DataX源码分析 reader
系列文章目录
一、DataX详解和架构介绍
二、DataX源码分析 JobContainer
三、DataX源码分析 TaskGroupContainer
四、DataX源码分析 TaskExecutor
五、DataX源码分析 reader
六、DataX源码分析 writer
七、DataX源码分析 Channel
文章目录
- 系列文章目录
- 前言
- Reader组件如何处理各类数据源
- 源码
前言
DataX的Reader组件负责从数据源中读取数据,并将这些数据转换成DataX框架可以处理的数据格式。DataX的Reader组件采用了插件化的设计,使得添加新的数据源类型变得相对容易。只需要实现相应的Reader接口或抽象类,并提供必要的配置参数,就可以将新的数据源集成到DataX框架中。这种可扩展性使得DataX能够适应不断变化的数据环境。Reader通常与特定的数据源绑定,每种数据源类型可能都需要一个独立的Reader实现。
以下是一个简化的源码分析步骤,以DataX的MySQLReader为例:
初始化:
在DataX的任务配置文件中,会指定使用哪种Reader,并配置相应的参数,如MySQL的连接信息、查询SQL等。这些信息会被解析并传递给Reader。
构建Reader:
根据配置文件中指定的Reader类型,DataX会动态地创建相应的Reader实例。对于MySQLReader,它会调用MysqlReader.Builder来构建Reader对象。
任务准备:
Reader会执行一些准备工作,如建立与数据源的连接、准备查询语句等。对于MySQLReader,这通常包括调用openConnection方法建立数据库连接,以及调用prepare方法准备SQL查询。
读取数据:
Reader的核心功能是从数据源中读取数据。对于MySQLReader,这通常涉及到执行SQL查询,并遍历查询结果集。Reader可能会使用多线程或分批处理的方式来提高读取效率。
数据转换:
读取到的原始数据可能需要进行一些转换,以满足DataX框架或目标Writer的要求。这可能包括数据类型转换、数据清洗等。
发送数据:
读取并转换后的数据会发送给DataX的Framework,由Framework负责将数据写入目标Writer。
关闭资源:
在读取任务完成后,Reader会负责关闭与数据源相关的资源,如数据库连接等。
Reader组件如何处理各类数据源
DataX的Reader组件处理不同的数据源类型主要是通过抽象和扩展的机制来实现的。具体来说,DataX框架为每种数据源类型定义了一个Reader接口或抽象类,并为每种具体的数据源实现了相应的Reader类。
以下是DataX的Reader组件如何处理不同数据源类型的基本步骤:
抽象定义:
DataX首先定义了一个抽象的Reader接口或抽象类,该接口或抽象类定义了一组通用的方法,如init(初始化)、prepare(准备)、post(读取数据)和close(关闭资源)等。这些方法为Reader提供了统一的生命周期和数据处理流程。
具体实现:
对于每种数据源类型,DataX会创建一个具体的Reader类来实现上述接口或抽象类。例如,对于MySQL数据源,会有一个MysqlReader类;对于Oracle数据源,会有一个OracleReader类。这些具体的Reader类会根据数据源的特性来实现接口中定义的方法。
配置文件解析:
当DataX启动一个数据同步任务时,它会首先解析任务配置文件(通常是JSON格式)。配置文件中包含了任务的各种参数,包括数据源类型、Reader类型、Writer类型以及各自的配置参数。
动态加载:
DataX框架会根据配置文件中的Reader类型动态加载相应的Reader实现类。这通常是通过反射机制实现的,即根据Reader类型的字符串名称,在运行时动态加载并实例化对应的Reader类。
调用Reader方法:
一旦Reader类被加载并实例化,DataX框架会按照定义的生命周期方法调用Reader的相应方法。例如,首先调用init方法进行初始化,然后调用prepare方法准备数据源连接和查询,接着调用post方法读取数据,并在任务完成后调用close方法关闭资源。
数据转换:
在读取数据的过程中,Reader可能需要对数据进行一些转换或适配,以便与DataX框架的数据处理流程兼容。这可能包括数据类型转换、字段重命名、数据清洗等。
错误处理与日志记录:
Reader实现类还需要处理可能出现的错误和异常,并记录必要的日志信息。这有助于在数据同步过程中出现问题时进行故障排查和问题定位。
通过以上步骤,DataX的Reader组件能够灵活处理不同类型的数据源,并实现了数据从数据源到DataX框架的顺畅传输。同时,这种抽象和扩展的机制也使得DataX框架易于扩展,可以方便地添加对新数据源类型的支持。
源码
/*** 每个Reader插件在其内部内部实现Job、Task两个内部类。* * * */
public abstract class Reader extends BaseObject {/*** 每个Reader插件必须实现Job内部类。* * */public static abstract class Job extends AbstractJobPlugin {/*** 切分任务* * @param adviceNumber* * 着重说明下,adviceNumber是框架建议插件切分的任务数,插件开发人员最好切分出来的任务数>=* adviceNumber。<br>* <br>* 之所以采取这个建议是为了给用户最好的实现,例如框架根据计算认为用户数据存储可以支持100个并发连接,* 并且用户认为需要100个并发。 此时,插件开发人员如果能够根据上述切分规则进行切分并做到>=100连接信息,* DataX就可以同时启动100个Channel,这样给用户最好的吞吐量 <br>* 例如用户同步一张Mysql单表,但是认为可以到10并发吞吐量,插件开发人员最好对该表进行切分,比如使用主键范围切分,* 并且如果最终切分任务数到>=10,我们就可以提供给用户最大的吞吐量。 <br>* <br>* 当然,我们这里只是提供一个建议值,Reader插件可以按照自己规则切分。但是我们更建议按照框架提供的建议值来切分。 <br>* <br>* 对于ODPS写入OTS而言,如果存在预排序预切分问题,这样就可能只能按照分区信息切分,无法更细粒度切分,* 这类情况只能按照源头物理信息切分规则切分。 <br>* <br>* * * */public abstract List<Configuration> split(int adviceNumber);}public static abstract class Task extends AbstractTaskPlugin {public abstract void startRead(RecordSender recordSender);}
}
