AdaBoost算法
Boosting是一种集成学习方法,AdaBoost是Boosting算法中的一种具体实现。
Boosting方法的核心思想在于将多个弱分类器组合成一个强分类器。这些弱分类器通常是简单的模型,比如决策树,它们在训练过程中的错误会被后续的弱分类器所修正。Boosting算法通过逐步增加新的弱分类器来提高整体模型的性能,每个新的弱分类器都专注于之前模型分类错误的样本。
AdaBoost(Adaptive Boosting)是Boosting算法家族中的一员,它的特点是使用了指数损失函数(exponential loss function),这种损失函数会给分类错误的样本赋予更大的权重,使得后续的弱分类器更加关注这些难以分类的样本。通过这种方式,AdaBoost能够自适应地调整每个样本的权重,从而提高模型的整体性能。除了AdaBoost,还有其他基于不同损失函数的Boosting算法,如L2Boosting和LogitBoost等。这些算法虽然在具体的实现细节上有所不同,但都遵循了Boosting方法将弱分类器组合成强分类器的基本框架。
Boosting每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
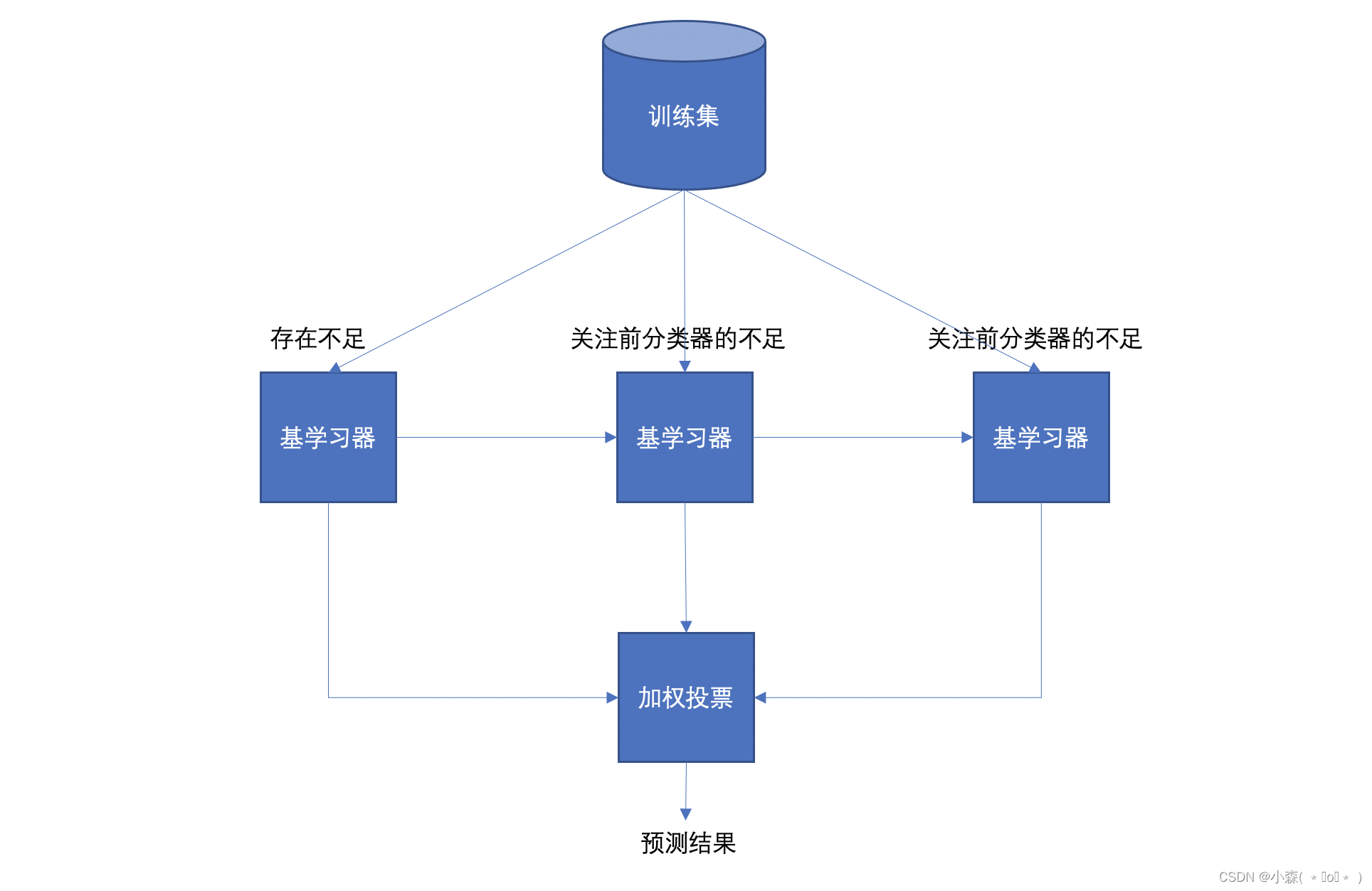
Bagging 和 Boosting
Bagging 通过均匀取样的方式从原始样本集中抽取训练集,而 Boosting 使用全部样本,并在每一轮训练中根据错误率调整样例权重。这意味着 Bagging 的训练过程可以并行进行,因为它的基模型之间是独立的,而 Boosting 通常是串行进行的,因为每个模型都依赖于前一个模型的表现。
Bagging 方法中每个基模型对于最终决策的贡献是相等的,类似于民主投票制,每个模型有一票;而在 Boosting 中,每个基模型的贡献是根据其性能加权的,性能更好的模型会有更大的影响力。
AdaBoost
AdaBoost算法的核心步骤是:
-
权重更新:在每一轮迭代中,根据样本的分类结果来更新每个样本的权重。如果一个样本被正确分类,那么它的权重将会降低;如果一个样本被错误分类,那么它的权重将会增加。这样可以使得在后续的迭代中,分类器更加关注那些难以分类的样本。
-
弱分类器的选择:在每一轮迭代中,从所有的弱分类器中选择一个最佳的弱分类器。这个最佳的弱分类器是指在当前权重分布下,分类误差最小的那个弱分类器。
-
分类误差率较小的弱分类器的权值大,在表决中起较大作用。
AdaBoost 模型公式
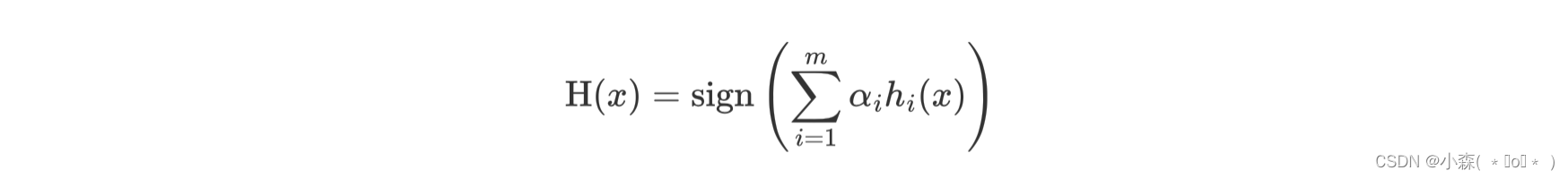
- α 为模型的权重,m 为弱学习器数量。
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost 构建过程
| Sample | Feature (x) | Label (y) |
|---|---|---|
| 1 | 1 | -1 |
| 2 | 2 | -1 |
| 3 | 3 | 1 |
| 4 | 4 | 1 |
初始化
D1(1)=D1(2)=D1(3)=D1(4)=1/4
第1轮迭代
- 训练一个弱分类器 ℎ1(x),例如 h_1(x) = \sign(x - 1.5)。
- 计算错误率 ϵ1,假设所有样本都被正确分类,则 ϵ1=0。
- 计算权重α1,由于epsilon1=0,则α1=infty。但通常我们会设置一个上限,比如α1=0.5。
- 更新样本权重,由于所有样本都被正确分类,权重保持不变。
第2轮迭代
- 训练另一个弱分类器 ℎ2(x),例如 h_2(x) = \sign(x - 3)。
