心法利器[107] onnx和tensorRT的bert加速方案记录
心法利器
本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。
2023年新一版的文章合集已经发布,获取方式看这里:又添十万字-CS的陋室2023年文章合集来袭,更有历史文章合集,欢迎下载。
往期回顾
心法利器[102] | 大模型落地应用架构的一种模式
心法利器[103] | 大模型bad case修复方案思考
心法利器[104] | 基础RAG-向量检索模块(含代码)
心法利器[105] 基础RAG-大模型和中控模块代码(含代码)
心法利器[106] 基础RAG-调优方案
假期想着补点遗漏的知识,所以选择了模型加速这块的工作,这块我的深度肯定是不够的,不过尝试动手做做实践收获还是不小,而且形成一些自己需要的组件还是挺有用的,所以记录一下。
目录:
加速整体思路。
环境和加速前准备。
onnx加速。
tensorRT加速。
速度测试。
这里的很多代码,都有参考这篇文章,我特别摆在这里:https://blog.csdn.net/m0_37576959/article/details/127123186,感谢社区大佬的贡献。
加速整体思路
现在其实已经有大量的工具可以用来进行加速,早在bert是主流的时代,就已经有研究很多有关的技术了。今天所介绍的onnx和tensorRT也都是这个时代的产物,后续成为这个时代的主流和代表性方案,而且随着逐步迭代,他们的封装也逐步变得简单,让我们使用的难度也变低了不少。
目前这两者的加速思路其实也比较类似,即主要分为两块:
模型的重新编译,使之转化为更适用于推理的格式,并将其进行保存。
加载保存的模型,并用其进行推理。
因此,我们核心需要做的,就是上面两步的开发。
环境和加速前准备
无论是onnx和tensorrt,因为加速依赖底层硬件和操作系统,所以环境配置成了繁杂但不可绕开的工作,此处我先把我目前的环境列举出来,给大家提供参考:
windows11,16G内存,i9-13900HX,NVIDIA GeForce RTX 4070 Laptop GPU(显存8G专用+8G共享)。
CUDA Version: 12.3,CUDNN:cudnn-windows-x86_64-8.9.6.50_cuda12,python:3.9.13。
torch==2.1.2+cu121,transformers==4.33.2
onnx==1.15.0,onnxruntime==1.16.3,onnxruntime-gpu==1.17.0,基本直接pip install即可。
tensorRT:tensorrt-8.6.1.6.windows10.x86_64.cuda-12.0,tensorrt==8.6.1。
tensorrt环境配置,可以参考这篇文章:https://blog.csdn.net/KRISNAT/article/details/130789078,核心流程如下:
从NVIDIA官网上,找到自己合适的版本解压。
配置好环境变量,同时有些文件要复制到cuda内。
找到合适的python whl包,进行安装。
环境配置好了,肯定就还需要有原料了,即需要加速的模型和原始推理方案,这里我选择的是心法利器[104] | 基础RAG-向量检索模块(含代码)中提到的simcse模型。原始的加载和推理是这样的:
import torch
import torch.nn as nn
import torch.nn.functional as F
from loguru import logger
from tqdm import tqdm
from transformers import BertConfig, BertModel, BertTokenizerclass SimcseModel(nn.Module):# https://blog.csdn.net/qq_44193969/article/details/126981581def __init__(self, pretrained_bert_path, pooling="cls") -> None:super(SimcseModel, self).__init__()self.pretrained_bert_path = pretrained_bert_pathself.config = BertConfig.from_pretrained(self.pretrained_bert_path)self.model = BertModel.from_pretrained(self.pretrained_bert_path, config=self.config)self.model.eval()# self.model = Noneself.pooling = poolingdef forward(self, input_ids, attention_mask, token_type_ids):out = self.model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)return out.last_hidden_state[:, 0]class VectorizeModel:def __init__(self, ptm_model_path, device = "cpu") -> None:self.tokenizer = BertTokenizer.from_pretrained(ptm_model_path)self.model = SimcseModel(pretrained_bert_path=ptm_model_path, pooling="cls")self.model.eval()# self.DEVICE = torch.device('cuda' if torch.cuda.is_available() else "cpu")self.DEVICE = devicelogger.info(device)self.model.to(self.DEVICE)self.pdist = nn.PairwiseDistance(2)def predict_vec(self,query):q_id = self.tokenizer(query, max_length = 200, truncation=True, padding="max_length", return_tensors='pt')with