jvm垃圾收集器之七种武器
目录
1.回收算法
1.1 标记-清除算法(Mark-Sweep)
1.2 复制算法(Copying)
1.3 标记-整理算法(Mark-Compact)
2.HotSpot虚拟机的垃圾收集器
2.1 新生代的收集器
Serial 收集器(复制算法)
ParNew 收集器 (复制算法)
Parallel Scavenge 收集器 (复制算法)
2.2 老年代的收集器
Serial Old 收集器 (标记-整理算法)
Parallel Old 收集器 (标记-整理算法)
CMS(Concurrent Mark Sweep)收集器(标记-清除算法)
2.3 整个堆
G1(Garbage First)收集器 (标记-整理算法)
1.回收算法
1.1 标记-清除算法(Mark-Sweep)
分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。

该算法最大的问题是内存碎片化严重,后续可能发生大对象不能找到可利用空间的问题。
1.2 复制算法(Copying)
按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉。

这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是可用内存被压缩到了原本的一半。且存活对象增多的话,Copying算法的效率会大大降低。
1.3 标记-整理算法(Mark-Compact)
标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。

2.HotSpot虚拟机的垃圾收集器

展示了7种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。虚拟机所处的区域,则表示它是属于新生代收集器还是老年代收集器。
2.1 新生代的收集器
Serial 收集器(复制算法)
新生代单线程收集器,标记和清理都是单线程,
优点:
简单高效:对于有限的资源环境,Serial 收集器由于其简单的算法和单线程的执行方式,在垃圾收集上能够达到一定的效率。
易于实现:没有多线程间同步的复杂性,使得Serial 收集器相对容易实现和维护。
缺点:
停顿时间:所有工作线程在垃圾收集时都需要暂停,这可能导致应用响应时间变长,特别是堆内存较大时,GC停顿时间会更加明显。
不适合多核处理器:在多核处理器系统上,由于Serial 收集器只能使用单个核心进行垃圾收集,无法充分利用现代硬件资源。
Serial/Serial Old收集器运行示意图

ParNew 收集器 (复制算法)
新生代并行收集器,实际上是 Serial 收集器的多线程版本
使用-XX:+UseParNewGC(新生代使用并行收集器,老年代使用串行回收收集器) 或者-XX:+UseConcMarkSweepGC(新生代使用并行收集器,老年代使用 CMS)
优点:
- 多线程收集:ParNew 收集器能够并行地使用多个线程进行垃圾收集,这使得它在多核处理器上相较于 Serial 收集器具有更好的性能表现。
- 适合多核环境:随着现代服务器通常配备多核处理器,ParNew 收集器能够更有效地利用这些处理器资源,提高垃圾收集的效率。
- 与CMS兼容:ParNew 收集器经常与老年代的 Concurrent Mark Sweep (CMS) 收集器配合使用,为需要低停顿时间且具有多核处理器的应用提供了一种有效的垃圾收集解决方案。
- 适用于交互式应用:由于 ParNew 收集器能够减少垃圾收集时的停顿时间,它特别适合于对响应时间有较高要求的交互式应用。
缺点:
- 消耗更多的CPU资源:虽然 ParNew 收集器通过并行收集减少了停顿时间,但这也意味着在垃圾收集过程中会使用更多的CPU资源,可能会对应用程序的其他部分造成影响。
- 配置和调优复杂:ParNew 收集器的配置和调优相对于 Serial 收集器更加复杂,需要合理设置并行线程数等参数以达到最佳性能。
- 停顿时间仍存在:尽管 ParNew 收集器减少了垃圾收集的停顿时间,但在进行垃圾收集时,仍然需要暂停所有工作线程(Stop-The-World),在大堆内存的情况下,这可能仍然导致明显的停顿。
- 在JDK 9+中被淘汰:随着G1收集器的引入和成为默认的垃圾收集器,ParNew 加 CMS 的组合在 JDK 9 及之后的版本中不再是主流选择,因为 G1 提供了更平衡的吞吐量和停顿时间,以及更简单的调优过程。
ParNew/Serial Old收集器运行示意图

Parallel Scavenge 收集器 (复制算法)
新生代并行收集器, 追求高吞吐量, 高效利用 CPU
-XX:MaxGCPauseMillis 配置最大垃圾收集停顿时间 -XX:GCTimeRatio 配置吞吐量大小
并行垃圾回收器在进行垃圾回收时, 同样会持有所有应用程序的线程, 并冻结所有应用程序线程,来进行垃圾回收工作
优点:
- 高吞吐量:Parallel Scavenge 收集器注重达到一个可控制的吞吐量(Throughput),它使用多个线程并行执行垃圾收集操作,可以充分利用多核CPU的计算能力,从而实现高吞吐量的垃圾收集。这使得它非常适合处理大规模数据和对处理能力要求较高的应用。
- 快速回收:该收集器主要关注减少垃圾收集时的停顿时间,通过将垃圾收集任务划分为多个阶段,并使用多个线程并行执行,可以更快地完成垃圾收集,并尽量减少应用程序的暂停时间。
- 可控制的吞吐量和最大停顿时间:Parallel Scavenge 收集器提供了一些参数来精确控制吞吐量和最大停顿时间的平衡。可以根据应用程序的性能需求来调整这些参数,以达到最佳的垃圾收集性能。
缺点:
- 高延迟:由于 Parallel Scavenge 收集器注重吞吐量而非低延迟,因此在追求高吞吐量的同时,可能会导致垃圾收集的停顿时间相对较长。这对于某些对实时性要求较高的应用程序可能不太适合。
- 内存占用:Parallel Scavenge 收集器为了追求高吞吐量,通常会使用较大的堆空间来存储对象,并且不会立即释放未使用的内存。这可能导致在某些情况下,垃圾收集器无法及时回收所有可回收的内存,从而造成一定的内存浪费。
Parallel Scavenge/Parallel Old收集器运行示意图

