Seurat - 聚类教程 (1)
设置 Seurat 对象
在本教程[1]中,我们将分析 10X Genomics 免费提供的外周血单核细胞 (PBMC) 数据集。在 Illumina NextSeq 500 上对 2,700 个单细胞进行了测序。可以在此处[2]找到原始数据。
我们首先读取数据。 Read10X() 函数从 10X 读取 cellranger 管道的输出,返回唯一的分子识别 (UMI) 计数矩阵。该矩阵中的值表示在每个细胞(列)中检测到的每个特征(即基因;行)的分子数量。请注意,较新版本的 cellranger 现在也使用 h5 文件格式进行输出,可以使用 Seurat 中的 Read10X_h5() 函数读取该格式。
接下来我们使用计数矩阵来创建 Seurat 对象。该对象充当容器,其中包含单细胞数据集的数据(如计数矩阵)和分析(如 PCA 或聚类结果)。例如,在 Seurat v5 中,计数矩阵存储在 pbmc[["RNA"]]$counts 中。
library(dplyr)
library(Seurat)
library(patchwork)
# Load the PBMC dataset
pbmc.data <- Read10X(data.dir = "/brahms/mollag/practice/filtered_gene_bc_matrices/hg19/")
# Initialize the Seurat object with the raw (non-normalized data).
pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k", min.cells = 3, min.features = 200)
pbmc
-
输出
## An object of class Seurat
## 13714 features across 2700 samples within 1 assay
## Active assay: RNA (13714 features, 0 variable features)
## 1 layer present: counts
-
示例
# Lets examine a few genes in the first thirty cells
pbmc.data[c("CD3D", "TCL1A", "MS4A1"), 1:30]
# 输出
## 3 x 30 sparse Matrix of class "dgCMatrix"
##
## CD3D 4 . 10 . . 1 2 3 1 . . 2 7 1 . . 1 3 . 2 3 . . . . . 3 4 1 5
## TCL1A . . . . . . . . 1 . . . . . . . . . . . . 1 . . . . . . . .
## MS4A1 . 6 . . . . . . 1 1 1 . . . . . . . . . 36 1 2 . . 2 . . . .
矩阵中.的值代表 0(未检测到分子)。由于 scRNA-seq 矩阵中的大多数值都是 0,因此 Seurat 只要有可能就使用稀疏矩阵表示。这会显著节省 Drop-seq/inDrop/10x 数据的内存和速度。
dense.size <- object.size(as.matrix(pbmc.data))
dense.size
## 709591472 bytes
sparse.size <- object.size(pbmc.data)
sparse.size
## 29905192 bytes
dense.size/sparse.size
## 23.7 bytes
预处理
以下步骤涵盖 Seurat 中 scRNA-seq 数据的标准预处理工作流程。这些基于 QC 指标、数据标准化和缩放以及高度可变特征的检测的细胞选择和过滤。
Seurat 允许您轻松探索 QC 指标并根据任何用户定义的标准过滤细胞。常用的一些 QC 指标包括:
-
每个细胞中检测到的唯一(unique)基因的数量 -
低质量的细胞或空液滴通常含有很少的基因 -
细胞双联体或多联体可能表现出异常高的基因计数
-
-
同样,细胞内检测到的分子总数(与唯一(unique)基因密切相关) -
映射到线粒体基因组的读数百分比 -
低质量/垂死细胞通常表现出广泛的线粒体污染 -
我们使用 PercentageFeatureSet() 函数计算线粒体 QC 指标,该函数计算源自一组特征的计数百分比 -
我们使用以 MT- 开头的所有基因的集合作为线粒体基因的集合
-
# The [[ operator can add columns to object metadata. This is a great place to stash QC stats
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
-
Seurat 中的 QC 指标存储在哪里?
