神经网络 | 基于 CNN 模型实现土壤湿度预测
Hi,大家好,我是半亩花海。在现代农业和环境监测中,了解土壤湿度的变化对于作物生长和水资源管理至关重要。通过深度学习技术,特别是卷积神经网络,我们可以利用过去的土壤湿度数据来预测未来的湿度趋势。本文将使用 PaddlePaddle 作为深度学习框架,通过数据分析、可视化、数据预处理、模型组网、模型训练和模型预测,基于卷积神经网络(CNN)模型来来处理时间序列数据,完成 10cm 土壤湿度的预测,从而实现一个简单的回归模型。
目录
一、导入必要库
二、数据分析
三、数据预处理
四、模型组网
五、模型训练
六、模型预测
一、导入必要库
import time
import warnings
import numpy as np
import paddle
import paddle.nn as nn
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScalerwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来设置字体样式(黑体)以正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
二、数据分析
# 读取数据
soil_humidity = pd.read_excel("./soil_humidity.xlsx", engine="openpyxl")
# print(soil_humidity.head())# 构建Datetime字段
soil_humidity["Datetime"] = pd.to_datetime(soil_humidity["datetime"])
soil_humidity.drop(["datetime"], axis=1, inplace=True)# 按照时间顺序排序
soil_humidity.index = soil_humidity.Datetime
soil_humidity.drop(["Datetime"], axis=1, inplace=True)
soil_humidity = soil_humidity.sort_index()
print(soil_humidity.head())
# print(soil_humidity.describe()) # 查看数据统计学描述
# print(soil_humidity.dtypes) # 查看数据类型# 可视化数据分布
sns.set(font='SimHei') # 设置Seaborn字体
plt.figure(figsize=(8, 5))
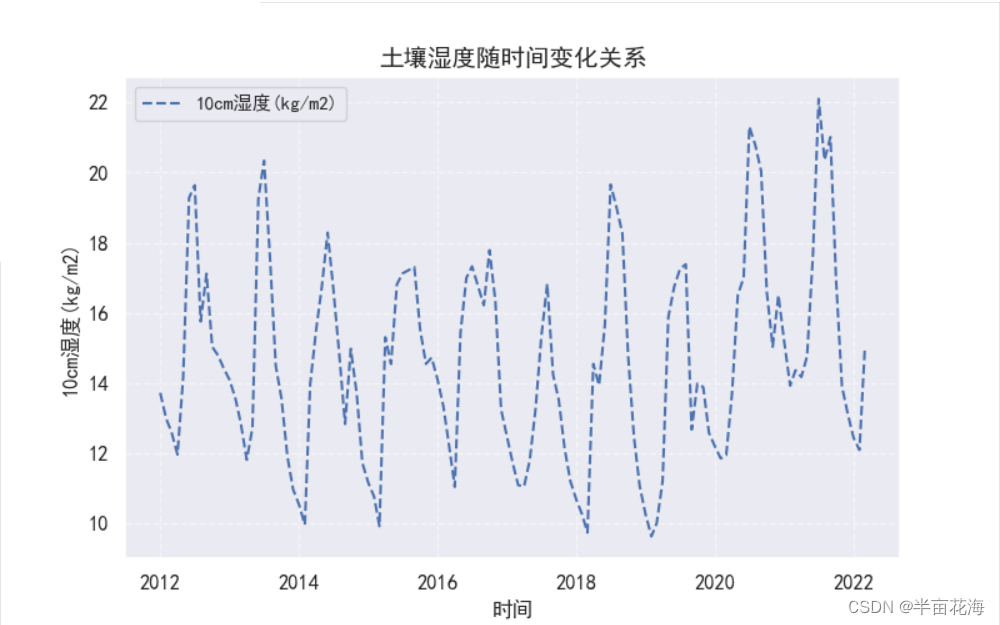
plt.plot(soil_humidity.index, soil_humidity["10cm湿度(kg/m2)"], "b--", label='10cm湿度(kg/m2)')
plt.title("土壤湿度随时间变化关系", fontsize=14)
plt.xlabel("时间", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.yticks(fontsize=12)
plt.xticks(fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5) # 添加网格显示(开启网格,虚线,透明度0.5)
plt.show()# 筛选所需要的字段
soil_humidity_10cm = soil_humidity.loc[soil_humidity.index[:], ['10cm湿度(kg/m2)']]
print(soil_humidity_10cm)# 绘制热力图,表示数据框中各列之间的相关性
sns.set(font='SimHei') # 设置Seaborn字体
corr = soil_humidity.corr() # 计算数据框中各列之间的相关性
plt.figure(figsize=(12, 8), dpi=100)
plt.title("数据框中各列之间的相关性", fontsize=13)
heatmap = sns.heatmap(corr, square=True, linewidths=0.2, annot=True, annot_kws={'size': 9})
heatmap.set_xticklabels(heatmap.get_xticklabels(), rotation=35, horizontalalignment='right') # 设置y轴标签向左旋转45度
# 设置x轴和y轴标签字体大小
heatmap.tick_params(axis='x', labelsize=8.5)
heatmap.tick_params(axis='y', labelsize=9)
# 调整热力范围字体大小
cbar = heatmap.collections[0].colorbar
cbar.ax.tick_params(labelsize=9)
plt.show()
soil_humidity.head() 输出结果:
10cm湿度(kg/m2) 40cm湿度(kg/m2) ... 最大单日降水量(mm) 降水天数
Datetime ...
2012-01-01 13.73 30.87 ... 0.51 5
2012-02-01 13.00 30.87 ... 0.76 5
2012-03-01 12.60 30.87 ... 4.83 13
2012-04-01 11.97 30.73 ... 5.33 3
2012-05-01 14.18 29.99 ... 15.49 10[5 rows x 14 columns]

