Python 3 时间序列可视化指南
简介
时间序列分析属于统计学的一个分支,涉及对有序的、通常是时间性的数据进行研究。当适当应用时,时间序列分析可以揭示意想不到的趋势,提取有用的统计数据,甚至预测未来的趋势。因此,它被应用于许多领域,包括经济学、天气预报和容量规划等。
在本教程中,我们将介绍时间序列分析中使用的一些常见技术,并逐步介绍操作、可视化时间序列数据所需的迭代步骤。
先决条件
本指南将介绍如何在本地桌面或远程服务器上进行时间序列分析。处理大型数据集可能会占用大量内存,因此在任何情况下,计算机都需要至少2GB的内存来执行本指南中的一些计算。
在本教程中,我们将使用Jupyter Notebook来处理数据。如果您尚未安装,请按照我们的教程安装和设置Python 3的Jupyter Notebook。
步骤1 — 安装软件包
我们将利用pandas库,它在处理数据时提供了很大的灵活性,以及statsmodels库,它允许我们在Python中进行统计计算。这两个库的结合扩展了Python的功能,显著增加了我们的分析工具包。
与其他Python软件包一样,我们可以使用pip安装pandas和statsmodels。首先,让我们进入本地编程环境或基于服务器的编程环境:
cd environments
. my_env/bin/activate
从这里开始,让我们为我们的项目创建一个新目录。我们将其命名为timeseries,然后进入该目录。如果您将项目命名为其他名称,请确保在整个指南中用您的名称替换timeseries。
mkdir timeseries
cd timeseries
现在,我们可以安装pandas、statsmodels和数据绘图包matplotlib。它们的依赖项也将被安装:
pip install pandas statsmodels matplotlib
到目前为止,我们已经准备好开始使用pandas和statsmodels进行工作。
步骤2 — 加载时间序列数据
要开始处理我们的数据,我们将启动Jupyter Notebook:
jupyter notebook
要创建一个新的笔记本文件,请从右上角的下拉菜单中选择New > Python 3:
!创建一个新的Python 3笔记本
这将打开一个笔记本,允许我们加载所需的库(请注意,我们使用了标准的缩写来引用pandas、matplotlib和statsmodels)。在我们的笔记本顶部,我们应该写入以下内容:
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
在本教程的每个代码块之后,您应该键入ALT + ENTER来运行代码,并在笔记本中进入新的代码块。
方便的是,statsmodels自带内置数据集,因此我们可以直接将时间序列数据集加载到内存中。
我们将使用一个名为“夏威夷火奴鲁鲁马努阿罗观测站连续空气样本中的大气二氧化碳(CO2)”的数据集,该数据集从1958年3月到2001年12月收集了CO2样本。我们可以这样导入这些数据:
data = sm.datasets.co2.load_pandas()
co2 = data.data
让我们看看我们的时间序列数据的前5行是什么样子:
print(co2.head(5))
co2
1958-03-29 316.1
1958-04-05 317.3
1958-04-12 317.6
1958-04-19 317.5
1958-04-26 316.4
通过导入包并准备好CO2数据集,我们可以继续对数据进行索引。
步骤3 — 使用时间序列数据进行索引
您可能已经注意到日期已经被设置为我们pandas DataFrame的索引。在Python中处理时间序列数据时,我们应该确保使用日期作为索引,因此请务必始终检查,我们可以通过运行以下命令来实现:
co2.index
DatetimeIndex(['1958-03-29', '1958-04-05', '1958-04-12', '1958-04-19','1958-04-26', '1958-05-03', '1958-05-10', '1958-05-17','1958-05-24', '1958-05-31',...'2001-10-27', '2001-11-03', '2001-11-10', '2001-11-17','2001-11-24', '2001-12-01', '2001-12-08', '2001-12-15','2001-12-22', '2001-12-29'],dtype='datetime64[ns]', length=2284, freq='W-SAT')
dtype=datetime[ns]字段确认了我们的索引由日期时间戳对象组成,而length=2284和freq='W-SAT'告诉我们,我们有2284个每周日期时间戳,从星期六开始。
每周数据可能很难处理,因此让我们改为使用时间序列的月均值。这可以通过使用方便的resample函数来实现,该函数允许我们将时间序列分组为桶(1个月),在每个组上应用函数(均值),并组合结果(每组一行)。
y = co2['co2'].resample('MS').mean()
在这里,术语MS表示我们按月份将数据分组到桶中,并确保我们使用每个月的开始作为时间戳:
y.head(5)
1958-03-01 316.100
1958-04-01 317.200
1958-05-01 317.120
1958-06-01 315.800
1958-07-01 315.625
Freq: MS, Name: co2, dtype: float64
pandas的一个有趣特性是它能够处理日期时间戳索引,这使我们能够快速地切片我们的数据。例如,我们可以将数据集切片,仅检索1990年之后的数据点:
y['1990':]
1990-01-01 353.650
1990-02-01 354.650...
2001-11-01 369.375
2001-12-01 371.020
Freq: MS, Name: co2, dtype: float64
或者,我们可以将数据集切片,仅检索1995年10月到1996年10月之间的数据点:
y['1995-10-01':'1996-10-01']
1995-10-01 357.850
1995-11-01 359.475
1995-12-01 360.700
1996-01-01 362.025
1996-02-01 363.175
1996-03-01 364.060
1996-04-01 364.700
1996-05-01 365.325
1996-06-01 364.880
1996-07-01 363.475
1996-08-01 361.320
1996-09-01 359.400
1996-10-01 359.625
Freq: MS, Name: co2, dtype: float64
通过适当地为处理时间数据进行索引,我们可以继续处理可能缺失的值。
第四步 — 处理时间序列数据中的缺失值
现实世界的数据往往是杂乱的。正如我们从图中所看到的,时间序列数据中包含缺失值并不罕见。检查缺失值的最简单方法要么是直接绘制数据,要么是使用下面的命令来查看输出中的缺失数据:
y.isnull().sum()
5
这个输出告诉我们,在我们的时间序列中有 5 个月的数据缺失。
通常情况下,如果缺失值不是太多,我们应该“填补”这些缺失值,以免数据中出现间断。我们可以使用 pandas 中的 fillna() 命令来实现这一点。为简单起见,我们可以使用时间序列中最接近的非空值来填补缺失值,尽管需要注意的是,有时滚动均值可能更可取。
y = y.fillna(y.bfill())
填补了缺失值之后,我们可以再次检查是否存在任何空值,以确保我们的操作成功:
y.isnull().sum()
0
经过这些操作之后,我们看到我们已经成功填补了时间序列中的所有缺失值。
第五步 — 可视化时间序列数据
在处理时间序列数据时,通过可视化可以揭示很多信息。一些需要注意的事项包括:
- 季节性:数据是否显示出明显的周期模式?
- 趋势:数据是否遵循一致的上升或下降趋势?
- 噪音:是否存在任何与其余数据不一致的异常值或缺失值?
我们可以使用 pandas 对 matplotlib API 的封装来显示数据集的图表:
y.plot(figsize=(15, 6))
plt.show()
!时间序列可视化图 1
当我们绘制数据时,一些明显的模式出现了。时间序列具有明显的季节性模式,以及总体上升的趋势。我们还可以使用一种称为时间序列分解的方法来可视化我们的数据。顾名思义,时间序列分解允许我们将时间序列分解为三个不同的组成部分:趋势、季节性和噪音。
幸运的是,statsmodels 提供了方便的 seasonal_decompose 函数来执行季节性分解。如果您有兴趣了解更多信息,可以在以下论文中找到其原始实现的参考资料:“STL: A Seasonal-Trend Decomposition Procedure Based on Loess.”
下面的脚本展示了如何在 Python 中执行时间序列季节性分解。默认情况下,seasonal_decompose 返回一个相对较小的图形,因此代码块的前两行确保输出图形足够大,以便我们进行可视化。
from pylab import rcParams
rcParams['figure.figsize'] = 11, 9decomposition = sm.tsa.seasonal_decompose(y, model='additive')
fig = decomposition.plot()
plt.show()
!时间序列季节性-趋势分解可视化图 2
使用时间序列分解可以更容易地快速识别数据中的均值变化或变异性。上面的图表清楚地显示了数据的上升趋势,以及其年度季节性。这些可以用来理解我们时间序列的结构。时间序列分解背后的直觉很重要,因为许多预测方法都建立在这种结构化分解的概念之上,以生成预测。
结论
如果您跟随本指南,现在您已经具备了在 Python 中可视化和操作时间序列数据的经验。
为了进一步提高您的技能,您可以加载另一个数据集,并重复本教程中的所有步骤。例如,您可以使用 pandas 库读取一个 CSV 文件,或者使用 statsmodels 库预先加载的 sunspots 数据集:data = sm.datasets.sunspots.load_pandas().data。
相关文章:

Python 3 时间序列可视化指南
简介 时间序列分析属于统计学的一个分支,涉及对有序的、通常是时间性的数据进行研究。当适当应用时,时间序列分析可以揭示意想不到的趋势,提取有用的统计数据,甚至预测未来的趋势。因此,它被应用于许多领域࿰…...

[算法前沿]--059-大语言模型Fine-tuning踩坑经验之谈
前言 由于 ChatGPT 和 GPT4 兴起,如何让人人都用上这种大模型,是目前 AI 领域最活跃的事情。当下开源的 LLM(Large language model)非常多,可谓是百模大战。面对诸多开源本地模型,根据自己的需求,选择适合自己的基座模型和参数量很重要。选择完后需要对训练数据进行预处…...

【Docker】01 Docker安装与配置
文章目录 一、Docker二、离线安装Docker三、联网安装Docker3.1 下载YUM软件库文件3.2 安装epel-release3.3 安装yum-utils3.4 设置镜像仓库3.5 查看docker-ce所有版本3.6 安装Docker3.7 启动Docker3.8 查看Docker信息3.9 启动第一个容器 四、一些配置4.1 登录DockerHub4.2 镜像…...

Unity3d Shader篇(六)— BlinnPhong高光反射着色器
文章目录 前言一、BlinnPhong高光反射着色器是什么?1. BlinnPhong高光反射着色器的工作原理2. BlinnPhong高光反射着色器的优缺点优点缺点 3. 公式 二、使用步骤1. Shader 属性定义2. SubShader 设置3. 渲染 Pass4. 定义结构体和顶点着色器函数5. 片元着色器函数 三…...
定时任务的选择调研)
Go-zero微服务个人探究之路(十二)定时任务的选择调研
前言 很多时候后台需要做定时任务的需求,笔者的项目采用go-zero框架微服务框架,需要做定时任务,于是做了如下方法调研,共有大概三种主要选择 方案 难度总体由容易到复杂 go的timer库 通过Go的标准库time中的Ticker和Tick功能…...

Java中,List、Map和Set的区别是什么?
在Java中,List、Map和Set是三种常用的集合类型,它们之间的主要区别如下: 1、List List是有序集合,它可以包含重复元素。 List中的元素是按照插入顺序排列的,可以通过索引访问每个元素。 Java中常见的List实现类有A…...
Google刚刚推出了图神经网络Tensorflow-GNN
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
链表基础知识汇总
链表 链表是一种基本的数据结构,是由一系列节点组成的集合。每个节点包含两个部分:值和指向下一个节点的指针。链表中的节点可以动态地添加、删除,其大小可以根据需要进行扩展或缩小。 链表通常用于处理不固定长度的数据结构,具有…...
)
Educational Codeforces Round 2(远古edu计划)
A. 恶心模拟。。 模拟一下分类即可 数字类,数字0,或者都是数字 字母类,字母空的也是字母,有字母就是字母 #include<bits/stdc.h> #define INF 1e9 using namespace std; typedef long long ll; const int N2e59; strin…...
【Tauri】(1):使用Tauri1.5版本,进行桌面应用开发,在windows,linux进行桌面GUI应用程序开发,可以打包成功,使用 vite 最方便
1,视频地址: https://www.bilibili.com/video/BV1Pz421d7s4/ 【Tauri】(1):使用Tauri1.5版本,进行桌面应用开发,在windows,linux进行桌面GUI应用程序开发,可以打包成功&…...

