[缓存] - 1.缓存共性问题
1. 缓存的作用
为什么需要缓存呢?缓存主要解决两个问题,一个是提高应用程序的性能,降低请求响应的延时;一个是提高应用程序的并发性。
1.1 高并发
一般来说, 如果 10Wqps,或者20Wqps ,可使用分布式缓存来抗。
比如redis集群,6主6从:主提供读写,从作为备,从不提供读写服务。
6主6从架构下,1台平均抗3w-4W并发,还可以抗住 18Wqps -24Wqps。
并且,如果QPS达到100w,通过增加redis集群中的机器数量,可以扩展缓存的容量和并发读写能力。6主6从的架构,可以扩容到 30主30从。
2. 缓存的分类
本地缓存,分布式缓存,多级缓存
3. 缓存数据分类
3.1 数据缓存
程序数据直接缓存,不需要经过计算。这种类型的缓存并不需要耗费计算性能。例如缓存用户信息。
3.2 结果缓存
程序数据并不能直接缓存,需要经过计算,或者连表查询等,将计算后的结果进行缓存,因此缓存的更新可能是昂贵的。比如缓存的报表数据。
4. 缓存过期策略
缓存使用的是内存,内存是有限的,通常无法将所有的数据都进行缓存,因此,当需要缓存的数据超过内存的大小时,需要将部分的缓存数据从缓存中踢出出去。
在有限的空间内,保留尽可能多的会经常访问的entry,过期策略就显得特别重要。常见的过期策略包括TTL,Random,LFU,LRU等。
5. 缓存模式
Cache Aside
Read/Write Through
Write Behind
| No | 缓存不一致 | 优点 | 缺点 | 适用场景 |
| CacheAside | Y | 实现比较简单 | 需要维护两个数据存储,存在分布式事务问题 | 延时要低,能容忍数据丢失和数据不一致 |
| Read/Write Through | N | 使用简单 只需要关心缓存,数据写sh入数据库由框架完成,不需要处理分布式事务问题 | 延时高 | 同步操作,数据保证一致性 |
| Write Behind | Y | 延时低 | 数据丢失和数据不一致 | 延时要低,能容忍数据丢失和数据不一致 |
6. 缓存的数据一致性问题
6.1 CacheAside数据不一致问题
(1)出现原因
1)缓存更新(含缓存新增)时,操作数据库和缓存时,一个成功,一个失败;
2)更新和query并发
(2)解决方案
为什么是删除缓存?
很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个例子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
解决方案一般包括:
1)更新数据库 + 删除缓存(优于2)
2)删除缓存 + 更新数据库
3)删除缓存 + 更新数据库 + sleep + 删除缓存
4)更新数据库 + 删除缓存消息入mq/binlog消息入mq + 监听消息删除缓存
5)分布式事务解决机制。
7. 分布式缓存常见问题
7.1 缓存击穿
定义:缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
解决方案:
- 若缓存的数据是基本不会发生更新的,则可尝试设置热点数据永远不过期;
- 采用多级缓存架构,热点数据,肯定数据量不大,可以使用 本地缓存;
- 若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到对应的缓存;
- 若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下可以加互斥锁,保障缓存中的数据,被第一次请求回填。此方案不适用于超高并发场景。
7.2 缓存穿透
定义:缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
解决方案:
1、**接口校验**:在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2、缓存空值:当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3、hashmap记录存在性:存在去查redis,不存在直接返回。
