[缓存] - Redis
0.为什么要使用缓存?
用缓存,主要有两个用途:高性能、高并发。
1. 高性能
尽量使用短key
不要存过大的数据
避免使用keys *:使用SCAN,来代替
在存到Redis之前压缩数据
设置 key 有效期
选择回收策略(maxmemory-policy)
减少不必要的连接
限制redis的内存大小(防止swap,OOM)
slowLog
使用pipline批量操作数据
2. 高可用
2.1 单机版的高可用
数据持久化:AOF(WAL) & RDB
2.2 Replication-Sentinel模式
也就是哨兵模式。哨兵能对节点进行监控,提醒,自动故障迁移。
缺点:主从模式,切换需要时间,可能会丢数据,而且没有解决 master 写的压力;存储性能没办法横向扩展。
适用场景:缓存大小<10G时建议使用一主多从的哨兵模式。 从节点的数量,根据qps来扩展,比如10WQPS,可以有3-4个从节点(只能提高读操作的qps,写的qps不能扩展)。
架构图:
2.3 Redis-Cluster模式
redis在3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。
Gossip协议维护节点的元数据信息,进行节点间的信息同步。P2P去中心化的模式。最终一致性。
每个分区有一个master和若干slaver组成。
缺点:对于大型集群来说, 例如200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况下,每个节点仍然会产生 40Mb/s 的流量(gossip协议), 不建议使用官方的 Redis Cluster。
适用场景:如果系统的缓存大小<2000G, 主节点数<200个,建议使用Redis Cluster模式
2.4 Proxy模式
适用于主节点数量 > 200的情况下。有Codis Proxy和Twemproxy Proxy来年各种中间件模式。
数据分片算法:
(1)Codis 代理分片
(2)Twemproxy 代理分片
2.4.1 数据分片
(1)Range分片
常用在关系型数据库的设计。
比如:1到100个数字,要保存在3个节点上,按照顺序分区,把数据平均分配成三个片段
-
1号到33号数据为 片段1
-
34号到66号数据为 片段2
-
67号到100号数据为 片段3
(2)节点取余分片
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上。
缺点:
当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分片。
建议:
建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据。
(3)一致性哈希分区
步骤:构造一致性哈希环、节点映射、路由规则。
1)构造一致性哈希环
通过哈希算法,将哈希值映射到哈希空间([0, 2^32])。
2)节点映射
将集群中的各节点映射到环上的某个一位置。比如集群中有三个节点,那么可以大致均匀的将其分布在环上。
3)路由规则
路由规则包括存储(setX)和取值(getX)规则。
当需要存储一个对时,首先计算键key的hash值:hash(key),这个hash值必然对应于一致性hash环上的某个位置,然后沿着这个值按顺时针找到第一个节点,并将该键值对存储在该节点上。
缺点:数据倾斜,不能对所有节点进行负载均衡
(4)虚拟槽分区
为了在增删节点的时候,各节点能够保持动态的均衡,将每个真实节点虚拟出若干个虚拟节点,再将这些虚拟节点随机映射到环上。此时每个真实节点不再映射到环上,真实节点只是用来存储键值对,它负责接应各自的一组环上虚拟节点。当对键值对进行存取路由时,首先路由到虚拟节点上,再由虚拟节点找到真实的节点。增加虚拟节点其实是减小了路由规则过程中的粒度,使每个真实节点可以分摊局部压力。
(5)Redis分区
槽位,共16384个槽位。
所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16383。
3. 主从复制
哨兵模式和集群模式,都需要进行主从复制。
核心流程:
建立连接,数据同步,命令传播
4. 分布式缓存的常见问题
4.1 缓存击穿
定义:缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
解决方案:
- 若缓存的数据是基本不会发生更新的,则可尝试设置热点数据永远不过期;
- 采用多级缓存架构,热点数据,肯定数据量不大,可以使用 本地缓存;
- 若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到对应的缓存;
