Hive的小文件问题
目录
一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量
3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐)
3.2.2 方式二:concatenate
3.2.3 方式三:使用hive的archive归档
3.2.4 方式四:hadoop getmerge
一、小文件产生的原因
- 数据源本身就包含大量的小文件,例如api,kafka消息管道等。
- 动态分区插入数据的时候,会产生大量的小文件,从而导致map数量剧增;;
- reduce 数量越多,小文件也越多,小文件数量=ReduceTask数量*分区数;
- hive中的小文件是向 hive 表中导入数据时产生;
向 hive 中导入数据的几种方式:
(1)直接向表中插入数据
insert into table t_order2 values (1,'zhangsan',88),(2,'lisi',61);这种方式每次插入时都会产生一个小文件,多次插入少量数据就会出现多个小文件,故这种方式生产环境基本不使用;
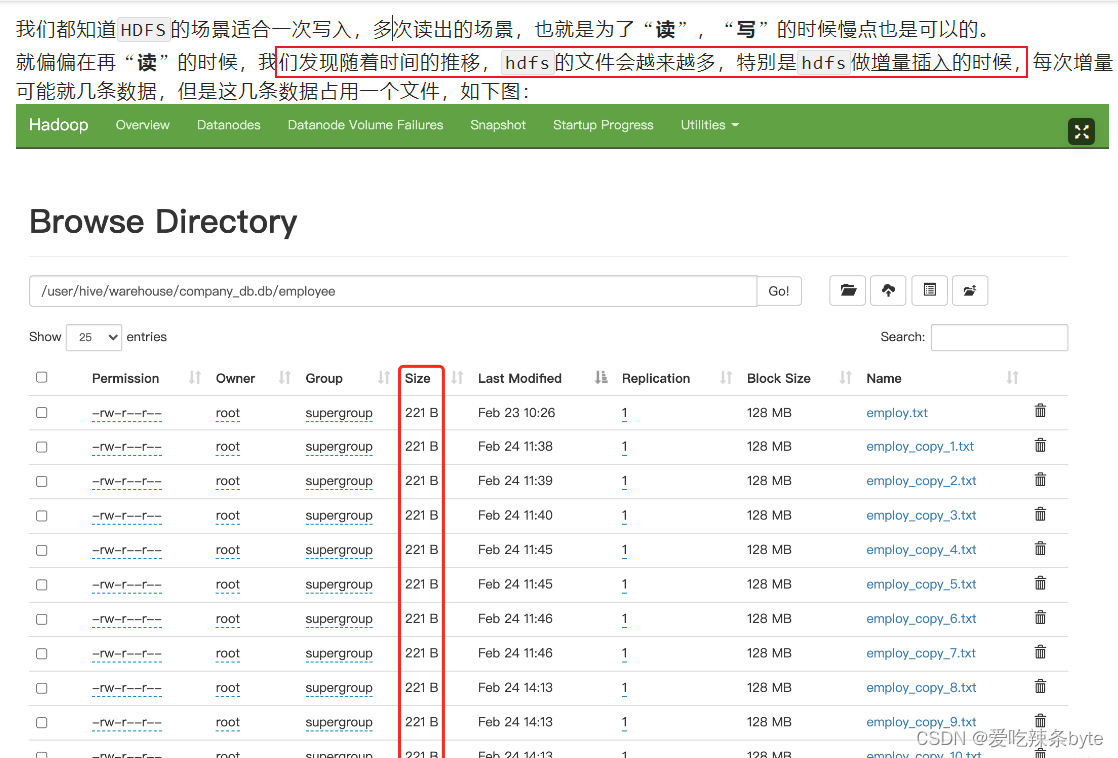
(2)通过load方式加载数据
-- 导入文件
load data local inpath "/opt/module/hive_data/t_order.txt" overwrite into table t_order;
-- 导入文件夹
load data local inpath "/opt/module/hive_data/t_order" overwrite into table t_order;使用 load方式可以导入文件或文件夹,当导入一个文件时,hive表就有一个文件,当导入文件夹时,hive表的文件数量为文件夹下所有文件的数量;
(3)通过查询方式加载数据
insert overwrite t_order select oid,uid from t_order2这种方式是生产环境中经常用的,也是最容易产生小文件的方式。insert 导入数据时会启动MR任务,MR-reduce的个数与输出文件个数一致。
因此,hdfs的文件数量= reduceTask数量* 分区数,有些fetch本地抓取任务(例如:简单的 select * from tableA)仅有map阶段,那此时文件个数 = mapTask数量*分区数
二、小文件的危害
小文件通常是指文件大小要比HDFS块大小(一般是128M)还要小很多的文件。
-
NameNode在内存中维护整个文件系统的元数据镜像、其中每个HDFS文件元数据信息(位置、大小、分块等)对象约占150字节,如果小文件过多会占用大量内存,会直接影响NameNode性能。相对的,HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立pipeline连接。
- 从 Hive 角度看,一个小文件会开启一个 MapTask,一个 MapTask开一个 JVM 去执行,这些任务的启动及初始化,会浪费大量的资源,严重影响性能。
三、小文件的解决方案
小文件的解决思路主要有两个方向:1.小文件的预防;2.已存在的小文件合并
3.1 小文件的预防
通过调整参数进行合并,在 hive 中执行 insert overwrite tableA select xx from tableB 之前设置如下合并参数,即可自动合并小文件。
3.1.1 减少Map数量
- 设置map输入时的合并参数:
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split切片作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认#每个Map最大的输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256*1000*100; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100*100*100; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100*100*100; -- 100M- 设置map输出时和reduce输出时的合并参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M- 启用压缩(小文件合并后,也可以选择启用压缩)
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
3.1.2 减少Reduce的数量
#reduce的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#通过设置reduce的数量,利用distribute by使得数据均衡的进入每个reduce。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;#第二种是设置每个reduceTask的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=512*1000*1000; -- 默认是1G,这里为设置为5G#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;insert overwrite table A partition(dt)
