Linux多线程[二]
引入知识
进程在线程内部执行是OS的系统调度单位。
内核中针对地址空间,有一种特殊的结构,VM_area_struct。这个用来控制虚拟内存中每个malloc等申请的空间,来区别每个malloc的是对应的堆区哪一段。OS可以做到资源的精细度划分。
对于磁盘上的exe本质上是一个文件,我们的可执行程序本来就是按照地址空间来划分的,可执行程序其实也按照了区域,被划分为以4kb为单位部分。物理内存也按照是4kb划分(软件层面的划分)。对于这么4kb的块我们也要管理起来(先描述在组织)。每个4kb我们把它叫做页帧。物理内存的4kb大小一端我们叫做页框。每次Io的时候我们就把页帧装到页框里面。虚拟内存有多少个地址(32位)2^32个。映射一定有key和value
物理内存和虚拟内存的映射关系因为物理内存是按照4字节划分的。如果每个4自己进行映射直接保存,页表压根保存不下,所以必须进行特殊的保存。
关于页表,有32位,前10位是一级页表,2^10=1024个映射关系,首先拿前10位对一级页表进行索引。找到的也不是真实物理地址,而是二级页表,11-20个比特位。对二级页表进行索引,找到数据在物理内存所在页的起始位置。然后通过起始位置进行便宜找到要访问的内容。最后12位保存的就是偏移量。这样子就可以把虚拟地址转化为物理地址。这样子就很好解决了空间不够的问题,通过一二级页表可以很好的找到对应的物理内存文件。
如何理解线程
每个进程都有自己的虚拟内存和页表,如果他创建子进程,子进程的的PCB test_struct也指向父进程的struct mm_struct.也就是说子进程有自己的pcb结构体,但是子进程公用父进程的struct mm_struct。创建的每个task_strcut就叫做线程。对于cpu来说只关心pcb一个pcb就是一个线程,cpu压根不管是线程还是进程。(linux特有的)为了管理线程也需要先描述再组织。

对于Linux上的线程和进程的区别,进程有自己的mm_struct。线程没有,线程是复用的。
既然这样子,那么我们之前的进程也需要重新理解一下,用户视角:进程=进程对应的代码和数据+内核数据结构(task_struct。。)这是我们之前理解的。内核视角:承担分配系统资源的基本实体。只有伸手向系统要资源的就被叫做进程。资源角度:之前,内部只有一个执行流的进程。现在:内部有多个执行流。这种情况叫单进程多线程。pcb我们按照现在的视角重新看下:task_strcut是进程内部的一个执行流。cpu在执行的时候压根不关心进程和线程只关心pcb结构体。进行和线程无所谓。那么既然这个是linux下的特殊处理方法。linux没有真正意义上的线程,他是和进程共用一套。linux不会提供进程接口,只提供了轻量级系统接口。于是在用户层实现了一层轻量级多线程方案,以库的形式提供给用户——pthread,原生线程库。
使用
功能:创建一个新的线程
#include<pthread.h>
原型 int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void*), void *arg);
参数 thread:返回线程ID
attr:设置线程的属性,attr为NULL表示使用默认属性
start_routine:是个函数地址,线程启动后要执行的函数
arg:传给线程启动函数的参数 返回值:成功返回0;失败返回错误码(将arg传递给void *(*start_routine) (void*))
示例代码
#include<iostream>
#include<pthread.h>
#include<string>
#include<sys/types.h>
#include<unistd.h>
#include<cstdio>
using namespace std;
void *threadrun(void *args)
{const string name=(char*)args;while(1){cout<<"name:"<<name<<"-----pid :"<<getpid()<<"\n"<<endl;sleep(1);}
}int main()
{pthread_t tid[5];char name[64];for(int i;i<5;i++){ snprintf(name,sizeof name,"%s-%d","thread",i);pthread_create(tid+i,nullptr,threadrun,(void*)name);sleep(1);//缓解传参的bug}//主线程 main中的是主进程while(1){cout<<"main thread pid::"<<getpid()<<endl;sleep(1);}}查看是否调用线程库