2.2 老年代的收集器
Serial Old 收集器 (标记-整理算法)
老年代单线程收集器,Serial 收集器的老年代版本,使用“标记-整理”(Mark-Compact)算法来进行垃圾收集。在标记阶段,它会遍历堆内存,标记出所有可达的对象;然后在整理阶段,将所有存活的对象向一端移动,从而清理出连续的空闲内存空间,减少内存碎片。
优点:
- 简单高效:对于单核处理器或者小内存资源的应用,Serial Old 收集器因为其简单和直接的垃圾回收方式,在这类环境下可以非常高效。
- 易于实现和调试:由于只涉及单线程操作,使得 Serial Old 收集器相对容易实现和调试。
缺点:
- 停顿时间长:所有应用线程都必须在垃圾收集期间暂停,这可能导致较长的停顿时间,影响到应用的响应速度和吞吐量。
- 不适合多核处理器:在多核处理器系统上,Serial Old 收集器无法充分利用硬件资源,因此并不适合大型、多线程的服务器端应用。
Serial/Serial Old收集器运行示意图
Parallel Old 收集器 (标记-整理算法)
老年代并行收集器, 吞吐量优先, Parallel Scavenge收集器的老年代版本
特点
- 多线程:Parallel Old 收集器同样采用多线程进行垃圾回收,这意味着它可以充分利用多核心处理器的优势,提高垃圾收集的效率。
- 算法:它使用“标记-整理”(Mark-Compact)算法来处理老年代的垃圾收集。与“标记-清除”(Mark-Sweep)算法相比,“标记-整理”算法在完成垃圾收集后不会留下空间碎片,从而避免了长时间运行后可能出现的内存分配问题。
- 适用场景:Parallel Old 收集器适用于多核服务器环境中,对吞吐量有较高要求的场景。它能够提供比CMS更好的吞吐量,但在停顿时间上可能不如CMS收集器和G1收集器
Parallel Scavenge/Parallel Old收集器运行示意图
CMS(Concurrent Mark Sweep)收集器(标记-清除算法)
收集器是一种以获取最短回收停顿时间为目标的垃圾收集器,主要用于收集老年代的垃圾。它适用于对响应时间有较高要求的场景,通过并发标记和清除来实现减少停顿时间的目的。
整个过程分为4个步骤,包括:
1.初始标记(CMS initial mark)
- 特点:这是一个需要“Stop-The-World”(STW)的阶段,但其持续的时间相对较短。
- 工作内容:标记所有直接与GC Roots相连的对象,以及从年轻代到老年代的引用对象(跨代引用)。此阶段虽然停顿时间短,但需要暂停所有应用线程。
2.并发标记(CMS concurrent mark)
- 特点:在这个阶段,GC线程和应用线程可以并发运行,不需要暂停应用线程。
- 工作内容:从初始标记阶段找到的根对象开始遍历整个对象图,标记所有可达的存活对象。由于在并发标记过程中应用线程仍在运行,可能会改变对象引用关系,因此需要记录这些改变。
3.重新标记(CMS remark)
- 特点:这也是一个需要STW的阶段,但CMS采用了多种技术(如增量更新、原始快照等)来缩短这一阶段的停顿时间。
- 工作内容:修正并发标记阶段因程序运行导致的标记记录变动。为了减少停顿时间,CMS在这个阶段使用了算法,如增量更新(Incremental Update)和原始快照(SATB,Snapshot At The Beginning),来处理并发阶段遗留的问题。
4.并发清除(CMS concurrent sweep)
- 特点:应用线程和垃圾收集线程可以并发执行,不需要暂停应用线程。
- 工作内容:清理掉在标记阶段标记为已死亡的对象,并回收他们占用的内存空间。这一阶段结束后,CMS收集器将已经清理好的内存空间归还给JVM使用。
但是CMS还远达不到完美的程度,它有以下3个明显的缺点:
- CMS收集器对CPU资源非常敏感。
- CMS收集器无法处理浮动垃圾(Floating Garbage),
- CMS收集结束时会有大量空间碎片产生。
Concurrent Mark Sweep收集器运行示意图

2.3 整个堆
G1(Garbage First)收集器 (标记-整理算法)
G1 回收的范围是整个 Java 堆(包括新生代,老年代)
G1具备如下特点。
- 并行与并发:G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短Stop-The-World停顿的时间,部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让Java程序继续执行。
- 分代收集:与其他收集器一样,分代概念在G1中依然得以保留。虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次GC的旧对象以获取更好的收集效果。
- 空间整合:与CMS的“标记—清理”算法不同,G1从整体来看是基于“标记—整理”算法实现的收集器,从局部(两个Region之间)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着G1运作期间不会产生内存空间碎片,收集后能提供规整的可用内存。这种特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。
- 可预测的停顿:这是G1相对于CMS的另一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
G1收集器的运作大致可划分为以下几个步骤:
1.初始标记(Initial Marking)
- 特点:此阶段需要暂停所有的应用线程(Stop-The-World, STW),但持续时间相对较短。
- 工作内容:标记从GC Roots直接可达的对象,以及年轻代中存活对象的边界。
2.根区域扫描(Root Region Scanning)
- 特点:在应用线程运行的同时执行,不需要暂停应用线程。
- 工作内容:处理初始标记阶段找到的存活对象所引用的对象。这一步骤必须在年轻代的下一次垃圾收集前完成。
3.并发标记(Concurrent Marking)
- 特点:与应用线程并发执行,不会导致应用线程停顿。
- 工作内容:从根区域扫描阶段标记的对象开始,遍历整个堆,标记出所有可达的存活对象。
4.最终标记(Final Marking)
- 特点:需要STW,但通过优化(如使用记忆集和卡表来减少标记范围)尽量缩短停顿时间。
- 工作内容:处理并发标记阶段遗留的少量工作,如处理SATB(Snapshot At The Beginning)队列中的剩余对象,以及修正并发标记期间因应用程序运行产生的变动。
5.筛选回收(Live Data Counting and Evacuation)
- 特点:需要STW,此阶段的停顿时间是G1收集器控制的重点。
- 工作内容:根据之前的标记结果,选择一部分内存区域进行清理。G1会优先选择回收价值最大的区域(即垃圾最多的区域)进行清理,以提高垃圾收集的效率。在这个阶段,存活的对象会被移动到其他区域,同时整理碎片,释放空间。
G1收集器运行示意图

相关文章:
jvm垃圾收集器之七种武器
目录 1.回收算法 1.1 标记-清除算法(Mark-Sweep) 1.2 复制算法(Copying) 1.3 标记-整理算法(Mark-Compact) 2.HotSpot虚拟机的垃圾收集器 2.1 新生代的收集器 Serial 收集器(复制算法) ParNew 收集器 (复制算法) Parallel Scavenge 收集器 (复制…...

