【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
- 提出背景
- 如何在不重训练模型的情况下从I2I生成模型中移除特定数据?
- 超高效的机器遗忘方法
- 子问题1: 如何在图像到图像(I2I)生成模型中进行高效的机器遗忘?
- 子问题2: 如何确定哪些数据需要被遗忘?
- 子问题3: 如何保持对其他数据的记忆不受影响?
- 评估与效果
- 子问题: 机器遗忘算法如何平衡保留集和遗忘集之间的性能?
- 子问题: 如何定义一个能够量化遗忘效果的目标函数?
提出背景
论文:https://arxiv.org/pdf/2402.00351.pdf
代码:https://github.com/jpmorganchase/l2l-generator-unlearning
如何在不重训练模型的情况下从I2I生成模型中移除特定数据?
- 背景: 现行法律对数据隐私和版权提出了新要求,这需要机器学习模型能够遗忘特定的训练数据。
传统的机器遗忘方法,如SISA,需要重新训练模型,这在大型生成模型中不现实。
探索直接操作训练好的模型权重的方法,如使用Neural Tangent Kernel (NTK)或最大化遗忘集上的损失,减少遗忘所需的计算量。
- 解法: 探索允许模型删除特定的训练样本数据,而无需从头开始重训练整个模型。
- 例子: 用户要求删除其数据,遗忘技术能让模型忘记这些数据,而不影响对其他数据的处理能力。
与重新训练整个模型或简单的数据删除相比,提出的机器遗忘方案在计算效率和应用的灵活性方面更为优越。
超高效的机器遗忘方法
子问题1: 如何在图像到图像(I2I)生成模型中进行高效的机器遗忘?
- 背景: 在I2I生成模型中,删除敏感数据的同时保持模型性能是一个挑战,因为简单的数据删除无法消除模型中已经学到的信息。
- 解法: 提出了一种不需从头开始训练模型的高效遗忘算法,通过优化KL散度和利用L2损失实现遗忘。
这种解法避免了从头开始训练整个模型,而是直接在模型的现有权重上应用调整。
它使用KL散度来度量和最大化遗忘集(即将被模型“遗忘”的数据)的生成图像与原图之间的统计分布差异,同时利用L2损失来最小化保留集(即模型需要继续记住的数据)的生成图像与原图之间的差异。
假设有一个I2I模型,它被训练用于将简笔画转换为详细的彩色图像。
出于隐私原因,我们需要模型遗忘所有包含特定符号的简笔画。
在不重训练模型的情况下,我们可以调整模型的权重,使得当模型再次看到这些特定符号的简笔画时,它生成的图像与原图的KL散度最大化(即生成的图像与原图差异很大),而对于其他类型的简笔画,模型应通过L2损失保持其原有的转换能力。
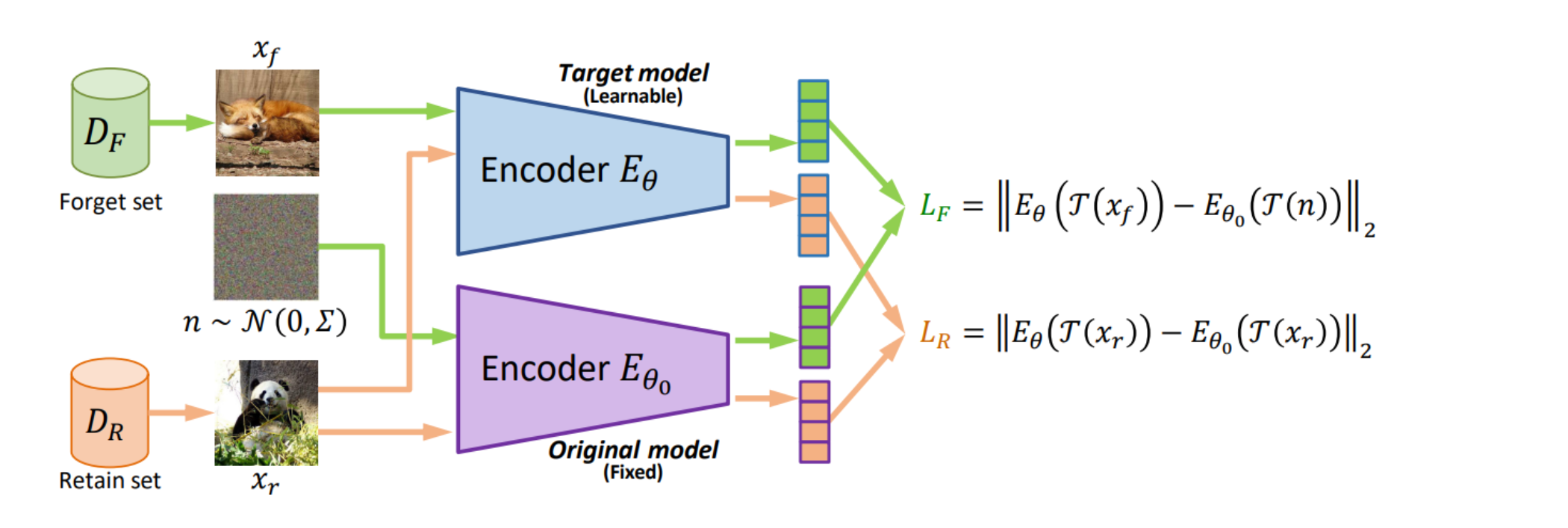
这张图提供了一个机器遗忘方法的概览。
在这个方法中,有两个数据集:遗忘集(( D_F ))和保留集(( D_R )),以及两个编码器:目标模型编码器 E θ E_{\theta} Eθ(可学习的)和原始模型编码器 E θ 0 E_{\theta_0} Eθ0(固定的)。
对于遗忘集(( x_f )),方法的目标是最小化目标模型编码器 E θ E_{\theta} Eθ 输出的嵌入向量与由高斯噪声 ( n )生成的嵌入向量之间的L2损失( L F L_F LF)。
这意味着,在遗忘集上,目标模型的输出应与随机噪声相似,从而“遗忘”或移除相关的特征。
对于保留集( x r x_r xr),目标是最小化目标模型编码器 E θ E_{\theta} Eθ 输出的嵌入向量与原始模型编码器 E θ 0 E_{\theta_0} Eθ0 输出的嵌入向量之间的L2损失(( L_R ))。
这确保了在保留集上,即使经过遗忘过程,目标模型仍然能够保持对原始特征的记忆。
- 遗忘方法的核心原理,即通过调整编码器输出,使得遗忘集的数据被有效地去除,同时保留集的数据特征被保留。
- 这种方法旨在保护隐私,同时保持模型在不需要遗忘的数据上的性能。
子问题2: 如何确定哪些数据需要被遗忘?
- 背景: 在应对隐私保护法律要求或用户的个人数据删除请求时,必须明确哪些数据需要从模型中移除。
- 解法: 设立一个遗忘集(( D_F )),包含所有需被遗忘的数据样本。
- 例子: 如果用户要求删除其在在线服务中的面部数据,所有包含该用户面部的图像将被归入遗忘集。
子问题3: 如何保持对其他数据的记忆不受影响?
- 背景: 在移除特定数据的同时,不应损害模型对于其他数据的处理能力。
- 解法: 设立一个保留集(( D_R )),并通过算法保证在遗忘过程中这些数据的特征不会被改变。
- 例子: 在同一个面部识别服务中,即便删除某些用户的数据,服务仍能准确识别并处理其他用户的面部图像。
通过区分遗忘集和保留集,并对遗忘集应用特定的遗忘算法,实现了数据的精确遗忘。
不足之处可能在于如何确保在遗忘集和保留集之间划分的界限是明确的,以及如何处理边界模糊的情况。
逻辑链条:
-
确定哪些数据需要被遗忘:这是逻辑链条的起点。
在这一步,我们需要识别出哪些数据因隐私保护法律要求、用户个人数据删除请求或其他原因需要从模型中移除。
这个过程涉及到将特定的数据样本标记为遗忘集(( D_F ))。
-
高效的机器遗忘算法:一旦确定了遗忘集,下一步就是应用高效的机器遗忘算法。
这个算法直接在模型的现有权重上进行调整,而不是从头开始重新训练整个模型。
它利用KL散度和L2损失来分别最大化遗忘集的数据与模型生成图像之间的差异,并最小化保留集(( D_R ))的数据与模型生成图像之间的差异。
这一步确保了特定数据的遗忘,同时保持了对其他数据的处理能力。
-
保持对其他数据的记忆不受影响(子问题3):这是逻辑链条的最后一个环节。
通过设立保留集并精确控制遗忘算法的应用,我们可以确保在遗忘特定数据的同时,模型对于保留集中的数据特征记忆不受影响。这保证了模型在删除某些数据后,仍能准确处理和识别其他数据。
这个逻辑链条反映了一个从识别需要遗忘的数据,到应用特定算法遗忘这些数据,最终确保模型整体性能不受影响的完整过程。
它是线性的,因为每个步骤都依赖于前一个步骤的完成,并为下一个步骤提供基础。
虽然每个步骤内部可能涉及更复杂的决策和算法处理,但从宏观上看,这些子问题和解法形成了解决机器遗忘问题的直接逻辑链条。
评估与效果
子问题: 机器遗忘算法如何平衡保留集和遗忘集之间的性能?
- 背景: 在机器遗忘中需要确保遗忘集中的数据被去除,同时保留集的数据性能不受影响。
- 解法: 通过最小化保留集的生成图像与原图的分布差异,同时最大化遗忘集的生成图像与原图的分布差异。
- 例子: 对于风格转换模型,保留集中的艺术风格转换能力不受影响,而遗忘集中特定艺术家的风格被模型遗忘。
在这种方法中,目标是调整模型权重,使得保留集上的图像生成尽可能保持高质量(与原图差异小),而遗忘集上的图像生成则明显偏离原有数据分布。
这通常通过在训练期间添加特定的约束或损失函数来实现,以确保模型在保留集上的生成图像与真实图像保持一致,同时在遗忘集上生成与原图不同的图像。
考虑一个被训练用于风格迁移的I2I模型,现在需要遗忘特定艺术家的风格。
遗忘操作将通过调整模型权重实现,当模型尝试在遗忘集上进行风格迁移时,结果图像与原始艺术家风格的分布有很大差异,而在保留集上的其他艺术风格则保持不变。

