Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。
1.Transformer中decoder的流程
在论文《Attention is all you need》中,关于encoder及self attention有较为详细的论述,这也是网上很多教程在谈及transformer时候会重点讨论的部分。但是关于transformer的decoder部分,他的结构上与encoder实际非常像,但其中有一些巧妙的设计。本文会详细谈谈。首先给出一个完整transformer的结构图:
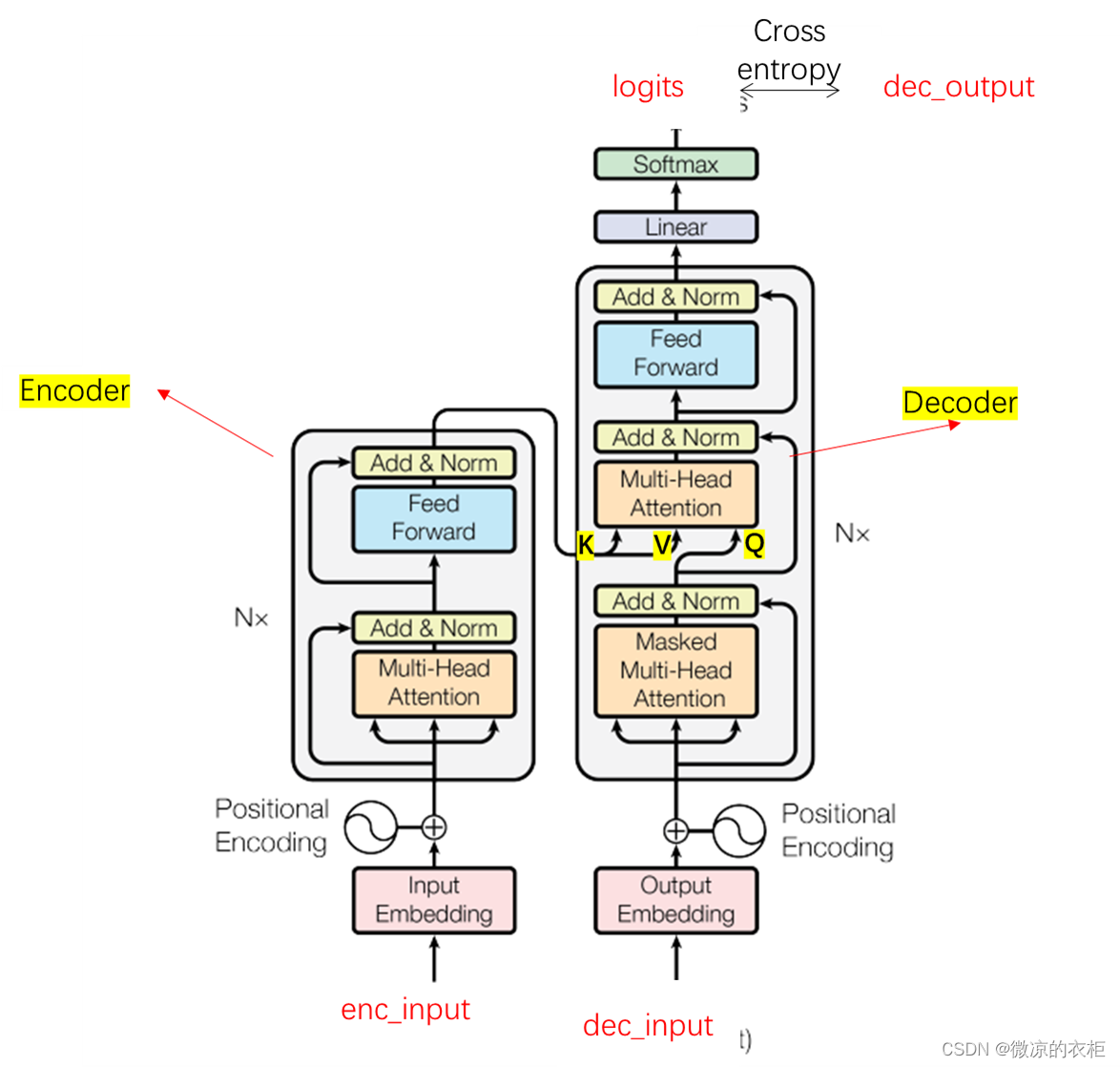
上图左侧为encoder部分,右侧为decoder部分。对于decoder部分,将enc_input经过multi head attention后得到的张量,以K,V送入decoder中。而decoder阶段的masked multi head attention需要解决如何将dec_input编码成Q。最终输出的logits实际是与Q的维度一致。对于Scaled Dot-Product Attention,其公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
在《Transformer的PyTorch实现之若干问题探讨(一)》中,decoder阶段,Q的维度为[2,8,6,64](2为batch size,8为head数,6为句子长度,64为向量长度),K的维度为[2,8,5,64],V的维度为[2,8,5,64]。其中, Q K T QK^T QKT的维度为[2,8,6,5] 的,可以理解每个查询张量Q对每个键值张K的注意力权重。之后乘以V,维度为[2,8,6,64]。可以看到最终的维度是根据查询张量Q来加权值向量V。Q就是dec_input经过masked multi head attention得来。那么,dec_input中实际是包含了所有的标签的。那么dec_input是如何mask掉不需要的token的呢?
2.Decoder中的self attention mask
class Decoder(nn.Module):def __init__(self):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs):'''这三个参数对应的不是Q、K、V,dec_inputs是Q,enc_outputs是K和V,enc_inputs是用来计算padding mask的dec_inputs: [batch_size, tgt_len]enc_inpus: [batch_size, src_len]enc_outputs: [batch_size, src_len, d_model]'''dec_outputs = self.tgt_emb(dec_inputs)#词序号编码成向量dec_outputs = self.pos_emb(dec_outputs).cuda()#位置编码dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() #[2, 6, 6]dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() #[2, 6, 6],上三角矩阵# 将两个mask叠加,布尔值可以视为0和1,和大于0的位置是需要被mask掉的,赋为True,和为0的位置是有意义的为Falsedec_self_attn_mask = torch.gt((dec_self_attn_pad_mask +dec_self_attn_subsequence_mask), 0).cuda()# 这是co-attention部分,为啥传入的是enc_inputs而不是enc_outputs:enc_outputs是向量,这儿是需要通过词编码来判断是否需要mask掉dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) #[2, 6, 5]for layer in self.layers:dec_outputs = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)return dec_outputs # dec_outputs: [batch_size, tgt_len, d_model]
上述代码为Decoder部分。可以看到有两个mask:dec_self_attn_pad_mask(用于将dec_inputs中的P mask掉)与dec_self_attn_subsequence_mask(用于实现decoder的self attention)。这两个mask在后面会相加合并。这儿可以分别展示二者的值,其中:
dec_self_attn_pad_mask:
tensor([[[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False]],[[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False],[False, False, False, False, False, False]]], device='cuda:0')#[2, 6, 6]
dec_self_attn_subsequence_mask:
