探讨java系统中全局唯一ID实现方案
为什么需要全局唯一ID
我们这里引用美团 Leaf 的场景介绍:在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一ID 的系统是非常必要的。
UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为 1632=2128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ - ',一般我们使用的时候会将连字符删除 uuid.toString().replaceAll(“-”,“”)。
UUID的产生方式主要包括以下几种:
- 基于时间戳和MAC地址(UUID v1):这种方式结合了主机的网络接口卡MAC地址和当前的日期时间来生成UUID。由于包含了MAC地址,因此这种方式生成的UUID在一定程度上是可以被跟踪的,因为它隐含了生成UUID的设备信息。
- 基于随机数(UUID v4):这是目前最常用的UUID生成方式。它完全基于随机数或伪随机数,没有任何可以识别的个人或组织信息,因此是完全匿名的。这也是为什么它被广泛应用于需要高度安全性和隐私保护的场景。
- 基于命名空间的UUID(UUID v3、v5):这种方式基于MD5和SHA-1散列算法,通过将特定命名空间的标识符和名字进行散列来生成UUID。这种方法允许UUID基于给定的名字和命名空间来生成,确保不同命名空间下的UUID是唯一的。
- 基于硬件的UUID:某些系统可能还会根据其他硬件信息来生成UUID,例如硬盘序列号等。
java实现的uuid为基于随机数,使用代码:
public static void main(String[] args) {//获取一个版本4根据随机字节数组的UUID。UUID uuid = UUID.randomUUID();System.out.println(uuid.toString().replaceAll("-",""));
}
虽然 UUID 生成方便,本地生成没有网络消耗,但是使用起来也有一些缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
使用redis实现
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。以下代码通过引入jedis来实现:
import redis.clients.jedis.Jedis;public class UniqueIdGenerator {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;private static final String UNIQUE_ID_KEY = "unique_id";public static void main(String[] args) {Jedis jedis = new Jedis(REDIS_HOST, REDIS_PORT);long uniqueId = generateUniqueId(jedis);System.out.println("生成的唯一ID: " + uniqueId);jedis.close();}private static long generateUniqueId(Jedis jedis) {return jedis.incr(UNIQUE_ID_KEY);}
}雪花算法-Snowflake
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
具体实现步骤如下:
- 第一位为未使用(符号位表示正数),接下来的41位为毫秒级时间(41位的长度可以使用69年)
- 然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)
- 最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)