select * from B
distribute by cast(rand()*10 as int);解释:如设置reduce数量为10,则使用cast(rand()*10 as int),生成0-10之间的随机整数,根据【随机整数 % 10】计算分区编号,这样数据就会均衡的分发到各reduce中,防止出现有的文件过大或过小3.2 已存在的小文件合并
对集群上已存在的小文件进行定时或实时的合并操作,定时操作可在访问低峰期操作,如凌晨2点,合并操作主要有以下几种方式:
3.2.1 方式一:insert overwrite (推荐)
执行流程总体如下:
(1)创建备份表(创建备份表时需和原表的表结构一致)
create table test.table_hive_back like test.table_hive ;(2)设置合并文件相关参数,并使用insert overwrite 语句读取原表,再插入备份表
- 设置合并文件相关参数
使用 hive的merger合并参数,在正式 insert overwrite 之前做一个合并,合并的时候注意设置好压缩,不然文件会比较大。
- 合并文件至备份表中,执行前保证没有数据写入原表
#如果有多级分区,将分区名放到partition中
insert overwrite table test.table_hive_back partition(batch_date)
select * from test.table_hive;
ps:insert overwrite table test.table_hive_back 备份表的时候,可以使用distribute by 命令设置合并后的batch_date分区下的文件数据量
insert overwrite table 目标表 [partition(hour=...)] select * from 目标表
distribute by cast( rand() * 具体最后落地生成多少个文件数 as int);
insert overwrite:会重写数据,先进行删除后插入(不用担心如果overwrite失败,数据没了,这里面是有事务保障的);
distribute by分区:能控制数据从map端发往到哪个reduceTask中,distribute by的分区规则:分区字段的hashcode值对reduce 个数取模后, 余数相同的数据会分发到同一个reduceTask中。
rand()函数:生成0-1的随机小数,控制最终输出多少个文件。
# 使用distribute by rand()将数据随机分配给reduce,这样可以使得每个reduce处理的数据大体一致。 避免出现有的文件特别大, 有的文件特别小,例如:控制dt分区目录下生成100个文件,那么hsql如下:
insert overwrite table A partition(dt)select * from B
distribute by cast(rand()*100 as int);#cast(rand()*100 as int) 可以生成0-100的随机整数如果合并之后的文件竟然还变大了,可能是 select from的原数据是被压缩的,但是insert overwrite目标表的时候,没有设置输出文件压缩功能,解决方案:
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
(3)确认表数据一致后,将原表修改名称为临时表tmp,将备份表修改名称为原表
- 先查看原表和备份表数据量,确保表数据一致
#查看原表和备份表数据量
set hive.compute.query.using.stats=false ;
set hive.fetch.task.conversion=none;
SELECT count(*) FROM test.table_hive;
SELECT count(*) FROM test.table_hive_back ;- 将原表修改名称为临时表tmp,将备份表修改名称为原表
alter table test.table_hive rename to test.table_hive_tmp;
alter table test.table_hive_back rename to test.table_hive ;(4)查看合并后的分区数和小文件数量
正常情况下:hdfs文件系统上的table_hive表的分区数量没有改变,但是每个分区的几个小文件已经合并为一个文件。
#统计合并后的分区数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive
#统计合并后的分区数下的文件数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive/batch_date=20210608例如:

(5)观察一段时间后再删除临时表
drop table test.table_hive_tmp ;
ps:注意修改hive表名的时候,对应表的存储路径会发生变化,如果有新的任务上传数据到具体路径,需要注意可能需要修改。
3.2.2 方式二:concatenate
对于orc文件,可以使用hive自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table test concatenate;#对于分区表
alter table test [partition(...)] concatenate
#例如:alter table test partition(dt='2021-05-07',hr='12') concatenate;注意:
- concatenate 命令只支持 rcfile和 orc文件类型。
- concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
- 当多次使用concatenate后文件数量不变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
3.2.3 方式三:使用hive的archive归档
每日定时脚本,对于已经产生小文件的hive表使用har归档,然后已归档的分区不能insert overwrite ,必须先unarchive
#用来控制归档是否可用
set hive.archive.enabled=true;#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;#控制需要归档文件的大小
set har.partfile.size=256000000;#对表的某个分区进行归档
alter table test_rownumber2 archive partition(dt='20230324');#对已归档的分区恢复为原文件
alter table test_rownumber2 unarchive partition(dt='20230324');
3.2.4 方式四:hadoop getmerge
对于txt格式的文件可以使用hadoop getmerge命令来合并小文件。使用 getmerge 命令先合并数据到本地,再通过put命令回传数据到hdfs。
- 将hdfs上分区为pdate=20220815,文件路径为 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* 下载到linux 本地进行合并文件,本地路径为:/home/hadoop/pdate/20220815
hadoop fs -getmerge /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* /home/hadoop/pdate/20220815;
- 将hdfs源分区数据删除
hadoop fs -rm /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
- 在hdfs上新建分区
hadoop fs -mkdir -p /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815
- 将本地合并后的文件回传到hdfs上
hadoop fs -put /home/hadoop/pdate/20220815 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
参考文章:
HIVE中小文件问题_hive小文件产生的原因-CSDN博客
Hive教程(09)- 彻底解决小文件的问题-阿里云开发者社区
0704-5.16.2-如何使用Hive合并小文件-腾讯云开发者社区-腾讯云
相关文章:
Hive的小文件问题
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...

