【论文精读】BERT
摘要
以往的预训练语言表示应用于下游任务时的策略有基于特征和微调两种。其中基于特征的方法如ELMo使用基于上下文的预训练词嵌入拼接特定于任务的架构;基于微调的方法如GPT使用未标记的文本进行预训练,并针对有监督的下游任务进行微调。
但上述两种策略都使用从左到右的架构,每个token只能处理self-attention层中的前一个token,这种限制在将基于微调的方法应用于问答等token级任务时可能非常有损性能。故改进为:
- 使用掩码语言模型(MLM)预训练基于transformer的双向编码器,得到的预训练表示可以改进以往基于单向性约束的(GPT)微调方法,证明了双向预训练对语言表示的重要性
- BERT的预训练表示减少了许多工程对特定任务模型架构的需求,对其微调后的表示模型,在大量句子级和标记级任务上实现了最先进的性能,超过了许多特定于任务的体系结构
框架
模型架构
BERT是一个多层双向Transformer编码器,故定义Transformer层数为 L L L,隐层维度为 H H H,自注意力头数为 A A A。实验定义了 B E R T B A S E ( L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M ) BERT_{BASE}(L=12,H=768,A=12, Total Parameters=110M) BERTBASE(L=12,H=768,A=12,TotalParameters=110M), B E R T L A R G E ( L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M ) BERT_{LARGE}(L=24,H=1024,A=16, Total Parameters=340M) BERTLARGE(L=24,H=1024,A=16,TotalParameters=340M)两种尺寸的模型。
输入/输出表示方法

对于输入文本序列,使用带有30000个token词汇的WordPiece embedding对序列分片形成输入token序列,token序列的第一个token指定为分类token [ C L S ] [CLS] [CLS],用于作分类任务的聚合序列表示。由于输入文本可以为单个句子或句子对,单个句子可以简单表示,但为了能在一个token序列中无歧义地表示句子对,采用一个特殊的token [ S E P ] [SEP] [SEP]将句子分开。
随后对分片打包好的序列计算其token embedding,并累加可学习嵌入position embedding和segment embedding得到嵌入 E E E。其中position embedding用于学习token间的相对位置,segment embedding用于学习token属于句子A或句子B。整体流程如上图。
[ C L S ] [CLS] [CLS]的最终隐层向量为 C ∈ R H C \in \R^H C∈RH,其余 i t h i^{th} ith个token的最终隐层向量为 T i ∈ R H T_i \in \R^H Ti∈RH。
预训练

Masked LM
对于掩码语言模型任务,为了训练网络的双向表示,随机mask一定比例的输入token并记为 [ M A S K ] [MASK] [MASK],然后让模型预测这些被mask的token,与masked token相对应的最终隐层向量通过softmax得到最终预测分布。在所有实验中,随机屏蔽比例设为15%。
上述设置的缺点是预训练和微调之间存在gap,因为在微调期间不会出现 [ M A S K ] [MASK] [MASK]token,故实际使用并不是简单的用 [ M A S K ] [MASK] [MASK]token替换mask的单词。因为训练数据生成器会随机选择15%的token进行预测,如果选择 i t h i^{th} ithtoken,将会替换为:
- [ M A S K ] [MASK] [MASK]token(80%概率)
- 随机token(10%概率)
- 不变(10%概率)
损失定义为 i t h i^{th} ithtoken 相对应的最终隐层向量 T i T_i Ti与原始token的交叉熵。整体流程如上图左。
Next Sentence Prediction (NSP)
对于下一个句子预测任务,如问答(Question Answering, QA)和自然语言推理(Natural Language Inference, NLI),都是基于理解两个句子之间的关系,而语言建模无法直接捕捉到这些关系,故设计一个二值分类任务用于预训练。具体为,当为每个预训练示例选择句子对时,50%的概率为A之后的实际下一个句子(标签为IsNext),50%的概率为语料库中的随机句子(标签为NotNext)。如上图左, C C C用于计算分类结果 N S P NSP NSP。
预训练数据
预训练语料库使用BooksCorpus(8亿单词)和只提取文本段落,忽略列表、表格和标题的英语维基百科(2500亿单词)。
微调
对于单个文本或文本对,Transformer中的自注意力机制允许BERT通过替换合适的输入/输出格式对下游任务建模。故对于任意下游任务,只需将特定于任务的输入和输出插入BERT中,并对所有参数进行端到端的微调。
对于输入,预训练句子对的句子A和句子B格式类似于:句子释义中的句子对;句子蕴含中的句子对;问答中的句子对;文本分类或序列标注中的句子对。对于输出,token表示形式可以完成token级任务,如序列标记或问题回答。而 [ C L S ] [CLS] [CLS]表示形式可以进行分类,如句子蕴含或情感分析。
故输入输出都可对应上述格式进行下游任务转换及微调参数。
对比实验
GLUE
本实验对GLUE进行微调,使用 C C C作为聚合表示。微调过程中引入分类层权重 W ∈ R K × H W \in \R^{ K×H} W∈RK×H,其中 K K K是类别数量,分类损失定义为 l o g ( s o f t m a x ( C W T ) ) log(softmax(CW^T )) log(softmax(CWT))。 使用32的batch size,对所有GLUE任务的数据进行3个epoch的微调。对于每个任务,最佳的微调学习率(在5e-5、4e-5、3e-5和2e-5中)。
对于 B E R T L A R G E BERT_{LARGE} BERTLARGE,发现微调在小型数据集上有时不稳定,因此运行了几次随机重启,并选择了最佳模型。对于每次随机重启,使用相同的预训练checkpoint,但执行不同的微调数据打乱和分类器层初始化。