以下是java实现版本:
public class Snowflake implements Serializable {private static final long serialVersionUID = 1L;/*** 默认的起始时间,为Thu, 04 Nov 2010 01:42:54 GMT*/public static long DEFAULT_TWEPOCH = 1288834974657L;/*** 默认回拨时间,2S*/public static long DEFAULT_TIME_OFFSET = 2000L;private static final long WORKER_ID_BITS = 5L;// 最大支持机器节点数0~31,一共32个@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})private static final long MAX_WORKER_ID = -1L ^ (-1L << WORKER_ID_BITS);private static final long DATA_CENTER_ID_BITS = 5L;// 最大支持数据中心节点数0~31,一共32个@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})private static final long MAX_DATA_CENTER_ID = -1L ^ (-1L << DATA_CENTER_ID_BITS);// 序列号12位(表示只允许workId的范围为:0-4095)private static final long SEQUENCE_BITS = 12L;// 机器节点左移12位private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;// 数据中心节点左移17位private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;// 时间毫秒数左移22位private static final long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;// 序列掩码,用于限定序列最大值不能超过4095private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);// 4095/*** 初始化时间点*/private final long twepoch;private final long workerId;private final long dataCenterId;private final boolean useSystemClock;/*** 允许的时钟回拨毫秒数*/private final long timeOffset;/*** 当在低频模式下时,序号始终为0,导致生成ID始终为偶数<br>* 此属性用于限定一个随机上限,在不同毫秒下生成序号时,给定一个随机数,避免偶数问题。<br>* 注意次数必须小于{@link #SEQUENCE_MASK},{@code 0}表示不使用随机数。<br>* 这个上限不包括值本身。*/private final long randomSequenceLimit;/*** 自增序号,当高频模式下时,同一毫秒内生成N个ID,则这个序号在同一毫秒下,自增以避免ID重复。*/private long sequence = 0L;private long lastTimestamp = -1L;/*** 构造,使用自动生成的工作节点ID和数据中心ID*/public Snowflake() {this(IdUtil.getWorkerId(IdUtil.getDataCenterId(MAX_DATA_CENTER_ID), MAX_WORKER_ID));}/*** 构造** @param workerId 终端ID*/public Snowflake(long workerId) {this(workerId, IdUtil.getDataCenterId(MAX_DATA_CENTER_ID));}/*** 构造** @param workerId 终端ID* @param dataCenterId 数据中心ID*/public Snowflake(long workerId, long dataCenterId) {this(workerId, dataCenterId, false);}/*** 构造** @param workerId 终端ID* @param dataCenterId 数据中心ID* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳*/public Snowflake(long workerId, long dataCenterId, boolean isUseSystemClock) {this(null, workerId, dataCenterId, isUseSystemClock);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @since 5.1.3*/public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock) {this(epochDate, workerId, dataCenterId, isUseSystemClock, DEFAULT_TIME_OFFSET);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @param timeOffset 允许时间回拨的毫秒数* @since 5.8.0*/public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock, long timeOffset) {this(epochDate, workerId, dataCenterId, isUseSystemClock, timeOffset, 0);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @param timeOffset 允许时间回拨的毫秒数* @param randomSequenceLimit 限定一个随机上限,在不同毫秒下生成序号时,给定一个随机数,避免偶数问题,0表示无随机,上限不包括值本身。* @since 5.8.0*/public Snowflake(Date epochDate, long workerId, long dataCenterId,boolean isUseSystemClock, long timeOffset, long randomSequenceLimit) {this.twepoch = (null != epochDate) ? epochDate.getTime() : DEFAULT_TWEPOCH;this.workerId = Assert.checkBetween(workerId, 0, MAX_WORKER_ID);this.dataCenterId = Assert.checkBetween(dataCenterId, 0, MAX_DATA_CENTER_ID);this.useSystemClock = isUseSystemClock;this.timeOffset = timeOffset;this.randomSequenceLimit = Assert.checkBetween(randomSequenceLimit, 0, SEQUENCE_MASK);}/*** 根据Snowflake的ID,获取机器id** @param id snowflake算法生成的id* @return 所属机器的id*/public long getWorkerId(long