运行结果
 线程如何看待内部资源
线程如何看待内部资源
操作系统给线程分配资源,线程向进程申请资源,进程挂掉线程都挂掉。线程使用进程资源,很多东西他们都是共享的。
文件描述符表共享:一个线程打开文件fd=3那么下一个线程就是fd=4了
每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
函数处理方法,初始化,未初始化
当前工作目录
用户id和组id
但是也有不共享的
线程ID
一组寄存器(进程上下文)
栈
errno
信号屏蔽字
调度优先级
进程VS线程
线程切换成本更低,在进程内调度线程,地址空间不需要切换,页表不需要切换 。同时进程加载的时候有3级缓存。所以进程内部代码不需要重新加载。而切换cou需要重新加载。
线程不是越多越好,线程数量一般等于cpu的核心数,因为如果线程过多线程之间切换也需要时间。造成性能损失。
单进程类似于vfork
线程控制:
假设线程中有一个线程发送除0错误呢?导致进程整体退出。
进程等待
线程在运行的时候需要等待,会导致类似于僵尸进程的问题,造成内存泄漏。
功能:等待线程结束
原型int pthread_join(pthread_t thread, void **value_ptr);
参数thread:线程IDvalue_ptr:它指向一个指针,后者指向线程的返回值
返回值:成功返回0;失败返回错误码#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<cassert>
using namespace std;void *threadRun(void *args)
{int i=0;while(1){cout<<"args:"<<(char*)args<<"------runing"<<endl;sleep(1);if(i++==4){break;}}cout<<"子线程退出。。。。。"<<endl;
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,threadRun,(void*)"thread 1");int n=pthread_join(tid,nullptr);//默认会等待阻塞新线程退出assert(n==0);cout<<"子线程等待成功"<<endl;while(1){cout<<"main:"<<"------runing"<<endl;sleep(1);}
}运行结果

因为进程等待的问题,所以只能子进程结束后父进程再继续传参。
线程创建回调函数返回值可以返回自己想要的值强转就可以
return (void*)10;但是线程返回值压根返回给谁?谁等给谁——给主线程一般。那么主线程一般如何获取到。join函数的第二个参数。
void *ret =nullptr;//linux环境下开辟8个字节。int n=pthread_join(tid,(void**)&ret);//默认会等待阻塞新线程退出cout<<"返回值---:"<<(int)ret<<endl;线程异常
如何知道线程异常呢?
线程一旦异常就会全部崩溃,所以线程异常就没有什么意义了。不需要关系退出是否异常。
线程终止
exit??
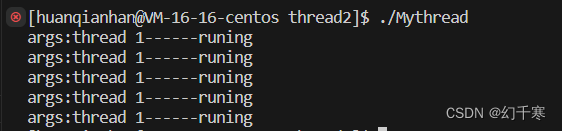
我们发现子进程执行之后,父进程剩下的代码都不执行了。整个个进程直接终止。 所以需要专门的函数。
功能:线程终止
原型
void pthread_exit(void *value_ptr);
参数
value_ptr:value_ptr不要指向一个局部变量。
返回值:无返回值,跟进程一样,线程结束的时候无法返回到它的调用者(自身)void *threadRun(void *args)
{int i=0;while(1){cout<<"args:"<<(char*)args<<"------runing"<<endl;sleep(1);if(i++==4){break;}}pthread_exit((void*)13);//exit(2);cout<<"子线程退出。。。。。"<<endl;return (void*)10;
}此外还有一种线程取消的方式
功能:取消一个执行中的线程
原型int pthread_cancel(pthread_t thread);
参数thread:线程ID
返回值:成功返回0;失败返回错误码pthread_t
线程id我们一般会想到LWP,一个整数。那么这个数我们可能有点好奇线程ID为什么这么大呢?那是因为,他表示线程的地址。因为我们用的不少linux自己创建的接口而是pthread的库。
在之前的内容中我们知道线程的栈是独立的,那么栈是在用户层还是内核层呢?用户层,操作系统执行线程的时候多个进程入栈出栈,很容易相互覆盖栈的数据,我们只能在用户层提供,进行管理区分。

库不仅仅可以提供操作方法,也可以做数据维护。所以线程库内还维护了每个线程的私有数据。其中就包括线程ID 局部存储,以及线程对应的栈结构。库映射到内存中是线性的,为了更快的找到对应的线程资源,就使用起始地址来当线程id。主线程使用内核区栈结构,其他线程使用共享区的栈结构。同时pthread_t pthread_self(void);函数可以获取线程id。
线程全局变量是共有的但是前面加入__thread 就每个thread线程都具有一个变量,不共享。这个就叫线程的局部存储。
进程分离
我们不想等待线程,想要线程执行完自动结束就需要分离线程