实验结果如上图, B E R T B A S E BERT_{BASE} BERTBASE和 B E R T L A R G E BERT_{LARGE} BERTLARGE在所有任务上的表现都大大超过了以往系统,与之前的技术水平相比分别获得了4.5%和7.0%的平均精度提高。对于MNLI任务,BERT获得了4.6%的绝对精度提升。
B E R T L A R G E BERT_{LARGE} BERTLARGE在所有任务中明显优于 B E R T B A S E BERT_{BASE} BERTBASE,特别是在训练数据很少的任务中。
SQuAD v1.1
斯坦福问答数据集(SQuAD v1.1)是一个有10万组问题/答案对的集合。给定一个问题和一篇来自维基百科的包含答案的文章,任务是预测答案在文章中的文本范围。
如图1右,在问答任务中,将问题和文章打包为单个输入序列,问题使用 A embedding,文章使用B embedding。在微调过程中,引入开始向量 S ∈ R H S ∈ R^ H S∈RH和结束向量 E ∈ R H E ∈ R ^H E∈RH。单词 i i i为答案范围开始的概率定义为通过 T i T_i Ti和 S S S 的点乘加对文章中所有词的softmax,即 P i = e S ⋅ T i ∑ j e S ⋅ T i P_i=\frac {e^{S \cdot T_i}} {\sum_j e^{S \cdot T_i}} Pi=∑jeS⋅TieS⋅Ti ,答案的末尾 j j j的概率类似,从位置 i i i到位置 j j j的候选评分定义为 S ⋅ T i + E ⋅ T j S·T_i+E·T_j S⋅Ti+E⋅Tj,且 j ≥ i j≥i j≥i。训练目标是正确开始位置向量和结束位置向量的对数似然的和。微调进行3个epoch,学习率为5e-5,batch size为32。在算法中使用适度的数据增强,首先在TriviaQA上进行微调,然后再对SQuAD进行微调。

上图为实验结果,表现最好的算法比之前最优nlnet高出1.5 F1, single BERT高出QANet1.3 F1。 single BERT模型在F1分数方面优于之前顶级集成算法。在没有TriviaQA微调数据的情况下,BERT也只损失了0.1-0.4 F1,仍然大大超过了所有现有算法。
SQuAD v2.0
SQuAD 2.0任务在提供的文章上,允许出现长答案,从而扩展了SQuAD 1.1的问题定义,让问题更具有现实意义。
实验采用了类似的方法在这个任务上扩展SQuAD v1.1 BERT微调模型,将没有答案的问题处理为答案范围为起始和终止都在 [ C L S ] [CLS] [CLS]token上,可能的起始终止回答范围从而扩展到包含 [ C L S ] [CLS] [CLS]token的位置。对于预测而言,定义没有答案的分数为 s n u l l = S ⋅ C + E ⋅ C s_{null}=S \cdot C + E \cdot C snull=S⋅C+E⋅C,最好的非空答案(non-null)分数为 s ^ i , j = max j ≥ i S ⋅ T i + E ⋅ T j \hat s_{i,j}=\max_{j \ge i}S \cdot T_i +E \cdot T_j s^i,j=maxj≥iS⋅Ti+E⋅Tj ,若 s ^ i , j > s n u l l + τ \hat s_{i,j} > s_{null}+\tau s^i,j>snull+τ则预测结果非空,阈值 τ \tau τ通过在测试集上最大化F1选择。
实验没有使用TriviaQA数据集预训练,采用batch size为48和学习率为5e-5微调2个epochs。