在下面的示例中,我们将 QC 指标可视化,并使用它们来过滤细胞。
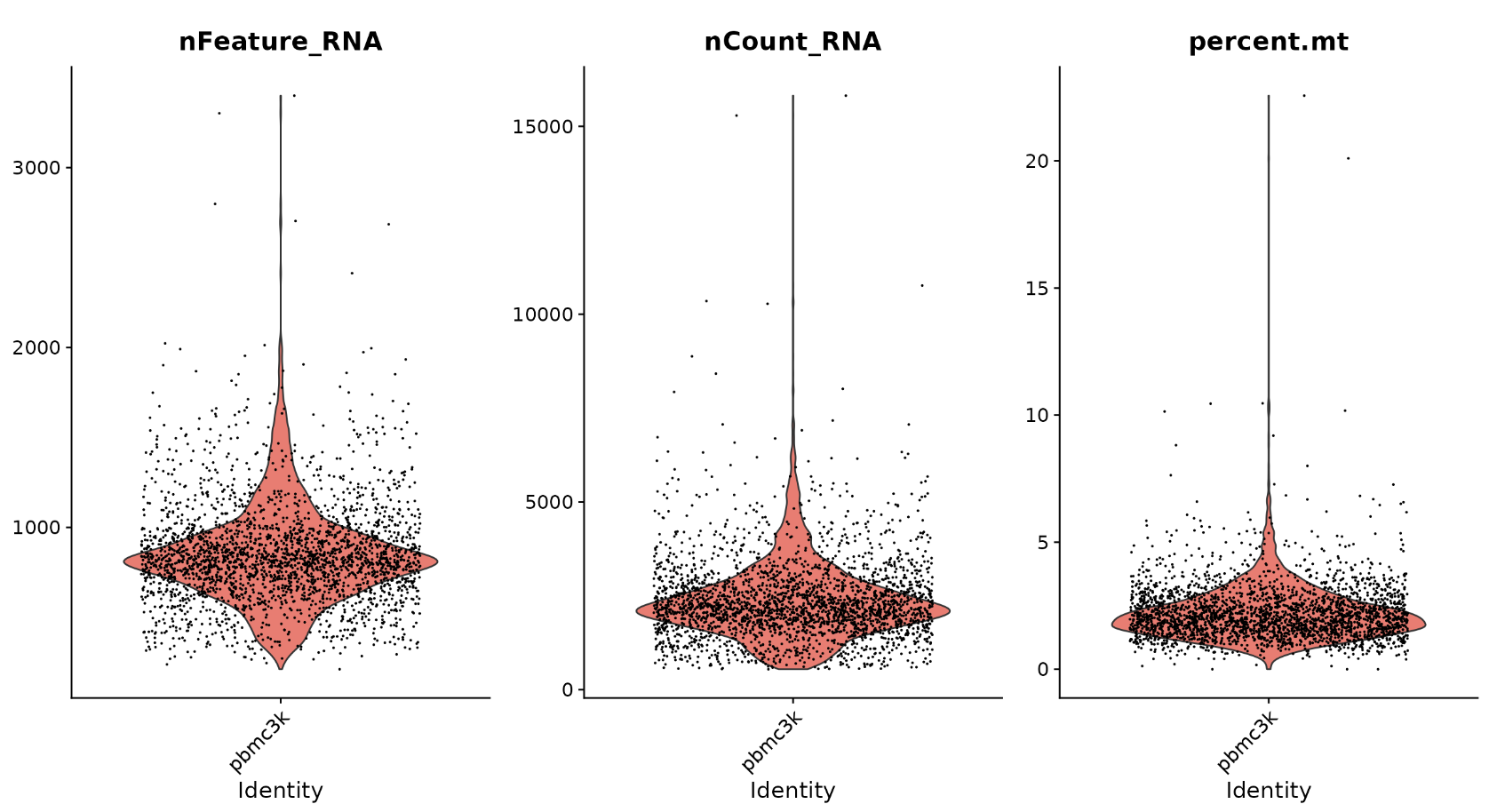
我们过滤具有唯一特征计数超过 2,500 或少于 200 的细胞;我们过滤线粒体计数 >5% 的细胞
# Visualize QC metrics as a violin plot
VlnPlot(pbmc, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)
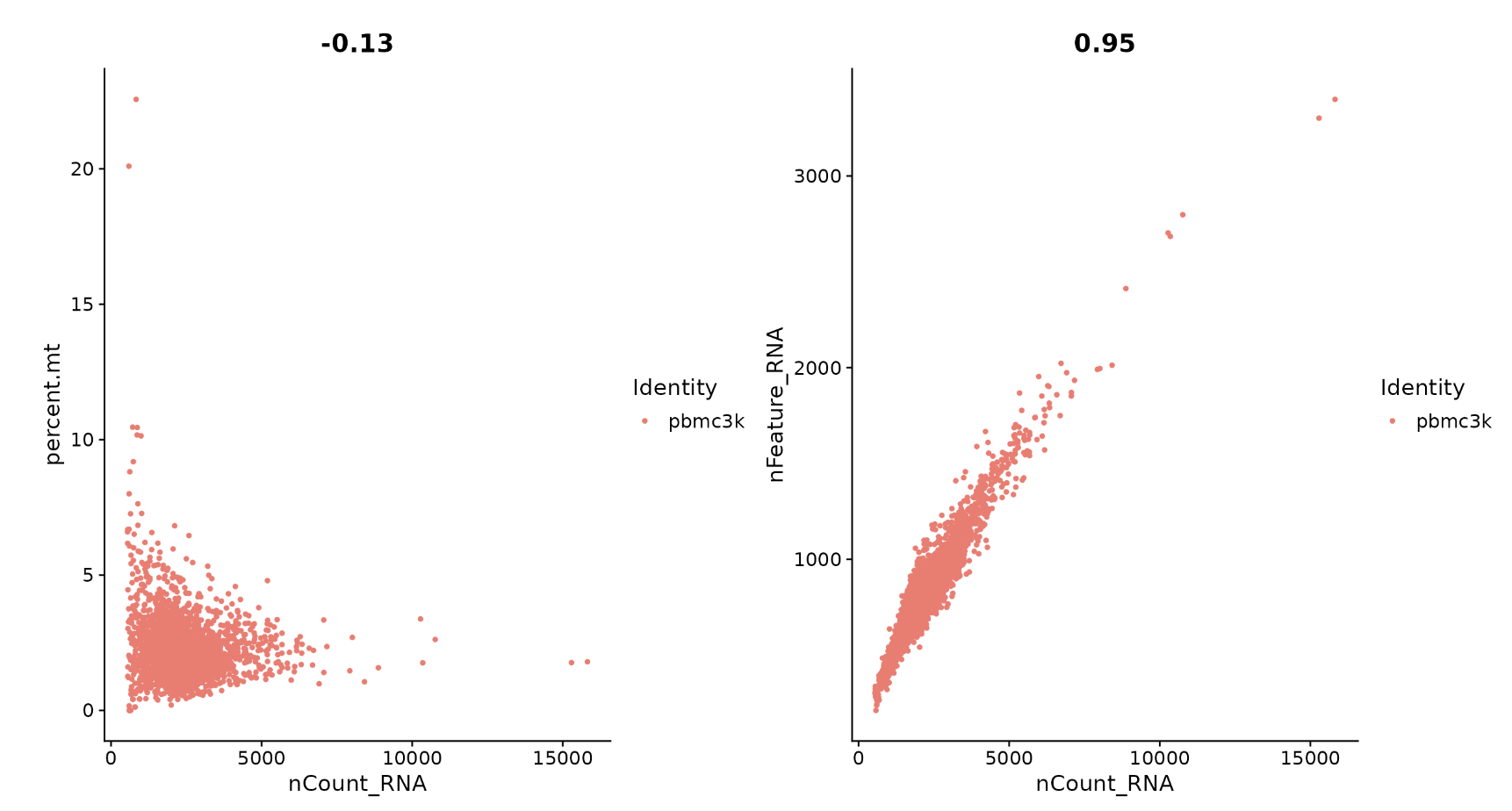
# FeatureScatter is typically used to visualize feature-feature relationships, but can be used
# for anything calculated by the object, i.e. columns in object metadata, PC scores etc.
plot1 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "percent.mt")
plot2 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
plot1 + plot2
pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5)
未完待续,持续关注!