- 若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下可以加互斥锁,保障缓存中的数据,被第一次请求回填。此方案不适用于超高并发场景。
4.2 缓存穿透
定义:缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
解决方案:
1、**接口校验。**在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2、缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3、hashmap 记录存在性,存在去查redis,不存在直接返回。
4、布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
4.3 缓存雪崩
定义:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
解决方案:
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃;过期时间打散,热点数据不过期;
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
4.4 缓存一致性
binlog,程序(mq)
4.4.1 cache pattern
| No | 缓存不一致 | 优点 | 缺点 | 适用场景 |
| CacheAside | Y | 实现比较简单 | 需要维护两个数据存储,存在分布式事务问题 | 延时要低,能容忍数据丢失和数据不一致 |
| Read/Write Through | N | 使用简单 只需要关心缓存,数据写sh入数据库由框架完成,不需要处理分布式事务问题 | 延时高 | 同步操作,数据保证一致性 |
| Write Behind | Y | 延时低 | 数据丢失和数据不一致 | 延时要低,能容忍数据丢失和数据不一致 |
4.4.2 CacheAside数据不一致问题
(1)出现原因
(2)解决方案
为什么是删除缓存?
很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
1)更新数据库 + 删除缓存
2)删除缓存 + 更新数据库
3)删除缓存 + 更新数据库 + sleep + 删除缓存
4)更新数据库 + 删除缓存消息入mq/binlog消息入mq + 监听消息删除缓存
5)分布式事务解决机制
4.5 数据丢失
1.AOF异步刷盘
2.master和slave的数据同步是异步的
5. 数据预热 & 冷热分离
6.多级缓存
6.1 二级缓存
6.1.1 本地缓存
(1)延时要求极高
因为本地缓存的访问速度最快
(2)hotKey问题
hotkey分布式缓存不能通过横向扩展来解决
(3)带宽限制
数据分摊到不同的缓存节点,但这成本比本地缓存高很多
6.1.2 多级缓存的数据一致性
不能使用删除策略,因为本地缓存一般是热点数据,删除会导致缓存击穿。
6.2 三级缓存
L3级缓存的数据一致性保障以及防止缓存击穿方案:
1.数据预热(或者叫预加载)
2.设置热点数据永远不过期,通过 ngx.shared.DICT的缓存的LRU机制去淘汰
3.如果缓存主动更新,在快过期之前更新,如有变化,通过订阅变化的机制,主动本地刷新
4.提供兜底方案,如果本地缓存没有,则通过后端服务获取数据,然后缓存起来
7. 缓存选型
由于 redis 只使用单核,而 memcached 可以使用多核,所以平均每一个核上 redis 在存储小数据时比memcached 性能更高。而在 100k 以上的数据中,memcached 性能要高于 redis。虽然 redis 最近也在存储大数据的性能上进行优化,但是比起 memcached,还是稍有逊色。
8. 缓存过期
8.1 过期策略
TTL, LFU, LRU, Random
8.2 过期删除策略
- 定期删除:将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
- 惰性删除:所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除是集中处理,惰性删除是零散处理。
9. BigKey问题
9.1 定义
Big Key就是某个key对应的value很大,占用的redis空间很大,本质上是大value问题。
9.2 产生原因
- 1. redis数据结构使用不恰当
- 2. 未及时清理垃圾数据
- 3. 对业务预估不准确
- 4. 热点数据列表
9.3 危害
1、阻塞请求、
2、内存增大
3、阻塞网络
4、影响主从同步、主从切换
9.4 bigKey识别
9.5 解决方案
1、对大Key进行拆分
2、对大Key进行清理
3、监控Redis的内存、网络带宽、超时等指标
4、定期清理失效数据
5、压缩value
相关文章:

[缓存] - Redis
0.为什么要使用缓存? 用缓存,主要有两个用途:高性能、高并发。 1. 高性能 尽量使用短key 不要存过大的数据 避免使用keys *:使用SCAN,来代替 在存到Redis之前压缩数据 设置 key 有效期 选择回收策略(maxmemory-policy) 减…...
spring boot和spring cloud项目中配置文件application和bootstrap加载顺序
在前面的文章基础上 https://blog.csdn.net/zlpzlpzyd/article/details/136060312 日志配置 logback-spring.xml <?xml version"1.0" encoding"UTF-8"?> <configuration scan"true" scanPeriod"10000000 seconds" debug…...

AdaBoost算法
Boosting是一种集成学习方法,AdaBoost是Boosting算法中的一种具体实现。 Boosting方法的核心思想在于将多个弱分类器组合成一个强分类器。这些弱分类器通常是简单的模型,比如决策树,它们在训练过程中的错误会被后续的弱分类器所修正。Boosti…...

基于 elasticsearch v8 的 CRUD 操作及测试用例
基于 elasticsearch v8 的 CRUD 操作及测试用例 https://github.com/chenshijian73-qq/go-es/tree/main...

深度学习的新进展:解析技术演进与应用前景
深度学习的新进展:解析技术演进与应用前景 深度学习,作为人工智能领域的一颗璀璨明珠,一直以来都在不断刷新我们对技术和未来的认知。随着时间的推移,深度学习不断迎来新的进展,这不仅推动了技术的演进,也…...

【第二届 Runway短视频创作大赛】——截至日期2024年03月01日
短视频创作大赛 关于AI Film Festival竞赛概况参加资格报名期间报名方法 提交要求奖品附录 关于AI Film Festival 2022年成立的AIFF是一个融合了最新AI技术于电影制作中的艺术和艺术家节日,让我们得以一窥新创意时代的风采。从众多参赛作品中…...

UniApp 快速上手与深度学习指南
一、UniApp 简介 UniApp 是中国DCloud公司研发的一款创新的跨平台应用开发框架,它基于广受欢迎的前端开发库Vue.js,旨在解决多端适配和快速开发的问题。通过UniApp,开发者能够采用一套统一的代码结构、语法和API来构建应用程序,从而实现真正意义上的“一次编写,到处运行”…...
10个简单有效的编辑PDF文件工具分享
10个编辑PDF文件工具作为作家、编辑或专业人士,您可能经常发现自己在处理 PDF 文件。无论您是审阅文档、创建报告还是与他人共享工作,拥有一个可靠的 PDF 编辑器供您使用都非常重要。 10个简单适用的编辑PDF文件工具 在本文中,我们将介绍当今…...
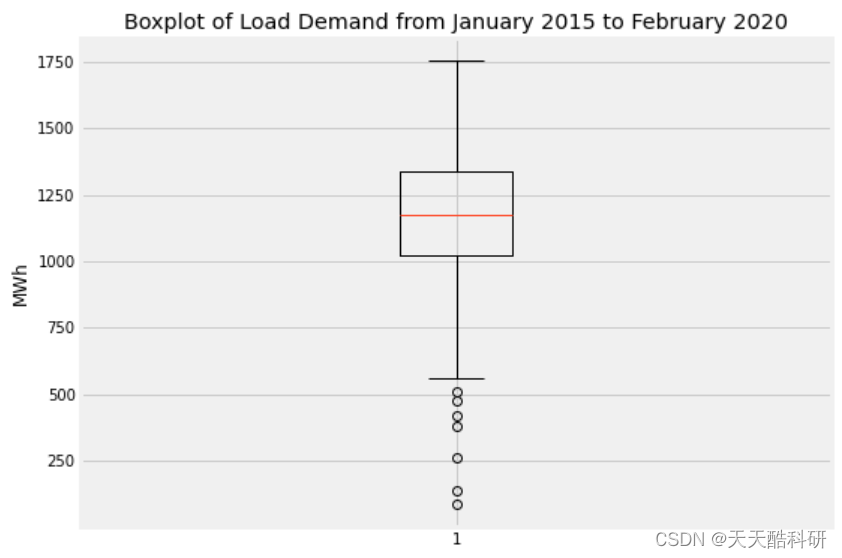
电力负荷预测 | 基于GRU门控循环单元的深度学习电力负荷预测,含预测未来(Python)
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 电力负荷预测 | 基于GRU门控循环单元的深度学习电力负荷预测,含预测未来(Python&...

