论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors
进一步学习:AMP,baseline方法,TO
摘要:
介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地形上实现稳健和敏捷的行走。主要贡献包括为机器人生成AMP数据集,并提出一种教师-学生训练框架来学习稳健和敏捷的运动技能。该系统在现实世界应用中显示出前景,克服了先前依赖广泛环境感应或手工设计模型的方法的限制。
方法:
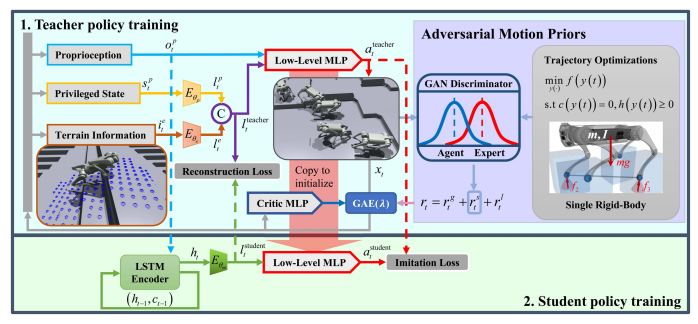
- Privileged learning
由于地形信息不完全可观察,没有外部感应器,盲行过程被建模为部分可观察的马尔可夫决策过程。
因此借助Privileged learning,即特权学习。
特权学习中,教师策略在模拟中训练,利用只有在模拟中才有的特权状态。然后学生策略学习模仿教师的特权状态编码和相应的行为。首先训练一个能够观察到机器人和环境动态属性的教师策略。然后将教师策略提炼到学生策略中,通过监督学习从一系列的观察中推断这些属性。
动作空间:
对于教师策略,状态空间 x teacher t x_{\text{teacher}}^t xteachert包含以下部分:
-
本体感知观察 o p t o_p^t opt:包括重力矢量的方向、基座的角速度、关节位置和速度、由当前策略选择的前一个动作 a t − 1 a_{t-1} at−1,以及期望的基座速度命令向量。
-
特权状态 s p t s_p^t spt:由于基座的线速度计算来自状态估算算法且含噪声,因此将其作为特权状态的一部分,同时还包括地面摩擦系数、地面恢复系数、接触力、外部力及其在机器人上的位置,以及碰撞状态(包括躯干、大腿和小腿部分)。
-
地形信息 i e t i_e^t iet:包含从机器人基座周围的网格中采样的地形点的187项测量数据,代表从采样点到机器人基座的垂直距离。
学生策略只能访问本体感知观察 o p t o_p^t opt,而无法访问特权状态 s p t s_p^t spt和地形信息 i e t i_e^t iet。学生策略需要通过监督学习来模仿教师策略,并从历史观察中推断那些它无法直接观察到的动态属性。
行动空间:策略行动 a t a_t at是一个12维向量,被解释为目标关节位置的偏移量,这个偏移量被加到时间不变的名义关节位置上,以指定每个关节的目标电机位置。然后,关节的PD控制器使用这些目标电机位置和固定增益( K p = 20 , K d = 0.5 K_p = 20, K_d = 0.5 Kp=20,Kd=0.5)计算扭矩命令。
- Reward Terms Design
在这项工作中,奖励函数由任务组成部分 r t g r_t^g rtg、风格组成部分 r t s r_t^s rts和正则化组成部分 r t l r_t^l rtl构成,即 r t = r t g + r t s + r t l r_t = r_t^g + r_t^s + r_t^l rt=rtg+rts+rtl。任务奖励项包括线性和角速度追踪功能。
风格奖励(引入强化学习的监督项):
风格奖励用于评估示范者行为和智能体行为之间的相似性,意味着它们越相似,智能体就能获得更多的风格奖励。由于我们期望我们的机器人在穿越平坦或不平坦的地形时获得自然平滑的小跑步态,我们使用基于AMP的风格奖励函数鼓励我们的机器人产生与参考数据集D中的相同步态风格的行为。
定义了一个由神经网络参数 ϕ 表示的鉴别器 D ϕ D_\phi Dϕ,来预测状态转换 ( s t , s t + 1 ) (s_t, s_{t+1}) (st,st+1)是来自数据集D的真实样本还是由智能体A生成的伪样本。每个状态 s A M P t ∈ R 31 s_{AMP}^t \in \mathbb{R}^{31} sAMPt∈R31 包含关节位置、关节速度、基座线速度、基座角速度和相对于地形的基座高度。