STM32面试相关问题
STM32面试相关问题: STM32的内核型号,主频,传感器和单片机总线类型,IIC,SPI,RS485UART数据帧项目中一些参数的设置 STM32 系统移植 ARM编译 常用的驱动编写方式 自己写过哪些方面驱动 其实如果问32的问题,…...

风行智能电视N39S、N40 强制刷机升级方法,附刷机升级数据MstarUpgrade.bin
升级步骤: 1、下载刷机数据,如是压缩包,需要先解压,然后将刷机bin格式的文件重命名为MstarUpgrade.bin 2、将此文件放到U盘根目录 (U盘格式FAT32,单分区,建议4G的优盘刷机成功率高)…...

【C语言】简易英语词典
文章目录 一、定义英语单词信息的结构体二、主函数功能逻辑三、查单词函数四、背单词函数五、补充 一、定义英语单词信息的结构体 添加必要的头文件、宏定义和声明,之后定义英语单词信息结构体。 /* 头文件和宏定义 */ #include <stdio.h> #include <std…...

【算法题】104. 二叉树的最大深度
题目 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3 示例 2: 输入:root [1,nul…...
Docker配置Portainer容器管理界面
目录 一、Portainer 简介 优点: 缺点: 二、环境配置 1. 拉取镜像 2. 创建启动容器 三、操作测试 1. 进入容器 2. 拉取镜像并部署 3. 访问测试 一、Portainer 简介 Portainer 是一个开源的轻量级容器管理界面,用于管理 Docker 容器…...
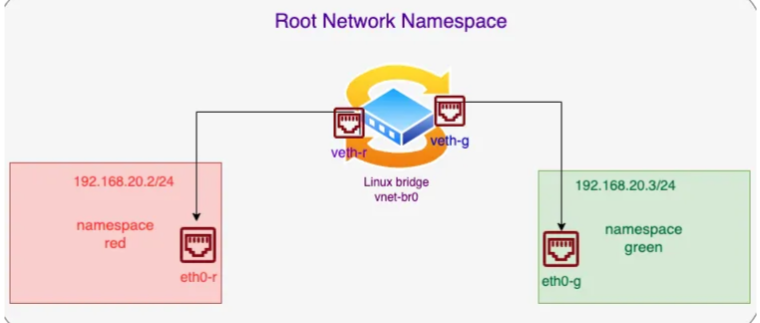
Linux network namespace 访问外网以及多命名空间通信(经典容器组网 veth pair + bridge 模式认知)
写在前面 整理K8s网络相关笔记博文内容涉及 Linux network namespace 访问外网方案 Demo实际上也就是 经典容器组网 veth pair bridge 模式理解不足小伙伴帮忙指正 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已…...

网络渗透测试:Wireshark抓取qq图片
Wireshark Wireshark Downloadhttps://www.wireshark.org/download.html 简介 WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。本文主要内容包括: 1、Wireshar…...
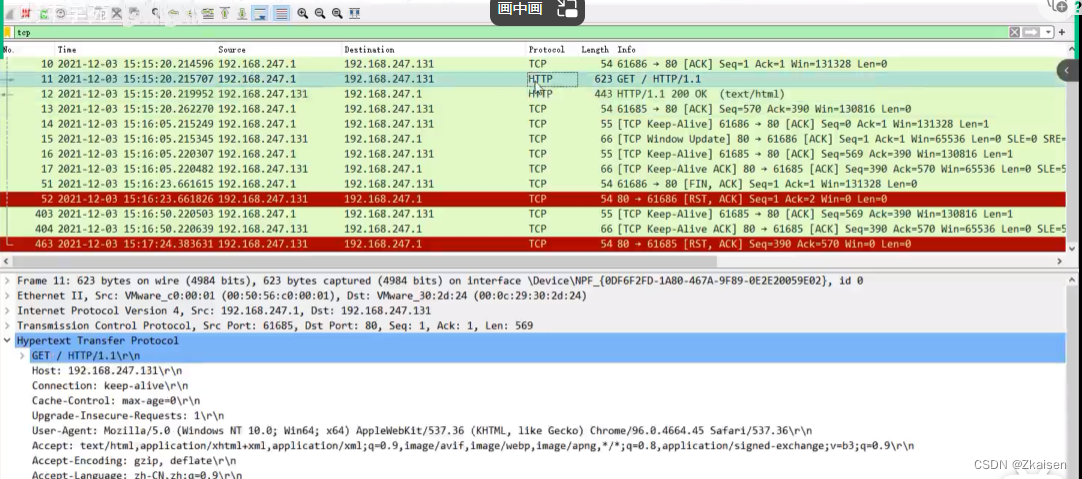
网络协议与攻击模拟_16HTTP协议
1、HTTP协议结构 2、在Windows server去搭建web扫描器 3、分析HTTP协议流量 一、HTTP协议 1、概念 HTTP(超文本传输协议)用于在万维网服务器上传输超文本(HTML)到本地浏览器的传输协议 基于TCP/IP(HTML文件、图片、查询结构等&…...

