【hello, world】计算机系统漫游
文章目录
- hello程序
- 信息就是位 + 上下文
- 程序被其他程序翻译成不同的格式
- 预处理阶段
- 编译阶段
- 汇编阶段
- 链接阶段
- 了解编译系统如何工作是大有益处的
- 优化程序性能
- 理解链接时出现的错误
- 避免安全漏洞
- 处理器读并解释储存在内存中的指令
- 系统的硬件组成
- 总线
- I/O设备
- 主存
- 处理器
- 运行hello程序
- 高速缓存至关重要
- 存储设备形成层次结构
- 操作系统管理硬件
- 进程
- 线程
- 虚拟内存
- 文件
- 系统之间利用网络通信
- 重要主题
- Amdahl定律
- 并发和并行
- 线程级并发
- 指令级并行
- 单指令、多数据并行
- 计算机系统中抽象的重要性
计算机系统是硬件和系统软件互相交织的集合体。
hello程序
hello.c
#include <stdio.h>int main()
{printf("hello, world\n");return 0;
}
我们通过跟踪hello程序的生命周期来开始对系统的学习:从它被程序员创建开始,到在系统上运行,输出简单的消息,然后终止。
信息就是位 + 上下文
hello程序的生命周期是从源程序(源文件)开始的,即程序员通过编辑器创建并保存的文本文件hello.c。源程序实际上就是一个由0和1组成的位(比特、bit)序列。8个位被组织成一组,称为字节(byte)。
ASCII标准用一个唯一的单字节大小的整数值表示一个字符,如字符#对应的数值是35,字符i对应的数值是105。hello.c的ASCII文本表示如下图所示:

像hello.c这样可以通过标准字符集(如ASCII)解析的文件称为文本文件,所有其他文件都称为二进制文件。
系统中的所有信息——包括磁盘文件、内存中的程序、内存中存放的用户数据以及网络上传送的数据,都是由一串比特表示的。区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文。比如在不同的上下文中,一串相同的字节序列可能表示一个整数、浮点数、字符串或机器指令。
通常情况下,机器表示的数值是实际数值的有限近似值。
程序被其他程序翻译成不同的格式
hello.c是能够被人读懂的文本文件,但为了在系统上运行它,每条C语句都必须被其他程序转化为一系列的低级机器语言指令(能被机器读懂)。然后这些指令按照一种称为可执行目标程序的格式打好包,并以二进制文件(可执行目标文件)的形式存放在磁盘。
在Unix系统上,从源文件到目标文件的转化是由编译器驱动程序(简称编译器)完成的:

在这里,gcc编译器读取hello.c并生成hello的过程可分为四个阶段:预处理、编译、汇编、链接。与此相关的预处理器、编译器、汇编器和链接器一起构成了编译系统。

预处理阶段
预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。比如#include <stdio.h>命令告诉cpp读取系统头文件stdio.h里的内容,并把它插入程序文本中相应的位置。结果就得到了另一个以.i作为文件扩展名的C程序。
编译阶段
编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。该程序包含函数main的定义:
main:
.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $.LC0, %edicall putsmovl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
上述每条汇编语句都文本的形式描述了一条低级机器语言指令。不同高级语言的不同编译器针对某个确定的CPU架构输出统一的汇编语言。
汇编阶段
汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件hello.o中。hello.o中包含的是函数main的指令编码,如果在文本编辑器中打开该二进制文件,会看到一堆乱码。
链接阶段
hello程序调用了printf函数,它是每个C编译器都提供的标准C库中的一个函数。printf函数存在于一个名为printf.o的单独的预编译好了的目标文件中,这个文件必须以某种方式合并到hello.o中,否则main函数将无法调用printf函数。
链接器(ld)就负责处理这种合并,结果就得到hello文件,它是一个可执行目标文件(简称可执行文件),平时存储在磁盘上,运行时被加载到内存,由系统执行。
了解编译系统如何工作是大有益处的
优化程序性能
了解编译器将不同的C语句转化为机器代码的方式,有助于我们写出更高效的代码。如:
- 一个
switch语句是否总比一系列的if-else高效? - 一个函数调用的开销有多大?
while循环比for循环更有效吗?- 指针引用比数组索引更有效吗?
- 为什么将循环求和的结果放到一个本地变量中,会比将其放到一个通过引用传递过来的参数中,运行起来快很多呢?
- 为什么我们只是简单地重新排列一下算术表达式中的括号就能让函数运行得更快?
理解链接时出现的错误
一些最令人困扰的程序错误都和链接有关,尤其是构建大型软件系统的时候。如:
- 链接器报告说它无法解析一个引用,这是什么意思?
- 静态变量和全局变量的区别是什么?
- 在不同的
C文件中定义了名字相同的两个全局变量会发生什么? - 静态库和动态库的区别是什么?
- 命令行上排列库的顺序有什么影响?
- 为什么有些链接错误直到运行时才会出现?
避免安全漏洞
缓冲区溢出是造成软件安全漏洞的主要原因,学习安全编程的第一步就是理解数据和控制信息存储在程序栈上的方式(这种方式由编译器决定)及其会引起的后果。
处理器读并解释储存在内存中的指令
现在,hello.c源程序已经被编译系统翻译成了可执行目标文件hello,并被存放在磁盘上。要想在Unix系统上运行该可执行文件,我们将它的文件名输入到称为shell的应用程序中。
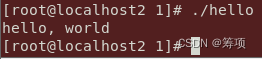
shell是一个命令行解释器,它输出一个提示符,等待输入一个命令行,然后执行这个命令。
在此例中,shell加载并运行hello程序,然后等待程序终止,随后再输出一个提示符,等待输入下一个命令行。
系统的硬件组成
要理解hello程序运行时发生了什么,我们需要了解一下典型系统的硬件组织。

