XGB-5: DART Booster
XGBoost 主要结合了大量的回归树和一个小的学习率。在这种情况下,早期添加的树是重要的,而晚期添加的树是不重要的。
Vinayak 和 Gilad-Bachrach 提出了一种将深度神经网络社区的 dropout 技术应用于梯度提升树的新方法,并在某些情况下报告了更好的结果。
以下是新的树增强器 dart 的说明。
原始论文
Rashmi Korlakai Vinayak, Ran Gilad-Bachrach。“DART: Dropouts meet Multiple Additive Regression Trees.” [arXiv]。
特性
- 通过删除树来解决过拟合问题。
- 可以阻止不重要的普通树(以纠正普通错误)
由于训练中引入的随机性,可以期待以下一些差异:
-
由于随机丢弃dropout会阻止使用预测缓冲区,因此训练可能比
gbtree慢 -
由于随机性,早停Early-stop可能不稳定
工作原理
-
在第 m m m训练轮次中,假设 k k k棵树被选中丢弃。
-
令 D = ∑ i ∈ K F i D = \sum_{i \in \mathbf{K}} F_i D=∑i∈KFi为被丢弃树的叶节点分数, F m = η F ~ m F_m = \eta \tilde{F}_m Fm=ηF~m为新树的叶节点分数。
-
目标函数如下:
O b j = ∑ j = 1 n L ( y j , y ^ j m − 1 − D j + F ~ m ) Ω ( F ~ m ) . \mathrm{Obj} = \sum_{j=1}^n L \left( y_j, \hat{y}_j^{m-1} - D_j + \tilde{F}_m \right)\Omega \left( \tilde{F}_m \right). Obj=j=1∑nL(yj,y^jm−1−Dj+F~m)Ω(F~m).
- D D D和 F m F_m Fm是超调,因此使用缩放因子
y ^ j m = ∑ i ∉ K F i + a ( ∑ i ∈ K F i + b F m ) . \hat{y}_j^m = \sum_{i \not\in \mathbf{K}} F_i + a \left( \sum_{i \in \mathbf{K}} F_i + b F_m \right) . y^jm=i∈K∑Fi+a(i∈K∑Fi+bFm).
参数
Booster dart 继承自 gbtree booster,因此支持 gbtree 的所有参数,比如 eta、gamma、max_depth 等。
以下是额外的参数:
-
sample_type:采样算法的类型。uniform:(默认)以均匀方式选择要删除的树。weighted:以权重比例选择要删除的树。
-
normalize_type:规范化算法的类型。-
tree:(默认)新树的权重与每个被删除的树相同。
a ( ∑ i ∈ K F i + 1 k F m ) = a ( ∑ i ∈ K F i + η k F ~ m ) ∼ a ( 1 + η k ) D = a k + η k D = D , a = k k + η \begin{split}a \left( \sum_{i \in \mathbf{K}} F_i + \frac{1}{k} F_m \right) &= a \left( \sum_{i \in \mathbf{K}} F_i + \frac{\eta}{k} \tilde{F}_m \right) \\ &\sim a \left( 1 + \frac{\eta}{k} \right) D \\ &= a \frac{k + \eta}{k} D = D , \\ &\quad a = \frac{k}{k + \eta}\end{split} a(i∈K∑Fi+k1Fm)=a(i∈K∑Fi+kηF~m)∼a(1+kη)D=akk+ηD=D,a=k+ηk
-
forest:新树的权重等于被删除的树的权重之和(森林)。
a ( ∑ i ∈ K F i + F m ) = a ( ∑ i ∈ K F i + η F ~ m ) ∼ a ( 1 + η ) D = a ( 1 + η ) D = D , a = 1 1 + η . \begin{split}a \left( \sum_{i \in \mathbf{K}} F_i + F_m \right) &= a \left( \sum_{i \in \mathbf{K}} F_i + \eta \tilde{F}_m \right) \\ &\sim a \left( 1 + \eta \right) D \\ &= a (1 + \eta) D = D , \\ &\quad a = \frac{1}{1 + \eta} .\end{split} a(i∈K∑Fi+Fm)=a(i∈K∑Fi+ηF~m)∼a(1+η)D=a(1+η)D=D,a=1+η1.
-
-
dropout_rate: 丢弃率。
- 范围:[0.0, 1.0]
-
skip_dropout: 跳过丢弃的概率。
- 如果跳过了dropout,新树将以与 gbtree 相同的方式添加。
- 范围:[0.0, 1.0]
示例
import xgboost as xgb# read in data
dtrain = xgb.DMatrix('./xgboost/demo/data/agaricus.txt.train?format=libsvm')
dtest = xgb.DMatrix('./xgboost/demo/data/agaricus.txt.test?format=libsvm')# specify parameters via map
param = {'booster': 'dart','max_depth': 5, 'learning_rate': 0.1,'objective': 'binary:logistic','sample_type': 'uniform','normalize_type': 'tree','rate_drop': 0.1,'skip_drop': 0.5}num_round = 50
bst = xgb.train(param, dtrain, num_round)
preds = bst.predict(dtest)
参考
- https://xgboost.readthedocs.io/en/latest/tutorials/dart.html
- https://arxiv.org/abs/1505.01866
相关文章:

XGB-5: DART Booster
XGBoost 主要结合了大量的回归树和一个小的学习率。在这种情况下,早期添加的树是重要的,而晚期添加的树是不重要的。 Vinayak 和 Gilad-Bachrach 提出了一种将深度神经网络社区的 dropout 技术应用于梯度提升树的新方法,并在某些情况下报告了…...
HiveSQL——不使用union all的情况下进行列转行
参考文章: HiveSql一天一个小技巧:如何不使用union all 进行列转行_不 union all-CSDN博客文章浏览阅读881次,点赞5次,收藏10次。本文给出一种不使用传统UNION ALL方法进行 行转列的方法,其中方法一采用了concat_wsposexplode()方…...
Python环境下基于指数退化模型和LSTM自编码器的轴承剩余寿命预测
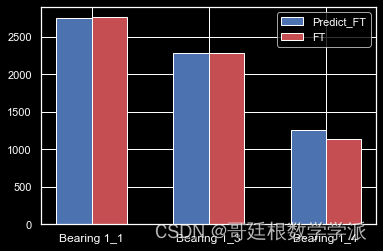
滚动轴承是机械设备中关键的零部件之一,其可靠性直接影响了设备的性能,所以对滚动轴承的剩余使用寿命(RUL)进行预测是十分必要的。目前,如何准确地对滚动轴承剩余使用寿命进行预测,仍是一个具有挑战的课题。对滚动轴承剩余寿命评估…...
)
无人机竞赛视觉算法开发流程开源计划(询问大家意见)
