Vue源码系列讲解——模板编译篇【四】(文本解析器)
1. 前言
在上篇文章中我们说了,当HTML解析器解析到文本内容时会调用4个钩子函数中的chars函数来创建文本型的AST节点,并且也说了在chars函数中会根据文本内容是否包含变量再细分为创建含有变量的AST节点和不包含变量的AST节点,如下:
// 当解析到标签的文本时,触发chars
chars (text) {if(res = parseText(text)){let element = {type: 2,expression: res.expression,tokens: res.tokens,text}} else {let element = {type: 3,text}}
}
从上面代码中可以看到,创建含有变量的AST节点时节点的type属性为2,并且相较于不包含变量的AST节点多了两个属性:expression和tokens。那么如何来判断文本里面是否包含变量以及多的那两个属性是什么呢?这就涉及到文本解析器了,当Vue用HTML解析器解析出文本时,再将解析出来的文本内容传给文本解析器,最后由文本解析器解析该段文本里面是否包含变量以及如果包含变量时再解析expression和tokens。那么接下来,本篇文章就来分析一下文本解析器都干了些什么。
2. 结果分析
研究文本解析器内部原理之前,我们先来看一下由HTML解析器解析得到的文本内容经过文本解析器后输出的结果是什么样子的,这样对我们后面分析文本解析器内部原理会有很大的帮助。
从上面chars函数的代码中可以看到,把HTML解析器解析得到的文本内容text传给文本解析器parseText函数,根据parseText函数是否有返回值判断该文本是否包含变量,以及从返回值中取到需要的expression和tokens。那么我们就先来看一下parseText函数如果有返回值,那么它的返回值是什么样子的。
假设现有由HTML解析器解析得到的文本内容如下:
let text = "我叫{{name}},我今年{{age}}岁了"
经过文本解析器解析后得到:
let res = parseText(text)
res = {expression:"我叫"+_s(name)+",我今年"+_s(age)+"岁了",tokens:["我叫",{'@binding': name },",我今年"{'@binding': age },"岁了"]
}
从上面的结果中我们可以看到,expression属性就是把文本中的变量和非变量提取出来,然后把变量用_s()包裹,最后按照文本里的顺序把它们用+连接起来。而tokens是个数组,数组内容也是文本中的变量和非变量,不一样的是把变量构造成{'@binding': xxx}。
那么这样做有什么用呢?这主要是为了给后面代码生成阶段的生成render函数时用的,这个我们在后面介绍代码生成阶段是会详细说明,此处暂可理解为单纯的在构造形式。
OK,现在我们就可以知道文本解析器内部就干了三件事:
- 判断传入的文本是否包含变量
- 构造expression
- 构造tokens
那么接下来我们就通过阅读源码,逐行分析文本解析器内部工作原理。
3. 源码分析
文本解析器的源码位于 src/compiler/parser/text-parsre.js 中,代码如下:
const defaultTagRE = /\{\{((?:.|\n)+?)\}\}/g
const buildRegex = cached(delimiters => {const open = delimiters[0].replace(regexEscapeRE, '\\$&')const close = delimiters[1].replace(regexEscapeRE, '\\$&')return new RegExp(open + '((?:.|\\n)+?)' + close, 'g')
})
export function parseText (text,delimiters) {const tagRE = delimiters ? buildRegex(delimiters) : defaultTagREif (!tagRE.test(text)) {return}const tokens = []const rawTokens = []/*** let lastIndex = tagRE.lastIndex = 0* 上面这行代码等同于下面这两行代码:* tagRE.lastIndex = 0* let lastIndex = tagRE.lastIndex*/let lastIndex = tagRE.lastIndex = 0let match, index, tokenValuewhile ((match = tagRE.exec(text))) {index = match.index// push text tokenif (index > lastIndex) {// 先把'{{'前面的文本放入tokens中rawTokens.push(tokenValue = text.slice(lastIndex, index))tokens.push(JSON.stringify(tokenValue))}// tag token// 取出'{{ }}'中间的变量expconst exp = parseFilters(match[1].trim())// 把变量exp改成_s(exp)形式也放入tokens中tokens.push(`_s(${exp})`)rawTokens.push({ '@binding': exp })// 设置lastIndex 以保证下一轮循环时,只从'}}'后面再开始匹配正则lastIndex = index + match[0].length}// 当剩下的text不再被正则匹配上时,表示所有变量已经处理完毕// 此时如果lastIndex < text.length,表示在最后一个变量后面还有文本// 最后将后面的文本再加入到tokens中if (lastIndex < text.length) {rawTokens.push(tokenValue = text.slice(lastIndex))tokens.push(JSON.stringify(tokenValue))}// 最后把数组tokens中的所有元素用'+'拼接起来return {expression: tokens.join('+'),tokens: rawTokens}
}我们看到,除开我们自己加的注释,代码其实不复杂,我们逐行分析。
parseText函数接收两个参数,一个是传入的待解析的文本内容text,一个包裹变量的符号delimiters。第一个参数好理解,那第二个参数是干什么的呢?别急,我们看函数体内第一行代码:
const tagRE = delimiters ? buildRegex(delimiters) : defaultTagRE
函数体内首先定义了变量tagRE,表示一个正则表达式。这个正则表达式是用来检查文本中是否包含变量的。我们知道,通常我们在模板中写变量时是这样写的:hello 。这里用{{}}包裹的内容就是变量。所以我们就知道,tagRE是用来检测文本内是否有{{}}。而tagRE又是可变的,它是根据是否传入了delimiters参数从而又不同的值,也就是说如果没有传入delimiters参数,则是检测文本是否包含{{}},如果传入了值,就会检测文本是否包含传入的值。换句话说在开发Vue项目中,用户可以自定义文本内包含变量所使用的符号,例如你可以使用%包裹变量如:hello %name%。
