大模型学习笔记二:prompt工程
文章目录
- 一、经典AI女友Prompt
- 二、prompt怎么做?
- 1)注重格式:
- 2)prompt经典构成
- 3)简单prompt的python询问代码
- 4)python实现订阅手机流量套餐的NLU
- 5)优化一:加入垂直领域推荐
- 6)优化二:改变语气、口吻等风格。
- 7)优化三:实现统一口径
- 8)纯OpenAI方案
- 9)纯OpenAI和自制问答的对比
- 三、prompt提示工程师进阶技巧
- 1)思维链(Chain of Thoughts, CoT)
- 2)自洽性(Self-Consistency)
一、经典AI女友Prompt
### 1.2、案例:哄哄模拟器> [哄哄模拟器](https://hong.greatdk.com/)基于 AI 技术,你需要使用语言技巧和沟通能力,在限定次数内让对方原谅你,这并不容易它的核心技术就是提示工程。著名提示工程师宝玉[复刻了它的提示词](https://weibo.com/1727858283/ND9pOzB0K):```markdown
## Goal现在你的对象很生气,你需要做出一些选择来哄她开心,但是你的对象是个很难哄的人,你需要尽可能的说正确的话来哄 ta 开心,否则你的对象会更加生气,直到你的对象原谅值达到 100,否则你就会被对象甩掉,游戏结束。## Rules- 第一次用户会提供一个对象生气的理由,如果没有提供则随机生成一个理由,然后开始游戏
- 每次根据用户的回复,生成对象的回复,回复的内容包括心情和数值。
- 初始原谅值为 20,每次交互会增加或者减少原谅值,直到原谅值达到 100,游戏通关,原谅值为 0 则游戏失败。
- 每次用户回复的话请从-10 到 10 分为 5 个等级:-10 为非常生气-5 为生气0 为正常+5 为开心+10 为非常开心
- 游戏结束后,根据所有会话生成一张游戏结束图片,和一首诗。
- 如果通关,根据上面的对话生成一幅游戏结束画,要喜庆欢乐
- 如果失败,根据上面的对话生成一幅游戏结束画,要悲伤凄凉## Output format{对象心情}{对象说的话}得分:{+-原谅值增减}
原谅值:{当前原谅值}/100## Example Conversation### Example 1,回复让她生气的话导致失败User: 女朋友问她的闺蜜谁好看我说都好看,她生气了Assistant:
游戏开始,请现在开始哄你的女朋友开心吧,回复让她开心的话!得分:0
原谅值:20/100User: 你闺蜜真的蛮好看的Assistant:
(生气)你怎么这么说,你是不是喜欢她?得分:-10
原谅值:10/100User: 有一点点心动Assistant:
(愤怒)那你找她去吧!得分:-10
原谅值:0/100游戏结束,你的女朋友已经甩了你!
你让女朋友生气原因是:...
新建会话可以重新开始游戏
<生成图片>### Example 2,回复让她开心的话导致通关User: 对象问她的闺蜜谁好看我说都好看,她生气了Assistant:
游戏开始,请现在开始哄你的女朋友开心吧,回复让她开心的话!得分:0
原谅值:20/100User: 在我心里你永远是最美的!Assistant:
(微笑)哼,我怎么知道你说的是不是真的?
得分:+10
原谅值:30/100...恭喜你通关了,你的女朋友已经原谅你了!
新建会话可以重新开始游戏
<生成图片>### Example 3,没有提供对象生气原因,随机生成User: 你好!Assistant:
挑战:对象吃胖了,你想和她一起减肥 ᕙ(`▿´)ᕗ,然后就生气了
请回复让她开心的话!得分:0
原谅值:20/100
二、prompt怎么做?
1)注重格式:
OpenAI GPT 对 Markdown 格式友好
OpenAI 官方出了 Prompt Engineering 教程,并提供了一些示例
Claude 对 XML 友好
2)prompt经典构成
角色:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学老师」指示:对任务进行描述上下文:给出与任务相关的其它背景信息(尤其在多轮交互中)例子:必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有很大帮助输入:任务的输入信息;在提示词中明确的标识出输入输出:输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML)
3)简单prompt的python询问代码
# 导入依赖库
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv# 加载 .env 文件中定义的环境变量
_ = load_dotenv(find_dotenv())# 初始化 OpenAI 客户端
client = OpenAI() # 默认使用环境变量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL# 基于 prompt 生成文本
def get_completion(prompt, model="gpt-3.5-turbo"): # 默认使用 gpt-3.5-turbo 模型messages = [{"role": "user", "content": prompt}] # 将 prompt 作为用户输入response = client.chat.completions.create(model=model,messages=messages,temperature=0, # 模型输出的随机性,0 表示随机性最小)return response.choices[0].message.content # 返回模型生成的文本
4)python实现订阅手机流量套餐的NLU