id) {return id >> WORKER_ID_SHIFT & ~(-1L << WORKER_ID_BITS);}/*** 根据Snowflake的ID,获取数据中心id** @param id snowflake算法生成的id* @return 所属数据中心*/public long getDataCenterId(long id) {return id >> DATA_CENTER_ID_SHIFT & ~(-1L << DATA_CENTER_ID_BITS);}/*** 根据Snowflake的ID,获取生成时间** @param id snowflake算法生成的id* @return 生成的时间*/public long getGenerateDateTime(long id) {return (id >> TIMESTAMP_LEFT_SHIFT & ~(-1L << 41L)) + twepoch;}/*** 下一个ID** @return ID*/public synchronized long nextId() {long timestamp = genTime();if (timestamp < this.lastTimestamp) {if (this.lastTimestamp - timestamp < timeOffset) {// 容忍指定的回拨,避免NTP校时造成的异常timestamp = lastTimestamp;} else {// 如果服务器时间有问题(时钟后退) 报错。throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));}}if (timestamp == this.lastTimestamp) {final long sequence = (this.sequence + 1) & SEQUENCE_MASK;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}this.sequence = sequence;} else {// issue#I51EJYif (randomSequenceLimit > 1) {sequence = RandomUtil.randomLong(randomSequenceLimit);} else {sequence = 0L;}}lastTimestamp = timestamp;return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT)| (dataCenterId << DATA_CENTER_ID_SHIFT)| (workerId << WORKER_ID_SHIFT)| sequence;}/*** 下一个ID(字符串形式)** @return ID 字符串形式*/public String nextIdStr() {return Long.toString(nextId());}// ------------------------------------------------------------------------------------------------------------------------------------ Private method start/*** 循环等待下一个时间** @param lastTimestamp 上次记录的时间* @return 下一个时间*/private long tilNextMillis(long lastTimestamp) {long timestamp = genTime();// 循环直到操作系统时间戳变化while (timestamp == lastTimestamp) {timestamp = genTime();}if (timestamp < lastTimestamp) {// 如果发现新的时间戳比上次记录的时间戳数值小,说明操作系统时间发生了倒退,报错throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));}return timestamp;}/*** 生成时间戳** @return 时间戳*/private long genTime() {return this.useSystemClock ? SystemClock.now() : System.currentTimeMillis();}}
百度-UidGenerator
百度的 UidGenerator 是百度开源基于Java语言实现的唯一ID生成器,是在雪花算法 snowflake 的基础上做了一些改进。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略,适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上,UidGenerator 提供了两种生成唯一ID方式,分别是 DefaultUidGenerator 和 CachedUidGenerator,官方建议如果有性能考虑的话使用 CachedUidGenerator 方式实现。UidGenerator 依然是以划分命名空间的方式将 64-bit位分割成多个部分,只不过它的默认划分方式有别于雪花算法 snowflake。它默认是由 1-28-22-13 的格式进行划分。可根据你的业务的情况和特点,自己调整各个字段占用的位数。
- 第1位仍然占用1bit,其值始终是0。
- 第2位开始的28位是时间戳,28-bit位可表示2^28个数,这里不再是以毫秒而是以秒为单位,每个数代表秒则可用(1L<<28)/ (360024365) ≈ 8.51 年的时间。
- 中间的 workId (数据中心+工作机器,可以其他组成方式)则由 22-bit位组成,可表示 2^22 = 4194304个工作ID。
- 最后由13-bit位构成自增序列,可表示2^13 = 8192个数。
Medis 薄雾算法工程实践
https://github.com/asyncins/medis
薄雾算法 Mist 由书籍《Python3 反爬虫原理与绕过实战》的作者韦世东综合各大厂的技术点且考虑高性能分布式序列号生成器架构后设计的一款“递增态势、不依赖数据库、高性能且不受时间回拨影响”的全局唯一序列号生成算法。
Medis 是薄雾算法 Mist 的工程实践,其名取自 Mist 和 Redis。薄雾算法是一款性能强到令我惊喜的全局唯一 ID 算法。有了 Mist 和 Medis,你就拥有了和美团 Leaf、微信 Seqsvr、百度 UIDGenerator 性能相当(甚至超过)的全局唯一 ID 服务了。相比复杂的 UIDGenerator 双 Buffer 优化和 Leaf-Snowflake,薄雾算法 Mist 简单太多了。
相关文章:
探讨java系统中全局唯一ID实现方案
为什么需要全局唯一ID 我们这里引用美团 Leaf 的场景介绍:在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一…...
微信小程序(四十四)鉴权组件插槽-登入检测
注释很详细,直接上代码 新增内容: 1.鉴权组件插槽的用法 2.登入检测示范 源码: app.json {"usingComponents": {"auth":"/components/auth/auth"} }app.js App({globalData:{//定义全局变量isLoad:false} })…...
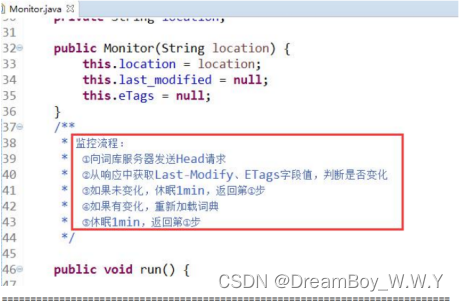
【ES】--ES集成热更新自定义词库(字典)
目录 一、问题描述二、具体实施1、Tomcat实现远程扩展字典2、验证生效3、ES配置远程扩展字典4、为何不重启ES能实现热更新 一、问题描述 问题现象: 前面完成了自定义分词器词库集成到ES中。在实际项目中词库是时刻在变更的,但又不希望重启ES,对此我们应…...