线程分离之后不能join,join之后会报错。
线程安全
线程互斥
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个 线程,其他线程无法获得这种变量。 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之 间的交互。 多个线程并发的操作共享变量,会带来一些问题。
多线程函数调度的时候很容易多个线程都调度同一个函数,很容易造成一个线程执行到一半准备返回结果,但是另一个线程开始执行对结果进行了处理之后,之前的线程返回结果覆盖率最新的结果。在并发访问的时候很容易导致时序不一致的问题。

cpu ticket判断的时候极有可能别的线程也ticket判断,会导致多个执行流进入执行代码。同时计算机支持多个线程并行,多个线程同时跑,多个执行流同时执行一段代码。这么都会导致结果错误。
在ticket>0和ticket--的时候都很大概率发生这样的问题,那么如何避免这样的问题产生呢?加锁保护mutex。
示例代码:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<cassert>
#include<cstdio>
using namespace std;
// pthread_mutex_t mu2x;//定义一把锁
pthread_mutex_t mu2x = PTHREAD_MUTEX_INITIALIZER; //完成锁的初始化 //静态全局变量int ticker =1000;void*threadrun(void* args)
{while(1){pthread_mutex_lock(&mu2x);//对线程完成枷锁if(ticker>0)//判断本质也是计算{usleep(1000);printf("%p : %s ----%d\n",pthread_self(),(char*)args,ticker);ticker--;pthread_mutex_unlock(&mu2x);//解锁}//解锁//在加锁和解锁之间的代码是临界区else{pthread_mutex_unlock(&mu2x);//解锁break;//如果这里break的话就会一直不释放锁}}
}//锁的初始化有2中方式
//方法一: pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER int main()
{pthread_t tid,tid2,tid3;pthread_create(&tid,nullptr,threadrun,(void*)"thread 1");pthread_create(&tid2,nullptr,threadrun,(void*)"thread 2");pthread_create(&tid3,nullptr,threadrun,(void*)"thread 3");pthread_join(tid,nullptr);pthread_join(tid2,nullptr);pthread_join(tid3,nullptr);}但是即便是加了锁也会出现一直情况,一个线程始终能抢到资源。

