prometheus
文章目录
- 一、Prometheus简介
- 什么是Prometheus?
- Prometheus的优势
- Prometheus的组件、架构
- Prometheus适用于什么场景
- Prometheus不适合什么场景
- 二、相关概念
- 数据模型
- 指标名称和标签
- 样本
- 表示方式
- 指标类型
- Counter计数器
- Gauge仪表盘
- Histogram直方图
- Summary摘要
- Jobs和Instances
- 三、Prometheus快速开始
- 四、Exporter
- 五、服务发现
一、Prometheus简介
什么是Prometheus?
Prometheus是由前 Google 工程师从 2012 年开始在 Soundcloud以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入CNCF基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。
Prometheus的优势
Prometheus 的主要优势有:
- 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型
- 强大的查询语言 PromQL
- 不依赖分布式存储;单个服务节点具有自治能力。
- 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
- 也可以通过中间网关来推送时间序列数据
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图表和仪表盘。
Prometheus的组件、架构
Prometheus 的整体架构以及生态系统组件如下图所示:

Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana或者其他工具来实现监控数据的可视化。
- Prometheus server是Prometheus架构中的核心组件,基于go语言编写而成,无第三方依赖关系,可以独立部署在物理服务器上、云主机、Docker容器内。主要用于收集每个目标数据,并存储为时间序列数据,对外可提供数据查询支持和告警规则配置管理。
- Prometheus服务器可以对监控目标进行静态配置管理或者动态配置管理,它将监控采集到的数据按照时间序列存储在本地磁盘的时序数据库中(当然也支持远程存储),自身对外提供了自定义的PromQL语言,可以对数据进行查询和分析
- Client Library是用于检测应用程序代码的客户端库。在监控服务之前,需要向客户端库代码添加检测实现Prometheus中metric的类型。
- Exporter(数据采集)用于输出被监控组件信息的HTTP接口统称为Exporter(导出器)。目前互联网公司常用的组件大部分都有Expoter供 直接使用,比如Nginx、MySQL、linux系统信息等。
- Pushgateway是指用于支持短期临时或批量计划任务工作的汇聚节点。主要用于短期的job,此类存在的job时间较短,可能在Prometheus来pull之前就自动消失了。所以针对这类job,设计成可以直接向Pushgateway推送metric,这样Prometheus服务器端便可以定时去Pushgateway拉去metric
- Pushgateway是prometheus的一个组件,prometheus server默认是通过exporter主动获取数据(默认采取pull拉取数据),pushgateway则是通过被动方式推送数据到prometheusserver,用户可以写一些自定义的监控脚本把需要监控的数据发送给pushgateway, 然后pushgateway再把数据发送给Prometheus server
- 总结就是pushgateway是普罗米修斯的一个组件,是通过被动的方式将数据上传至普罗米修斯。这个可以解决不在一个网段的问题
- Alertmanager主要用于处理Prometheus服务器端发送的alerts信息,对其去除重数据、分组并路由到正确的接收方式,发出告警,支持丰富的告警方式。
- Service Discovery:动态发现待监控的target,从而完成监控配置的重要组件,在容器环境中尤为重要,该组件目前由Prometheus Server内建支持
Prometheus适用于什么场景
Prometheus适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务的监控,在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个Prometheus Server都是相互独立的,不依赖于网络存储或者其他远程服务。当基础架构出现问题时,你可以通过Prometheus快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus不适合什么场景
Prometheus非常重视可靠性,即使在出现故障的情况下,你也可以随时统计有关系统的可用系统信息。如果你需要百分之百的准确度,例如按请求数量计费,那么Prometheus可能不太适合你,因为它收集的数据可能不够详细完整精确。
二、相关概念
数据模型
Prometheus所有采集的监控数据均以指标的形式保存在内置的时间序列数据库当中(TSDB):属于同一指标名称、同一标签集合的、有时间戳标记的数据流。除了存储的时间序列,Prometheus还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
指标名称和标签
每一条时间序列由指标名称(Metric Name)以及一组标签(键值对)唯一标识。其中指标的名称(Metric Name)可以反映被监控样本的含义(例如,http_request_total可以看出来表示当前系统接收到的http请求总量),指标名称只能由ASCII字符、数字、下划线以及冒号组成,同时必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]* 。
注意
冒号用来表示用户自定义的记录规则,不能在 exporter 中或监控对象直接暴露的指标中使用冒号来定义指标名称。
通过使用标签,Prometheus开启了强大的多维数据模型:对于相同的指标名称,通过不同标签列表的集合,会形成特定的度量维度实例(例如,所有包含度量名称为 /api/tracks 的 http 请求,打上method=POST 的标签,就会形成具体的 http 请求)。查询语言在这些指标和标签列表的基础上进行过滤和聚合,改变任何度量指标上的任何标签值(包括添加或删除指标),都会创建新的时间序列。
标签的名称只能由ASCII字符、数字、以及下划线组成并满足正则表达式 [a-zA-Z_][a-zA-Z0-9_]* 。其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode 编码的字符。
样本
在时间序列中的每一个点称为样本,样本由以下三部分组成:
- 指标(metric):指标名称和描述当前样本特征的labelset;
- 时间戳:一个精确到时间毫秒的时间戳
- 样本值:一个浮点型数据表示当前样本的值
表示方式
通过如下表示方式表示指定名称和指定标签集合的时间序列
<metric name>{<label name>=<label value>, ...}
例如,指标名称为 api_http_requests_total ,标签为 method=“POST” 和 handler="/messages"的时间序列可以表示为:
api_http_requests_total{method="POST", handler="/messages"}
指标类型
Prometheus的客户端库中提供了四种核心的指标类型。但这些类型只是在客户端库(客户端可以根据不同的数据类型调用不同的api接口)和在线协议中,实际在Prometheus Server中并不对指标类型进行区分,而是简单地把这些指标统一视为无类型的时间序列
Counter计数器
Counter类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。例如,你可以使用counter类型的指标表示服务请求总数、已经完成的任务数、错误发生的次数等。
counter类型数据可以让用户方便的了解事件发生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如HTTP应用请求量来进行说明:
//通过rate()函数获取HTTP请求量的增长率
rate(http_requests_total[5m])
//查询当前系统中,访问量前10的HTTP地址
topk(10, http_requests_total)
Gauge仪表盘
Gauge类型代表一种样本数据可以任意变化的指标,即可增可减。Gauge通常用于像温度或者内存使用率这种指标数据,也可以表示能随时请求增加会减少的总数,例如当前并发请求的数量。