这张图展示了一个机器遗忘框架在不同类型的图像到图像(I2I)生成模型上的应用效果,包括扩散模型(Diffusion Models)、向量量化生成对抗网络(VQ-GAN),以及掩蔽自编码器(MAE)。
图中展示了两个不同的集合:保留集(Retain Set)和遗忘集(Forget Set)。
在保留集部分(a),可以看到原始图片(Ground Truth),输入图片(Input),以及遗忘前后的图片(Before Unlearning 和 After Unlearning)。
保留集的图片在遗忘前后几乎没有受到影响,图像质量和内容保持一致。
在遗忘集部分(b),同样展示了原始图片和输入图片,以及遗忘前后的图片。
遗忘后的图片与原始图片相比,几乎成为了噪声,这意味着模型成功“忘记”了遗忘集中的信息,图片内容被大幅度扭曲,以至于无法识别原来的内容,符合遗忘框架的设计目的。
- 机器遗忘框架在各种I2I生成模型上的适用性,并验证了其能够有效地在遗忘集上实现数据的遗忘,同时保持保留集上数据的完整性。
子问题: 如何定义一个能够量化遗忘效果的目标函数?
- 背景: 需要一个清晰的目标,以量化模型遗忘特定数据的效果。
- 解法: 使用KL散度和互信息(MI)作为度量,定义了一个目标函数来量化遗忘的效果。
- 例子: 在遗忘算法的效果评估中,可以通过比较遗忘前后模型生成的图像与原图的KL散度来量化遗忘的程度。
在这个解法中,使用KL散度和互信息(MI)来定义一个目标函数,旨在量化模型遗忘特定数据的效果。
KL散度衡量两个概率分布之间的差异,而互信息量化两个变量间的相互依赖性。
这些指标结合起来能够给出模型遗忘效果的量化评估。
假如有一个生成模型被用于生成人脸图像,现在需要遗忘某个人的脸部数据。
通过调整模型参数,当模型接收到与该人脸相关的输入时,输出的图像与原始人脸的KL散度很高,表明生成的图像与被遗忘的人脸差异很大。
同时,通过测量互信息,确保在保留集上模型仍能生成与输入高度相关的人脸图像。
遗忘性能展示:

- 上半部分(Figure 3) 展示了在扩散模型上对中心8x8像素块进行裁剪后的结果,其中每个裁剪块的大小为16x16像素。
- 图像从左到右依次展示了:
- “Ground Truth”:原始未处理的图像。
- “Input”:输入到模型中的图像,中间有被遗忘的8x8像素块。
- 一系列不同遗忘方法的结果,包括“Original Model”(原始模型输出),“Max Loss”(最大化损失),“Noisy Label”(噪声标签),“Retain Label”(保留标签),“Random Encoder”(随机编码器),以及“Ours”(我们的方法)。
这部分显示了在进行遗忘操作后,保留集的图像质量几乎没有影响,而遗忘集的图像则变得接近噪声,说明遗忘操作成功执行。
相关文章:
【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据 提出背景如何在不重训练模型的情况下从I2I生成模型中移除特定数据? 超高效的机器遗忘方法子问题1: 如何在图像到图像(I2I)生成模型中进行高效…...
Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。 1.Transformer中decoder的流程 在论文《Attention is all you need》中࿰…...
及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别)
解释Python中的GIL(全局解释器锁)及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别
解释Python中的GIL(全局解释器锁)及其影响 Python中的GIL(全局解释器锁)是CPython解释器中的一个机制,用于同步线程的执行。GIL确保任何时候只有一个线程在执行Python字节码。这意味着,即使在多核或多处理器…...
Appium使用初体验之参数配置,简单能够运行起来
一、服务器配置 Appium Server配置与Appium Server GUI(可视化客户端)中的配置对应,尤其是二者如果不在同一台机器上,那么就需要配置Appium Server GUI所在机器的IP(Appium Server GUI的HOST也需要配置本机IP…...