4、布隆过滤器:使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
7.3 缓存雪崩
定义:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
解决方案:
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃;过期时间打散,热点数据不过期;
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
7.4 BigKey
7.4.1 定义
Big Key就是某个key对应的value很大,占用的redis空间很大,本质上是大value问题。
7.4.2 产生原因
- 1. 数据结构使用不恰当
- 2. 未及时清理垃圾数据
- 3. 对业务预估不准确
- 4. 热点数据列表
7.4.3 危害
1、阻塞请求、
2、内存增大
3、阻塞网络
4、影响主从同步、主从切换
7.4.4 bigKey识别
7.4.5 解决方案
1、对大Key进行拆分
2、对大Key进行清理
3、监控Redis的内存、网络带宽、超时等指标
4、定期清理失效数据
5、压缩value
7.5 HotKey
某些key访问量特别大,这种情况下,由于这些key只有一份,无法通过横向扩展进行进一步负载均衡。解决方案包括:
(1)二级缓存
通过本地缓存来解决。
(2)增加分布式缓存的冗余
通常一个缓存在分布式缓存中只有一份,通过多设置几份冗余数据,分布到不同的节点上来进行负载均衡。
(3)限流
HotKey很难预测,限流是兜底方案。
8. 多级缓存
通常包括二级缓存和三级缓存。
8.1 二级缓存
8.1.1 本地缓存
本地缓存可以解决以下问题:
(1)延时要求极高
因为本地缓存的访问速度最快
(2)hotKey问题
hotkey分布式缓存不能通过横向扩展来解决
(3)带宽限制
数据分摊到不同的缓存节点,但这成本比本地缓存高很多
8.1.2 多级缓存的数据一致性
不能使用删除策略,因为本地缓存一般是热点数据,删除会导致缓存击穿。
8.1.3 多级缓存注意事项
由于本地缓存会占用 Java 进程的 JVM 内存空间,因此不适合存储大量数据,需要对缓存大小进行评估。
如果业务能够接受短时间内的数据不一致,那么本地缓存更适用于读取场景。
在缓存更新策略中,无论是主动更新还是被动更新,本地缓存都应设置有效期。
考虑设置定时任务来同步缓存,以防止极端情况下数据丢失。
在 RPC 调用中,需要避免本地缓存被污染,可以通过合理的缓存淘汰策略,来解决这个问题。
当应用重启时,本地缓存会失效,因此需要注意加载分布式缓存的时机。
通过发布/订阅解决数据一致性问题时,如果发布/订阅模式不持久化消息数据,如果消息丢失, 本地缓存就会删除失败。 所以,要解决发布订阅消息的高可用问题。
当本地缓存失效时,需要使用 synchronized 进行加锁,确保由一个线程加载 Redis 缓存,避免并发更新。-- 不适合高并发场景
8.2 三级缓存
L3级缓存的数据一致性保障以及防止缓存击穿方案:
1.数据预热(或者叫预加载)
2.设置热点数据永远不过期,通过 ngx.shared.DICT的缓存的LRU机制去淘汰
3.如果缓存主动更新,在快过期之前更新,如有变化,通过订阅变化的机制,主动本地刷新
4.提供兜底方案,如果本地缓存没有,则通过后端服务获取数据,然后缓存起来
9. 分布式缓存结构问题
分布式缓存架构需要解决本身的一些架构问题:
(1)高可用
主从,集群,并由此带来的主从数据复制,数据分片,选举,数据丢失等问题。
(2)高并发
负载均衡:请求响应均衡,数据分布均衡
(3)高性能
序列化,压缩,集群间通信,一致性协议
(4)监控
命中率,内存,cpu,健康状态
9.1 数据分片
(1)Range分片
常用在关系型数据库的设计。
比如:1到100个数字,要保存在3个节点上,按照顺序分区,把数据平均分配成三个片段
-
1号到33号数据为 片段1
-
34号到66号数据为 片段2
-
67号到100号数据为 片段3