攻防世界——re2-cpp-is-awesome
64位 我先用虚拟机跑了一下这个程序,结果输出一串字符串flag ——没用 IDA打开后 F5也没有什么可看的 那我们就F12查看字符串找可疑信息 这里一下就看见了 __int64 __fastcall main(int a1, char **a2, char **a3) {char *v3; // rbx__int64 v4; // rax__int64 v…...
问山海——天涯海角——桃花渊boss攻击顺序
文章目录 桃花渊代码代码解读代码执行结果攻击顺序示意图 桃花渊 规划击杀各个boss顺序。 副本持续时间为30分钟,每个地方的boss被打死后,需要一定时间才能重新刷新。 只考虑其中两种boss,龟将和龟龙。各有四个。 其中我从一个boss地点到…...
springboot181基于springboot的乐享田园系统
简介 【毕设源码推荐 javaweb 项目】基于springbootvue 的 适用于计算机类毕业设计,课程设计参考与学习用途。仅供学习参考, 不得用于商业或者非法用途,否则,一切后果请用户自负。 看运行截图看 第五章 第四章 获取资料方式 **项…...

Dubbo集成Zookeeper embbed模式
为了简化应用支持服务方便的分合,使用Zookeeper embbed模式。集成Zookeeper比较容易,使用starter或自己写代码都可以。但是由于集成了Dubbo,每次启动时都会发现zookeeper没有启动就开始报错退出,但是确是已经集成了。 于是只能翻…...
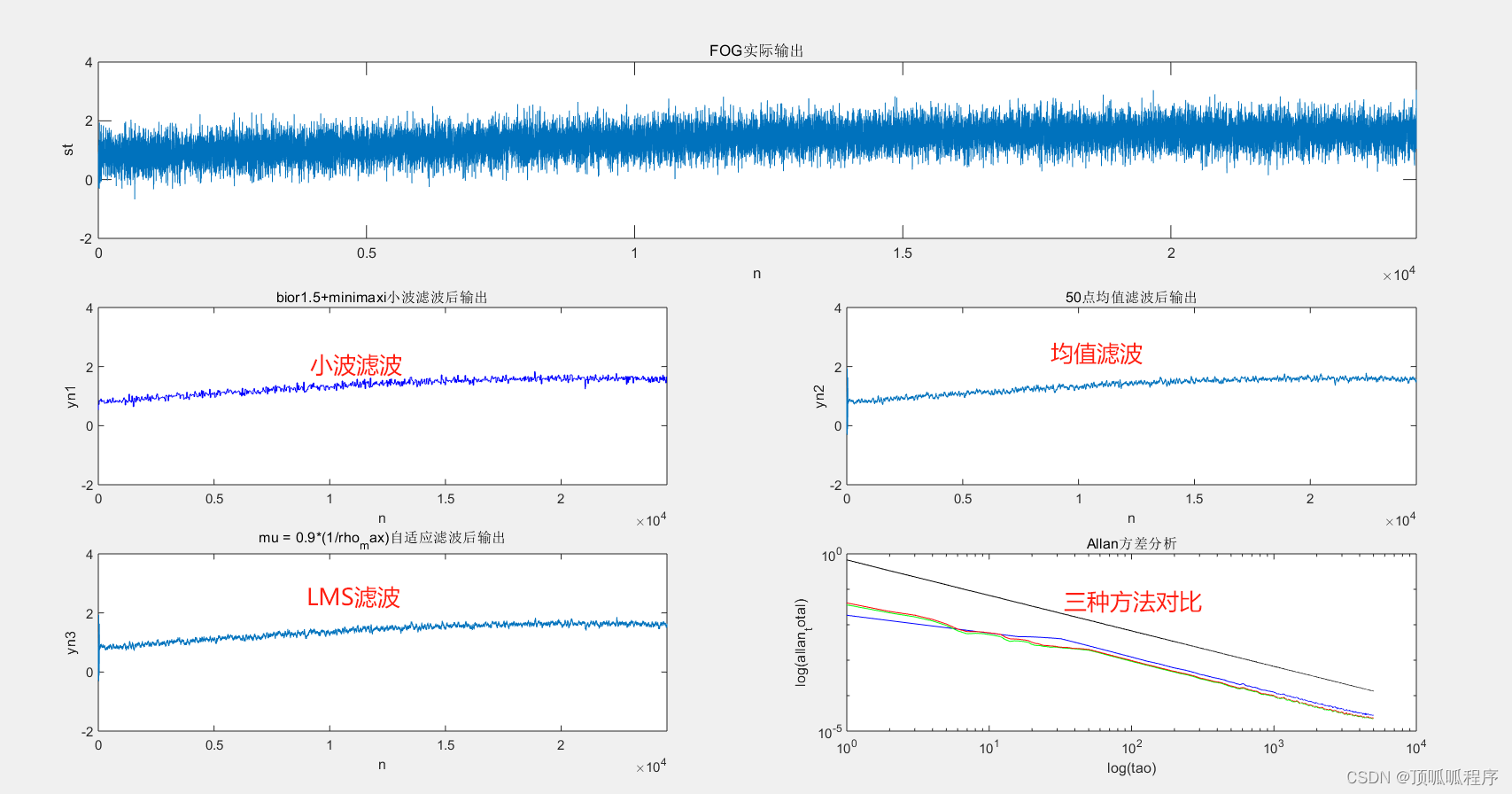
156基于Matlab的光纤陀螺随机噪声和信号
基于Matlab的光纤陀螺随机噪声和信号,利用固定步长和可调步长的LMS自适应滤波、最小二乘法、滑动均值三种方法进行降噪处理,最后用阿兰方差评价降噪效果。程序已调通,可直接运行。 156 信号处理 自适应滤波 降噪效果评估 (xiaohongshu.com)...
秋招上岸大厂,分享一下经验
文章目录 秋招过程学习过程项目经验简历经验面试经验offer选择总结 秋招过程 今天是除夕,秋招已经正式结束了,等春节过完就到了春招的时间点了。 运气比较好,能在秋招的末尾进入一家大厂,拿到20k的sp offer。 从九月份十月份就开…...

