数据分析基础之《pandas(6)—高级处理》
一、缺失值处理
1、如何处理nan
两种思路:
(1)如果样本量很大,可以删除含有缺失值的样本
(2)如果要珍惜每一个样本,可以替换/插补(计算平均值或中位数)
2、判断数据是否为nan
(1)pd.isnull(df)
返回一堆布尔值,False不是缺失值,True是缺失值
(2)pd.notnull(df)
返回一堆布尔值,True不是缺失值,False是缺失值
3、缺失值处理方式
存在缺失值nan,并且是np.nan
(1)dropna(axis='rows', inplace=False)
删除存在缺失值
默认不替换原数据,返回新数据,inplace=True修改原数据
(2)fillna(value, inplace=True)
替换缺失值
说明:
value:替换成的值
inplace:
True:会修改原数据
False:不替换修改原数据,生成新的对象
(3)缺失值不是nan,是其他标记的
后面再说
二、缺失值处理实例
1、电影数据文件获取
import pandas as pdmovie = pd.read_csv("./IMDB-Movie-Data.csv")movieimport numpy as np# 判断是否存在缺失值
np.any(pd.isnull(movie))np.all(pd.notnull(movie))# 用dataframe的any方法
pd.isnull(movie).any() # 返回每一个字段是否有缺失值# 用dataframe的all方法
pd.notnull(movie).all()# 用dataframe的isnull方法
movie.isnull().sum()
2、删除含有缺失值的样本
# 缺失值处理
# 删除含有缺失值的样本
data1 = movie.dropna()data1.isnull().sum()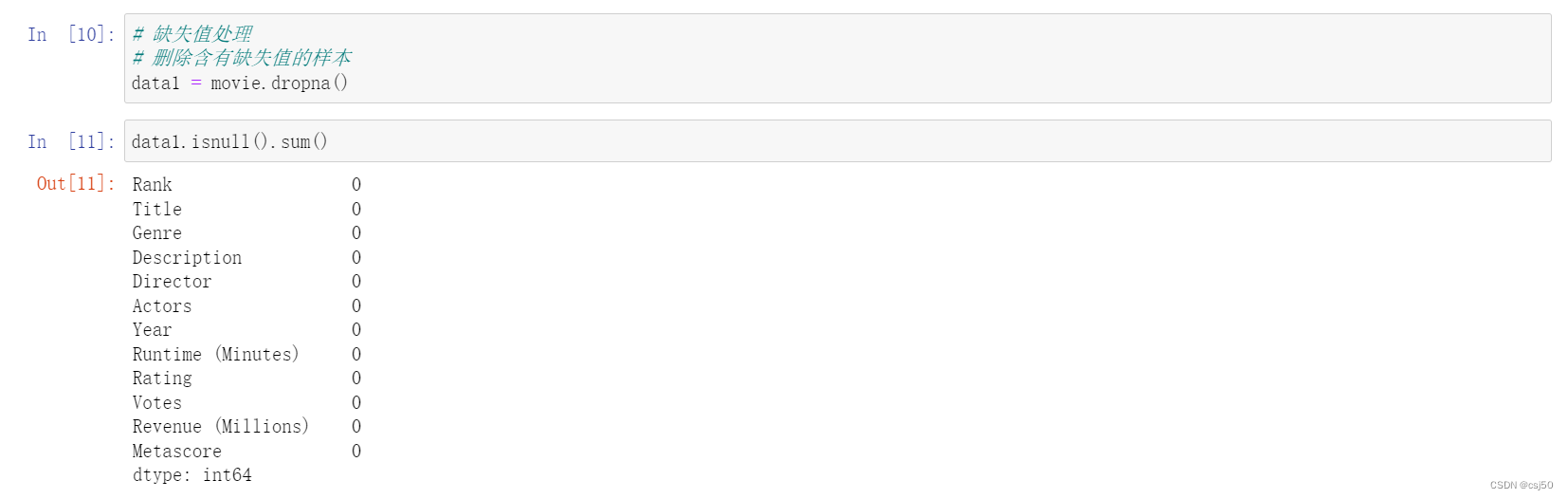
3、替换缺失值
# 含有缺失值的字段
# Revenue (Millions)
# Metascoremovie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)movie.isnull().sum()
4、不是缺失值nan,是其他标记的
比如是?
思路:
(1)进行替换,将?替换成np.nan
(2)处理np.nan缺失值的步骤来
(3)replace(to_replace=, value=)
说明:
to_replace:替换前的值
value:替换后的值
# 不是缺失值nan,是其他标记的
name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("./breast-cancer-wisconsin.data", names=name)datadata_new = data.replace(to_replace="?", value=np.nan)data_newdata_new.dropna(inplace=True)data_new.isnull().sum()
三、数据离散化
1、什么是数据离散化
我们用数值表示类别,计算机它只知道数值,会认为数值大的有什么优势
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数、值代表落在每个子区间中的属性值,避免了由于数值差异导致类别的平衡
例子1:
男 女 年龄
A 1 0 23
B 0 1 30
C 1 0 18
例子2:
原始的升高数据:165、174、160、180、159、163、192、184、
假设按照身高分几个区间段:(150,165],(166,180],(180,195]
这样我们将数据分到了三个区间段,我们可以对应的标记为矮、中、高三个类别,最终要处理成一个“哑变量”矩阵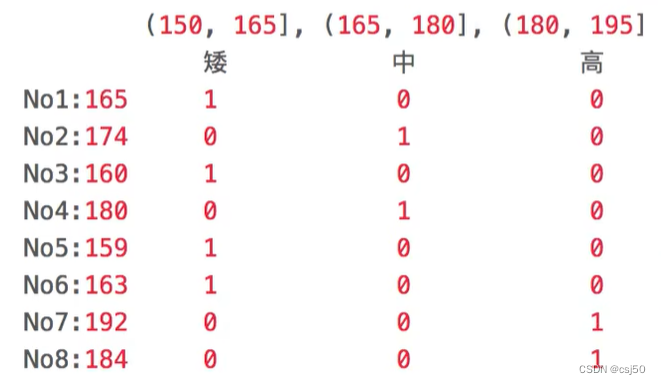
我们把这种数据编码称为one-hot编码,也叫哑变量
2、为什么要数据离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数,离散化方法经常作为数据挖掘的工具
3、如何实现数据离散化
流程:
(1)对数据进行分组
(2)对分好组的数据求哑变量
4、对数据分组方法
pd.qcut(data, bins)
自动分组
说明:
data:要分组的数据
bins:要分的组数
返回值:分好组的Series
pd.cut(data, bins)
自定义分组
说明:
data:要分组的数据
bins:自定义的区间,以列表的形式[]传进来
返回值:分好组的Series
series.value_counts()
