如何在 Python 中处理 Unicode
介绍
Unicode 是世界上大多数计算机的标准字符编码。它确保文本(包括字母、符号、表情符号,甚至控制字符)在不同设备、平台和数字文档中显示一致,无论使用的操作系统或软件是什么。它是互联网和计算机行业的重要组成部分,没有它,互联网将会更加混乱和难以使用。
Unicode 本身不是编码,而更像是地球上几乎所有可能字符的数据库。Unicode 包含一个代码点,用于标识其数据库中的每个字符,其值范围从 0 到 110 万,这意味着它很可能不会很快用尽这些独特的代码点。Unicode 中的每个代码点都表示为 U+n,其中 U+ 表示它是一个 Unicode 代码点,n 是字符的四到六个十六进制数字集。它比 ASCII 更强大,ASCII 只表示 128 个字符。使用 ASCII 在全球范围内交换数字文本是困难的,因为它基于美国英语,不支持重音字符。另一方面,Unicode 包含几乎 15 万个字符,涵盖了地球上每种语言的字符。
随之而来的是对编程语言(如 Python)的要求,以正确处理文本,并使软件能够实现国际化。Python 可以用于各种用途——从电子邮件到服务器再到网络——并且具有一种优雅的处理 Unicode 的方式,即通过采用 Unicode 标准来处理其字符串。
然而,在 Python 中处理 Unicode 可能会令人困惑并导致错误。本教程将介绍如何在 Python 中使用 Unicode 的基础知识,以帮助您避免这些问题。您将使用 Python 解释 Unicode,使用 Python 的规范化函数对数据进行规范化,并处理 Python Unicode 错误。
先决条件
要按照本教程操作,您需要:
- 本地安装或远程服务器上安装的 Python。如果您尚未设置 Python,可以按照我们的教程《如何安装 Python 3 并设置编程环境》进行设置。选择适合您的 Linux 发行版的版本。
- 熟悉基本的 Python 编程和 Python 的字符串方法
- 知道如何使用 Python 交互式控制台
步骤 1 —— 在 Python 中转换 Unicode 代码点
编码是将数据表示为计算机可读形式的过程。有许多编码数据的方法——ASCII、Latin-1 等——每种编码都有其优势和劣势,但也许最常见的是 UTF-8。这是一种编码类型,允许来自世界各地的字符在单个字符集中表示。因此,UTF-8 对于任何处理国际化数据的人来说都是一种必不可少的工具。总的来说,UTF-8 对于大多数目的来说都是一个不错的选择。它相对高效,并且可以与各种软件一起使用。UTF-8 将 Unicode 代码点转换为计算机可以理解的十六进制字节。换句话说,Unicode 是映射,而 UTF-8 使计算机能够理解该映射。
在 Python 3 中,默认的字符串编码是 UTF-8,这意味着 Python 字符串中的任何 Unicode 代码点都会自动转换为相应的字符。
在这一步中,您将使用 Python 中的 Unicode 代码点创建版权符号(©)。首先,在终端中启动 Python 交互式控制台,然后输入以下内容:
>>> s = '\u00A9'
>>> s
在上述代码中,您创建了一个带有 Unicode 代码点 \u00A9 的字符串 s。如前所述,由于 Python 字符串默认使用 UTF-8 编码,打印 s 的值会自动将其更改为相应的 Unicode 符号。请注意,代码点前面的 \u 是必需的。没有它,Python 将无法转换代码点。上述代码的输出将返回相应的 Unicode 符号:
'©'
Python 编程语言提供了用于编码和解码字符串的内置函数。encode() 函数将字符串转换为字节字符串。
为了演示这一点,打开 Python 交互式控制台,然后输入以下代码:
>>> '🅥'.encode('utf-8')
这将产生字符的字节字符串作为输出:
b'\xf0\x9f\x85\xa5'
请注意,每个字节前面都有 \x,表示它是一个十六进制数。
接下来,您将使用 decode() 函数将字节字符串转换回字符串。decode() 函数接受编码类型作为参数。值得一提的是,decode() 函数只能解码字节字符串,这是通过在字符串开头使用字母 b 来指定的。去除 b 将导致 AttributeError。
在您的控制台中输入:
>>> b'\xf0\x9f\x85\xa5'.decode('utf-8')
该代码将返回如下输出:
'🅥'
现在,您对 Python 中的 Unicode 解释有了基本的了解。接下来,您将深入了解 Python 内置的 unicodedata 模块,以在字符串上执行高级的 Unicode 技术。
步骤 2 —— 在 Python 中对 Unicode 进行规范化
在这一步中,你将学习如何在 Python 中对 Unicode 进行规范化。规范化有助于确定不同字体中的两个字符是否相同,这在两个具有不同代码点但产生相同结果的字符时非常有用。例如,Unicode 字符 R 和 â„œ 在人眼中是相同的,因为它们都是字母 R,但计算机认为它们是不同的字符。
下面的代码示例进一步说明了这一点。打开你的 Python 控制台,输入以下内容:
>>> styled_R = 'ℜ'
>>> normal_R = 'R'
>>> styled_R == normal_R
你将得到以下输出:
False
该代码输出 False,因为 Python 字符串不认为这两个字符是相同的。这种区分能力是在处理 Unicode 时规范化很重要的原因。