接下来用tagRE去匹配传入的文本内容,判断是否包含变量,若不包含,则直接返回,如下:
if (!tagRE.test(text)) {return
}
如果包含变量,那就继续往下看:
const tokens = []
const rawTokens = []
let lastIndex = tagRE.lastIndex = 0
let match, index, tokenValue
while ((match = tagRE.exec(text))) {}
接下来会开启一个while循环,循环结束条件是tagRE.exec(text)的结果match是否为null,exec( )方法是在一个字符串中执行匹配检索,如果它没有找到任何匹配就返回null,但如果它找到了一个匹配就返回一个数组。例如:
tagRE.exec("hello {{name}},I am {{age}}")
//返回:["{{name}}", "name", index: 6, input: "hello {{name}},I am {{age}}", groups: undefined]
tagRE.exec("hello")
//返回:null
可以看到,当匹配上时,匹配结果的第一个元素是字符串中第一个完整的带有包裹的变量,第二个元素是第一个被包裹的变量名,第三个元素是第一个变量在字符串中的起始位置。
接着往下看循环体内:
while ((match = tagRE.exec(text))) {index = match.indexif (index > lastIndex) {// 先把'{{'前面的文本放入tokens中rawTokens.push(tokenValue = text.slice(lastIndex, index))tokens.push(JSON.stringify(tokenValue))}// tag token// 取出'{{ }}'中间的变量expconst exp = match[1].trim()// 把变量exp改成_s(exp)形式也放入tokens中tokens.push(`_s(${exp})`)rawTokens.push({ '@binding': exp })// 设置lastIndex 以保证下一轮循环时,只从'}}'后面再开始匹配正则lastIndex = index + match[0].length}
上面代码中,首先取得字符串中第一个变量在字符串中的起始位置赋给index,然后比较index和lastIndex的大小,此时你可能有疑问了,这个lastIndex是什么呢?在上面定义变量中,定义了let lastIndex = tagRE.lastIndex = 0,所以lastIndex就是tagRE.lastIndex,而tagRE.lastIndex又是什么呢?当调用exec( )的正则表达式对象具有修饰符g时,它将把当前正则表达式对象的lastIndex属性设置为紧挨着匹配子串的字符位置,当同一个正则表达式第二次调用exec( ),它会将从lastIndex属性所指示的字符串处开始检索,如果exec( )没有发现任何匹配结果,它会将lastIndex重置为0。示例如下:
const tagRE = /\{\{((?:.|\n)+?)\}\}/g
tagRE.exec("hello {{name}},I am {{age}}")
tagRE.lastIndex // 14
从示例中可以看到,tagRE.lastIndex就是第一个包裹变量最后一个}所在字符串中的位置。lastIndex初始值为0。
那么接下里就好理解了,当index>lastIndex时,表示变量前面有纯文本,那么就把这段纯文本截取出来,存入rawTokens中,同时再调用JSON.stringify给这段文本包裹上双引号,存入tokens中,如下:
if (index > lastIndex) {// 先把'{{'前面的文本放入tokens中rawTokens.push(tokenValue = text.slice(lastIndex, index))tokens.push(JSON.stringify(tokenValue))
}
如果index不大于lastIndex,那说明index也为0,即该文本一开始就是变量,例如:hello。那么此时变量前面没有纯文本,那就不用截取,直接取出匹配结果的第一个元素变量名,将其用_s()包裹存入tokens中,同时再把变量名构造成{'@binding': exp}存入rawTokens中,如下:
// 取出'{{ }}'中间的变量exp
const exp = match[1].trim()
// 把变量exp改成_s(exp)形式也放入tokens中
tokens.push(`_s(${exp})`)
rawTokens.push({ '@binding': exp })
接着,更新lastIndex以保证下一轮循环时,只从}}后面再开始匹配正则,如下:
lastIndex = index + match[0].length
接着,当while循环完毕时,表明文本中所有变量已经被解析完毕,如果此时lastIndex < text.length,那就说明最后一个变量的后面还有纯文本,那就将其再存入tokens和rawTokens中,如下:
// 当剩下的text不再被正则匹配上时,表示所有变量已经处理完毕
// 此时如果lastIndex < text.length,表示在最后一个变量后面还有文本
// 最后将后面的文本再加入到tokens中
if (lastIndex < text.length) {rawTokens.push(tokenValue = text.slice(lastIndex))tokens.push(JSON.stringify(tokenValue))
}
最后,把tokens数组里的元素用+连接,和rawTokens一并返回,如下:
return {expression: tokens.join('+'),tokens: rawTokens
}
以上就是文本解析器parseText函数的所有逻辑了。
4. 总结
本篇文章介绍了文本解析器的内部工作原理,文本解析器的作用就是将HTML解析器解析得到的文本内容进行二次解析,解析文本内容中是否包含变量,如果包含变量,则将变量提取出来进行加工,为后续生产render函数做准备。
相关文章:
)
Vue源码系列讲解——模板编译篇【四】(文本解析器)
1. 前言 在上篇文章中我们说了,当HTML解析器解析到文本内容时会调用4个钩子函数中的chars函数来创建文本型的AST节点,并且也说了在chars函数中会根据文本内容是否包含变量再细分为创建含有变量的AST节点和不包含变量的AST节点,如下ÿ…...
微信小程序开发学习笔记《17》uni-app框架-tabBar
微信小程序开发学习笔记《17》uni-app框架-tabBar 博主正在学习微信小程序开发,希望记录自己学习过程同时与广大网友共同学习讨论。建议仔细阅读uni-app对应官方文档 一、创建tabBar分支 运行如下的命令,基于master分支在本地创建tabBar子分支&#x…...