统计分组次数
对数据进行分组一般会与value_counts搭配使用,统计每组的个数
5、对分好组的数据求哑变量(one-hot编码)
pd.get_dummies(data, prefix=None)
说明:
data:array-like、Series、DataFrame
prefix:分组名字
6、小案例
# 数据的离散化
# 准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])data# 自动分组
sr = pd.qcut(data, 3)sr# 转换成one-hot编码
pd.get_dummies(sr, prefix="height")# 统计每个区间有多少样本
sr.value_counts()# 自定义分组
bins = [150, 165, 180, 195]
cut = pd.cut(data, bins)cutpd.get_dummies(cut, prefix="身高")cut.value_counts()
7、one-hot编码占内存,然后再用稀疏矩阵来减少内存。达到提取特征的目的
8、案例:股票的涨跌幅离散化
# 股票涨跌幅离散化
# 1、读取股票的数据
stock = pd.read_csv("./stock_day.csv")p_change = stock["p_change"]p_change# 自动分组
sr = pd.qcut(p_change, 10)sr.value_counts()# 离散化
pd.get_dummies(sr, prefix="涨跌幅")# 自定义分组
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
sr = pd.cut(p_change, bins)sr.value_counts()# 离散化
stock_change = pd.get_dummies(sr, prefix="rise")
stock_change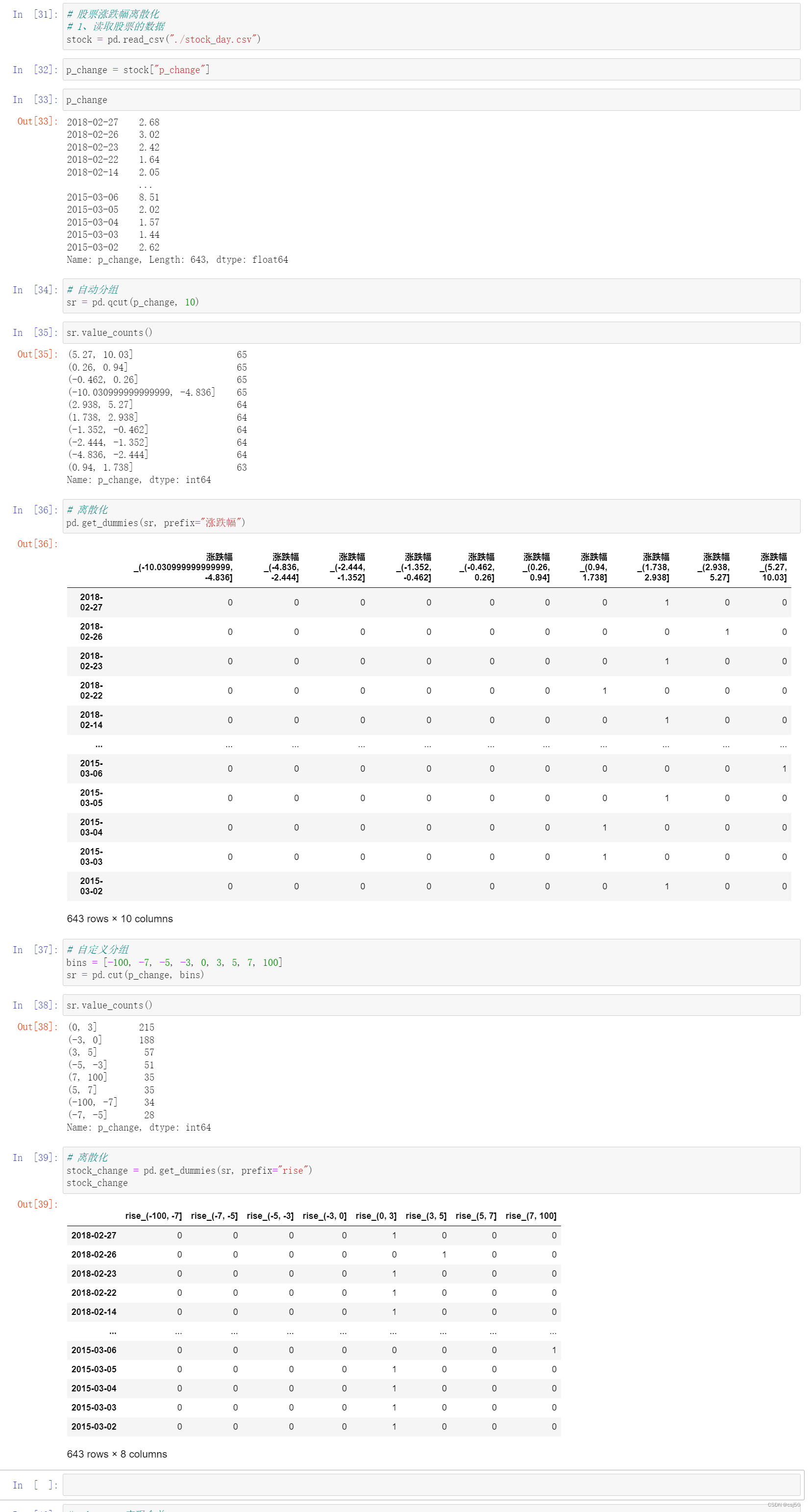
相关文章:
数据分析基础之《pandas(6)—高级处理》
一、缺失值处理 1、如何处理nan 两种思路: (1)如果样本量很大,可以删除含有缺失值的样本 (2)如果要珍惜每一个样本,可以替换/插补(计算平均值或中位数) 2、判断数据是否…...