public class MysqlReader extends Reader {private static final DataBaseType DATABASE_TYPE = DataBaseType.MySql;public static class Job extends Reader.Job {private static final Logger LOG = LoggerFactory.getLogger(Job.class);private Configuration originalConfig = null;private CommonRdbmsReader.Job commonRdbmsReaderJob;@Overridepublic void init() {this.originalConfig = super.getPluginJobConf();Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);if (userConfigedFetchSize != null) {LOG.warn("对 mysqlreader 不需要配置 fetchSize, mysqlreader 将会忽略这项配置. 如果您不想再看到此警告,请去除fetchSize 配置.");}this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);this.commonRdbmsReaderJob.init(this.originalConfig);}@Overridepublic void preCheck(){init();this.commonRdbmsReaderJob.preCheck(this.originalConfig,DATABASE_TYPE);}@Overridepublic List<Configuration> split(int adviceNumber) {return this.commonRdbmsReaderJob.split(this.originalConfig, adviceNumber);}@Overridepublic void post() {this.commonRdbmsReaderJob.post(this.originalConfig);}@Overridepublic void destroy() {this.commonRdbmsReaderJob.destroy(this.originalConfig);}}public static class Task extends Reader.Task {private Configuration readerSliceConfig;private CommonRdbmsReader.Task commonRdbmsReaderTask;@Overridepublic void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE,super.getTaskGroupId(), super.getTaskId());this.commonRdbmsReaderTask.init(this.readerSliceConfig);}@Overridepublic void startRead(RecordSender recordSender) {int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,super.getTaskPluginCollector(), fetchSize);}@Overridepublic void post() {this.commonRdbmsReaderTask.post(this.readerSliceConfig);}@Overridepublic void destroy() {this.commonRdbmsReaderTask.destroy(this.readerSliceConfig);}}}
public class RdbmsReader extends Reader {private static final DataBaseType DATABASE_TYPE = DataBaseType.RDBMS;static {//加载插件下面配置的驱动类DBUtil.loadDriverClass("reader", "rdbms");}public static class Job extends Reader.Job {private Configuration originalConfig;private CommonRdbmsReader.Job commonRdbmsReaderMaster;@Overridepublic void init() {this.originalConfig = super.getPluginJobConf();int fetchSize = this.originalConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE,Constant.DEFAULT_FETCH_SIZE);if (fetchSize < 1) {throw DataXException.asDataXException(DBUtilErrorCode.REQUIRED_VALUE,String.format("您配置的fetchSize有误,根据DataX的设计,fetchSize : [%d] 设置值不能小于 1.",fetchSize));}this.originalConfig.set(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE,fetchSize);this.commonRdbmsReaderMaster = new SubCommonRdbmsReader.Job(DATABASE_TYPE);this.commonRdbmsReaderMaster.init(this.originalConfig);}@Overridepublic List<Configuration> split(int adviceNumber) {return this.commonRdbmsReaderMaster.split(this.originalConfig,adviceNumber);}@Overridepublic void post() {this.commonRdbmsReaderMaster.post(this.originalConfig);}@Overridepublic void destroy() {this.commonRdbmsReaderMaster.destroy(this.originalConfig);}}public static class Task extends Reader.Task {private Configuration readerSliceConfig;private CommonRdbmsReader.Task commonRdbmsReaderSlave;@Overridepublic void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderSlave = new SubCommonRdbmsReader.Task(DATABASE_TYPE);this.commonRdbmsReaderSlave.init(this.readerSliceConfig);}@Overridepublic void startRead(RecordSender recordSender) {int fetchSize = this.readerSliceConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE);this.commonRdbmsReaderSlave.startRead(this.readerSliceConfig,recordSender, super.getTaskPluginCollector(), fetchSize);}@Overridepublic void post() {this.commonRdbmsReaderSlave.post(this.readerSliceConfig);}@Overridepublic void destroy() {this.commonRdbmsReaderSlave.destroy(this.readerSliceConfig);}}
}
相关文章:

DataX源码分析 reader
系列文章目录 一、DataX详解和架构介绍 二、DataX源码分析 JobContainer 三、DataX源码分析 TaskGroupContainer 四、DataX源码分析 TaskExecutor 五、DataX源码分析 reader 六、DataX源码分析 writer 七、DataX源码分析 Channel 文章目录 系列文章目录前言Reader组件如何处理…...

openssl3.2 - exp - RAND_bytes_ex
文章目录 openssl3.2 - exp - RAND_bytes_ex概述笔记END openssl3.2 - exp - RAND_bytes_ex 概述 生成随机数时, 要检查返回值是否成功, 不能认为一定是成功的(官方文档上有说明). 生成随机数的API, 和库上下文有关系, 使用RAND_bytes_ex()比RAND_bytes()好些. 笔记 /*! * …...

Oracle中怎么设置时区和系统时间
在Oracle数据库中,设置时区和系统时间可以通过多种方法实现。下面是一些常见的方法: 1. 设置数据库的时区 Oracle数据库允许你为每个会话或整个数据库设置时区。 a. 为整个数据库设置时区 你可以使用ALTER DATABASE语句为整个数据库设置时区。例如&a…...

常见的物联网操作系统介绍
物联网(Internet of Things,IoT)是指将各种物理设备、车辆、家用电器、工业设备等通过网络连接起来,实现数据交换和通信的技术。物联网操作系统是管理这些设备并使其能够相互通信的软件平台。以下是一些常见的物联网操作系统&…...