三、数据预处理
# 划分数据集
all_data = soil_humidity_10cm.values
split_fraction = 0.8 # 设置80%为训练集
train_split = int(split_fraction * int(soil_humidity_10cm.shape[0])) # 获取数据集的行数,转换为整数,计算切分的训练集大小
train_data = all_data[:train_split, :] # 从all_data中取前train_split行作为训练集
test_data = all_data[train_split:, :] # 从all_data中取剩余的部分作为测试集# 数据集可视化
plt.figure(figsize=(8, 5))
plt.plot(np.arange(train_data.shape[0]), train_data[:, 0], label='train data')
plt.plot(np.arange(train_data.shape[0], train_data.shape[0] + test_data.shape[0]), test_data[:, 0], label='test data')
plt.title("数据集可视化", fontsize=14)
plt.xlabel("时间", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.legend()
plt.show()# 归一化
scaler = MinMaxScaler(feature_range=(-1, 1)) # 归一化处理,将数据缩放到[-1, 1]之间
train_scal = scaler.fit_transform(train_data.reshape(-1, 1))
test_scal = scaler.fit_transform(test_data.reshape(-1, 1))# 划分卷积窗口与标签值
window_size = 12
train_scal = train_scal.reshape(-1)
train_scal = paddle.to_tensor(train_scal, dtype='float32') # 转换成 tensor# 定义数据输入函数,用于接受序列数据和窗口大小这俩个参数,用于CNN训练
def input_data(seq, ws):out = []L = len(seq)for i in range(L - ws):window = seq[i:i + ws]label = seq[i + ws:i + ws + 1]out.append((window, label))return out # 返回生成的训练样本列表train_scal_data = input_data(train_scal, window_size) # 归一化后的训练集数据,定义的窗口大小
# 打印一组数据集
print(train_scal_data[0])
train_scal_data[0] 这一组数据集的打印结果:
10cm湿度(kg/m2)
Datetime
2012-01-01 13.73
2012-02-01 13.00
2012-03-01 12.60
2012-04-01 11.97
2012-05-01 14.18
... ...
2021-11-01 13.91
2021-12-01 13.14
2022-01-01 12.45
2022-02-01 12.10
2022-03-01 14.96[123 rows x 1 columns]