锁的初始化
静态初始化
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER 这种必须锁在全局。
动态初始化——可以在任意位置设置锁,但是不用必须释放
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t
*restrict attr);参数:mutex:要初始化的互斥量attr:NULLint pthread_mutex_destroy(pthread_mutex_t *mutex); //锁的动态分布pthread_mutex_t mux1;pthread_mutex_init(&mux1,nullptr);//动态分配初始化;/*************************/pthread_t tid,tid2,tid3;pthread_create(&tid,nullptr,threadrun,(void*)"thread 1");pthread_create(&tid2,nullptr,threadrun,(void*)"thread 2");pthread_create(&tid3,nullptr,threadrun,(void*)"thread 3");pthread_join(tid,nullptr);pthread_join(tid2,nullptr);pthread_join(tid3,nullptr);//释放锁pthread_mutex_destroy(&mux1);/***********************************************/动态分配一般卸载局部,那么如何将锁传递给回调函数呢? 通过定义结构体来传递结构体
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<cassert>
#include<cstdio>
#include<string>
using namespace std;
#define Thread_NUM 5
// pthread_mutex_t mu2x;//定义一把锁
//pthread_mutex_t mu2x = PTHREAD_MUTEX_INITIALIZER; //完成锁的初始化 //静态全局变量int ticker =1000;class Thread_date
{
public:Thread_date(const string&n,pthread_mutex_t *mux):tname(n),ptmax(mux){}
public:string tname;pthread_mutex_t* ptmax;};void*threadrun(void* args)
{Thread_date* td=(Thread_date*)args;while(1){pthread_mutex_lock(td->ptmax);//对线程完成枷锁if(ticker>0)//判断本质也是计算{
usleep(rand()%1500);printf("%p : %s ----%d\n",pthread_self(),td->tname.c_str(),ticker);ticker--;pthread_mutex_unlock(td->ptmax);//解锁}//解锁//在加锁和解锁之间的代码是临界区else{pthread_mutex_unlock(td->ptmax);//解锁break;//如果这里break的话就会一直不释放锁}usleep(rand()%1500);}
}//锁的初始化有2中方式