总线
贯穿整个系统的是一组电子管道,称作总线(bus),它携带信息字节并负责在各个部件间传递。通常总线被设计成传送定长的字节块,也就是字(word)。字的字节数(即字长)是一个基本的系统参数,各系统不尽相同,如32位系统的字长是4字节,64位系统的字长是8字节。
I/O设备
I/O(输入/输出)设备是系统与外部世界的联系通道。图中包括4个I/O设备:作为输入设备的鼠标、键盘,作为输出设备的显示器,即能输入又能输出、长期存储数据和程序的磁盘驱动器(简称磁盘)。hello程序就存放在磁盘上。
每个I/O设备都通过一个控制器或适配器与I/O总线相连。控制器是I/O设备本身或者系统的主印制电路板(即主板)上的芯片组,适配器则是一块插在主板插槽上的卡(可插拔),它们的功能都是在I/O总线和I/O设备之间传递信息。
主存
主存(即内存)是一个临时存储设备,在处理器执行程序时,用来存放程序和程序处理的数据。每条程序指令所占用的字节数不尽相同,每个数据变量所占用的字节数也不尽相同。
物理上来说,主存是由一组动态随机访问存储器(DRAM)芯片组成的。逻辑上来说,主存是一个线性的字节数组,每个字节都有其唯一的地址(数组索引),地址从0开始。
处理器
中央处理单元(CPU),简称处理器,是执行存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(寄存器),称为程序计数器(PC),PC始终指向CPU执行的当前指令或下一条指令。从系统通电开始,直到系统断电,处理器一直在不断地执行PC指向的指令,再更新PC,执行下一条指令。
处理器是按照一个简单的指令执行模型工作的,这个模型由其指令集架构(如x86_64,armv8)决定。
执行指令时,处理器从PC指向的内存处读取指令,解释指令中的位,执行该指令指示的简单操作,然后更新PC。
这样的简单操作围绕着主存、寄存器文件、算术逻辑单元(ALU)进行。寄存器文件是一个小的存储设备,由一些单字长的寄存器组成,每个寄存器都有唯一的名字。ALU计算新的数据和地址。CPU在执行一条指令时,可能会做这些简单操作:
- 加载:从主存复制一个字节或一个字到寄存器,覆盖该寄存器原来的内容。
- 存储:从寄存器复制一个字节或一个字到主存中的某个位置,覆盖主存上该位置原来的内容。
- 操作:把两个寄存器的内容复制到
ALU做算术运算,将结果保存到一个寄存器中。 - 跳转:从指令本身中抽取一个字,复制到
PC上。
处理器看上去是它的指令集架构的简单实现,但是实际上现代处理器使用了非常复杂的机制来加速程序的执行。因此,我们将处理器的指令集架构和处理器的微体系结构区分开来:
- 指令集架构描述的是每条机器代码指令在做什么。
- 微体系结构描述的是处理器实际上是如何实现的。
指令集架构是对处理器的抽象表示,微体系结构是处理器的具体实现方式。
运行hello程序
当我们在shell上输入字符串./hello后,shell程序将字符逐一读入寄存器,再把它放到内存中。

当我们在键盘上敲回车键时,shell程序就知道我们已经结束了输入命令,于是shell便开始加载可执行文件hello,将hello目标文件中的代码和数据从磁盘复制到主存。
利用直接存储器存取(DMA)技术,字节信息可以不通过处理器而直接从磁盘达到主存。

一旦目标文件hello中的代码和数据被加载到主存,处理器就开始执行hello程序的main函数中的机器语言指令。这些指令将"hello, world\n"字符串中的字节从主存复制到寄存器文件,再从寄存器文件复制到显示设备,最终显示在显示器上。

高速缓存至关重要
可以看到程序执行时,信息在外部设备、磁盘、主存、寄存器文件之间来回传输,系统花费了大量的时间把信息(数据和指令)从一个地方复制到另一个地方。这些复制就是开销,因此提升程序性能的一个重要手段就是减少信息的复制。
处理器从寄存器文件中读数据比从主存中读数据要快很多(如100倍),针对这个问题,系统设计者采用了高速缓存存储器(简称高速缓存或cache),作为主存信息暂时的集结区域,存放处理器近期可能会需要的信息。cache使用一种叫做静态随机访问存储器(SRAM)的硬件技术实现。
位于处理器芯片上的L1 cache,处理器访问它的速度几乎和寄存器文件一样快。容量更大、访问速度稍慢的L2 cache和L3 cache通过一条特殊的总线连接到处理器。