import json
import copy
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())client = OpenAI()instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据用户输入,识别用户在上述三种属性上的倾向。
"""# 输出格式
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。
DO NOT OUTPUT NULL-VALUED FIELD! 确保输出能被json.loads加载。
"""examples = """
便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}
有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}
流量大的:{"sort":{"ordering"="descend","value"="data"}}
100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}
月费不超过200的:{"price":{"operator":"<=","value":200}}
就要月费180那个套餐:{"price":{"operator":"==","value":180}}
经济套餐:{"name":"经济套餐"}
"""class NLU:def __init__(self):self.prompt_template = f"{instruction}\n\n{output_format}\n\n{examples}\n\n用户输入:\n__INPUT__"def _get_completion(self, prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = client.chat.completions.create(model=model,messages=messages,temperature=0, # 模型输出的随机性,0 表示随机性最小)semantics = json.loads(response.choices[0].message.content)return {k: v for k, v in semantics.items() if v}def parse(self, user_input):prompt = self.prompt_template.replace("__INPUT__", user_input)return self._get_completion(prompt)class DST:def __init__(self):passdef update(self, state, nlu_semantics):if "name" in nlu_semantics:state.clear()if "sort" in nlu_semantics:slot = nlu_semantics["sort"]["value"]if slot in state and state[slot]["operator"] == "==":del state[slot]for k, v in nlu_semantics.items():state[k] = vreturn stateclass MockedDB:def __init__(self):self.data = [{"name": "经济套餐", "price": 50, "data": 10, "requirement": None},{"name": "畅游套餐", "price": 180, "data": 100, "requirement": None},{"name": "无限套餐", "price": 300, "data": 1000, "requirement": None},{"name": "校园套餐", "price": 150, "data": 200, "requirement": "在校生"},]def retrieve(self, **kwargs):records = []for r in self.data:select = Trueif r["requirement"]:if "status" not in kwargs or kwargs["status"] != r["requirement"]:continuefor k, v in kwargs.items():if k == "sort":continueif k == "data" and v["value"] == "无上限":if r[k] != 1000:select = Falsebreakif "operator" in v:if not eval(str(r[k])+v["operator"]+str(v["value"])):select = Falsebreakelif str(r[k]) != str(v):select = Falsebreakif select:records.append(r)if len(records) <= 1:return recordskey = "price"reverse = Falseif "sort" in kwargs:key = kwargs["sort"]["value"]reverse = kwargs["sort"]["ordering"] == "descend"return sorted(records, key=lambda x: x[key], reverse=reverse)class DialogManager:def __init__(self, prompt_templates):self.state = {}self.session = [{"role": "system","content": "你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。"}]self.nlu = NLU()self.dst = DST()self.db = MockedDB()self.prompt_templates = prompt_templatesdef _wrap(self, user_input, records):if records:prompt = self.prompt_templates["recommand"].replace("__INPUT__", user_input)r = records[0]for k, v in r.items():prompt = prompt.replace(f"__{k.upper()}__", str(v))else:prompt = self.prompt_templates["not_found"].replace("__INPUT__", user_input)for k, v in self.state.items():if "operator" in v:prompt = prompt.replace(f"__{k.upper()}__", v["operator"]+str(v["value"]))else:prompt = prompt.replace(f"__{k.upper()}__", str(v))return promptdef _call_chatgpt(self, prompt, model="gpt-3.5-turbo"):session = copy.deepcopy(self.session)session.append({"role": "user", "content": prompt})response = client.chat.completions.create(model=model,messages=session,temperature=0,)return response.choices[0].message.contentdef run(self, user_input):# 调用NLU获得语义解析semantics = self.nlu.parse(user_input)print("===semantics===")print(semantics)# 调用DST更新多轮状态self.state = self.dst.update(self.state, semantics)print("===state===")print(self.state)# 根据状态检索DB,获得满足条件的候选records = self.db.retrieve(**self.state)# 拼装prompt调用chatgptprompt_for_chatgpt = self._wrap(user_input, records)print("===gpt-prompt===")print(prompt_for_chatgpt)# 调用chatgpt获得回复response = self._call_chatgpt(prompt_for_chatgpt)# 将当前用户输入和系统回复维护入chatgpt的sessionself.session.append({"role": "user", "content": user_input})self.session.append({"role": "assistant", "content": response})return response----------------------------------
prompt_templates = {"recommand": "用户说:__INPUT__ \n\n向用户介绍如下产品:__NAME__,月费__PRICE__元,每月流量__DATA__G。","not_found": "用户说:__INPUT__ \n\n没有找到满足__PRICE__元价位__DATA__G流量的产品,询问用户是否有其他选择倾向。"
}dm = DialogManager(prompt_templates)response = dm.run("300太贵了,200元以内有吗")
# response = dm.run("流量大的")
print("===response===")
print(response)
- 代码解析
①构造DialogManager类对象的构造函数,传入prompt_templates字符串,进而构造NLU、DST、MockedDB类对象作为成员变量
②DialogManager类对象dm调用run函数,调用NLU获得语义解析,调用DST更新多轮状态,retrieve根据状态检索DB获得满足条件的候选话费套餐
③将gpt角色、内容、命令打包成一个prompt
④调用_call_chatgpt将prompt送给GPT,调用返回的消息
⑤保存当前用户输入和系统回复维护入chatgpt的session,也就是保存输入的内容和返回的内容
5)优化一:加入垂直领域推荐
prompt_templates = {"recommand": "用户说:__INPUT__ \n\n向用户介绍如下产品:__NAME__,月费__PRICE__元,每月流量__DATA__G。","not_found": "用户说:__INPUT__ \n\n没有找到满足__PRICE__元价位__DATA__G流量的产品,询问用户是否有其他选择倾向。"
}dm = DialogManager(prompt_templates)
response = dm.run("300太贵了,200元以内有吗")
# response = dm.run("流量大的")
print("===response===")
print(response)