上图为实验结果,与之前的最佳系统相比,F1值提高了5.1。
SWAG
对抗性生成(SWAG)数据集包含113k个句子对补全示例,实验模型的基础常识推理能力。给定一个句子,任务是在四个选项中选择最合理的下一句。
在SWAG数据集上微调时,每个句子对构建4个输入序列,每个序列拼接了给定句子(句子A)和可能的下一句(句子B)。引入的唯一特定于任务的参数是一个向量,其和 [ C L S ] [CLS] [CLS]token点乘,再通过softmax层得到归一化的向量。

上为实验结果, B E R T L A R G E BERT_{LARGE} BERTLARGE的性能比ESIM+ELMo提高27.1%,比GPT提高8.3%。
消融实验
Effect of Pre-training Tasks
实验评估两项预训练目标,证明BERT的深度双向性的重要性,评估过程中使用了和 B E R T B A S E BERT_{BASE} BERTBASE完全相同的预训练数据,微调策略和超参数。
No NSP:预训练过程采用MLM但不采用NSP任务的双向模型。
LTR & No NSP:采用标准的Left-to-Right (LTR) LM训练的模型(不采用MLM),左性约束也作用在微调阶段,因为不采用这种策略会导致预训练/微调的gap,而导致下游性能受损,且不采用NSP任务进行预训练。除了训练采用了更大的数据集,不同的输入表征和fine tuning策略,这个模型和GPT非常类似。

上图为实验结果,观察到移除NSP任务将显著地降低QNLI,MNLI,SQuAD 1.1上的性能。LTR & No NSPLTR模型在所有任务上都比MLM模型要差,在MRPC和SQuAD上性能大幅下降。
对于SQuAD任务,LTR要在token预测上表现极差,这是因为token-level的隐藏状态没有收到右边的语境。其次在LTR系统顶层增加了一个随机初始化的BiLSTM来弥补性能,观察到确实显著地提升SQuAD上的结果,但是结果依然要远远差于预训练的双向模型,BiLSTM结构对GLUE任务上甚至有害。
另外意识到类似ELMo,可以分别训练LTR和RTL模型(自左向右和自右向左)然后通过将两组表征拼接在一起。但是这样需要单独双向模型两倍的计算量,且对与QA一类的任务违反常识,RTL模型不可能根据回答来解释问题,而且这明显要弱于深度双向模型,因为深度双向模型可以在每一层同时利用双向语境。
Effect of Model Size
本实验研究不同模型尺寸在微调任务上的精度。实验采用不同的层数、隐藏尺寸数、注意力头数配比上训练了一组BERT模型,和之前的描述采用了完全相同的超参数和训练策略。

实验结果如上图,实验选择了5组随机重启微调模型均值作为结果。可以看到在4个数据集上,获得严格的性能提升。另外发现即使是在和现有的文献中相比已经非常大的模型上,也能够取得非常大的性能提升。
实验证明随着模型尺寸的增加,在大规模数据集上的任务比如机器翻译和语言模型上,将会不断地获得模型性能的提升。同时也首次证明了巨大的模型尺寸,在小规模数据集任务上微调也能获得巨大地性能提升,说明模型已经被充分地预训练了。
Feature-based Approach with BERT
上述实验的所有BERT结果都使用了微调方法,即在预训练模型中添加一个简单的分类层,并在下游任务上联合微调所有参数。但是,基于特征的方法直接从预训练模型中提取固定特征相比于微调具有一定的优势。首先,不是全部任务可以很容易地由Transformer编码器架构表示,因此需要添加特定于任务的模型架构;其次,基于特征的方法只需预先进行一次预训练,就可以直接运行在这种表示之上的模型。
本实验通过将BERT应用于CoNLL-2003命名实体识别(NER)任务来比较这两种方法。 在BERT的输入中,使用case-preserving WordPiece模型,并包含数据提供的最大化的文档上下文,并将其表述为标记任务,但在输出中不使用CRF层。使用第一个 sub-token的表示作为NER标签集上token-level分类器的输入。
为了削弱微调方法,实验应用基于特征的方法从一个或多个层中提取特征值,而无需微调BERT的任何参数。这些上下文嵌入被用作分类层之前随机初始化的两层768维BiLSTM的输入。

实验结果如上图,表现最好的基于特征方法拼接了预训练Transformer的最后四层隐藏层的token表示,与微调整个模型相比只降低了0.3 F1。这表明BERT对于微调和基于特征的方法都是有效的。
详细配置
Comparison of BERT, ELMo, and OpenAI GPT