Source: https://zenghensatijalab.org/seurat/articles/pbmc3k_tutorial
[2]data: https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz
本文由 mdnice 多平台发布
相关文章:
Seurat - 聚类教程 (1)
设置 Seurat 对象 在本教程[1]中,我们将分析 10X Genomics 免费提供的外周血单核细胞 (PBMC) 数据集。在 Illumina NextSeq 500 上对 2,700 个单细胞进行了测序。可以在此处[2]找到原始数据。 我们首先读取数据。 Read10X() 函数从 10X 读取 cellranger 管道的输出&…...

Mac 版 Excel 和 Windows 版 Excel的区别
Excel是一款由微软公司开发的电子表格程序,广泛应用于数据处理、分析和可视化等领域。它提供了丰富的功能和工具,包括公式、函数、图表和数据透视表等,帮助用户高效地处理和管理大量数据。同时,Excel还支持与其他Office应用程序的…...
【报错解决】-bash: export: `-8‘: not a valid identifier 不是有效的标识符
现象 一登陆就提示-bash: export: -8’: not a valid identifier 不是有效的标识符 问题出现的原因 设置字符集时多写了空格 [rootdb1 ~]# cat >>/etc/profile<<EOF export LANGen_US.UTF -8(-8前不应有空格) EOF 解决方法 cd /etc vi profile 把export带有-8的…...

Docker-Learn(三)创建镜像Docker(换源)
根据之前的内容基础,本小点的内容主要涉及到的内容是比较重要的文本Dockerfile 1. 编辑Dockerfile 启动命令行终端(在自己的工作空间当中),创建和编辑Dockerfile。 vim Dockerfile然后写入以下内容 # 使用一个基础镜像 FROM ubuntu:late…...
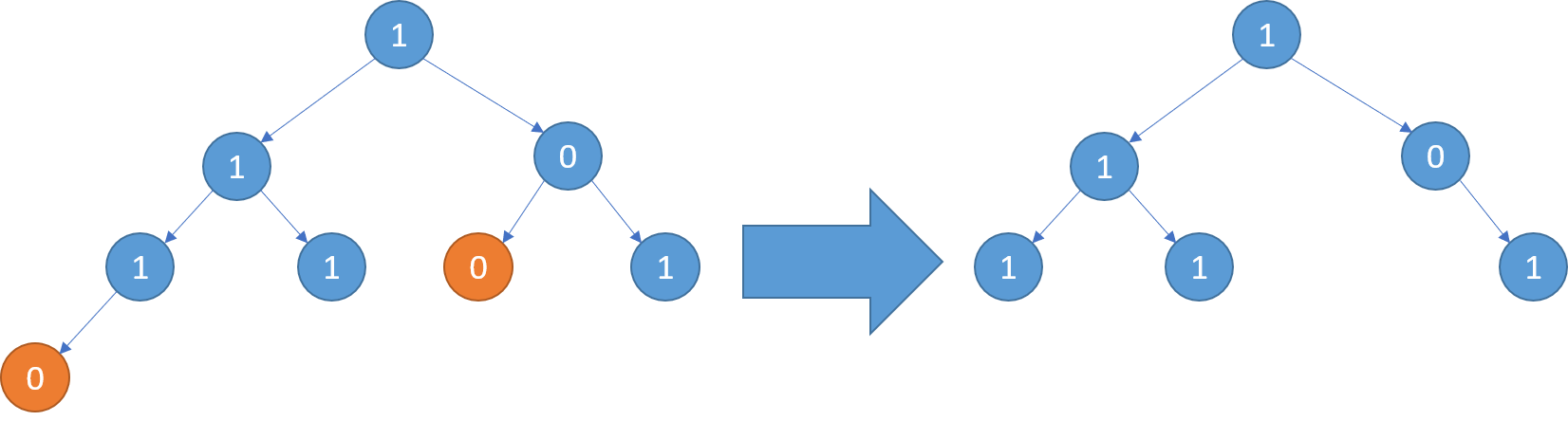
「递归算法」:二叉树剪枝
一、题目 给你二叉树的根结点 root ,此外树的每个结点的值要么是 0 ,要么是 1 。 返回移除了所有不包含 1 的子树的原二叉树。 节点 node 的子树为 node 本身加上所有 node 的后代。 示例 1: 输入:root [1,null,0,0,1] 输出&…...