上图仅供参考,
L2 cache和L3 cache也有别的实现方式,比如都集成到CPU。
利用高速缓存的局部性原理(程序具有访问局部区域里的数据和代码的趋势),缓存命中率高的情况下,大部分的内存操作都能在快速的高速缓存中完成,程序的性能会因此提高一个数量级。
存储设备形成层次结构
每个计算机系统中的存储设备都被组织成了一个存储器层次结构。在这个层次结构中,从上至下,设备的访问速度越来越慢、容量越来越大、每字节的造价越来越便宜。寄存器文件处于最顶层(L0),高速缓存占用L1、L2、L3,主存在第四层(L4),以此类推。

存储器层次结构的主要思想是:上一层存储器作为下一层存储器的高速缓存。
操作系统管理硬件
当shell加载和运行hello程序时,它们并没有直接访问键盘、主存、磁盘和显示器。所有应用程序对硬件的操作尝试都必须通过操作系统。

操作系统有两个基本功能:
- 防止硬件被失控的应用程序滥用(保护系统)。
- 向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备(提供抽象)。
系统认为应用程序指令是存在安全隐患的,而操作系统指令是一定安全的。
操作系统通过几个基本的抽象(进程、虚拟内存和文件)来实现这两个功能。

文件是对
I/O设备的抽象表示
虚拟内存是对主存和I/O设备的抽象表示
进程是对处理器、主存和I/O设备的抽象表示
进程
进程是操作系统对一个正在运行的程序的抽象。在一个系统上可以同时运行多个进程,而在每个进程看来,它都在独占处理器、主存和I/O设备。并发运行是说一个进程的指令和另一个进程的指令是交错执行的,这是通过处理器在进程间切换(上下文切换)来实现的。
操作系统保持跟踪进程运行所需的所有状态信息,这种状态就是进程上下文,包括PC和寄存器文件的当前值、主存的内容。在任何一个时刻,单处理器系统都只能执行一个进程的代码。当操作系统要把控制权转移给其它进程时,就会进行上下文切换。即保存当前进程的上下文,恢复新进程的上下文,转移控制权给新进程,新进程就会从它上次停止的地方开始执行。
进程有两种运行状态:用户态和内核态。单个进程执行过程中,也会涉及到内核态和用户态之间的切换。但这种切换相比于进程间的上下文切换,开销要小。
从一个进程到另一个进程的转换是由操作系统内核管理的,内核是操作系统代码常驻主存的部分。
内核不是一个独立的进程,它是系统管理全部进程所用代码和数据结构的集合。所以内核态和用户态之间的切换不是进程间上下文切换。
系统中可以有很多进程,但通常只有一个内核。
上述通过shell进程加载和执行hello程序的场景,其简易执行流程如下:

更完整的流程描述:

read、exec、write这些函数属于系统调用,执行系统调用时,进程会切换到内核态。
shell进程调用read从命令行读到字符串"./hello"。shell进程创建子进程,并加载hello目标文件到该子进程。操作系统把控制权交给子进程(hello进程)。hello进程正常执行。调用write把"hello, world\n"写到显示器上。hello进程终止,shell进程获得操作系统控制权。
线程
一个进程可以由多个称为线程的执行单元组成,每个线程都运行在进程的上下文中,共享同样的代码和全局数据,每个线程也会有自己的资源。操作系统在同一进程的多线程之间切换开销较小。
虚拟内存
操作系统为每个进程提供了一个假象,即每个进程都在独占地使用一块超大的虚拟内存,且每个进程的虚拟内存地址空间结构是一样的。
在Linux虚拟地址空间中,地址空间最上面的区域是留给内核的,底部区域存放用户进程定义的代码和数据。

虚拟地址空间的每个区都有各自的功能:
- 程序代码和数据。对所有的进程来说,代码是从同一固定地址开始的。代码和数据区是直接按照可执行目标文件的内容初始化的。它们在进程开始运行时就被指定了大小。
- 运行时堆。当调用
malloc和free这样的C标准库函数时,堆区动态地扩展和收缩。 - 共享库。存放
C标准库、数学库等共享库的代码和数据。 - 运行时栈。位于用户虚拟地址空间顶部,用于函数的调用和返回、局部变量的申请和释放等,也可以在运行时动态地扩展和收缩。
- 内核区。位于虚拟地址空间顶部。里面的内容对所有进程来说都是一样的。但不允许应用程序读写或者直接调用这个区域的内容。
用户进程要访问内核区的话,需要产生中断、切换到内核态,再访问内核区的代码和数据,最后切换回用户态,把结果返回给用户进程。
文件
文件就是字节序列。每个I/O设备,包括磁盘、键盘、显示器,甚至网络,都可以看成是文件。对所有的设备读写都可以通过文件读写(如Unix的I/O系统函数)来实现。
系统之间利用网络通信
可以把网络看作一个I/O设备。
当系统从主存复制一串字节到网络适配器时,数据流经过网络到达另一台机器。