对于Gauge类型的监控指标,通过PromQL内置的函数delta()可以获取样本在一段时间内的变化情况,例如,计算cpu温度在两小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以通过PromQL内置函数predict_linear()基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于两小时的样本数据,来预测主机可用磁盘空间在4个小时之后的剩余情况
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
Histogram直方图
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如cpu的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统api调用的平均响应时间为例:如果大多数api请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5秒,那么就会导致某些web页面的响应落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在0-10ms之间的请求数有多少而10-20ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标我们可以快速了解监控样本的分布情况。

Histogram在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
Histogram类型的样本会提供三种指标(假设指标名称为):
- 样本的值分布在 bucket 中的数量,命名为
<basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
// 在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
// 在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0
// 在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0
// 在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0- 所有样本值的大小总和,命名为
<basename>_sum。
// 实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001
- 样本总数,命名为
<basename>_count。值和<basename>_bucket{le="+Inf"}相同。
// 实际含义: 当前一共发生了 2 次 http 请求io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的采样点是包含前面的采样点的,假设 xxx_bucket{...,le="0.01"} 的值为 10,而xxx_bucket{...,le="0.05"} 的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 10 ms 的,其余 20 个采样点的响应时间是介于 10 ms 和 50 ms 之间的。
Summary摘要
Summary即概率图,类似于Histogram,常用于跟踪与时间相关的数据。典型的应用包括请求持续时间、响应大小等。Summary同样提供样本的count和sum功能;还提供quantiles功能,可以按百分比划分跟踪结果,例如,quantile取值0.95,表示取样本里的95%数据。Histogram需要通过<basename*>*bucket计算quantile,而Summary直接存储了quantile的值。
Jobs和Instances
在Prometheus中,任何被采集的目标,即每一个暴露监控样本数据的HTTP服务都称为一个实例instance,通常对应于单个进程。而具有相同采集目的实例集合称为作业job。
三、Prometheus快速开始
四、Exporter
五、服务发现
相关文章:
prometheus
文章目录 一、Prometheus简介什么是Prometheus?Prometheus的优势Prometheus的组件、架构Prometheus适用于什么场景Prometheus不适合什么场景 二、相关概念数据模型指标名称和标签样本表示方式 指标类型Counter计数器Gauge仪表盘Histogram直方图Summary摘要 Jobs和In…...