Java:JDK8新特性(Stream流)、File类、递归 --黑马笔记
一、JDK8新特性(Stream流) 接下来我们学习一个全新的知识,叫做Stream流(也叫Stream API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案…...

【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置【文末送书】
前言 【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置一、效果展示二、根据坐标控制溶解的位置,物体靠近局部溶解三、应用实例👑评论区抽奖送书 前言 本文将使用ShaderGraph制作一个根据坐标控制溶解的位置,物…...

测试OpenSIPS3.4.3的lua模块
这几天测试OpenSIPS3.4.3的lua模块,记录如下: 有bug,但能用 但现实世界就是这样,总是不完美的,发现之后马上提了issue 下面这段代码运行报错: function func1(msg) xlog("ERR","…...

【机器学习】数据清洗之处理缺失点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

Linux 命令行的世界 :2.文件系统中跳转
我们需要学习的第一件事(除了打字之外)是如何在 Linux 文件系统中跳转。在这一章节中,我们将介绍以下命令:pwd 打印出当前工作目录名 cd 更改目录 ls 列出目录内容 Linux以分层目录结构来组织所有文件。这就意味着所有文件…...
R语言:箱线图绘制(添加平均值趋势线)
箱线图绘制 1. 写在前面2.箱线图绘制2.1 相关R包导入2.2 数据导入及格式转换2.3 ggplot绘图 1. 写在前面 今天有时间把之前使用过的一些代码和大家分享,其中箱线图绘制我认为是非常有用的一个部分。之前我是比较喜欢使用origin进行绘图,但是绘制的图不太…...