//方法一: pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER int main()
{//锁的动态分布pthread_mutex_t mux1;pthread_mutex_init(&mux1,nullptr);//动态分配初始化;/*************************/pthread_t tid[Thread_NUM];for(int i=0;i<Thread_NUM;i++){ string name="thread";name+=to_string(i+1);Thread_date *td =new Thread_date(name,&mux1);pthread_create(tid+i,nullptr,threadrun,(void*)td);}for(int i=0;i<Thread_NUM;i++){pthread_join(tid[i],nullptr);}//释放锁pthread_mutex_destroy(&mux1);/***********************************************/cout<<"总线程结束"<<endl;return 0;}那么加锁之后就是串行了吗?加锁之后在临界区是否会切换呢?以及原子性的体现。不会,就算被切换也是,你把锁带走了,其他的线程也无法申请锁进入临界区。保证了临界资源的一致性,,假设线程不申请锁直接访问临界区,这就编码错误了。对于没有锁的线程只关心2种情况:1.其他的线程 也没有持有锁。2.其他的线程也没有释放锁。
那么加锁就算串行执行了吗?
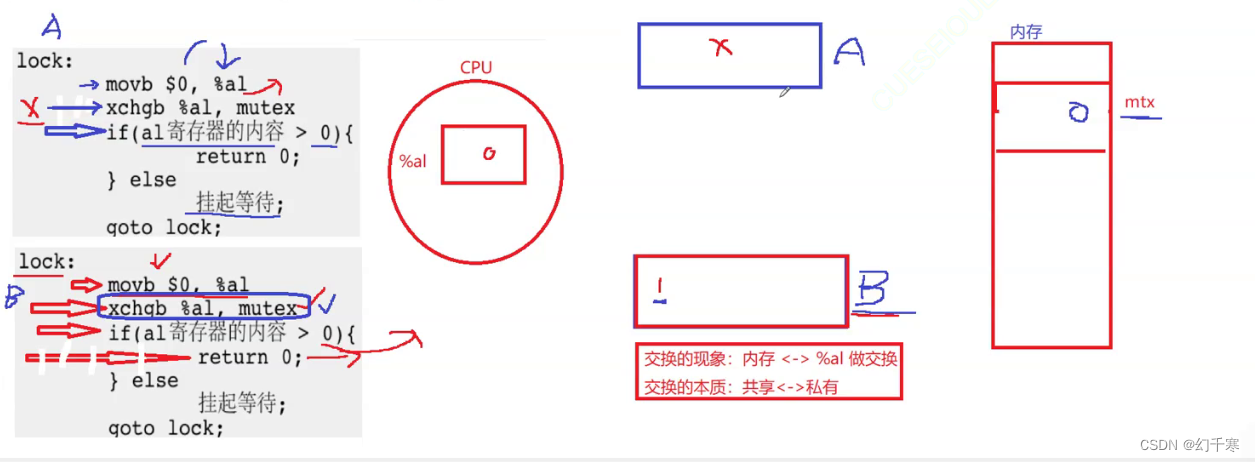
是的,执行临界区代码一定是串行的。要访问呢临界资源,每一个线程都必须申请锁,每一个线程都必须看到同一个锁&&访问锁,锁本身就算一种共享资源。那么锁怎么保证他的安全呢?必须保证锁是原子的。那么锁是如何实现的,原子性如何让保证?
站在汇编的角度,如果只有一条汇编指令,我们就认为是原子的。swap和exchange指令是以一条指令将内存和cpu数据进行交换。cpu内部有寄存器,cpu内部寄存器本质上是当前执行流的山下文,寄存器的空间是共享的,但是寄存器的内容是私有的,逻辑如下。

函数重入
一个函数被多个执行流同时进入,没有问题就是可重入函数,出问题的就算不可重入函数。之前的回调函数,加入锁之后就算可重入函数。
死锁
在用锁的时候不一定用了一把锁,使用了好几把锁,因为锁申请次序导致必须的线程互相申请对方锁的现象叫死锁。
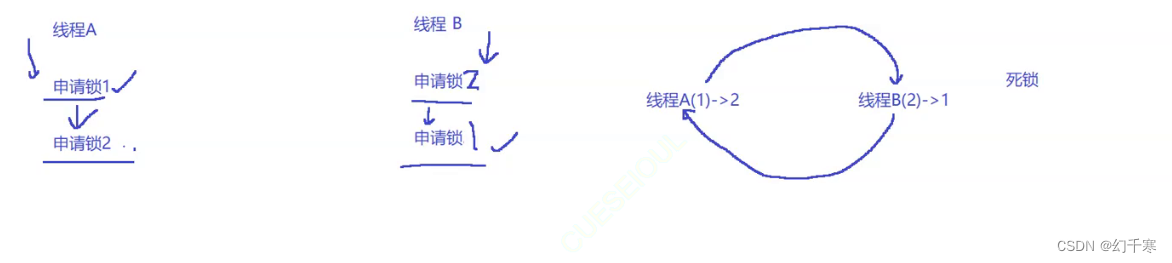
死锁的必要条件
互斥条件:一个资源每次只能被一个执行流使用
请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放
不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺
循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
避免死锁
破坏死锁的四个必要条件
加锁顺序一致
避免锁未释放的场景
资源一次性分配
相关文章:
Linux多线程[二]
引入知识 进程在线程内部执行是OS的系统调度单位。 内核中针对地址空间,有一种特殊的结构,VM_area_struct。这个用来控制虚拟内存中每个malloc等申请的空间,来区别每个malloc的是对应的堆区哪一段。OS可以做到资源的精细度划分。 对于磁盘…...