在 Unicode 中,一些字符是由两个或多个字符组合而成的。在这种情况下,规范化非常重要,因为它可以使你的字符串保持一致。为了更好地理解这一点,打开你的 Python 控制台,输入以下代码:
>>> s1 = 'hôtel'
>>> s2 = 'ho\u0302tel'
>>> len(s1), len(s2)
在上面的代码中,你创建了一个包含 ô 字符的字符串 s1,在第二行,字符串 s2 包含了尖音字符( Ì‚ )。执行后,代码返回以下输出:
(5, 6)
上面的输出显示,这两个字符串由相同的字符组成,但长度不同,这意味着它们不会相等。在同一个控制台中输入以下内容进行测试:
>>> s1 == s2
该代码返回以下输出:
False
尽管字符串变量 s1 和 s2 产生相同的 Unicode 字符,但它们的长度不同,因此它们不相等。
你可以使用 normalize() 函数来解决这个问题,这也是你将在下一步中要做的事情。
步骤 3 —— 使用 NFD、NFC、NFKD 和 NFKC 对 Unicode 进行规范化
在这一步中,你将使用 Python 的 unicodedata 库中的 normalize() 函数来对 Unicode 字符串进行规范化。unicodedata 模块提供了字符查找和规范化功能。normalize() 函数的第一个参数可以是规范化形式,第二个参数是要规范化的字符串。Unicode 有四种规范化形式可供使用:NFD、NFC、NFKD 和 NFKC。
NFD 规范化形式将一个字符分解为多个组合字符。它使你的文本不区分重音,这在搜索和排序时非常有用。你可以通过将字符串编码为字节来实现这一点。
在你的控制台中输入以下内容:
>>> from unicodedata import normalize
>>> s1 = 'hôtel'
>>> s2 = 'ho\u0302tel'
>>> s1_nfd = normalize('NFD', s1)
>>> len(s1), len(s1_nfd)
该代码产生以下输出:
(5, 6)
正如示例所示,规范化字符串 s1 会使其长度增加一个字符。这是因为 ô 符号被分解为两个字符 o 和 ˆ,你可以通过以下代码确认:
>>> s1.encode(), s1_nfd.encode()
执行后的输出显示,在对规范化后的字符串进行编码后,o 字符从字符串 s1_nfd 中分离出来:
(b'h\xc3\xb4tel', b'ho\xcc\x82tel')
NFC 规范化形式首先分解一个字符,然后重新组合为任何可用的组合字符。由于 NFC 会将一个字符串组合成最短可能的输出,W3C 建议在网络上使用 NFC。键盘输入默认返回组合字符串,因此在这种情况下使用 NFC 是个好主意。
作为示例,在你的交互式控制台中输入以下内容:
>>> from unicodedata import normalize
>>> s2_nfc = normalize('NFC', s2)
>>> len(s2), len(s2_nfc)
该代码产生以下输出:
(6, 5)
在示例中,规范化字符串 s2 的长度减少了一个字符。你可以通过在交互式控制台中运行以下代码来确认这一点:
>>> s2.encode(), s2_nfc.encode()
该代码的输出是:
(b'ho\xcc\x82tel', b'h\xc3\xb4tel')
输出显示,o 和 ˆ 字符合并成了单个 ô 字符。
NFKD 和 NFKC 规范化形式用于“严格”规范化,并可用于与 Unicode 字符串相关的各种搜索和模式匹配问题。NFKD 和 NFKC 中的 “K” 代表兼容性。
NFD 和 NFC 规范化形式会分解字符,但 NFKD 和 NFKC 会对不相似但等效的字符执行兼容性分解,去除任何格式上的区别。例如,字符串 â‘¡â‘ 与 21 不相似,但它们都表示相同的值。NFKC 和 NFKD 规范化形式会去除这些字符中的格式(在本例中是数字周围的圆圈),以提供它们的最简形式。
以下示例演示了 NFD 和 NFKD 规范化形式之间的区别。在你的 Python 交互式控制台中输入以下内容:
>>> s1 = '2�ô'
>>> from unicodedata import normalize
>>> normalize('NFD', s1), normalize('NFKD', s1)
你将得到以下输出:
('2�ô', '25ô')
输出显示,NFD 形式无法分解字符串 s1 中的指数字符,但 NFKD 去除了指数格式,并用其等效形式(作为数字的 5)替换了兼容字符。请记住,NFD 和 NFKD 规范化形式仍在分解字符,因此你应该期望 ô 字符的长度增加一个,就像你在前面的 NFD 示例中看到的那样。你可以通过运行以下代码来确认这一点:
>>> len(normalize('NFD', s1)), len(normalize('NFKD', s1))
该代码将返回以下内容:
(4, 4)
NFKC 规范化形式的工作方式类似,但是它会组合字符而不是分解字符。在同一个 Python 控制台中输入以下内容:
>>> normalize('NFC', s1), normalize('NFKC', s1)
该代码返回以下内容:
('2�ô', '25ô')
由于 NFKC 遵循组合方法,你应该期望 ô 字符的字符串长度减少一个,而不是分解的情况下增加一个。你可以通过运行以下代码来确认这一点:
>>> len(normalize('NFC', s1)), len(normalize('NFKC', s1))
这将返回以下输出:
(3, 3)
通过执行上述步骤,你将对规范化形式有了工作知识,并了解了它们之间的区别。在下一步中,你将解决 Python 中的 Unicode 错误。
第四步 —— 解决 Python 中的 Unicode 错误
在处理 Python 中的 Unicode 时,可能会出现两种类型的 Unicode 错误,即 UnicodeEncodeError 和 UnicodeDecodeError。虽然这些 Unicode 错误可能令人困惑,但可以加以处理。在本步骤中,您将解决这两种错误。
解决 UnicodeEncodeError
Unicode 编码是将 Unicode 字符串使用特定编码转换为字节的过程。当尝试对包含无法用指定编码表示的字符的字符串进行编码时,就会出现 UnicodeEncodeError。
要创建此错误,您将对包含不属于 ASCII 字符集的字符的字符串进行编码。
打开您的控制台,输入以下内容:
>>> ascii_supported = '\u0041'
>>> ascii_supported.encode('ascii')
以下是您的输出:
b'A'
然后输入以下内容:
>>> ascii_unsupported = '\ufb06'
>>> ascii_unsupported.encode('utf-8')
您将得到以下输出:
b'\xef\xac\x86'
最后,输入以下内容:
>>> ascii_unsupported.encode('ascii')
然而,当运行此代码时,您将收到以下错误:
Traceback (most recent call last):File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\ufb06' in position 0: ordinal not in range(128)
ASCII 字符集的字符数量有限,当发现一个不在 ASCII 字符集中的字符时,Python 会抛出错误。由于 ASCII 字符集不识别代码点 \ufb06,Python 返回一个错误消息,指出 ASCII 仅有 128 个字符,而该代码点的对应十进制值不在该范围内。
您可以通过在 encode() 函数中使用 errors 参数来处理 UnicodeEncodeError。errors 参数可以有三个值:ignore、replace 和 xmlcharrefreplace。
打开您的控制台,输入以下内容:
>>> ascii_unsupported = '\ufb06'
>>> ascii_unsupported.encode('ascii', errors='ignore')
您将得到以下输出:
b''
接下来输入以下内容:
>>> >>> ascii_unsupported.encode('ascii', errors='replace')
输出将是:
b'?'
最后,输入以下内容:
>>> ascii_unsupported.encode('ascii', errors='xmlcharrefreplace')
输出为:
b'st'
在每种情况下,Python 都不会抛出错误。
如前面的示例所示,ignore 会跳过无法编码的字符,replace 会用 ? 替换字符,xmlcharrefreplace 会用 XML 实体替换无法编码的字符。
解决 UnicodeDecodeError
当尝试将包含无法用指定编码表示的字符的字符串解码时,就会出现 UnicodeDecodeError。
要创建此错误,您将尝试将字节字符串解码为无法解码的编码。
打开您的控制台,输入以下内容:
>>> iso_supported = '§'
>>> b = iso_supported.encode('iso8859_1')
>>> b.decode('utf-8')
您将收到以下错误:
Traceback (most recent call last):File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa7 in position 0: invalid start byte
如果遇到此错误,您可以在 decode() 函数中使用 errors 参数,这可以帮助您解码字符串。errors 参数接受两个值,即 ignore 和 replace。
为了演示这一点,打开您的 Python 控制台,输入以下代码:
>>> iso_supported = '§A'
>>> b = iso_supported.encode('iso8859_1')
>>> b.decode('utf-8', errors='replace')
您将得到以下输出:
'�A'
然后输入以下内容:
>>> b.decode('utf-8', errors='ignore')
您将得到以下输出:
'A'
在上述示例中,使用 decode() 函数中的 replace 值添加了一个 � 字符,而使用 ignore 在解码器(在本例中为 utf-8)无法解码字节时返回空字符串。
在解码任何字符串时,请注意您不能假设编码是什么。要解码任何字符串,您必须知道它是如何编码的。
结论
本文介绍了如何在 Python 中使用 Unicode 的基础知识。您对字符串进行了编码和解码,使用 NFD、NFC、NFKD 和 NFKC 对数据进行了规范化,并解决了 Unicode 错误。您还在涉及排序和搜索的场景中使用了规范化形式。这些技术将帮助您使用 Python 处理 Unicode 问题。
相关文章:

如何在 Python 中处理 Unicode
介绍 Unicode 是世界上大多数计算机的标准字符编码。它确保文本(包括字母、符号、表情符号,甚至控制字符)在不同设备、平台和数字文档中显示一致,无论使用的操作系统或软件是什么。它是互联网和计算机行业的重要组成部分…...

CSDN文章导出PDF整理状况一览
最近CSDN有了导出文章PDF功能,导出的PDF还可以查询, 因此,把文章导出PDF,备份一下自己的重要资料。 目前整理内容如下 No.文章标题整理时间整理之后 文章更新Size (M)10001_本地电脑-开发相关软件保持位…...
)
jmeter-05变量(用户定义变量,用户参数,csv文档参数化)
文章目录 一、jmeter有三种变量二、用户定义变量(这个更多的可以理解为全局变量)1、设置2、引用三、用户参数(可以理解为局部变量)1、设置2、引用3、用户参数化要配合线程组的线程数使用4、结果五、csv文档参数1、创建csv文件2、设置2、引用csv文件可以配合线程组的线程数,…...

CSS之水平垂直居中
如何实现一个div的水平垂直居中 <div class"content-wrapper"><div class"content">content</div></div>flex布局 .content-wrapper {width: 400px;height: 400px;background-color: lightskyblue;display: flex;justify-content:…...