torch.no_grad():q_id_input_ids = q_id["input_ids"].squeeze(1).to(self.DEVICE)q_id_attention_mask = q_id["attention_mask"].squeeze(1).to(self.DEVICE)q_id_token_type_ids = q_id["token_type_ids"].squeeze(1).to(self.DEVICE)q_id_pred = self.model(q_id_input_ids, q_id_attention_mask, q_id_token_type_ids)return q_id_preddef predict_vec_request(self, query):q_id_pred = self.predict_vec(query)return q_id_pred.cpu().numpy().tolist()def predict_sim(self, q1, q2):q1_v = self.predict_vec(q1)q2_v = self.predict_vec(q2)sim = F.cosine_similarity(q1_v[0], q2_v[0], dim=-1)return sim.cpu().numpy().tolist()这里是有两个类,分别是SimcseModel和VectorizeModel,前者是模型类,后者是应用类,为什么这么分,在这篇文章里有提及,这里不赘述:心法利器[104] | 基础RAG-向量检索模块(含代码),当然后面用加速模型推理的时候,大家也会发现这个代码设计的优点。
另外值得强调的是,早期版本的onnx对if的算子支持的不是很好,所以大家尽量不要在模型类内增加这个,if这个还是比较常见的,所以特别说明。
onnx加速
加速的第一步,是生成新编译好的模型文件,这部分还是偏简单的,直接照着写基本就可以了。
import torch
from transformers import BertTokenizer
from src.models.vec_model.simcse_model import SimcseModel# Reference: https://blog.csdn.net/m0_37576959/article/details/127123186
# ------------模型编译----------
# 1. 必要配置
MODEL_PATH = "C:/work/tool/huggingface/models/simcse-chinese-roberta-wwm-ext"
MODEL_ONNX_PATH = "./data/model_simcse_roberta_output_20240211.onnx"
DEVICE = torch.device('cuda' if torch.cuda.is_available() else "cpu")# 2. 模型加载
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = SimcseModel(pretrained_bert_path=MODEL_PATH, pooling="cls")
# OPERATOR_EXPORT_TYPE = torch._C._onnx.OperatorExportTypes.ONNX
model.eval()
model.to(DEVICE)# 3. 格式定义
query = "你好"
encodings = tokenizer(query, max_length = 200, truncation=True, padding="max_length", return_tensors='pt')
input_info = (encodings["input_ids"].to(DEVICE),encodings["attention_mask"].to(DEVICE),encodings["token_type_ids"].to(DEVICE))
# model(input_info)# 4. 模型导出
output = torch.onnx.export(model,input_info,MODEL_ONNX_PATH,verbose=False,export_params=True,# operator_export_type=OPERATOR_EXPORT_TYPE,opset_version=12,input_names=['input_ids', 'attention_mask', 'token_type_ids'], # 需要注意顺序!不可随意改变, 否则结果与预期不符output_names=['output'], # 需要注意顺序, 否则在推理阶段可能用错output_namesdo_constant_folding=True,dynamic_axes={"input_ids": {0: "batch_size", 1: "length"},"token_type_ids": {0: "batch_size", 1: "length"},"attention_mask": {0: "batch_size", 1: "length"},"output": {0: "batch_size"}})
print("Export of {} complete!".format(MODEL_ONNX_PATH))# ------------模型校验----------
import onnxruntime as ort
import onnxonnx_model = onnx.load(MODEL_ONNX_PATH)
onnx.checker.check_model(onnx_model)# ------------模型校验----------
sess = ort.InferenceSession(MODEL_ONNX_PATH, providers=['CUDAExecutionProvider'])
query = "你好"