tensor([[[0, 1, 1, 1, 1, 1],[0, 0, 1, 1, 1, 1],[0, 0, 0, 1, 1, 1],[0, 0, 0, 0, 1, 1],[0, 0, 0, 0, 0, 1],[0, 0, 0, 0, 0, 0]],[[0, 1, 1, 1, 1, 1],[0, 0, 1, 1, 1, 1],[0, 0, 0, 1, 1, 1],[0, 0, 0, 0, 1, 1],[0, 0, 0, 0, 0, 1],[0, 0, 0, 0, 0, 0]]], device='cuda:0', dtype=torch.uint8)#[2, 6, 6]
可以看到,dec_self_attn_pad_mask全为false,这是因为dec_input中不包含P,而dec_self_attn_subsequence_mask为上三角矩阵,对于每个token,需要mask掉它之后的token(本代码中,为1或True的位置会被mask掉)。接下来进一步追问,为什么上三角矩阵就可以mask掉该token之后的token?具体是如何实现的呢?
对于前文的Scaled Dot-Product Attention公式,代码中的表述实际为:
def forward(self, Q, K, V, attn_mask):'''Q: [batch_size, n_heads, len_q, d_k]K: [batch_size, n_heads, len_k, d_k]V: [batch_size, n_heads, len_v(=len_k), d_v] 全文两处用到注意力,一处是self attention,另一处是co attention,前者不必说,后者的k和v都是encoder的输出,所以k和v的形状总是相同的attn_mask: [batch_size, n_heads, seq_len, seq_len]'''# 1) 计算注意力分数QK^T/sqrt(d_k)scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores: [batch_size, n_heads, len_q, len_k]# 2) 进行 mask 和 softmax# mask为True的位置会被设为-1e9scores.masked_fill_(attn_mask, -1e9) # 把True设为-1e9attn = nn.Softmax(dim=-1)(scores) # attn: [batch_size, n_heads, len_q, len_k]# 3) 乘V得到最终的加权和context = torch.matmul(attn, V) # context: [batch_size, n_heads, len_q, d_v], [2, 8, 5, 64]'''得出的context是每个维度(d_1-d_v)都考虑了在当前维度(这一列)当前token对所有token的注意力后更新的新的值,换言之每个维度d是相互独立的,每个维度考虑自己的所有token的注意力,所以可以理解成1列扩展到多列返回的context: [batch_size, n_heads, len_q, d_v]本质上还是batch_size个句子,只不过每个句子中词向量维度512被分成了8个部分,分别由8个头各自看一部分,每个头算的是整个句子(一列)的512/8=64个维度,最后按列拼接起来'''return context # context: [batch_size, n_heads, len_q, d_v]
其中,Q,K,V的维度都是[2, 8, 6, 64], score的维度为[2, 8, 6, 6],即每个token之间的注意力分数。这儿取出一个batch中的一个head下的注意力分数a为例,a的维度为[6, 6],如图所示:
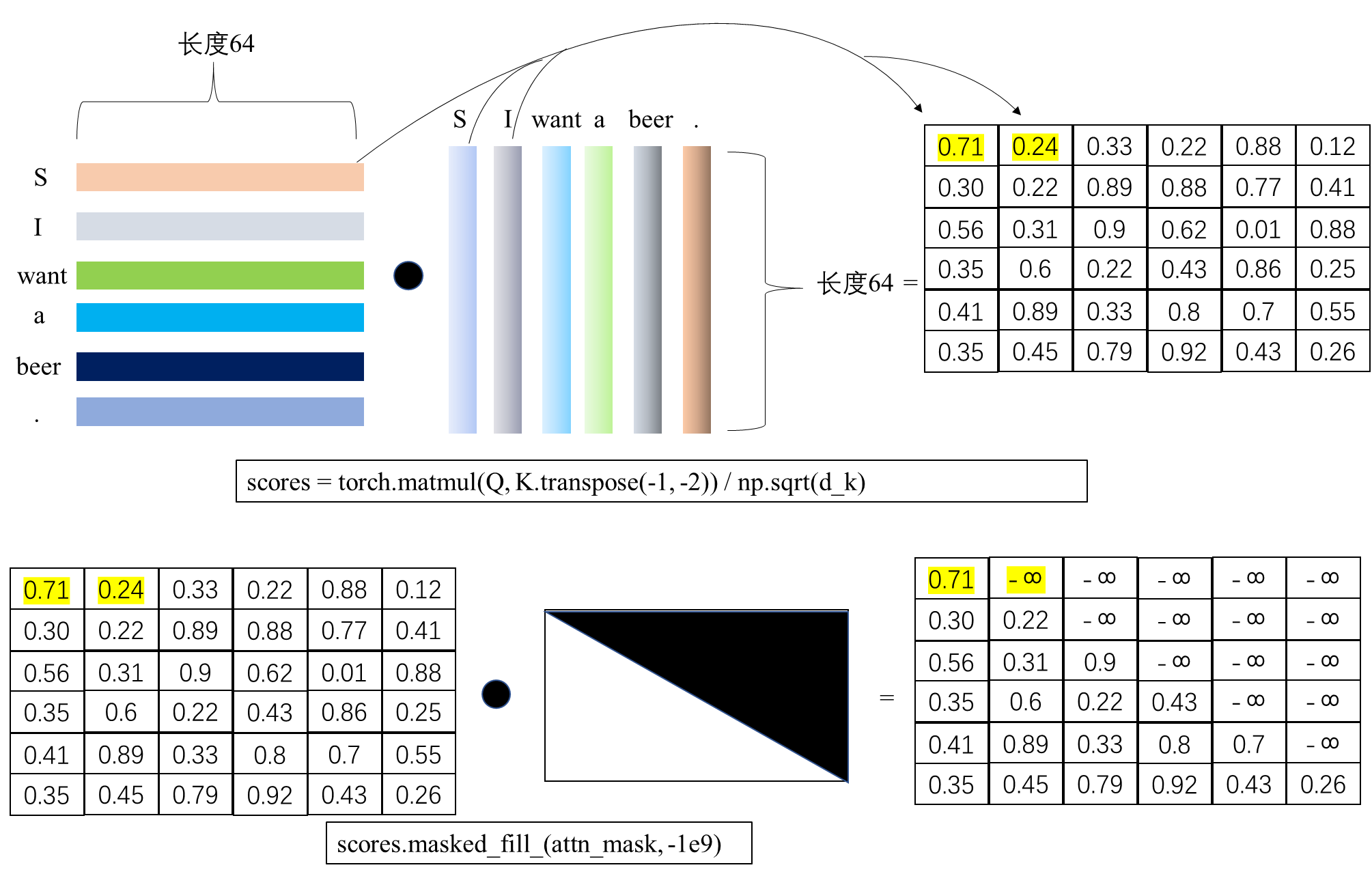
如上图所示,在得分score中,标黄的0.71和0.24分别是S与S,以及S与I的词向量相乘得到。由于I在S后面,所以需要通过mask将其置为负无穷大,而0.71需要保留,因为是S与S在同一个位置上。因此这个mask矩阵为上三角矩阵。
相关文章:
Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。 1.Transformer中decoder的流程 在论文《Attention is all you need》中࿰…...
及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别)
解释Python中的GIL(全局解释器锁)及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别
解释Python中的GIL(全局解释器锁)及其影响 Python中的GIL(全局解释器锁)是CPython解释器中的一个机制,用于同步线程的执行。GIL确保任何时候只有一个线程在执行Python字节码。这意味着,即使在多核或多处理器…...
Appium使用初体验之参数配置,简单能够运行起来
一、服务器配置 Appium Server配置与Appium Server GUI(可视化客户端)中的配置对应,尤其是二者如果不在同一台机器上,那么就需要配置Appium Server GUI所在机器的IP(Appium Server GUI的HOST也需要配置本机IP…...

