【Linux】线程概念和线程控制
线程概念
- 一、理解线程
- 1. Linux中的线程
- 2. 重新定义线程和进程
- 3. 进程地址空间之页表
- 4. 线程和进程切换
- 5. 线程的优点
- 6. 线程的缺点
- 7. 线程异常
- 8. 线程用途
- 9. 线程和进程
- 二、线程控制
- 1. pthread 线程库
- (1)pthread_create()
- (2)pthread_join()
- (3)pthread_exit()
- (4)pthread_cancel()
- (5)简单使用 pthread 库
- 2. 理解线程库
- (1)线程 id
- (2)线程栈
- (3)线程局部存储
- 3. 分离线程
一、理解线程
什么是线程呢?下面我们直接说定义,再理解。线程就是进程内的一个执行分支,线程的执行粒度要比进程细。
1. Linux中的线程
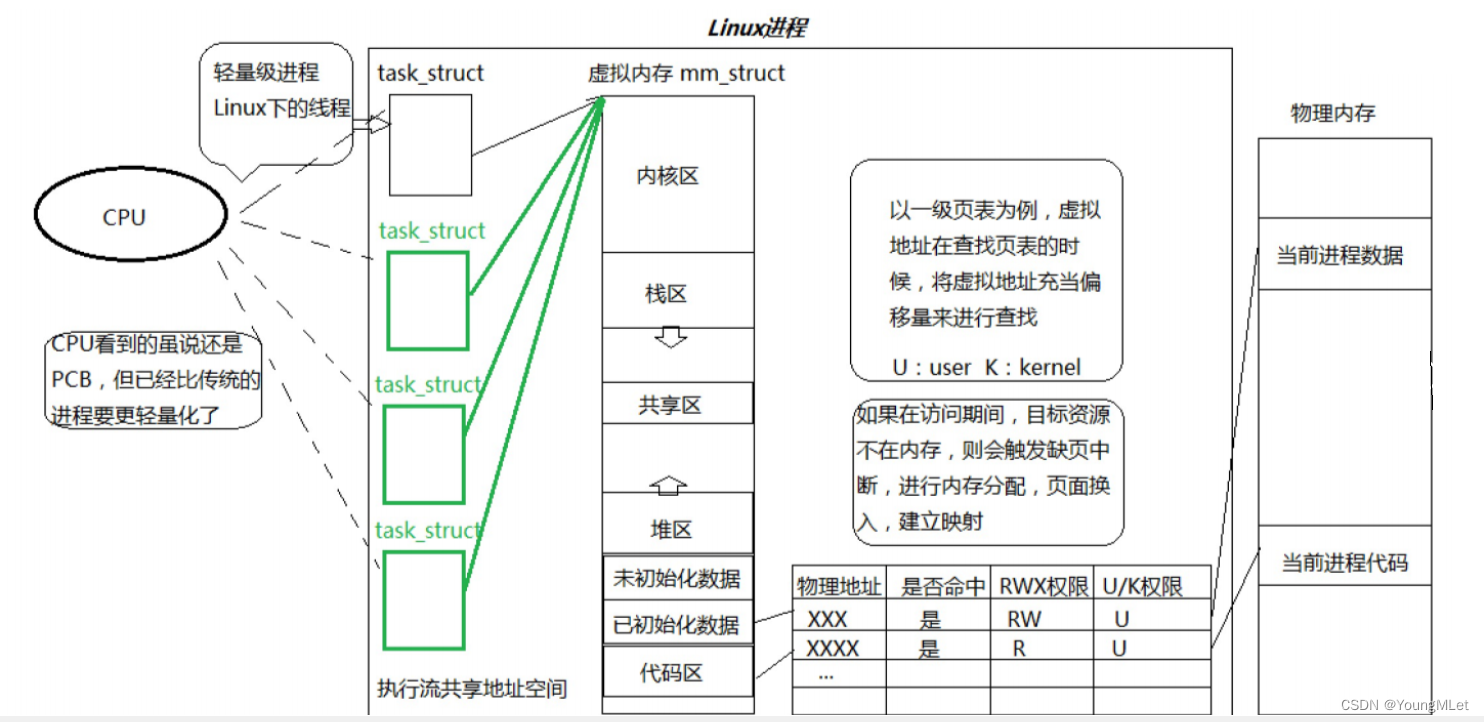
下面我们开始理解一下Linux中的线程。我们以前说过,一个进程被创建出来,要有自己对应的进程PCB的,也就是 task_struct,也要有自己的地址空间、页表,经过页表映射到物理内存中。所以在进程角度,我们能看到进程所有的资源时,目前就能通过地址空间来看,所以地址空间是进程的资源窗口!
以前我们谈的进程,它所创建的地址空间内的所有资源,都是由一个 task_struct 所享有的,那么页表也是属于它独有的。那么如果我们再创建一个“进程”,但是不再给这个“进程”创建新的地址空间和页表,它只需要在创建时指向“父进程”的地址空间。将来“父进程”就将代码区中的代码分一部分给这个“子进程”,以及其它数据分一部分给它,此时我们就可以让“父进程”在运行的时候“子进程”也在运行。那么该父进程能创建一个,就能创建很多个,如下图:
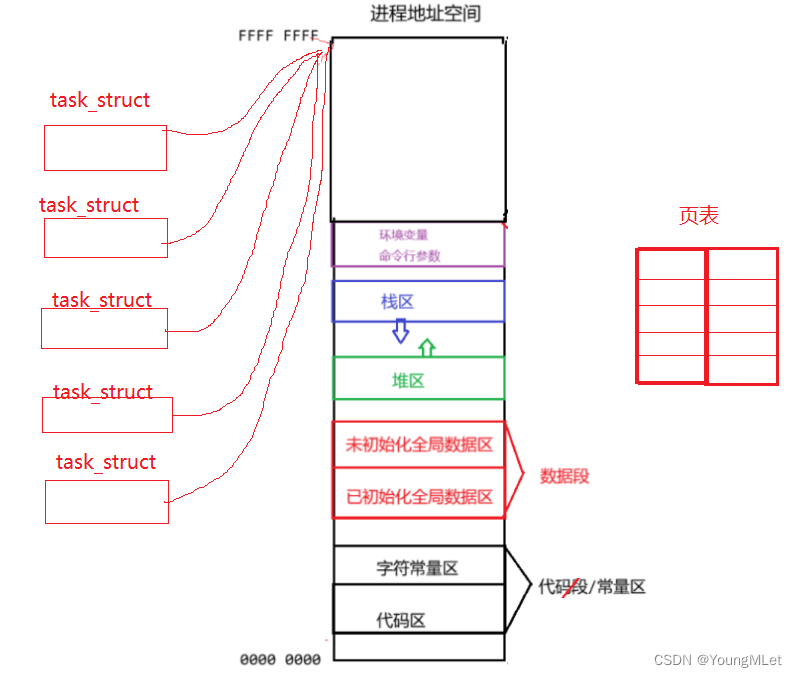
那么我们新创建出来的“子进程”,它们在执行粒度上要比“父进程”的执行粒度要更细一些,因为以前“父进程”需要执行全部代码,而这些“子进程”只需要执行一部分代码,所以,为了明显区分这些“子进程”和“父进程”,我们把这种形式的“子进程”,称为线程!
所以在 Linux 中,线程在进程“内部”执行,也就是线程在进程的地址空间内运行。那么它为什么要在进程的地址空间内运行呢?首先,任何执行流要执行,都要有资源!而地址空间是进程的资源窗口!
那么在 CPU 看来,它知道这个 task_struct 是进程还是线程吗?它需要知道吗?并不需要!因为CPU只有调度执行流的概念!
2. 重新定义线程和进程
那么有了上面的基础,我们现在重新定义线程和进程的概念。
- 线程:我们认为,线程是操作系统调度的基本单位;
所以什么到底什么是进程呢?我们以前说的进程指的是 task_struct 和代码数据,但是今天很显然已经有分歧了,因为它只是地址空间的一个执行分支,一个执行分支不能代表整个进程!那么我们现在需要重新理解一下了,全部 task_struct 执行流都叫做进程执行流,地址空间都叫做进程所占有的资源,页表和该进程所占用的物理内存,我们把这一整套才称之为进程!如下图:
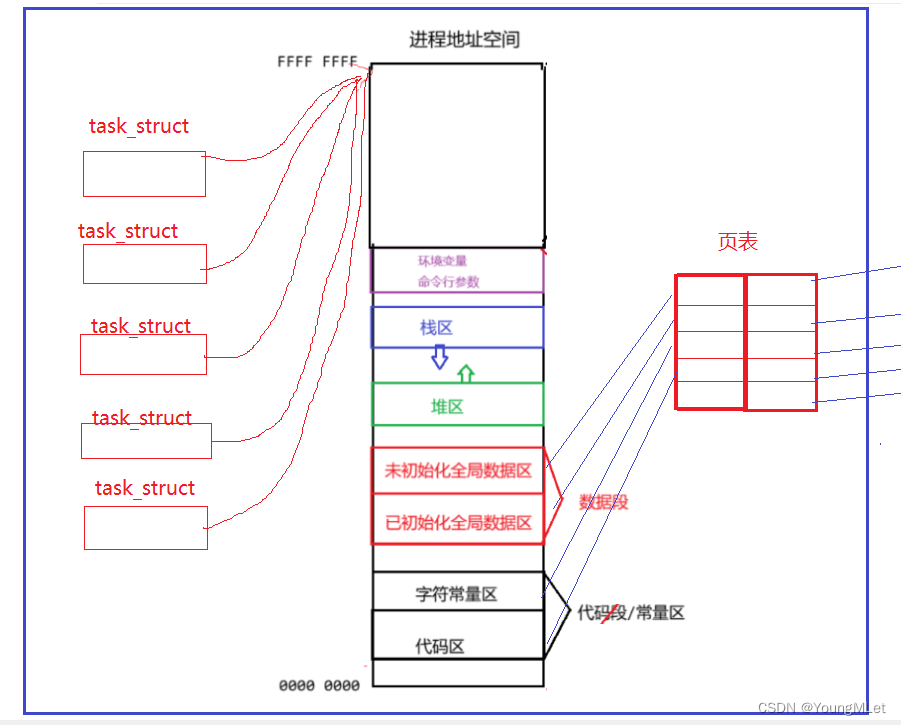
- 进程:进程是承担分配系统资源的基本实体
那么执行流是资源吗?是的!所以不要认为一个进程能被调度,它就是进程的所有,它只是进程内部的一个执行流资源被CPU执行了!所以进程和线程之间的关系是:进程内部是包含线程的,因为进程是承担分配系统资源的基本实体,而线程是进程内部的执行流资源!
那么如何理解我们以前学的进程呢?其实就是操作系统以进程为单位给我们分配资源,只是我们以前进程内部,只有一个执行流资源,也就是只有一个 task_struct!只是我们可以认为,以前我们学的进程只是进程的一种特殊情况!
- 管理线程
那么既然操作系统要对进程管理,如果线程多起来了,操作系统要对线程管理吗?很明显,如果不对线程管理,那么线程就不知道自己属于哪个进程,更不知道应该执行哪个进程的代码,所以必须得对线程管理,所以需要先描述再组织进行管理!
所以除了Linux之外,大多数操作系统都是对线程重新进行先描述再组织,重新为线程建立一个内核数据结构对线程管理起来,而这个结构叫做 struct tcb;除此之外还要把进程和线程之间关联起来。实际上这样做太复杂了,维护的关系太复杂了。那么 Linux 中,没有重新为线程重新设计一个内核数据结构,而是复用进程的数据结构和管理算法!
3. 进程地址空间之页表
我们上面的进程中,创建线程后给线程分配一部分代码和数据,也就是资源,那么我们应该如何理解基于地址空间的多个执行流分配资源的情况呢?怎么知道哪部分资源给哪个线程呢?接下来我们基于地址空间理解一下。
首先CPU里面有一个CR3寄存器,它会保存页表的地址,方便找到进程的页表。我们也知道,物理内存被分为许多的页框,每个页框的大小为 4KB。下面我们理解一下虚拟地址是如何转换为物理地址的,我们以32位的计算机为例,也就是虚拟地址也是32位的。
接下来我们展开说一说页表。首先,页表不是一个整体,我们假设页表是一个整体,就单单是一个映射关系,如下图,每一列分别是虚拟地址、物理地址、权限,假设每一行就10个字节,单单这一个页表建立整个虚拟空间的地址映射关系就需要有 2^32 个映射条目,这样算下来这个页表就已经几十G了,所以页表不可能是这个形式的。
其实 32 位的虚拟地址不是一个整体,其实是将它分为了 10 + 10 + 12,其中 10 + 10 分别代表一级和二级目录。
其中第一级页表,只有 1024 个条目,也就是一个数组,因为用 10 个比特位表示的最大值就是 1024,所以这 10 个比特位代表的十进制数就是该一级页表的下标,而一级页表中存放的是二级页表的地址,所以只需要拿着前十位找到二级页表的地址,找到二级页表,然后拿着次十位,也是 10 个比特位,把它转为十进制数,然后在二级页表中索引它的下标,那么二级页表中存的是什么呢?存的是页框的起始地址!如下图:
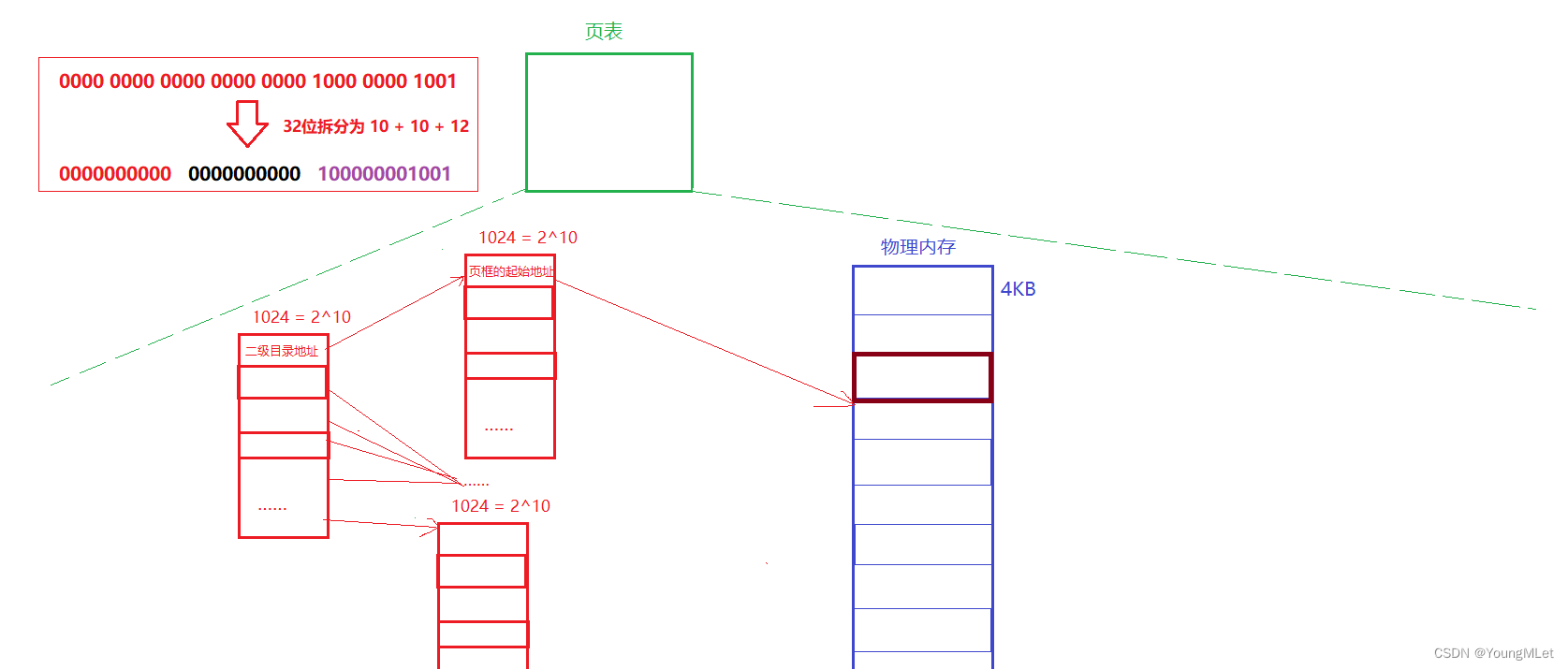
其实这个一级页表就叫做页目录,我们把页目录里面的内容叫做页目录表项;把二级页表里面的内容叫做页表表项。所以我们就能通过虚拟地址的前 20 位找到物理内存中页框的起始地址。
那么剩下的 12 位呢?那么我们知道 2^12 的大小刚好就是 4096,如果取字节为单位,也就是页框的大小!所以剩下的 12 个比特位就是作为某个物理地址的页框中的偏移量!也就是说,物理地址 = 页框起始地址 + 虚拟地址的最后12位!所以这就是虚拟地址到物理地址转换的过程!
在正常情况下,我们不可能将虚拟空间全部用完,所以二级页表也不一定全部存在。所以当需要访问一个虚拟地址时,怎么知道这个虚拟地址在不在物理内存中呢?就有可能在查页目录的时候,它的二级页表的目录根本就不存在,说明就没有被加载到内存,这个时候就是缺页中断。另外,也有可能二级页表和页框没有建立映射关系,在二级页表中还有一个字段中的标记位会记录页框是否存在。
那么就有一个问题了,我们通过页表找到的是物理内存的某一个地址,可是对于某一个类型,可能是 int、double 等等,我们并不是访问一个字节呀,对于上面两种类型我们访问的是 4、8 个字节啊。这时候,就能体现了类型的价值!例如一个整型变量 a,占4个字节,就要有4个地址,但是为什么我们 &a,只拿到了一个地址?因为我们只能取一个地址,那么4个地址中只能取最小的那一个,由于有类型的存在,我们只要从下往上连续读取 4 个字节就能找到它了!也就是根据起始地址+偏移量读取该变量。那么CPU怎么知道根据什么类型读取多少字节呢?其实类型是给 CPU 看的,CPU在读取类型时,是知道有多少字节的!我们根据软件帮CPU找到起始地址,接下来CPU就要读取内存,读的过程把物理内存在硬件上拷贝给CPU,拷贝的时候CPU就知道拷贝多少字节了!
所以我们上面说的 CR3 寄存器中,指向的其实是页目录的地址,任何一个进程必须得有页目录。如果对物理地址进行访问的时候,如果物理地址不存在,或者越界了,CPU 中的 CR2 寄存器,保存的是引起缺页中断或者异常的虚拟地址,完成建立物理地址后就会去 CR2 取回对应的虚拟地址。
最后,我们谈上面的内容都是为了理解如何进行资源分配的,线程的资源全部都是通过地址空间来的,而代码和数据都是通过地址空间+页表映射来的,所以线程分配资源的本质,就是分配地址空间范围!
4. 线程和进程切换
为什么线程比进程要更轻量化呢?
- 创建和释放更加轻量化
- 切换更加轻量化
线程切换时,线程的上下文肯定是要切换的,但是,页表不需要切换,地址空间不需要切换,所以线程在切换的时候,只是局部在切换,所以线程切换的效率更高。
线程在执行,本质就是进程在执行,因为线程是进程的执行分支。线程在执行本质就是进程在调度,CPU内有一个硬件级别的缓存,叫做 cache,cache 也是根据局部性原理,将线程/进程当前访问的代码附近的代码都加载到 cache 中,所以在进程调度的时候它应该会越跑越快,因为它的命中率会越来越高,这部分 cache 我们称为进程运行时的热数据,热数据就是这部分数据被高频访问,所以CPU在硬件上它就会把对应的数据加载到 cache 里。所以在调度的时候,它切换的是一个进程中的多个线程,那么它在切换的时候,此时上下文虽然一直在变化,但是 cache 里的数据一直不变,或者少量的更新,因为每一个线程很多属性都是共享的,就是为了让多个线程同时访问,所以数据就可以在一个进程内部的多个线程互相调度的时候,CPU当前 cache 中的数据就可以被多个线程用上,所以在线程切换的时候,只需要切换线程,不需要对 cache 保存。但是当线程的所有时间片用完了,整个进程也要被切换,CPU寄存器要保存,最重要的是,热缓存数据需要被丢弃掉,把另一个进程放上来,需要重新缓存 cache 中的数据,就要需要由冷变热,这就需要一段时间。所以线程切换的效率更高,更重要的是体现在 cache 数据不需要重新被缓存!
5. 线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多;
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多;
- 线程占用的资源要比进程少很多;
- 能充分利用多处理器的可并行数量;
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务;
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现;
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
6. 线程的缺点
- 性能损失
- 一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低
- 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
- 缺乏访问控制
- 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
- 编程难度提高
- 编写与调试一个多线程程序比单线程程序困难得多。
7. 线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃;
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
8. 线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率;
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)。
9. 线程和进程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
- 线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器(线程上下文)
- 栈
- errno
- 信号屏蔽字
- 调度优先级
进程的多个线程共享同一地址空间,因此代码区数据区都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到。除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户 id 和组 id
二、线程控制
1. pthread 线程库
因为 Linux 中没有专门为线程设计一个内核数据结构,所以内核中并没有很明确的线程的概念,而是用进程模拟的线程,只有轻量级进程的概念。这就注定了 Linux 中不会给我们直接提供线程的系统调用,只会给我们提供轻量级进程的系统调用!可是我们用户需要线程的接口,所以在用户和系统之间,Linux 开发者们给我们开发出来一个 pthread 线程库,这个库是在应用层的,它是对轻量级进程的接口进行了封装,为用户提供直接线程的接口!虽然这个是第三方库,但是这个库是几乎所有的 Linux 平台都是默认自带的!所以在 Linux 中编写多线程代码,需要使用第三方库 pthread 线程库!
(1)pthread_create()
接下来我们介绍 pthread 库中的第一个接口,创建一个线程:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
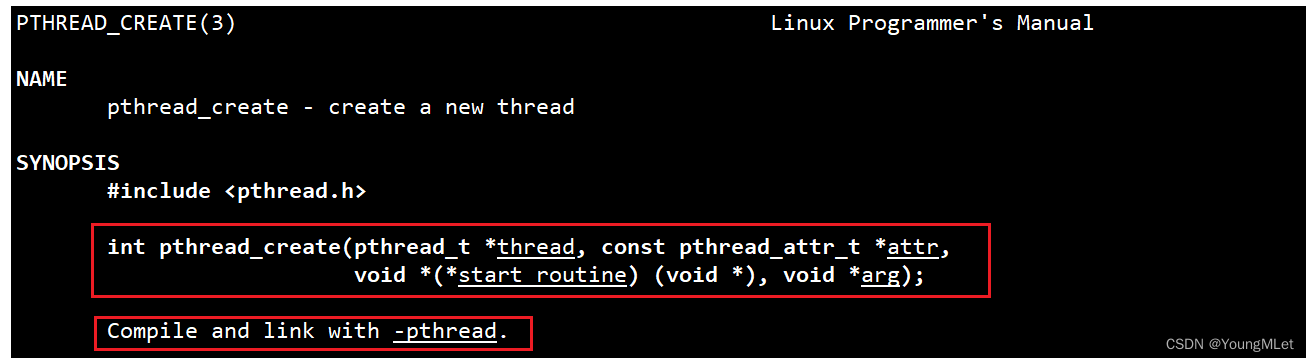
其中第一个参数是一个输出型参数,一旦我们创建好线程,我们是需要线程 id 的,所以该参数就是把线程 id 带出来;第二个参数 attr 为线程的属性,我们不用关心,设为 nullptr 即可。
第三个参数是一个函数指针类型,也就是说我们需要传一个函数进去。当我们创建线程的时候,我们是想让执行流执行代码的一部分,那么我们就可以把该线程要执行入口函数地址传进去,线程一启动就会转而执行该指针指向的函数处!关于该函数指针的返回值和参数,都是 void*,因为 void* 可以接收或者返回任意指针类型,这样就可以支持泛型了。而第四个参数 arg 是一个输入型参数,当线程创建成功,新线程回调线程函数的时候,如果需要参数,这个参数就是给线程函数传递的,也就是说该参数是给第三个参数函数指针中的参数传递的。