能源管理师——为能源可持续发展护航
能源管理师是在能源管理领域具有专业知识和技能的专业人士,他们的工作对于实现能源的有效利用和可持续发展至关重要。 能源管理师的主要职责是协助企业或组织进行能源管理,包括能源规划、能源审计、节能措施的实施和能源绩效的评估等。他们通过对能源使…...

设计模式理解:单例模式+工厂模式+建设者模式+原型模式
迪米特法则:Law of Demeter, LoD, 最少知识原则LKP 如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。 所以,在运用迪米特…...

DataX源码分析 writer
系列文章目录 一、DataX详解和架构介绍 二、DataX源码分析 JobContainer 三、DataX源码分析 TaskGroupContainer 四、DataX源码分析 TaskExecutor 五、DataX源码分析 reader 六、DataX源码分析 writer 七、DataX源码分析 Channel 文章目录 系列文章目录前言DataX的Writer写入流…...

为自己的项目媒体资源添加固定高度
为自己的项目媒体资源添加固定高度 未媒体资源添加固定高度,不仅有利于确定懒加载后的切确位置,还可以做骨架屏、loading动画等等,但是因为历史数据中很多没有加高度的媒体资源,所以一直嫌麻烦没有做。 直到这个季度有一个自上而…...

家政小程序系统源码开发:引领智能生活新篇章
随着科技的飞速发展,小程序作为一种便捷的应用形态,已经深入到我们生活的方方面面。尤其在家庭服务领域,家政小程序的出现为人们带来了前所未有的便利。它不仅简化了家政服务的流程,提升了服务质量,还为家政服务行业注…...

多表查询
目录 统计出一张数据表中的数据量 查询 dept 表中的数据量 查询 emp 表中的数据量 实现 emp 与 dept 的多表查询 笛卡尔积 消除笛卡尔积 把数据表 emp 的别名定为 e,数据表 dept 的别名定为 d,然后在查询中分别使用 e 和 d 代替这两个表 Oracle从…...

PHP开发日志 ━━ 深入理解三元操作与一般条件语句的不同
概况 三元运算符的功能与“if…else”流程语句一致。 在一般情况下,三元操作替换if条件语句可以精简代码,并且更为直观,但是在下面的情况中使用三元操作将会返回警告。 借图: 案例 比如原代码: class classA{publ…...
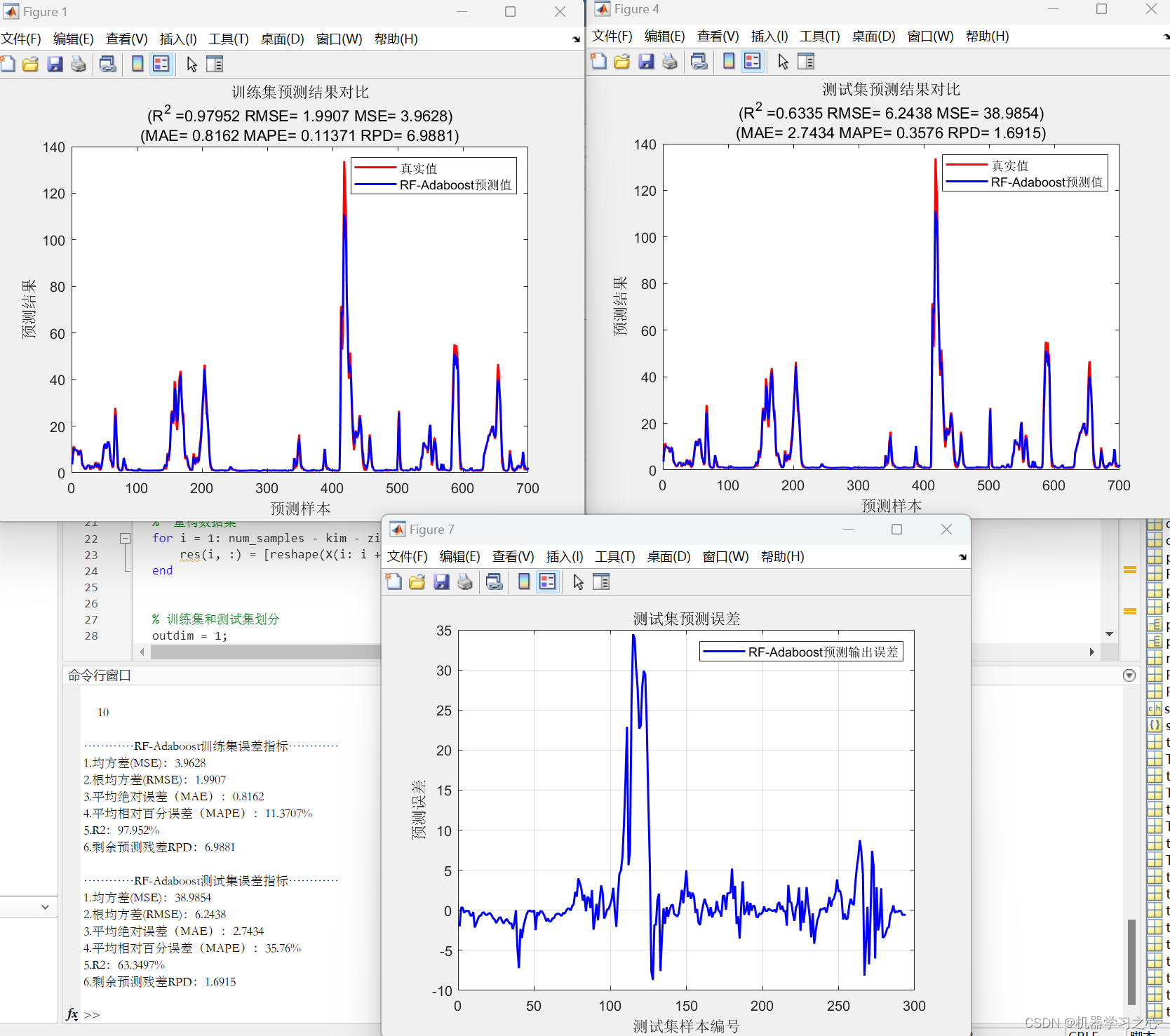
多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测
多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测 目录 多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预…...