宿舍报修|宿舍报修小程序|基于微信小程序的宿舍报修系统的设计与实现(源码+数据库+文档)
宿舍报修小程序目录 目录 基于微信小程序的宿舍报修系统的设计与实现 一、前言 二、系统功能设计 三、系统实现 1、学生信息管理 2 维修人员管理 3、故障上报管理 4、论坛信息管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推…...

浅谈开源软件的影响力
目录 1. 技术发展推动者: 2. 社区生态构建者: 3. 经济模式创新者: 4. 全球合作促进者: 5. 安全性贡献者: 6. 教育与人才培养: 7. 总结来说 不是每个人都能做自己想做的事,成为自己想成为…...
)
C++的多态(Polymorphism)
C中的多态(Polymorphism)是面向对象编程的一个重要概念,它允许以不同的方式使用同一个接口来处理不同类型的对象。多态性可以通过函数重载、运算符重载和虚函数实现。 多态的基本概念是:通过基类的指针或引用,可以在运…...

coding持续集成构建环境自定义node版本
coding持续集成构建环境自定义node版本 解决方案 只需要在构建计划的编写过程中增加一个如下的 stage,具体 nodejs 版本下载地址可参考 https://nodejs.org/en/download/releases/ 这里。 stage(toggle Node.js version) {steps {sh rm -rf /usr/lib/node_modules…...

【Java程序设计】【C00252】基于Springboot的实习管理系统(有论文)
基于Springboot的实习管理系统(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 这是一个基于Springboot的实习管理系统 本系统分为前台功能模块、管理员功能模块、教师功能模块、学生功能模块以及实习单位功能模块。 前台功能模块…...
)
100条经典C语言题第一天(1-10)
准备复习一下C语言,刷一些和面试相关的问题。 请填写 bool, float, 指针变量 与 “零值”比较的if语句 A.Bool flag 与 “零值”比较的if语句 1为true 0为false 分析 这里的flag 是布尔类型的变量 标准…...
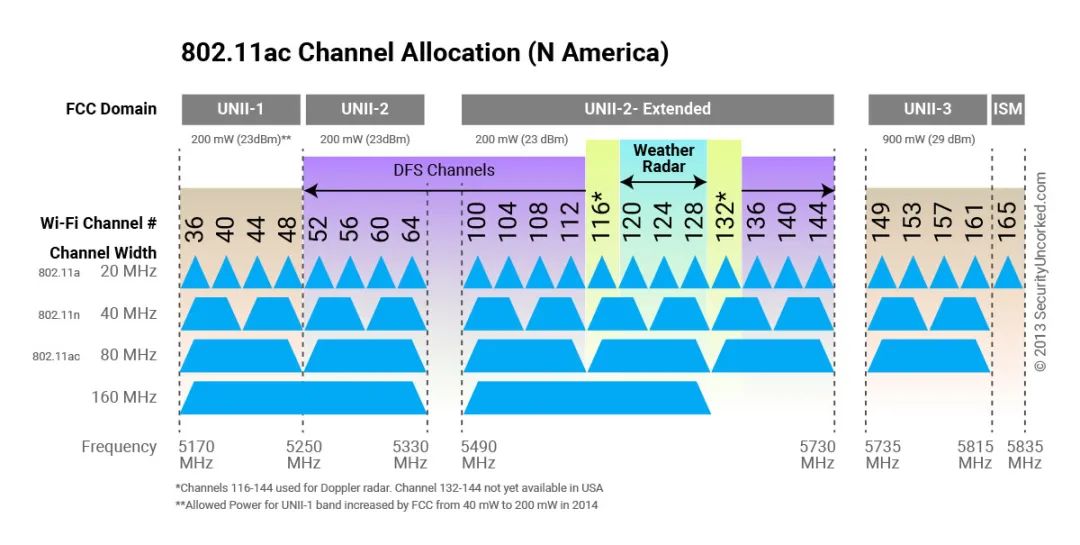
传输频宽是啥?对网速影响有多大?
频宽,即WIFI频道宽度,又称为WIFI信道宽度,是WiFi Channel width的缩写。从科学的定义来说,Wi-Fi频道宽度,是指Wi-Fi无线信号在频谱上所占用的带宽大小。它决定了Wi-Fi网络的数据传输速率和稳定性,一般有20M…...
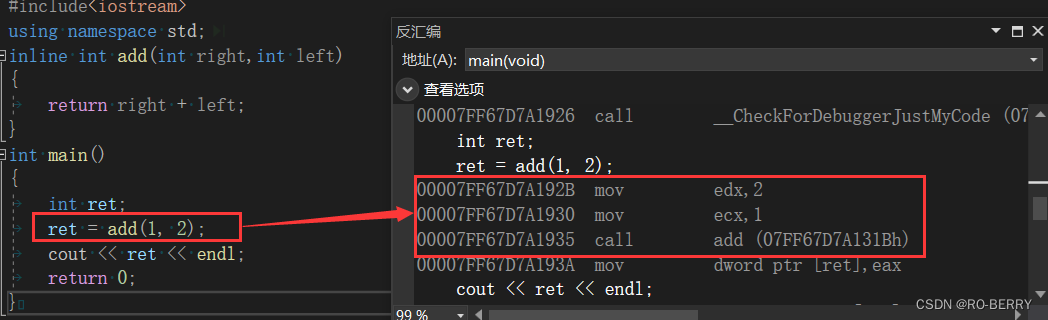
【C++函数探幽】内联函数inline
📙 作者简介 :RO-BERRY 📗 学习方向:致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持 目录 1. 前言2.概念3.特性…...