「Linux」软件安装
MySQL5.7在CentOS安装 安装 配置yum仓库 更新密钥:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022安装MySQL yum库:rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm使用yum安装MySQL:yum -y in…...

Ubuntu Desktop - Terminal 输出全部选中 + 复制
Ubuntu Desktop - Terminal 输出全部选中 复制 1. Terminal2. Terminal 最大化3. Edit -> Select All4. Copy & PasteReferences 1. Terminal 2. Terminal 最大化 3. Edit -> Select All 4. Copy & Paste Edit -> Copy or Shift Ctrl C Edit -> Paste…...

Java 三大并大特性-可见性介绍(结合代码、分析源码)
目录 编辑 一、可见性概念 1.1 概念 二、可见性问题由来 2.1 由来分析 三、可见性代码例子 3.1 代码 3.2 执行结果 四、Java 中保证可见性的手段 4.1 volatile 4.1.1 优化代码 4.1.2 测试结果 4.1.3 volatile原理分析 4.1.3.1 查看字节码 4.1.3.2 hotspot 层面…...
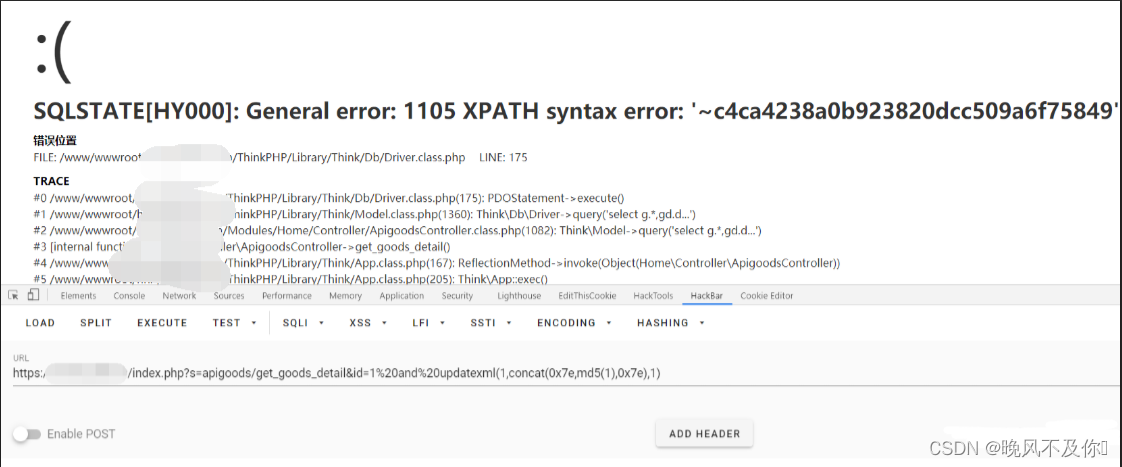
【漏洞复现】狮子鱼CMS某SQL注入漏洞01
Nx01 产品简介 狮子鱼CMS(Content Management System)是一种网站管理系统,它旨在帮助用户更轻松地创建和管理网站。该系统拥有用户友好的界面和丰富的功能,包括页面管理、博客、新闻、产品展示等。通过简单直观的管理界面…...