二级C语言笔试10
(总分101,考试时间90分钟) 一、选择题 1. 设有如下关系表: A) TR∩S B) TR∪S C) TRS D) TR/S 2. 在一棵二叉树中,叶子结点共有30个,度为1的结点共有40个,则该二叉树中的总结点数共有( )个。 A) 89 …...
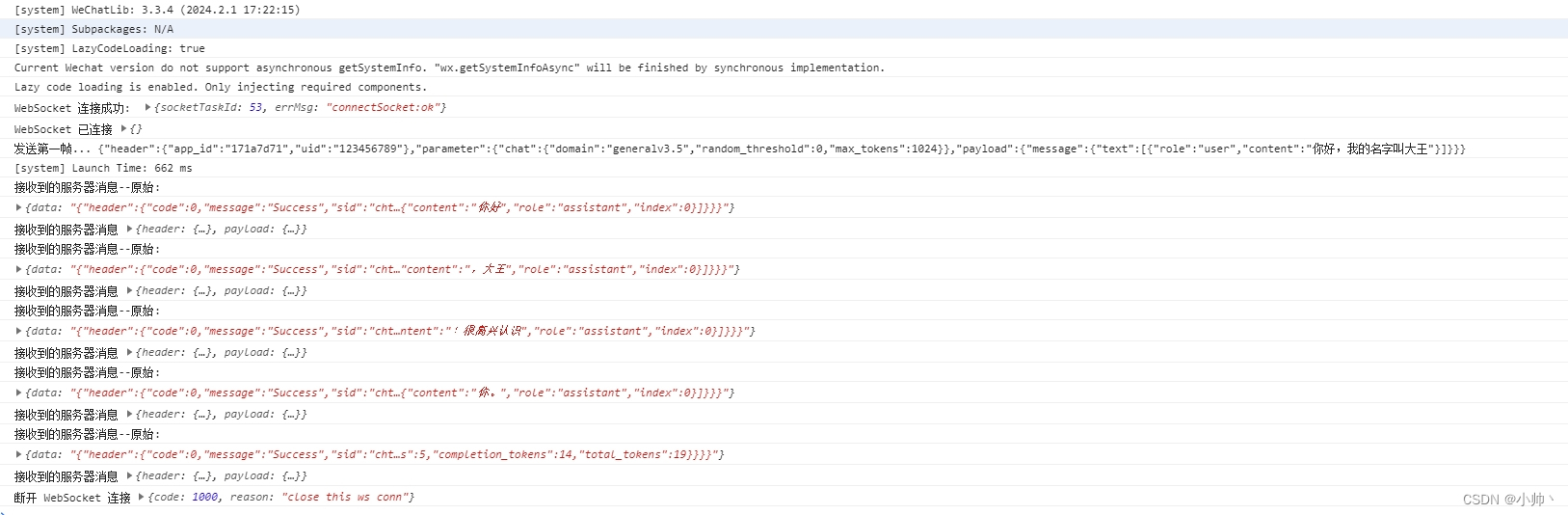
【WebSocket】微信小程序原生组件使用SocketTask 调用星火认知大模型
直接上代码 微信开发者工具-调试器-终端-新建终端 进行依赖安装 npm install base-64 npm install crypto-js 然后顶部工具栏依次点击 工具-构建npm // index.js const defaultAvatarUrl https://mmbiz.qpic.cn/mmbiz/icTdbqWNOwNRna42FI242Lcia07jQodd2FJGIYQfG0LAJGFxM4FbnQ…...
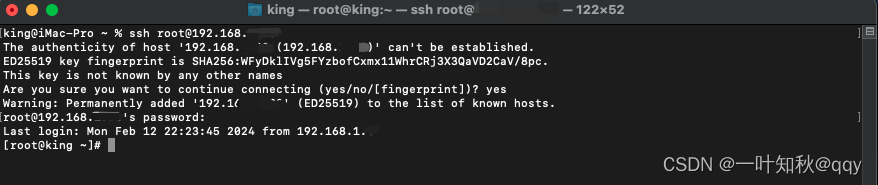