叙事弧基础
原文:MasterClass. 2020. Learn About Narrative Arcs: Definition, Examples, and How to Create a Narrative Arc in Your Writing - 2021. https://www.masterclass.com/articles/what-are-the-elements-of-a-narrative-arc-and-how-do-you-create-one-in-writin…...
:python的exe程序打包制作)
python从入门到精通(二十):python的exe程序打包制作
python的exe程序打包制作 python打包的概念python打包的模块导入模块安装验证基本语法命令参数文件夹模式单文件模式资源嵌入exe更改图标启动画面(闪屏)禁用异常提示 python打包的概念 将普通的*.py程序文件打包成exe文件。exe文件即可执行文件…...
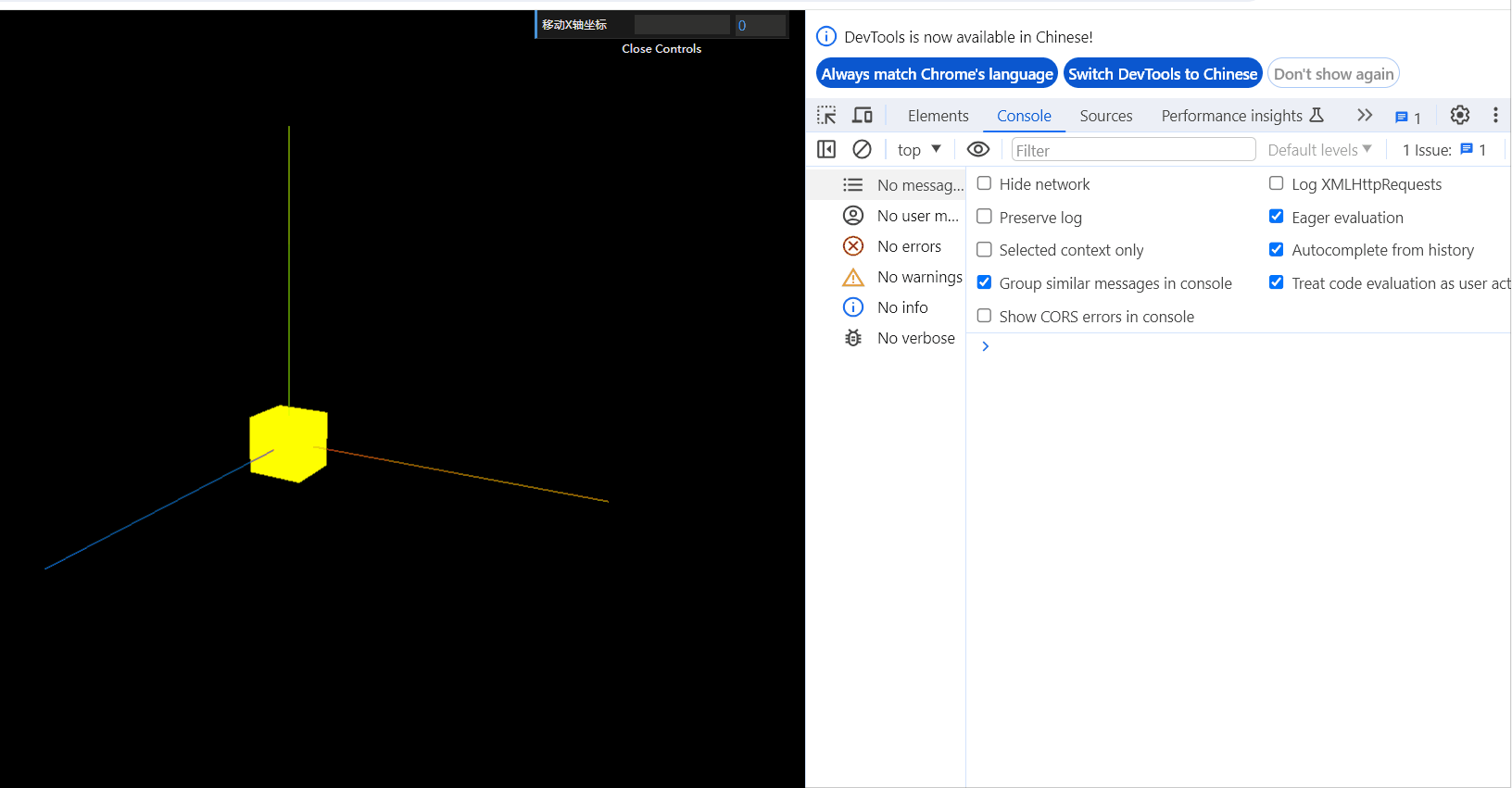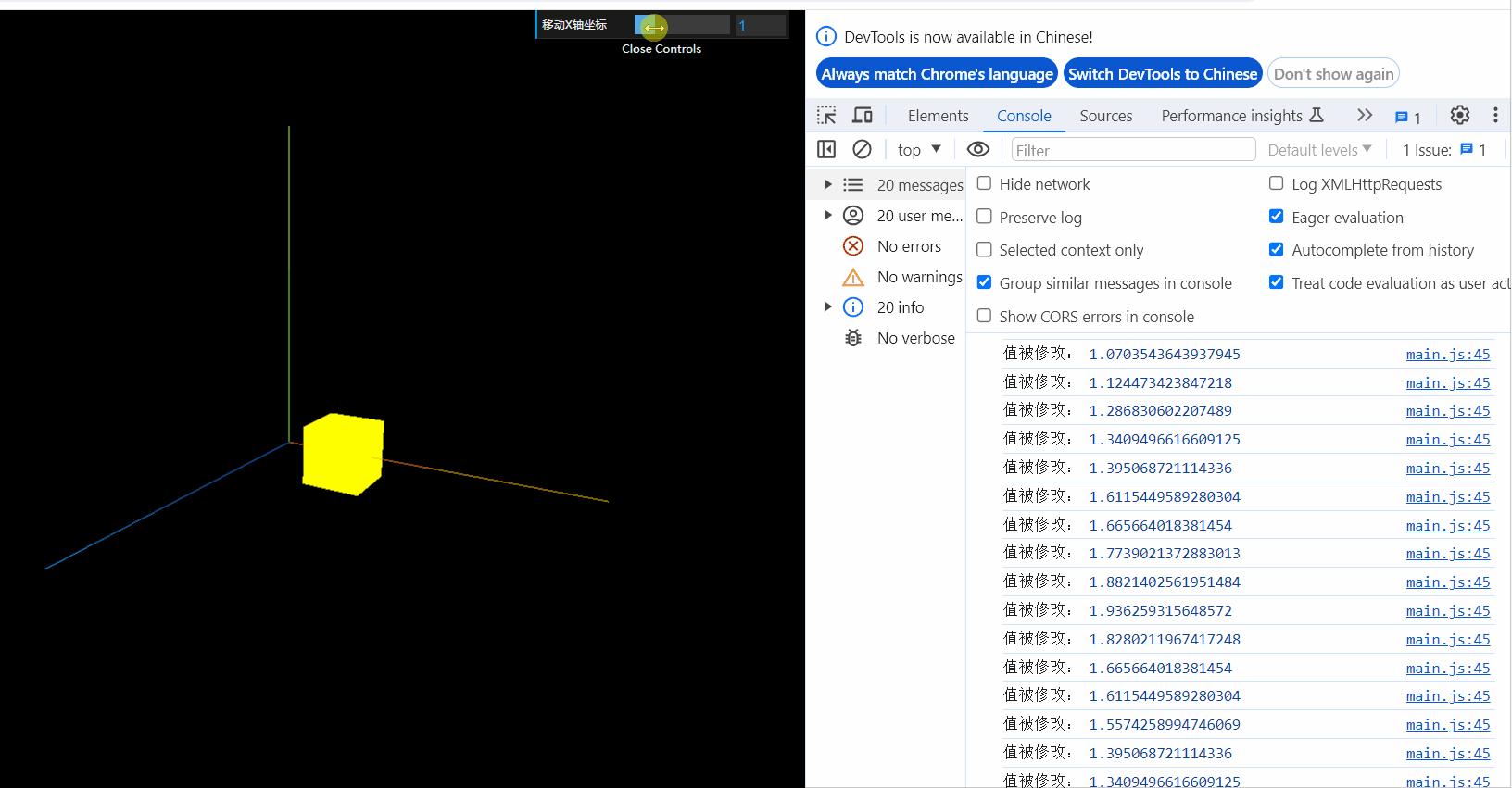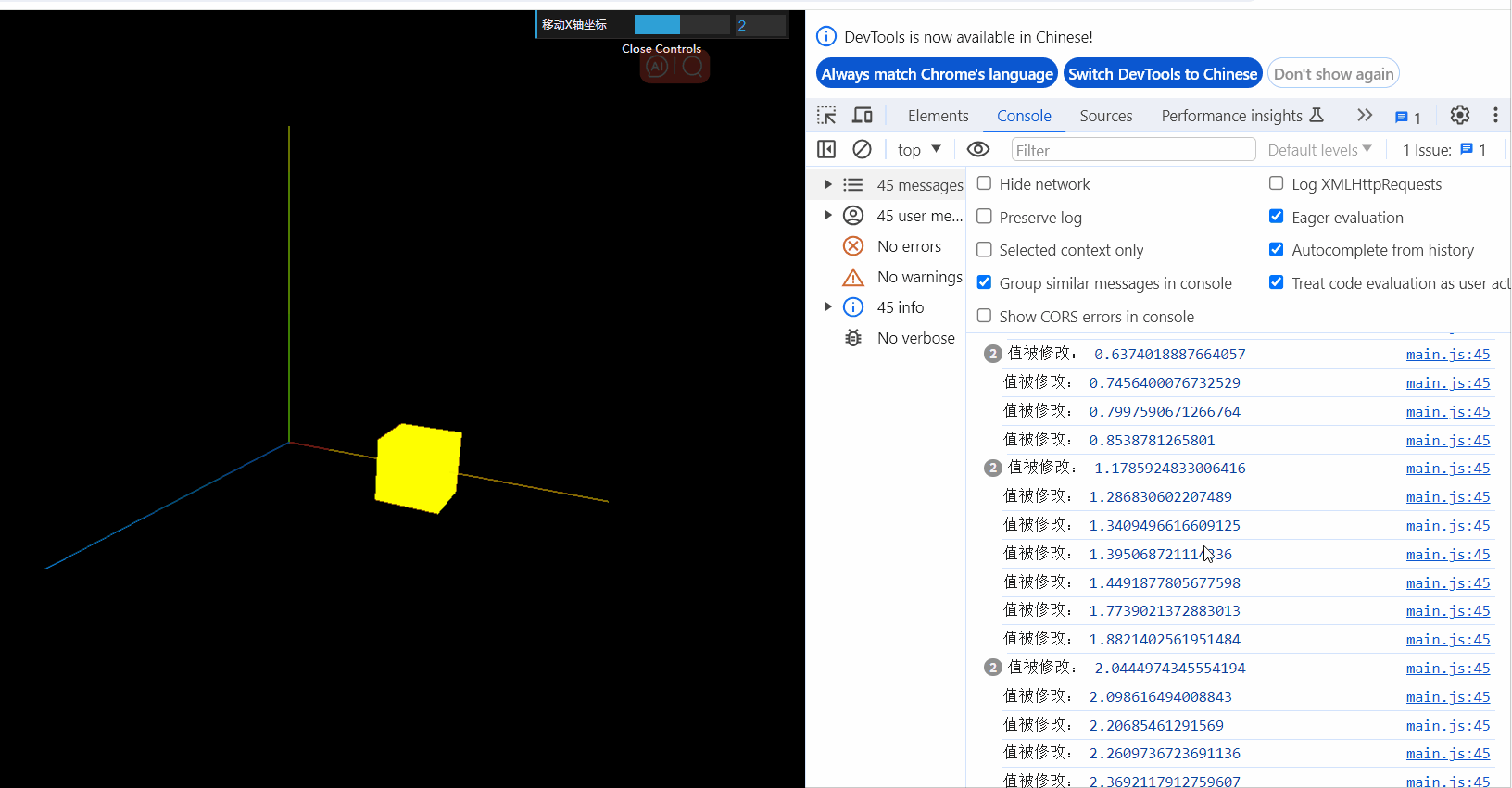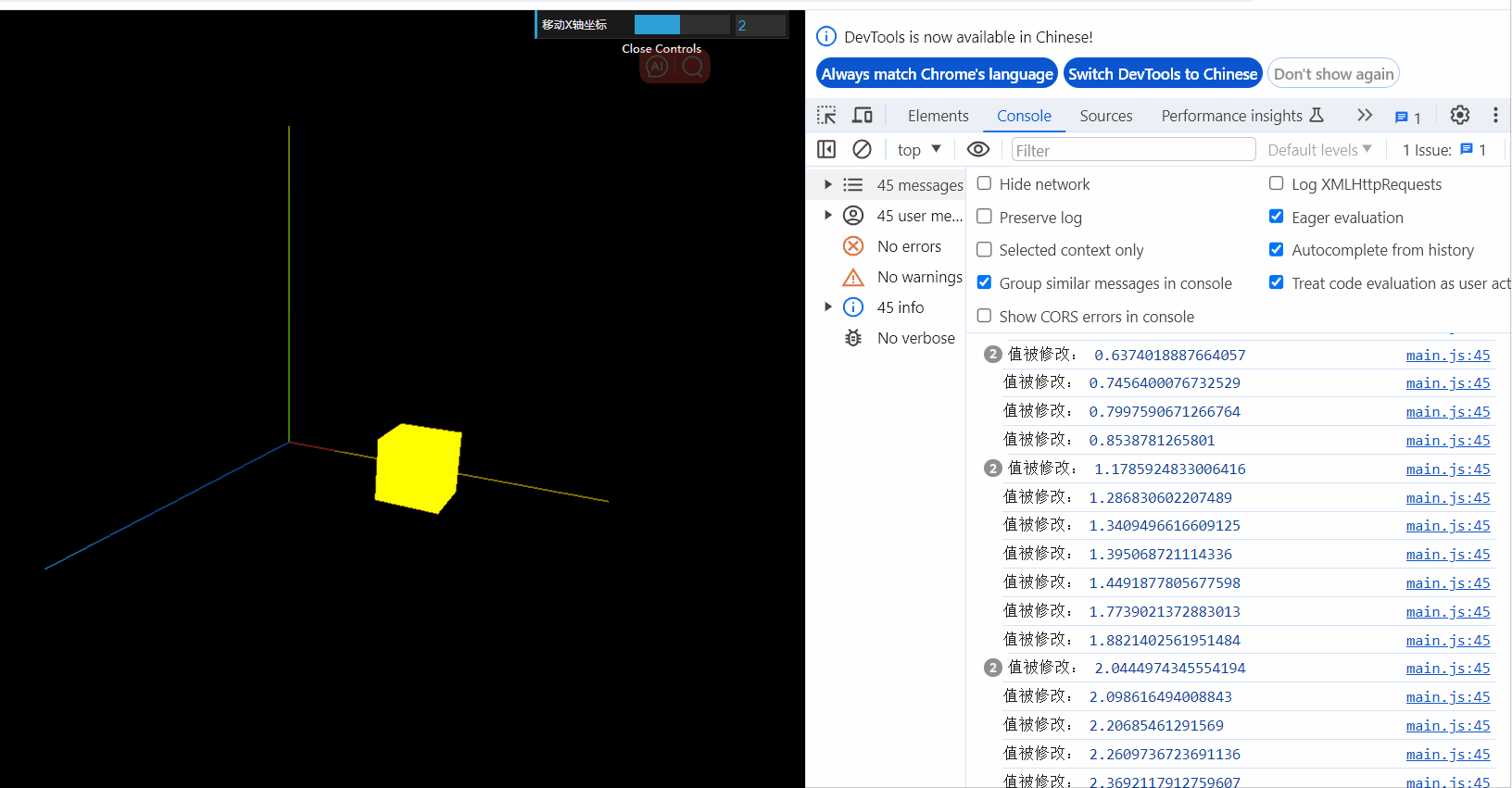