- 计算错误率 ϵ2,假设样本1和2被正确分类,样本3和4被错误分类,则ϵ2=21。
- 计算权重α2,α2=21ln(212)=21ln(4)≈0.693。
- 更新样本权重,增加样本3和4的权重,减少样本1和2的权重。
最终分类器
- 组合弱分类器的预测结果,形成最终的强分类器H(x)。
这个过程会根据迭代次数M 重复进行,直到达到预定的迭代次数或者满足某个停止条件(如错误率达到某个阈值)。
Demo实战
import pandas as pd
df_wine = pd.read_csv('wine.data')df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']df_wine = df_wine[df_wine['Class label'] != 1]X = df_wine[['Alcohol', 'Hue']]
y = df_wine['Class label']划分训练集测试集
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_splitle = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifiertree = DecisionTreeClassifier(criterion='entropy',max_depth=1)
ada= AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1)from sklearn.metrics import accuracy_scoretree = tree.fit(X_train,y_train)
y_train_pre = tree.predict(X_train)
y_test_pre = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pre)
tree_test = accuracy_score(y_test,y_test_pre)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# 0.845/0.854ada = ada.fit(X_train,y_train)
y_train_pre = ada.predict(X_train)
y_test_pre = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pre)
ada_test = accuracy_score(y_test,y_test_pre)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# 1/0.875AdaBosst的决策区域比单层的决策区域更加复杂。
集成学习与单独的分类器性能比较,集成学习提高了复杂度,但在实践中,需要衡量是否愿意为适度提高预测性能付出更多的计算成本。
AdaBoost算法的总结
AdaBoost的核心思想是通过对错误分类的样本增加权重,使得后续的弱分类器更加关注这些难以分类的样本。通过加权投票的方式,将多个弱分类器的预测结果组合起来,形成一个强分类器。
- 初始化:为每个训练样本分配相同的权重。
- 迭代训练弱分类器:对于每一轮迭代,训练一个弱分类器,使其在加权训练集上的错误率最小化。
- 计算弱分类器权重:根据弱分类器在加权训练集上的错误率,计算其权重。错误率越低,权重越高。
- 更新样本权重:根据弱分类器的表现,更新样本权重。被错误分类的样本权重增加,正确分类的样本权重减少。
- 构建最终分类器:将所有弱分类器的预测结果按照其权重进行加权求和,形成最终的强分类器。