)
Kafka下载(kafka和jdk、zookeeper、SpringBoot的版本对应关系)
文章目录 一、准备工作1、必须环境2、kafka使用自带的zookeeper还是自己单独部署zookeeper?二、下载一、准备工作 1、必须环境 kafka本身的开发语言是Scala,而Scala是基于jdk开发的,所以要先安装jdk kafka版本jdk版本kafka使用jdk版本官网说明1.0建议使用1.8https://kafka.…...

自然语言NLP
什么是NLP NLP(Natural Language Processing)是自然语言处理的缩写,是计算机科学和人工智能领域的一个研究方向。NLP致力于使计算机能够理解、处理和生成人类自然语言的能力。通过NLP技术,计算机可以通过识别和理解语言中的文本…...
-std::list)
容器库(5)-std::list
std::forward_list是可以从任何位置快速插入和移除元素的容器,不支持快速随机访问,支持正向和反向的迭代。 本文章的代码库: https://gitee.com/gamestorm577/CppStd 成员函数 构造、析构和赋值 构造函数 可以用元素、元素列表、迭代器…...

配置VMware实现从服务器到虚拟机的一键启动脚本
正文共:1666 字 15 图,预估阅读时间:2 分钟 首先祝大家新年快乐!略备薄礼,18000个红包封面来讨个开年好彩头! 虽然之前将服务器放到了公网(成本增加了100块,内网服务器上公网解决方案…...
第5讲小程序微信用户登录实现
小程序微信用户登录实现 小程序登录和jwt,httpclient工具类详细介绍可以看下小锋老师的 小程序电商系统课程:https://www.bilibili.com/video/BV1kP4y1F7tU application.yml加上小程序登录需要的参数,小伙伴们可以登录小程序后台管理&#…...
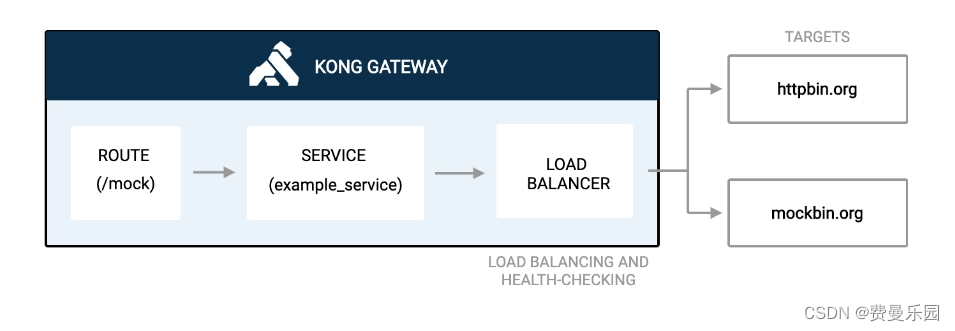
Kong 负载均衡
负载均衡是一种将API请求流量分发到多个上游服务的方法。负载均衡可以提高整个系统的响应速度,通过防止单个资源过载而减少故障。 在以下示例中,您将使用部署在两台不同服务器或上游目标上的应用程序。Kong网关需要在这两台服务器之间进行负载均衡&…...