encodings = tokenizer(query, max_length = 512, truncation=True, padding="max_length", return_tensors='pt')def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()input = {sess.get_inputs()[0].name: to_numpy(encodings["input_ids"]),sess.get_inputs()[1].name: to_numpy(encodings["attention_mask"]),sess.get_inputs()[2].name: to_numpy(encodings["token_type_ids"]),
}
print(sess.run(None, input_feed=input))
print(model(encodings["input_ids"].to(DEVICE),encodings["attention_mask"].to(DEVICE),encodings["token_type_ids"].to(DEVICE)))这里的必要流程我都有些写注释,应该基本足够了解了,不过还是把重点讲讲吧。
首先是转化这块,其所有流程的中心,就落在torch.onnx.export这一个函数身上,这点已经非常方便了,前面所有的工作都是为了这一个函数所需要的原料在准备,比较核心的参数只要是这几个:
model:核心需要转化的模型,torch.nn.Module肯定是可以支持的,也是比较常见的。
args:这里输入的内容,是预期模型的参数格式,描述格式本身还比较困难,格式比较多样,然而这里支持的是可以往里面塞例子,这里的第三步,也就是格式定义,就是准备了一个例子。
f:这里是指输出的路径,最终加速后的模型的路径,当然,也可以用文件对象,就是open读取的那个对象。
input_names:定义好具体模型的输入,类bert模型本身是有3个输入,名称要定义清楚,和args中一致,且注意要按照顺序。
output_names:输出的名字,这个自己定义好就行。
dynamic_axes:这里是指支持动态的变量,这里是可以指明的,动态会为速度带来一定的影响,但是也会带来较高的灵活性,一般动态的比较多的就是batch_size和句子长度了,注意这里输入和输出都得写在里面。
然后就是推理,这里的难度其实不大,基本上按照脚本走就没有什么大问题,值得注意的细节就一个,onnx模型的推理需要的输入是numpy格式,此时转化后记得要转化回来。
另外,这里有一个函数onnx.checker.check_model,这个函数是负责检验模型生成是否规范,onnx底层是用protobuf定义的,内部的各个节点的映射关系之类的都写在这里面,为了保证整体符合规范,所以出了这个函数,具体细节可以参考这篇文章:https://blog.csdn.net/qq_43456016/article/details/130256097。虽然我们这种转化比较简单,但个人还是建议在脚本里都加上。
在完成新的模型文件生成后,就可以开始推理了,直接看新的推理程序吧。
class VectorizeModel_onnx(VectorizeModel):def __init__(self, ptm_model_path, onnx_path) -> None:self.tokenizer = BertTokenizer.from_pretrained(ptm_model_path)self.model = ort.InferenceSession(onnx_path, providers=['CUDAExecutionProvider'])self.pdist = nn.PairwiseDistance(2)def _to_numpy(self, tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()def predict_vec(self,query):q_id = self.tokenizer(query, max_length = 200, truncation=True, padding="max_length", return_tensors='pt')input_feed = {self.model.get_inputs()[0].name: self._to_numpy(q_id["input_ids"]),self.model.get_inputs()[1].name: self._to_numpy(q_id["attention_mask"]),self.model.get_inputs()[2].name: self._to_numpy(q_id["token_type_ids"]),}return torch.tensor(self.model.run(None, input_feed=input_feed)[0])def predict_sim(self, q1, q2):q1_v = self.predict_vec(q1)q2_v = self.predict_vec(q2)sim = F.cosine_similarity(q1_v[0], q2_v[0], dim=-1)return sim.numpy().tolist()这里的程序,为了简单,我是直接继承了上面提及的VectorizeModel,有些必要的额函数就不用重新写了。这里的加载和推理其实都参考了前面的“模型校验”中的内容了,加载用的是ort.InferenceSession,至于推理,与之不同的是,推理需要对tokenizer后的变量转为numpy的格式,另外输出这里,为了和前面的函数对齐,做好无缝切换,所以把输出的结果转化为torch.tensor了。
tensorRT加速
tensorRT的加速需要基于onnx,是需要对onnx进行进一步编译完成,流程上核心坑主要有两个:
环境配置,必须满足python版本、cuda版本等信息,而且nvidia下载速度较慢。
数据类型等细节的对齐,否则很容易失败。
详细的操作和尝试,大家可以参考这篇文章,可以说非常详细,对于详细版,大家可以看这个:https://blog.csdn.net/m0_37576959/article/details/127123186
而我想在这里聊的,是onnx本身所具有的编译tensorRT的功能,就在这行代码里:
model = ort.InferenceSession(onnx_path, providers=['CUDAExecutionProvider'])这里的providers中提供了3种:['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'],顾名思义,分别对应tensorRT、GPU、CPU三种模式,而这里的TensorrtExecutionProvider就是tensorRT编译的结果了。(https://zhuanlan.zhihu.com/p/457484536)