上图比较了ELMo、OpenAI GPT和BERT的结构。BERT和GPT都是微调方法,而ELMo是基于特征的方法。GPT在大型文本语料库上采用了LTR Transformer LM,BERT和GPT中的核心不同在于双向性训练任务,其他一些的不同有:
- GPT在BooksCorpus(800M词),而BERT在BooksCorpus(800M词)和Wikipedia(2500M词)上训练得到
- GPT采用了一种句子分隔符 [ S E P ] [SEP] [SEP]和分类器token [ C L S ] [CLS] [CLS],这些只在微调阶段使用;而BERT则在预训练过程中学习 [ S E P ] [SEP] [SEP], [ C L S ] [CLS] [CLS]和句子 A/B embedding
- GPT训练1M步,batch size为32000词;BERT也训练1M步,但batch size为128000词
- GPT对所有的微调采用相同的学习率5e-5;而BERT采用了在测试集上表现最好的作为任务相关的微调学习率
Illustrations of Fine-tuning on Different Tasks

上图为不同任务上BERT的微调表示。在所有任务中,(a)、(b)是sequence level的任务,(c)和(d)是token level的任务。在图中E表示输入embedding, T i T_i Ti表示token i i i的语境表示, [ C L S ] [CLS] [CLS]是分类输出的特殊符号, [ S E P ] [SEP] [SEP]是分割非连续token序列的特殊符号。
Effect of Number of Training Steps

上图显示了MNLI测试精度,实验为在一个预训练k步的checkpoint上进行微调的结果。观察到, B E R T B A S E BERT_{BASE} BERTBASE在1M步上比500k步上提高1%的精度;MLM模型比LTR模型收敛的稍微慢一些,但MLM的绝对精度几乎是在瞬间就超过了LTR模型。
Ablation for Different Masking Procedures

上图为不同masking策略的对照实验,其中MASK表示将目标token用 [ M A S K ] [MASK] [MASK]符号进行替换,SAME表示保持token不变,RND表示随机替换。左边部分的数字表示MLM预训练中所采用的策略的概率(BERT采用了80%,10%,10%),右边的部分表示结果。对于feature-based的方法,将最后4层的BERT的输出作为特征。
可以看到,微调方法对于不同masking策略有很好的鲁棒性。只使用MASK策略在NER数据集上使用基于特征的方法会有问题。只采用RND策略会大幅降低性能。
reference
Devlin, J. , Chang, M. W. , Lee, K. , & Toutanova, K. . (2018). Bert: pre-training of deep bidirectional transformers for language understanding.
相关文章:
【论文精读】BERT
摘要 以往的预训练语言表示应用于下游任务时的策略有基于特征和微调两种。其中基于特征的方法如ELMo使用基于上下文的预训练词嵌入拼接特定于任务的架构;基于微调的方法如GPT使用未标记的文本进行预训练,并针对有监督的下游任务进行微调。 但上述两种策略…...
 - A、B、C、D、E)
Codeforces Round 925 (Div. 3) - A、B、C、D、E
文章目录 前言A. Recovering a Small StringB. Make EqualC. Make Equal AgainD. Divisible PairsE. Anna and the Valentines Day Gift 前言 本篇博客是Codeforces Round 925周赛的A、B、C、D、E五题的题解 A. Recovering a Small String 可以通过sum的大小分为三种情况&#…...

快速部署MES源码/万界星空科技开源MES
什么是开源MES软件? 开源MES软件是指源代码可以免费获取、修改和分发的MES软件。与传统的商业MES软件相比,开源MES软件具有更高的灵活性和可定制性。企业可以根据自身的需求对软件进行定制化开发,满足不同生产环境下的特定需求。 开源MES软件…...
【Python网络编程之TCP三次握手】
🚀 作者 :“码上有前” 🚀 文章简介 :Python开发技术 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 Python网络编程之[TCP三次握手] 代码见资源,效果图如下一、实验要求二、协议原理2.…...
【leetcode】深搜、暴搜、回溯、剪枝(C++)2
深搜、暴搜、回溯、剪枝(C)2 一、括号生成1、题目描述2、代码3、解析 二、组合1、题目描述2、代码3、解析 三、目标和1、题目描述2、代码3、解析 四、组合总和1、题目描述2、代码3、解析 五、字母大小写全排列1、题目描述2、代码3、解析 六、优美的排列1…...

鸿蒙开发-UI-图形-图片
鸿蒙开发-UI-组件 鸿蒙开发-UI-组件2 鸿蒙开发-UI-组件3 鸿蒙开发-UI-气泡/菜单 鸿蒙开发-UI-页面路由 鸿蒙开发-UI-组件导航-Navigation 鸿蒙开发-UI-组件导航-Tabs 文章目录 一、基本概念 二、图片资源加载 1. 存档图类型数据源 2.多媒体像素图 三、显示矢量图 四、图片…...
.NET Core WebAPI中使用Log4net记录日志
一、安装NuGet包 二、添加配置 // log4net日志builder.Logging.AddLog4Net("CfgFile/log4net.config");三、配置log4net.config文件 <?xml version"1.0" encoding"utf-8"?> <log4net><!-- Define some output appenders -->…...