应用领域
AdaBoost算法广泛应用于各种机器学习任务,包括图像识别、文本分类、医学诊断等领域。
优点
- 提高模型的性能:AdaBoost可以显著提高弱分类器的性能,使其成为一个强大的分类器。
- 鲁棒性:AdaBoost对于过拟合具有很好的鲁棒性。
- 灵活性:可以与各种类型的弱分类器结合使用。
缺点
- 对噪声敏感:如果训练数据包含噪声,AdaBoost可能会给噪声样本分配较高的权重,从而影响模型的性能。
- 长时间训练:对于大规模数据集,AdaBoost的训练时间可能会很长。
相关文章:
AdaBoost算法
Boosting是一种集成学习方法,AdaBoost是Boosting算法中的一种具体实现。 Boosting方法的核心思想在于将多个弱分类器组合成一个强分类器。这些弱分类器通常是简单的模型,比如决策树,它们在训练过程中的错误会被后续的弱分类器所修正。Boosti…...

基于 elasticsearch v8 的 CRUD 操作及测试用例
基于 elasticsearch v8 的 CRUD 操作及测试用例 https://github.com/chenshijian73-qq/go-es/tree/main...

深度学习的新进展:解析技术演进与应用前景
深度学习的新进展:解析技术演进与应用前景 深度学习,作为人工智能领域的一颗璀璨明珠,一直以来都在不断刷新我们对技术和未来的认知。随着时间的推移,深度学习不断迎来新的进展,这不仅推动了技术的演进,也…...

【第二届 Runway短视频创作大赛】——截至日期2024年03月01日
短视频创作大赛 关于AI Film Festival竞赛概况参加资格报名期间报名方法 提交要求奖品附录 关于AI Film Festival 2022年成立的AIFF是一个融合了最新AI技术于电影制作中的艺术和艺术家节日,让我们得以一窥新创意时代的风采。从众多参赛作品中…...

UniApp 快速上手与深度学习指南
一、UniApp 简介 UniApp 是中国DCloud公司研发的一款创新的跨平台应用开发框架,它基于广受欢迎的前端开发库Vue.js,旨在解决多端适配和快速开发的问题。通过UniApp,开发者能够采用一套统一的代码结构、语法和API来构建应用程序,从而实现真正意义上的“一次编写,到处运行”…...
10个简单有效的编辑PDF文件工具分享
10个编辑PDF文件工具作为作家、编辑或专业人士,您可能经常发现自己在处理 PDF 文件。无论您是审阅文档、创建报告还是与他人共享工作,拥有一个可靠的 PDF 编辑器供您使用都非常重要。 10个简单适用的编辑PDF文件工具 在本文中,我们将介绍当今…...
电力负荷预测 | 基于GRU门控循环单元的深度学习电力负荷预测,含预测未来(Python)
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 电力负荷预测 | 基于GRU门控循环单元的深度学习电力负荷预测,含预测未来(Python&...