因此,上面对VectorizeModel_onnx就能优化为这个形式了(改个名字V2吧):
class VectorizeModel_v2(VectorizeModel):def __init__(self, ptm_model_path, model_path, providers=['CUDAExecutionProvider']) -> None:# ['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']self.tokenizer = BertTokenizer.from_pretrained(ptm_model_path)self.model = ort.InferenceSession(model_path, providers=providers)self.pdist = nn.PairwiseDistance(2)def _to_numpy(self, tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()def predict_vec(self,query):q_id = self.tokenizer(query, max_length = 200, truncation=True, padding="max_length", return_tensors='pt')input_feed = {self.model.get_inputs()[0].name: self._to_numpy(q_id["input_ids"]),self.model.get_inputs()[1].name: self._to_numpy(q_id["attention_mask"]),self.model.get_inputs()[2].name: self._to_numpy(q_id["token_type_ids"]),}return torch.tensor(self.model.run(None, input_feed=input_feed)[0])def predict_sim(self, q1, q2):q1_v = self.predict_vec(q1)q2_v = self.predict_vec(q2)sim = F.cosine_similarity(q1_v[0], q2_v[0], dim=-1)return sim.numpy().tolist()速度测试
有了进行加速这事,那就来对比一下加速的优化效率吧。
先来看看我的脚本:
import time,random
from tqdm import tqdm
# 加载
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
vec_model = VectorizeModel('C:/work/tool/huggingface/models/simcse-chinese-roberta-wwm-ext', device=device)
vec_model = VectorizeModel_v2('C:/work/tool/huggingface/models/simcse-chinese-roberta-wwm-ext',"./data/model_simcse_roberta_output_20240211.onnx",providers=['CUDAExecutionProvider'])
vec_model = VectorizeModel_v2('C:/work/tool/huggingface/models/simcse-chinese-roberta-wwm-ext',"./data/model_simcse_roberta_output_20240211.onnx",providers=['TensorrtExecutionProvider'])
batch_sizes = [1,2,4,8,16,32]
# 单测
# q = ["你好啊"]
# print(vec_model.predict_vec(q))
# print(vec_model.predict_sim("你好呀","你好啊"))# 开始批跑
batch_sizes = [1,2,4,8,16]
tmp_queries = ["你好啊", "今天天气怎么样", "我要暴富"]
for b in batch_sizes:for i in tqdm(range(100),desc="warmup"):tmp_q = []for i in range(b):tmp_q.append(random.choice(tmp_queries))vec_model.predict_vec(tmp_q)for i in tqdm(range(1000),desc="batch_size={}".format(b)):tmp_q = []for i in range(b):tmp_q.append(random.choice(tmp_queries))vec_model.predict_vec(tmp_q)这里是4个部分,分别是加载、单测(测单独一个case)、预热和开始批跑,时间的测试用的tqdm最终的平均时间即可。事不宜迟直接给出结果吧(单位:item/s,item是指每次推理,而非每条数据):
| batch_size | pytorch | onnx | tensorRT |
|---|---|---|---|
| 1 | 107.57 | 167.21 | 204.40 |
| 2 | 63.99 | 103.82 | 126.92 |
| 4 | 40.54 | 57.81 | 70.51 |
| 8 | 21.69 | 29.43 | 36.05 |
| 16 | 10.51 | 14.46 | 17.24 |
这里可以看到,onnx和tensorRT相比原始的pytorch模型的提升还是非常大的。
补充一个实验后的发现,tensorRT的推理中,当输入进去的数据的batch_size变化后,都会有个不短的预热时间,而在batch_size固定的那段时间,速度还是比稳定的,不知道是不是有什么bug还是这个编译情况就是如此,有了解的大佬可以在评论区里说下看有没有什么解决方案。