四、模型组网
一维卷积层(convolution1d layer),根据输入、卷积核、步长(stride)、填充(padding)、空洞大小(dilations)一组参数计算输出特征层大小。
网络构造大体如下:
- 先经过一维卷积层 Conv1D
- 使用 ReLU 激活函数对其进行激活
- 然后经过第1层线性层 Linear1
- 再经过第2层线性层 Linear2
class CNNnetwork(paddle.nn.Layer):def __init__(self):super().__init__() # 调用父类函数self.conv1d = paddle.nn.Conv1D(1, 1, kernel_size=2) # 一维卷积层Conv1D(输入, 输出, 卷积核大小)self.relu = paddle.nn.ReLU() # 激活函数, 引入非线性性# 定义了线性层, 将输入维度为a的特征映射到输出维度为b的空间# 这是一个回归任务, 模型的输出是一个实数self.Linear1 = paddle.nn.Linear(11, 50)self.Linear2 = paddle.nn.Linear(50, 1)def forward(self, x):x = self.conv1d(x) # 通过一维卷积层处理输入数据,提取特征x = self.relu(x) # 将卷积层的输出通过 ReLU 激活函数, 进行非线性变换x = self.Linear1(x) # 第一个线性层,线性变换x = self.relu(x) # 将卷积层的输出通过 ReLU 激活函数, 进行非线性变换x = self.Linear2(x) # 第二个线性层,线性变换return x
五、模型训练
# 五、模型训练
paddle.seed(666)
model = CNNnetwork()
# 设置损失函数,这里使用的是均方误差损失
criterion = nn.MSELoss()
# 设置优化函数和学习率lr
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.001)
# 设置训练周期
epochs = 30# 划分训练集和验证集
split_idx = int(len(train_scal_data) * 0.8)
train_set = train_scal_data[:split_idx]
val_set = train_scal_data[split_idx:]model.train()
start_time = time.time()# 用于存储每轮的训练和验证损失
train_losses = []
val_losses = []for epoch in range(epochs):# 训练阶段model.train()train_loss = 0.0for seq, y_train in train_set:# 每次更新参数前都梯度归零和初始化optimizer.clear_grad()# 注意这里要对样本进行 reshape,转换成 conv1d 的 input size(batch size, channel, series length)seq = paddle.reshape(seq, [1, 1, -1])seq = paddle.to_tensor(seq, dtype='float32')y_pred = model(seq)y_train = paddle.to_tensor(y_train, dtype='float32')loss = criterion(y_pred, y_train)loss.backward()optimizer.step()train_loss += loss.numpy()[0]# 验证阶段model.eval()val_loss = 0.0with paddle.no_grad():for seq_val, y_val in val_set:seq_val = paddle.reshape(seq_val, [1, 1, -1])seq_val = paddle.to_tensor(seq_val, dtype='float32')y_val = paddle.to_tensor(y_val, dtype='float32')val_pred = model(seq_val)val_loss += criterion(val_pred, y_val).numpy()[0]avg_train_loss = train_loss / len(train_set)avg_val_loss = val_loss / len(val_set)# 存储训练和验证损失train_losses.append(avg_train_loss)val_losses.append(avg_val_loss)print('Epoch {}/{} - Train Loss: {:.4f} - Val Loss: {:.4f}'.format(epoch + 1, epochs, avg_train_loss, avg_val_loss))print('\nDuration: {:.0f} seconds'.format(time.time() - start_time))# 可视化训练和验证损失
plt.figure(figsize=(8, 5))
plt.plot(range(1, epochs + 1), train_losses, label='Train Loss')
plt.plot(range(1, epochs + 1), val_losses, label='Val Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('CNN_Loss')
plt.legend()
plt.show()