使用 C++23 从零实现 RISC-V 模拟器
👉🏻 文章汇总「从零实现模拟器、操作系统、数据库、编译器…」:https://okaitserrj.feishu.cn/docx/R4tCdkEbsoFGnuxbho4cgW2Yntc 使用 C23 从零实现 RISC-V 模拟器 使用 C23 从零实现的 RISC-V 模拟器,最终的模拟器可以运行 x…...
Hugging Face 刚刚推出了一款开源的 AI 助手制造工具,直接向 OpenAI 的定制 GPT 挑战
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

powershell 雅地关闭UDP监听器
在PowerShell中优雅地关闭UDP监听器意味着你需要一种机制来安全地停止正在运行的UdpClient实例。由于UdpClient类本身没有提供直接的停止或关闭方法,你需要通过其他方式来实现这一点。通常,这涉及到在监听循环中添加一个检查点,以便在接收到停…...

Google Cloud 2024 年报告重点介绍了关键的网络威胁和防御
Google Cloud 的 2024 年威胁范围报告预测了云安全的主要风险,并提出了加强防御的策略。 该报告由 Google 安全专家撰写,为寻求预测和应对不断变化的网络安全威胁的云客户提供了宝贵的资源。 该报告强调,凭证滥用、加密货币挖矿、勒索软件和…...

【算法题】102. 二叉树的层序遍历
题目 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] 示例 2:…...

【龙年大礼】| 2023中国开源年度报告!
【中国开源年度报告】由开源社从 2015 年发起,是国内首个结合多个开源社区、高校、媒体、风投、企业与个人,以纯志愿、非营利的理念和开源社区协作的模式,携手共创完成的开源研究报告。后来由于一些因素暂停,在 2018 年重启了这个…...
本地搭建three.js官方文档
因为three.js官网文档是国外的网站,所以你没有魔法的情况下打开会很慢,这时我们需要在本地搭建一个官方文档便于我们学习查看。 第一步:首先我们先访问GitHub地址 GitHub - mrdoob/three.js: JavaScript 3D Library. 下载不下来的小伙伴们私…...