(2)节点取余分片
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上。
缺点:
当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分片。
建议:
建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据。
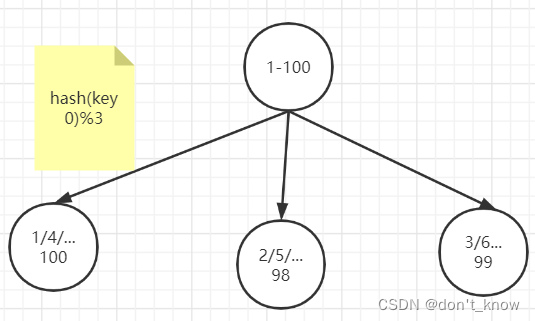
(3)一致性哈希分区
步骤:构造一致性哈希环、节点映射、路由规则。
1)构造一致性哈希环
通过哈希算法,将哈希值映射到哈希空间([0, 2^32])。
2)节点映射
将集群中的各节点映射到环上的某个一位置。比如集群中有三个节点,那么可以大致均匀的将其分布在环上。
3)路由规则
路由规则包括存储(setX)和取值(getX)规则。
当需要存储一个对时,首先计算键key的hash值:hash(key),这个hash值必然对应于一致性hash环上的某个位置,然后沿着这个值按顺时针找到第一个节点,并将该键值对存储在该节点上。
缺点:数据倾斜,不能对所有节点进行负载均衡
(4)虚拟槽分区
为了在增删节点的时候,各节点能够保持动态的均衡,将每个真实节点虚拟出若干个虚拟节点,再将这些虚拟节点随机映射到环上。此时每个真实节点不再映射到环上,真实节点只是用来存储键值对,它负责接应各自的一组环上虚拟节点。当对键值对进行存取路由时,首先路由到虚拟节点上,再由虚拟节点找到真实的节点。增加虚拟节点其实是减小了路由规则过程中的粒度,使每个真实节点可以分摊局部压力。
9.2 负载均衡
当客户端发起请求时,需要选取一个适当的缓存节点来处理。这就需要负载均衡算法的介入,该算法可以根据当前系统的负载情况、网络拓扑结构等因素,来选择最适合处理该请求的节点。这样,既可以保证客户端请求的及时响应,也能避免某个节点压力过大,影响系统的整体运行。
9.3 容错处理
在分布式环境下,由于网络通信等问题,可能会导致缓存节点间的故障。为了提高系统的可用性,需要设计一些容错机制。例如,数据备份可以防止数据丢失,故障转移可以确保即使某个节点出现问题,系统也能继续运行。这些容错机制,可以有效地提高系统的稳定性和可靠性。
9.4 数据一致性
由于数据在多个节点上进行分布存储,因此需要确保数据的一致性。为了实现这一目标,需要采用一些协议和算法来处理并发读写操作。例如,可以使用分布式事务协议来确保数据的原子性和一致性,或者使用乐观锁算法来避免并发写操作的冲突。这些手段,都可以有效地保证数据的一致性,确保系统的正确运行。
相关文章:
[缓存] - 1.缓存共性问题
1. 缓存的作用 为什么需要缓存呢?缓存主要解决两个问题,一个是提高应用程序的性能,降低请求响应的延时;一个是提高应用程序的并发性。 1.1 高并发 一般来说, 如果 10Wqps,或者20Wqps ,可使用分布…...
Python爬虫——解析库安装(1)
目录 1.lxml安装2.Beautiful Soup安装3.pyquery 的安装 我创建了一个社区,欢迎大家一起学习交流。社区名称:Spider学习交流 注:该系列教程已经默认用户安装了Pycharm和Anaconda,未安装的可以参考我之前的博客有将如何安装。同时默…...
中科大计网学习记录笔记(十一):CDN
前言: 学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程 该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信…...
[缓存] - 2.分布式缓存重磅中间件 Redis
1. 高性能 尽量使用短key 不要存过大的数据 避免使用keys *:使用SCAN,来代替 在存到Redis之前压缩数据 设置 key 有效期 选择回收策略(maxmemory-policy) 减少不必要的连接 限制redis的内存大小(防止swap,OOM) slowLog …...
)
1191. 家谱树(拓扑排序,模板题)
活动 - AcWing 有个人的家族很大,辈分关系很混乱,请你帮整理一下这种关系。 给出每个人的孩子的信息。 输出一个序列,使得每个人的孩子都比那个人后列出。 输入格式 第 11 行一个整数 n,表示家族的人数; 接下来 …...