IOS破解软件安装教程
对于很多iOS用户而言,获取软件的途径显得较为单一,必须通过App Store进行下载安装。 这样的限制,时常让人羡慕安卓系统那些自由下载各类版本软件的便捷。 心中不禁生出疑问:难道iOS世界里,就不存在所谓的“破解版”软件…...
[缓存] - 1.缓存共性问题
1. 缓存的作用 为什么需要缓存呢?缓存主要解决两个问题,一个是提高应用程序的性能,降低请求响应的延时;一个是提高应用程序的并发性。 1.1 高并发 一般来说, 如果 10Wqps,或者20Wqps ,可使用分布…...
Python爬虫——解析库安装(1)
目录 1.lxml安装2.Beautiful Soup安装3.pyquery 的安装 我创建了一个社区,欢迎大家一起学习交流。社区名称:Spider学习交流 注:该系列教程已经默认用户安装了Pycharm和Anaconda,未安装的可以参考我之前的博客有将如何安装。同时默…...
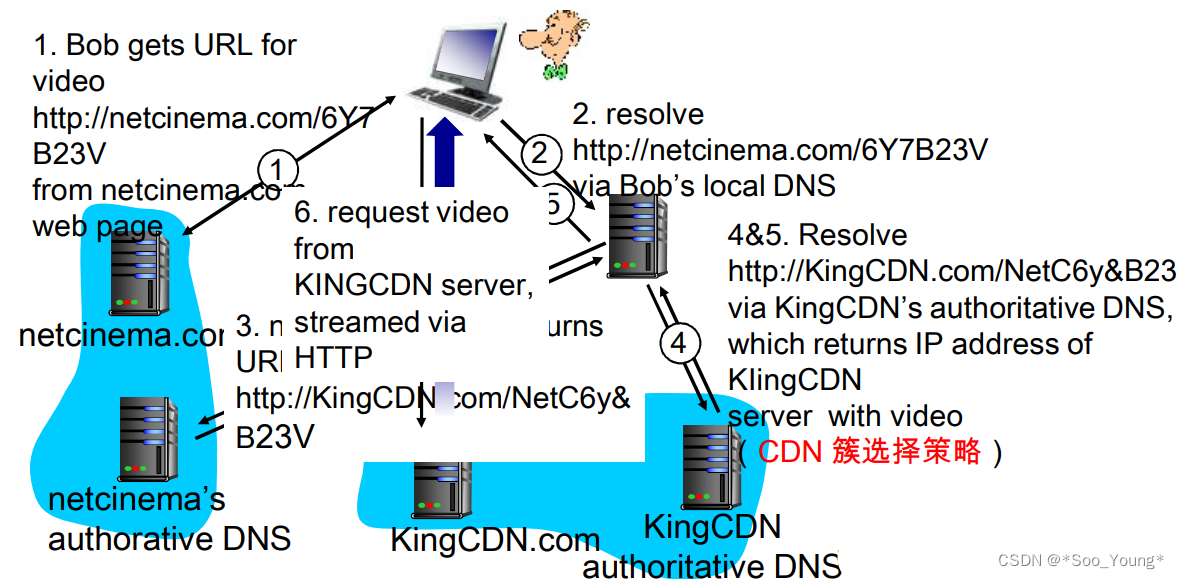
中科大计网学习记录笔记(十一):CDN
前言: 学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程 该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信…...
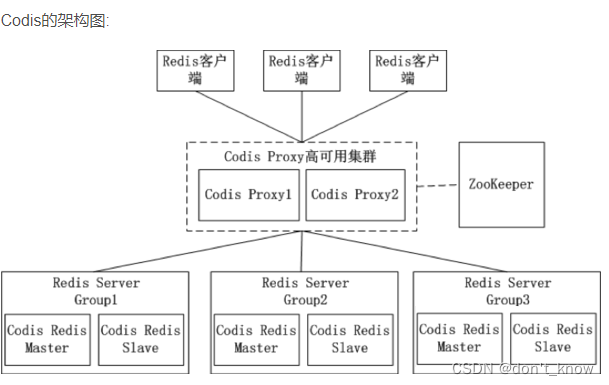
[缓存] - 2.分布式缓存重磅中间件 Redis
1. 高性能 尽量使用短key 不要存过大的数据 避免使用keys *:使用SCAN,来代替 在存到Redis之前压缩数据 设置 key 有效期 选择回收策略(maxmemory-policy) 减少不必要的连接 限制redis的内存大小(防止swap,OOM) slowLog …...
)
1191. 家谱树(拓扑排序,模板题)
活动 - AcWing 有个人的家族很大,辈分关系很混乱,请你帮整理一下这种关系。 给出每个人的孩子的信息。 输出一个序列,使得每个人的孩子都比那个人后列出。 输入格式 第 11 行一个整数 n,表示家族的人数; 接下来 …...

