【文本到上下文 #10】探索地平线:GPT 和 NLP 中大型语言模型的未来
一、说明
欢迎阅读我们【文本到上下文 #10】:此为最后一章。以我们之前对 BERT 和迁移学习的讨论为基础,将重点转移到更广阔的视角,包括语言模型的演变和未来,特别是生成式预训练转换器 (GPT) 及其在 NLP 中的重要作用。
在最后一章中,我们将探讨:
- 语言模型概述:了解它们在NLP中的作用和演变。
- GPT 模型:深入研究 GPT 谱系及其影响。
- 大型语言模型 (LLM):揭示潜力和挑战。
- 现实世界的NLP应用:这些模式如何改变行业。
- NLP的未来趋势:预测前进的道路。
- 道德考量:驾驭 NLP 的道德景观。
二. 语言模型概述
语言模型已成为自然语言处理 (NLP) 领域的基本要素,为从简单的文本预测到复杂的内容生成任务的广泛应用提供了重要基础。这些模型经过精心设计,可以理解、解释和生成人类语言,这是各种人工智能驱动技术进步的核心能力。
在发展的早期阶段,语言模型主要依赖于统计方法。这些方法基于对大型文本语料库的分析,以预测单词序列的可能性。从本质上讲,它们通过确定句子中给定的一系列单词之后的特定单词的概率来操作。这种方法虽然在一定程度上有效,但也有其局限性。它经常在较长的单词序列中挣扎,缺乏上下文理解,并且无法有效地处理语言中的细微差别,例如同音异义词或惯用语。
随着深度学习技术的出现和集成,语言模型的开发方式及其功能发生了重大的范式转变。深度学习是机器学习的一个子集,它采用具有多层的人工神经网络(因此称为“深度”)来模拟数据中的复杂模式。在 NLP 的背景下,这意味着创建能够以更有效和更细致的方式处理和生成语言的模型。
这些高级模型(通常称为神经语言模型)使用各种架构,包括递归神经网络 (RNN)、长短期记忆 (LSTM) 以及更新且高效的 Transformer 模型。特别是 Transformer 架构,一直是该领域的游戏规则改变者,导致了 OpenAI 的 GPT(生成式预训练转换器)系列等模型的开发。与它们的前辈不同,这些模型在理解上下文和生成类似人类的文本方面表现出色,这要归功于它们能够处理与句子中所有其他单词相关的单词,而不是按顺序。
此外,迁移学习等技术的结合——在大量数据集上训练的模型针对特定任务进行微调——使这些高级语言模型能够在各种 NLP 应用程序中实现前所未有的性能。它们不仅能够预测句子中的下一个单词,还能够完成总结文章、翻译语言、回答问题,甚至创建与人类情感和文化细微差别产生共鸣的内容等任务。
因此,这些复杂的语言模型正在迅速改变 NLP 的格局,开创了一个人工智能可以以更自然、更有意义的方式与人类互动、协助和协作的时代。这一演变不仅标志着一项重大的技术成就,也为人工智能和语言处理领域的未来应用和发展开辟了无数的可能性。
三. GPT 模型:革命性的飞跃
OpenAI 引入的生成式预训练转换器 (GPT) 模型极大地改变了自然语言处理 (NLP)。他们善于回答复杂的问题,并制定对简单提示的回应,展示了人工智能理解和模仿人类语言的能力的显着进步
GPT模型的核心功能:
变压器架构:GPT 模型建立在 transformer 架构上,该架构使用自注意力机制。这使他们能够同时处理和理解大型文本块,从而对语言有更细致的理解。
广泛的预培训: 这些模型在庞大的数据集上进行预训练,涵盖广泛的互联网文本。这有助于他们学习不同的语言模式和信息,形成全面的语言基础。
特定于任务的微调:GPT 模型可以针对特定应用程序进行微调,从而提高其在特定任务(如内容创建、对话或翻译)中的性能。这种微调可以根据特定要求定制模型,从而提高其有效性。
上下文理解:得益于 transformer 架构,GPT 模型在理解上下文方面表现出色,使它们能够在扩展的文本序列上生成连贯且相关的响应。
多面性:它们处理多种任务和语言的能力使 GPT 模型在各种应用程序中具有多功能工具,从客户服务自动化到语言研究。
总之,GPT 模型带来了 NLP 的范式转变。他们先进的架构、广泛的培训和微调能力使他们能够以前所未有的复杂程度进行交互和生成语言,为更自然、更直观的人机交互铺平了道路。
四、 大型语言模型(LLM)
像 GPT-3 这样的大型语言模型 (LLM) 是自然语言处理领域的关键参与者。它们的定义特征是巨大的尺寸,GPT-3 拥有数十亿个参数。这种尺寸使他们能够很好地理解和执行各种语言任务。
要点:
大小和技能: LLM 在他们可以处理的数据和理解能力方面很大。他们可以生成类似人类的文本并深入理解各种主题。
知识面广:在不同的数据集上接受训练,LLM对许多主题了解很多。这使得它们在文本生成、回答问题和翻译等任务中用途广泛。
复杂任务:它们擅长高难度的语言任务,而较小的模型很难完成这些任务。
计算需求:然而,它们需要大量的计算能力才能工作,这意味着先进的硬件和大量的能源。
偏置问题:LLM 可能会反映其训练数据的偏差。目前正在开展工作来发现和修复这些偏见,以实现合理使用。