Nginx配置php留档
好久没有用过php了,近几日配置nginxphp,留档。 安装 ubunt下nginx和php都可以使用apt安装: sudo apt install nginx php8 如果想安装最新的php8.2,则需要运行下面语句: sudo dpkg -l | grep php | tee packages.txt sudo add-…...
英语题不会怎么搜答案?分享五个支持答案和解析的工具 #学习方法#媒体
在大学的学习过程中,我们常常会遇到一些难以解决的问题,有时候甚至会感到束手无策。然而,如今的技术发展给我们提供了新的解决方案。搜题软件作为一种强大的学习工具,正在被越来越多的大学生所接受和使用。今天,我将为…...

Rust 数据结构与算法:4栈:用栈实现进制转换
2、进展转换 将十进制数转换为二进制表示形式的最简单方法是“除二法”,可用栈来跟踪二进制结果。 除二法 下面实现一个将十进制数转换为二进制或十六进制的算法,代码如下: #[derive(Debug)] struct Stack<T> {size: usize, // 栈大…...
树莓派4B(Raspberry Pi 4B)使用docker搭建阿里巴巴sentinel服务
树莓派4B(Raspberry Pi 4B)使用docker搭建阿里巴巴sentinel服务 由于国内访问不了docker hub,而国内镜像仓库又没有适配树莓派ARM架构的sentinel镜像,所以我们只能退而求其次——自己动手构建镜像。本文基于Ubuntu,Jav…...
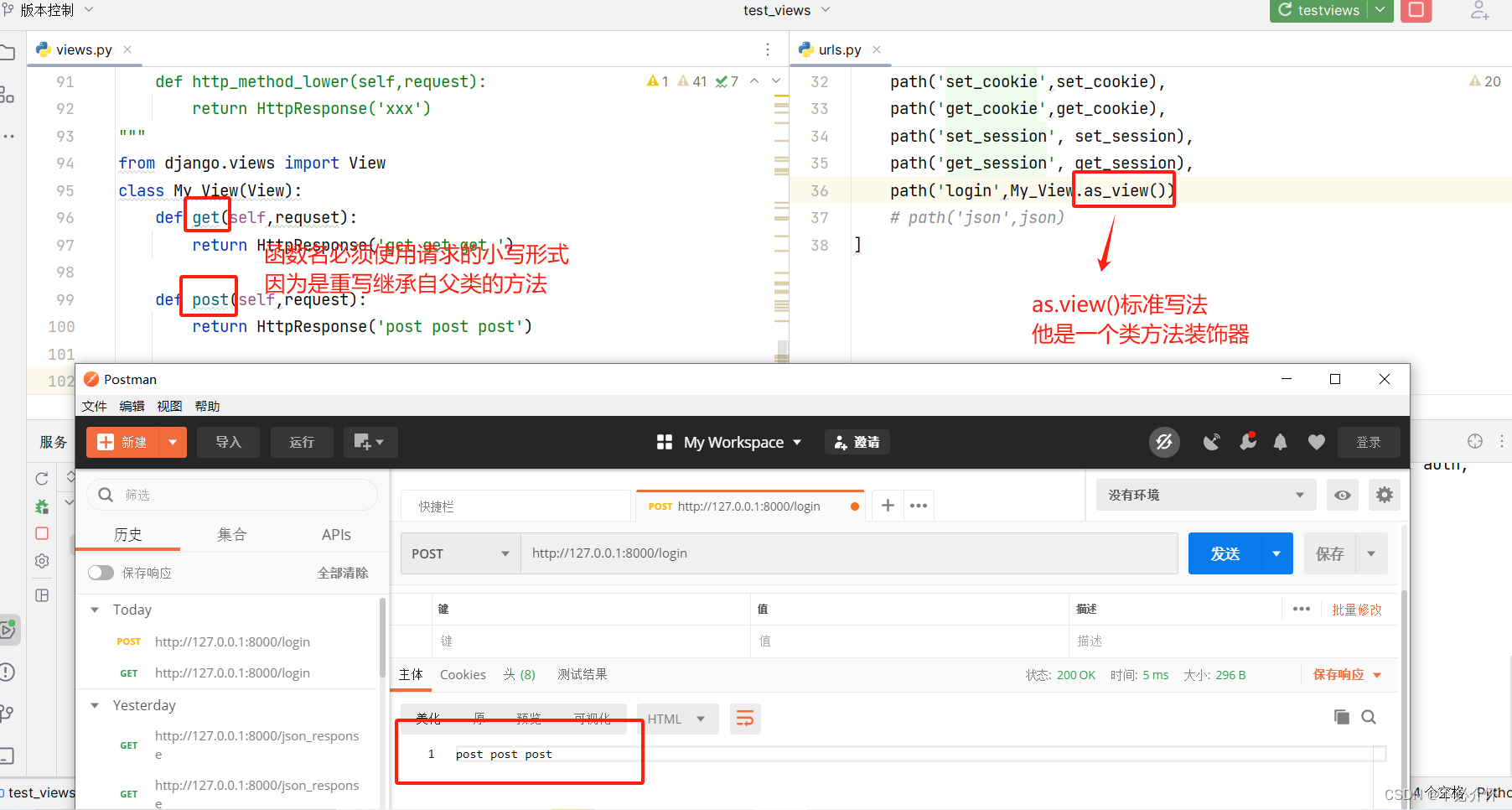
Django视图
HttpRequests对象 利用http协议向服务器传参的4种途径 提取url特定部分,如/web/index/,可以通过在服务器端的路由中用正则表达式截取查询字符串,形如?key1value&keyvalue2,(?前面是路由,…...

