交易中的胜率和盈亏比估算
交易中的胜率和盈亏比估算
1.定义
胜率是指交易者在一定时间内成功交易的次数占总交易次数的比例。例如,如果交易者在10次交易中成功了6次,那么他的胜率就是60%。
盈亏比是指交易者每笔成功交易的盈利与每笔失败交易的亏损之间的比例。例如,如果交易者每笔成功交易盈利100元,而每笔失败交易亏损50元,那么他的盈亏比就是2:1。
2.计算逻辑
假设一个交易者在100次交易中的胜率为60%,盈亏比为2:1。模拟计算他的总盈利情况:
(1)确定交易者在100次交易中的成功次数和失败次数。根据胜率60%,成功次数为60次,失败次数为40次。
(2)计算每次成功交易和失败交易的盈亏情况。根据盈亏比2:1,每次成功交易盈利2单位,每次失败交易亏损1单位。
(3)将成功交易的盈利和失败交易的亏损相加,得到总盈利情况。即:60次成功交易×2单位盈利 - 40次失败交易×1单位亏损 = 120单位盈利 - 40单位亏损 = 80单位总盈利 。
3.简单模拟计算
实际交易中,胜率设为55%,盈亏比设为4:3,比较合理的范围。
代码:
import numpy as np
import pandas as pd
import random#定义维度,交易数量
v_size = 1000
# 定义概率分布 ,设置胜率
probabilities = [0.45, 0.55]
# 定义盈亏比 4:3
v_win = 400.0
v_loss = -300.0# 生成随机数组
arr_probability = np.random.choice([0,1], size=v_size, p=probabilities, replace=True) # 将随机数组转换为pandas Series
series_probability = pd.Series(arr_probability) df_profit = pd.DataFrame()
df_profit['probability'] = series_probability# 使用numpy生成一个长度为v_size的数组,全部填充0.0,然后转换为Series
series = pd.Series(np.zeros(v_size))
# 增加profit 列
df_profit['profit'] = seriesi = 0
# df遍历赋值,如果是1,盈利赋值,如果是0, 亏损赋值。
for index, row in df_profit.iterrows(): if row['probability'] == 1 :df_profit.loc[i,'profit'] = random.uniform(0.0, v_win) else :df_profit.loc[i,'profit'] = random.uniform(v_loss, 0.0) i += 1print('Profit: ',round(df_profit['profit'].sum(),2))
print('Win times: ',df_profit['probability'].sum())
print('Test times:',len(df_profit))
执行结果:
Profit: 51270.84
Win times: 583
Test times: 1000
交易次数:1000
盈利 51270.84 。
胜率是:58.3% 。
还是比较可观的。
当然,随着交易的次数增加,胜率会更接近55% 。
交易次数 :100000 。
Profit: 4283618.09
Win times: 55098
Test times: 100000
可以看到,胜率55.098% 。
4.模拟交易
上面的数据不容易看出投资本金,利润之间的关系。
将改进程序,更接近模拟交易过程,看看胜率和盈亏比对最终利润的影响。
import numpy as np
import pandas as pd
import random#定义维度,交易数量
v_size = 100
# 定义概率分布 ,设置胜率
probabilities = [0.45, 0.55]
# 定义盈亏比 4:3
v_win = 400.0
v_loss = -300.0# 初始资金
init_cash = 10000.0# 手续费 万二
v_comm = 0.0002# 当前现金 ,每次交易的仓位
position = 0.6# 生成随机数组
arr_probability = np.random.choice([0,1], size=v_size, p=probabilities, replace=True) # 将随机数组转换为pandas Series
series_probability = pd.Series(arr_probability) df_profit = pd.DataFrame()
df_profit['probability'] = series_probability# 使用numpy生成一个长度为v_size的数组,全部填充0.0,然后转换为Series
series = pd.Series(np.zeros(v_size)) # 每次交易的利润,含参与交易的本金
df_profit['profit'] = series# 每次交易的初始资金
df_profit['cash'] = series# 每次的仓位值
df_profit['position'] = series# 每次交易的佣金
df_profit['comm'] = seriesi = 0 # df遍历赋值,如果是1,盈利赋值,如果是0, 亏损赋值。