而函数的返回值,如果我们创建成功就返回0;如果失败会返回错误码,而没有设置 errno.
最后我们在编译的时候需要加上 -lpthread 指定库名称。
示例代码:
void* pthread_handler(void* attr){while(1){cout << "i am a new thread, pid: " << getpid() << endl;sleep(2);}}int main(){pthread_t tid;pthread_create(&tid, nullptr, pthread_handler, nullptr);while(1){cout << "i am main thread, pid: " << getpid() << endl;sleep(1);}return 0;}
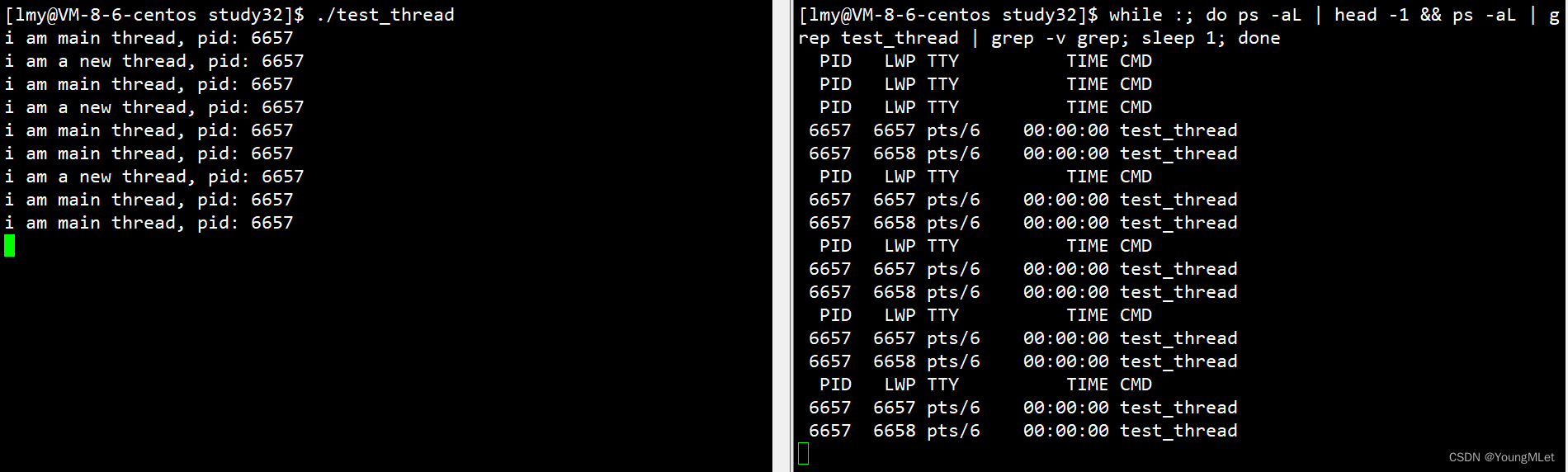
如上图,我们以前写的代码中是不可能出现两个死循环的,但是使用创建线程之后就可以了,这就说明它们是不同的执行流。而它们的 pid 是一样的,就说明它们是同一个进程。
而我们右侧终端中,正在查看两个执行流,其中查看执行流的指令为:ps -aL,我们上面循环打印了方便观察,我们看到 pid 是一样的,但是 LWP 是什么呢?为什么会不一样呢?在 Linux 中没有具体的线程概念,只有轻量级进程的概念,所以 CPU 在调度时,不仅仅只要看 pid,更重要的是每一个轻量级进程也要有自己对应的标识符,所以轻量级进程就有了 LWP (light weight process)这样的标识符,所以 CPU 是按照 LWP 来进行调度的!
但是我们如果杀掉上面任意一个执行流的 LWP,默认整个进程都会被终止,这就是线程的健壮性差的原因。
如果我们定义一个函数,或者全局变量,分别在两个执行流中执行,它们都可以读取到该函数和全局变量,如下代码:
void Print(const string& str){cout << str << endl;}void* pthread_handler(void* attr){while(1){cout << "i am a new thread, pid: " << getpid() << ", val = " << val << endl;Print("i am new thread");sleep(2);}}int main(){pthread_t tid;pthread_create(&tid, nullptr, pthread_handler, nullptr);while(1){cout << "i am main thread, pid: " << getpid() << ", val = " << val << endl;Print("i am main thread");val++;sleep(1);}return 0;}
有关线程的 id 的问题我们后面再谈。
(2)pthread_join()
那么创建线程后是主线程先运行还是新线程先运行呢?不确定,要看CPU先调度谁,那么肯定的是主线程是最后退出的!因为主线程退了整个进程就退出了,所以主线程要进行线程等待!如果主线程不进行线程等待,会导致类似于僵尸进程的问题!而 pthread_join() 就是进行线程等待的接口。
int pthread_join(pthread_t thread, void **retval);
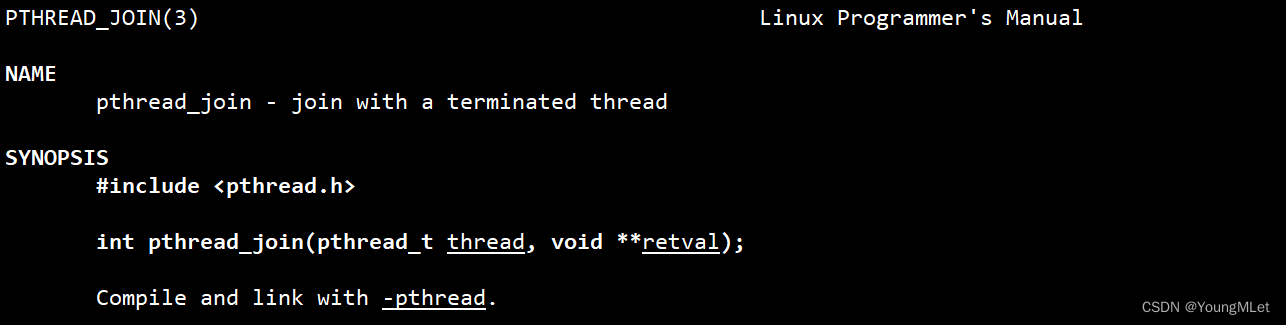
其中第一个参数,为线程的 id;第二个参数 retval 我们先不管,后面再介绍,设为 nullptr 即可。下面我们简单写一个程序:
void* pthread_handler(void* attr){int cnt = 5;while(cnt--){cout << "i am a new thread, pid: " << getpid() << endl;sleep(1);}}int main(){pthread_t tid;pthread_create(&tid, nullptr, pthread_handler, nullptr);pthread_join(tid, nullptr);cout << "main thread quit..." << endl;return 0;}
结果如下:
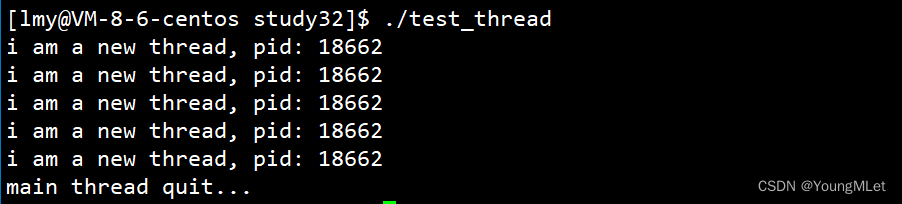
我们可以看到当新线程在运行的时候,主线程并没有直接运行结束,而是进行阻塞等待!
接下来我们说一下第二个参数 retval;其实我们给线程分配的函数,它的返回值是直接写入 pthread 库中的,而 retval 也是被封装在库中,所以我们可以根据 retval 读取到函数的返回值,也就是说这个 retval 就是一个输出型参数!首先我们需要定义一个 void* 类型的变量,然后将这个变量取地址当作 pthread_join 的第二个参数传入即可!例如以下代码:
void* pthread_handler(void* attr){return (void*)1234;}int main(){pthread_t tid;pthread_create(&tid, nullptr, pthread_handler, nullptr);void* retval;pthread_join(tid, &retval);cout << "main thread quit, retval = " << (long long)retval << endl;return 0;}