系统也可以从网络适配器上读取字节流,复制到自己的主存。

重要主题
Amdahl定律
阿姆达尔定律:当我们对系统的某个部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。若系统执行某应用程序需要时间为ToldT_{old}Told,假设系统某部分所需执行时间与该时间比例为α\alphaα,而该部分性能提升比例为kkk,即该部分初始所需时间为α∗Told\alpha*T_{old}α∗Told,现在所需时间为α∗Told/k\alpha*T_{old} / kα∗Told/k,总的执行时间为:
Tnew=(1−α)∗Told+α∗Told/k=Told∗[(1−α)+α/k]\begin{align} T_{new} = (1 - \alpha) * T_{old} + \alpha*T_{old} / k = T_{old} * [(1 - \alpha) + \alpha / k] \end{align} Tnew=(1−α)∗Told+α∗Told/k=Told∗[(1−α)+α/k]
老新时间比为:
S=ToldTnew=1(1−α)+α/k\begin{align} S = \frac{T_{old}}{T_{new}} = \frac{1}{(1 - \alpha) + \alpha / k} \end{align} S=TnewTold=(1−α)+α/k1
要想显著加速整个系统,必须提升全系统中相当大部分的速度,尤其是最耗时的部分。
性能提升最好的表示方式为ToldTnew\frac{T_{old}}{T_{new}}TnewTold,如果性能提升为原来的
2.2倍,记作2.2X
当系统部分性能提升比例kkk趋近于∞\infty∞时,SSS的值为:
S=11−α\begin{align} S = \frac{1}{1 - \alpha} \end{align} S=1−α1
如果系统的某部分占整体性能的60%,那么即便对该部分做了极致的优化,使其消耗的时间可以忽略不计,那么系统整体的性能提升只有2.5X。
并发和并行
并发:宏观上,系统能同时处理多个任务就叫并发。如同一时间段内,单处理器系统快速轮询处理多个任务。
并行:微观上,任意时刻,多个处理器同时处理多个任务,这些任务都不会出现被闲置的时刻。
并行是并发的一种场景。
我们按照系统层次结构中由高到低(抽象到具体)的顺序讨论一下并发。
线程级并发
线程是CPU调度的基本单位。线程级并发是指程序控制流的并发。
当构建一个由单操作系统内核控制的单处理器系统时,我们就得到一个单处理器系统。
当构建一个由单操作系统内核控制的多处理器系统时,我们就得到一个多处理器系统。
多处理器又分为多核处理器和超线程处理器。
有些功能强大的处理器既是多核的,又是超线程的。
多核处理器是将多个CPU(称核)集成到一个芯片上。每个CPU有自己的PC、寄存器文件、计算单元、高速缓存等,多核处理器可以同时维护多个控制流。如Intel i5-7200U是4核处理器。
超线程,有时称同时多线程,是一项允许一个CPU执行多个控制流的技术。比如单个CPU有多份PC、寄存器文件等,也可以同时维护多个控制流。如Intel i7可以让每个核执行2个线程,做成4核8线程处理器。
指令级并行
现代处理器可以同时执行多条指令的属性称为指令级并行(无线程级并发的情况下)。
处理器通过流水线等技术,可以做到单个时钟周期内执行一条甚至多条机器指令,超过一条机器指令的,就称之为超标量处理器。
单指令、多数据并行
许多现代处理器有特殊的硬件,允许一条指令产生多个可以并行执行的操作,即单指令、多数据(SIMD)。如图形处理器(GPU)。
计算机系统中抽象的重要性
抽象的使用是计算机科学中最为重要的概念之一。抽象带来了极大的方便,如程序员将某需求抽象为一组应用编程接口(API),且为这些API在不同场景下提供了不同的实现。而调用方在不同的场景下,可以使用同一调用接口。
指令集架构提供了对实际处理器硬件的抽象。有了这个抽象,机器代码程序表现得就好像运行在一个串行执行指令的处理器上。其实处理器底层硬件要比抽象描述复杂精细得多,它并行地执行多条指令,但整体效果跟抽象模型保持一致。只要模型一样,在不同的处理器上执行时,就会产生一样的结果,但会体现出不同的开销和性能。
文件是对I/O设备的抽象。
虚拟内存是对系统存储器的抽象。
进程是对一个正在运行的程序的抽象。
虚拟机是对整个计算机系统的抽象。

相关文章:
【hello, world】计算机系统漫游
文章目录hello程序信息就是位 上下文程序被其他程序翻译成不同的格式预处理阶段编译阶段汇编阶段链接阶段了解编译系统如何工作是大有益处的优化程序性能理解链接时出现的错误避免安全漏洞处理器读并解释储存在内存中的指令系统的硬件组成总线I/O设备主存处理器运行hello程序高…...
1. SpringMVC 简介
文章目录1. SpringMVC 概述2. SpringMVC 入门案例2.1 入门案例2.2 入门案例工作流程3. bean 加载控制4. PostMan 工具1. SpringMVC 概述 SpringMVC 与 Servlet 功能等同,均属于 Web 层开发技术。SpringMVC 是 Spring 框架的一部分。 对于 SpringMVC,主…...