for index, row in df_profit.iterrows(): if row['probability'] == 1 :# 如果是首次交易if i == 0 :df_profit.loc[i,'cash'] = init_cashdf_profit.loc[i,'position'] = init_cash * positiondf_profit.loc[i,'profit'] = random.uniform(0.0, v_win) / 10000 * df_profit.loc[i,'position'] + df_profit.loc[i,'position'] # 盈利 df_profit.loc[i,'comm'] = abs(df_profit.loc[i,'profit']) * v_comm # 总是正值df_profit.loc[i,'profit'] = df_profit.loc[i,'profit'] - df_profit.loc[i,'comm']#非首次交易else :df_profit.loc[i,'cash'] = df_profit.loc[i-1,'cash'] - df_profit.loc[i-1,'position'] + df_profit.loc[i-1,'profit']df_profit.loc[i,'position'] = df_profit.loc[i,'cash'] * positiondf_profit.loc[i,'profit'] = random.uniform(0.0, v_win) / 10000 * df_profit.loc[i,'position'] + df_profit.loc[i,'position'] # 盈利 df_profit.loc[i,'comm'] = abs(df_profit.loc[i,'profit']) * v_comm # 总是正值df_profit.loc[i,'profit'] = df_profit.loc[i,'profit'] - df_profit.loc[i,'comm']else :# 如果是首次交易if i == 0 :df_profit.loc[i,'cash'] = init_cashdf_profit.loc[i,'position'] = init_cash * positiondf_profit.loc[i,'profit'] = random.uniform(v_loss, 0.0) / 10000 * df_profit.loc[i,'position'] + df_profit.loc[i,'position'] # 亏损df_profit.loc[i,'comm'] = abs(df_profit.loc[i,'profit']) * v_comm # 总是正值df_profit.loc[i,'profit'] = df_profit.loc[i,'profit'] - df_profit.loc[i,'comm']#非首次交易 else :df_profit.loc[i,'cash'] = df_profit.loc[i-1,'cash'] - df_profit.loc[i-1,'position'] + df_profit.loc[i-1,'profit']df_profit.loc[i,'position'] = df_profit.loc[i,'cash'] * positiondf_profit.loc[i,'profit'] = random.uniform(v_loss, 0.0) / 10000 * df_profit.loc[i,'position'] + df_profit.loc[i,'position'] # 亏损df_profit.loc[i,'comm'] = abs(df_profit.loc[i,'profit']) * v_comm # 总是正值df_profit.loc[i,'profit'] = df_profit.loc[i,'profit'] - df_profit.loc[i,'comm']i += 1#print('Profit: ',round(df_profit['profit'].sum(),2))
print('Win times: ',df_profit['probability'].sum())
print('Test times: ',len(df_profit))
print('Profit ratio %: ',round((df_profit.loc[v_size -1,'cash']/init_cash - 1)*100,2))
print('Last trade cash: ',round(df_profit.loc[v_size-1,'cash'],2))
print('Sum trade comm: ',round(df_profit['comm'].sum(),2))
# df_profit
结果:
Win times: 48
Test times: 100
Profit ratio %: 7.52
Last trade cash: 10752.08
Sum trade comm: 120.04
如果把交易次数设置1000
Win times: 550
Test times: 1000
Profit ratio %: 965.35
Last trade cash: 106534.91
Sum trade comm: 3919.97
相关文章:

交易中的胜率和盈亏比估算
交易中的胜率和盈亏比估算 1.定义 胜率是指交易者在一定时间内成功交易的次数占总交易次数的比例。例如,如果交易者在10次交易中成功了6次,那么他的胜率就是60%。 盈亏比是指交易者每笔成功交易的盈利与每笔失败交易的亏损之间的比例。例如࿰…...

mysql RR、RC隔离级别实现原理
事务隔离级别实现过程 快照读(select语句) 获取事务自己版本号,即事务 ID获取 Read View 查询得到数据,然后 Read View 中事务版本号进行比较。如果不符合 Read View 可见性规则(看最新数据还是副本里的数据…...

c语言--指针数组(详解)
目录 一、什么是指针数组?二、指针数组模拟二维数组 一、什么是指针数组? 指针数组是指针还是数组? 我们类比一下,整型数组,是存放整型的数组,字符数组是存放字符的数组。 那指针数组呢?是存放…...

Elasticsearch单个索引数据量过大的优化
当Elasticsearch(ES)中的单个索引(index)的数据量变得过大时,可能会遇到性能下降、查询缓慢、管理困难等问题。为了优化和应对大索引的挑战,可以考虑以下策略: 1. 使用分片和副本 分片…...
Java安全 CC链1分析(Lazymap类)
Java安全 CC链1分析 前言CC链分析CC链1核心LazyMap类AnnotationInvocationHandler类 完整exp: 前言 在看这篇文章前,可以看下我的上一篇文章,了解下cc链1的核心与环境配置 Java安全 CC链1分析 前面我们已经讲过了CC链1的核心ChainedTransf…...
【lesson51】信号之信号处理
文章目录 信号处理可重入函数volatileSIGCHLD信号 信号处理 信号产生之后,信号可能无法被立即处理,一般在合适的时候处理。 1.在合适的时候处理(是什么时候?) 信号相关的数据字段都是在进程PCB内部。 而进程工作的状态…...
分享springboot框架的一个开源的本地开发部署教程(若依开源项目开发部署过程分享持续更新二开宝藏项目MySQL数据库版)
1首先介绍下若依项目: 若依是一个基于Spring Boot和Spring Cloud技术栈开发的多租户权限管理系统。该开源项目提供了一套完整的权限管理解决方案,包括用户管理、角色管理、菜单管理、部门管理、岗位管理等功能。 若依项目采用前后端分离的架构…...

leetcode:131.分割回文串
树形结构: 切割到字符串的尾部,就是叶子节点。 回溯算法三部曲: 1.递归的参数和返回值: 参数字符串s和startIndex切割线 2.确定终止条件: 当分割线到字符串末尾时到叶子节点,一种方案出现 3.单层搜索…...

Linux下的json-c
一、json-c库的安装(ubuntu) root用户运行以下命令: apt-get install libjson0-dev libjson0非root用户运行以下命令: sudo apt-get install libjson0-dev libjson0二、解析json数据 1. json_object json_object是JSON-C库中定义的一个结构体&#…...
[C#] 如何使用ScottPlot.WPF在WPF桌面程序中绘制图表
什么是ScottPlot.WPF? ScottPlot.WPF 是一个开源的数据可视化库,用于在 WPF 应用程序中创建高品质的绘图和图表。它是基于 ScottPlot 库的 WPF 版本,提供了简单易用的 API,使开发人员能够通过简单的代码创建各种类型的图表&#…...
如何修复Mac的“ kernel_task” CPU使用率过高的Bug?
当计算机开始缓慢运行时,这从来都不是一件有趣的事情,但是当您弄不清它为何如此缓慢时,甚至会变得更糟。如果您已经关闭了所有程序,并且Mac上的所有内容仍然感觉像是在糖蜜中移动,这可能是令人讨厌的kernel_task导致高…...
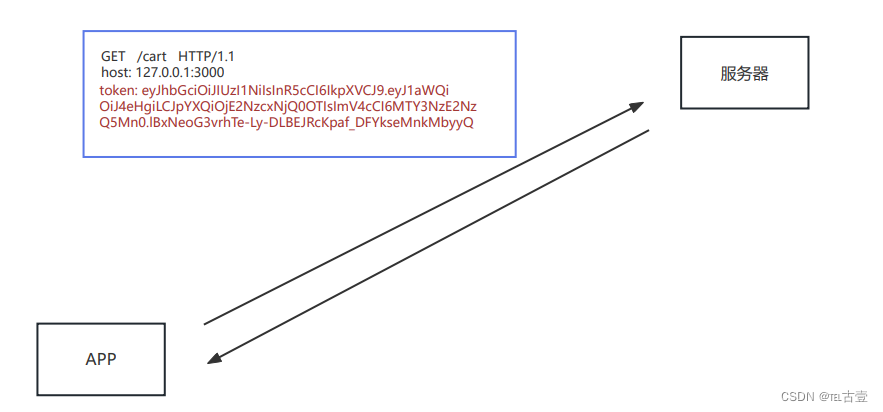
【NodeJS】006- API模块与会话控制介绍d
1.简介 1.1 接口是什么 接口是 前后端通信的桥梁 简单理解:一个接口就是 服务中的一个路由规则 ,根据请求响应结果 接口的英文单词是 API (Application Program Interface),所以有时也称之为 API 接口 这里的接口指的是『数据接口』&#…...