(3)pthread_exit()
那么除了在函数中直接 return 终止线程外,还有什么方法吗?有的,pthread_exit() 接口就是用来终止线程的:
void pthread_exit(void *retval);
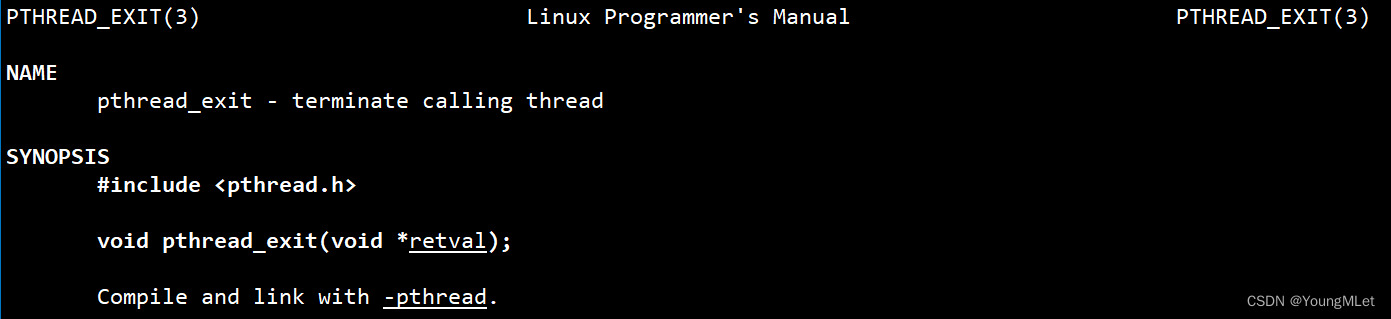
参数就是和 void* 返回值一样。注意线程内不能使用 exit() 系统接口终止线程,因为 exit() 是用来终止进程的!例如:
void* pthread_handler(void* attr){pthread_exit((void*)1234);}