六、模型预测
将数据按 window_size 一组分段,每次输入一段后,会输出一个预测的值 y_pred,y_pred 与每段之后的第 window_size + 1 个数据作为对比值,用于计算损失函数。
例如前 5 个数据为 (1,2,3,4,5),取前 4 个进行 CNN 预测,得出的值与 (5) 比较计算 loss。这里使用每组 13 个数据,最后一个数据作评估值,即 window_size=12。
# 六、模型预测
"""
将数据按window_size一组分段,每次输入一段后,会输出一个预测的值y_pred
y_pred与每段之后的window_size+1个数据作为对比值,用于计算损失函数
例如前5个数据为(1,2,3,4,5),取前4个进行CNN预测,得出的值与(5)比较计算loss
这里使用每组13个数据,最后一个数据作评估值,即window_size=12
"""
# 选取序列最后12个值开始预测
preds = train_scal_data[-window_size:]
y_pred1 = []
model.eval() # 设置成eval模式
# 循环的每一步表示向时间序列向后滑动一格
for seq, y_train in preds:# 每次更新参数前都梯度归零和初始化# 转换成conv1d的input size(batch size, channel, series length)seq = paddle.reshape(seq, [1, 1, -1])seq = paddle.to_tensor(seq, dtype='float32')result = model(seq)y_pred1.append(result)print("当前预测值:", y_pred1)
y_pred1 = np.array(y_pred1)
y_pred1 = y_pred1.reshape(-1, 1)
print("完整预测值:", y_pred1)# 预测结果反归一化,还原真实值
true_predictions = scaler.inverse_transform(y_pred1).reshape(-1, 1)# 预测结果可视化
sns.set(font='SimHei') # 设置Seaborn字体
plt.figure(figsize=(8, 5))
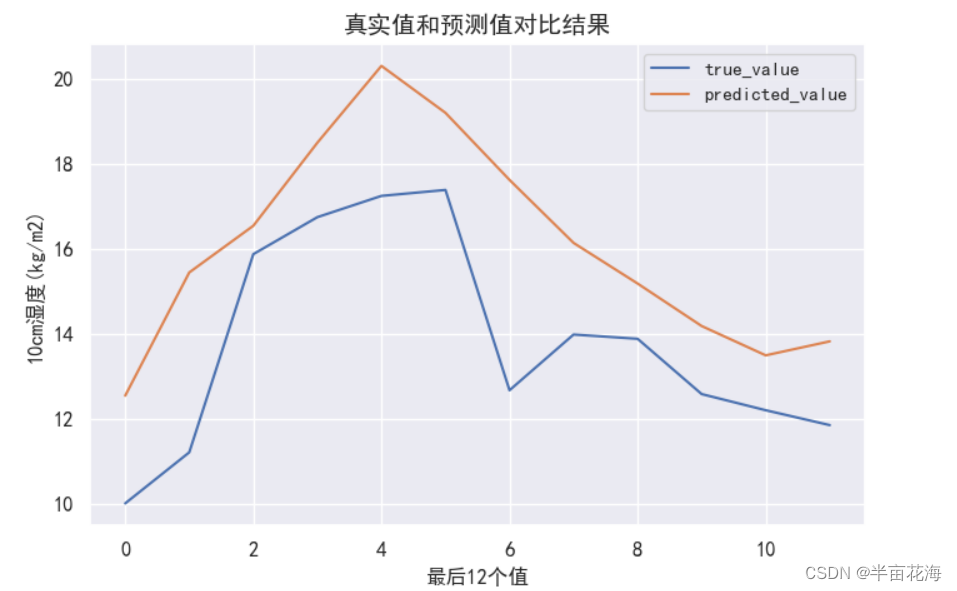
plt.plot(train_data[-window_size:], label='true_value') # 绘制真实值
plt.plot(true_predictions, label='predicted_value') # 绘制预测值
plt.title("真实值和预测值对比结果", fontsize=14)
plt.xlabel("最后12个值", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.yticks(fontsize=12)
plt.xticks(fontsize=12)
plt.grid(True)
plt.legend()
plt.show()
完整预测值:
[[-0.8811799 ]
[-0.31046718]
[-0.09406683]
[ 0.29082218]
[ 0.64678204]
[ 0.4292445 ]
[ 0.11846957]
[-0.17343275]
[-0.36173454]
[-0.55860955]
[-0.6944711 ]
[-0.6295543 ]]
相关文章:
神经网络 | 基于 CNN 模型实现土壤湿度预测
Hi,大家好,我是半亩花海。在现代农业和环境监测中,了解土壤湿度的变化对于作物生长和水资源管理至关重要。通过深度学习技术,特别是卷积神经网络,我们可以利用过去的土壤湿度数据来预测未来的湿度趋势。本文将使用 Pad…...
江科大STM32 终
目录 SPI协议10.1 SPI简介W25Q64简介10.3 SPI软件读写W25Q6410.4 SPI硬件外设读写W25Q64 BKP备份寄存器、PER电源控制器、RTC实时时钟11.0 Unix时间戳代码示例:读写备份寄存器BKP11.2 RTC实时时钟 十二、PWR电源控制12.1 PWR简介代码示例:修改主频12.3 串…...

《MySQL 简易速速上手小册》第10章:未来趋势和进阶资源(2024 最新版)
文章目录 10.1 MySQL 在云计算和容器化中的应用10.1.1 基础知识10.1.2 重点案例:使用 Python 部署 MySQL 到 Kubernetes10.1.3 拓展案例 1:在 AWS RDS 上部署 MySQL 实例10.1.4 拓展案例 2:使用 Docker 部署 MySQL 10.2 MySQL 和 NoSQL 的整合…...