Open3D 模型切片
目录 一、算法原理1、算法过程2、主要函数二、代码实现三、结果展示1、原始数据2、切片结果本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理...
KtConnect 本地连接连接K8S工具
KT Connect简介 Kt Connect (Kubernetes Developer Tool)是一个阿里开源、轻量级的面向 Kubernetes 用户的开发测试环境治理辅助工具。其核心是通过建立本地到集群以及集群到本地的双向通道。 1.阿里开源,轻量级, 2. 安装快捷简单…...

【Java万花筒】数据的安全钥匙:Java的加密与保护方法
编码的盾牌:Java开发人员的安全性武器库 前言 在当今数字化时代,保护用户数据和信息的安全已成为开发人员的首要任务。无论是在Web应用程序开发还是安全测试中,加密和安全性都是至关重要的。本文将介绍六个Java库和工具,它们为开…...
【Java多线程案例】实现阻塞队列
1. 阻塞队列简介 1.1 阻塞队列概念 阻塞队列:是一种特殊的队列,具有队列"先进先出"的特性,同时相较于普通队列,阻塞队列是线程安全的,并且带有阻塞功能,表现形式如下: 当队列满时&…...

【制作100个unity游戏之24】unity制作一个3D动物AI生态系统游戏3(附项目源码)
最终效果 文章目录 最终效果系列目录前言随着地面法线旋转在地形上随机生成动物不同部位颜色不同最终效果源码完结系列目录 前言 欢迎来到【制作100个Unity游戏】系列!本系列将引导您一步步学习如何使用Unity开发各种类型的游戏。在这第24篇中,我们将探索如何用unity制作一…...

home work day5
第四章 堆与拷贝构造函数 一 、程序阅读题 1、给出下面程序输出结果。 #include <iostream.h> class example {int a; public: example(int b5){ab;} void print(){aa1;cout <<a<<"";} void print()const {cout<<a<<endl;} …...
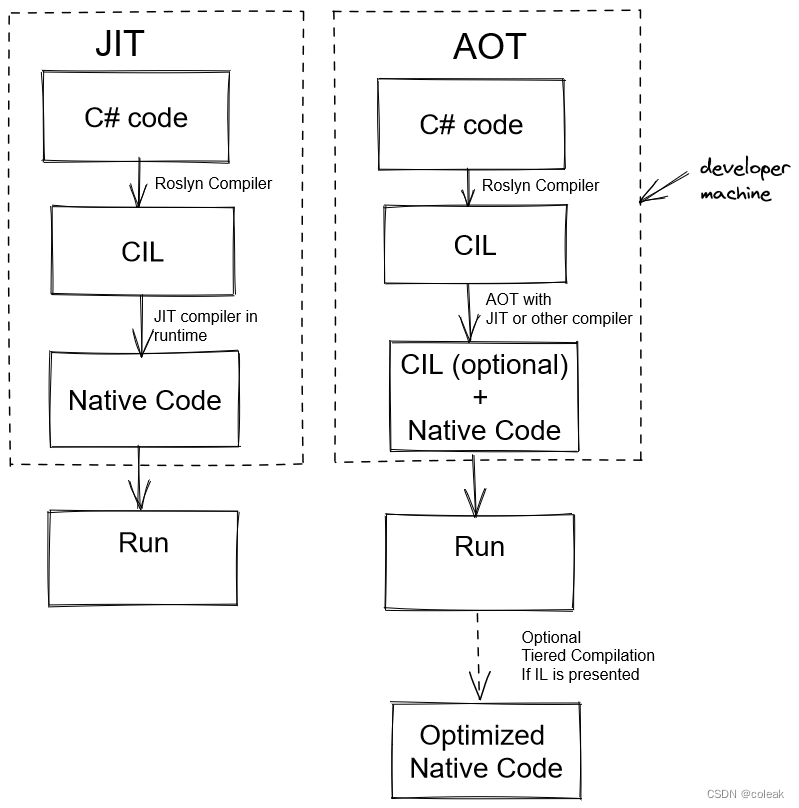
c#安全-nativeAOT
文章目录 前记AOT测试反序列化Emit 前记 JIT\AOT JIT编译器(Just-in-Time Complier),AOT编译器(Ahead-of-Time Complier)。 AOT测试 首先编译一段普通代码 using System; using System.Runtime.InteropServices; namespace co…...