(4)pthread_cancel()
除了上面的方法,pthread_cancel() 也可以取消一个线程,参数就是目标线程的 id:
int pthread_cancel(pthread_t thread);
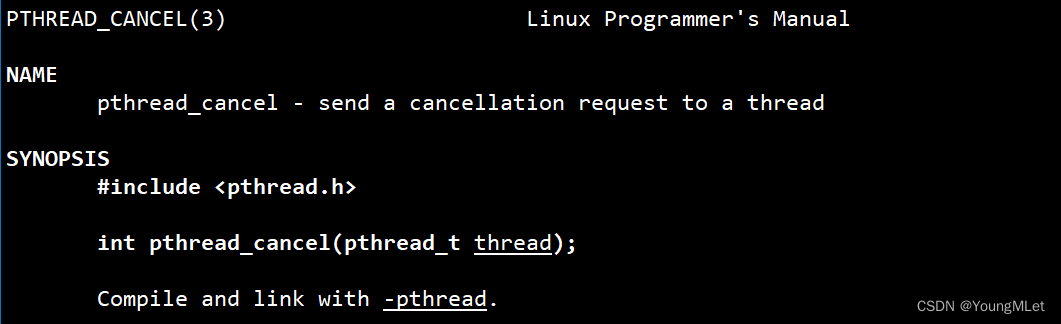
返回值如下:

如果 thread 线程被别的线程调用 pthread_ cancel 异常终掉, pthread_join 第二个参数 retval 所指向的单元里存放的是常数PTHREAD_ CANCELED,也就是 -1.
(5)简单使用 pthread 库
假设我们现在需要写一个线程进行整数相加,代码如下:
Request 类为一个需求类,_start 和 _end 为需要求的整数相加的范围。
class Request{public:Request(int start, int end):_start(start),_end(end){}~Request(){cout << "~Request()" << endl;}public:int _start;int _end;};
Result 类为一个结果的类,Run 方法为求和方法;_result 为计算结果;_exitcode 为记录计算结果是否可靠。
class Result{public:Result(int result, int exitcode):_result(result),_exitcode(exitcode){}void Run(int start, int end){for(int i = start; i <= end; i++){_result += i;}}~Result(){cout << "~Result()" << endl;}public:int _result; // 计算结果int _exitcode; // 计算结果是否可靠};
下面为测试代码:
void* countSum(void* args){Request* rq = static_cast<Request*>(args);Result* res = new Result(0, 0);res->Run(rq->_start, rq->_end);return res;}int main(){Request* rq = new Request(1, 100);pthread_t tid;pthread_create(&tid, nullptr, countSum, rq);void* res;pthread_join(tid, &res);Result* req = static_cast<Result*>(res);cout << req->_result << endl;delete req;delete rq;return 0;}
结果如下:

所以线程的参数和返回值,不仅仅可以用来进行传递一般参数,也可以传递对象!
2. 理解线程库
(1)线程 id
我们上面学习了 pthread_create() 接口,但是第一个参数就是线程的 id,我们至今都没有介绍过它,所以我们可以尝试打印一下看一下它究竟长什么样,如下:
int main(){pthread_t tid;pthread_create(&tid, nullptr, mythread, nullptr);cout << "tid = " << tid << endl;pthread_join(tid, nullptr);return 0;}

我们可以看到 tid 是一个非常大的数字,假设我们换成十六进制呢?如下图:

我们可以看到,它很像一个地址。
如果线程想要获得自己的线程 id,还可以通过线程库中的接口获得,如下:
pthread_t pthread_self(void);
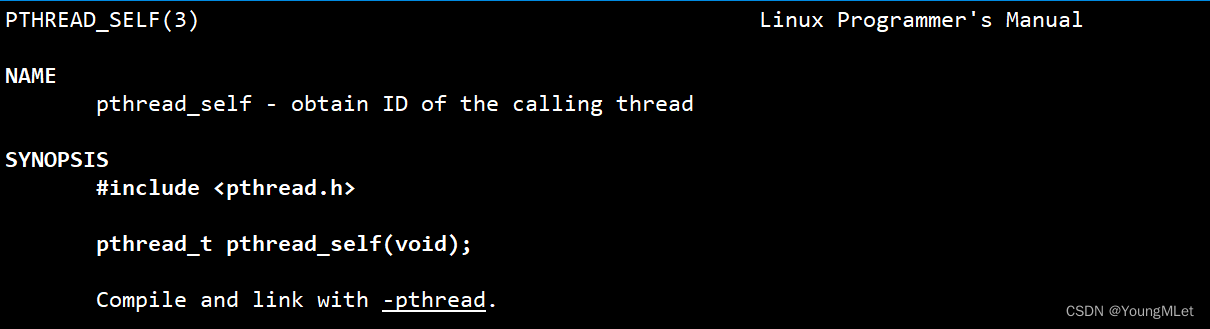
返回值就是线程的 id.
那么这个线程 id 究竟是什么呢?因为 Linux 中没有明确的线程概念,所以没有直接提供线程的系统接口,只能给我们提供轻量级进程的系统接口,那么系统中是怎么创建轻量级进程呢?其实是用 clone() 接口,如下:
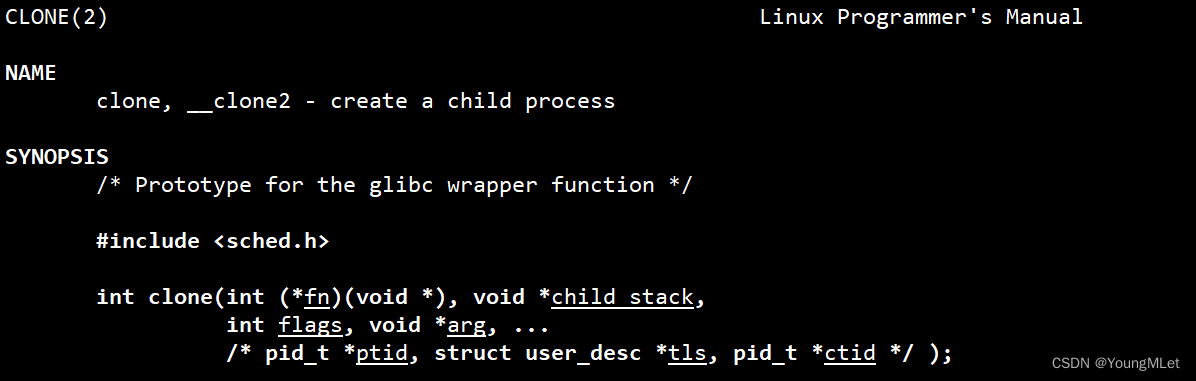
其实这个接口就是创建一个子进程,fork() 的底层原理和 clone() 类似,但是 clone() 是专门用来创建轻量级进程的。第一个参数函数指针类型,就是新创建执行流要执行的函数地址入口;第二个参数 child stack 就是自己自定义的栈;第三个参数就是是否让地址空间共享;后面的参数就不用关心了。
所以,这个接口就被线程库封装了,给我们提供的就是我们上面所介绍的线程库的接口。所以,clone() 允许用户传入一个回调函数和一个用户空间,来代表这个轻量级进程运行过程中所执行的代码,它在运行中的临时变量全部放在用户空间栈上。也就是说,线程库需要封装 clone() 的话,线程库中每一个线程都要给 clone() 提供执行方法,还要在线程库中开辟空间。所以,线程的概念是库给我们维护的。另外,我们用的第三方线程库,是需要加载到内存里的!而且是加载到共享区中!那么,在 pthread 库里面,每个创建好的线程,它就要为该线程在库里面开辟一段空间,用来充当新线程的栈!也就是说,新线程的栈是在共享区当中的!
那么,线程的概念是库给我们维护的,也就是说线程库要维护线程的概念,不需要维护线程的执行流。也就是,线程库中的线程在底层中对应的其实是轻量级进程的执行流,但是线程相关的属性等字段,必须需要库来维护!所以线程库注定了要维护多个线程属性的集合,所以线程库需要先描述,再组织管理这些线程!如下图:
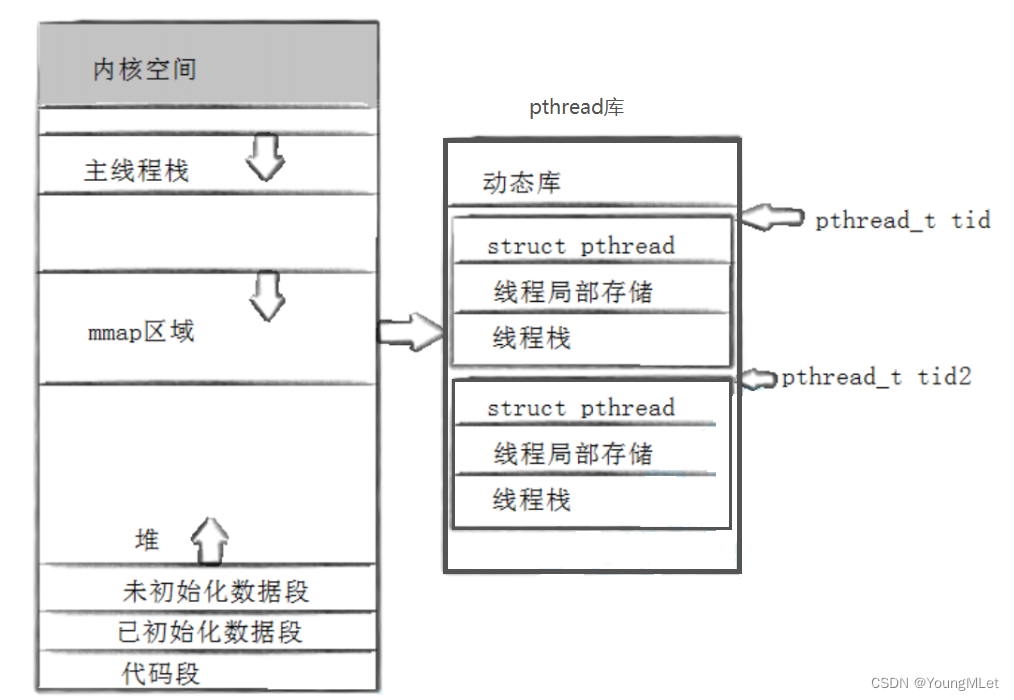
所以,我们每创建一个线程,在线程库中就要为我们创建线程库级别的线程,我们把它叫做线程控制块。所以这个线程控制块我们就可以理解成 tcb,那么对于每一个 tcb 在库中可以理解成用数组的方式进行管理维护。所以为了让我们快速找到在共享库中的每一个 tcb,我们把每一个 tcb 在内存中的起始地址称为线程的 tid,即线程的 id!
(2)线程栈
每一个线程在运行时,一定要有自己独立的栈结构,因为每一个线程都要有自己的调用链,也就是说每一个线程都要有自己调用链所对应的栈帧结构。这个栈结构会保存任何一个执行流在运行过程中的所有临时变量。其中,主线程用地址空间提供的栈结构即可,而新线程则是首先在库中创建一个线程控制块,这个控制块中有包含默认大小的空间,就是线程栈;然后库就要帮我们调用系统接口 clone() 帮我们创建执行流,最重要的是它会帮我们把线程栈传递给 clone() ,作为它的第二个参数!
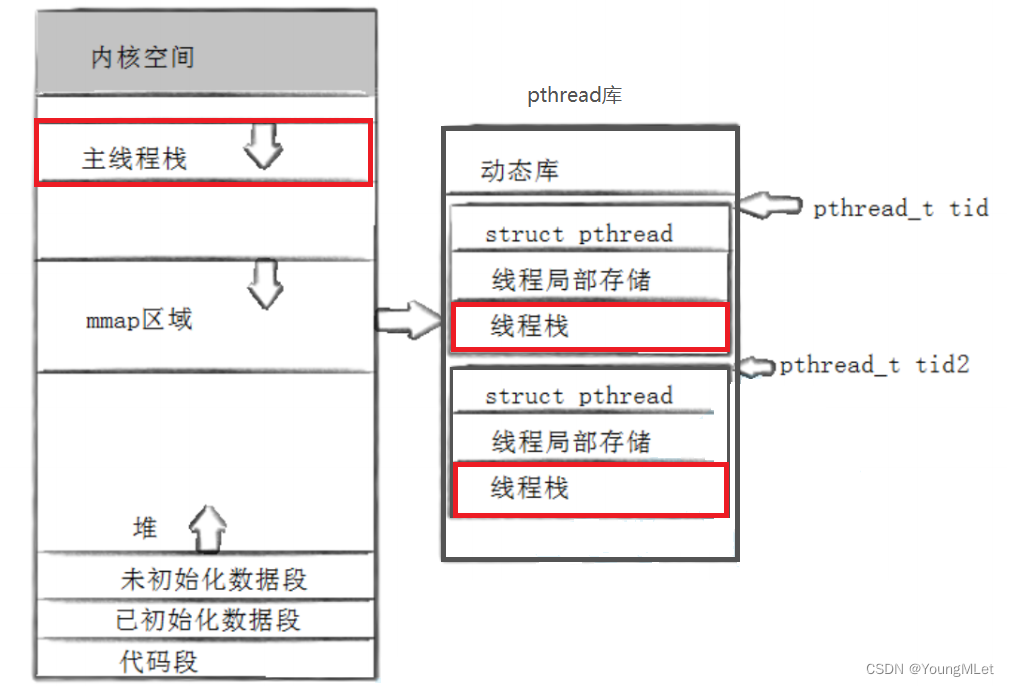
所以,所有对应的非主线程的栈都在库中进行维护,即在共享区中维护,具体来说,是在 pthread 库中 tid 指向的线程控制块中!
我们可以写代码验证一下每一个线程都有自己独立的栈,代码链接:验证独立栈.
结果如下,test_stack 是三个线程里的临时变量,它们的地址都不一样:

同时我们也可以验证,全局变量是可以被所有线程同时看到并访问的。
其实线程和线程之间,几乎没有秘密,虽然它们是独立的栈,但是线程上的数据也是可以被其它线程访问到的。
(3)线程局部存储
我们知道,全局变量是可以被所有线程访问的,但是假设我们的线程想要一个私有的全局变量呢?我们可以在一个全局变量前加上 __thread,如下:
__thread int g_val = 100;
接下来我们使用上面的代码,设置这样一个全局变量,并打印它的信息出来观察:
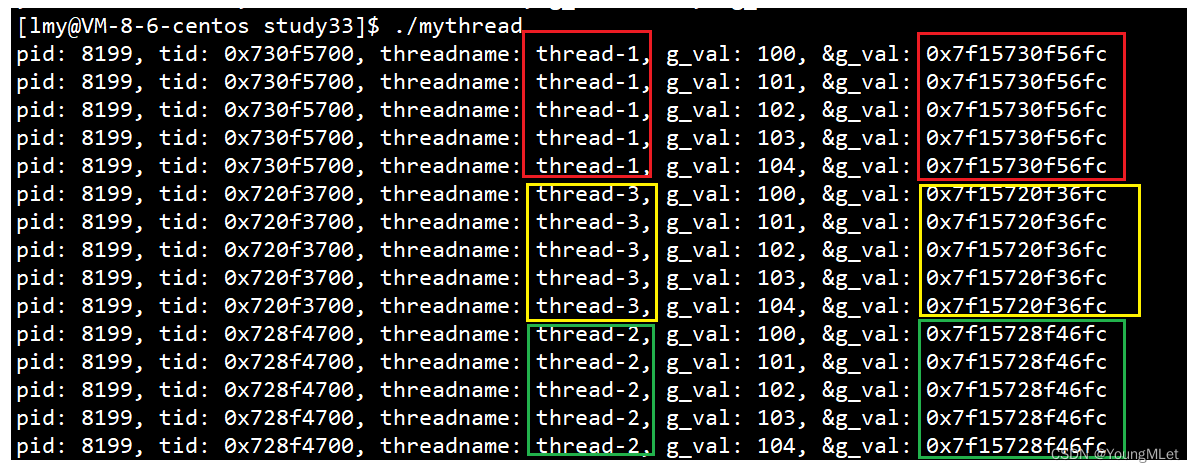
我们发现,每一个线程中的 g_val 的地址都是不一样的!而且对 g_val 运算的时候,它们互不干扰!所以这个 g_val 加上 __thread,就变成了线程的全局变量!其实 __thread 不是 C/C++ 提供的,而是一个编译选项。我们发现,打印出来的地址非常大,因为它是在堆栈之间的地址!它是位于线程控制块的线程局部存储区域!
注意,线程局部存储只能定义内置类型,不能定义自定义类型!
3. 分离线程
-
默认情况下,新创建的线程是 joinable 的,线程退出后,需要对其进行 pthread_join 操作,否则无法释放资源,从而造成系统泄漏。
-
如果不关心线程的返回值,join 是一种负担,因为主线程需要等待其它线程,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源,这就叫做线程的分离,可以用如下接口:
int pthread_detach(pthread_t thread);
其中参数就是线程的 tid.
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());
相关文章:
【Linux】线程概念和线程控制
线程概念 一、理解线程1. Linux中的线程2. 重新定义线程和进程3. 进程地址空间之页表4. 线程和进程切换5. 线程的优点6. 线程的缺点7. 线程异常8. 线程用途9. 线程和进程 二、线程控制1. pthread 线程库(1)pthread_create()(2)pth…...
maven创建webapp+Freemarker组件的实现
下载安装配置maven Maven官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘123云盘为您提供Maven最新版正式版官方版绿色版下载,Maven安卓版手机版apk免费下载安装到手机,支持电脑端一键快捷安装https://www.123pan.com/s/9QRqVv-TcUY.html链接为3.6.2-3.6.3的版本 下载解…...
Stable Diffusion 模型下载:Samaritan 3d Cartoon SDXL(撒玛利亚人 3d 卡通 SDXL)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十...