简而言之,像 GPT-3 这样的 LLM 带来了 NLP 的巨大进步,但也带来了资源和确保它们以合乎道德的方式使用的挑战。
五. 现实世界的NLP应用
GPT-3 和高级转换器模型的引入极大地扩展了自然语言处理 (NLP) 的实际应用范围。以下是各行各业的一些关键应用:
医疗保健 — 患者护理和医疗文件:GPT-3 有助于解释以自然语言描述的患者症状并提出可能的诊断或治疗建议。它还通过将医生的语音记录转换为结构化的患者记录来简化医疗文档,从而提高医疗记录保存的效率。
法律行业 — 合同分析和法律研究: NLP 技术,尤其是 GPT-3 之后的技术,已经彻底改变了法律领域。他们协助分析法律文件,从合同中提取关键条款和条款,并通过筛选庞大的法律先例和文献数据库进行全面的法律研究。
财务 — 个性化财务建议和风险评估:在金融领域,GPT-3 能够创建高级聊天机器人,提供个性化的财务建议、分析市场趋势和评估风险。这些人工智能顾问可以与客户互动,了解他们的财务目标,并提供量身定制的投资策略。
客户服务 — 高级聊天机器人和支持系统: 通过使用复杂的聊天机器人,客户服务已经发生了变化,这些聊天机器人能够以类似人类的理解和响应来处理各种查询。这样可以改善客户体验和运营效率。
电子商务 — 产品描述和客户评论分析:电子商务平台使用NLP来生成动态产品描述和分析客户评论。这有助于了解消费者情绪、个性化推荐和改进产品供应。
教育 — 个性化学习和评估: 由 GPT-3 提供支持的教育工具通过根据个别学生的需求和学习风格调整内容来提供个性化的学习体验。他们还可以协助对书面作业进行评分和提供反馈,从而节省教育工作者的时间。
汽车 — 声控助手和用户手册:在汽车行业,NLP用于开发车辆中的高级语音激活助手,允许驾驶员通过语音命令控制功能。此外,用户手册可以使用自然语言轻松查询,从而改善用户体验。
媒体和娱乐 — 内容策划和剧本创作:媒体公司利用 NLP 进行内容策划、剧本创作,甚至产生创意内容创意,从而改变故事的讲述和消费方式。
旅游和酒店业 — 语言翻译和客户互动:在旅游和酒店业,NLP对于实时语言翻译服务至关重要,可以增强与国际旅行者的沟通。它还用于客户服务聊天机器人,以提供预订帮助和个性化旅行建议。
人力资源 — 简历筛选和员工敬业度:人力资源部门使用 NLP 工具更有效地筛选简历并分析员工反馈以衡量满意度和敬业度。
这些应用程序展示了 NLP 的多功能性和变革潜力,尤其是在 GPT-3 和 transformer 技术在各个领域带来的进步之后。
六 NLP的未来趋势
当我们展望自然语言处理(NLP)的视野时,一些有希望的趋势正在出现,这些趋势有望重新定义该领域的格局。其中最关键的是:
提高模型效率: 人们越来越重视创建NLP模型,这些模型不仅功能强大,而且在使用计算资源方面也很有效。这种转变对于使先进的NLP技术更容易获得和可持续至关重要。
拥抱语言多样性:一个重要的趋势是开发能够理解和处理更广泛的语言的模型,包括目前在NLP系统中代表性不足的语言。这种扩展对于构建真正全球化和包容性的 AI 解决方案至关重要。
多模态 NLP 的进展: 文本与其他形式的数据(如视觉和听觉输入)的集成是一个快速发展的领域。多模态 NLP 有望提供更全面、更通用的 AI 系统,能够理解更丰富的人类交流并与之交互。
数据高效学习:另一个重点领域是开发能够从较小的数据集中有效学习的模型。这一进步对于大量数据不易获得的专业领域的应用或数字资源有限的语言和方言尤为重要。
这些趋势说明了 NLP 的持续发展,明显转向更具包容性、效率和多功能的模型。随着这些进步的实现,它们有可能显着扩大NLP在各个领域的适用性和影响,从全球通信到个性化的AI交互。
七. 道德考量
随着我们改进语言技术,重要的是要考虑如何保护人们的信息私密性,确保技术对每个人都是公平的,并了解它如何影响社会。我们需要谨慎使用这些工具,以确保它们对所有人都有帮助和公平。
八、结论
随着我们的“完整的NLP指南:文本到上下文”系列的结束,让我们回顾一下我们一起开始的迷人旅程。这是一次探索探索自然语言处理 (NLP) 的复杂世界,这是一个将文本转化为有意义的上下文的领域。
从了解 NLP 是什么及其日常应用的最初步骤开始,我们就开始涉足文本处理的复杂性。我们解开了标记化的线索,深入研究了文本清理的细微差别,并在命名实体识别的迷宫中导航。
我们的道路将我们带入了更深的机器学习中心,在那里我们揭开了情感分析的奥秘和语言翻译的微妙之处。当我们探索深度学习领域时,我们目睹了神经网络的力量以及它们如何为文字注入活力。
变形金刚的变革世界是我们旅程的关键部分,它揭示了彻底改变机器理解人类语言方式的架构。我们看到了BERT的奇迹,以及迁移学习如何推动NLP的边界。
我们的探索不仅仅是关于技术;这是一次理解这种权力带来的道德和责任的旅程。当我们结束时,我们站在一个有利位置,回顾我们穿越的地形,从简单的文本到对上下文的深刻理解。这个系列不仅仅是一个指南;它一直是欣赏 NLP 未来令人难以置信的潜力和前景的门户。
相关文章:

【文本到上下文 #10】探索地平线:GPT 和 NLP 中大型语言模型的未来
一、说明 欢迎阅读我们【文本到上下文 #10】:此为最后一章。以我们之前对 BERT 和迁移学习的讨论为基础,将重点转移到更广阔的视角,包括语言模型的演变和未来,特别是生成式预训练转换器 (GPT) 及其在 NLP 中…...
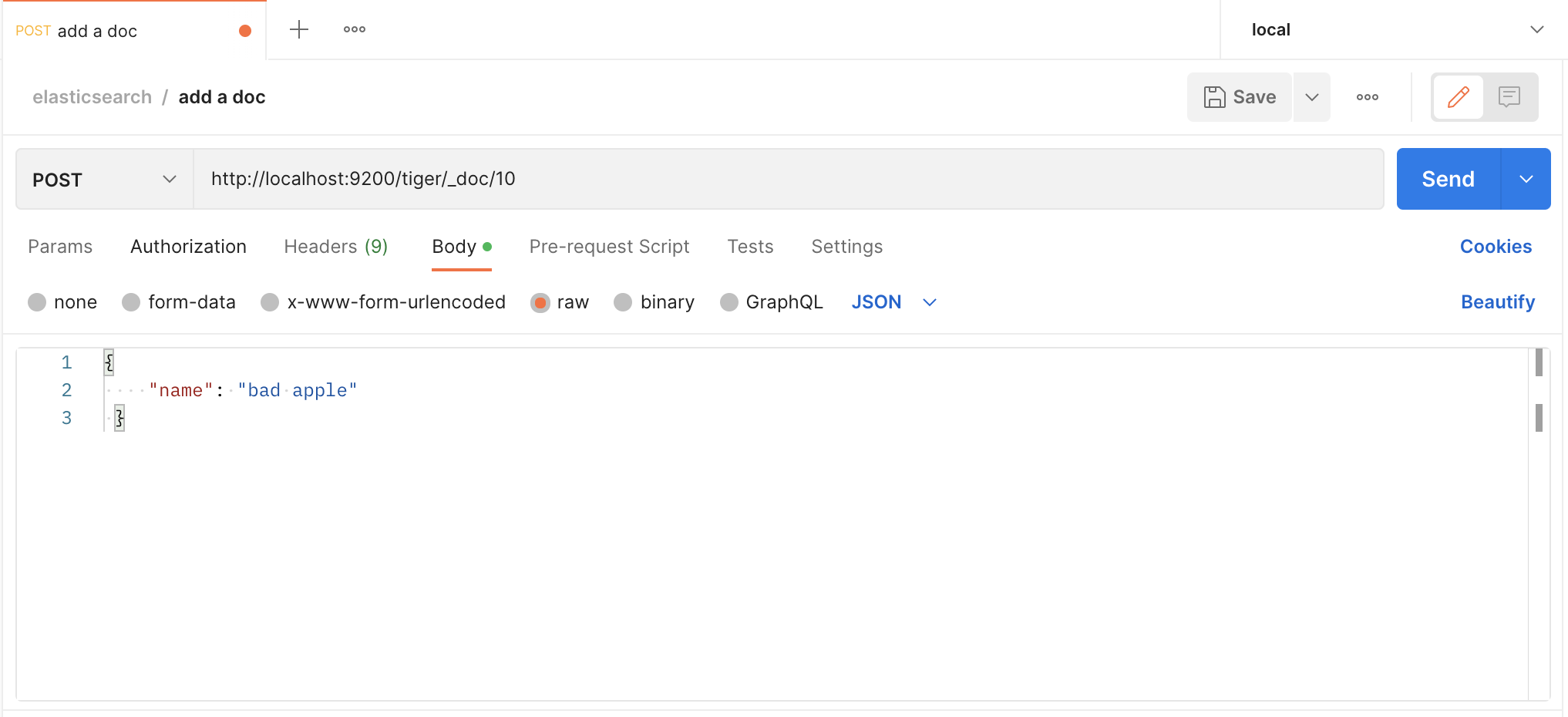
(四)elasticsearch 源码之索引流程分析
https://www.cnblogs.com/darcy-yuan/p/17024341.html 1.概览 前面我们讨论了es是如何启动,本文研究下es是如何索引文档的。 