CSS之BFC
BFC概念 BFC(Block Formatting Context)即块级格式化上下文,是Web页面的可视CSS渲染的一部分。它是一个独立的渲染区域,让其中的元素在布局上与外部的元素互不影响。简单来说,BFC提供了一个环境,允许内部的…...

2024 年合并 PDF 文件的免费 PDF 合并软件榜单
合并 PDF 是当今人们寻找的最重要的功能之一。在本文中,您将了解前五名的 PDF 合并软件以及详细的介绍,以便您选择最佳的。如果您想将所有重要信息都放在一个文件中,而不是在不同的文件中查找,那么合并 PDF 文件是必要的。通过这种…...

Python教程56:海龟画图turtle画kitty猫
---------------turtle源码集合--------------- Python教程91:关于海龟画图,Turtle模块需要学习的知识点 Python教程51:海龟画图turtle画(三角形、正方形、五边形、六边形、圆、同心圆、边切圆,五角星,椭…...

c入门第十篇——指针入门
一句话来说: 指针就是存储了内存地址值的变量。 在前面讨论传值和传址的时候,我们就已经开始使用了指针来传递地址。 在正式介绍指针之前,我们先来简单了解一下内存。内存可以简单的理解为一排连续的房子的街道,每个房子都有自己的地址&#…...
ret2syscall)
pwn学习笔记(3)ret2syscall
pwn学习笔记(3) ROP原理: ROP(Return Oriented Programming)返回导向编程,主要思想是通过在程序中已有的小片段(gadgets)来改变某些寄存器或者变量的值,从而控制程序的执行流程。 栈溢出–…...

React18原理: 生命周期中特别注意事项
概述 生命周期就是一个组件从诞生到销毁的全过程(包含错误捕获,这里暂且不聊这个)react 在组件的生命周期中注册了一系列的钩子函数支持开发者在其中嵌入代码,并在适当的时机运行生命周期本质上就是组件中的钩子函数,主要有三个主要的钩子 挂…...

【C语言】Linux内核bind系统调用代码
一、Linux 4.9内核bind系统调用代码注释 int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen) {struct socket *sock; // 定义socket对象的指针struct sockaddr_storage address; // 用于存储从用户空间复制过来的地址int err…...
Ubuntu下Anaconda+PyCharm搭建PyTorch环境
这里主要介绍在condapytorch都正确安装的前提下,如何通过pycharm建立开发环境; Ubuntu下AnacondaPyCharm搭建PyTorch环境 系统环境:Ubuntu22.04 conda: conda 23.11.0 pycharm:如下 condapytorch的安装教程介绍,请点击这里&…...
酷开科技荣获“消费者服务之星”称号后的未来展望
恭喜酷开科技荣获2023年第四季度黑猫平台“消费者服务之星”称号!这是对酷开科技长期以来坚持用户至上、用心服务的肯定和认可。作为OTT行业的佼佼者,酷开科技一直秉承着“以用户为中心”的服务理念,不断追求卓越品质,为用户提供更…...