本科中参加过一系列的无人机机器人竞赛,像电赛、工训赛、机器人大赛这些,有一些比较常用的方案打算开源一下。现在读研了,也算是对本科的一个总结,但是还是想看看大家意见,大家有什么需求可以在评论区说,我…...
DMA直接内存访问,STM32实现高速数据传输使用配置
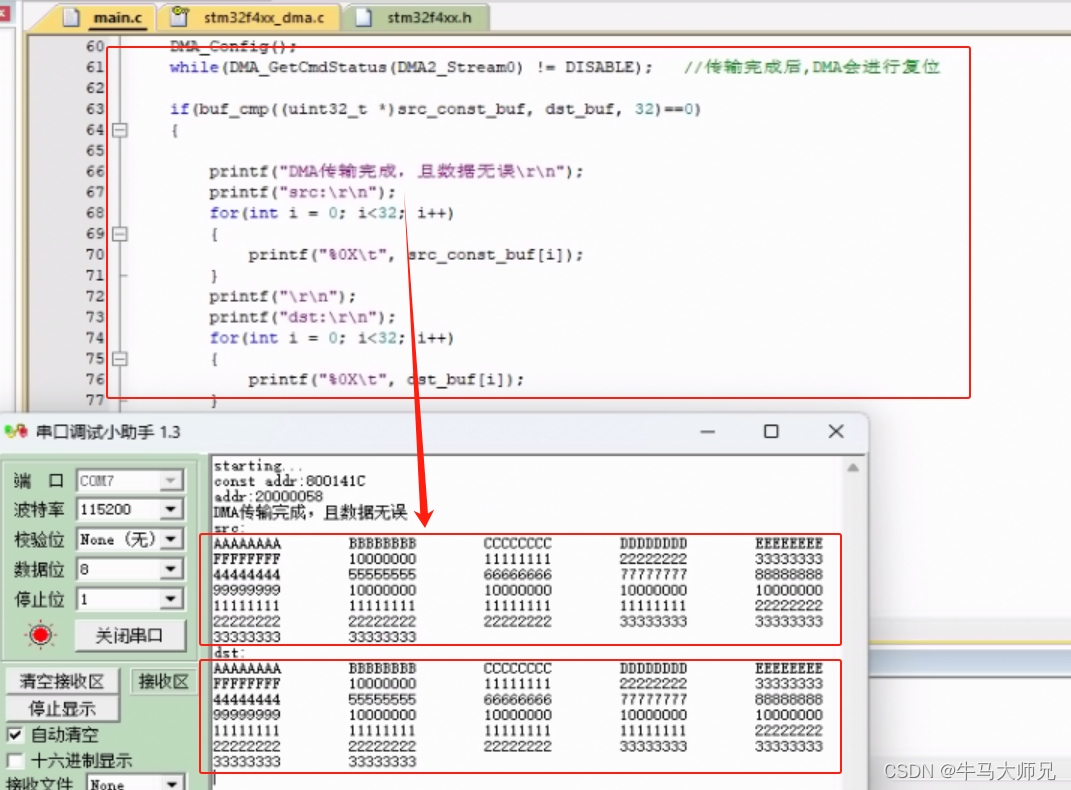
1、DMA运用场景 随着智能化、信息化的不断推进,嵌入式设备的数据处理量也呈现指数级增加,因此对于巨大的数据量处理的情况时,必须采取其它的方式去替CPU减负,以保证嵌入式设备性能。例如SD卡存储器和音视频、网络高速通信等其它情…...
Web安全研究(六)
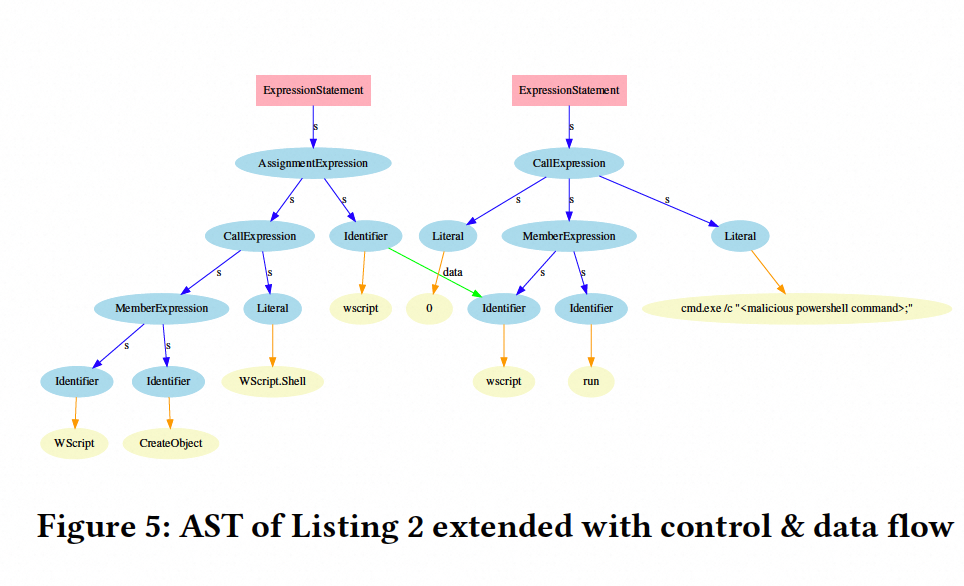
文章目录 HideNoSeek: Camouflaging(隐藏) Malicious JavaScript in Benign ASTs文章结构Introjs obfuscationmethodologyExample HideNoSeek: Camouflaging(隐藏) Malicious JavaScript in Benign ASTs CCS 2019 CISPA 恶意软件领域,基于学习的系统已经非常流行&am…...