下面是启动流程图,我们按照流程图的顺序依次描述。 其中主要类的关系如下: 2. 索引流程 (primary) 我们用postman发送请求&…...
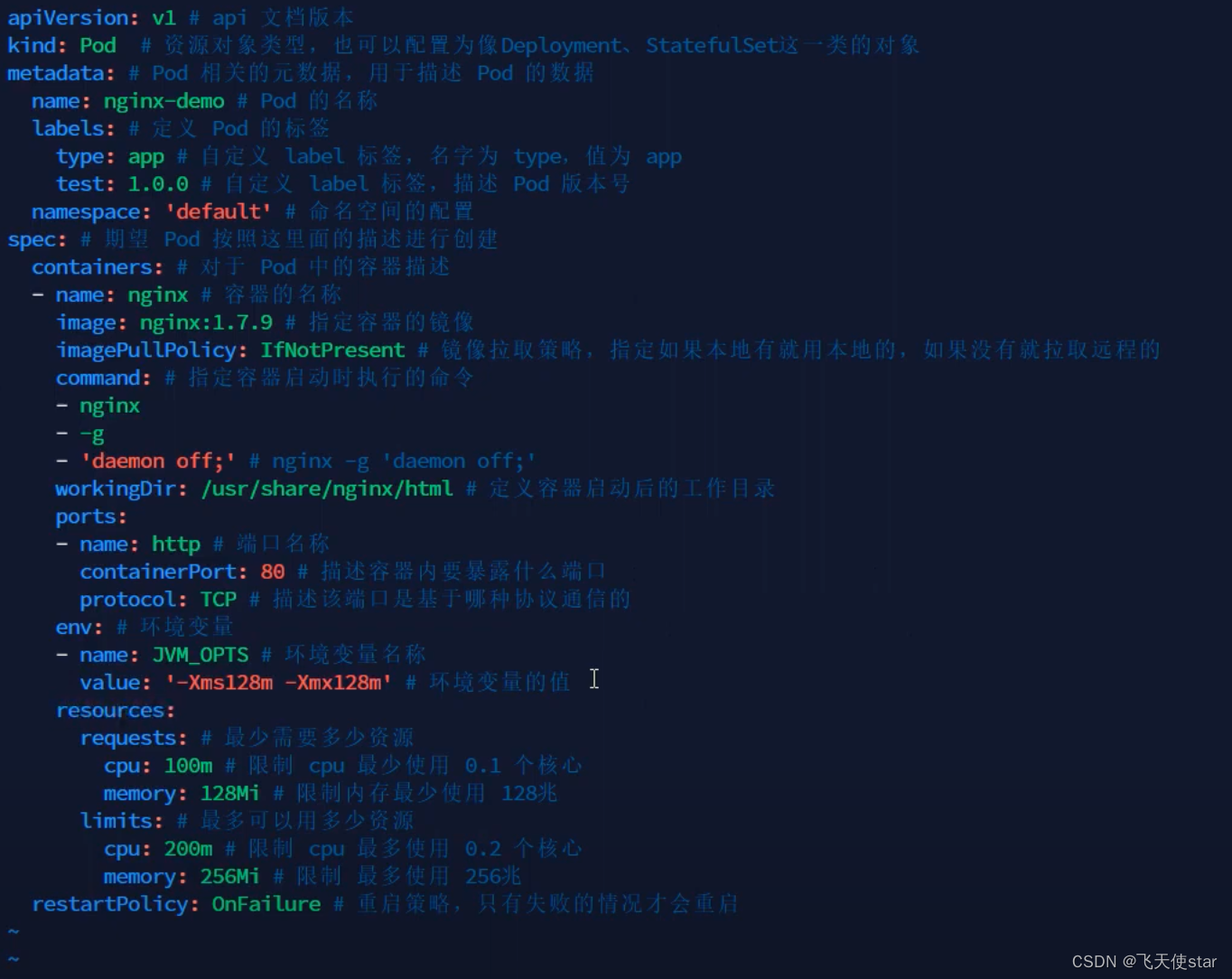
飞天使-k8s知识点16-kubernetes实操1-pod
文章目录 深入Pod 创建Pod:配置文件详解写个pod的yaml 文件深入Pod 探针:探针技术详解 深入Pod 创建Pod:配置文件详解 资源清单参考链接:https://juejin.cn/post/6844904078909128712写个pod的yaml 文件 apiVersion: v1 kind: P…...