python基本语法
变量无需声明 Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。 在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。 len800 #整型变…...

app逆向-⽹络请求库rxjava2
文章目录 一、前言二、安装三、GET请求实现四、POST请求实现 一、前言 RxJava 2 是一个流行的 Java 库,用于使用可观察序列组合异步和基于事件的程序。它是原始 RxJava 库的重新实现,旨在更高效并且更适合于 Java 8 及更高版本。 RxJava 2 的主要特性包…...
Spring Boot 笔记 007 创建接口_登录
1.1 登录接口需求 1.2 JWT令牌 1.2.1 JWT原理 1.2.2 引入JWT坐标 1.2.3 单元测试 1.2.3.1 引入springboot单元测试坐标 1.2.3.2 在单元测试文件夹中创建测试类 1.2.3.3 运行测试类中的生成和解析方法 package com.geji;import com.auth0.jwt.JWT; import com.auth0.jwt.JWTV…...
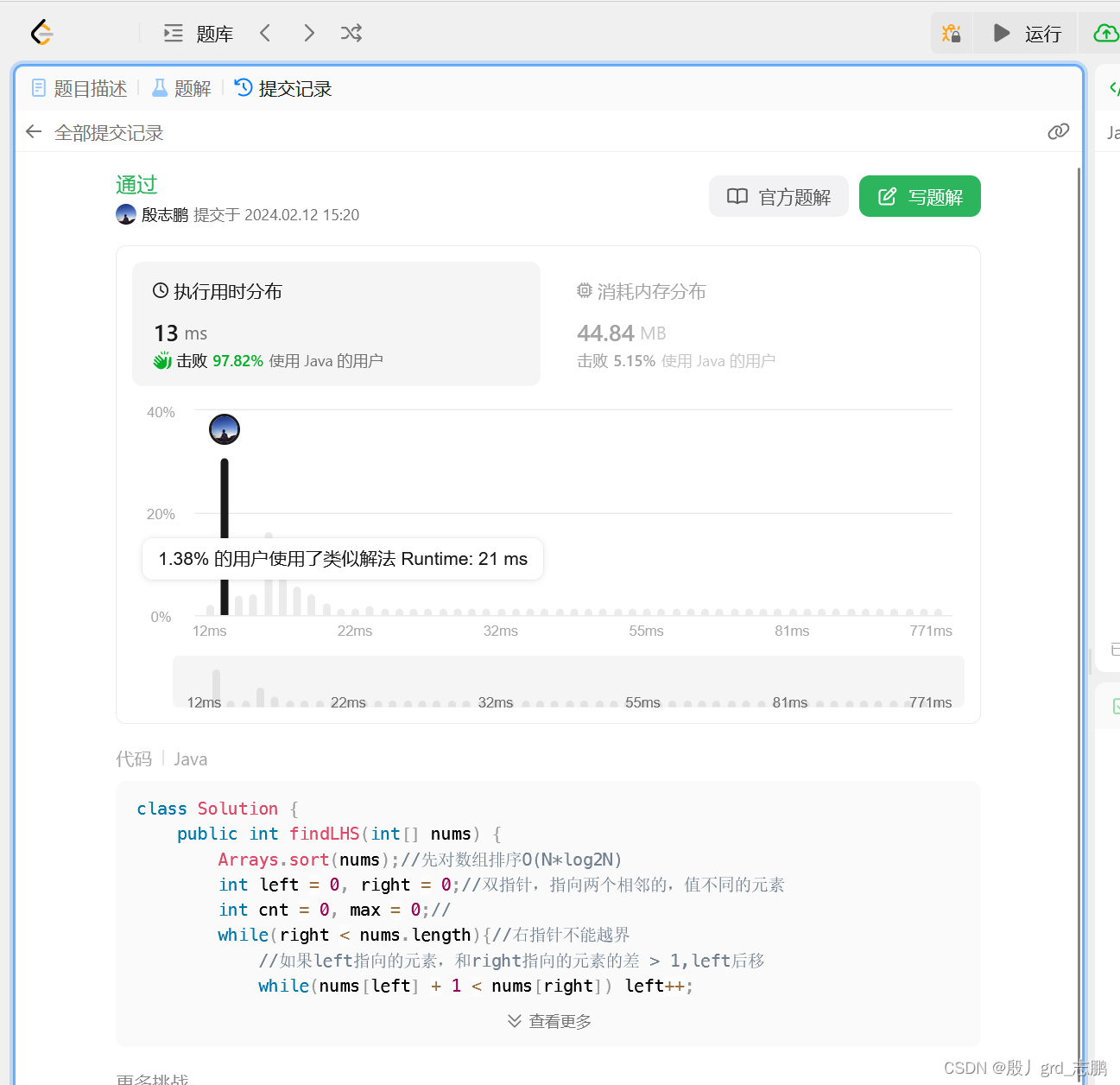
java数据结构与算法刷题-----LeetCode594. 最长和谐子序列
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 解题思路 子序列要尽可能长,并且最大值和最小值之间的差&#…...
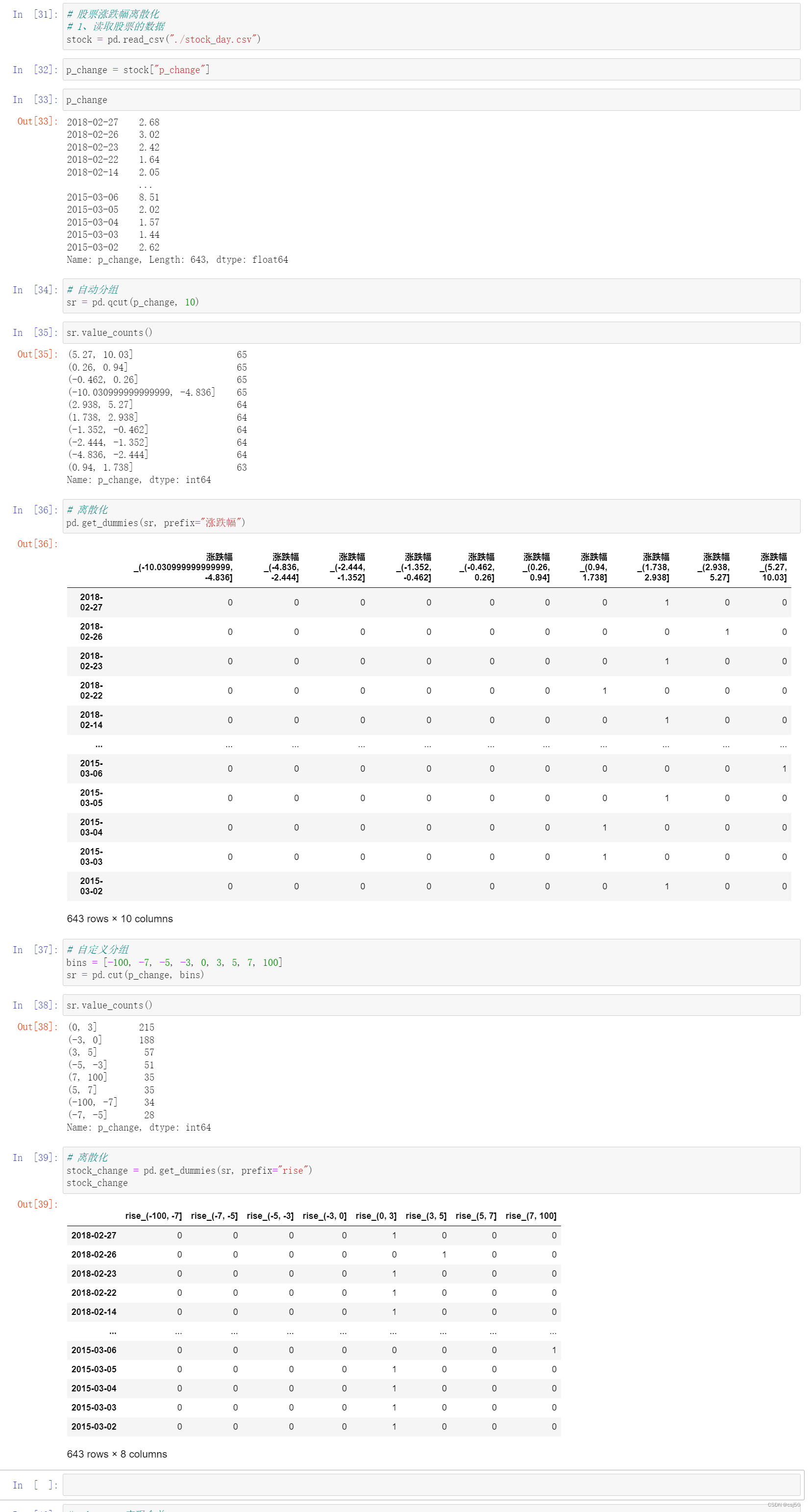
数据分析基础之《pandas(6)—高级处理》
一、缺失值处理 1、如何处理nan 两种思路: (1)如果样本量很大,可以删除含有缺失值的样本 (2)如果要珍惜每一个样本,可以替换/插补(计算平均值或中位数) 2、判断数据是否…...