vue 实现 手机号中间4位分格输入框(暂无选中标识
vue 实现 手机号中间4位分格输入框 效果图 <!--4位分格输入框--> <!--<template><div><div style"display: flex;"><div class"phone-input"><inputv-for"(digit, index) in digits":key"index"…...
#免费 苹果M系芯片Macbook电脑MacOS使用Bash脚本写入(读写)NTFS硬盘教程
Mac电脑苹果芯片读写NTFS硬盘bash脚本 (ntfs.sh脚本内容在本文最后面) ntfs.sh脚本可以将Mac系统(苹果M系芯片)上的NTFS硬盘改成可读写的挂载方式,从而可以直接往NTFS硬盘写入数据。此脚本免费,使用过程中无需下载任何收费软件。…...
PPT录屏功能在哪?一键快速找到它!
在现代办公环境中,ppt的录屏功能日益受到关注,它不仅能帮助我们记录演示文稿的播放过程,还能将操作过程、游戏等内容完美录制下来。可是很多人不知道ppt录屏功能在哪,本文将为您介绍ppt录屏的打开方法,以帮助读者更好地…...

Linux下的多线程
前面学习了进程、文件等概念,接下里为大家引入线程的概念 多线程 线程是什么?为什么要有线程?线程的优缺点Linux线程操作线程创建线程等待线程终止线程分离 线程间的私有和共享数据理解线程库和线程id深刻理解Linux多线程(重点&a…...

Nginx+React在Docker中实现项目部署
一、引言 Nginx 是一个高性能的 HTTP 和反向代理服务器,也能够处理 IMAP/POP3/SMTP 服务,由 Igor Sysoev 开发并在 2004 年首次公开发布。它以处理静态内容、提供反向代理服务以及其高稳定性、低资源消耗而广受欢迎。Nginx 能够通过非阻塞方式处理多个连…...

Centos 7.5 安装 NVM 详细步骤
NVM(Node Version Manager)是一个用于管理Node.js版本的工具,它可以让你轻松地在多个版本之间切换。NVM 通过下载和管理 Node.js 的多个版本,为用户提供了一种灵活的方式来使用不同版本的 Node.js。如果你需要更多关于NVM的信息&a…...

【python】绘制春节烟花
一、Pygame库春节烟花示例 下面是一个使用Pygame实现的简单春节烟花效果的示例代码。请注意,运行下面的代码之前,请确保计算机上已经安装了Pygame库。 import pygame import random import math from pygame.locals import *# 初始化pygame pygame.ini…...

ChatPromptTemplate和AI Message的用法
ChatPromptTemplate的用法 用法1: from langchain.chains import LLMChain from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_community.tools.tavily_search import TavilySear…...
-在AWS上尝试Terraform的Vault Provider)
Terraform实战(三)-在AWS上尝试Terraform的Vault Provider
使用自Terraform 0.8起添加的Vault Provider后,aws云基础设施尝试从Vault而不是tfvars或环境变量中读取AWS凭证。 1 什么是vault? vault是一种由Hashicorp发布的用于管理机密信息的工具。 2 aws使用Terraform的Vault Provider 2.1 创建静态密钥 以开…...