《解谜三星堆:开启中华文明之门》-范勇 笔记
甲篇 应重视民间流传的疑似三星堆的文物,对其展开充分的研究,以发现更多关于三星堆的秘密,并且避免“敦煌窘境”,让我国的三星堆学术研究处于世界领先地位!(书中就讲到了在民间首次发现了圆形玉器…...
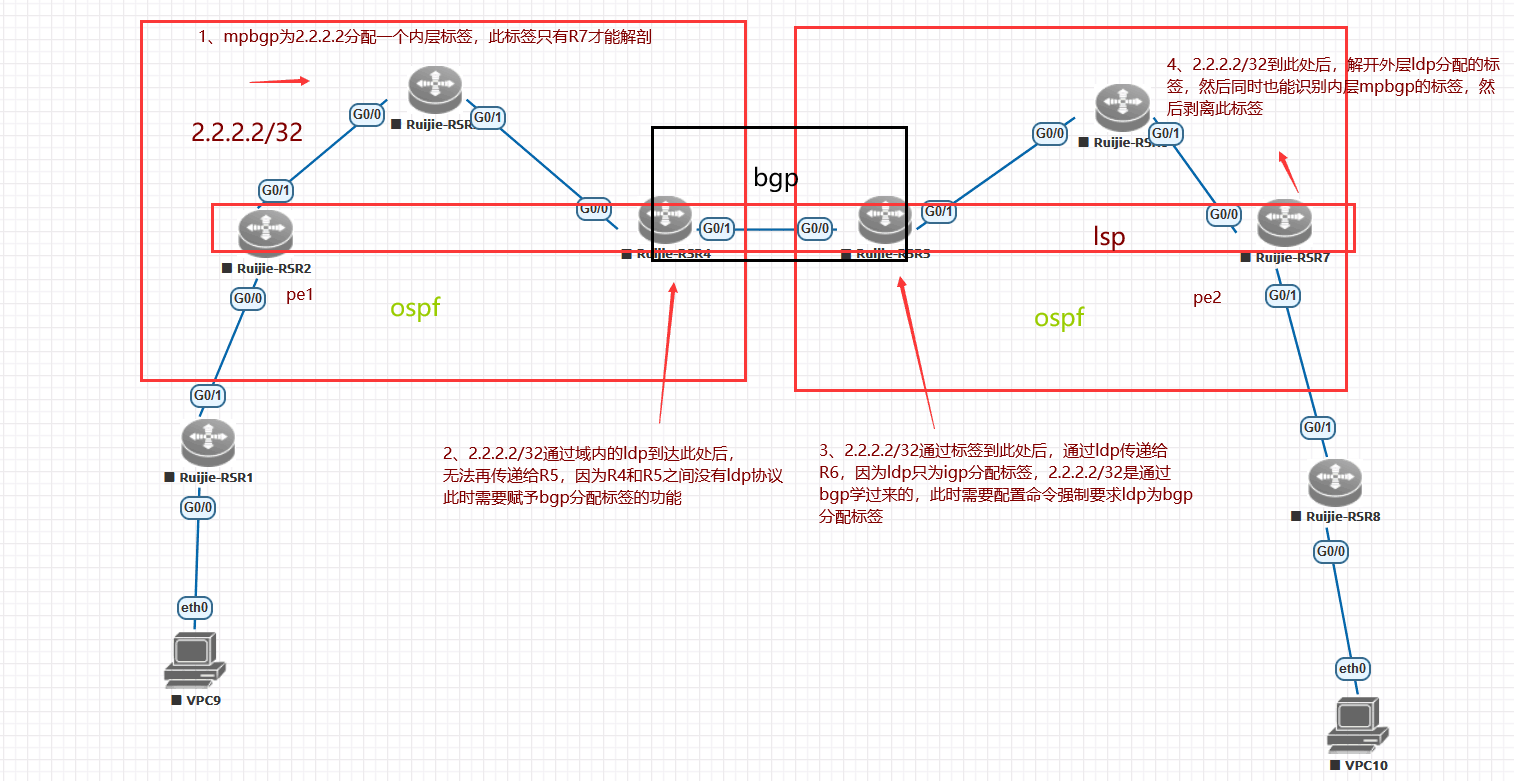
锐捷(十四)mpls vxn optionc的关键问题所在和具体问题分析
用锐捷的设备搭建mpls vxn optionc的基础版和带RR的版本,在控制平面和转发平免上分析mpls vxn optionc的关键问题所在和具体问题分析。一 基础mpls vxn optionc:核心:两pe之间之间建立MP EBGP邻居,从而直接传递路由解放了ASBR。关…...

Python语言零基础入门教程(十四)
Python 日期和时间 Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。 Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。 时间间隔是以秒为单位的浮点小数。 每个时间戳都以自从1970年1月1日午夜(历元&…...
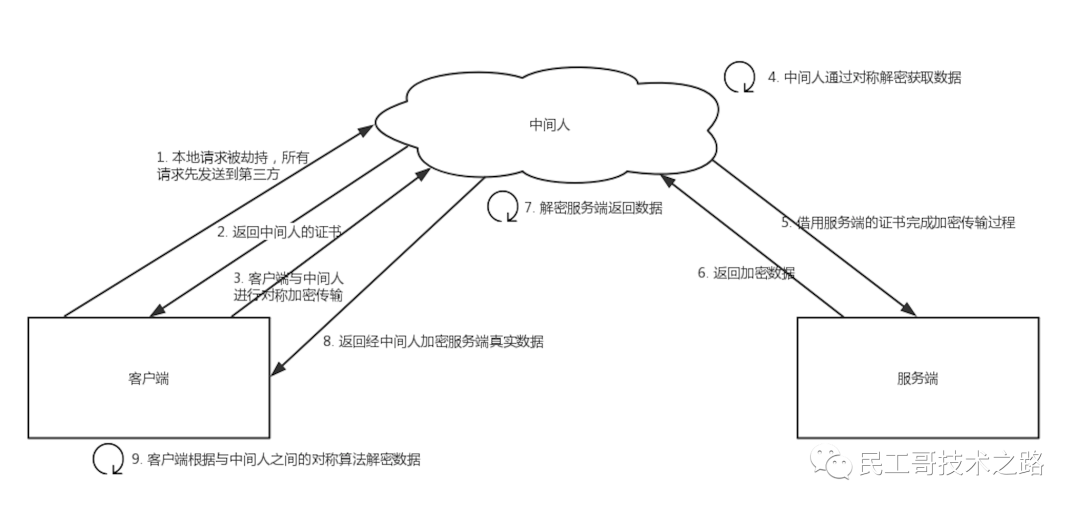
Https 协议超强讲解(一)
都说Https协议非常安全,那为什么还是会被抓包呢?抓包后会影响什么吗? HTTPS协议 随着 HTTPS 建站的成本下降,现在大部分的网站都已经开始用上 HTTPS 协议。大家都知道 HTTPS 比 HTTP 安全,也听说过与 HTTPS 协议相关…...