CSS之BFC
BFC概念 BFC(Block Formatting Context)即块级格式化上下文,是Web页面的可视CSS渲染的一部分。它是一个独立的渲染区域,让其中的元素在布局上与外部的元素互不影响。简单来说,BFC提供了一个环境,允许内部的…...

2024 年合并 PDF 文件的免费 PDF 合并软件榜单
合并 PDF 是当今人们寻找的最重要的功能之一。在本文中,您将了解前五名的 PDF 合并软件以及详细的介绍,以便您选择最佳的。如果您想将所有重要信息都放在一个文件中,而不是在不同的文件中查找,那么合并 PDF 文件是必要的。通过这种…...

Python教程56:海龟画图turtle画kitty猫
---------------turtle源码集合--------------- Python教程91:关于海龟画图,Turtle模块需要学习的知识点 Python教程51:海龟画图turtle画(三角形、正方形、五边形、六边形、圆、同心圆、边切圆,五角星,椭…...

c入门第十篇——指针入门
一句话来说: 指针就是存储了内存地址值的变量。 在前面讨论传值和传址的时候,我们就已经开始使用了指针来传递地址。 在正式介绍指针之前,我们先来简单了解一下内存。内存可以简单的理解为一排连续的房子的街道,每个房子都有自己的地址&#…...
ret2syscall)
pwn学习笔记(3)ret2syscall
pwn学习笔记(3) ROP原理: ROP(Return Oriented Programming)返回导向编程,主要思想是通过在程序中已有的小片段(gadgets)来改变某些寄存器或者变量的值,从而控制程序的执行流程。 栈溢出–…...

React18原理: 生命周期中特别注意事项
概述 生命周期就是一个组件从诞生到销毁的全过程(包含错误捕获,这里暂且不聊这个)react 在组件的生命周期中注册了一系列的钩子函数支持开发者在其中嵌入代码,并在适当的时机运行生命周期本质上就是组件中的钩子函数,主要有三个主要的钩子 挂…...

【C语言】Linux内核bind系统调用代码
一、Linux 4.9内核bind系统调用代码注释 int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen) {struct socket *sock; // 定义socket对象的指针struct sockaddr_storage address; // 用于存储从用户空间复制过来的地址int err…...
Ubuntu下Anaconda+PyCharm搭建PyTorch环境
这里主要介绍在condapytorch都正确安装的前提下,如何通过pycharm建立开发环境; Ubuntu下AnacondaPyCharm搭建PyTorch环境 系统环境:Ubuntu22.04 conda: conda 23.11.0 pycharm:如下 condapytorch的安装教程介绍,请点击这里&…...
酷开科技荣获“消费者服务之星”称号后的未来展望
恭喜酷开科技荣获2023年第四季度黑猫平台“消费者服务之星”称号!这是对酷开科技长期以来坚持用户至上、用心服务的肯定和认可。作为OTT行业的佼佼者,酷开科技一直秉承着“以用户为中心”的服务理念,不断追求卓越品质,为用户提供更…...