Vi 和 Vim 编辑器
Vi 和 Vim 编辑器 vi 和 vim 的基本介绍 Linux 系统会内置 vi 文本编辑器 Vim 具有程序编辑的能力,可以看做是 Vi 的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。 代码补完、编译及错误跳转等方便编程的功能特别丰富&…...
算法沉淀——队列+宽度优先搜索(BFS)(leetcode真题剖析)
算法沉淀——队列宽度优先搜索(BFS) 01.N 叉树的层序遍历02.二叉树的锯齿形层序遍历03.二叉树最大宽度04.在每个树行中找最大值 队列 宽度优先搜索算法(Queue BFS)是一种常用于图的遍历的算法,特别适用于求解最短路径…...
编辑器的新选择(基本不用配置)
Cline 不用看网上那些教程Cline几乎不用配置。 点击设置直接选择Chinese, C直接在选择就行了。 Cline是一个很好的编辑器,有很多懒人必备的功能。 Lightly 这是一个根本不用配置的C编辑器。 旁边有目录,而且配色也很好,语言标准可以自己…...

算法沉淀——栈(leetcode真题剖析)
算法沉淀——栈 01.删除字符串中的所有相邻重复项02.比较含退格的字符串03.基本计算器 II04.字符串解码05.验证栈序列 栈(Stack)是一种基于先进后出(Last In, First Out,LIFO)原则的数据结构。栈具有两个主要的操作&am…...

耳机壳UV树脂制作私模定制耳塞需要注意什么问题?
制作私模定制耳塞需要注意以下问题: 耳模制作:获取准确的耳模是制作私模定制耳塞的关键步骤。需要使用合适的材料和方法,确保耳模的准确性和稳定性。材料选择:选择合适的UV树脂和其它相关材料,确保它们的质量和性能符…...

easyx搭建项目-永七大作战(割草游戏)
永七大作战 游戏介绍: 永七大作战 游戏代码链接:永七大作战 提取码:ABCD 不想水文了,直接献出源码,表示我的诚意...

nginx命名location跳转的模块上下文继承
目录 1. 缘起2. 解决方案2.1 保留指定模块的上下文信息2.2 获取指定模块的上下文信息2.3 设置指定模块的上下文信息2.4 设置模块上下文是否需要继承标记2.5 对openrety lua代码的支持 1. 缘起 nginx提供了非常棒的功能,命名location,如文章nginx的locati…...
)
洛谷 P2678 [NOIP2015 提高组] 跳石头 (Java)
洛谷 P2678 [NOIP2015 提高组] 跳石头 (Java) 传送门:P2678 [NOIP2015 提高组] 跳石头 题目: [NOIP2015 提高组] 跳石头 题目背景 NOIP2015 Day2T1 题目描述 一年一度的“跳石头”比赛又要开始了! 这项比赛将在一条笔直的河道中进行&…...
第2讲投票系统后端架构搭建
创建项目时,随机选择一个,后面会生成配置properties文件 生成文件 maven-3.3.3 设置阿里云镜像 <?xml version"1.0" encoding"UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more cont…...
Flask 入门7:使用 Flask-Moment 本地化日期和时间
如果Web应用的用户来自世界各地,那么处理日期和时间可不是一个简单的任务。服务器需要统一时间单位,这和用户所在的地理位置无关,所以一般使用协调世界时(UTC)。不过用户看到 UTC 格式的时间会感到困惑,他们…...

FileZilla Server 1.8.1内网搭建
配置环境服务器服务器下载服务器配置服务器配置 Server - ConfigureServer Listeners - Port 协议设置 Protocols settingsFTP and FTP over TLS(FTPS) Rights management(权利管理)Users(用户) 客户端建立连接 配置环境 服务器处于局域网内: 客户端 < -访问- > 公网 &l…...
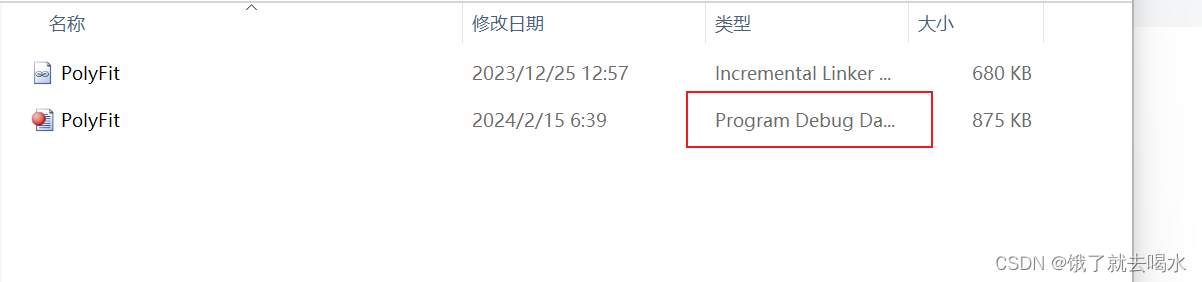
C++LNK1207中的 PDB 格式不兼容;请删除并重新生成
在打开别人发的C文件时,可能出现该报错 解决办法 打开资源管理器,找到原来的路径 进入Debug, 找到对应的PDB文件删除即可。...