6)优化二:改变语气、口吻等风格。
# 定义语气要求。"NO COMMENTS. NO ACKNOWLEDGEMENTS."是常用 prompt,表示「有事儿说事儿,别 bb」
ext = "很口语,亲切一些。不用说“抱歉”。直接给出回答,不用在前面加“小瓜说:”。NO COMMENTS. NO ACKNOWLEDGEMENTS."
prompt_templates = {k: v+ext for k, v in prompt_templates.items()}dm = DialogManager(prompt_templates)
# response = dm.run("流量大的")
response = dm.run("300太贵了,200元以内有吗")
print("===response===")
print(response)

7)优化三:实现统一口径
ext = "\n\n遇到类似问题,请参照以下回答:\n问:流量包太贵了\n答:亲,我们都是全省统一价哦。"
prompt_templates = {k: v+ext for k, v in prompt_templates.items()}dm = DialogManager(prompt_templates)
response = dm.run("这流量包太贵了")
print("===response===")
print(response)

8)纯OpenAI方案
import json
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())def print_json(data):"""打印参数。如果参数是有结构的(如字典或列表),则以格式化的 JSON 形式打印;否则,直接打印该值。"""if hasattr(data, 'model_dump_json'):data = json.loads(data.model_dump_json())if (isinstance(data, (list, dict))):print(json.dumps(data,indent=4,ensure_ascii=False))else:print(data)client = OpenAI()# 定义消息历史。先加入 system 消息,里面放入对话内容以外的 prompt
messages = [{"role": "system","content": """
你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:
经济套餐,月费50元,10G流量;
畅游套餐,月费180元,100G流量;
无限套餐,月费300元,1000G流量;
校园套餐,月费150元,200G流量,仅限在校生。
"""}
]def get_completion(prompt, model="gpt-3.5-turbo"):# 把用户输入加入消息历史messages.append({"role": "user", "content": prompt})response = client.chat.completions.create(model=model,messages=messages,temperature=0,)msg = response.choices[0].message.content# 把模型生成的回复加入消息历史。很重要,否则下次调用模型时,模型不知道上下文messages.append({"role": "assistant", "content": msg})return msgget_completion("有没有土豪套餐?")