5.Redis 实现点赞 优化登陆(验证码 token..)
Redis(1)简介Redis 是一个高性能的 key-value 数据库原子 – Redis的所有操作都是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。非关系形数据库数据全部存在内存中,性能高。(2&#…...

scscanner:一款功能强大的大规模状态码扫描工具
关于scscanner scscanner是一款功能强大的大规模状态码扫描工具,该工具可以帮助广大研究人员从一个URL列表文件中批量读取目标网站的状态码响应信息。除此之外,该工具还可以过滤出指定的状态码,并将结果存储到一个文件中以供后续深入分析使用…...

Word 和 LaTeX 文档相互转换
Word 和 LaTeX 文档相互转换 目前可以找到两种工具完成将 LaTeX\LaTeXLATEX 文档向 Word 文档的转换, 分别为 Tex2Word和LaTeX-to-Word。 Tex2Word 安装Tex2Word后, 启动 Word, 打开你要转换的 LaTeX\LaTeXLATEX 源文件 (注意,如果没有成功安装 Tex2Word,那么你无法读取…...
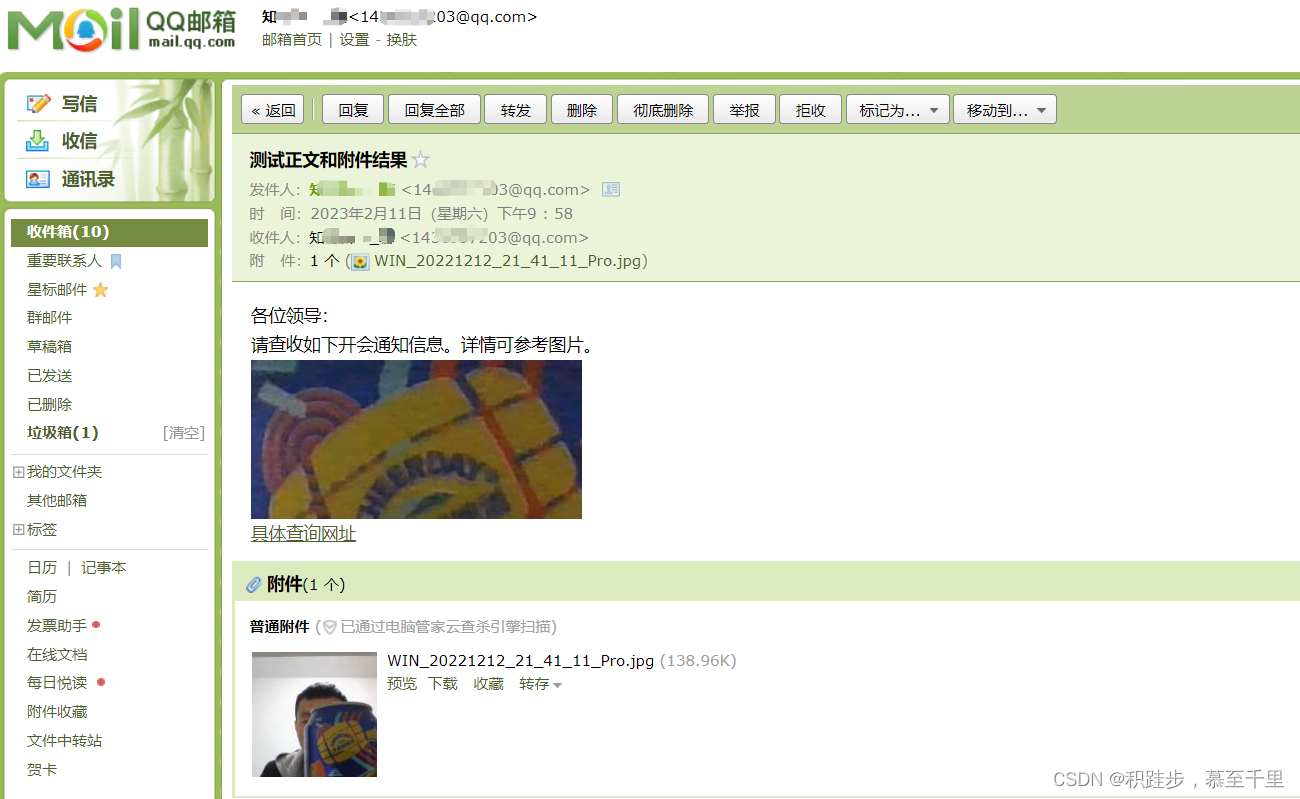
python自动发送邮件实现
目录1 前言2 准备工作2.1 电子邮件的基础知识。2.2 python邮件库2.3 邮箱设置3 python实现邮件自动发送3.1 SMTP()和send()方法介绍3.2 python实现实例参考信息1 前言 python功能强大,可以实现我们日常办公的很多任务。诸如批量处理word,excel,pdf等等文件…...