【Java】案例:检测MySQL是否存在某数据库,没有则创建
1.代码 package hello; import java.sql.*;public class CeShi {//定义基本数据static final String JDBC_DRIVER "com.mysql.cj.jdbc.Driver";static final String DB_URL "jdbc:mysql://localhost/";static final String USER "your_username&q…...
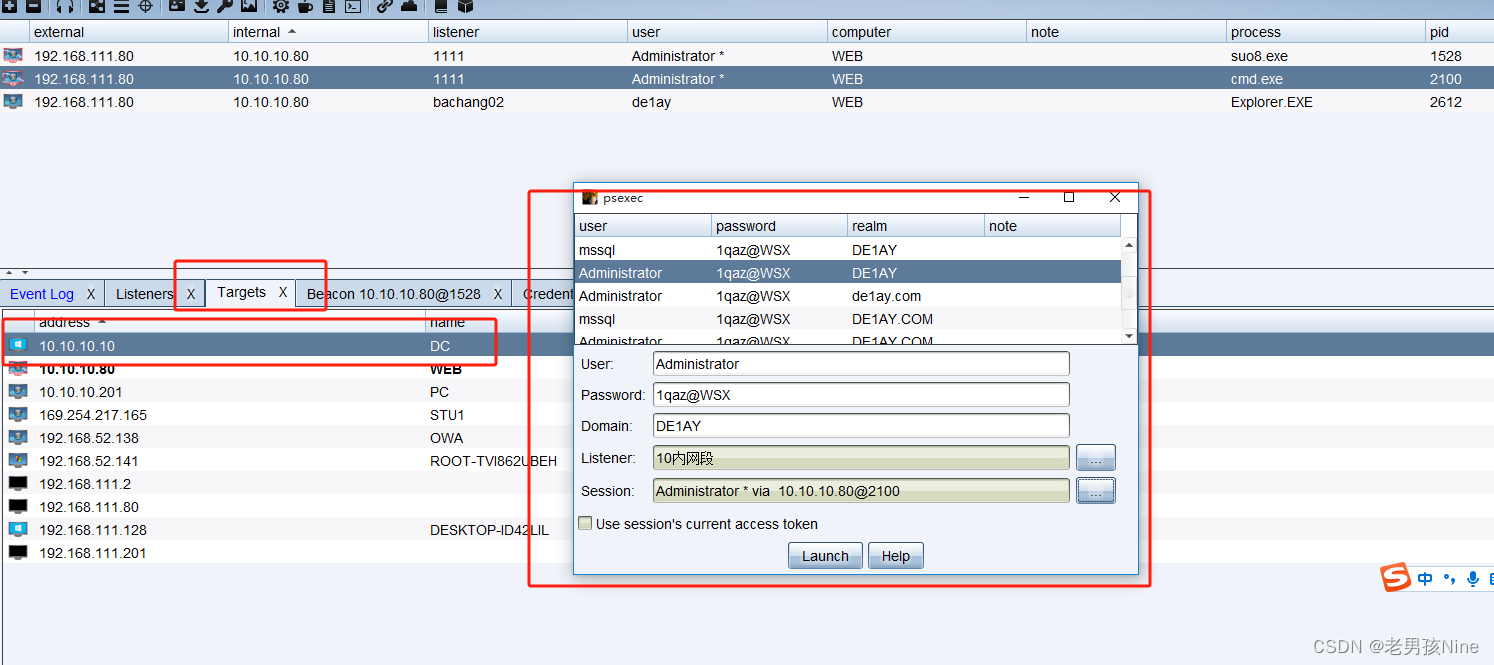
内网渗透靶场02----Weblogic反序列化+域渗透
网络拓扑: 攻击机: Kali: 192.168.111.129 Win10: 192.168.111.128 靶场基本配置:web服务器双网卡机器: 192.168.111.80(模拟外网)10.10.10.80(模拟内网)域成员机器 WIN7PC192.168.…...