vue 实现 手机号中间4位分格输入框(暂无选中标识
vue 实现 手机号中间4位分格输入框 效果图 <!--4位分格输入框--> <!--<template><div><div style"display: flex;"><div class"phone-input"><inputv-for"(digit, index) in digits":key"index"…...
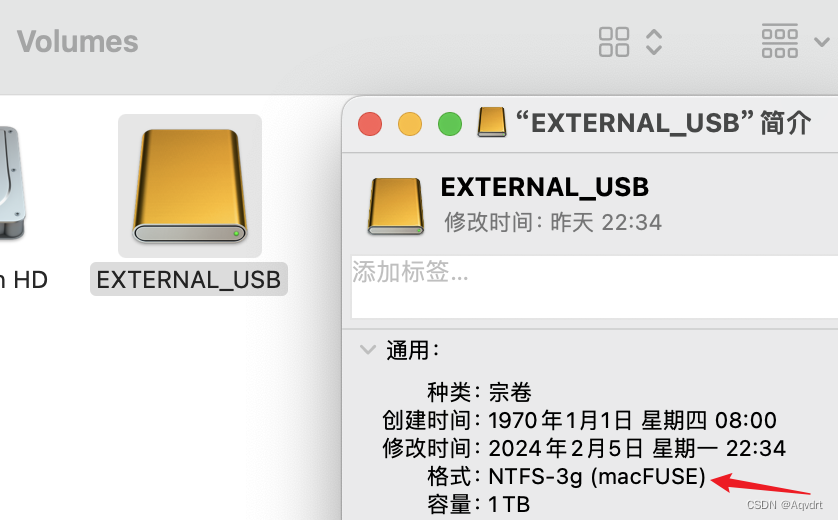
#免费 苹果M系芯片Macbook电脑MacOS使用Bash脚本写入(读写)NTFS硬盘教程
Mac电脑苹果芯片读写NTFS硬盘bash脚本 (ntfs.sh脚本内容在本文最后面) ntfs.sh脚本可以将Mac系统(苹果M系芯片)上的NTFS硬盘改成可读写的挂载方式,从而可以直接往NTFS硬盘写入数据。此脚本免费,使用过程中无需下载任何收费软件。…...
PPT录屏功能在哪?一键快速找到它!
在现代办公环境中,ppt的录屏功能日益受到关注,它不仅能帮助我们记录演示文稿的播放过程,还能将操作过程、游戏等内容完美录制下来。可是很多人不知道ppt录屏功能在哪,本文将为您介绍ppt录屏的打开方法,以帮助读者更好地…...

Linux下的多线程
前面学习了进程、文件等概念,接下里为大家引入线程的概念 多线程 线程是什么?为什么要有线程?线程的优缺点Linux线程操作线程创建线程等待线程终止线程分离 线程间的私有和共享数据理解线程库和线程id深刻理解Linux多线程(重点&a…...

Nginx+React在Docker中实现项目部署
一、引言 Nginx 是一个高性能的 HTTP 和反向代理服务器,也能够处理 IMAP/POP3/SMTP 服务,由 Igor Sysoev 开发并在 2004 年首次公开发布。它以处理静态内容、提供反向代理服务以及其高稳定性、低资源消耗而广受欢迎。Nginx 能够通过非阻塞方式处理多个连…...

Centos 7.5 安装 NVM 详细步骤
NVM(Node Version Manager)是一个用于管理Node.js版本的工具,它可以让你轻松地在多个版本之间切换。NVM 通过下载和管理 Node.js 的多个版本,为用户提供了一种灵活的方式来使用不同版本的 Node.js。如果你需要更多关于NVM的信息&a…...

【python】绘制春节烟花
一、Pygame库春节烟花示例 下面是一个使用Pygame实现的简单春节烟花效果的示例代码。请注意,运行下面的代码之前,请确保计算机上已经安装了Pygame库。 import pygame import random import math from pygame.locals import *# 初始化pygame pygame.ini…...

ChatPromptTemplate和AI Message的用法
ChatPromptTemplate的用法 用法1: from langchain.chains import LLMChain from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_community.tools.tavily_search import TavilySear…...
-在AWS上尝试Terraform的Vault Provider)
Terraform实战(三)-在AWS上尝试Terraform的Vault Provider
使用自Terraform 0.8起添加的Vault Provider后,aws云基础设施尝试从Vault而不是tfvars或环境变量中读取AWS凭证。 1 什么是vault? vault是一种由Hashicorp发布的用于管理机密信息的工具。 2 aws使用Terraform的Vault Provider 2.1 创建静态密钥 以开…...