Java:JDK8新特性(Stream流)、File类、递归 --黑马笔记
一、JDK8新特性(Stream流) 接下来我们学习一个全新的知识,叫做Stream流(也叫Stream API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案…...

【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置【文末送书】
前言 【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置一、效果展示二、根据坐标控制溶解的位置,物体靠近局部溶解三、应用实例👑评论区抽奖送书 前言 本文将使用ShaderGraph制作一个根据坐标控制溶解的位置,物…...

测试OpenSIPS3.4.3的lua模块
这几天测试OpenSIPS3.4.3的lua模块,记录如下: 有bug,但能用 但现实世界就是这样,总是不完美的,发现之后马上提了issue 下面这段代码运行报错: function func1(msg) xlog("ERR","…...

【机器学习】数据清洗之处理缺失点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

Linux 命令行的世界 :2.文件系统中跳转
我们需要学习的第一件事(除了打字之外)是如何在 Linux 文件系统中跳转。在这一章节中,我们将介绍以下命令:pwd 打印出当前工作目录名 cd 更改目录 ls 列出目录内容 Linux以分层目录结构来组织所有文件。这就意味着所有文件…...
R语言:箱线图绘制(添加平均值趋势线)
箱线图绘制 1. 写在前面2.箱线图绘制2.1 相关R包导入2.2 数据导入及格式转换2.3 ggplot绘图 1. 写在前面 今天有时间把之前使用过的一些代码和大家分享,其中箱线图绘制我认为是非常有用的一个部分。之前我是比较喜欢使用origin进行绘图,但是绘制的图不太…...

Open3D 模型切片
目录 一、算法原理1、算法过程2、主要函数二、代码实现三、结果展示1、原始数据2、切片结果本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理...
KtConnect 本地连接连接K8S工具
KT Connect简介 Kt Connect (Kubernetes Developer Tool)是一个阿里开源、轻量级的面向 Kubernetes 用户的开发测试环境治理辅助工具。其核心是通过建立本地到集群以及集群到本地的双向通道。 1.阿里开源,轻量级, 2. 安装快捷简单…...

【Java万花筒】数据的安全钥匙:Java的加密与保护方法
编码的盾牌:Java开发人员的安全性武器库 前言 在当今数字化时代,保护用户数据和信息的安全已成为开发人员的首要任务。无论是在Web应用程序开发还是安全测试中,加密和安全性都是至关重要的。本文将介绍六个Java库和工具,它们为开…...
【Java多线程案例】实现阻塞队列
1. 阻塞队列简介 1.1 阻塞队列概念 阻塞队列:是一种特殊的队列,具有队列"先进先出"的特性,同时相较于普通队列,阻塞队列是线程安全的,并且带有阻塞功能,表现形式如下: 当队列满时&…...

【制作100个unity游戏之24】unity制作一个3D动物AI生态系统游戏3(附项目源码)
最终效果 文章目录 最终效果系列目录前言随着地面法线旋转在地形上随机生成动物不同部位颜色不同最终效果源码完结系列目录 前言 欢迎来到【制作100个Unity游戏】系列!本系列将引导您一步步学习如何使用Unity开发各种类型的游戏。在这第24篇中,我们将探索如何用unity制作一…...

home work day5
第四章 堆与拷贝构造函数 一 、程序阅读题 1、给出下面程序输出结果。 #include <iostream.h> class example {int a; public: example(int b5){ab;} void print(){aa1;cout <<a<<"";} void print()const {cout<<a<<endl;} …...
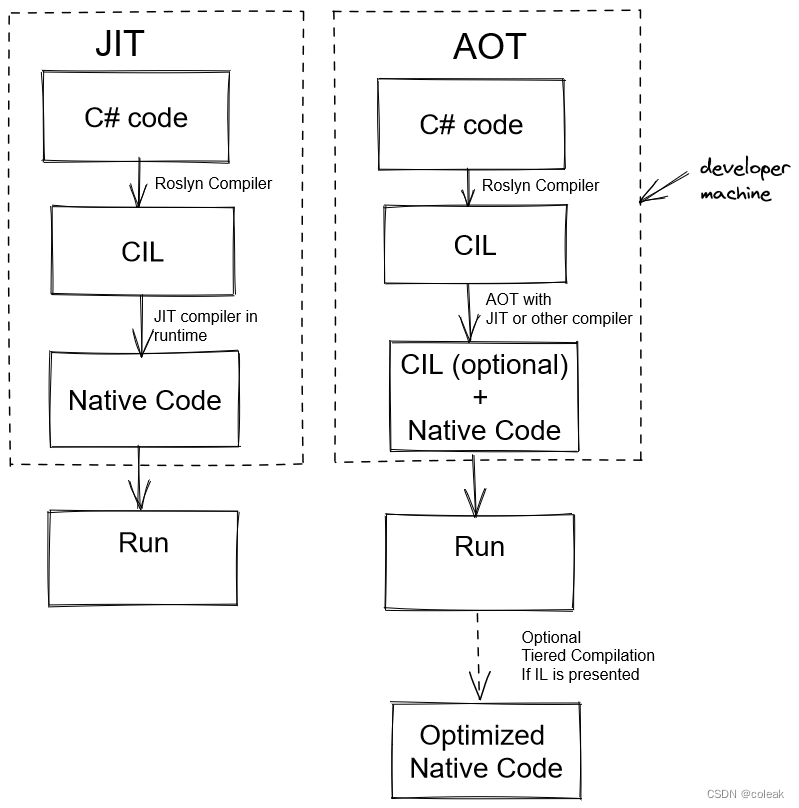
c#安全-nativeAOT
文章目录 前记AOT测试反序列化Emit 前记 JIT\AOT JIT编译器(Just-in-Time Complier),AOT编译器(Ahead-of-Time Complier)。 AOT测试 首先编译一段普通代码 using System; using System.Runtime.InteropServices; namespace co…...