[1-docker-01]centos环境安装docker
官方参考文档 可以在官方docker桌面版本指导文档里找到适合自己的电脑平台进行参考,或者你是老司机的话直接自己上车。 如果不需要桌面版,也可以在官方docker engine版本指导文档里找到适合自己的平台进行参考,同样,老司机可以自…...
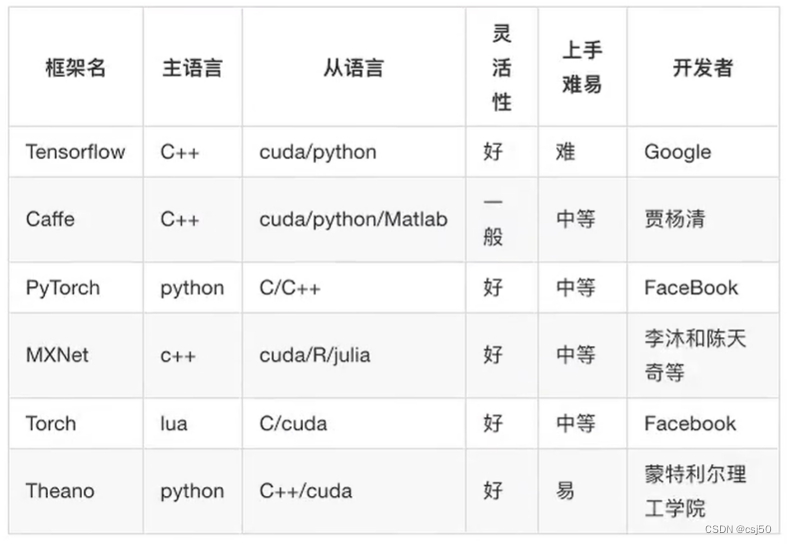
深度学习基础之《深度学习介绍》
一、深度学习与机器学习的区别 1、特征提取方面 机器学习:人工特征提取 分类算法 深度学习:没有人工特征提取,直接将特征值传进去 (1)机器学习的特征工程步骤是要靠手工完成的,而且需要大量领域专业知识…...
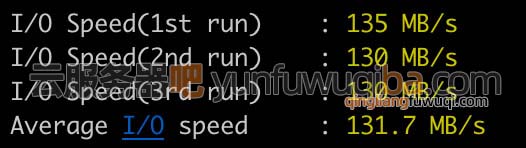
4核8g服务器能支持多少人访问?2024新版测评
腾讯云轻量4核8G12M轻量应用服务器支持多少人同时在线?通用型-4核8G-180G-2000G,2000GB月流量,系统盘为180GB SSD盘,12M公网带宽,下载速度峰值为1536KB/s,即1.5M/秒,假设网站内页平均大小为60KB…...