《Java 简易速速上手小册》第6章:Java 并发编程(2024 最新版)
文章目录 6.1 线程的创建和管理 - 召唤你的士兵6.1.1 基础知识6.1.2 重点案例:实现一个简单的计数器6.1.3 拓展案例 1:定时器线程6.1.4 拓展案例 2:使用 Executor 框架管理线程 6.2 同步机制 - 维持军队的秩序6.2.1 基础知识6.2.2 重点案例&a…...
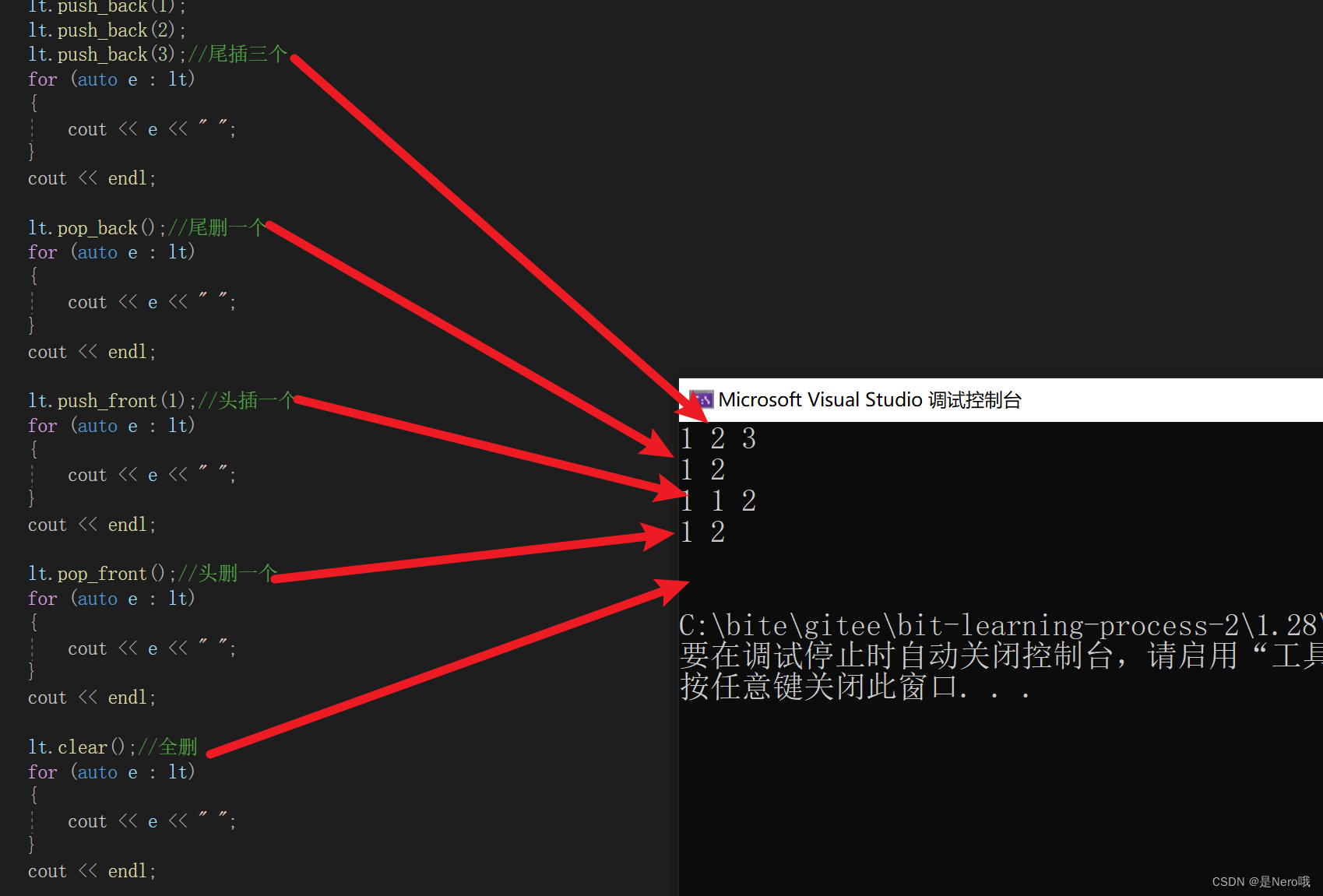
C++初阶:容器(Containers)list常用接口详解
介绍完了vector类的相关内容后,接下来进入新的篇章,容器list介绍: 文章目录 1.list的初步介绍2.list的定义(constructor)3.list迭代器( iterator )4.string的三种遍历4.1迭代器4.2范围for循环 5…...
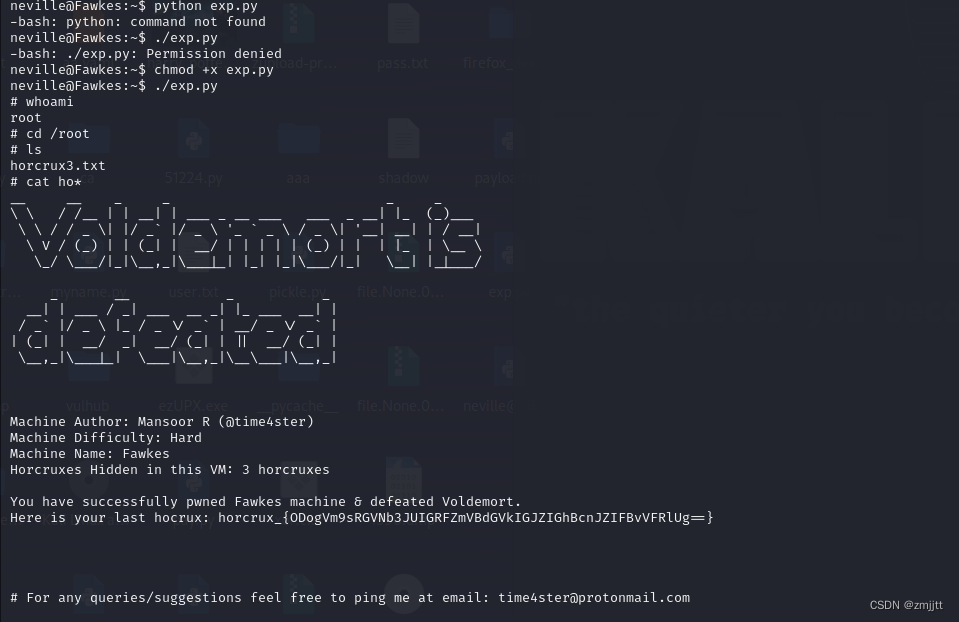
HARRYPOTTER: FAWKES
攻击机 192.168.223.128 目标机192.168.223.143 主机发现 nmap -sP 192.168.223.0/24 端口扫描 nmap -sV -p- -A 192.168.223.143 开启了21 22 80 2222 9898 五个端口,其中21端口可以匿名FTP登录,好像有点说法,百度搜索一下发现可以用anonymous登录…...