python3 中try 异常调试 raise 异常抛出
一、什么是异常? 异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。 一般情况下,在Python无法正常处理程序时就会发生一个异常。 异常是Python对象,表示一个错误。 当Python脚本发生异常时我…...
Java中的序列化是什么?如何实现对象的序列化和反序列化?请解释Serializable接口的作用是什么?请解释transient关键字的作用是什么?为什么会使用它?
Java中的序列化是指将对象转换为字节序列的过程,以便可以在网络上传输或将其保存到持久存储介质中。反序列化则是将字节序列重新转换回对象的过程。Java提供了一种称为序列化(Serialization)的机制来实现对象的序列化和反序列化。 要实现对象…...

二维差分---三维差分算法笔记
文章目录 一.二维差分构造差分二维数组二维差分算法状态dp求b[i][j]数组的二维前缀和图解 二.三维前缀和与差分三维前缀和图解:三维差分核心公式图解:模板题 一.二维差分 给定一个原二维数组a[i][j],若要给a[i][j]中以(x1,y1)和(x2,y2)为对角线的子矩阵中每个数都加上一个常数…...

D. Divisible Pairs
思路:我们预处理出每个数分别摸上xy的值,用map存一下,然后遍历每个数,如果a b是x的倍数的话,那么他们模x的值相加为x,如果a - b是y的倍数的话,那么他们的模y的值相等。 代码: voi…...

【教程】Kotlin语言学习笔记(二)——数据类型(持续更新)
写在前面: 如果文章对你有帮助,记得点赞关注加收藏一波,利于以后需要的时候复习,多谢支持! 【Kotlin语言学习】系列文章 第一章 《认识Kotlin》 第二章 《数据类型》 文章目录 【Kotlin语言学习】系列文章一、基本数据…...

react 插槽
问题开发当中会经常出现组件十分相似的组件,只有一部分是不同的 解决: 父组件:在引用的时候 import { Component } from "react"; import Me from "../me";const name <div>名称</div> class Shoop extends Compone…...

Linux运用fork函数创建进程
fork函数: 函数原型: pid_t fork(void); 父进程调用fork函数创建一个子进程,子进程的用户区父进程的用户区完全一样,但是内核区不完全一样;如父进程的PID和子进程的PID不一样。 返回值: RETURN VALUEO…...

Pytest测试技巧之Fixture:模块化管理测试数据
在 Pytest 测试中,有效管理测试数据是提高测试质量和可维护性的关键。本文将深入探讨 Pytest 中的 Fixture,特别是如何利用 Fixture 实现测试数据的模块化管理,以提高测试用例的清晰度和可复用性。 什么是Fixture? 在 Pytest 中&a…...

设计模式-职责链模式Chain of Responsibility
职责链模式 一、原理和实现二、实现方式1) 使用链表实现2) 使用数组实现3) 扩展 作用:复用和扩展,在实际的项目开发中比较常用。在框架开发中,我们也可以利用它们来提供框架的扩展点,能够让框架的使用者在不修改框架源码的情况下&…...

书生浦语大模型实战营-课程作业(3)
下载sentence_transformer的代码运行情况。sentence_transformer用于embedding(转向量) 本地构建持久化向量数据库。就是把txt和md文件抽取出纯文本,分割成定长(500)后转换成向量,保存到本地,称…...

考研英语单词25
Day 25 bench n.长凳 elastic n.橡皮圈,松紧带 a.灵活的 “e-last 延伸出去” disaster n.灾难,灾祸【disastrous a.灾难性的,极坏的】 deadly a.致命的,极端的,势不两立的 hike n.徒步旅行&…...