【Nicn的刷题日常】之有序序列合并
1.题目描述 描述 输入两个升序排列的序列,将两个序列合并为一个有序序列并输出。 数据范围: 1≤�,�≤1000 1≤n,m≤1000 , 序列中的值满足 0≤���≤30000 0≤val≤30000 输入描述…...
PostgreSql与Postgis安装
POstgresql安装 1.登录官网 PostgreSQL: Linux downloads (Red Hat family) 2.选择版本 3.安装 ### 源 yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm ### 客户端 yum install postgresql14 ###…...
----Redis流 Streams)
【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams
【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams 一、追加Appending二、消费Consuming2.1 同步接收Synchronous reception2.2 通过消息监听器容器进行异步接收Asynchronous reception through Message Listener Containers2.2.1 命令式I…...

MySQL:从基础到实践(简单操作实例)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 下载前言一、MySQL是什么?二、使用步骤1.引入库2.读入数据 提交事务查询数据获取查询结果总结 下载 点击下载提取码888999 前言 在现代信息技术的世界…...

Cherry Studio集成火山方舟模型实战:从接入到性能调优全解析
最近在项目中尝试将火山方舟的模型集成到 Cherry Studio 里,整个过程踩了不少坑,也总结了一些经验。今天就来和大家分享一下从接入到性能调优的完整实战过程,希望能帮到有同样需求的开发者。 1. 背景与痛点:为什么集成过程让人头疼…...

OpenClaw定时任务配置:GLM-4.7-Flash实现凌晨自动备份与报告
OpenClaw定时任务配置:GLM-4.7-Flash实现凌晨自动备份与报告 1. 为什么需要夜间自动化 作为独立开发者,我经常面临一个矛盾:白天需要专注写代码,但服务器日志分析、数据库备份、日报生成这些琐事又不得不做。直到发现OpenClaw的…...
带运行效果操作讲解视频和设计...)
电镀生产线组态王6.55和三菱PLC联机仿真程序10(OPC通讯)带运行效果操作讲解视频和设计...
电镀生产线组态王6.55和三菱PLC联机仿真程序10(OPC通讯)带运行效果操作讲解视频和设计要求io表接线图主电路CAD曲线报表报警界面作为一名高级程序员兼IT知识写手,我将按照您的要求创作一篇关于电镀生产线组态王6.55和三菱PLC联机仿真程序10&a…...

AC6966B开发板开发准备-环境搭建:Windows下JL杰理AC696N开发环境配置
引言做蓝牙音频、音箱或IoT产品的开发,最怕的不是写代码,而是环境配半天跑不起来。JL杰理AC696N这颗芯片在耳机、音箱方案里很常见,性价比高,外设也全,但第一次接触杰理方案时,环境配置往往要先踩几个坑。尤…...

flac3d台阶法开挖命令流,5.0版本,计算结果有效合理,支护方式为初衬单元与锚杆联合支护...
flac3d台阶法开挖命令流,5.0版本,计算结果有效合理,支护方式为初衬单元与锚杆联合支护,初衬采用shell单元,锚杆为cable单元,可为相关计算提供参考 直接开整吧!最近在搞隧道台阶法开挖模拟&#…...
- 页面滚动操作)
Web自动化测试(05)- 页面滚动操作
页面滚动操作1 使用JavaScript滚动1.1 垂直滚动(1)滚动到页面顶部# 滚动到页面顶部driver.execute_script("window.scrollTo(0, 0);")(2)滚动到页面底部# 滚动到页面底部driver.execute_script("window.scrollTo(0…...

百川2-13B模型效果展示:代码生成与解释能力实测
百川2-13B模型效果展示:代码生成与解释能力实测 最近在开发者圈子里,关于AI编程助手的讨论越来越热。大家不再只关心模型参数有多大,而是更看重它实际干活的能力:我描述一个需求,它能写出能跑的代码吗?我贴…...
)
L298N电机驱动模块避坑指南:从选型到实战(附Arduino代码)
L298N电机驱动模块避坑指南:从选型到实战(附Arduino代码) 当你第一次拿到L298N模块时,可能会被它简单的蓝色PCB板迷惑——这个看似普通的模块,实际上藏着不少"坑"。作为创客项目中最常用的电机驱动方案之一&…...

突破性数据增强:如何用Time-Series-Library解决时间序列稀疏性难题
突破性数据增强:如何用Time-Series-Library解决时间序列稀疏性难题 【免费下载链接】Time-Series-Library A Library for Advanced Deep Time Series Models. 项目地址: https://gitcode.com/GitHub_Trending/ti/Time-Series-Library 在时间序列分析领域&…...

深度解析:7大深度学习模型构建PyTorch文本分类框架
深度解析:7大深度学习模型构建PyTorch文本分类框架 【免费下载链接】Text-Classification-Pytorch Text classification using deep learning models in Pytorch 项目地址: https://gitcode.com/gh_mirrors/te/Text-Classification-Pytorch 文本分类作为自然…...