小白学习Halcon100例:如何利用动态阈值分割图像进行PCB印刷缺陷检测?
文章目录 *读入图片*关闭所有窗口*获取图片尺寸*根据图片尺寸打开一个窗口*在窗口中显示图片* 缺陷检测开始 ...*1.开运算 使用选定的遮罩执行灰度值开运算。*2.闭运算 使用选定的遮罩执行灰度值关闭运算*3.动态阈值分割 使用局部阈值分割图像显示结果*显示原图*设置颜色为红色…...
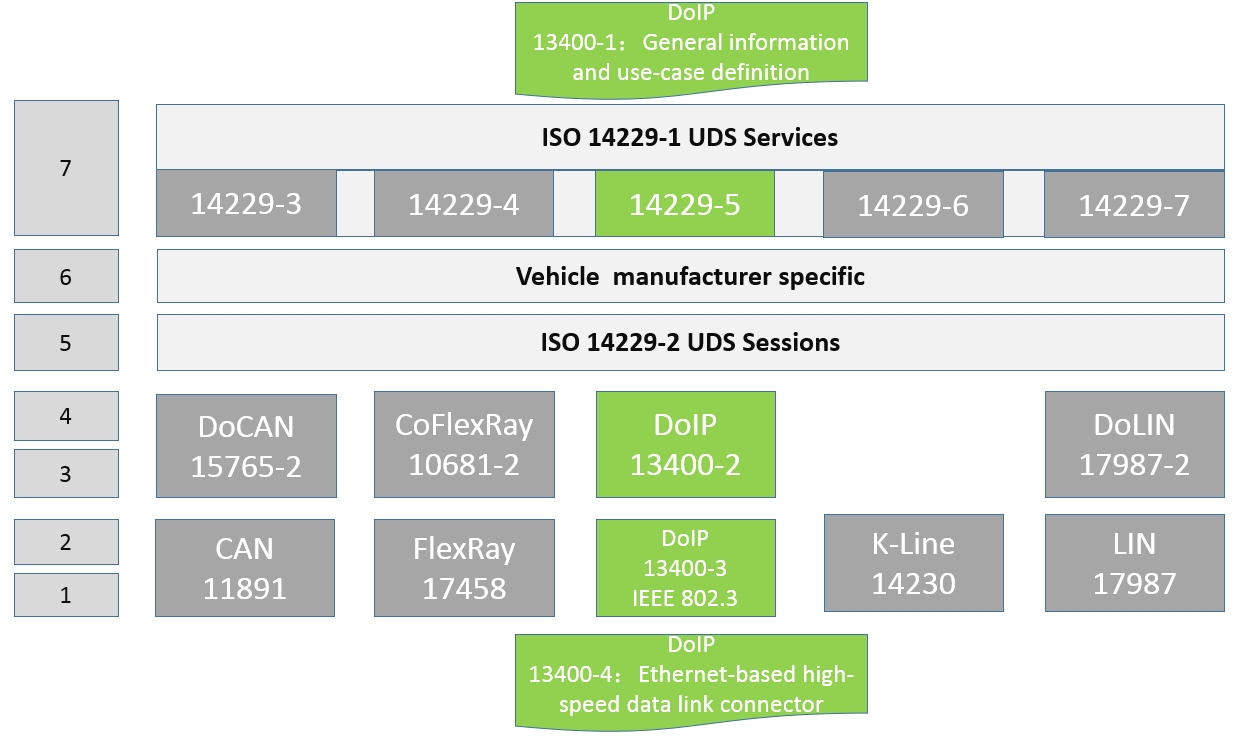
车载诊断协议DoIP系列 —— 车载以太网诊断需求规范(网关、路由)
车载诊断协议DoIP系列 —— 车载以太网诊断需求规范(网关、路由) 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师(Wechat:gongkenan2013)。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 本就是小人物,输了就是输了,不要在意别人怎么看自…...