【gcc】webrtc发送侧 基于丢包更新码率
参考大神的分析1 rtt 有问题:网络拥堵,直接下调码率 G:\CDN\rtcCli\m98\src\modules\congestion_controller\goog_cc\send_side_bandwidth_estimation.hRttBasedBackoff RttBasedBackoff rtt_backoff_;class RttBasedBackoff {public:explicit RttBasedBackoff(const WebRtcK…...

数字经济的未来:探索Web3的商业模式
随着技术的不断演进,Web3正逐渐成为数字经济发展的关键驱动力之一。在这个数字时代,我们目睹着Web3为商业模式带来翻天覆地的变革,探索着数字经济未来的可能性。 1. 去中心化的商业生态 Web3以去中心化为核心理念,打破了传统商业…...

Centos7部署MetaBase-v0.48.3
MetaBase_v0.48.3下载地址 : http://downloads.metabase.com/v0.48.3/metabase.jar JDK11 下载地址:https://repo.huaweicloud.com/java/jdk/11.0.113/jdk-11.0.1_linux-x64_bin.tar.gz 1.不修改源数据库的方式 官方提示此方式仅用于测试学习使用,如用生…...
【计算机网络】Socket的SO_TIMEOUT与连接超时时间
SO_TIMEOUT选项是Socket的一个选项,用于设置读取数据的超时时间。它指定了在读取数据时等待的最长时间,如果在指定的时间内没有数据可读取,将抛出SocketTimeoutException异常。 SO_TIMEOUT的设置 默认情况下,SO_TIMEOUT选项的值…...