Linux中pipe管道操作
管道的读写操作: 读操作: 有数据:read正常读,返回读出的字节数无数据:1 写段全部关闭:read解除阻塞,返回0,相当于文件读到了尾部 2 写段没有全部关闭…...

中年中产程序员从西安出发到海南三亚低成本吃喝万里行:西安-南宁-湛江-雷州-徐闻-博鳌-陵水-三亚-重庆-西安(2.游玩过程)
文章大纲 出发时间:Day1-1月25日星期四,西安飞南宁路途中:Day2-1月26日星期五,南宁-湛江-住雷州(曾经支教过的地方)【晚上买徐闻到海安新港】路途中:Day3-1月27日星期六,雷州-徐闻渡…...
)
day38 面向对象编程、构造函数等(纯概念)
目录 深入对象构造函数实例成员静态成员内置构造函数ObjectArray包装类型StringNumber 深入对象 了解面向对象的基础概念,能够利用构造函数创建对象。 构造函数 构造函数是专门用于创建对象的函数,如果一个函数使用 new 关键字调用,那么这…...

nginx用域名http://xx.com/aaa/代理一个网页http://ff.com但是请求资源时发生404
哎,还得是chatgpt,难道就没有人有这种使用场景吗?没查到一个配置是有效的。 我: 我配置了nginx反向代理,用域名http://xx.com/aaa/代理一个网页http://ff.com, 但是请求资源时发生404,如何解决&…...
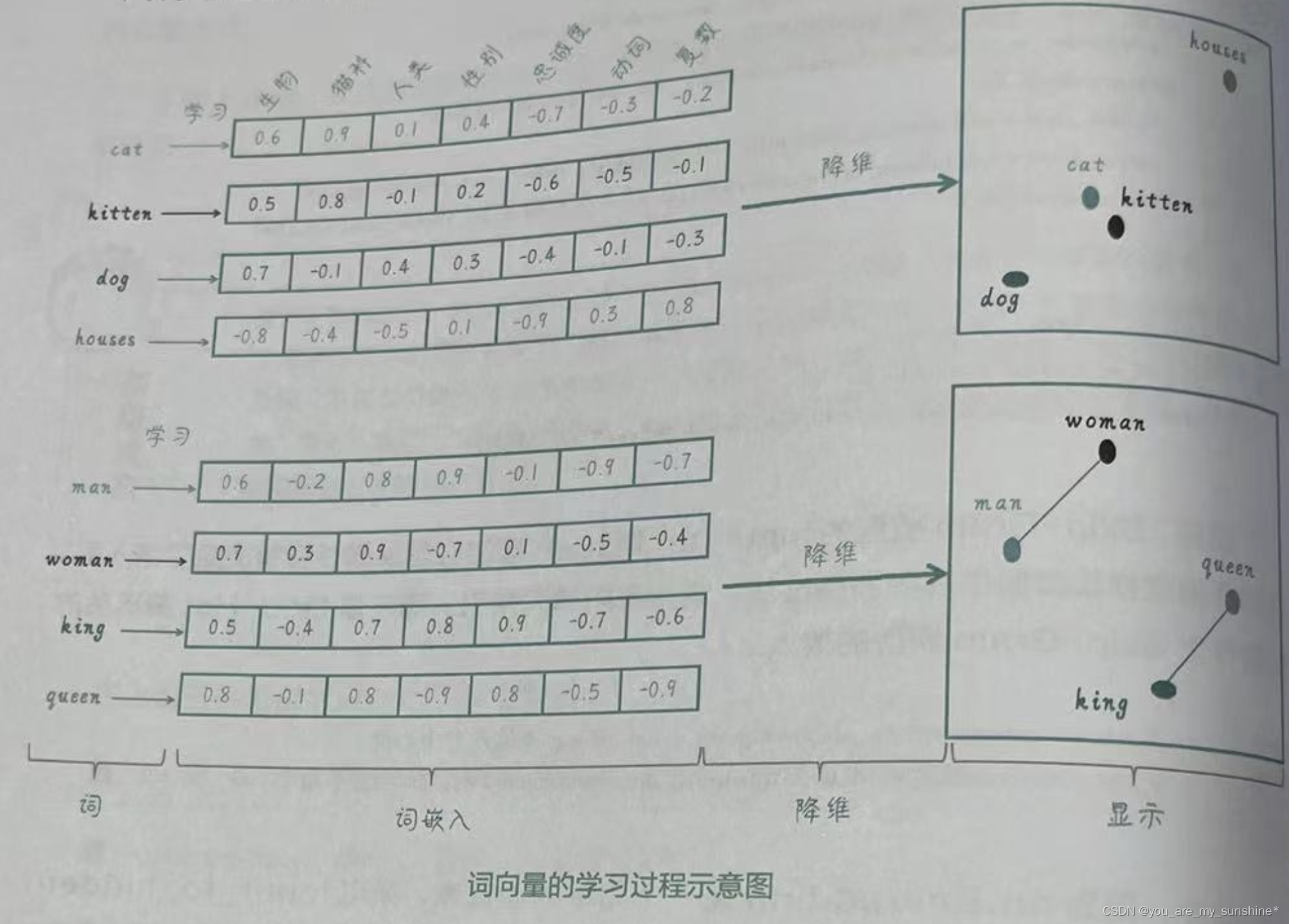
NLP_词的向量表示Word2Vec 和 Embedding
文章目录 词向量Word2Vec:CBOW模型和Skip-Gram模型通过nn.Embedding来实现词嵌入Word2Vec小结 词向量 下面这张图就形象地呈现了词向量的内涵:把词转化为向量,从而捕捉词与词之间的语义和句法关系,使得具有相似含义或相关性的词语在向量空间…...