2.8日学习打卡----初学RabbitMQ(三)
2.8日学习打卡 一.springboot整合RabbitMQ 之前我们使用原生JAVA操作RabbitMQ较为繁琐,接下来我们使用 SpringBoot整合RabbitMQ,简化代码编写 创建SpringBoot项目,引入RabbitMQ起步依赖 <!-- RabbitMQ起步依赖 --> <dependency&g…...

Unity学习笔记(零基础到就业)|Chapter02:C#基础
Unity学习笔记(零基础到就业)|Chapter02:C#基础 前言一、复杂数据(变量)类型part01:枚举数组1.特点2.枚举(1)基本概念(2)申明枚举变量(3ÿ…...

容器化的基础概念:不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。
不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。 想象一下用乐高积木代替橡皮泥进行搭建。使用橡皮泥时,您可以直接塑形和改变它。而使用乐高积木,您需要逐个零件搭建特定结构,并在需要时整体替换它们。这就是…...
智胜未来,新时代IT技术人风口攻略-第二版(弃稿)
文章目录 抛砖引玉 鸿蒙生态小科普焦虑之下 理想要落到实处校园鼎力 鸿蒙发展不可挡培训入场 机构急于吃红利企业布局 鸿蒙应用规划动智胜未来 技术人风口来临 鸿蒙已经成为行业的焦点,未来的发展潜力无限。作为一名程序员兼UP主,我非常荣幸地接受了邀请…...
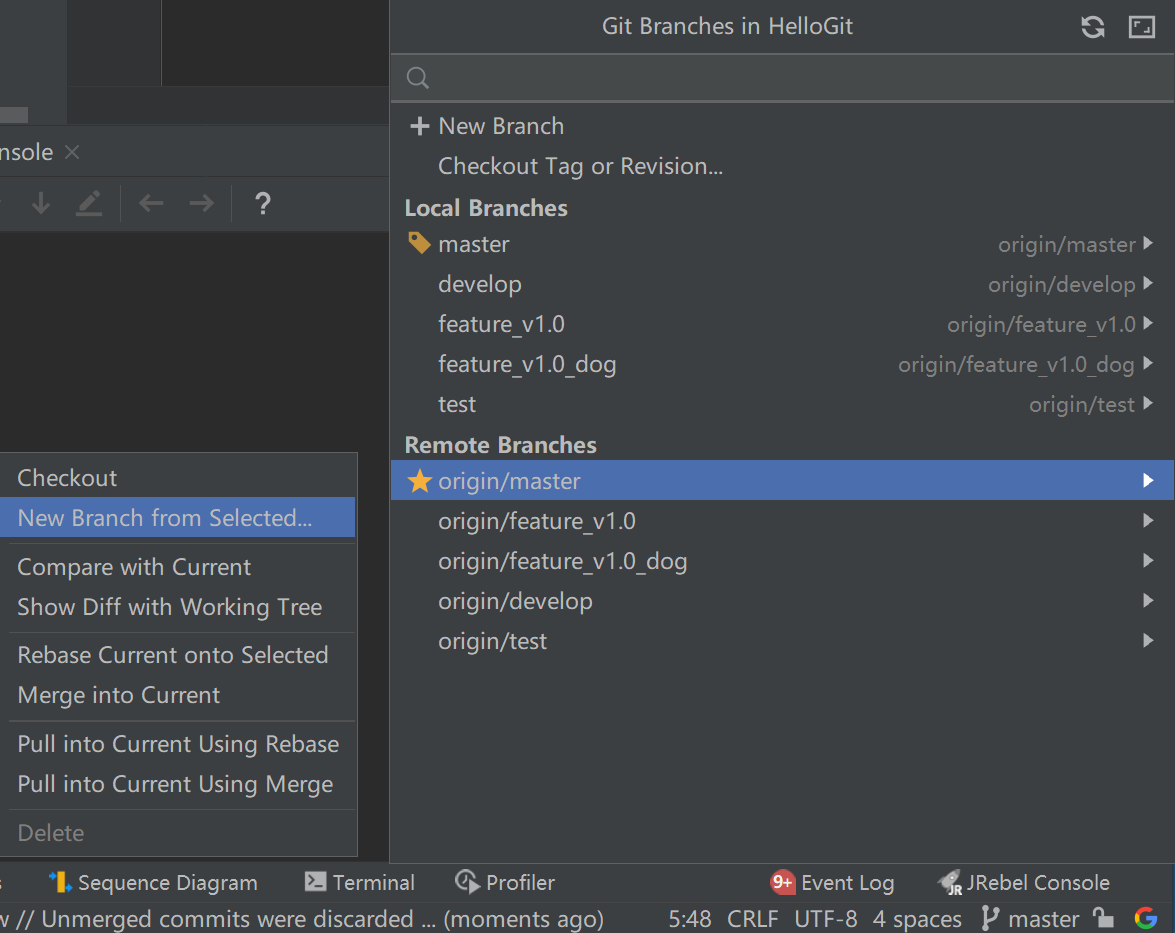
Git分支和迭代流程
Git分支 feature分支:功能分支 dev分支:开发分支 test分支:测试分支 master分支:生产环境分支 hotfix分支:bug修复分支。从master拉取,修复并测试完成merge回master和dev。 某些团队可能还会有 reale…...
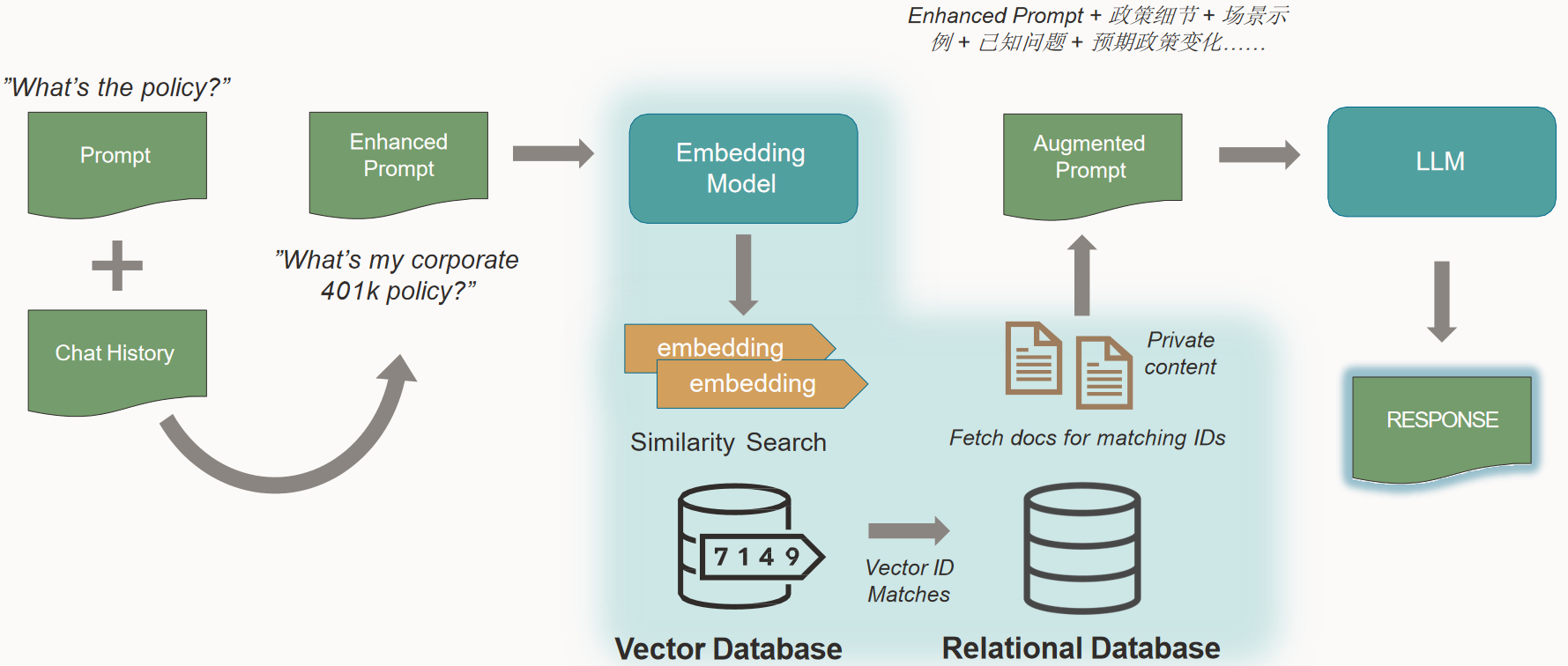
数据库管理-第150期 Oracle Vector DB AI-02(20240212)
数据库管理150期 2024-02-12 数据库管理-第150期 Oracle Vector DB & AI-02(20240212)1 LLM2 LLM面临的挑战3 RAG4 向量数据库LLM总结 数据库管理-第150期 Oracle Vector DB & AI-02(20240212) 作者:胖头鱼的鱼…...

