...

GTX1650也能跑!Windows11上OLLAMA+AnythingLLM本地部署Llama3保姆级教程
GTX1650也能跑!Windows11上OLLAMAAnythingLLM本地部署Llama3保姆级教程 老旧硬件也能玩转大模型?当GTX1650这样的入门级显卡遇上Llama3这类前沿AI模型,很多人第一反应可能是"跑不动"。但经过实测,只要合理配置和优化&am…...

网站SEO优化与网站内容更新的关系_企业网站SEO优化与行业特点的关系
<h3 id"seo_seo">网站SEO优化与网站内容更新的关系_企业网站SEO优化与行业特点的关系</h3> <p>在当今数字化时代,网站的SEO优化与内容更新之间有着密切的关系。这不仅关系到企业网站的流量,还直接影响企业的品牌形象和市场竞…...

深入解析cufftPlanMany:从参数配置到高效FFT实现
1. 为什么需要cufftPlanMany? 第一次接触CUDA FFT时,很多人都是从cufftPlan1d、cufftPlan2d这些基础接口开始的。但当你真正处理实际工程问题时,会发现这些简单接口远远不够用。比如要处理批量信号、非连续内存数据、子区域FFT计算等场景时&a…...

YOLO12开源模型合规部署:离线环境+审计日志+模型版本固化方案
YOLO12开源模型合规部署:离线环境审计日志模型版本固化方案 1. 项目背景与核心价值 YOLO12作为Ultralytics在2025年推出的最新实时目标检测模型,在保持高速推理性能的同时显著提升了检测精度。其引入的注意力机制优化了特征提取网络,nano版…...

学术写作“变形记”:书匠策AI如何让课程论文从“青铜”变“王者”——解锁AI时代论文写作新姿势
论文写作,曾是无数学生的“噩梦”:选题撞车、文献堆积如山、逻辑混乱如麻、格式调整让人抓狂……如今,随着人工智能技术的爆发,学术写作的“游戏规则”正在被彻底改写。书匠策AI(官网:www.shujiangce.com&a…...

手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单
手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单 1. 为什么你需要这个AI超分工具? 你是不是也遇到过这些头疼的情况? 翻出十几年前的老照片,想打印出来,却发现画面模糊得像蒙了一层雾。从网上下…...