[嵌入式系统-9]:C语言程序调用汇编语言程序的三种方式
目录 1. 使用函数声明和函数调用: 2. 使用汇编内联(Inline Assembly): 3. 使用汇编代码文件和链接器: C语言程序可以调用汇编程序的方式有多种,下面列举了几种常见的方式: 1. 使用函数声明和…...

量子同态加密:理论与实践的突破
1. 量子同态加密:理论与实践的桥梁量子同态加密(Quantum Homomorphic Encryption, QHE)是密码学领域的一项突破性技术,它允许在加密的量子数据上直接执行任意量子计算,而无需事先解密。这项技术对于构建真正隐私保护的…...

SpringCloud+Vue智慧云停车场服务管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略
让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 还在为足球经理游戏中千篇一律…...
)
当你的BERT模型被‘下毒’了怎么办?聊聊NLP后门攻击的实战检测与防御(附ONION、T-Miner工具实操)
当BERT模型遭遇后门攻击:一线工程师的检测与防御实战指南 在部署基于BERT的文本分类服务时,许多团队会忽略一个潜在威胁——模型可能已在训练阶段被植入后门。这类攻击极其隐蔽:模型对正常输入表现完美,但当遇到特定触发词&#x…...

从USB转TTL到RS485:手把手教你用一颗CH342F芯片玩转三种串口通信
CH342F芯片实战指南:一芯三用的串口通信解决方案 在物联网和工业控制领域,串口通信依然是设备间可靠数据传输的基石。面对多样化的接口标准(TTL、RS232、RS485),工程师常常需要准备多种转换模块。而CH342F芯片以其独特…...
)
从51到Linux:一个嵌入式工程师的五年踩坑与填坑全记录(附避坑清单)
从51到Linux:一个嵌入式工程师的五年踩坑与填坑全记录(附避坑清单) 五年前,当我第一次点亮51单片机的LED灯时,绝没想到这条路上会有这么多隐藏的陷阱。从寄存器配置的字节对齐问题,到Linux驱动中的竞态条件…...

从社交网络到疾病传播:ER随机图模型在实际场景中的仿真应用指南
从社交网络到疾病传播:ER随机图模型在实际场景中的仿真应用指南 在流行病学研究中,一个关键问题是如何预测疾病在人群中的传播速度和范围。想象一下,你是一名公共卫生官员,需要评估某种新型流感在小镇上的潜在传播风险。传统方法可…...

消息平台接入实战:Hermes Agent 实现微信/钉钉日常任务自动化的 4 步配置
1. 微信/钉钉自动化不是“接个API就完事”,而是上下文边界的重新定义 大多数人第一次配置 Hermes Agent 接入微信或钉钉时,会下意识打开官方文档,复制粘贴几行 webhook 配置,跑通一条“收到消息→回复‘你好’”的 demo 就以为大功告成。我试过三次——第一次在测试环境里…...

嵌入式Linux启动优化实战:从U-Boot到应用的全链路加速
1. 项目概述与优化价值作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我深知产品启动速度对于用户体验和系统性能的“第一印象”有多重要。尤其是在像全志T113这类面向工控、物联网、智能终端的应用处理器平台上,从按下电源键到应用界面就绪ÿ…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...