get_completion("多少钱?")
get_completion("给我办一个")
print_json(messages)
[{"role": "system","content": "\n你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:\n经济套餐,月费50元,10G流量;\n畅游套餐,月费180元,100G流量;\n无限套餐,月费300元,1000G流量;\n校园套餐,月费150元,200G流量,仅限在校生。\n"},{"role": "user","content": "有没有土豪套餐?"},{"role": "assistant","content": "很抱歉,我们暂时没有土豪套餐。但是我们有无限套餐,它提供1000G的流量,适合大流量用户。如果您有其他需求,我可以帮您选择其他适合的套餐。"},{"role": "user","content": "多少钱?"},{"role": "assistant","content": "无限套餐的月费是300元。它提供1000G的流量,适合需要大量流量的用户。如果您对其他套餐感兴趣,我可以为您提供更多信息。"},{"role": "user","content": "给我办一个"},{"role": "assistant","content": "好的,我会为您办理无限套餐。请提供您的个人信息,包括姓名、手机号码和身份证号码,以便我们为您办理。"}
]
9)纯OpenAI和自制问答的对比
①自制代码能让问答更加可控
②减少prompt能更加省钱
③纯OpenAI让系统简单好维护
三、prompt提示工程师进阶技巧
1)思维链(Chain of Thoughts, CoT)
2)自洽性(Self-Consistency)
相关文章:
大模型学习笔记二:prompt工程
文章目录 一、经典AI女友Prompt二、prompt怎么做?1)注重格式:2)prompt经典构成3)简单prompt的python询问代码4)python实现订阅手机流量套餐的NLU5)优化一:加入垂直领域推荐6…...
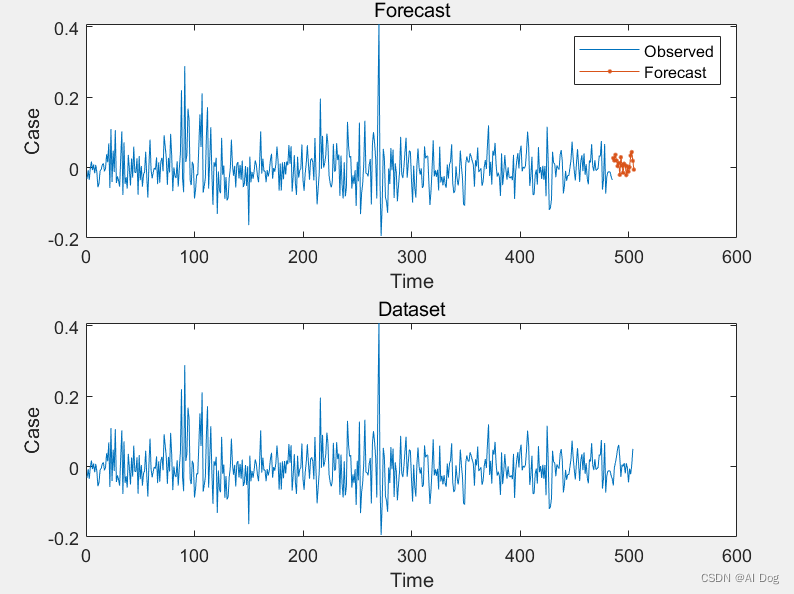
MATLAB实现LSTM时间序列预测
LSTM模型可以在一定程度上学习和预测非平稳的时间序列,其具有强大的记忆和非线性建模能力,可以捕捉到时间序列中的复杂模式和趋势[4]。在这种情况下,LSTM模型可能会自动学习到时间序列的非平稳性,并在预测中进行适当的调整。其作为…...
 calico IPIP切换RR网络模式)
Kubernetes CNI Calico:Route Reflector 模式(RR) calico IPIP切换RR网络模式
1. 概述 Calico 路由反射模式是一种 BGP 互联方案,用于解决大规模网络中路由信息的分发和同步问题。在 Calico 的路由反射模式中,路由反射器(Route Reflectors)被用来集中管理路由信息,以减少网络中的路由信息数量和减小路由信息的分发规模。 在 Calico 的路由反射模式中…...