three.js 细一万倍教程 从入门到精通(一)
目录 一、three.js开发环境搭建 1.1、使用parcel搭建开发环境 1.2、使用three.js渲染第一个场景和物体 1.3、轨道控制器查看物体 二、three.js辅助设置 2.1、添加坐标轴辅助器 2.2、设置物体移动 2.3、物体的缩放与旋转 缩放 旋转 2.4、应用requestAnimationFrame …...
电路设计(16)——纪念馆游客进出自动计数显示器proteus仿真
1.设计要求 设计、制作一个纪念馆游客进出自动计数显示器。 某县,有一个免费参观的“陶渊明故里纪念馆”,游客进出分道而行,如同地铁有确保单向通行的措施。在入口与出口处分别设有红外检测、声响、累加计数器装置,当游人进&#…...
Python数学建模之回归分析
1.基本概念及应用场景 回归分析是一种预测性的建模技术,数学建模中常用回归分析技术寻找存在相关关系的变量间的数学表达式,并进行统计推断。例如,司机的鲁莽驾驶与交通事故的数量之间的关系就可以用回归分析研究。回归分析根据变量的…...
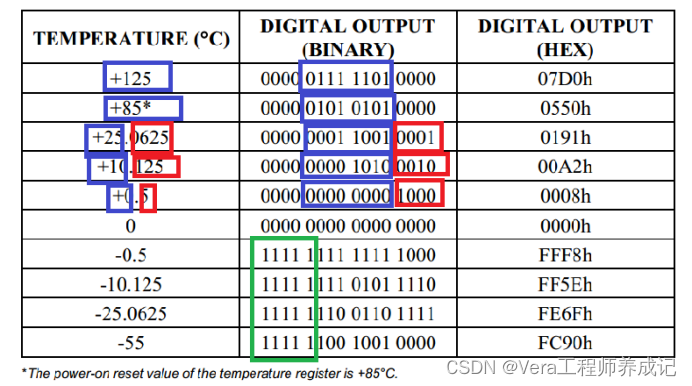
单片机学习笔记---DS18B20温度传感器