vue3-内置组件-Suspense
Suspense (实验性功能) <Suspense> 是一项实验性功能。它不一定会最终成为稳定功能,并且在稳定之前相关 API 也可能会发生变化。 <Suspense> 是一个内置组件,用来在组件树中协调对异步依赖的处理。它让我们可以在组件树上层等待下层的多个嵌…...
Rust入门:如何在windows + vscode中关闭程序codelldb.exe
在windows中用vscode单步调试rust程序的时候,发现无论是按下stop键,还是运行完程序,调试器codelldb.exe一直霸占着主程序不退出,如果此时对代码进行修改,后续就没法再编译调试了。 目前我也不知道要怎么处理这个事&am…...

git错误整理
remote: Support for password authentication was removed on August 13, 2021. 参考:这篇即可 GnuTLS recv error (-110): The TLS connection was non-properly terminated. 执行下面的指令: git config --global http.sslVerify false...

跟着cherno手搓游戏引擎【22】CameraController、Resize
前置: YOTO.h: #pragma once//用于YOTO APP#include "YOTO/Application.h" #include"YOTO/Layer.h" #include "YOTO/Log.h"#include"YOTO/Core/Timestep.h"#include"YOTO/Input.h" #include"YOTO/KeyCod…...
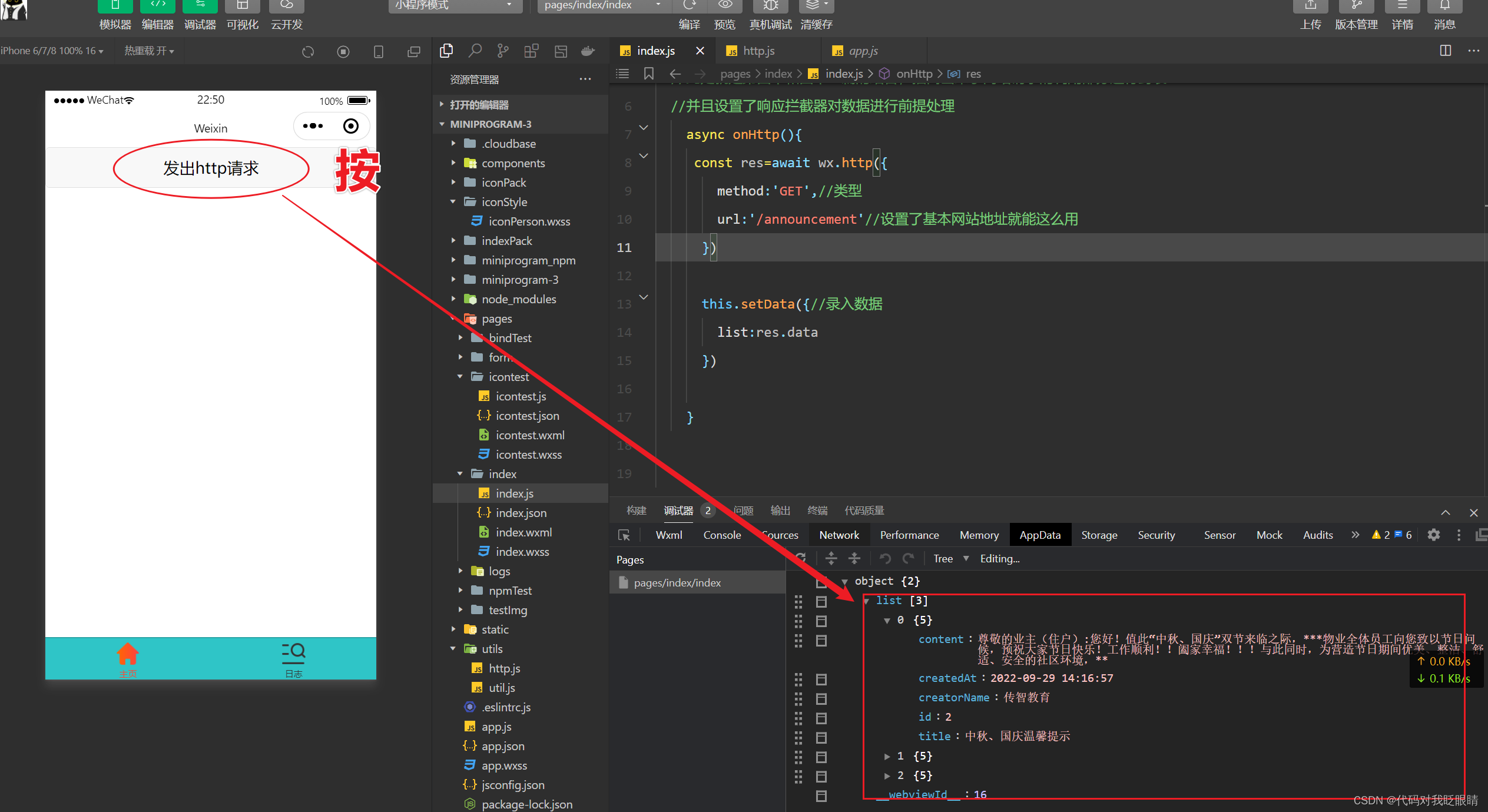
微信小程序(四十二)wechat-http拦截器
注释很详细,直接上代码 上一篇 新增内容: 1.wechat-http请求的封装 2.wechat-http请求的拦截器的用法演示 源码: utils/http.js import http from "wechat-http"//设置全局默认请求地址 http.baseURL "https://live-api.ith…...

tomcat部署zrlog
1.下载zrlog包,并添加到虚拟机中 1)进入/opt/apache-tomcat-8.5.90/webapps目录 cd /opt/apache-tomcat-8.5.90/webapps2)下载zrlog包 wget http://dl.zrlog.com/release/zrlog-1.7.1-baaecb9-release.war 3)重命名包 mv zrlog-1.7.1-baaecb9-release zrblog 2…...

Ubuntu Desktop 开机数字小键盘
Ubuntu Desktop 开机数字小键盘 1. 开机数字小键盘References 1. 开机数字小键盘 一般情况下,Ubuntu 开机后小键盘区是控制方向键而非数字键,每次开机后若用到数字键都需要按下 NumLock 键。 References [1] Yongqiang Cheng, https://yongqiang.blog…...