Stable Diffusion 模型下载:GhostMix(幽灵混合)
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十 下载地址 模型介绍 GhostMix 是绝对让你惊艳的模型,也是自己认为现在最强的2.5D模型。我认为模型的更新应该是基于现有的画面整体不大变的前提下,提高模型的成…...

django解决Table ‘xx‘ already exists的方法
1,首先看已存在的这个库表结构是什么样的,先让对应的model.py恢复到和他一样的字段 2,删除对应app下的migrations目录里面除__init__.py文件的其他所有文件 3,回到manage.py所在目录执行python manage.py makemigrations 4&#x…...

qt学习:arm摄像头+c调用v412框架驱动+qt调用v412框架驱动 显示摄像头画面
目录 跟内核进行数据通信的函数 编程步骤 c代码 头文件 打开摄像头文件 /dev/videox 获取当前主机上(开发板)摄像头列表信息 设置当前摄像头的画面格式 比如说 设置 采集图像的宽度为640 高度 480 在内核空间中,申请一个缓冲区队列…...
Linux 36.2@Jetson Orin Nano基础环境构建
Linux 36.2Jetson Orin Nano基础环境构建 1. 源由2. 步骤2.1 安装NVIDIA Jetson Linux 36.2系统2.2 必备软件安装2.3 基本远程环境2.3.1 远程ssh登录2.3.2 samba局域网2.3.3 VNC远程登录 2.4 开发环境安装 3. 总结 1. 源由 现在流行什么,也跟风来么一个一篇。当然&…...
牛客网SQL264:查询每个日期新用户的次日留存率
官网链接: 牛客每个人最近的登录日期(五)_牛客题霸_牛客网牛客每天有很多人登录,请你统计一下牛客每个日期新用户的次日留存率。 有一个登录(login。题目来自【牛客题霸】https://www.nowcoder.com/practice/ea0c56cd700344b590182aad03cc61b8?tpId82 …...
echarts 曲线图自定义提示框
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>曲线图</title><!-- 引入 ECharts 库 -->…...
幻兽帕鲁服务器怎么搭建?Palworld多人联机教程
玩转幻兽帕鲁服务器,阿里云推出新手0基础一键部署幻兽帕鲁服务器教程,傻瓜式一键部署,3分钟即可成功创建一台Palworld专属服务器,成本仅需26元,阿里云服务器网aliyunfuwuqi.com分享2024年新版基于阿里云搭建幻兽帕鲁服…...
DAY39: 动态规划不同路径问题62
Leetcode: 62 不同路径 机器人从(0 , 0) 位置出发,到(m - 1, n - 1)终点。 基本思路 1、确定dp数组(dp table)以及下标的含义 dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条…...
idea开发工具的简单使用与常见问题
1、配置git 选择左上角目录file->setting 打开,Version Control 目录下Git,选择git安装目录下的git.exe文件; 点击test,出现git版本,则表示git识别成功,点击右下角确认即可生效。 2、配置node.js 选…...
使用 WMI 查询安全软件信息
在这篇文章中,我们将详细介绍如何使用 Windows Management Instrumentation (WMI) API 来查询当前计算机上安装的安全软件的基本信息。我们将分析代码的各个部分,并解释每个步骤所涉及的技术和原理。 一、什么是 WMI? WMI 是 Windows Manag…...
创建TextMeshPro字体文件
相比于Unity的Text组件,TextMesh Pro提供了更强大的文本格式和布局控制,更高级的文本渲染技术,更灵活的文本样式和纹理支持,更好的性能以及更易于使用的优点。但unity自带TextMeshPro字体不支持中文。这里使用普通字体文件生成Tex…...

信创ARM架构QT应用开发环境搭建
Linux ARM架构QT应用开发环境搭建 前言交叉工具链Ubuntu上安装 32 位 ARM 交叉工具链Ubuntu上安装 64 位 ARM 交叉工具链 交叉编译 QT 库下载 QT 源码交叉编译 QT 源码 Qt Creator交叉编译配置配置 Qt Creator Kits创建一个测试项目 小结 前言 有没有碰到过这种情况࿱…...
使用SPM_batch进行批量跑脚本(matlab.m)
软件:spm8matlab2023bwin11 数据格式: F:\ASL\HC\CBF\HC_caishaoqing\CBF.nii F:\ASL\HC\CBF\HC_caishaoqing\T1.nii F:\ASL\HC\CBF\HC_wangdonga\CBF.nii F:\ASL\HC\CBF\HC_wangdonga\T1.nii clear spmdirD:\AnalysisApps\spm8; datadirF:\ASL\HC\CBF…...