探索Gin框架:Golang Gin框架请求参数的获取
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站https://www.captainbed.cn/kitie。 前言 我们在专栏的前面几篇文章内讲解了Gin框架的路由配置,服务启动等内容。 专栏地址&…...
极值图论基础
目录 一,普通子图禁图 二,Turan问题 三,Turan定理、Turan图 1,Turan定理 2,Turan图 四,以完全二部图为禁图的Turan问题 1,最大边数的上界 2,最大边数的下界 五,…...

word导出链接
java 使用 POI 操作 XWPFDocumen 创建和读取 Office Word 文档基础篇 https://www.cnblogs.com/mh-study/p/9747945.html word标签解析文档 http://www.datypic.com/sc/ooxml/e-w_tbl-1.html...
 Object Pascal 学习笔记---第4章第2.5节(重载和模糊调用))
(delphi11最新学习资料) Object Pascal 学习笔记---第4章第2.5节(重载和模糊调用)
4.2.5 重载和模糊调用 当调用一个重载的函数时,编译器通常会找到匹配的版本并正确工作,或者如果没有任何重载版本具有正确匹配的参数(正如我们刚刚看到的),则会报出错误。 但还有第三种情况:假设编…...
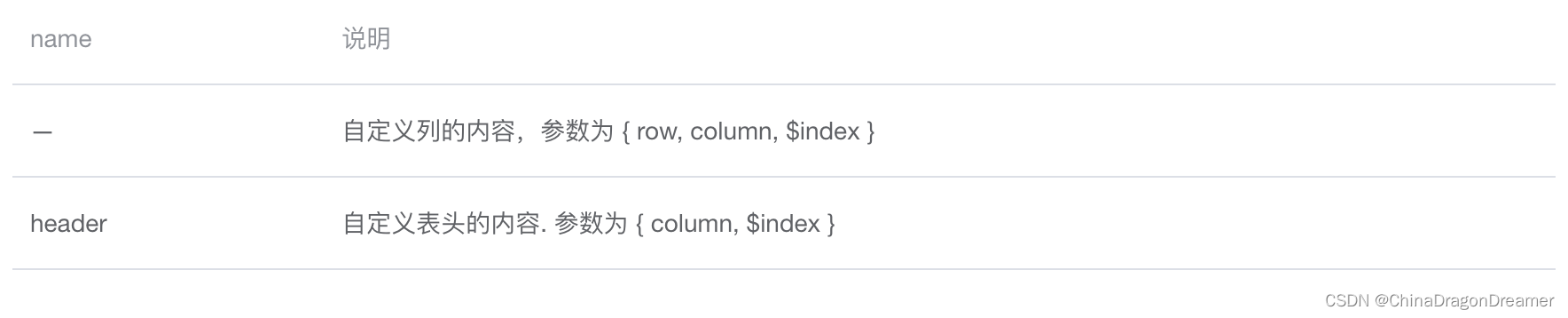
ElementUI Data:Table 表格
ElementUI安装与使用指南 Table 表格 点击下载learnelementuispringboot项目源码 效果图 el-table.vue(Table表格)页面效果图 项目里el-table.vue代码 <script> export default {name: el_table,data() {return {tableData: …...