《区块链公链数据分析简易速速上手小册》第5章:高级数据分析技术(2024 最新版)
文章目录 5.1 跨链交易分析5.1.1 基础知识5.1.2 重点案例:分析以太坊到 BSC 的跨链交易理论步骤和工具准备Python 代码示例构思步骤1: 设置环境和获取合约信息步骤2: 分析以太坊上的锁定交易步骤3: 跟踪BSC上的铸币交易 结论 5.1.3 拓展案例 1:使用 Pyth…...
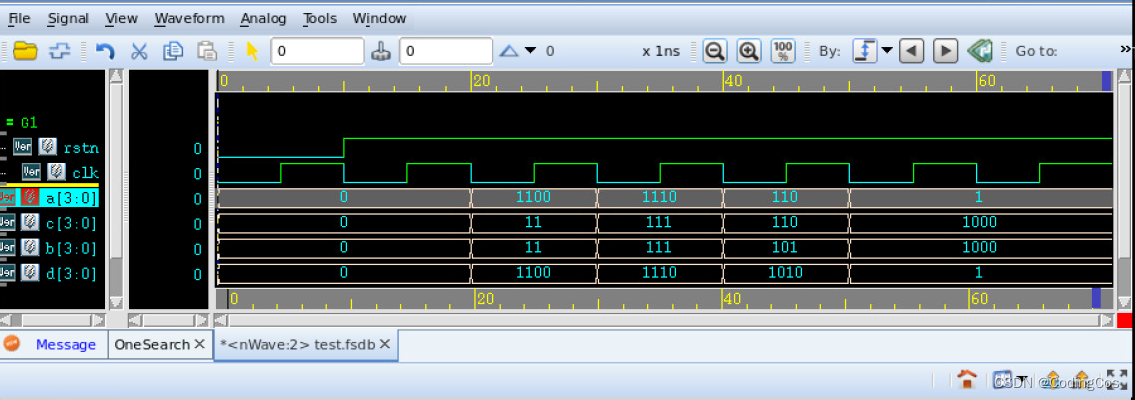
【芯片设计- RTL 数字逻辑设计入门 15 -- 函数实现数据大小端转换】
文章目录 函数实现数据大小端转换函数语法函数使用的规则Verilog and Testbench综合图VCS 仿真波形 函数实现数据大小端转换 在数字芯片设计中,经常把实现特定功能的模块编写成函数,在需要的时候再在主模块中调用,以提高代码的复用性和提高设…...

Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java)
Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java) 比赛链接:Codeforces Round 925 (Div. 3) D题传送门:D.Divisible Pairs 题目:D.Divisible Pairs 题目描述 输出格式 For each test case, output a single integer — the num…...

【C语言】实现单链表
目录 (一)头文件 (二)功能实现 (1)打印单链表 (2)头插与头删 (3)尾插与尾删 (4) 删除指定位置节点 和 删除指定位置之后的节点 …...

Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...
责任链模式)
设计模式(行为型模式)责任链模式
目录 一、简介二、责任链模式2.1、处理器接口2.2、具体处理器类2.3、使用 三、优点与缺点 一、简介 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,允许你将请求沿着处理者链进行传递,直到有一个处理者能够处理…...
HTTP和HTTPS区别!
http 是我们几乎天天都要打交道的东西,相关知识点有点多,所以也有不少面试必问的点,这里做了一些整理,帮且大家树立完整的 http 知识体系,对面试官说 so easy HTTP 的特点和缺点 特点:无连接、无状态、灵…...
)
麻将普通胡牌算法(带混)
最近在玩腾讯的麻将游戏,但是经常需要充值,于是就想自己实现一个简单的单机麻将游戏.第一个难点就是实现胡牌的判断.这里写一下心得. 术语 本文的胡牌是指手牌构成了3N2的牌型,即一对做将,剩下的牌均为刻子(3张一样的牌)或者顺子(3张连续的牌比如234饼). 下面就是一个14张牌…...

Rust结构体详解:定义、使用及方法
Rust 是一门强调安全性和性能的系统级编程语言,它引入了结构体(struct)作为一种自定义的数据类型,允许程序员以更加灵活的方式组织和操作数据。在本篇博客中,我们将深入探讨 Rust 结构体的定义、使用以及相关概念。 什…...
LeetCode、435. 无重叠区间【中等,贪心 区间问题】
文章目录 前言LeetCode、435. 无重叠区间【中等,贪心 区间问题】题目链接及分类思路贪心、区间问题 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技…...
 —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三))
【实战】一、Jest 前端自动化测试框架基础入门(三) —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三)
文章目录 一、Jest 前端自动化测试框架基础入门7.异步代码的测试方法8.Jest 中的钩子函数9.钩子函数的作用域 学习内容来源:Jest入门到TDD/BDD双实战_前端要学的测试课 相对原教程,我在学习开始时(2023.08)采用的是当前最新版本&a…...

信息学奥赛一本通1228:书架
1228:书架 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 18190 通过数: 10557 【题目描述】 John最近买了一个书架用来存放奶牛养殖书籍,但书架很快被存满了,只剩最顶层有空余。 John共有N�头奶牛(1≤N≤20,0001≤…...

红队打靶练习:GLASGOW SMILE: 1.1
目录 信息收集 1、arp 2、nmap 3、nikto 4、whatweb 目录探测 1、gobuster 2、dirsearch WEB web信息收集 /how_to.txt /joomla CMS利用 1、爆破后台 2、登录 3、反弹shell 提权 系统信息收集 rob用户登录 abner用户 penguin用户 get root flag 信息收集…...

网络安全的今年:量子、生成人工智能以及 LLM 和密码
尽管世界总是难以预测,但网络安全的几个强劲趋势表明未来几个月的发展充满希望和令人担忧。有一点是肯定的:2024 年将是非常重要且有趣的一年。 近年来,人工智能(AI)以令人难以置信的速度发展,其在网络安全…...

【FPGA】Verilog:奇偶校验位发生器 | 奇偶校验位校验器
目录 0x00 奇偶校验位发生器 0x01 奇偶校验位校验器 0x02 错误检测器和纠错器...

【心得】关于STM32中RTC的校准方法
最近看了一些关于RTC校准的帖子,发现很多人存在疑惑。正好最近我也在STM32中实现了RTC校准。发些心得。这些对老手来说有些罗索,但对新手有益处。 实现RTC 校准的核心之一是库文件Stm321f0x_bkp.c中的void BKP_SetRTCCalibrationValue (uint8_t Calibra…...