C#面:什么是Code-Behind技术
Code-Behind技术是一种在Web开发中常用的技术,它将前端页面与后端代码分离,使得前端页面的设计和后端代码的逻辑处理可以分别进行。在Code-Behind模式下,前端页面通常是一个标记语言(如HTML或ASPX),而后端代…...

【ES6】Promise
Promise 回调地狱 const fs require(fs);fs.readFile(./a.txt, utf-8, (err, data) > {if(err) throw err;console.log(data);fs.readFile(./b.txt, utf-8, (err, data) > {if(err) throw err;console.log(data);fs.readFile(./c.txt, utf-8, (err, data) > {if(er…...

Leetcode 3035. Maximum Palindromes After Operations
Leetcode 3035. Maximum Palindromes After Operations 1. 解题思路2. 代码实现 题目链接:3035. Maximum Palindromes After Operations 1. 解题思路 这一题的话因为可以任意交换,因此事实上要考察回文的最大个数,我们只需要统计所有单词当…...
SCM供应链系统:一文读懂,需要优化升级的看过来。
单一的供应链系统平时很少碰到,但是很多B端系统中都会集成供应链的功能,贝格前端工场尝试对SCM做一下扫盲性的介绍,如有管理系统界面是优化和升级的需求,欢迎私信我们,共同探讨。 一、定义与由来 SCM有时也可以指供应…...
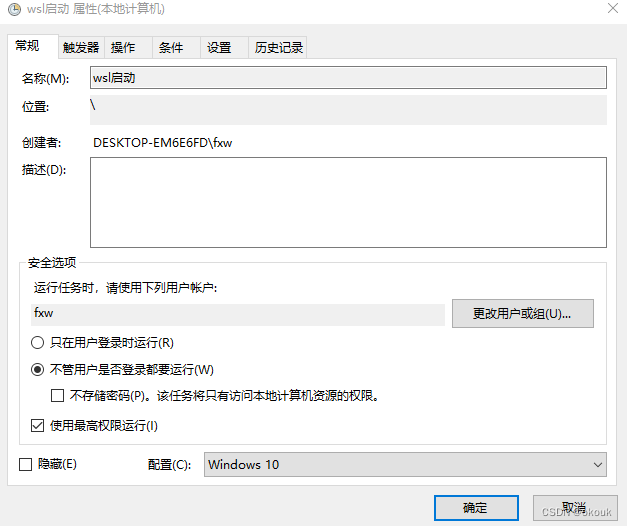
WSL外部SSH连接有效方法
前言 wsl作为windows下使用linux平台有效的手段之一,本文可以让win作为工作站,外部系统用来连接win下的wsl系统。 自动启动服务脚本 https://zhuanlan.zhihu.com/p/47733615 开机自启端口转发 wslname "Ubuntu-20.04" 要转发端口的Linux…...
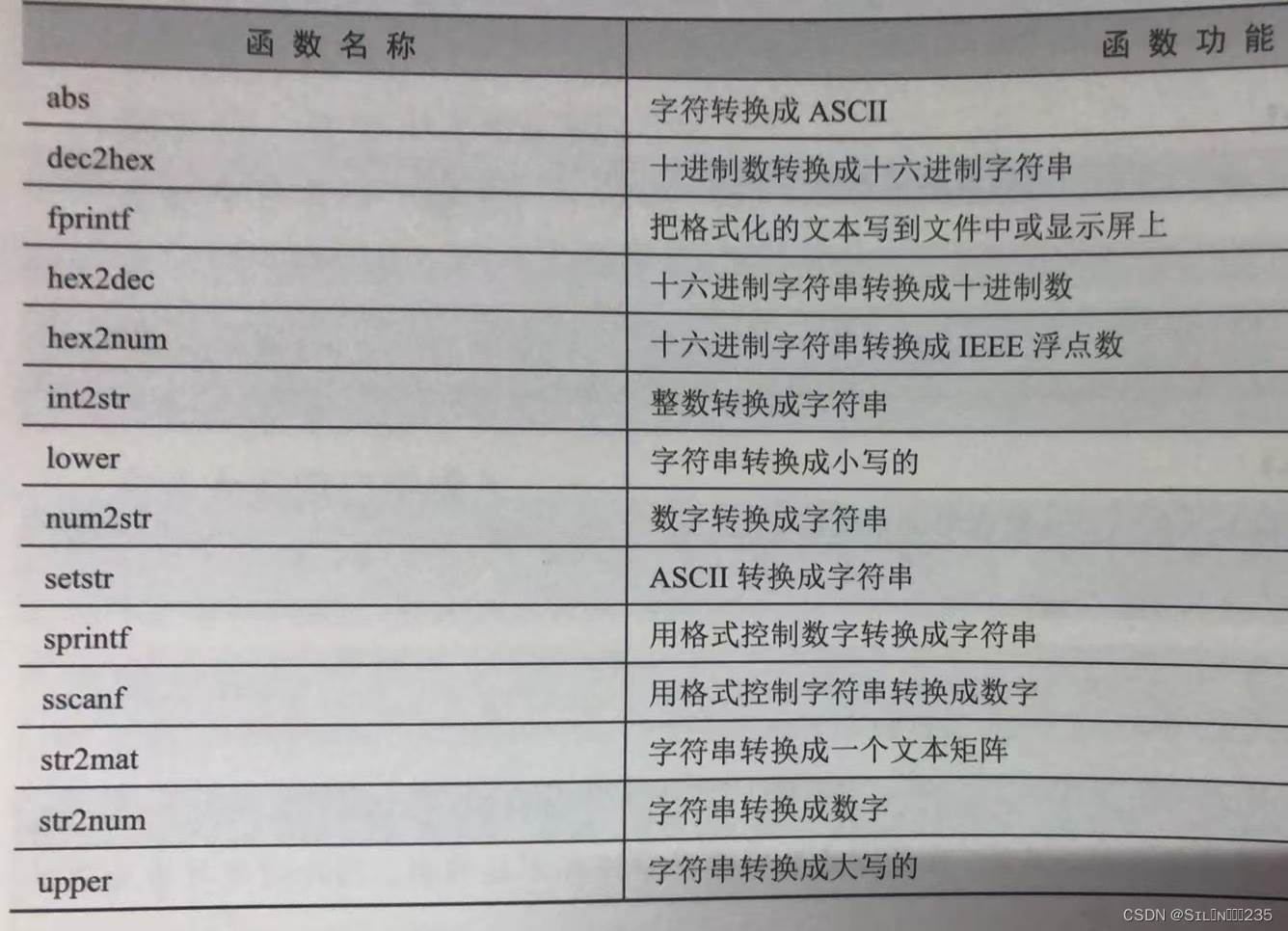
MATLAB 1:基础知识
MATLAB中的数据类型主要包括数值类型、逻辑类型、字符串、函数句柄、结构体和单元数组类型。这六种基本的数据类型都是按照数组形式存储和操作的。 MATLAB中还有两种用于高级交叉编程的数据类型,分别是用户自定义的面向对象的用户类类型和Java类类型。 1.1.1数值类…...