Oracle系列之十:Oracle正则表达式
Oracle正则表达式 1. 基本语法2. POSIX字符类3. 正则表达式函数4. 常用正则表达式 正则表达式 (Regular expression) 是一种强大的文本处理工具,Oracle数据库自9i版本开始引入了正则表达式支持,可帮助开发者快速而准确地匹配、查找和替换字符串ÿ…...
php基础学习之运算符(重点在连接符和错误抑制符)
运算符总结 在各种编程语言中,常用的运算符号有这三大类: 算术运算符:,-,*,/,%位运算符:&,|,^,<<,>>赋值运算符&…...

【CC工具箱1.2.0】更新_免费无套路,60+个工具,原码放出
CC工具箱目前已经更新到1.2.0版本,完全免费无套路。 适用版本ArcGIS Pro 3.0及以上。 欢迎大家使用,反馈bug,以及提出需求和意见,时间和能力允许的话我会尽量满足要求。 如有关于工具的使用问题和需求建议,可以加下…...
Java 将TXT文本文件转换为PDF文件
与TXT文本文件,PDF文件更加专业也更适合传输,常用于正式报告、简历、合同等场合。项目中如果有使用Java将TXT文本文件转为PDF文件的需求,可以查看本文中介绍的免费实现方法。 免费Java PDF库 本文介绍的方法需要用到Free Spire.PDF for Java…...

Sketch 99.1 for macOS
Sketch 99.1 for macOS 概述 这个程序是对矢量绘图的创新性和焕然一新的看法。它特意采用了极简主义的设计,基于一个大小无限、图层自由的绘图空间,没有调色板、面板、菜单、窗口和控件。 此外,它提供了强大的矢量绘图和文本工具,…...
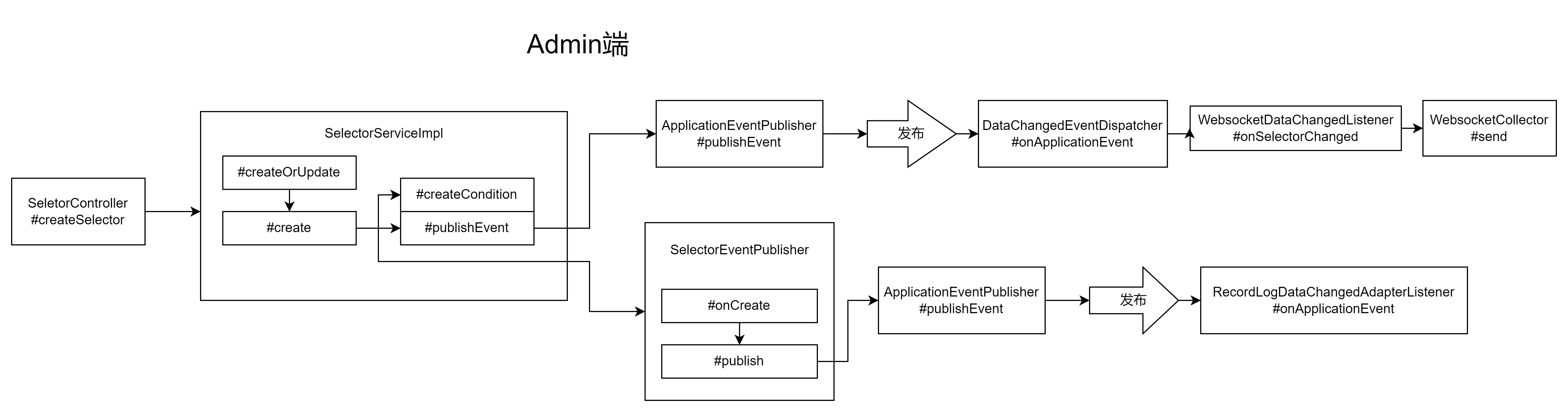
Apache 神禹(shenyu)源码阅读(一)——Admin向Gateway的数据同步(Admin端)
源码版本:2.6.1 单机源码启动项目 启动教程:社区新人开发者启动及开发防踩坑指南 源码阅读 前言 开了个新坑,也是第一次阅读大型项目源码,写文章记录。 在写文章前,已经跑了 Divide 插件体验了一下(体…...
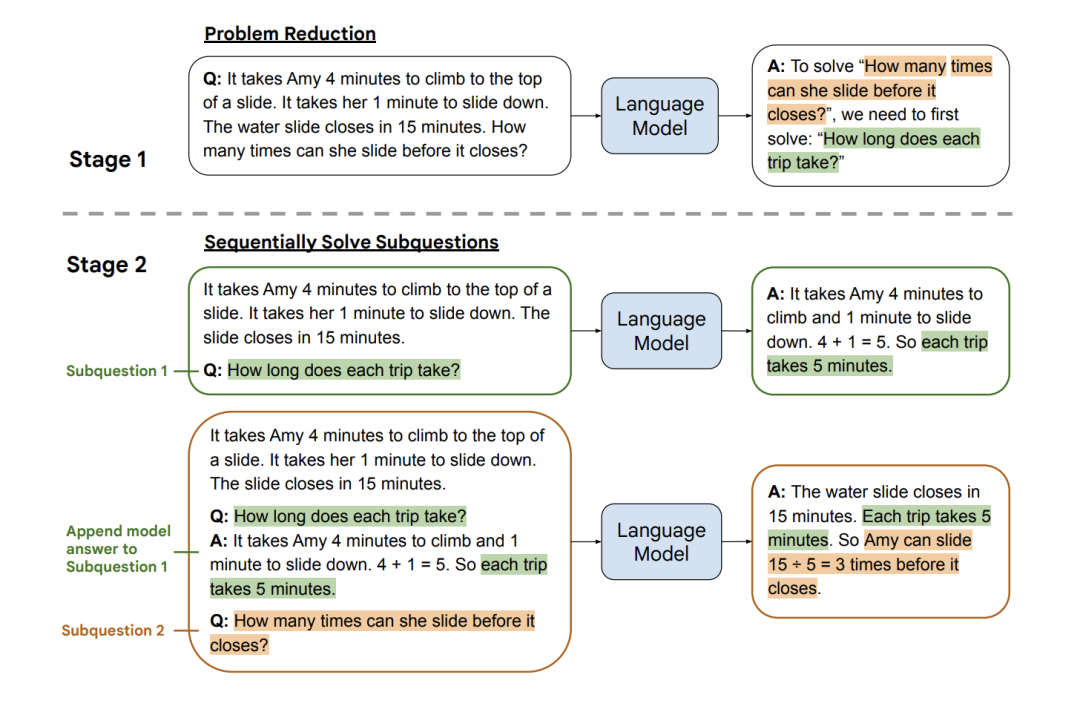
Prompt Tuning:深度解读一种新的微调范式
阅读该博客,您将系统地掌握如下知识点: 什么是预训练语言模型? 什么是prompt?为什么要引入prompt?相比传统fine-tuning有什么优势? 自20年底开始,prompt的发展历程,哪些经典的代表…...

Unity3d Shader篇(五)— Phong片元高光反射着色器
文章目录 前言一、Phong片元高光反射着色器是什么?1. Phong片元高光反射着色器的工作原理2. Phong片元高光反射着色器的优缺点优点缺点 二、使用步骤1. Shader 属性定义2. SubShader 设置3. 渲染 Pass4. 定义结构体和顶点着色器函数5. 片元着色器函数 三、效果四、总…...

sql求解连续两个以上的空座位
Q:查找电影院所有连续可用的座位。 返回按 seat_id 升序排序 的结果表。 测试用例的生成使得两个以上的座位连续可用。 结果表格式如下所示。 A:我们首先找出所有的空座位:1,3,4,5 按照seat_id排序(上面已…...

【链表】-Lc146-实现LRU(双向循环链表)
写在前面 最近想复习一下数据结构与算法相关的内容,找一些题来做一做。如有更好思路,欢迎指正。 目录 写在前面一、场景描述二、具体步骤1.环境说明2.双向循环链表3.代码 写在后面 一、场景描述 运用你所掌握的数据结构,设计和实现一个 LRU (…...