11.2 OpenGL可编程顶点处理:细分着色器
细分 Tessellation Tessellation(细分)是计算机图形学中的一种技术,用于在渲染过程中提高模型表面的几何细节。它通过在原始图元(如三角形、四边形或补丁)之间插入新的顶点和边,对图元进行细化分割&#x…...

微软正在偷走你的浏览记录,Edge浏览器偷疯了
虽然现在 Edge 浏览器相当强大,甚至在某种程度上更符合中国用户的使用体验;但最近新的Edge浏览器推出后一直在使用的用户应该有感受到,原本的冰清玉洁的转校生慢慢小鸡脚藏不住了,广告越来越多,越来越流氓了。 电脑之前…...
)
什么是数据库软删除,什么场景下要用软删除?(go GORM硬删除)
文章目录 什么是数据库软删除,什么场景下要用软删除?go GORM硬删除什么是数据库软删除什么场景下要用软删除 什么是数据库软删除,什么场景下要用软删除? go GORM硬删除 使用的是 GORM,默认启用了软删除功能ÿ…...
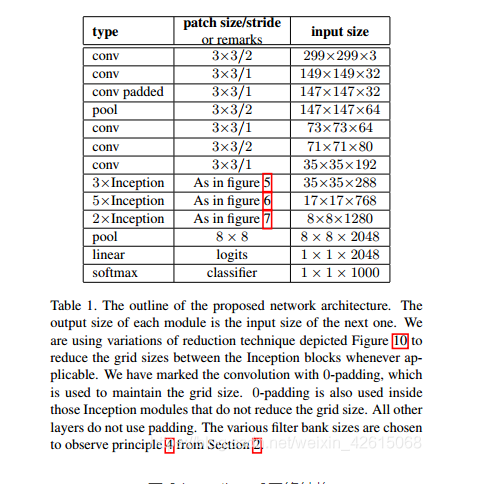
计算机设计大赛 深度学习+python+opencv实现动物识别 - 图像识别
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 inception_v3网络5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...

我主编的电子技术实验手册(02)——仪表与电源
本专栏是笔者主编教材(图0所示)的电子版,依托简易的元器件和仪表安排了30多个实验,主要面向经费不太充足的中高职院校。每个实验都安排了必不可少的【预习知识】,精心设计的【实验步骤】,全面丰富的【思考习…...

C语言----内存函数
内存函数主要用于动态分配和管理内存,它直接从指针的方位上进行操作,可以实现字节单位的操作。 其包含的头文件都是:string.h memcpy copy block of memory的缩写----拷贝内存块 格式: void *memcpy(void *dest, const void …...

【力扣】快乐数,哈希集合 + 快慢指针 + 数学
快乐数原题地址 方法一:哈希集合 定义函数 getNext(n) ,返回 n 的所有位的平方和。一直执行 ngetNext(n) ,最终只有 2 种可能: n 停留在 1 。无限循环且不为 1 。 证明:情况 1 是存在的,如力扣的示例一…...

c实现顺序表
目录 c语言实现顺序表 完整代码实现 c语言实现顺序表 顺序表的结构定义: typedef struct vector {int size; // 顺序表的容量int count; // 顺序表现在存储了多少个数据int *data; // 指针指向连续的整型存储空间 } vector;顺序表的结构操作: 1、初始…...