django安装使用
Django 是一个高级的 Python Web 框架,用于构建安全和可维护的网站。以下是如何安装和使用 Django 的步骤。 一:安装 确保你安装了 Python 在 Django 3.x 中,官方支持 Python 3.6, 3.7, 3.8, 3.9, 和 3.10。你可以使用 python --version 或…...
基于LightGBM的回归任务案例
在本文中,我们将学习先进的机器学习模型之一:Lightgbm。在对XGB模型进行了越来越多的改进以获得更好的性能之后,XGBoost是一种极限梯度提升机器,但通过lightgbm,我们可以在没有太多计算的情况下实现类似或更好的结果&a…...
CTFshow web(php文件上传155-158)
web155 老样子,还是那个后端检测。 知识点: auto_append_file 是 PHP 配置选项之一,在 PHP 脚本执行结束后自动追加执行指定的文件。 当 auto_append_file 配置被设置为一个文件路径时,PHP 将在执行完脚本文件的所有代码后&…...

Leetcode 53 最大子数组和
题意理解: 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 所以每个元素都有两个状态,是前一部分的延续࿰…...

【pandas 不同文件读取和存储】
文章目录 一、Pandas 文件读取和存储概览二、读取不同类型的文件1. CSV文件的读取与存储代码及解释: 2. Excel文件的读取与存储代码及解释: 3. JSON文件的读取与存储代码及解释: 4. SQL数据库的读取与存储代码及解释: 5. 其他格式…...
)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南(含清晰对比图)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南 在数字化与纸质化并行的学术工作流中,希腊字母的书写问题常常成为效率瓶颈。当你在深夜推导公式时,是否曾因手写θ与δ难以区分而被迫重新查阅资料?当你在整理课堂笔记时&#…...

2026年计算机专业就业现状,不想35岁被淘汰?网络安全或许是程序员的最佳转型方向!
计算机专业虽进入分化阶段,但网络安全人才缺口达300万,高端领域供不应求。高校扩招与市场需求脱节导致供需失衡,未来"计算机行业"的复合型人才更具竞争力。建议早做规划,构建"T型能力体系",掌握前…...

XUnity自动翻译器:打破游戏语言障碍的终极解决方案
XUnity自动翻译器:打破游戏语言障碍的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂外语游戏而烦恼吗?XUnity自动翻译器就是你需要的答案!这…...

基于XCKU060 FPGA的高速数据采集卡硬件架构与开发实践
1. 项目概述与核心价值最近在做一个高速数据采集与实时处理的项目,对市面上的FPGA加速卡做了一圈调研和测试。其中,青翼这款基于XCKU060 FPGA的4路SFP光纤数据处理板卡(型号PCIE734)给我留下了挺深的印象。它本质上是一张插在服务…...
)
LVGL事件处理实战:从按钮点击到滚动列表,手把手教你写交互代码(附避坑指南)
LVGL事件处理实战:从按钮点击到滚动列表,手把手教你写交互代码(附避坑指南) 在嵌入式GUI开发中,流畅的交互体验往往决定了产品的成败。LVGL作为轻量级通用图形库,其事件处理机制是构建动态界面的核心。本文…...

Windows 11终极优化指南:使用Win11Debloat实现专业级系统调校
Windows 11终极优化指南:使用Win11Debloat实现专业级系统调校 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

【Perplexity专利搜索黄金法则】:20年资深IP专家首度公开3大反直觉检索技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity专利搜索黄金法则的底层逻辑 Perplexity 作为基于语言模型的智能搜索工具,其在专利检索场景中的卓越表现并非源于简单关键词匹配,而是植根于对专利文本结构化语义、法…...

【GitHub热门工具】TikTokDownloader深度体验:从零到一的抖音/TikTok视频下载实战
1. 为什么我们需要TikTokDownloader? 最近在社交媒体上看到一个超有趣的视频,想保存下来反复观看或者分享给朋友,却发现平台没有提供下载按钮?这种场景相信很多人都遇到过。TikTokDownloader就是为了解决这个痛点而生的开源工具&a…...

serverless-http 与主流框架兼容性测试:Express、Koa、Hapi、Fastify 全面对比
serverless-http 与主流框架兼容性测试:Express、Koa、Hapi、Fastify 全面对比 【免费下载链接】serverless-http Use your existing middleware framework (e.g. Express, Koa) in AWS Lambda 🎉 项目地址: https://gitcode.com/gh_mirrors/se/server…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...