面试官:介绍一下MVC框架
前言 大家好,我是chowley,MVC相信大家都听说过,今天我就记录一下我心中的MVC框架 MVC(Model-View-Controller)是一种软件设计模式,用于将应用程序分为三个核心部分:模型(Model&…...

C++ new 和 malloc 的区别?
相关系列文章 C内存分配策略-CSDN博客 目录 1.引言 2.区别 2.1.申请的内存分配区域 2.2.类型安全和自动大小计算 2.3.构造函数和析构函数的调用 2.4.异常处理 2.5.配对简便性 2.6.new 的重载 2.7.关键字和操作符 3.总结 1.引言 new 和 delete 在 C 中被引入…...
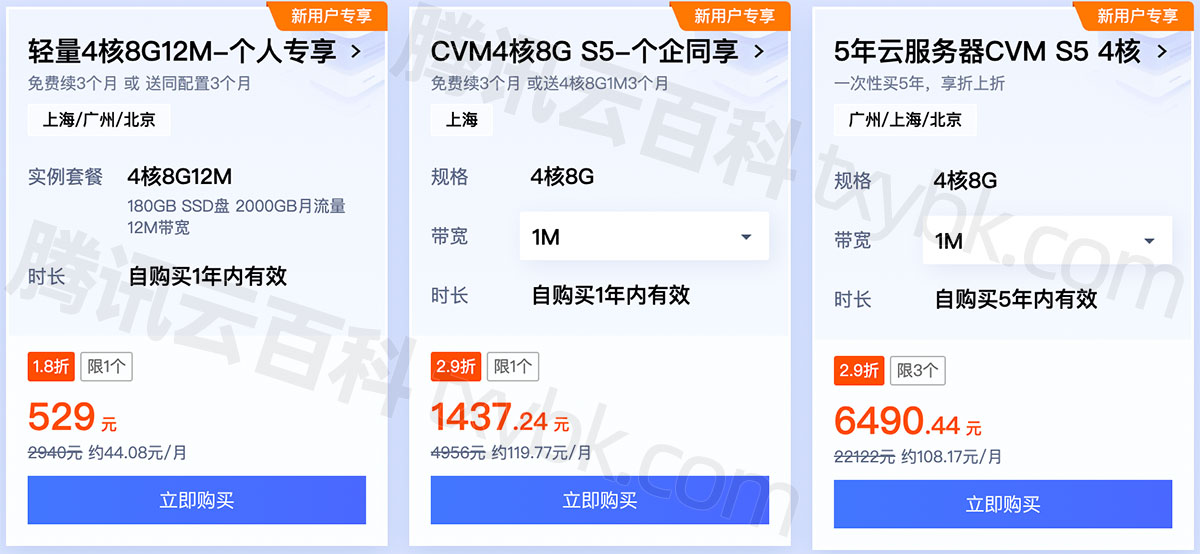
腾讯云4核8G服务器多少钱?
腾讯云4核8G服务器多少钱?轻量应用服务器4核8G12M带宽一年446元、646元15个月,云服务器CVM标准型S5实例4核8G配置价格15个月1437.3元,5年6490.44元,标准型SA2服务器1444.8元一年,在txy.wiki可以查询详细配置和精准报价…...