【seata自动化治愈数据库问题解决方案】
wu-database-lazy-seata-cure-plus-starter 描述 针对saas 数据库隔离情况下,每次版本迭代都需要重新修改对应的数据库,对于升级与运维存在一定的难度,那么这个数据库治愈框架来了,使用场景如下 1.数据库不存在自动创建数据库 …...
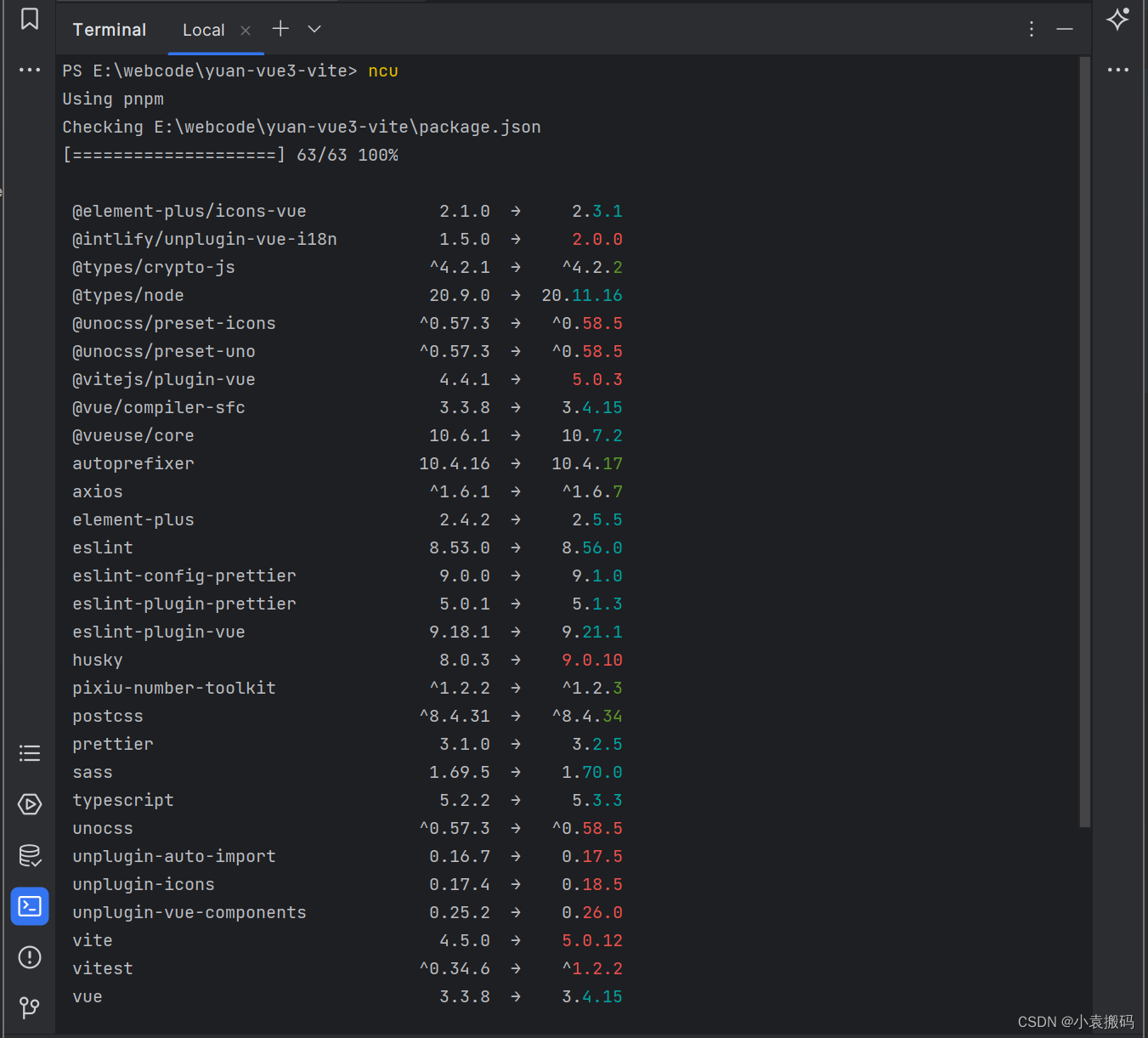
Node.js之npm单独与批量升级依赖包的方式
Node.js之npm单独与批量升级依赖包的方式 文章目录 Node.js之npm单独与批量升级依赖包的方式npm查看与升级依赖包1. 单独安装或升级最新版本2. 查看依赖但不升级1. npm outdated2. npm update 3. 批量升级新版本4. npm-check-updates1. 全局安装2. ncu查看可升级的版本3. 升级依…...