MySQL双写机制
双写机制 问题的出现 在发生数据库宕机时,可能Innodb正在写入某个页到表中,但是这个页只写了一部分,这种情况被称为部分写失效,虽然innodb会先写重做日志,在修改页,但是重做日志中记录的是对页的物理操作,但…...
uniapp的配置和使用
①安装环境和编辑器 注册小程序账号 微信开发者工具下载 uniapp 官网 HbuilderX 下载 首先先下载Hbuilder和微信开发者工具 (都是傻瓜式安装),然后注册小程序账号: 拿到appid: ②简单通过demo使用微信开发者工具和…...

【ES】--Elasticsearch的分词器深度研究
目录 一、问题描述及分析二、analyze分析器原理三、 multi-fields字段支持多场景搜索(如同时简繁体、拼音等)1、ts_match_analyzer配置分词2、ts_match_all_analyzer配置分词3、ts_match_1_analyzer配置分词4、ts_match_2_analyzer配置分词5、ts_match_3_analyzer配置分词6、ts…...
【Langchain Agent研究】SalesGPT项目介绍(三)
【Langchain Agent研究】SalesGPT项目介绍(二)-CSDN博客 上节课,我们介绍了salesGPT项目的初步的整体结构,poetry脚手架工具和里面的run.py。在run.py这个运行文件里,引用的最主要的类就是SalesGPT类,今天我…...
Java安全 URLDNS链分析
Java安全 URLDNS链分析 什么是URLDNS链URLDNS链分析调用链路HashMap类分析URL类分析 exp编写思路整理初步expexp改进最终exp 什么是URLDNS链 URLDNS链是Java安全中比较简单的一条利用链,无需使用任何第三方库,全依靠Java内置的一些类实现,但…...

【网站项目】026校园美食交流系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

使用raw.gitmirror.com替换raw.githubusercontent.com以解决brew upgrade python@3.12慢的问题
MacOS系统上,升级python3.12时,超级慢,而且最后还失败了。看了日志,发现是用curl从raw.githubusercontent.com上下载Python安装包超时了。 解决方案一:开启翻墙工具,穿越围墙 解决方案二:使用…...

深度学习的进展
#深度学习的进展# 深度学习的进展 深度学习是人工智能领域的一个重要分支,它利用神经网络模拟人类大脑的学习过程,通过大量数据训练模型,使其能够自动提取特征、识别模式、进行分类和预测等任务。近年来,深度学习在多个领域取得…...