相关文章:
心法利器[107] onnx和tensorRT的bert加速方案记录
心法利器 本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。 2023年新一版的文章合集已经发布,获取方式看这里:又添十万字-CS的陋室2…...
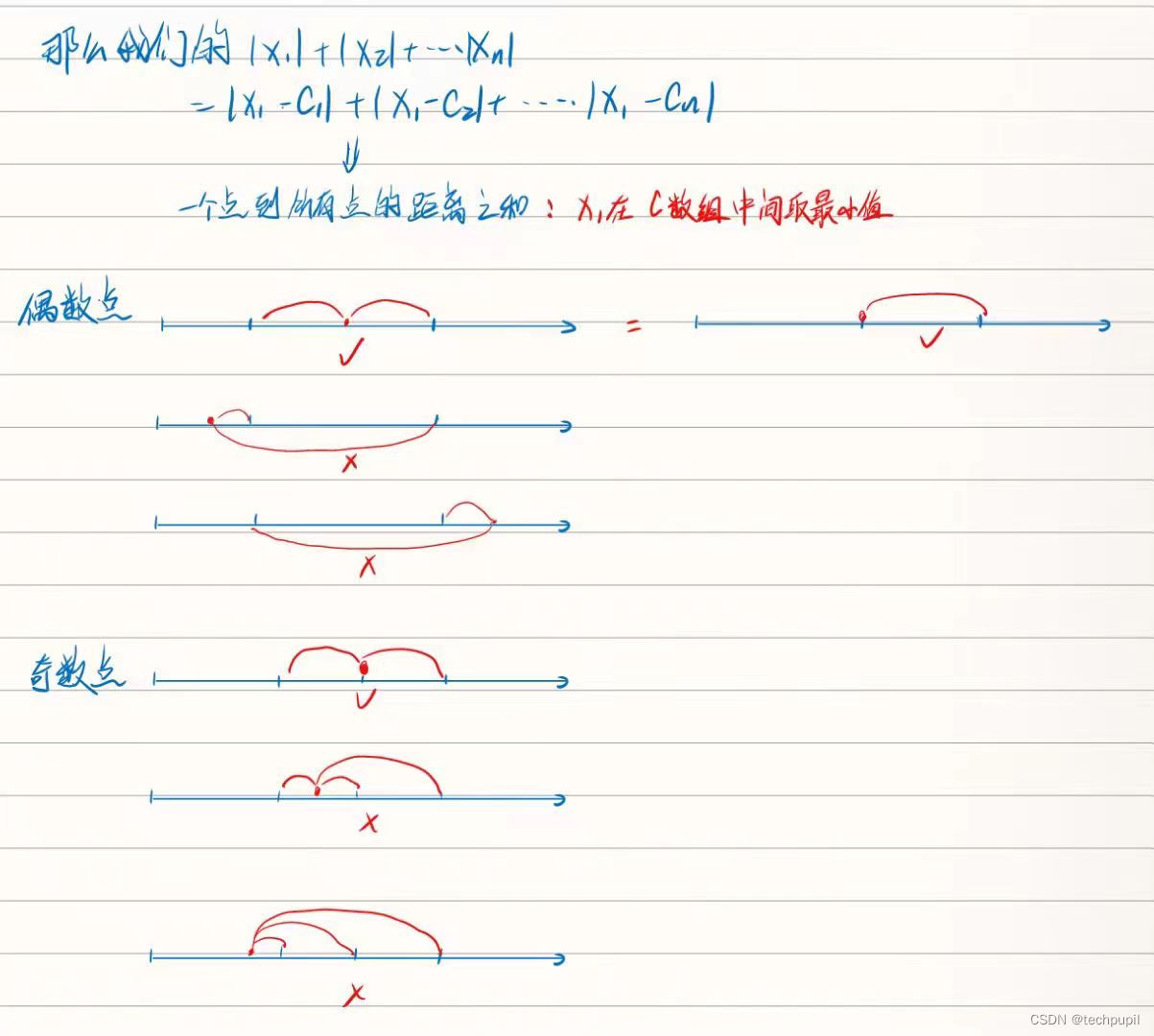
AcWing 122 糖果传递(贪心)
[题目概述] 有 n 个小朋友坐成一圈,每人有 a[i] 个糖果。 每人只能给左右两人传递糖果。 每人每次传递一个糖果代价为 1。 求使所有人获得均等糖果的最小代价。 输入格式 第一行输入一个正整数 n,表示小朋友的个数。 接下来 n 行,每行一个…...
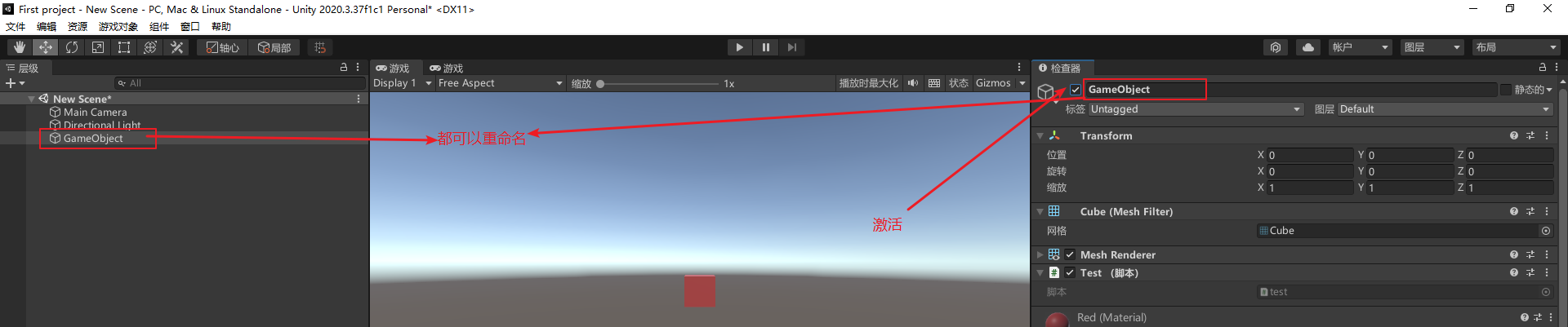
unity的重中之重:组件
检查器(Hierarchy)面板中的所有东西都是组件。日后多数工作都是和组件打交道,包括调参、自定义脚本组件。 文章目录 12 游戏的灵魂,脚本组件13 玩转脚本组件14 尽职的一生,了解组件的生命周期15 不能插队!…...