python:xml.etree 生成思维导图 Freemind文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree python 用 xm…...
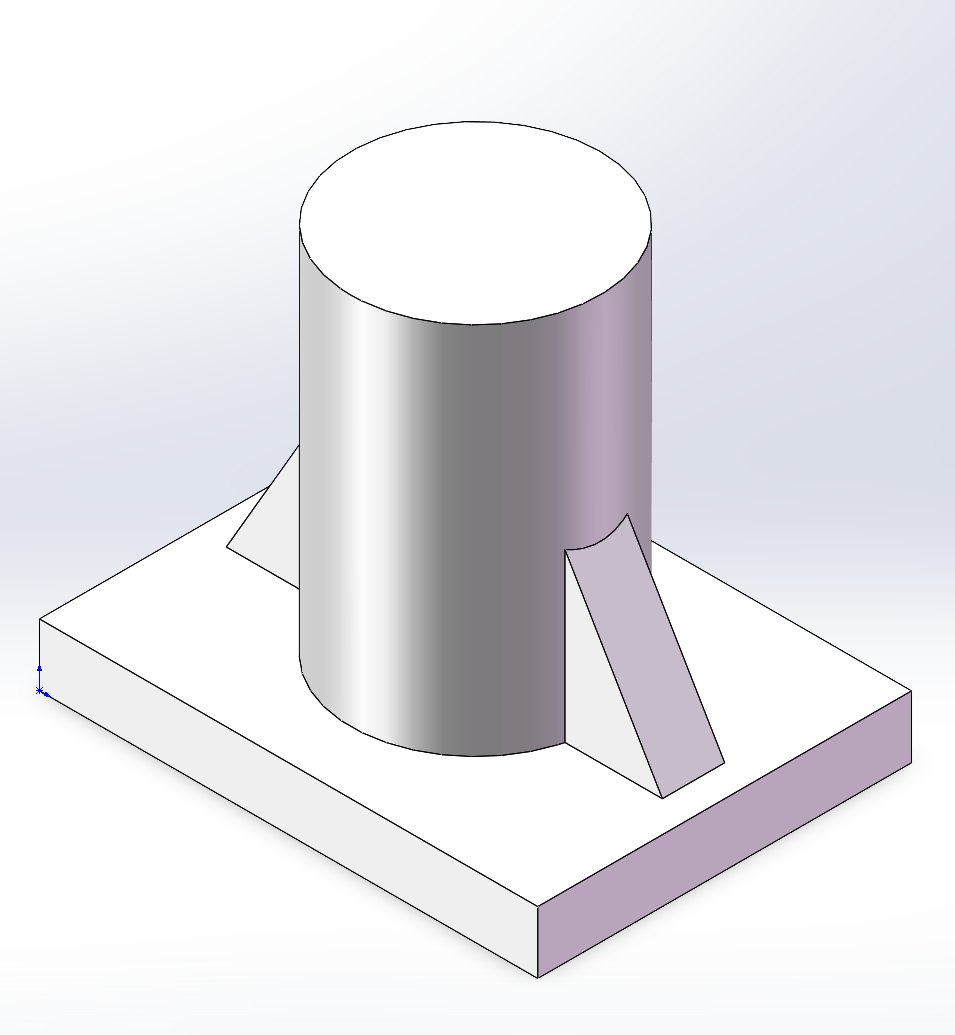
Solidworks:从2D走向3D
Sokidworks 的强大之处在于三维实体建模,这个形状看似复杂,实际上只需要拉伸一次,再做一次减法拉伸就行了。第一次做三维模型,费了不少时间才搞明白。 接下来做一个稍微复杂一点的模型,和上面这个操作差不多࿰…...

【开源】JAVA+Vue.js实现高校学院网站
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 学院院系模块2.2 竞赛报名模块2.3 教育教学模块2.4 招生就业模块2.5 实时信息模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 学院院系表3.2.2 竞赛报名表3.2.3 教育教学表3.2.4 招生就业表3.2.5 实时信息表 四、系…...
题解19-24
48. 旋转图像 - 力扣(LeetCode) 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在** 原地** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 示例 1࿱…...

基于图像掩膜和深度学习的花生豆分拣(附源码)
目录 项目介绍 图像分类网络构建 处理花生豆图片完成预测 项目介绍 这是一个使用图像掩膜技术和深度学习技术实现的一个花生豆分拣系统 我们有大量的花生豆图片,并以及打好了标签,可以看一下目录结构和几张具体的图片 同时我们也有几张大的图片&…...
【网络】:序列化和反序列化
序列化和反序列化 一.json库 二.简单使用json库 前面已经讲过TCP和UDP,也写过代码能够进行双方的通信了,那么有没有可能这种通信是不安全的呢?如果直接通信,可能会被底层捕捉;可能由于网络问题,一方只接收到…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

安全聚合技术:原理、实现与多场景应用
1. 安全聚合技术概述安全聚合(Secure Aggregation)是一种多方安全计算技术,它允许多个互不信任的参与方在不泄露各自私有数据的前提下,共同计算出一个聚合结果。这项技术的核心价值在于解决了数据隐私与数据共享之间的矛盾&#x…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南
C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南 在C语言开发中,结构体、枚举和联合体是构建复杂数据模型的三大基石。但很多开发者在实际项目中常遇到这样的困惑:为什么结构体占用的内存比预期大?枚举变量在…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...

LoRA模型合并实战:多技能大模型融合指南与vLLM+Copaw工具链解析
1. 项目概述:LoRA模型合并的“瑞士军刀” 在AIGC(人工智能生成内容)领域,模型微调是让大语言模型(LLM)或扩散模型适配特定任务、风格或知识库的核心手段。而LoRA(Low-Rank Adaptation࿰…...