嵌入式Qt 第一个Qt项目
一.创建Qt项目 打开Qt Creator 界面选择 New Project或者选择菜单栏 【文件】-【新建文件或项目】菜单项 弹出New Project对话框,选择Qt Widgets Application 选择【Choose】按钮,弹出如下对话框 设置项目名称和路径,按照向导进行下一步 选…...

【OpenHarmony硬件操作】风扇与温湿度模块
文章目录 前言一、串行通信是什么二、IC2.1 IC是什么2.2 IC涉及到的线2.3 IC的时序三、风扇的操作3.1 关于 pcf85743.2 风扇的接口函数IO拓展芯片的定义初始化PCF8574初始化 IO拓展版的引脚属性开启和关闭风扇读状态四、温湿度传感器的使用4.1 初始化温湿度传感器</...
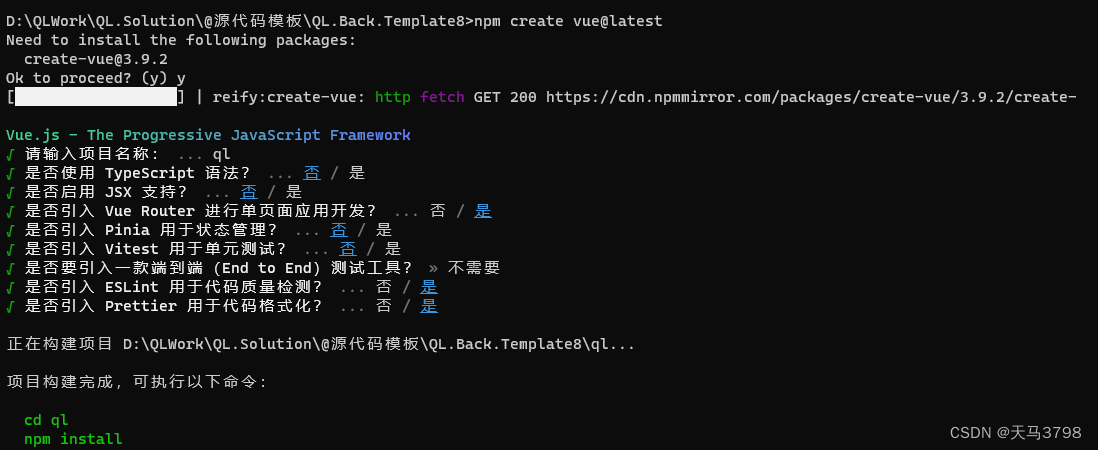
Vue3.4+element-plus2.5 + Vite 搭建教程整理
一、 Vue3Vite 项目搭建 说明: Vue3 最新版本已经基于Vite构建,关于Vite简介:Vite 下一代的前端工具链,前端开发与构建工具-CSDN博客 1.安装 并 创建Vue3 应用 npm create vuelatest 创建过程可以一路 NO 目前推荐使用 Vue R…...