[UI5 常用控件] 08.Wizard,NavContainer
文章目录 前言1. Wizard1.1 基本结构1.2 属性1.2.1 Wizard:complete1.2.2 Wizard:finishButtonText1.2.3 Wizard:currentStep1.2.4 Wizard:backgroundDesign1.2.5 Wizard:enableBranching1.2.6 WizardStep:…...
EasyExcel分页上传数据
EasyExcel分页上传数据 一、实例 controller上传入口 PostMapping("/upload")ResponseBodyLog(title "导入工单", businessType BusinessType.IMPORT)public AjaxResult uploadFile(HttpServletRequest request, MultipartFile files) throws Exceptio…...
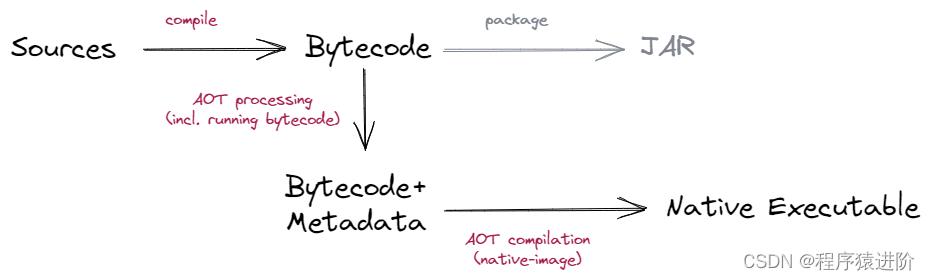
Spring Native 解放 JVM
一、Spring Native 是什么 Spring Native可以通过GraalVM将Spring应用程序编译成原生镜像,提供了一种新的方式来部署Spring应用。与Java虚拟机相比,原生镜像可以在许多场景下降低工作负载,包括微服务,函数式服务,非常…...

汇编的两道题
1.编写一个在显示器上显示一个笑脸字符的程序 看这段程序的结构,可以看出,每个代码段,带有segment的必须用ASSUME 来进行段分配。 PROG1 SEGMENT;PROG1段的开始ASSUME CS:PROG1;PROG1(自己命名的,叫啥都可以ÿ…...
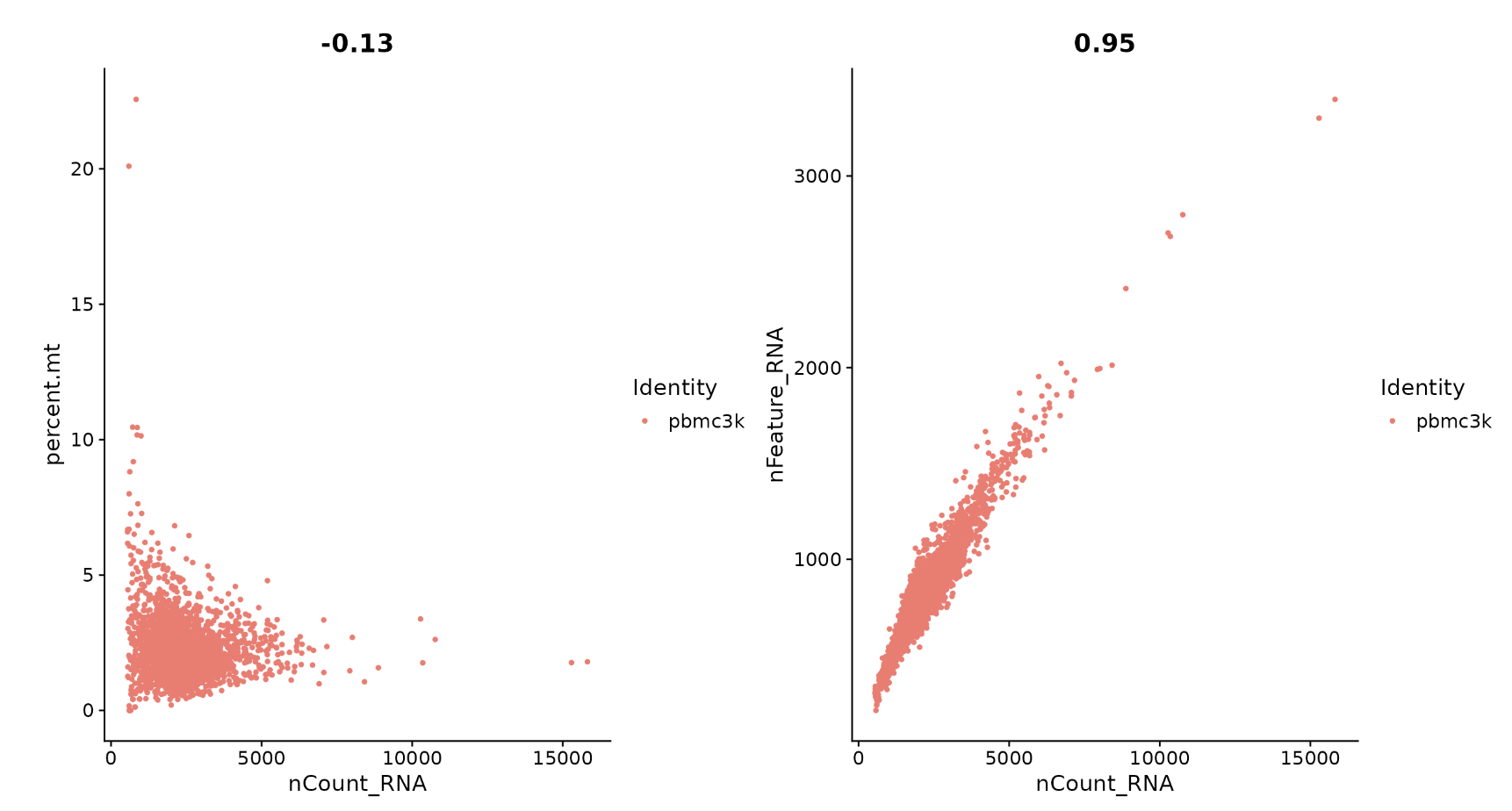
Seurat - 聚类教程 (1)
设置 Seurat 对象 在本教程[1]中,我们将分析 10X Genomics 免费提供的外周血单核细胞 (PBMC) 数据集。在 Illumina NextSeq 500 上对 2,700 个单细胞进行了测序。可以在此处[2]找到原始数据。 我们首先读取数据。 Read10X() 函数从 10X 读取 cellranger 管道的输出&…...