计算机网络——08应用层原理
应用层原理 创建一个新的网络 编程 在不同的端系统上运行通过网络基础设施提供的服务,应用进程批次通信如Web Web服务器软件与浏览器软件通信 网络核心中没有应用层软件 网络核心没有应用层功能网络应用只能在端系统上存在 快速网络应用开发和部署 网络应用…...

面试计算机网络框架八股文十问十答第五期
面试计算机网络框架八股文十问十答第五期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)与缓存相关的HTTP请…...
拟合案例1:matlab积分函数拟合详细步骤及源码
本文介绍一下基于matlab实现积分函数拟合的过程。采用的工具是lsqcurvefit和nlinfit两个函数工具。关于包含积分运算的函数,这里可以分为两大类啊。我们用具体的案例来展示:一种是积分运算中不包含这个自变量,如下图的第一个公式,也就是说它这个积分运算只有R和Q这两个待定…...

如何免费获得119,376个英语单词的标准发音MP3?终极发音库下载指南
如何免费获得119,376个英语单词的标准发音MP3?终极发音库下载指南 【免费下载链接】English-words-pronunciation-mp3-audio-download Download the pronunciation mp3 audio for 119,376 unique English words/terms 项目地址: https://gitcode.com/gh_mirrors/e…...
)
大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开)
更多请点击: https://codechina.net 第一章:大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开) Perplexity(困惑度)并非仅是语言模型训练阶段的监控指标,而是当前大模型查询质量评估中…...
的显式与隐式设备管理对比)
PyTorch实战:多GPU环境下torch.cuda.set_device()的显式与隐式设备管理对比
1. 多GPU环境下的设备管理基础 当你在实验室或者公司服务器上看到多块GPU时,是不是既兴奋又有点无从下手?PyTorch为我们提供了多种方式来管理这些计算资源,但选择不当可能会带来意想不到的问题。让我们从一个实际场景开始:假设你正…...
)
C盘告急?手把手教你用mklink命令把Fusion 360挪到D盘(Win11保姆级教程)
拯救C盘空间:用符号链接将Fusion 360迁移到D盘的完整指南 当C盘空间告急时,很多用户会发现Fusion 360默认安装在系统盘,占用了大量宝贵空间。本文将详细介绍如何利用Windows的mklink命令,在不影响软件功能的前提下,将F…...
)
告别pip install torch:手把手教你离线安装PyTorch 1.5.1(含CUDA 9.2配置)
离线环境下的PyTorch 1.5.1实战部署指南:从依赖解析到CUDA配置 在科研机构封闭网络或企业开发环境中,离线安装深度学习框架往往成为阻碍项目推进的第一道门槛。PyTorch作为动态图计算的代表框架,其离线部署涉及Python环境管理、CUDA驱动适配…...

从Stable Diffusion到DALL-E 3:深入聊聊Diffusion Model里‘前向过程’的设计哲学与工程权衡
从Stable Diffusion到DALL-E 3:扩散模型前向过程的设计哲学与工程智慧 当你在MidJourney中输入一段文字描述,几秒后就能得到一张精美的图片,这背后隐藏着一场精心设计的"破坏与重建"游戏。扩散模型(Diffusion Model&…...

OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南
OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor OpenPLC Editor是一款基于Beremiz项目的开源工业自动化编程工具,为工程师和开发…...

单片机代码优化实战:从数据类型到算法与数据结构的效率提升
1. 项目概述:为什么单片机代码需要“斤斤计较”?如果你是从PC端或者服务器端开发转过来的朋友,第一次接触单片机编程,可能会觉得处处掣肘。在PC上,我们习惯了动辄几个G的内存,上百G的硬盘,CPU频…...

VPU与NPU协同优化:边缘AI视觉处理的算力融合实践
1. 项目概述:边缘计算时代的算力融合新范式最近和几个做嵌入式AI和边缘设备的老朋友聊天,大家不约而同地都在讨论一个话题:在资源受限的边缘端,如何把有限的算力“榨干”,让模型跑得更快、更省电。聊着聊着,…...

Office Custom UI Editor:终极指南:如何彻底改造你的Office工作界面?
Office Custom UI Editor:终极指南:如何彻底改造你的Office工作界面? 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/…...