独孤思维:看到副业坚持4年,我震惊了
01 新人写作,不要写纯理论的东西,也不要写自我高潮的内容。 都写点接地气,多实操的内容。 比如,独孤现在每一篇短文写作,都会引入一个案例。 这样,对于很多读者来说,更好理解,能…...
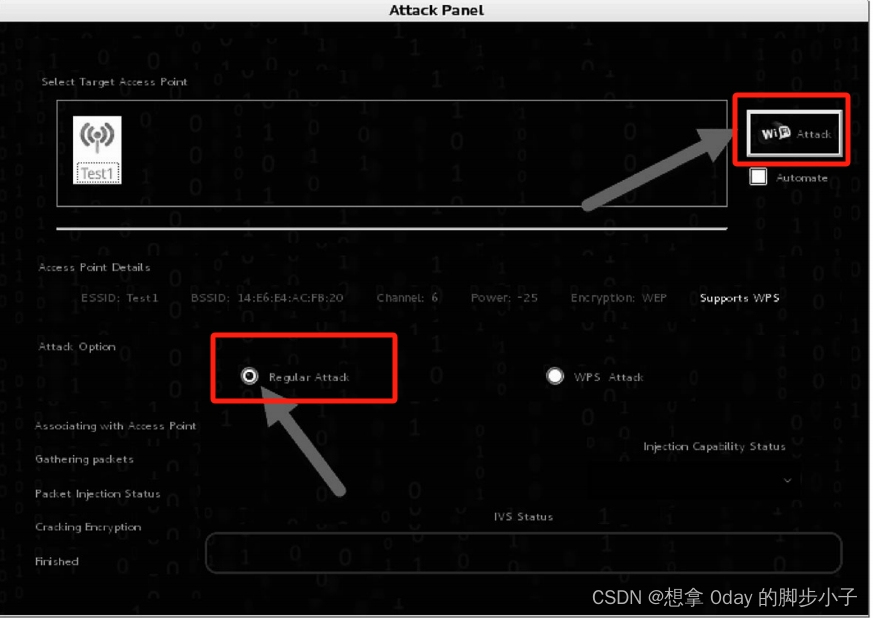
kali无线渗透之wps加密模式和破解12
WPS(Wi-Fi Protected Setup,Wi-Fi保护设置)是由Wi-Fi联盟推出的全新Wi-Fi安全防护设定标准。该标准推出的主要原因是为了解决长久以来无线网络加密认证设定的步骤过于繁杂之弊病,使用者往往会因为步骤太过麻烦,以致干脆不做任何加密安全设定&…...

别光顾着写EXP:复盘BUUCTF warmup_csaw_2016,聊聊PWN题里的‘信息泄露’与安全编程
从CTF漏洞利用到安全编程:深入解析信息泄露与防御实践 引言 在网络安全竞赛和实际系统安全中,信息泄露往往成为攻击者突破防御的第一块敲门砖。2016年CSAW CTF的warmup题目虽然看似简单,却完美展示了这类漏洞的典型模式——程序不仅存在栈溢出…...

骁龙855深度解析:5G基带集成与移动芯片架构演进
1. 从爆料到现实:骁龙855的早期信息拼图2018年初,当搭载骁龙845的手机才刚刚在市场上崭露头角时,关于其继任者的传闻就已经开始流传。对于像我这样长期关注移动芯片发展的从业者来说,每一代旗舰SoC的迭代节奏都像是一场精心编排的…...
)
CentOS 7.9上5分钟搞定openGauss极简版安装(附防火墙和权限避坑指南)
CentOS 7.9极速部署openGauss:5分钟实战与深度避坑手册 在数据库技术快速迭代的今天,openGauss作为企业级开源数据库的佼佼者,正受到越来越多开发者和运维团队的青睐。本文将带你在CentOS 7.9系统上,用最短时间完成openGauss极简版…...

ToastFish:终极Windows通知栏摸鱼背单词神器,上班族必备的隐蔽学习工具
ToastFish:终极Windows通知栏摸鱼背单词神器,上班族必备的隐蔽学习工具 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish 你是否厌倦了枯燥的背单词软件?Toas…...

Claude Mythos出笼!AI猛兽秒破人类一年无解漏洞,GPT-5.5直接被按在地上摩擦
前言各位码农老铁、安全圈大佬、以及正在用CtrlC/V续命的程序员朋友们,请放下你手里的咖啡——别洒了,因为接下来的消息,可能会让你惊得连键盘都按歪!最近AI圈炸了锅,不是因为谁又调参调出了花,而是Anthrop…...

Hotkey Detective:终极Windows热键冲突检测指南,快速找出“按键劫持“元凶
Hotkey Detective:终极Windows热键冲突检测指南,快速找出"按键劫持"元凶 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mir…...

JetBrains IDE试用期重置插件:简单三步恢复30天完整功能
JetBrains IDE试用期重置插件:简单三步恢复30天完整功能 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?ide-eval-resetter插件是你需要的终极解决…...

5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南
5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...

人类的自然关系与AI的形式化关系
“人类的自然关系”与“AI的形式化关系”是理解下一代人机环境系统智能的两个核心哲学维度。它们分别代表了智能系统在物理世界中的生存根基与在数字世界中的运行逻辑。我们可以从以下三个层面来深度解析这两者的区别与融合:人类的自然关系:从“征服掠夺…...

实测 DeepSeek-V4 接入 Hermes:一句话爬取几十个网页,真的丝滑!
你好,我是郭震OpenClaw龙虾使用有一段时间了,体感很好,即便使用本地模型,如Qwen3.5:9B这样的模型,养虾Token自由,回复也比较丝滑。如下所示,轻松生成HTML风格的文件结构树:也能轻松生…...