UVA1449 Dominating Patterns 题解
UVA1449 Dominating Patterns 题解 板子题诶。 解法 AC 自动机模板题,因为数据范围比较小,所以不加拓扑排序优化建图即可通过本题。这里简单介绍一下拓扑排序优化建图。 在查找时,每次都暴力的条 f a i l fail fail 指针是很消耗时间的&…...
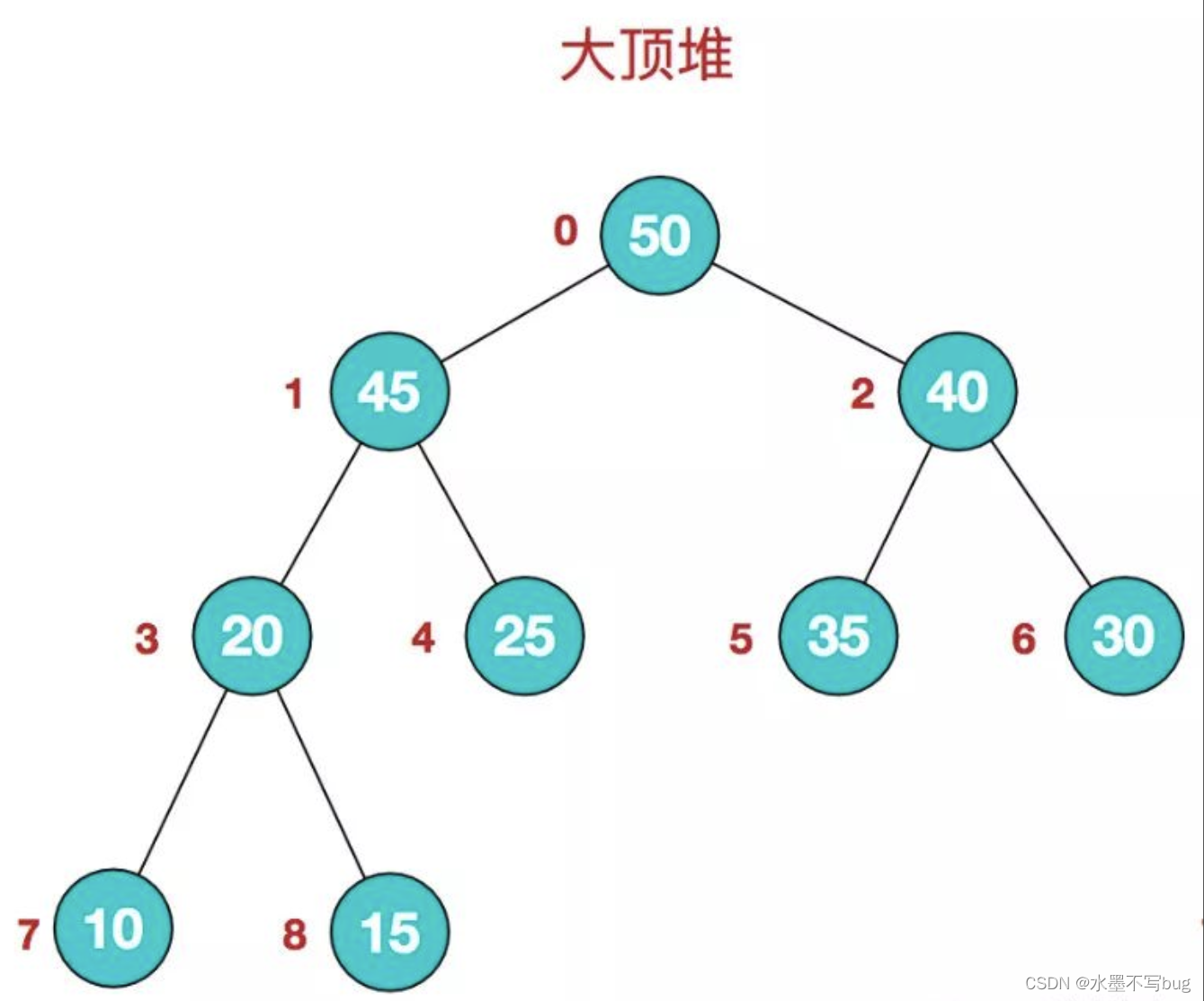
【C语言】数据结构#实现堆