树莓派编程基础与硬件控制
1.编程语言 Python 是一种泛用型的编程语言,可以用于大量场景的程序开发中。根据基于谷歌搜 索指数的 PYPL(程序语言流行指数)统计,Python 是 2019 年 2 月全球范围内最为流行 的编程语言 相比传统的 C、Java 等编程语言&#x…...

autojs通过正则表达式获取带有数字的text内容
视频连接 视频连接 参考 参考 var ctextMatches(/\d/).findOne()console.log("当前金币"c.text()) // 获取当前金币UiSelector.textMatches(reg) reg {string} | {Regex} 要满足的正则表达式。 为当前选择器附加控件"text需要满足正则表达式reg"的条件。 …...

如何彻底解决Mac设备滚动方向冲突:Scroll Reverser终极配置指南
如何彻底解决Mac设备滚动方向冲突:Scroll Reverser终极配置指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是不是经常在Mac上同时使用触控板和鼠标࿰…...

孤胆英雄的黄昏,社会化智能的黎明:一文看透 Multi-Agent 架构底层逻辑
在过去的一两年里,我们见证了单体大语言模型(LLM)的疯狂进化。我们给它穿上基建外骨骼(Harness),给它挂载无数的函数工具(Skills),试图把它打造成一个无所不能的“全栈超…...

XXMI启动器:6款热门二次元游戏模组一站式管理终极指南
XXMI启动器:6款热门二次元游戏模组一站式管理终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款专为二次元游戏爱好者设计的开源模组管理平台…...

短剧进军韩国:外卡收单+本地钱包,Antom助你打通“付费最后一公里”
韩国短剧市场正以惊人的速度崛起。2024年,韩国短剧市场规模已达4.9亿美元,全球排名第4,预计未来将突破15亿美元。中国出海平台如DramaBox、ShortMax、ReelShort等早已抢先布局,在下载榜和收入榜上占据大半江山。然而,流…...

6G通信中的HMA天线技术:原理、优势与应用
1. HMA天线技术概述在6G通信和大规模MIMO系统的发展背景下,Huygens Metasurface Antennas(HMA)技术正逐渐成为无线通信领域的研究热点。作为一名长期从事天线系统设计的工程师,我见证了从传统相控阵到现代超表面天线的技术演进历程…...
)
从场景到代码:如何用研华Navigator为PCIE1751规划数据采集方案(AI/AO/DI/DO全解析)
从场景到代码:如何用研华Navigator为PCIE1751规划数据采集方案(AI/AO/DI/DO全解析) 在工业自动化领域,数据采集系统的设计往往面临一个核心矛盾:硬件性能的丰富性与实际需求的精准匹配。研华PCIE-1751作为一款多功能数…...

合同系统业务功能
合同管理系统的核心是实现合同全生命周期管控,其生命周期主要分为五大环节:签订前管理、审批流程管理审批管理、合同签订、合同信息与文本管理、合同履约执行。 不同环节对应不同的功能需求,需结合企业业务特点灵活适配,以下是各环…...

深入解析Keil MDK FLM算法:SRAM运行原理与下载机制
1. 项目概述:FLM算法,Keil MDK下载的“灵魂引擎”如果你用Keil MDK给一块新的APM32或者STM32芯片下载程序,点下那个“Download”或“Load”按钮,几秒钟后“Programming Done”的提示框弹出,这个过程看似简单࿰…...

rag 进行 全局聚合的结构性失败 解析
rag 进行 全局聚合的结构性失败 解析 目录 rag 进行 全局聚合的结构性失败 解析 一句话核心结论 逐句拆解原文含义 1. 前提:什么是"全局聚合"? 2. 致命问题:采样引入不可纠正的选择偏差 农情任务实例:直观感受结构性偏差 真实数据分布(12M农情CSV,共12000条上…...

PSIM与ModelSim的VHDL联合仿真:数字电源控制算法验证利器
1. 项目概述:为什么要在PSIM里搞VHDL联合仿真?做电源硬件或者电力电子控制的朋友,肯定对PSIM不陌生。它是个专门搞电力电子和电机驱动仿真的利器,开关器件模型准,仿真速度快,画起主功率拓扑来那叫一个顺手。…...