基于Chrome插件的Chatgpt对话无损导出markdown格式(Typora完美显示)
Google插件名称为:ChatGPT to MarkDown plus, 下载地址为ChatGPT to MarkDown plus使用方法:见GitHub主页或插件介绍页面https://github.com/thisisbaiy/ChatGPT-To-Markdown-google-plugin/tree/main 我将源代码上传至了GitHub,欢迎star, Is…...

react函数组件中使用context
效果 1.在父组件中创建一个createcontext并将他导出 import React, { createContext } from react import Bpp from ./Bpp import Cpp from ./Cpp export let MyContext createContext(我是组件B) export let Ccontext createContext(我是组件C)export default function App…...
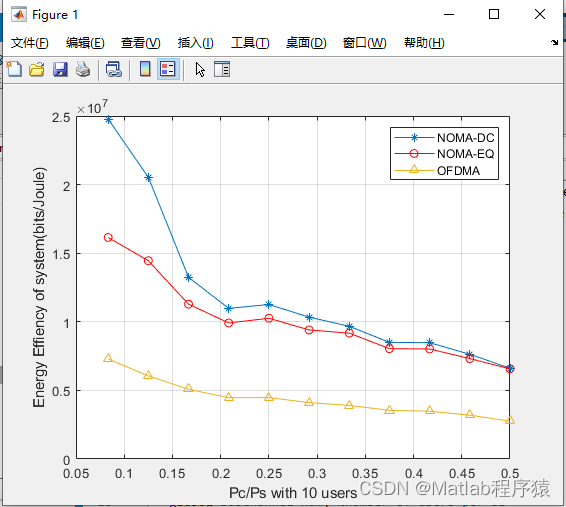
【MATLAB源码-第137期】基于matlab的NOMA系统和OFDMA系统对比仿真。
操作环境: MATLAB 2022a 1、算法描述 NOMA(非正交多址)和OFDMA(正交频分多址)是两种流行的无线通信技术,广泛应用于现代移动通信系统中,如4G、5G和未来的6G网络。它们的设计目标是提高频谱效…...

【FPGA Verilog】各种加法器Verilog
1bit半加器adder设计实例 module adder(cout,sum,a,b); output cout; output sum; input a,b; wire cout,sum; assign {cout,sum}ab; endmodule 解释说明 (1)assign {cout,sum}ab 是连续性赋值 对于线网wire进行赋值,必须以assign或者dea…...
)
【MySQL】-21 MySQL综合-7(MySQL主键+MySQL外检约束+MySQL唯一约束+MySQL检查约束)
MySQL主键MySQL外检约束MySQL唯一约束MySQL检查约束 MySQL主键选取设置主键约束的字段在创建表时设置主键约束在创建表时设置复合主键在修改表时添加主键约束 MySQL外键约束选取设置 MySQL 外键约束的字段在创建表时设置外键约束在修改表时添加外键约束删除外键约束 MySQL唯一约…...