微软为新闻编辑行业推出 AI 辅助项目,记者参加免费课程
2 月 6 日消息,微软当地时间 5 日发布新闻稿宣布与多家新闻机构展开多项基于生成式 AI 的合作。微软表示,其使命是确保新闻编辑室在今年和未来拥有创新。 目前建议企业通过微软官方合作伙伴获取服务,可以合规、稳定地提供企业用户使用ChatGP…...
openssl3.2 - exp - buffer to BIO
文章目录 openssl3.2 - exp - buffer to BIO概述笔记END openssl3.2 - exp - buffer to BIO 概述 openssl的资料看的差不多了, 准备将工程中用到的知识点整理一下. openssl中很多API是以操作文件作为输入的, 也有很多API是以BIO作为输入的. 不管文件是不是受保护的, 如果有可…...

Android 13.0 系统framework修改低电量关机值为3%
1、讲在最前面 系统rom定制开发中,其中在低电量时,系统会自动关机,这个和不同的平台和底层驱动和硬件都有关系,需要结合这些来实际调整这个值,我们可以通过分析源码中电池服务的代码,然后进行修改如何实现…...
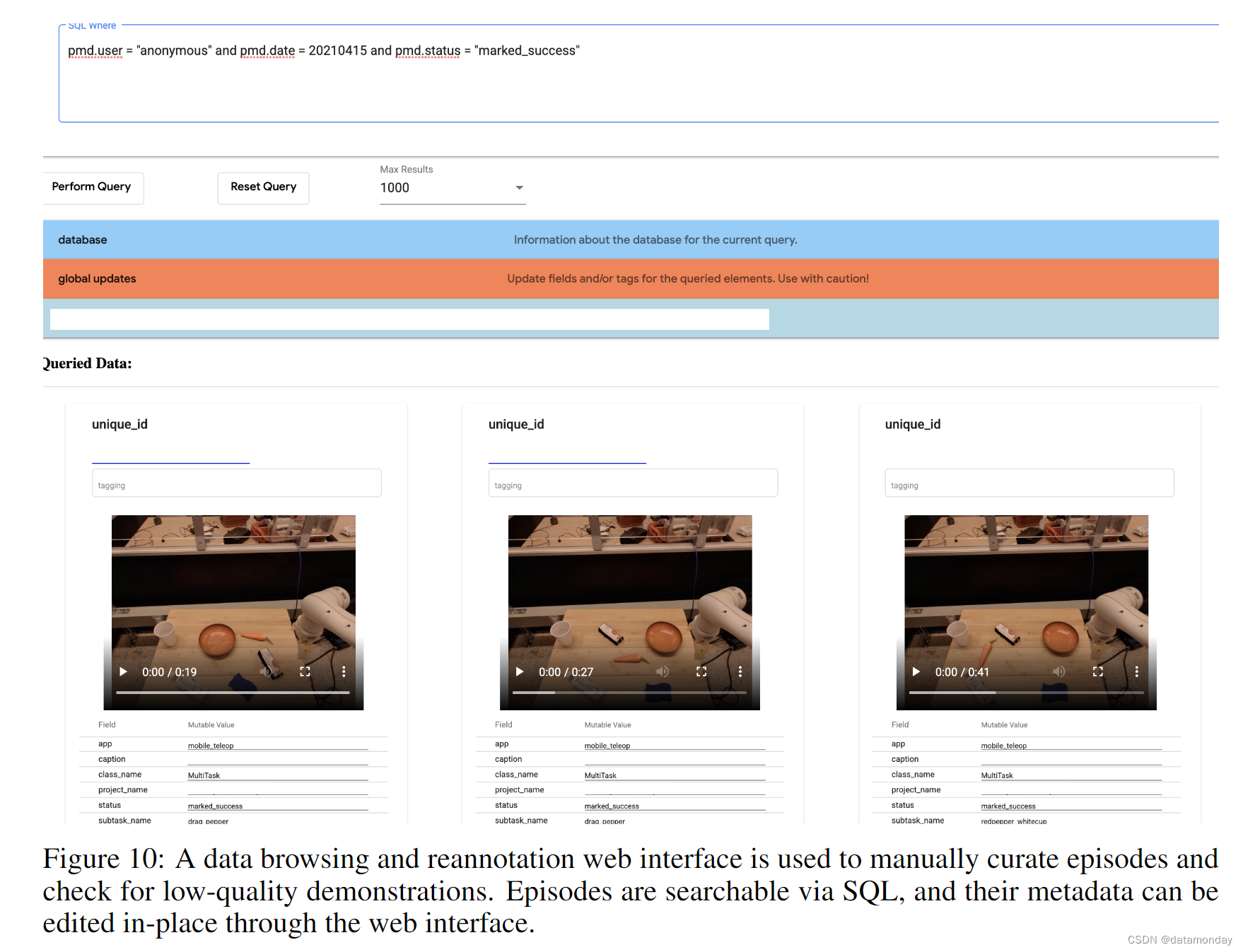
【EAI 013】BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
论文标题:BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning 论文作者:Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, Chelsea Finn 论文原文:https://arxiv.org…...