UVA1449 Dominating Patterns 题解
UVA1449 Dominating Patterns 题解 板子题诶。 解法 AC 自动机模板题,因为数据范围比较小,所以不加拓扑排序优化建图即可通过本题。这里简单介绍一下拓扑排序优化建图。 在查找时,每次都暴力的条 f a i l fail fail 指针是很消耗时间的&…...
【C语言】数据结构#实现堆
目录 (一)堆 (1)堆区与数据结构的堆 (二)头文件 (三)功能实现 (1)堆的初始化 (2)堆的销毁 (3)插入数据 …...
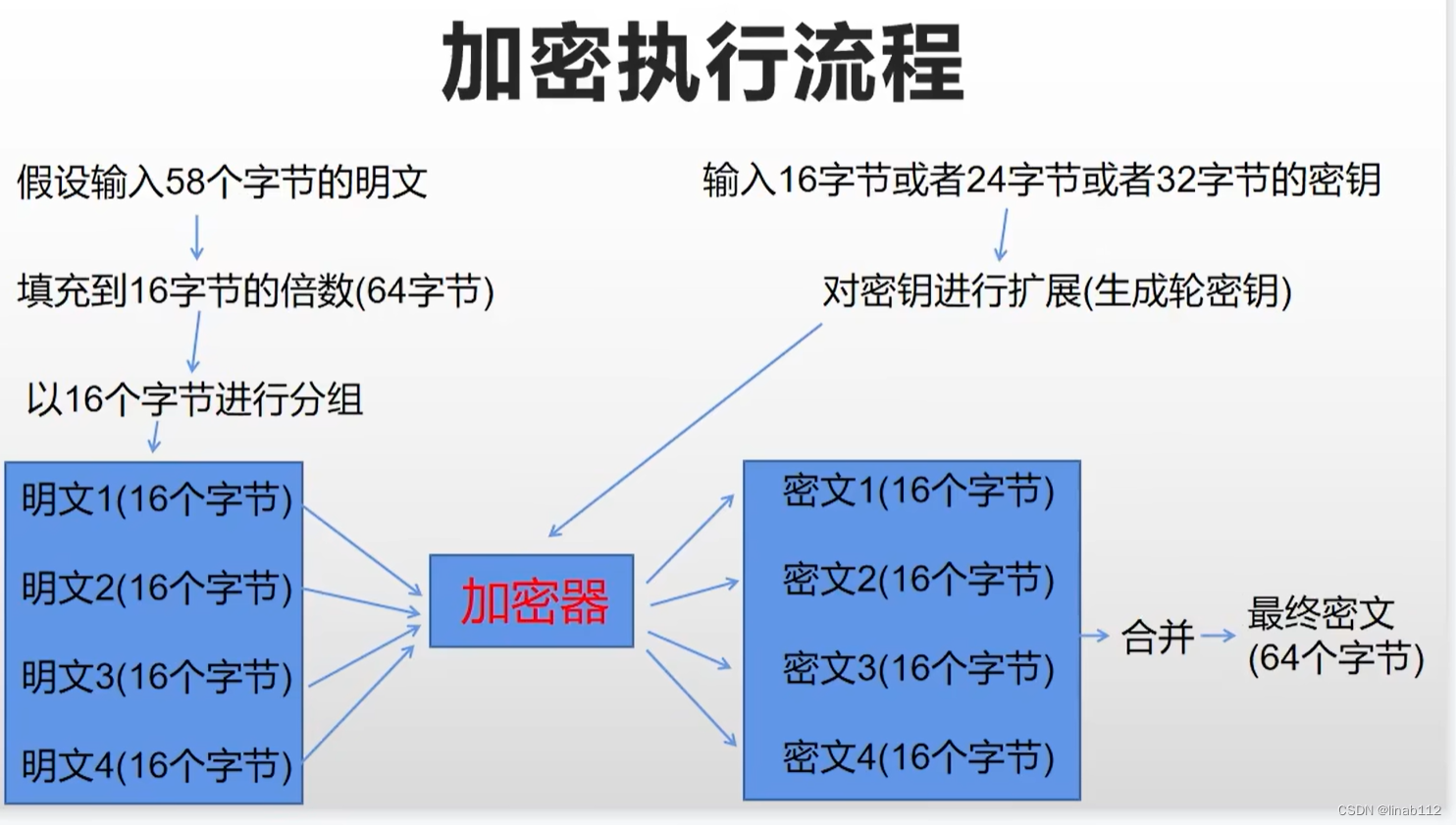
AES加密中的CBC和ECB
目录 1.说明 2.ECB模式(base64) 3.CBC模式 4.总结 1.说明 AES是常见的对称加密算法,加密和解密使用相同的密钥,流程如下: 主要概念如下: ①明文 ②密钥 用来加密明文的密码,在对称加密算…...

【C++】类和对象(四)
前言:在类和对象中,我们走过了十分漫长的道路,今天我们将进一步学习类和对象,类和对象这块荆棘地很长,各位一起加油呀。 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:高质量&a…...