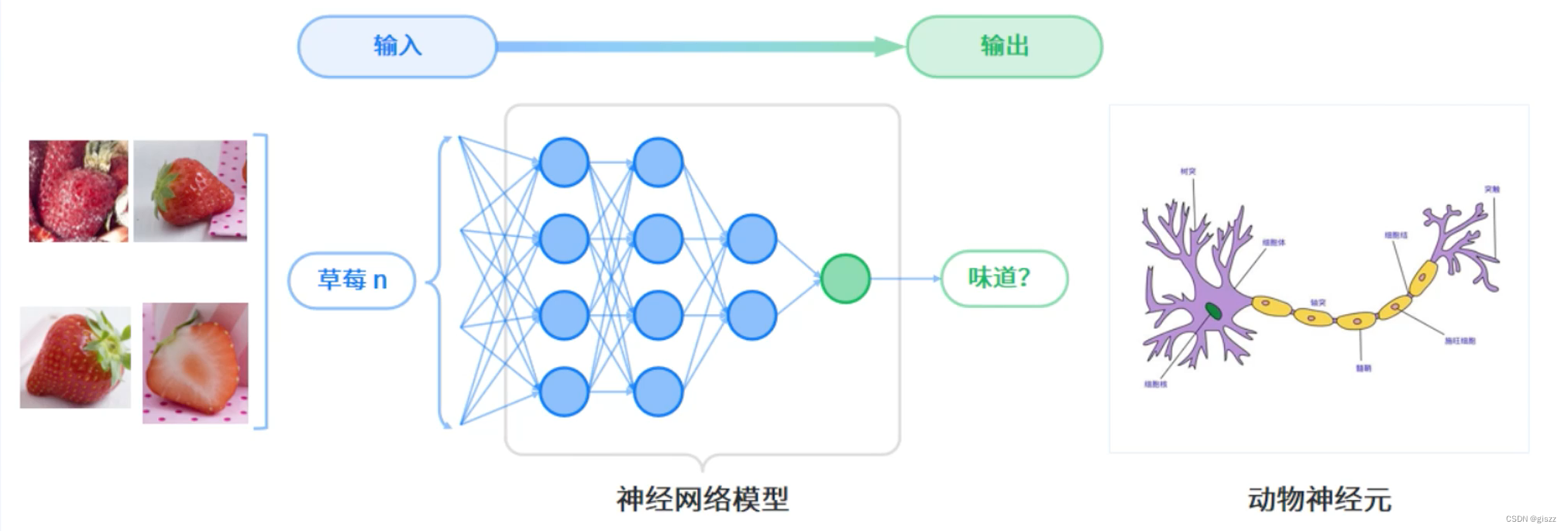
【大厂AI课学习笔记】【1.6 人工智能基础知识】(3)神经网络
深度学习是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅草莓照片)可以使用 多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。 深度学习的最主要特征是使用神经网络作为计算模型。神经网络模型 …...
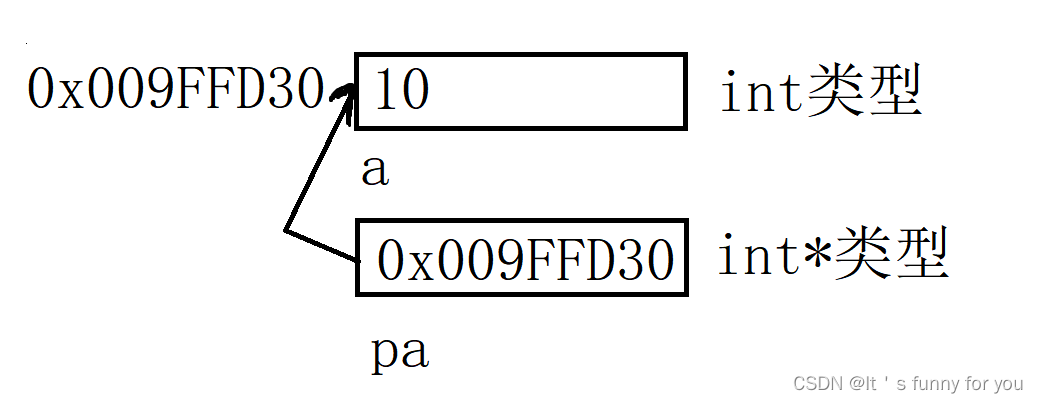
指针的基本含义及其用法
1.前言 在学习C语言的时候,我们会经常接触一个概念,指针和地址,关于这两个概念很多人并不能理解地十分透彻,接下来我将详细介绍一下这两者的概念 2.地址 我们知道计算机的上CPU(中央处理器)在处理数据的时…...

黄金交易策略(Nerve Nnife.mql4):趋势做单
完整EA:Nerve Knife.ex4黄金交易策略_黄金趋势ea-CSDN博客 当大小趋势相同行情走向也相同,就会开仓做顺势单,并会顺势追单,以达到快速止盈平仓的效果。大趋势追求稳定,小趋势追求敏捷,行情走向比小趋势更敏…...