目录 DS18B20介绍 模拟温度传感器的基本结构 数字温度传感器的应用 引脚及应用电路 DS18B20的原理图 DS18B20内部结构框图 暂存器内部 单总线介绍 单总线电路规范 单总线时序结构 初始化 发送一位 发送一个字节 接收一位 接收一个字节 DS18B20操作流程 指令介…...
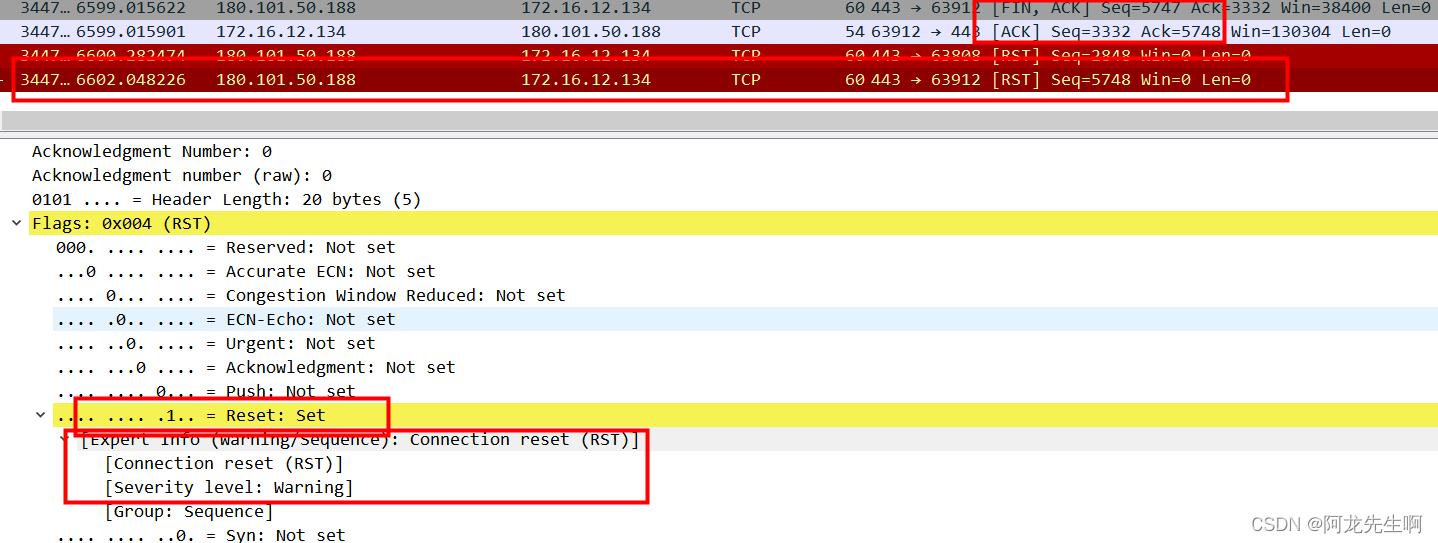
【网络】WireShark过滤 | WireShark实现TCP三次握手和四次挥手
目录 一、开启WireShark的大门 1.1 WireShark简介 1.2 常用的Wireshark过滤方式 二、如何抓包搜索关键字 2.1 协议过滤 2.2 IP过滤 编辑 2.3 过滤端口 2.4 过滤MAC地址 2.5 过滤包长度 2.6 HTTP模式过滤 三、ARP协议分析 四、WireShark之ICMP协议 五、TCP三次握…...
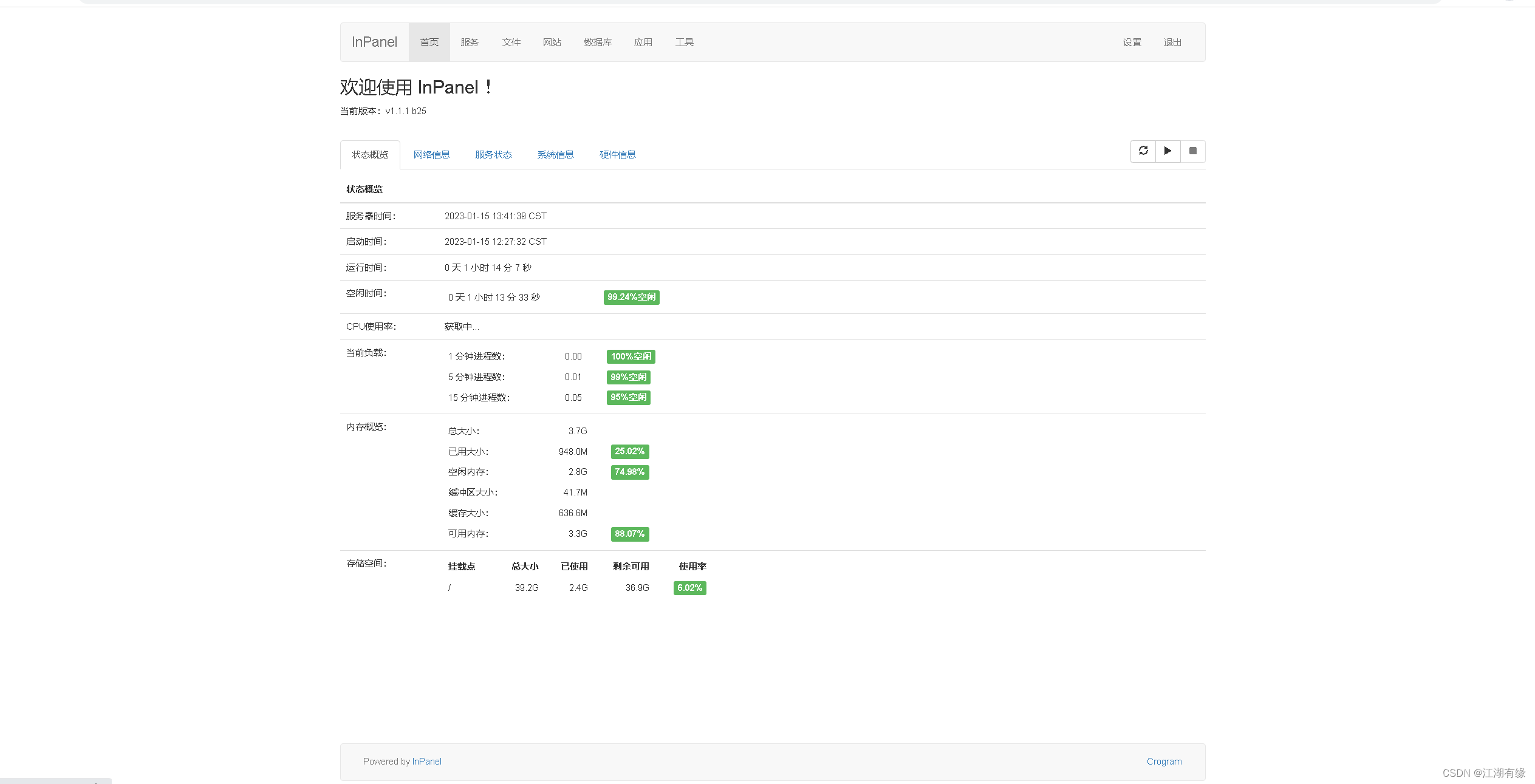
开源免费的Linux服务器管理面板分享
开源免费的Linux服务器管理面板分享 一、1Panel1.1 1Panel 简介1.2 1Panel特点1.3 1Panel面板首页1.4 1Panel使用体验 二、webmin2.1 webmin简介2.2 webmin特点2.3 webmin首页2.4 webmin使用体验 三、Cockpit3.1 Cockpit简介3.2 Cockpit特点3.3 Cockpit首页3.4 Cockpit使用体验…...