Mac 版 Excel 和 Windows 版 Excel的区别
Excel是一款由微软公司开发的电子表格程序,广泛应用于数据处理、分析和可视化等领域。它提供了丰富的功能和工具,包括公式、函数、图表和数据透视表等,帮助用户高效地处理和管理大量数据。同时,Excel还支持与其他Office应用程序的…...
【报错解决】-bash: export: `-8‘: not a valid identifier 不是有效的标识符
现象 一登陆就提示-bash: export: -8’: not a valid identifier 不是有效的标识符 问题出现的原因 设置字符集时多写了空格 [rootdb1 ~]# cat >>/etc/profile<<EOF export LANGen_US.UTF -8(-8前不应有空格) EOF 解决方法 cd /etc vi profile 把export带有-8的…...

Docker-Learn(三)创建镜像Docker(换源)
根据之前的内容基础,本小点的内容主要涉及到的内容是比较重要的文本Dockerfile 1. 编辑Dockerfile 启动命令行终端(在自己的工作空间当中),创建和编辑Dockerfile。 vim Dockerfile然后写入以下内容 # 使用一个基础镜像 FROM ubuntu:late…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

婚礼技能库:用开源协作与项目管理思维打造个性化婚礼
1. 项目概述:婚礼技能库的诞生与价值婚礼,对大多数人来说,是人生中为数不多的、需要同时扮演项目经理、创意总监、财务主管和情感联络员的高压事件。筹备过程琐碎繁杂,从场地布置、流程设计,到妆发造型、摄影摄像&…...
深入Transformer内部:LoRA到底改动了哪部分权重才让模型“学会”新任务?
深入Transformer内部:LoRA如何通过低秩更新重塑大模型能力 在自然语言处理领域,大型预训练模型的微调一直是个计算密集型任务。传统全参数微调需要更新数十亿甚至数千亿参数,这对大多数研究者和企业来说都是难以承受的负担。低秩适应(LoRA)技…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

Ash印相渲染失败率骤升47%?紧急预警:V6.2更新后Gamma 2.2→2.4迁移引发的印相断层危机
更多请点击: https://intelliparadigm.com 第一章:Ash印相渲染失败率骤升47%的全局现象与危机定性 近期,全球多个采用 Ash 印相引擎(v3.8.2)的影像处理平台集中报告渲染任务异常终止、输出空白或超时中断。监控数据显…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...

Arm Iris组件参数化建模与调试实践
1. Arm Iris组件概述与核心价值Arm Iris组件是Fast Models仿真平台中的关键模块,它为芯片设计验证和软件开发提供了高度参数化的虚拟原型环境。作为一名长期从事Arm架构开发的工程师,我发现Iris组件的设计理念完美体现了"配置即硬件"的思想——…...