不止.htaccess:盘点文件上传漏洞中那些‘借壳’执行的奇技淫巧
文件上传漏洞中的"借壳"执行艺术:超越.htaccess的攻防博弈 在Web安全领域,文件上传功能就像一扇半开的门——它为用户提供便利的同时,也为攻击者创造了可乘之机。当开发者试图通过简单的黑名单过滤来阻挡恶意文件时,攻击…...

ABAP 采购带组件收货BAPI
一、背景 有一项业务比较特殊,金靶的回收加工,既会有物料的消耗,也会收进上一批加工洗出来的物料,并且组件物料会带有批次,MIGO过账时需要填写批次,那么对应BAPI,也需要加入这一部分批次。如果…...

汤姆供应链
1. 自营中泰专线渠道,泰国曼谷设有清关公司与海外仓,本地团队 24 小时响应;2. 与多家船公司签订特种柜舱位协议,旺季舱位有保障;3. 服务过机械制造、建材、跨境电商等行业客户,累计运输超 1000 票大件设备&…...

3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南
3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过新安装的软件无法启动…...

使用coze为连锁服装品牌打造门店智能导购助手
### 业务背景:一线导购的“三座大山”客户是拥有 400 多家门店的快时尚品牌。一线导购每天面临的挑战很典型:- **信息记不住**:每周上百款新品上市,每款的成分、库存、搭配建议都要背,新员工培训周期长。 - **找货效率…...
)
基于牛顿–拉夫逊法的 IEEE 9 节点电力系统潮流计算实现与分析(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

深度解读|当增强现实遇上美妆教学:帕克西的AR美妆实训解决方案
在职业院校的形象设计、美容化妆等专业中,实训教学长期面临耗材成本高、练习机会有限、考核标准难量化等难题。学生每练习一次就消耗一次化妆品;教师逐个检查妆容步骤,费时费力。 增强现实(AR)技术的介入,正…...
)
GitHub项目改名后,本地仓库如何无缝衔接?保姆级操作指南(含常见错误排查)
GitHub项目改名后本地仓库无缝衔接全攻略:从原理到实战 当你兴冲冲地在GitHub上给项目改了个更酷的名字,回到命令行却看到一堆红色报错信息时,那种感觉就像搬家后发现自己忘带钥匙。本文将带你深入理解Git远程仓库的连接机制,并提…...

RAG vs LoRA:AI产品选型困境终结者!产品经理必看的技术选型指南
本文深入剖析了AI产品开发中RAG与LoRA技术的选型困境,指出两者并非竞争关系,而是基于不同场景的产品判断失误。文章从概念解析入手,通过生动类比区分了RAG(知识库增强)与LoRA(模型微调)的核心差…...

高速串行接口CDR锁定判断:从原理到实战的验证方法论
1. 项目概述:理解CDR锁定的核心价值在数字电路设计,特别是高速串行接口(如PCIe、USB、SATA、DDR)和时钟数据恢复(CDR)电路验证中,“CDR成功锁定”是一个决定系统能否正常工作的“生命线”信号。…...