MYSQL学习笔记:MYSQL存储引擎
MYSQL学习笔记:MYSQL存储引擎 MYSQL是插件式的存储引擎 存储引擎影响数据的存储方式 存储引擎是用来干什么的,innodb和myisam的主要区别–数据存储方式----索引 mysql> show engines; ----------------------------------------------------------…...

Bitcoin Bridge:治愈还是诅咒?
1. 引言 主要参考: Bitcoin Bridges: Cure or Curse? 2. 为何需关注Bitcoin bridge? 当前的Bitcoin bridge,其所谓bridge,实际是deposit: 在其它链上的BTC情况为: 尽管当前约有43.7万枚BTC在其它链上…...
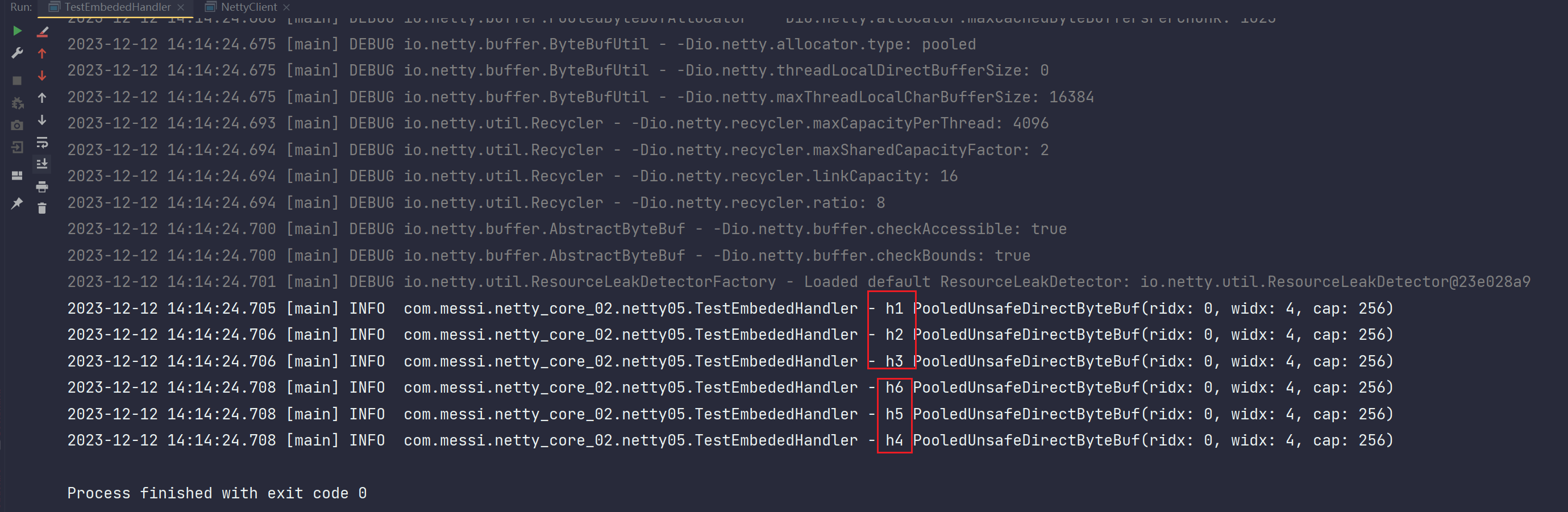
Netty应用(七) 之 Handler Netty服务端编程总结
目录 15.Handler 15.1 handler的分类 15.1.1 按照方向划分 15.1.2 handler的结构 15.2 输入方向ChannelInboundHandlerAdapter 15.2.1 输出方向Handler的顺序 15.2.2 多个输入方向Handler之间的数据传递 15.2.2.1 handler消失了 15.2.2.2 手动编写netty提供的new Strin…...

LeetCode、1268. 搜索推荐系统【中等,前缀树+优先队列、排序+前缀匹配】
文章目录 前言LeetCode、1268. 搜索推荐系统【中等,前缀树优先队列、排序前缀匹配】题目类型及分类思路API调用(排序前缀匹配)前缀树优先队列 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创…...

计算机视觉基础:矩阵运算
矩阵及其表示方式 一个矩阵是由行(row)和列(column)组成的一个矩形数组,通常包含数字。我们可以用大写字母(如 A、B)来表示一个矩阵。例如,矩阵 A 可能看起来像这样: A [ a11 a12 a13 ][ a21 a22 a23 ][ a31 a32 a3…...

Gateway中Spring Security6统一处理CORS
文章目录 一、起因二、解决方法 一、起因 使用了gateway微服务作为整体的网关,并且整合了Spring Security6;还有一个system微服务,作为被请求的资源,当浏览器向gateway发送请求,请求system资源时,遇到CORS…...
)
突破编程_C++_基础教程(输入、输出与文件)
1 流和缓冲区 C中,流( stream )和缓冲区( buffer )是两个紧密相关的概念,它们在处理输入和输出时起着重要的作用。 流( Stream ) 流是一种抽象的概念,用于表示数据的流动…...

从数学建模到流畅体验:smooth-signature如何重塑电子签名技术范式
从数学建模到流畅体验:smooth-signature如何重塑电子签名技术范式 【免费下载链接】smooth-signature H5带笔锋手写签名,支持PC端和移动端,任何前端框架均可使用 项目地址: https://gitcode.com/gh_mirrors/smo/smooth-signature 在数…...

3步解锁B站缓存视频:m4s-converter让你的离线收藏永不过期
3步解锁B站缓存视频:m4s-converter让你的离线收藏永不过期 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 当B站视频突然下架&#x…...

ElevenLabs蒙古文语音接入全攻略:从API密钥配置到蒙古文音素对齐的7步落地法
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs蒙古文语音接入的背景与技术价值 随着全球多语言AI语音技术加速演进,蒙古语作为联合国教科文组织列为“脆弱型”语言之一,其数字语音合成能力长期受限于高质量语音数据…...

告别Python程序分发难题:Auto PY to EXE图形化打包终极指南
告别Python程序分发难题:Auto PY to EXE图形化打包终极指南 【免费下载链接】auto-py-to-exe Converts .py to .exe using a simple graphical interface 项目地址: https://gitcode.com/gh_mirrors/au/auto-py-to-exe 还在为Python程序分享而烦恼吗&#x…...

STM32F407用HAL库驱动42步进电机,从CubeMX配置到代码调试的完整避坑指南
STM32F407 HAL库驱动42步进电机实战:从CubeMX配置到高效调试的完整指南 第一次用STM32F407的HAL库驱动42步进电机时,我花了整整三天时间才让电机转起来。最让我抓狂的是明明CubeMX配置看起来一切正常,TIM1通道就是死活不出PWM波形。后来才发现…...

Camunda流程版本管理避坑指南:从Version Tag查询到迁移验证,这些细节决定成败
Camunda流程版本管理实战精要:从精准查询到安全迁移的全链路策略 在企业级流程自动化领域,Camunda作为领先的工作流引擎,其版本管理机制直接影响着业务系统的稳定性和迭代效率。本文将深入剖析版本管理的核心痛点,提供一套覆盖全…...

Perplexity习语查询响应延迟超800ms?3个冷启动配置错误正在 silently 毁掉你的语言生产力
更多请点击: https://kaifayun.com 第一章:Perplexity习语查询功能概览 Perplexity 的习语查询功能专为语言学习者与内容创作者设计,支持对英语中高频、多义、文化负载型习语进行上下文感知的精准解析。该功能不仅返回标准释义,还…...

别再死记硬背公式了!用Python实战SCS模型,5分钟搞定城市降雨径流估算
用Python实战SCS模型:5分钟自动化城市降雨径流分析 水文工程师们是否厌倦了手动查表计算CN值?环境分析师是否还在为重复的径流公式推导头疼?今天我们将用Python彻底改变传统工作流——无需记忆复杂公式,只需5行核心代码即可完成从…...

图数据库 TuGraph 基本操作 作业一
一、基础知识介绍(一) 图数据库图数据库以顶点 (Vertex / Node)、边 (Edge / Relationship) 与属性 (Property) 三种元素表达事物及其关联关系。顶点对应实体, 边对应实体之间的关系, 属性以键值对形式附着在顶点或边上。相较关系数据库, 图数据库把 "关系" 提升为存…...

Tenstorrent:基于RISC-V的异构计算架构如何挑战AI芯片市场
1. 项目概述:Tenstorrent的野心与Jim Keller的蓝图在芯片设计的江湖里,Jim Keller这个名字本身就代表着一种传奇。从AMD的K7、K8架构,到苹果A系列、M1芯片的奠基,再到特斯拉的自动驾驶芯片,他参与的每一个项目都深刻影…...