IOS破解软件安装教程
对于很多iOS用户而言,获取软件的途径显得较为单一,必须通过App Store进行下载安装。 这样的限制,时常让人羡慕安卓系统那些自由下载各类版本软件的便捷。 心中不禁生出疑问:难道iOS世界里,就不存在所谓的“破解版”软件…...
[缓存] - 1.缓存共性问题
1. 缓存的作用 为什么需要缓存呢?缓存主要解决两个问题,一个是提高应用程序的性能,降低请求响应的延时;一个是提高应用程序的并发性。 1.1 高并发 一般来说, 如果 10Wqps,或者20Wqps ,可使用分布…...
Python爬虫——解析库安装(1)
目录 1.lxml安装2.Beautiful Soup安装3.pyquery 的安装 我创建了一个社区,欢迎大家一起学习交流。社区名称:Spider学习交流 注:该系列教程已经默认用户安装了Pycharm和Anaconda,未安装的可以参考我之前的博客有将如何安装。同时默…...

从鼠类到人体:汉坦病毒的全球威胁与科研突破
2026年5月17日,加拿大正式确诊一名“洪迪厄斯”号邮轮乘员感染汉坦病毒。结合世界卫生组织(WHO)的通报,疫情已陆续造成9人感染并出现3例死亡。这引起广泛的关注和担忧。汉坦病毒究竟是哪类病毒呢?感染力强吗࿱…...

知识库搭建:从认知到实践的完整指南
知识库搭建:从认知到实践的完整指南一、先搞清楚:什么是知识? 数据 → 信息 → 知识 → 智慧 是经典的 DIKW 金字塔,描述了认知逐层升维的过程:层级核心定义关键特征回答的问题示例数据原始事实,raw facts离…...

告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡
告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡 在手机摄影普及的今天,我们常常会遇到这样的困扰:夜间拍摄的照片要么噪点明显,要么经过降噪处理后变得模糊不清,丢失了细节…...

B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理
B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容反复…...

ME_PURCHDOC_POSTED
创建采购订单时常用的保存增强ME_PROCESS_PO_CUST~POST里是没有订单号的可以使用ME_PURCHDOC_POSTED来做相关处理...

VisualHMI灵敏度调校全攻略:从触摸校准到性能优化
1. 项目概述:从“调参”到“调感”的界面设计进阶在工业HMI(人机界面)开发领域,尤其是使用像VisualHMI这类图形化设计软件时,“调节灵敏度”这个需求,远不止是拖动一个滑块、输入一个数值那么简单。它背后牵…...

别再傻傻用FFT了!用MATLAB的czt函数5分钟搞定频谱细化,精准定位98Hz和99Hz信号
别再被FFT分辨率坑了!MATLAB工程师的频谱细化实战指南 当你在分析一段包含98Hz和99Hz混合信号的频谱时,是否遇到过这样的尴尬:明明知道有两个频率成分存在,但FFT给出的结果却像被打了马赛克,两个峰值糊成一团…...

告别Xshell:免费利器FinalShell的Linux远程连接与高效运维实战
1. 为什么选择FinalShell替代Xshell? 作为长期使用Xshell的老用户,我完全理解大家对这款经典SSH客户端的依赖。但最近两年,我逐渐将团队的所有运维工作迁移到了FinalShell。这个决定不仅帮我们省下了每年数千元的软件授权费用,更重…...

Overleaf实战:利用multicol宏包实现LaTeX文档的灵活分栏布局
1. 为什么需要分栏布局? 第一次用LaTeX写论文时,我被期刊模板要求"双栏排版"整懵了。单栏文档写得好好的,突然要在同一页并排显示两列内容,还要处理图片表格的跨栏问题。传统\twocolumn命令虽然简单,但调整…...

Windows远程桌面终极解锁指南:RDP Wrapper Library完整使用教程
Windows远程桌面终极解锁指南:RDP Wrapper Library完整使用教程 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面功能而烦恼吗?RDP Wrapper Library是您…...