ccc-Classification-李宏毅(4)
文章目录Classification 概念Example ApplicationHow to do ClassificationWhy not RegesssionProbability from Class - FeatureProbability from ClassHow’s the results?Modifying ModelThree StepsProbability DistributionClassification 概念 本质是找一个函数&#x…...
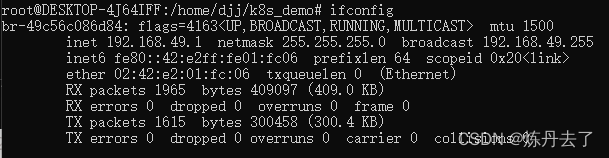
Kubernetes + Docker 部署一个yolov5检测服务(基于FastDeploy)
Kubernetes Docker 从零部署一个yolov5检测服务,服务基于PaddlePaddle/FastDeploy的服务化部署;所有软件从零安装。 文章目录1.说明2.环境3.安装过程 3.1安装 Docker 3.2安装 minikube 3.3安装 Kubectl4.部署过程 4.1 Docker相关 4.2 k8s相关 4.3 启动服…...
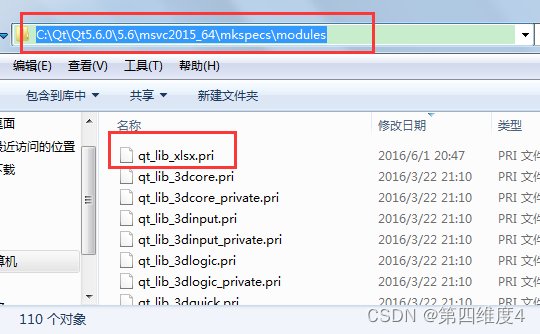
【C++/QT】QT5.6解析Excel教程(qtxlsx)
这里写目录标题【背景】【下载qtxlsx】【安装perl】【编译qtxlsx】【添加模块】【使用qtxlsx】【背景】 新接触QT,很多东西都不会,刚接触一个解析Excel的demo,记录一下安装、编译、解析Excel的过程 【下载qtxlsx】 在解析之前,…...

C++之智能指针
前言普通指针的不足new和new门的内存需要用delete和delete[释放。程序员的主观失误,忘了或漏了释放程序员也不确定何时释放(例如多个线程共享同一个对象,没办法确定什么时候释放)普通指针的释放类内的指针,在析构函数中…...
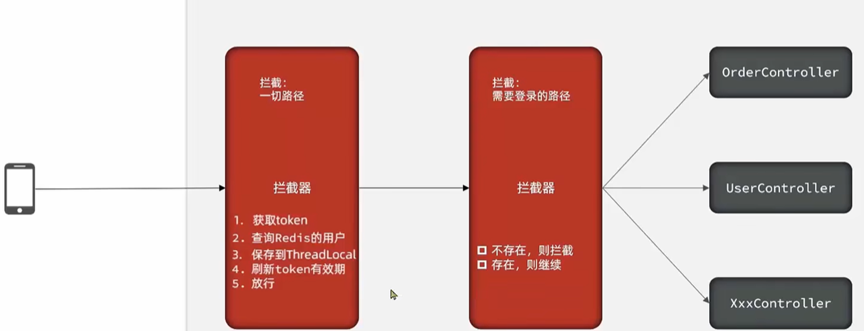
Redis实战-session共享之修改登录拦截器
在上一篇中Redis实战之session共享,我们知道了通过Redis实现session共享了,那么token怎么续命呢?怎么刷新用户呢?本来咱们就通过拦截器来实现这两个功能。 登录拦截器优化: 先来看看现在拦截器情况: 拦截…...
数据可视化,流程化处理pycharts-
本文直接进入可视化,输入讲解输入列表生成图片,关于pandas操作看这篇pandas matplotlib 导包后使用 import matplotlib.pyplot as plt饼图 使用 plt.figure 函数设置图片的大小为 15x15 使用 plt.pie 函数绘制饼图,并设置相关的参数&…...

1626_MIT 6.828 lab1课程大纲学习过程整理
全部学习汇总: GreyZhang/g_unix: some basic learning about unix operating system. (github.com) 现在lab1的内容全都学习完了,该做的练习也都做了。接下来,整理一下自己看这一部分课程讲义的一些笔记。 整理之前,先把自己完成…...