Linux释放内存
free -m是Linux上查看内存的指令,其中-m是以兆(MB)为单位,如果不加则以KB为单位。 如下图表示,(total)总物理内存是809MB,(used)已使用167MB,&…...

Python算法题集_翻转二叉树
Python算法题集_翻转二叉树 题226:翻转二叉树1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【DFS递归】2) 改进版一【BFS迭代,节点循环】3) 改进版二【BFS迭代,列表循环】 4. 最优算法 本文为Python算法题集…...
Git快速掌握,通俗易懂
Git分布式版本控制工具 介绍 Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。Git是由Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件。Git可以帮助开发者们管理代码的版本,避免代码冲突&#…...
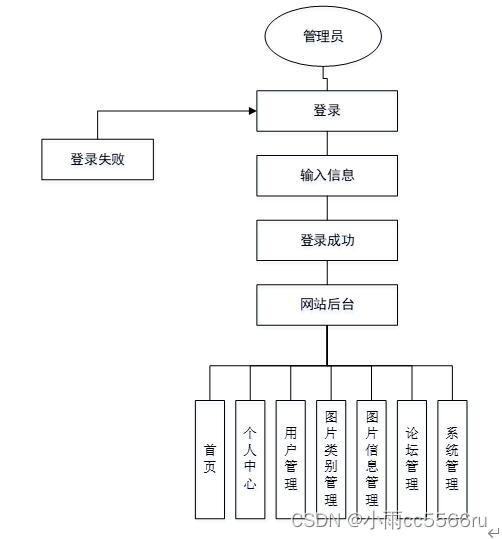
PHP毕业设计图片分享网站76t17
图片分享网站主要是为了提高工作人员的工作效率和更方便快捷的满足用户,更好存储所有数据信息及快速方便的检索功能,对系统的各个模块是通过许多今天的发达系统做出合理的分析来确定考虑用户的可操作性,遵循开发的系统优化的原则,…...