leetcode算法-位运算
位运算,直接在二进制上进行的按位操作,位运算的种类如下: 1.按位异或^:异或的含义是操作的两位不同,则结果为1,相同则结果为0,所以两个相同的数异或,结果应该是0,3^3的结果是0,3^4的…...

「MySQL」约束
概述 分类 约束描述关键字非空约束限制该字段的数据不能为 nullNOT NULL唯一约束保证该字段的所有数据都是唯一、不重复的UNIQUE主键约束主键是一行数据的唯一标识,要求非空且唯一PRIMARY KEY默认约束保存数据时,如果未指定该字段的值,则采…...
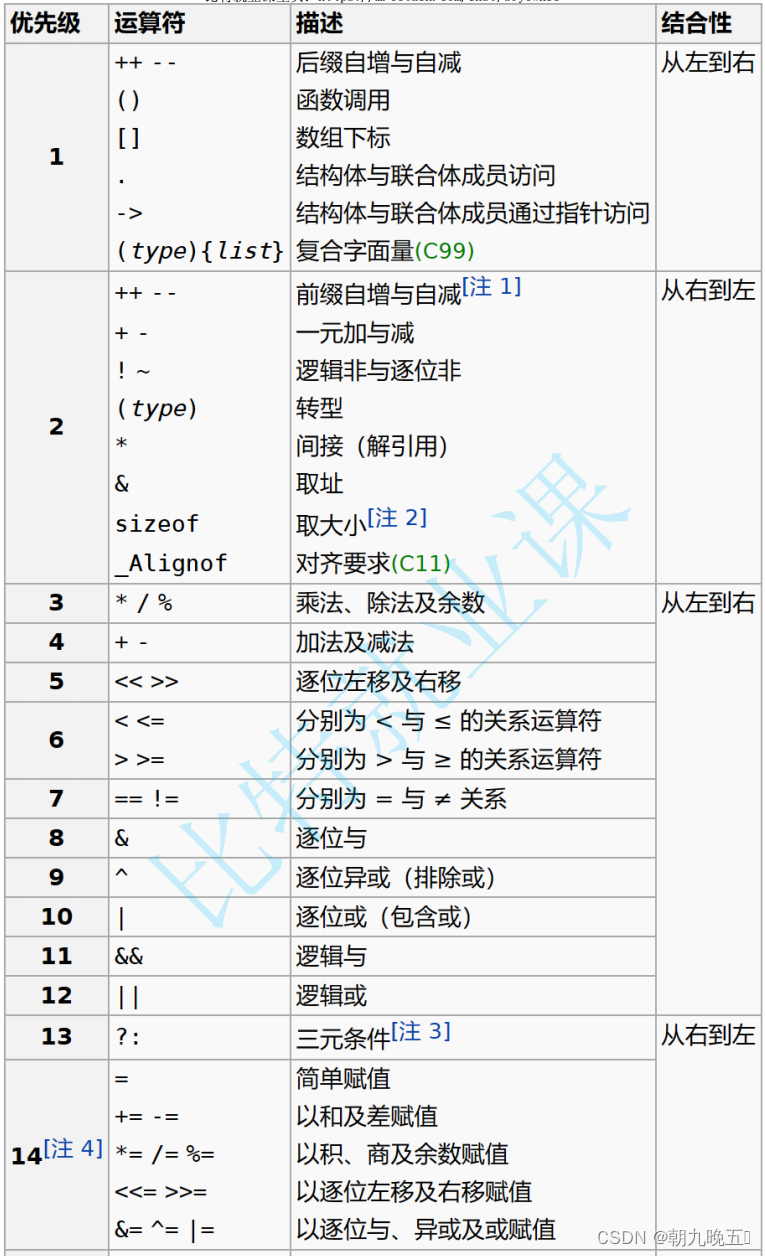
C语言:详解操作符(下)
上一篇链接:C语言:详解操作符(上)摘要: 在上篇文章中,我们已经讲过位操作符等涉及二进制的操作符,这些有助于帮助我们后期理解数据如何在计算机中运算并存储,接下来本篇将更多的讲述…...