12月无情被辞:想给还不会自动化测试的技术人提个醒
公司前段时间缺人,也面了不少测试,结果竟没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但是平均水平很让人失望。基本能用一句话概括就是:3年测…...
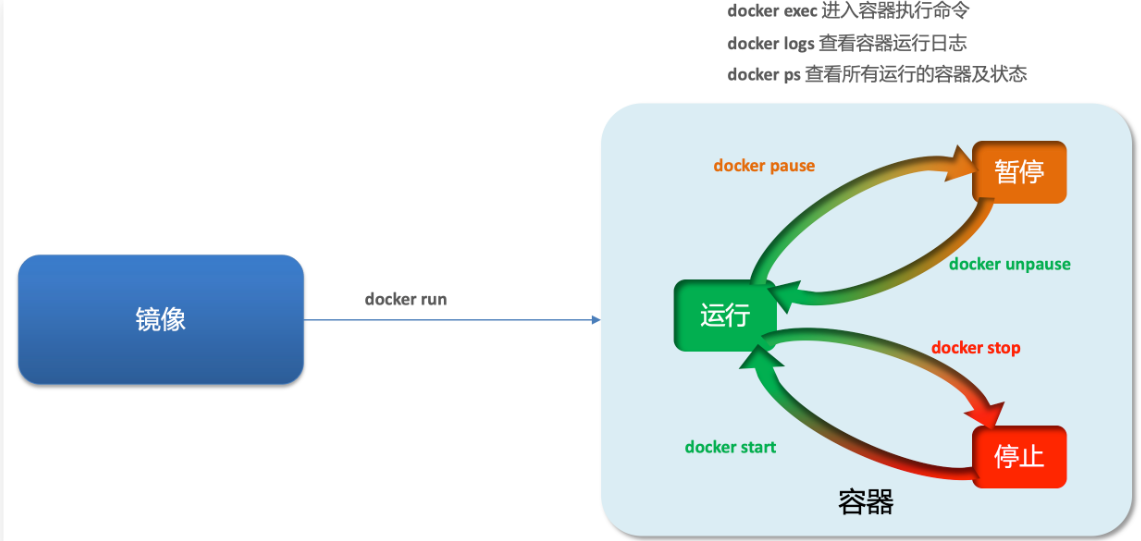
开发必备技术--docker(使用篇)
文章目录前言Docker的基本概念概念数据卷虚拟网络镜像操作镜像名称镜像命令容器操作基本操作容器创建数据卷操作创建和查看数据卷其他指令实战前言 续接上一篇博文: 开发必备技术–docker(一) 这也是开学了,假期的最后一篇博文&a…...
)
2023备战金三银四,Python自动化软件测试面试宝典合集(三)
马上就又到了程序员们躁动不安,蠢蠢欲动的季节~这不,金三银四已然到了家门口,元宵节一过后台就有不少人问我:现在外边大厂面试都问啥想去大厂又怕面试挂面试应该怎么准备测试开发前景如何面试,一个程序员成长之路永恒绕…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲…...

从零配置到生产就绪,Claude深度集成Angular CLI的7个关键步骤,错过再等一年
更多请点击: https://intelliparadigm.com 第一章:Claude Angular开发支持 Claude 系列大模型虽原生不直接嵌入 Angular 框架,但可通过 REST API 与 Angular 应用高效集成,实现智能提示、代码补全、组件生成等增强开发体验。关键…...

长期使用后观察Taotoken聚合路由在高并发下的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后观察Taotoken聚合路由在高并发下的稳定性 在构建和运营依赖大模型API的中大型项目时,服务的长期稳定性是技术…...

终极指南:使用dmg2img免费快速转换苹果DMG镜像文件
终极指南:使用dmg2img免费快速转换苹果DMG镜像文件 【免费下载链接】dmg2img DMG2IMG allows you to convert a (compressed) Apple Disk Images (imported from http://vu1tur.eu.org/dmg2img). Note: the master branch contains imported code, but lacks bugfix…...

Ubuntu 18.04下ISE 14.7与Vivado 2018.2的避坑安装与深度配置指南
1. 环境准备与依赖安装 在Ubuntu 18.04上安装ISE 14.7和Vivado 2018.2之前,系统环境配置是决定成败的关键。我遇到过不少开发者因为跳过这个步骤,导致后续安装过程频繁报错。这里分享几个必须检查的要点: 首先确认系统架构,虽然…...

Windows 10/11终极指南:如何快速解决PL2303驱动兼容性问题
Windows 10/11终极指南:如何快速解决PL2303驱动兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10/11系统上的PL2303串口设备无法…...

编写程序统计行业招聘薪资行情数据,智能比对企业薪资标准,优化薪资体系,减少企业人才流失问题。
一、实际应用场景描述在中型及以上企业的人力资源管理中,经常出现:- 企业需制定或调整岗位薪资标准(Salary Band)- 市场上同岗位薪资随城市、行业、经验年限波动明显- 企业内部薪资数据分散在 HR 系统 / Excel 中,缺乏…...

词达人自动化解决方案:从重复劳动到智能学习的效率革命
词达人自动化解决方案:从重复劳动到智能学习的效率革命 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 在数字化学习时代,词汇积累成为英语…...

React Native Actions Sheet源码解析:深入理解其架构与实现原理
React Native Actions Sheet源码解析:深入理解其架构与实现原理 【免费下载链接】react-native-actions-sheet A Cross Platform(Android, iOS & Web) ActionSheet with a flexible api, native performance for react native. Create anything you want inside…...

12-分布式系统测试-缓存-注册中心与链路追踪验证
分布式系统测试:缓存、注册中心与链路追踪验证上篇咱们搞定了消息队列测试,今天继续深入分布式系统的其他组件——Redis缓存、服务注册中心、分布式链路追踪。这些"基础设施"的测试往往被忽略,但出了问题定位起来最头疼。一、Redis…...