【Java】案例:检测MySQL是否存在某数据库,没有则创建
1.代码 package hello; import java.sql.*;public class CeShi {//定义基本数据static final String JDBC_DRIVER "com.mysql.cj.jdbc.Driver";static final String DB_URL "jdbc:mysql://localhost/";static final String USER "your_username&q…...
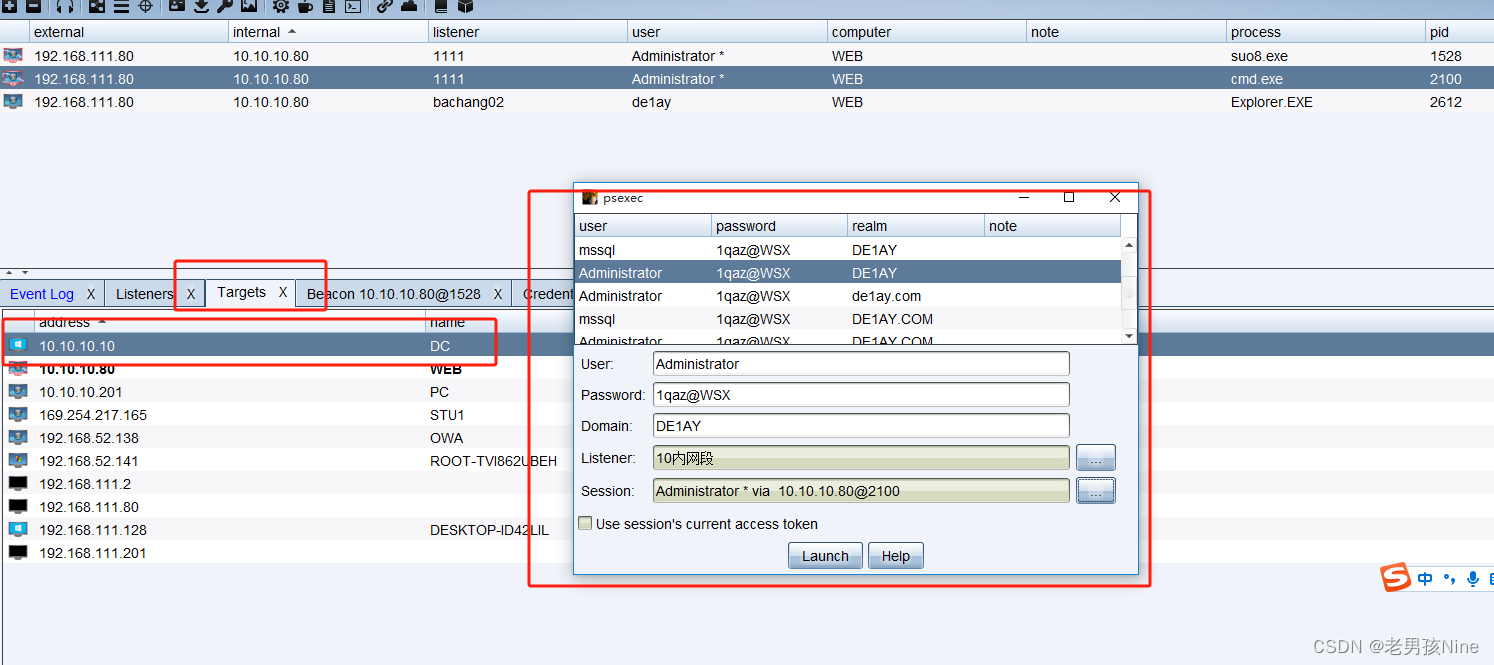
内网渗透靶场02----Weblogic反序列化+域渗透
网络拓扑: 攻击机: Kali: 192.168.111.129 Win10: 192.168.111.128 靶场基本配置:web服务器双网卡机器: 192.168.111.80(模拟外网)10.10.10.80(模拟内网)域成员机器 WIN7PC192.168.…...