3步搞定缠论分析:通达信自动画中枢和笔段的终极免费工具
3步搞定缠论分析:通达信自动画中枢和笔段的终极免费工具 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为缠论的复杂理论头疼吗?想要快速掌握市场节奏却苦于分析耗时太长&…...

BetterDiscord Installer完全指南:如何一键安装和优化Discord插件
BetterDiscord Installer完全指南:如何一键安装和优化Discord插件 【免费下载链接】Installer A simple standalone program which automates the installation, removal and maintenance of BetterDiscord. 项目地址: https://gitcode.com/gh_mirrors/ins/Instal…...
)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层(丝印、装配、阻焊)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层 在PCB设计领域,封装设计往往被视为"简单"的基础工作。许多工程师认为,只要焊盘位置正确、丝印轮廓大致匹配,一个封装就算完成了。直到某天,工…...

当流程图XML“损坏”时:手把手教你用Activiti API解析与修复BPMN文件
当BPMN文件遭遇“数据灾难”:Activiti深度修复实战指南 凌晨三点,服务器警报突然响起——核心业务流程引擎拒绝加载最新上传的BPMN文件。这不是简单的格式错误,而是一个从老旧系统迁移来的、经过多次手工编辑的流程定义文件。作为技术负责人&…...

SAE J1939请求与响应实战:用PCAN-View抓包分析‘要转速’的全过程
SAE J1939实战解析:从请求转速到数据解码的全链路操作指南 在车载诊断和商用车通信领域,SAE J1939协议如同神经系统般贯穿整个车辆架构。当工程师需要获取发动机转速这类关键参数时,协议中PGN(参数组编号)的请求与响应…...
)
用Python和Matplotlib搞定高光谱图像可视化:从.mat文件到伪彩色图(附完整代码)
PythonMatplotlib高光谱图像可视化实战:从.mat文件到伪彩色合成 高光谱图像处理正逐渐从专业遥感领域走向更广泛的工业应用场景。当一位农业科技公司的算法工程师第一次拿到作物生长监测的高光谱数据时,面对.mat格式文件中那个神秘的三维矩阵,…...

拒绝“拍脑袋“备货:武汉丝路云如何利用Flink实时计算打造跨境供应链的“数据大脑“?
前言 在之前的文章中(如《揭秘跨境供应链的高并发架构》),我们探讨了如何通过微服务架构保证系统在"黑五"大促时不崩溃。但很多客户反馈了一个更深层的问题: "系统确实不崩了,但库存还是积压。要么备货…...

终极指南:使用Play Integrity API Checker保护你的Android应用安全
终极指南:使用Play Integrity API Checker保护你的Android应用安全 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-a…...

全志T113-i嵌入式Linux系统一键升级方案设计与实现
1. 项目概述:为什么我们需要“一键升级”?拿到一块全志T113-i的开发板,或者用它做产品的朋友,肯定都经历过手动更新固件的“痛苦”。传统的升级方式,比如用PhoenixSuit、LiveSuit这类PC端工具,需要连接USB线…...

WSL2网络抽风?能ping通宿主机但上不了网?试试这个一劳永逸的DNS修复脚本
WSL2网络故障终极解决方案:自动化DNS修复脚本实战指南 你是否遇到过这样的场景:在WSL2中能够ping通宿主机,却无法访问任何外网资源?每次重启后手动修改的/etc/resolv.conf配置总是被神秘重置?这种恼人的网络问题已经成…...