代码随想录 Leetcode45. 跳跃游戏 II
题目: 代码(首刷看解析 2024年2月15日): class Solution { public:int jump(vector<int>& nums) {if (nums.size() 1) return 0;int res 0;int curDistance 0;int nextDistance 0;for (int i 0; i < nums.size(); i) {nex…...

【C语言】socketpair 的系统调用
一、 Linux 内核 4.19socketpair 的系统调用 SYSCALL_DEFINE4(socketpair, int, family, int, type, int, protocol,int __user *, usockvec) {return __sys_socketpair(family, type, protocol, usockvec); } 这段代码定义了一个名为 socketpair 的系统调用。系统调用是操作…...

【论文精读】BERT
摘要 以往的预训练语言表示应用于下游任务时的策略有基于特征和微调两种。其中基于特征的方法如ELMo使用基于上下文的预训练词嵌入拼接特定于任务的架构;基于微调的方法如GPT使用未标记的文本进行预训练,并针对有监督的下游任务进行微调。 但上述两种策略…...
 - A、B、C、D、E)
Codeforces Round 925 (Div. 3) - A、B、C、D、E
文章目录 前言A. Recovering a Small StringB. Make EqualC. Make Equal AgainD. Divisible PairsE. Anna and the Valentines Day Gift 前言 本篇博客是Codeforces Round 925周赛的A、B、C、D、E五题的题解 A. Recovering a Small String 可以通过sum的大小分为三种情况&#…...

快速部署MES源码/万界星空科技开源MES
什么是开源MES软件? 开源MES软件是指源代码可以免费获取、修改和分发的MES软件。与传统的商业MES软件相比,开源MES软件具有更高的灵活性和可定制性。企业可以根据自身的需求对软件进行定制化开发,满足不同生产环境下的特定需求。 开源MES软件…...
【Python网络编程之TCP三次握手】
🚀 作者 :“码上有前” 🚀 文章简介 :Python开发技术 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 Python网络编程之[TCP三次握手] 代码见资源,效果图如下一、实验要求二、协议原理2.…...
【leetcode】深搜、暴搜、回溯、剪枝(C++)2
深搜、暴搜、回溯、剪枝(C)2 一、括号生成1、题目描述2、代码3、解析 二、组合1、题目描述2、代码3、解析 三、目标和1、题目描述2、代码3、解析 四、组合总和1、题目描述2、代码3、解析 五、字母大小写全排列1、题目描述2、代码3、解析 六、优美的排列1…...

鸿蒙开发-UI-图形-图片
鸿蒙开发-UI-组件 鸿蒙开发-UI-组件2 鸿蒙开发-UI-组件3 鸿蒙开发-UI-气泡/菜单 鸿蒙开发-UI-页面路由 鸿蒙开发-UI-组件导航-Navigation 鸿蒙开发-UI-组件导航-Tabs 文章目录 一、基本概念 二、图片资源加载 1. 存档图类型数据源 2.多媒体像素图 三、显示矢量图 四、图片…...
.NET Core WebAPI中使用Log4net记录日志
一、安装NuGet包 二、添加配置 // log4net日志builder.Logging.AddLog4Net("CfgFile/log4net.config");三、配置log4net.config文件 <?xml version"1.0" encoding"utf-8"?> <log4net><!-- Define some output appenders -->…...