目录 (一)堆 (1)堆区与数据结构的堆 (二)头文件 (三)功能实现 (1)堆的初始化 (2)堆的销毁 (3)插入数据 …...
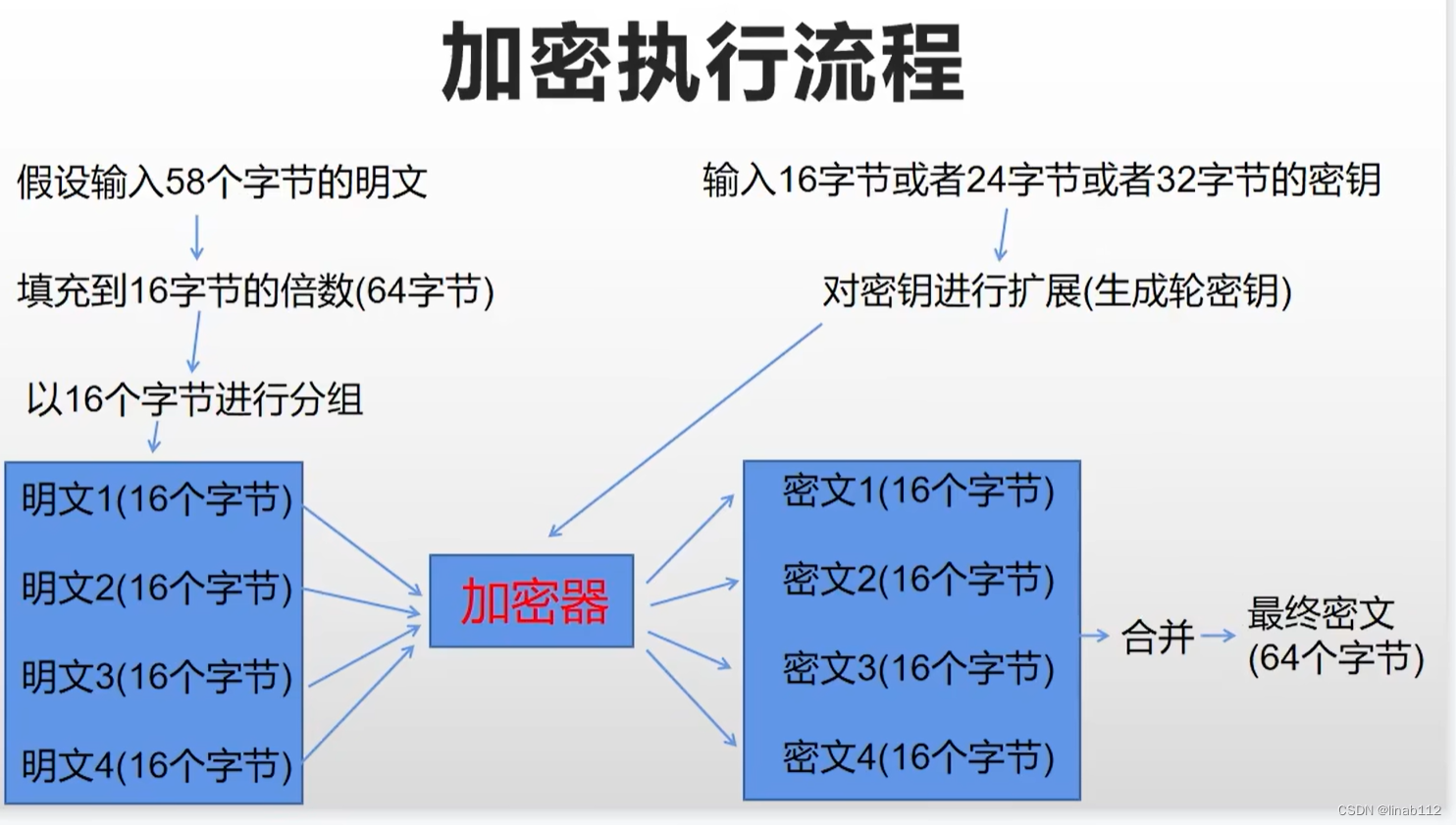
AES加密中的CBC和ECB
目录 1.说明 2.ECB模式(base64) 3.CBC模式 4.总结 1.说明 AES是常见的对称加密算法,加密和解密使用相同的密钥,流程如下: 主要概念如下: ①明文 ②密钥 用来加密明文的密码,在对称加密算…...