[高性能] - 缓存架构
对于交易系统来说,低延时是核心业务的基本要求。因此需要对业务进行分级,还需要对数据按质量要求进行分类,主要包含两个维度:重要性,延时要求,数据质量。共包含以下三种场景: 1. 重要 延时性要…...

django实现外键
一:介绍 在Django中,外键是通过在模型字段中使用ForeignKey来实现的。ForeignKey字段用于表示一个模型与另一个模型之间的多对一关系。这通常用于关联主键字段,以便在一个模型中引用另一个模型的相关记录。 下面是一个简单的例子࿰…...
)
别再用理想模型了!手把手教你用Multisim仿真LM741反相放大电路(含电源、电容、失真全避坑)
从理想模型到实战避坑:Multisim仿真LM741反相放大电路全流程解析 1. 为什么你的仿真结果总与教科书不符? 许多电子工程初学者在课本上学完"虚短虚断"原理后,第一次用Multisim搭建LM741反相放大电路时都会遇到这样的困惑:…...

Linux系统维护:高效查找与清理失效符号链接的两种核心方法
1. 项目概述:为什么我们需要清理“幽灵”链接 在Linux系统里摸爬滚打久了,你肯定遇到过这种情况:运行一个脚本或者启动一个服务时,突然报错“No such file or directory”,但你明明记得这个文件是存在的。一查才发现&a…...

3种简单方法解决Navicat Premium Mac试用期重置难题
3种简单方法解决Navicat Premium Mac试用期重置难题 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你是否正在为Navicat Pre…...

从设备树到内核启动:一步步拆解Linux内核中CMA连续内存区域的创建与初始化全过程
Linux内核CMA连续内存分配器深度解析:从设备树配置到伙伴系统整合 引言 在现代嵌入式系统和多媒体设备开发中,大块连续物理内存的获取一直是开发者面临的棘手问题。当摄像头需要处理4K视频流、GPU渲染复杂场景或硬件编解码器处理高码率内容时ÿ…...

罗技鼠标宏:绝地求生后坐力控制全攻略
罗技鼠标宏:绝地求生后坐力控制全攻略 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 想要在《绝地求生》中实现精准压枪,…...

Azure 资源管理器编程:resourcemanager 模块的 100+ 服务集成
Azure 资源管理器编程:resourcemanager 模块的 100 服务集成 【免费下载链接】azure-sdk-for-go This repository is for active development of the Azure SDK for Go. For consumers of the SDK we recommend visiting our public developer docs at: 项目地址:…...

词达人自动化助手终极指南:10倍提升英语学习效率的Python工具
词达人自动化助手终极指南:10倍提升英语学习效率的Python工具 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 核心关键词:词达人自动化助手…...
)
给新手的保姆级教程:在VMware里一步步装好Ubuntu Server 22.04 LTS(附静态IP和SSH配置)
虚拟化环境下的Ubuntu Server 22.04 LTS全流程部署指南 对于刚接触Linux服务器运维的新手而言,在虚拟化环境中搭建Ubuntu Server是一个理想的起点。不同于物理机安装,虚拟化平台提供了可重复、隔离的实验环境,让学习者能够大胆尝试而无需担心…...

大模型上下文窗口管理技巧:突破长度限制的艺术
大模型上下文窗口管理技巧:突破长度限制的艺术 前言 大模型的上下文窗口(Context Window)是指模型能够处理的最大输入长度。目前主流模型的上下文窗口从 4K 到 128K 不等,GPT-4 Turbo 甚至达到了 128K tokens。然而,随…...

Gemini 3.5 Flash:AI界“闪电侠”来袭,速度与性价比双封神!
极速、低成本、原生多模态、面向智能体(Agent) 的主力模型,代号 “雪兔”,当前面向公众免费开放。(图源网络,侵删)如果AI模型有“速度奥运会”,2026 年 5 月谷歌 I/O 大会上新发的 Gemini 3.5 Flash&#x…...