消息中间件面试篇
目录 消息中间件 RabbitMQ 消息不丢失 生产者确认机制 消息持久化 交换机持久化 队列持久化 消息持久化 消费者确认 消息重复消费 出现的场景 解决方案 每条消息设置一个唯一的标识id 幂等方案:【 分布式锁、数据库锁(悲观锁、乐观锁&#…...
)
【MySQL】-20 MySQL综合-6(MySQL创建数据表+MySQL修改数据表+MySQL删除数据表)
MySQL创建数据表MySQL修改数据表MySQL删除数据表 MySQL创建数据表基本语法在指定的数据库中创建表查看表结构 MySQL修改数据表基本语法添加字段修改字段数据类型删除字段修改字段名称修改表名 MySQL删除数据表基本语法删除表 MySQL创建数据表 在创建数据库之后,接下…...

别再只盯着CPU内存了!用Prometheus+Grafana打造你的K8S应用黄金监控仪表盘
从基础设施到业务价值:用PrometheusGrafana构建Kubernetes应用黄金监控体系 当Kubernetes集群中的Pod状态全部显示"Running"时,很多团队会误以为万事大吉。直到某天凌晨3点,客服系统被用户投诉淹没,才发现订单成功率已暴…...

2026降AI率工具红黑榜:降AIGC工具怎么选?照着用就行!
2026年论文降AI率工具竞争激烈,千笔AI、ThouPen、豆包凭借精准适配国内高校AI率检测规范成为红榜首选。黑榜需警惕低质免费工具、无正规检测对接、改写痕迹生硬的产品。选择时应综合考量(降AI效果 - 学术合规性 - 使用成本)三维模型ÿ…...

国产电池包传感监测芯片:从AFE设计到BMS系统实战解析
1. 项目概述:从“芯”守护,让每一度电都安全在电动汽车的心脏——动力电池包里,温度、电压、电流这些关键参数哪怕出现一丝一毫的异常,都可能从量变引发质变,最终导致热失控等严重安全事故。因此,对电池包内…...
)
YOLACT实战:在Windows 10/11上用RTX 3060显卡跑通实例分割(含CUDA 11.7配置)
YOLACT实战:在Windows 10/11上用RTX 3060显卡跑通实例分割(含CUDA 11.7配置) 当RTX 3060遇上实例分割,如何在Windows平台上避开那些深坑?去年用YOLACT完成工业质检项目时,发现大多数教程都假设用户使用Linu…...
)
告别环境冲突!用Miniconda3在Windows上为不同Python项目创建独立开发环境(保姆级图文)
告别Python环境冲突:Miniconda3在Windows下的高效开发环境管理实战 刚接手新项目的Python开发者小王遇到了一个典型问题:本地运行良好的Django 3.2项目,在同事电脑上却频频报错。经过排查,发现是Python环境版本不一致导致的依赖冲…...

从STM32转战合泰HT32F52352:手把手教你用GPTM定时器搞定四路舵机PWM控制
从STM32到HT32F52352的平滑迁移:GPTM定时器实现四路舵机PWM控制实战 对于习惯了STM32生态的开发者而言,初次接触合泰HT32系列MCU时往往面临两个挑战:如何快速理解新芯片的架构设计,以及如何将已有的STM32开发经验有效迁移。HT32F…...

3分钟学会在Windows上安装安卓应用:APK-Installer完整指南
3分钟学会在Windows上安装安卓应用:APK-Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,…...

Prompt核心原则与技巧
1. Prompt的本质Prompt是用户和模型之间的"接口"。设计好的Prompt就像把话说清楚——越清楚,模型越能给你想要的答案。类比:就像你请人帮忙做事:说"帮我处理一下" → 对方可能做错说"帮我把这封信装进信封ÿ…...

保姆级教程:用Wireshark抓包搞定Velodyne VLP-16激光雷达的IP配置与网络调试
从数据包到点云:Wireshark深度解析Velodyne VLP-16网络配置全流程 当你第一次拿到Velodyne VLP-16激光雷达时,那种兴奋感很快会被网络配置的挫败感取代——明明按照教程设置了IP,却始终ping不通设备,浏览器访问后台更是天方夜谭。…...

agent 学习路径解析 学习资源分享
文章目录 先给结论:你接下来不要优先读 GLM-4.5你对 agent 的轻视,有一半对,一半错关于 Claude Code 泄露:你应该学“架构收获”,不要沉迷“源码猎奇”你提到的 learn-claude-code 仓库:值得看,…...