【C++】类和对象(四)
前言:在类和对象中,我们走过了十分漫长的道路,今天我们将进一步学习类和对象,类和对象这块荆棘地很长,各位一起加油呀。 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:高质量&a…...

细胞的“近距离对话大师”——Notch信号通路
在我们身体里,细胞并非孤立存在,它们通过信号通路精准沟通,其中Notch信号通路堪称细胞间的“近距离对话大师”,从果蝇到人类都高度保守,不靠远距离信号扩散,仅靠相邻细胞“面对面接触”,就能掌控…...

如何高效下载B站视频:3分钟掌握智能下载工具完整指南
如何高效下载B站视频:3分钟掌握智能下载工具完整指南 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾经遇到过这样的情况&a…...

GoogleTest 使用指南 | 测试模板函数
GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数 模板类和函数由于其泛型特性,需要在不同类型下进行测试,以确保其通用性和正确性。 下面是一个示例。 m…...

探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界
探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界 【免费下载链接】nvme-cli NVMe management command line interface. 项目地址: https://gitcode.com/gh_mirrors/nv/nvme-cli NVMe-CLI作为现代NVMe固态存储设备的核心管理工具,在v2.…...

FPGA验证核心:Vivado中功能与代码覆盖率的实战指南
1. 项目概述:为什么验证是FPGA开发的重中之重? 如果你刚接触FPGA开发,可能会觉得写代码(HDL)是最核心、最花时间的部分。但等你真正上手几个项目,尤其是那些需要流片或者部署到关键系统的项目后,…...

手把手教你用CT107D板子复现蓝桥杯省赛题:光敏传感器触发与长按按键的实战编程
从零实现CT107D光敏传感与长按按键:蓝桥杯省赛级开发指南 硬件准备与环境搭建 打开CT107D开发板的包装盒时,那股新电路板特有的松香味总是让人兴奋。作为蓝桥杯官方指定平台,这块板子集成了我们需要的所有外设模块。先找到板子右下角的光敏…...

在 GitHub Actions 中集成 Taotoken 实现大模型 API 自动化调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 GitHub Actions 中集成 Taotoken 实现大模型 API 自动化调用 将大模型能力集成到自动化工作流中,是提升开发效率的有…...

BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案
BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾为无法下载B站…...

别再只跑仿真了!用Vivado 2023.1给你的FPGA图像处理项目做个“硬件体检”
从仿真到硬件的跨越:FPGA图像处理项目实战验证指南 在实验室里看着仿真波形完美无缺,却在开发板上遭遇各种"灵异事件"——这可能是每个FPGA开发者都经历过的成长仪式。仿真环境就像飞行模拟器,能教会你基本操作,但真正的…...

加热套、半导体加热带、工业加热夹克是同一种东西吗?
首先明确这个答案是肯定的,,这三种名称指同一种产品。作为北京龙腾圣华(LOTUSANA)的技术人员,我常被客户问到这个问题。我司自2002 年成立之初便自主研发投产此类柔性温控产品,最早行我们定名为加热套&…...