解密 ARMS 持续剖析:如何用一个全新视角洞察应用的性能瓶颈?
作者:饶子昊、杨龙 应用复杂度提升,根因定位困难重重 随着软件技术发展迭代,很多企业软件系统也逐步从单体应用向云原生微服务架构演进,一方面让应用实现高并发、易扩展、开发敏捷度高等效果,但另外一方面也让软件应…...

【OJ比赛日历】春节快乐 #02.10-02.16 #9场
CompHub[1] 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号会推送最新的比赛消息,欢迎关注! 以下信息仅供参考,以比赛官网为准 目录 2024-02-10(周六) #4场比赛2024-02-11…...

前端下载文件有哪些方式
前端下载文件有哪些方式 在前端,最常见和最常用的文件下载方式是: 使用 标签的 download 属性: 创建一个 标签,并设置其 href 属性为文件的 URL,然后使用 download 属性指定下载的文件名。 这种方式简单直接&…...
vscode预览github上的markdown效果
需要安装的插件有: Github Markdown Preview Markdown Checkboxes Markdown Emoji Markdown footnotes Markdown Preview Github Styling Markdown Preview Mermaid Support Markdown yaml Preamble ctrlshiftv结合双页功能...
)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)。 要使用PaddleNLP和BERT来识别垃圾邮件并做中文邮件内容分类,可以按照以下步骤进行操作: 安装PaddlePaddle和PaddleNLP:首先,确保在你的环境中已经安装了PaddlePaddle和…...
在bash或脚本中,如何并行执行命令或任务(命令行、parallel、make)
最近要批量解压归档文件和压缩包,所以就想能不能并行执行这些工作。因为tar自身不支持并行解压,但是像make却可以支持生成一些文件,所以我才有了这种想法。 方法有两种,第一种不用安装任何软件或工具,直接bash或其他 …...

拼音笔记笔记
一、翀的读音:chōng 声母:ch 韵母:ong 声调:一声 二、汉字释义: 向上直飞,相当于“冲”。 三、汉字结构:左右结构 四、部首:羽 五、相关词组: 翀举:谓成仙升…...

13. Threejs案例-绘制3D文字
13. Threejs案例-绘制3D文字 实现效果 知识点 FontLoader 一个用于加载 JSON 格式的字体的类。 返回 font,返回值是表示字体的 Shape 类型的数组。 其内部使用 FileLoader 来加载文件。 构造器 FontLoader( manager : LoadingManager ) 参数类型描述managerLo…...

clickhouse清理日志。
参考Clickhouse:日志表占用大量磁盘空间怎么办?_clickhouse store目录很大-CSDN博客t 清理脚本如下,清理动作需要时间比较长,10多分钟: alter table system.trace_log delete where event_date < 2024-01-01 alt…...

JS中实现继承
1.使用call实现继承(不推荐) function Animal(name) {this.name name;this.run function() {console.log(this.name, "跑");} } function Dog(name) {// 继承Animal.call(this, name);this.sleep function() {console.log(this.name, &quo…...

spring boot学习第九篇:操作mongo的集合和集合中的数据
1、安装好了Mongodb 参考:ubuntu安装mongod、配置用户访问、添删改查-CSDN博客 2、pom.xml文件内容如下: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns…...
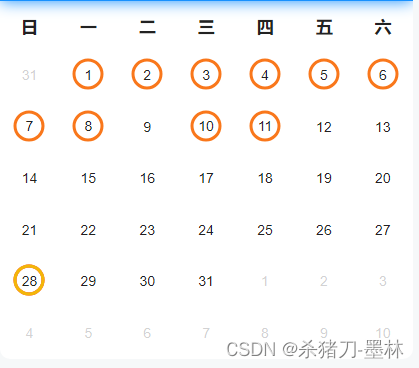
momentJs推导日历组件
实现效果: 代码: 引入momentjs然后封装两个函数构建出基本数据结构 import moment from moment;// 某月有多少天 export const getEndDay (m) > m.daysInMonth();/*** description 获取本月空值数据* param { Date } year { } 年度* param { Number } month …...