Nginx配置php留档
好久没有用过php了,近几日配置nginxphp,留档。 安装 ubunt下nginx和php都可以使用apt安装: sudo apt install nginx php8 如果想安装最新的php8.2,则需要运行下面语句: sudo dpkg -l | grep php | tee packages.txt sudo add-…...
英语题不会怎么搜答案?分享五个支持答案和解析的工具 #学习方法#媒体
在大学的学习过程中,我们常常会遇到一些难以解决的问题,有时候甚至会感到束手无策。然而,如今的技术发展给我们提供了新的解决方案。搜题软件作为一种强大的学习工具,正在被越来越多的大学生所接受和使用。今天,我将为…...

Rust 数据结构与算法:4栈:用栈实现进制转换
2、进展转换 将十进制数转换为二进制表示形式的最简单方法是“除二法”,可用栈来跟踪二进制结果。 除二法 下面实现一个将十进制数转换为二进制或十六进制的算法,代码如下: #[derive(Debug)] struct Stack<T> {size: usize, // 栈大…...
树莓派4B(Raspberry Pi 4B)使用docker搭建阿里巴巴sentinel服务
树莓派4B(Raspberry Pi 4B)使用docker搭建阿里巴巴sentinel服务 由于国内访问不了docker hub,而国内镜像仓库又没有适配树莓派ARM架构的sentinel镜像,所以我们只能退而求其次——自己动手构建镜像。本文基于Ubuntu,Jav…...
)
别再傻傻分不清了!给硬件工程师的SI、PI、EMI关系速查手册(附高频PCB设计实例)
硬件工程师实战指南:SI、PI、EMI的三角关系与高频PCB设计避坑 当你第一次面对DDR4布线导致的EMI测试失败时,可能会陷入这样的困惑:明明是信号完整性问题,为什么整改方案却是调整电源层的去耦电容?这种看似跨领域的因果…...

Google 的 IDE 演进小史
不知道你平时用的 IDE 是什么?小七的工程师同事有在用 Vim 的,也有 Emacs 党,IntelliJ 全家桶也有人在用,用得最多的可能是 VS Code。只要代码能写好、工具链能跑通,似乎大家没有必要使用同一个 IDE。 Google 早年也是…...

初创公司利用taotoken token plan在ai原型开发期控制成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司利用 Taotoken Token Plan 在 AI 原型开发期控制成本 对于一家处于产品原型快速迭代阶段的 AI 初创公司而言,技…...

高性能Go Web框架Volo:设计原理、核心功能与生产实践
1. 项目概述:一个高性能的Go语言Web框架最近在折腾一个需要处理高并发请求的API服务,选型时又一次把目光投向了Go生态。说实话,Go的Web框架选择不少,从轻量级的Gin、Echo,到功能更全的Beego、Iris,各有各的…...

知识库搭建:从认知到实践的完整指南
知识库搭建:从认知到实践的完整指南一、先搞清楚:什么是知识? 数据 → 信息 → 知识 → 智慧 是经典的 DIKW 金字塔,描述了认知逐层升维的过程:层级核心定义关键特征回答的问题示例数据原始事实,raw facts离…...

ImageToSTL:将二维图片转化为可打印三维模型的艺术
ImageToSTL:将二维图片转化为可打印三维模型的艺术 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. 项…...
)
别再只用ARIMA了!用Python+statsmodels搞定SARIMA预测电商销量(附完整代码)
电商销量预测实战:用PythonSARIMA破解季节性销售波动 电商销量预测的痛点与SARIMA的破局之道 每逢大促季节,电商运营团队总会陷入两难困境:备货不足错失销售良机,库存积压又导致资金周转困难。传统ARIMA模型在预测日常销量时表现尚…...

TC2526 低功耗原边反馈开关电源芯片
概述 TC2526 是一款低功耗原边反馈(PSR)开关电源芯片,其内部集成了大功率 BJT 管,适用于隔离型的高效低功耗便携式设备充电器应用。TC2526 采用独特具有恒流恒压功能的原边反馈控制技术,以及独特的轻载调频技术降低轻载…...

Android Studio中文插件5分钟快速安装完整指南:告别英文开发困扰
Android Studio中文插件5分钟快速安装完整指南:告别英文开发困扰 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在…...

抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案
抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...