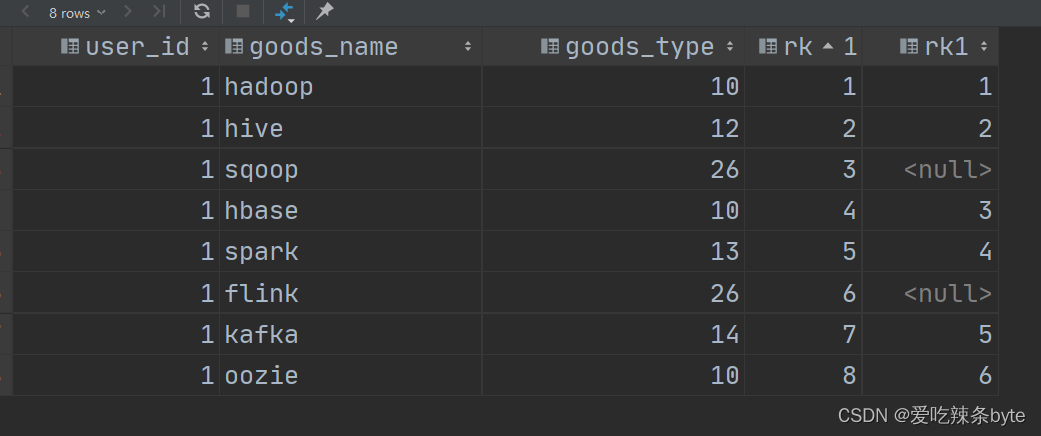
HiveSQL——条件判断语句嵌套windows子句的应用
注:参考文章: SQL条件判断语句嵌套window子句的应用【易错点】--HiveSql面试题25_sql剁成嵌套判断-CSDN博客文章浏览阅读920次,点赞4次,收藏4次。0 需求分析需求:表如下user_idgood_namegoods_typerk1hadoop1011hive1…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

城通网盘高速解析终极指南:如何免费实现40倍下载提速
城通网盘高速解析终极指南:如何免费实现40倍下载提速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的蜗牛下载速度?每次下载大文件都要面对漫长…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制
OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中的卡顿和帧率限制?Open…...

从零构建可定制对话系统:架构设计、RAG与智能体实战
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“customized-chat”。这名字听起来可能有点泛,但它的核心目标非常明确:打造一个完全由你自己掌控、能深度融入你特定业务逻辑或知识体系的对话…...

Ash印相渲染失败率骤升47%?紧急预警:V6.2更新后Gamma 2.2→2.4迁移引发的印相断层危机
更多请点击: https://intelliparadigm.com 第一章:Ash印相渲染失败率骤升47%的全局现象与危机定性 近期,全球多个采用 Ash 印相引擎(v3.8.2)的影像处理平台集中报告渲染任务异常终止、输出空白或超时中断。监控数据显…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

Claude-Code-Board:构建AI编程工作台,提升开发效率与协作
1. 项目概述与核心价值最近在GitHub上看到一个名为“Claude-Code-Board”的项目,作者是cablate。这个项目标题直译过来就是“Claude代码板”,听起来像是一个与AI编程助手Claude相关的工具。作为一名长期在开发一线摸爬滚打的程序员,我对这类能…...
)
不止于统计:用ArcGIS Model Builder自动化你的土地利用转移矩阵(附模型下载与修改教程)
从手动到智能:ArcGIS Model Builder在土地利用分析中的高阶自动化实践 当规划师面对十年间的土地利用变化数据时,传统的手工操作流程往往成为效率瓶颈。每增加一个研究时段,就需要重复执行数据融合、空间相交、表格导出和矩阵制作等标准化操作…...

2026年实测推荐:10款思维导图工具,开发者效率翻倍
作为技术博主,我常年用思维导图拆解需求、梳理架构、记录学习笔记。2026年,工具们卷出了新高度:AI辅助、白板一体化、实时协作成了标配。本文从开发者视角出发,实测了10款热门工具,帮你选出最适合的那把“瑞士军刀”。…...