[嵌入式系统-9]:C语言程序调用汇编语言程序的三种方式
目录 1. 使用函数声明和函数调用: 2. 使用汇编内联(Inline Assembly): 3. 使用汇编代码文件和链接器: C语言程序可以调用汇编程序的方式有多种,下面列举了几种常见的方式: 1. 使用函数声明和…...

备战蓝桥杯---搜索(完结篇)
再看一道不完全是搜索的题: 解法1:贪心并查集: 把冲突事件从大到小排,判断是否两个在同一集合,在的话就返回,不在的话就合并。 下面是AC代码: #include<bits/stdc.h> using namespace …...

大模型注意力机制深度解析:从Dot-Product到Flash Attention的演进之路
引言如果让你用一句话概括过去七年人工智能领域最重要的技术突破,答案几乎毫无悬念——注意力机制(Attention Mechanism) 。2017年,Google团队在论文《Attention Is All You Need》中首次提出Transformer架构,彻底摒弃…...

B站缓存视频无损转换终极指南:3步快速上手m4s-converter开源工具
B站缓存视频无损转换终极指南:3步快速上手m4s-converter开源工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视…...

SpringCloud+Vue智慧云停车场服务管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

【每日一题】排序
📌 写在前面:排序是算法竞赛中最基础也最核心的技能之一。它不仅是快速查找、去重、贪心等算法的前置步骤,更是自定义比较策略、多关键字排序、排序后贪心等高级技巧的基石。本文基于蓝桥杯官方课程与真题,从基础排序到竞赛实战&a…...

深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史
深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史 当你在Keil5环境下打开一个遗留的单片机项目时,那个看似微不足道的#1295-D: Deprecated declaration警告可能正暗示着一段跨越四十年的编程语言进化史。这个关于函数声明的警告不是Keil5的任…...

如何快速获取免费的EB Garamond 12字体:古典优雅的终极排版解决方案
如何快速获取免费的EB Garamond 12字体:古典优雅的终极排版解决方案 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 EB Garamond 12是一款完全免费的开源字体,完美复刻了16世纪Claude Garamont的经典…...

嵌入式学习的第八天
字符指针常见错误 核心:字符串常量存只读内存,不可修改! #include <stdio.h> int main() {// 错误写法:指针指向字符串常量(只读),不能修改内容char *p "hello"; // *(p0) e…...

AI职业成长地图:软件测试从业者的精准发展路径
在AI技术重塑软件工程生态的当下,软件测试行业正经历从自动化到智能化的范式跃迁。2026年全球AI测试市场规模突破12亿美元,传统测试岗位需求年复合增长率不足2%,而AI测试工程师岗位增幅达45%。对于软件测试从业者而言,构建清晰的A…...

微积分入门书籍之高考篇
导数的秘密(第二版)-2021.01 高考导数满分精讲(2021) 高考导数探秘:解题技巧与策略 董晟渤(2024.10) 微积分与高考数学(第2版)-2024 高考导数解题全攻略(2024…...

causal-learn实战指南:从算法选择到因果图解读
1. 为什么你需要causal-learn? 第一次接触因果发现这个概念时,我正被一个电商用户行为分析项目搞得焦头烂额。传统机器学习模型能准确预测用户是否会购买商品,但产品经理总追着我问:"到底哪些因素真正导致了购买行为…...