XGB-5: DART Booster
XGBoost 主要结合了大量的回归树和一个小的学习率。在这种情况下,早期添加的树是重要的,而晚期添加的树是不重要的。 Vinayak 和 Gilad-Bachrach 提出了一种将深度神经网络社区的 dropout 技术应用于梯度提升树的新方法,并在某些情况下报告了…...
HiveSQL——不使用union all的情况下进行列转行
参考文章: HiveSql一天一个小技巧:如何不使用union all 进行列转行_不 union all-CSDN博客文章浏览阅读881次,点赞5次,收藏10次。本文给出一种不使用传统UNION ALL方法进行 行转列的方法,其中方法一采用了concat_wsposexplode()方…...

别再轮询了!在Qt里用HIDAPI实现USB设备通信,试试这个异步读取方案
告别轮询:在Qt中实现高效USB-HID异步通信的现代方案 当开发者需要在Qt应用中与USB-HID设备通信时,传统的轮询方式往往会导致UI卡顿、CPU资源浪费等问题。本文将介绍几种更优雅的异步通信方案,充分利用Qt的事件循环机制,实现高效、…...

如何新建自己的应用
建议步骤如下。 1 创建 WPF 项目 项目文件至少包含: <TargetFramework>net7.0-windows</TargetFramework> <UseWPF>true</UseWPF>2 引用基础库 至少引用: HeBianGu.Base.WpfBaseHeBianGu.General.WpfControlLib 根据需要再…...

EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践
EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践 【免费下载链接】epubcheck The conformance checker for EPUB publications 项目地址: https://gitcode.com/gh_mirrors/ep/epubcheck EPUBCheck作为EPUB出版物的官方一致性检查工具,其强…...

【亲测免费】 探索U-Net多类别图像分割:基于PyTorch的开源利器
探索U-Net多类别图像分割:基于PyTorch的开源利器 【下载地址】U-Net多类别训练代码基于PyTorch 本仓库提供了一个基于PyTorch实现的U-Net模型代码,适用于多类别图像分割任务。你可以使用该代码训练自己的数据集,实现对图像中不同类别的精确分…...

长期项目使用Taotoken Token Plan套餐的成本控制实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken Token Plan套餐的成本控制实际体验 1. 项目背景与成本挑战 在为期数月的AI应用开发项目中,我们…...

深入SmoothL1Loss:从Faster R-CNN到YOLO,看一个损失函数如何影响模型精度
深入解析SmoothL1Loss:目标检测模型中的边框回归利器 在目标检测领域,边框回归(Bounding Box Regression)是决定模型定位精度的关键环节。当我们翻阅Faster R-CNN、YOLOv3等经典模型的源码时,会发现一个反复出现的损失…...
)
保姆级教程:用R包MaAsLin2搞定微生物组与临床数据的关联分析(附完整代码)
微生物组与临床数据关联分析实战:MaAsLin2从入门到精通 在微生物组研究中,揭示菌群变化与宿主表型之间的关联是核心科学问题之一。传统统计方法往往难以应对高维稀疏的微生物组数据特性,而专门设计的工具如MaAsLin2(Microbiome Mu…...

try-catch到底有没有性能开销
有一种说法是”try-catch 有性能开销,关键路径上不要用”。另一种说法是”try-catch 不抛异常的话没有开销”。这两种说法都不全对,开销在哪里要看具体用法。try-catch 本身不贵,异常对象才贵JVM 里,try-catch 的实现方式是在字节…...

[笔记] 系统分析师 目录
文章目录系统分析师 第一章 绪论系统分析师 第二章 经济管理与应用数学系统分析师 第三章 操作系统基本原理系统分析师 第四章 数据通信与计算机网络系统分析师 第五章 数据库系统系统分析师 第六章 系统配置与性能评价系统分析师 第七章 企业信息化系统分析师 第八章 软件工程…...

基于Arduino与VS1053的宠物智能服装DIY:嵌入式系统集成实践
1. 项目概述与核心思路给宠物做一件会发光、会发声的智能服装,听起来像是科幻电影里的情节,但用今天触手可及的硬件和开源工具,这完全是一个可以亲手实现的周末项目。这个项目的核心,是将一个微小的“智能大脑”和一套声光系统&am…...