避坑指南:在Ubuntu 22.04上用Anaconda配置Vision-Mamba环境,解决‘bimamba_type‘报错
深度避坑:Ubuntu 22.04下Vision-Mamba环境配置全攻略 在深度学习项目部署过程中,环境配置往往是第一个拦路虎。最近在配置Vision-Mamba环境时,我遇到了几个令人头疼的问题,特别是那个让人摸不着头脑的bimamba_type报错。经过一番折…...

对比直接购买与通过Taotoken聚合使用大模型API的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买与通过Taotoken聚合使用大模型API的体验差异 在开发和集成大模型能力的过程中,开发者或团队通常面临两种主…...

我答辩前 3 天 AI 率还有 72%?这款工具 4 小时降到 7% 顺利答辩
我答辩前 3 天 AI 率还有 72%?这款工具 4 小时降到 7% 顺利答辩 去年研三答辩前 3 天那个晚上——我送学校做最后的知网 AIGC 检测、回来一看AI 率 72%、学校卡 15% 红线。我整个人坐地上了——3 天根本来不及手改。 后来一位 211 同门给我推荐了比话 PASSÿ…...

虚幻引擎小白人下岗指南:三步搞定商城角色替换,附赠武器隐藏和动画修复彩蛋
虚幻引擎角色替换实战指南:从基础操作到进阶技巧 第一次打开虚幻引擎时,那个默认的"小白人"角色总让人感觉缺乏个性。作为开发者,我们都希望游戏中的角色能快速展现独特风格。本文将带你用最简洁的流程完成商城角色替换,…...
)
不止图表引用!VSCode+LaTeX完整编译链配置指南(含BibTeX文献处理)
VSCodeLaTeX高效工作流:从交叉引用到文献管理的全栈配置指南 当你第一次在VSCode中尝试用LaTeX撰写学术论文时,是否曾被那些顽固的"??"标记困扰?这些问号背后隐藏着LaTeX编译机制的核心逻辑——交叉引用需要多轮编译才能正确解析…...

从单摆到机械臂:拉格朗日方程如何统一描述‘运动与力’?一个思维模型讲透
从单摆到机械臂:拉格朗日方程如何统一描述‘运动与力’?一个思维模型讲透 想象你手中握着一根细绳,末端悬挂着一个小球。轻轻推动它,小球便开始左右摆动——这就是经典的单摆系统。看似简单的运动背后,却隐藏着自然界最…...

Royal TSX 终极中文汉化包:让专业远程管理工具说中文的完整解决方案
Royal TSX 终极中文汉化包:让专业远程管理工具说中文的完整解决方案 【免费下载链接】Royal_TSX_Chinese_Language_Pack Royal_TSX的简体中文汉化包 项目地址: https://gitcode.com/gh_mirrors/ro/Royal_TSX_Chinese_Language_Pack Royal TSX 是一款功能强大…...

如何在Windows上完美使用苹果触控板:终极配置指南
如何在Windows上完美使用苹果触控板:终极配置指南 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-touchpad 还…...

长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈 作为一名长期负责项目维护的开发者,我所在团队在…...

告别混乱!Flink指标报告选型指南:Graphite、InfluxDB、Prometheus、StatsD到底怎么选?
Flink监控体系选型实战:Graphite、InfluxDB、Prometheus与StatsD深度对比 当Flink集群从测试环境走向生产环境时,监控指标的可视化与分析能力直接关系到系统的稳定性和运维效率。面对Graphite、InfluxDB、Prometheus和StatsD这四种主流指标报告方案&…...