Linux C/C++ 原始套接字:打造链路层ping实现
在C/C中,我们可以使用socket函数来创建套接字。我们需要指定地址族为AF_PACKET,协议为htons(ETH_P_ALL)来捕获所有传入和传出的数据包。 可以使用sendto和recvfrom函数来发送和接收数据包。我们需要构建一个合法的链路层数据包,在数据包的头…...

OpenClaw+Qwen3.5-9B实战:5步完成本地AI助手部署与飞书接入
OpenClawQwen3.5-9B实战:5步完成本地AI助手部署与飞书接入 1. 为什么选择OpenClawQwen3.5-9B组合? 去年冬天,当我第5次因为忘记整理会议录音而被领导提醒时,终于决定给自己找个"数字助理"。在尝试了多个自动化工具后&…...
)
IPD实战:如何用DCP决策点避免产品开发中的‘死亡陷阱’(附真实案例)
IPD实战:如何用DCP决策点避免产品开发中的"死亡陷阱" 在硅谷某科技公司的产品复盘会上,CTO盯着投影仪上的数据图表沉默良久——这个投入1200万美元、历时18个月的智能硬件项目,最终因为电池续航不达标而被迫终止。更令人痛心的是&a…...

Ollama部署granite-4.0-h-350m:350MB小模型如何实现高精度RAG推理?
Ollama部署granite-4.0-h-350m:350MB小模型如何实现高精度RAG推理? 350MB的模型大小,却能实现高质量的RAG推理效果?granite-4.0-h-350m这个小巧而强大的模型正在重新定义轻量级AI的可能性。 1. 认识granite-4.0-h-350m:…...

DownKyi:B站视频高效解决方案——如何三步搞定8K资源本地化管理
DownKyi:B站视频高效解决方案——如何三步搞定8K资源本地化管理 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印…...

视频转PPT智能提取工具:自动化幻灯片提取效率提升10倍的完整方案
视频转PPT智能提取工具:自动化幻灯片提取效率提升10倍的完整方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字化学习和远程办公的时代,视频内容已成…...

SHA-3:从海绵结构到抗量子密码学的基石
1. SHA-3的诞生背景与核心价值 2004年,密码学界发现SHA-1存在理论漏洞,这直接推动了NIST启动新一代哈希算法竞赛。经过5年激烈角逐,Keccak团队提出的海绵结构方案最终胜出。与传统哈希算法不同,SHA-3不是对SHA-2的简单升级&#x…...

别再手动组合特征了!用GBDT+LR搞定CTR预估,附Python实战代码与调参心得
GBDTLR:自动化特征工程的CTR预估实战指南 在推荐系统和广告投放领域,点击率(CTR)预估的准确性直接影响着平台的核心商业指标。传统手动特征工程方法在面对高维稀疏特征时往往力不从心,而GBDTLR的组合策略为我们提供了一…...

AD5660 16位DAC驱动库深度解析:嵌入式SPI接口实践
1. AD5660 数字模拟转换器库深度解析:面向嵌入式工程师的16位高精度DAC驱动实践1.1 器件本质与工程定位AD5660 是 Analog Devices 推出的单通道、16位电压输出型数模转换器(DAC),采用紧凑的 8 引脚 MSOP 封装,专为对精…...
)
ESP32+LVGL实战:手把手教你搞定ST7789屏幕镜像显示(附完整代码)
ESP32LVGL实战:从寄存器到工程化配置,彻底解决ST7789屏幕镜像显示问题 当你用ESP32驱动ST7789屏幕时,是否遇到过图像上下左右颠倒的困扰?这个问题看似简单,但网上的零散教程往往只告诉你改某个寄存器值,却忽…...
)
PX4 OFFBOARD模式实战:手把手教你用C++代码让无人机自主起飞(附心跳包避坑指南)
PX4 OFFBOARD模式深度实战:从心跳包机制到三维轨迹控制的完整实现 当你的无人机在OFFBOARD模式下突然失控坠落,或者莫名其妙地退出自主控制模式时,是否曾怀疑过自己的代码逻辑?这些问题往往源于对PX4底层通信机制理解不够深入。本…...