66.加一
66. 加一 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数不会以零开头。 示例 1: 输入ÿ…...

UI自动化之Poco常用断言方式
实际上用到的几种写断言的方式: 1.验证UI界面(断言图片是否存在,UI页面不稳定情况下,图片识别效率不高) assert_exists assert_not_exists 2.验证数值(断言传入的两个值(数字或者string)是否相等ÿ…...

c语言_实现类class的功能 实例
c语言_实现类class的功能 实例 1.需求与背景2.实例1.类的头文件 class_A.h2.类的实现 class_A.c3.引用4.编译与运行 3.总结 1.需求与背景 使用C , python语言久了, 发现 类 class写代码逻辑更方便, 简洁. 封装的API更加易用; 内核代码中, 也经常看到类似类的封装. 自己尝试实现…...

[2024]常用的pip指令
[2024]常用的pip指令 HI,这里是肆十二,好久不见,大家! 新年好! pip是Python的包管理工具,它可以用来安装、升级、卸载Python包。以下是一些常用的pip指令: 安装包: bash复制代码…...

PlotSquared 终极指南:如何在 Minecraft 服务器上安装和配置强大的领地管理插件
PlotSquared 终极指南:如何在 Minecraft 服务器上安装和配置强大的领地管理插件 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared PlotSquared 是一个功能强大的 Minecraft …...

ARM1176JZF芯片架构与时钟管理深度解析
1. ARM1176JZF芯片架构概览 ARM1176JZF是ARMv6架构中的经典处理器内核,广泛应用于嵌入式系统和移动设备。这款芯片采用了先进的流水线设计和动态时钟调节技术,在性能与功耗之间实现了出色的平衡。开发芯片版本特别集成了完整的调试功能和性能监控单元&am…...

CircuitJS1:如何在浏览器中免费创建电子电路仿真
CircuitJS1:如何在浏览器中免费创建电子电路仿真 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款强大的开源电子电路仿真工具,让你直接在浏…...

python系列【仅供参考】:mongo4.0.0 加用户认证 motor和pymongo的auth连接
mongo4.0.0 加用户认证 && motor和pymongo的auth连接 mongo4.0.0 加用户认证 摘要 一. 数据库版本 二. 为mongo 添加用户认证 1. 创建超级用户 3. 开启auth 4.重启mongo 5. 添加库用户 三.验证 四.pymongo,motor连接 摘要 正文 mongo4.0.0 加用户认证 摘要 本文介绍…...

如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定!
如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定! 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而…...

你的耳机真的在发挥全部潜力吗?Equalizer APO带来的音频革命
你的耳机真的在发挥全部潜力吗?Equalizer APO带来的音频革命 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你有没有过这样的体验?花了几千块钱买来的高端耳机,播放…...
)
NotebookLM信息冗余顽疾破解指南(92%用户忽略的3层语义去重机制)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM信息去重的核心挑战与认知重构 NotebookLM 作为 Google 推出的基于用户文档构建的 AI 助手,其核心能力依赖于对上传资料的语义理解与上下文关联。然而,当用户批量导入…...

算力基石:CPU、GPU与嵌入式AI的技术逻辑与融合发展
在人工智能全面普及的时代,算力已经成为数字产业发展的核心驱动力。从日常使用的智能手机、家用电脑,到云端大模型、智能汽车、工业传感设备,各类智能终端的运转都离不开处理器的算力支撑。其中,CPU作为通用计算核心、GPU作为并行…...

英雄联盟个性化改造神器:3分钟打造专属游戏身份
英雄联盟个性化改造神器:3分钟打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 还在为千篇一律的英雄联盟个人资料感到乏味吗?想要在好友面前展示与众不同的游戏身份却苦于官方限制&…...

G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate
G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...