【Nicn的刷题日常】之有序序列合并
1.题目描述 描述 输入两个升序排列的序列,将两个序列合并为一个有序序列并输出。 数据范围: 1≤�,�≤1000 1≤n,m≤1000 , 序列中的值满足 0≤���≤30000 0≤val≤30000 输入描述…...
PostgreSql与Postgis安装
POstgresql安装 1.登录官网 PostgreSQL: Linux downloads (Red Hat family) 2.选择版本 3.安装 ### 源 yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm ### 客户端 yum install postgresql14 ###…...
)
避开这些坑!Sigma-Delta调制器设计中最容易忽略的5个稳定性问题(附MASH级联实测数据)
避开这些坑!Sigma-Delta调制器设计中最容易忽略的5个稳定性问题(附MASH级联实测数据) 在高速高精度ADC设计中,Sigma-Delta调制器因其优异的噪声整形特性成为首选方案。但当工程师们沉浸在理论计算的理想世界时,实验室示…...

Sqoop性能调优之 --fetch-size:小参数,大作用
Sqoop性能调优之 --fetch-size:小参数,大作用1. 引言:被忽视的"隐形冠军"2. 什么是 --fetch-size?2.1 基本定义2.2 核心作用3. 底层原理:从逐行到批量3.1 没有 --fetch-size 的情况(逐行读取&…...

2026Agent元年!手把手教你从0到1搭建高能智能体,小白也能秒变大神!
逼自己练完这些,你的Agent搭建就很牛了!!2026年可谓是Agent元年,智能体(AI Agent)正以惊人的速度重塑我们的工作方式,从简单的被动响应工具,进化为能自主规划、执行、协作的"数…...
,实现传统文化里的 “时间轮回”)
【数据结构实战】循环队列FIFO 特性生成六十甲子(天干地支纪年法),实现传统文化里的 “时间轮回”
前言天干地支纪年法是中国传统文化的重要组成部分,十天干与十二地支依次相配,组成六十甲子。本文将使用循环队列这一数据结构完成六十甲子的生成,严格遵循题目要求:定义两个循环队列,分别存储十天干、十二地支队列空则…...

LeagueAkari:基于LCU API的英雄联盟自动化工具集架构设计与实战应用
LeagueAkari:基于LCU API的英雄联盟自动化工具集架构设计与实战应用 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit L…...

[2026 职场洗牌系列 01] 程序员正在“杀死”自己的工作?科技行业高危预警
长久以来,学计算机(CS)在很多年轻人眼里就等同于拿到了通往高薪和阶层跃升的金钥匙。大家都觉得,只要把代码敲得溜,这辈子在职场上基本就稳了。可惜,到了2026年的今天,生成式AI正在毫不留情地把…...
)
Linux Ubuntu 24.04 Server 超简单部署 Fast GPT(新手零踩坑)
前言: Fast GPT 是一款基于大语言模型的知识型平台,支持数据处理、RAG检索、可视化AI工作流编排,能快速搭建专属问答系统,无需复杂开发配置。本文针对 Ubuntu 24.04 Server 系统,用最简洁的步骤完成部署,全…...

石家庄整家定制口碑供应商
在石家庄,寻找一家值得信赖的整家定制服务商,是许多家庭在装修时的重要考量。一个优秀的定制品牌,不仅能为居者提供个性化的空间解决方案,更能将美学、功能与品质融为一体,让日常居住成为一种享受。关于我们位于石家庄…...

蒙纳什大学发现多模态推理模型的“不确定性陷阱“
这项由蒙纳什大学、佐治亚理工学院、康奈尔大学等多所知名学府联合完成的研究发表于2026年3月的《计算机视觉与模式识别》会议,论文编号为arXiv:2603.13366v1。有兴趣深入了解的读者可以通过该编号查询完整论文。当你问一个AI"这张图片里有什么"时&#x…...

效率直接起飞!盘点2026年全民喜爱的的AI论文写作工具
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂的AI论文写作工具,实测提速效果惊人,覆盖选题、文献、写作、降重、排版全流程,让你高效搞定论文不再难。 一、全流程王者:一站式搞定论文全链路(一天定稿首选&…...