力扣0124——二叉树的最大路径和
二叉树的最大路径和 难度:困难 题目描述 二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。 路径和 是路径中各节点…...

c# 字符串帮助类
public class StringHelper { #region 全角半角互相转换 /// <summary> /// 转全角的函数(SBC case) /// </summary> /// <param name"str">任意字符串</param> /// <returns>全…...
LabVIEW双光子荧光显微成像系统开发
双光子显微成像是一种高级荧光显微技术,广泛用于生物学和医学研究,尤其是用于活体组织的深层成像。在双光子成像过程中,振镜(Galvo镜)扮演了非常关键的角色,它负责精确控制激光束在样本上的扫描路径。以下是…...

Prim模板
通过代码探索Prim算法:最小生成树之旅 在计算机科学领域,图算法占据了至关重要的位置,尤其是在设计高效的网络(无论是社交网络、计算机网络还是交通网)时。在这些算法中,寻找最小生成树(MST&am…...

为什么你的Ziatype输出总是发灰?3分钟定位CMYK→RGB色域坍缩根源并一键修复
更多请点击: https://intelliparadigm.com 第一章:Ziatype印相发灰现象的直观诊断与认知重构 Ziatype是一种基于铁-银工艺的古典摄影印相法,其典型特征是高对比度、深沉黑位与细腻中间调。然而在实际操作中,“发灰”(…...

FreeVA:零训练成本,用图像大模型实现视频理解的新范式
1. 项目概述:一个无需训练的“零成本”视频助手 最近在折腾多模态大模型(MLLM)的时候,我发现了一个挺有意思的现象:大家一提到让模型理解视频,第一反应就是得搞“视频指令微调”。简单说,就是拿…...

AI时代工程师的超能力进化
好的,这是一篇关于AI时代工程师能力进化的技术文章大纲: 标题: AI时代工程师的“超能力”进化论:从工具使用者到智能架构师 导言: 简述AI技术的迅猛发展及其对各行业的深刻影响。提出问题:在AI成为强大“…...

长期使用Taotoken的Token Plan套餐在项目开发成本控制上的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐在项目开发成本控制上的实际感受 1. 从按需付费到计划用量的转变 在AI应用开发的早期阶段&…...

2026年5月PLC厂家:十大品牌专业评测解决工厂自动化选型难
摘要当制造业加速迈向智能化和柔性生产,PLC作为工业自动化的核心控制单元,其选型直接决定了产线效率、系统稳定性与长期运营成本。然而,面对众多品牌在技术路线、开放程度、生态兼容性上的显著分化,决策者常陷入“性能与成本如何平…...

Java的Random类
在Java中,java.util.Random 类是日常开发中最常用的伪随机数生成器。它基于线性同余算法生成随机数,只要给定相同的初始值(种子 seed),就能生成完全相同的随机数序列。 🎲 Random 类的基础使用 使用 Random…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...

工业视觉杂散物检测系统方案设计
构建一套完整可靠的工业视觉检测系统,核心在于将其无缝嵌入到现有的装配流程中。下面是一个从系统架构部署、执行标准、再到具体模块技术选型的完整实施方案,希望能帮你构建一套精准且高效的检测闭环。 🏗️ 系统总体架构 一个完整的检测系统…...

流处理优化:提高实时数据处理性能
流处理优化:提高实时数据处理性能 一、流处理优化概述 1.1 流处理优化的定义 流处理优化是指通过优化流处理系统的性能、吞吐量和延迟,提高实时数据处理能力的过程。它涉及优化数据处理管道、资源配置和算法实现。 1.2 流处理优化的价值 低延迟ÿ…...

谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率
搜索结果首页占据了超过 94% 的点击流量。如果你的网站排在第二页,那几乎等同于不存在。很多人在寻找 谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率 的答案时,容易被复杂的技术词汇绕晕。提升排名的过程其实是关于…...