鉴别器的训练目标定义为: arg min ϕ E ( s t , s t + 1 ) ∼ D [ ( D ϕ ( s t , s t + 1 ) − 1 ) 2 ] + E ( s t , s t + 1 ) ∼ A [ ( D ϕ ( s t , s t + 1 ) + 1 ) 2 ] + α g p 2 E ( s t , s t + 1 ) ∼ D [ ∣ ∣ ∇ ϕ D ϕ ( s t , s t + 1 ) ∣ ∣ 2 ] , \underset{\phi}{\text{arg min}} \ \mathbb{E}_{(s_t, s_{t+1}) \sim D} \left[ (D_\phi (s_t, s_{t+1}) - 1)^2 \right] + \mathbb{E}_{(s_t, s_{t+1}) \sim A} \left[ (D_\phi (s_t, s_{t+1}) + 1)^2 \right] + \frac{\alpha_{gp}}{2} \mathbb{E}_{(s_t, s_{t+1}) \sim D} \left[ ||\nabla_\phi D_\phi (s_t, s_{t+1})||^2 \right], ϕarg min E(st,st+1)∼D[(Dϕ(st,st+1)−1)2]+E(st,st+1)∼A[(Dϕ(st,st+1)+1)2]+2αgpE(st,st+1)∼D[∣∣∇ϕDϕ(st,st+1)∣∣2],其中前两项是最小二乘GAN公式,鼓励鉴别器区分给定的输入状态转换是来自智能体A还是参考数据集D。公式中的最后一项是梯度惩罚项,用于减少鉴别器在真实数据样本的流形上分配非零梯度的倾向。 α g p \alpha_{gp} αgp是手动指定的系数(我们使用 α g p = 10 \alpha_{gp} = 10 αgp=10)。然后风格奖励定义为: r t s [ ( s t , s t + 1 ) ∼ A ] = max [ 0 , 1 − 0.25 ( d score t − 1 ) 2 ] , r_t^s [(s_t, s_{t+1}) \sim A] = \max \left[ 0, 1 - 0.25 (d_{\text{score}}^t - 1)^2 \right], rts[(st,st+1)∼A]=max[0,1−0.25(dscoret−1)2],其中 d score t = D ϕ ( s t , s t + 1 ) d_{\text{score}}^t = D_\phi(s_t, s_{t+1}) dscoret=Dϕ(st,st+1)且风格奖励缩放到范围 [0, 1]。
所有奖励项:
| 术语 | 方程 | 权重 | 作用 |
|---|---|---|---|
| 任务奖励 r t g r_t^g rtg | exp ( − ∣ v t , d e s , x y − v t , x y ∣ 2 0.15 ) \exp\left(-\frac{|v_{t,des,xy} - v_{t,xy}|_2}{0.15}\right) exp(−0.15∣vt,des,xy−vt,xy∣2) | 1.0 | 鼓励匹配目标线速度 |
| exp ( − ∣ ω t , d e s , z − ω t , z ∣ 2 0.15 ) \exp\left(-\frac{|\omega_{t,des,z} - \omega_{t,z}|_2}{0.15}\right) exp(−0.15∣ωt,des,z−ωt,z∣2) | 0.5 | 鼓励匹配目标角速度 | |
| 平滑性奖励 r t l r_t^l rtl | ∣ τ t ∣ 2 |\tau_t|_2 ∣τt∣2 | 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4 | 最小化扭矩 |
| ∣ q ¨ t ∣ 2 |\ddot{q}_t|_2 ∣q¨t∣2 | 2.5 × 1 0 − 7 2.5 \times 10^{-7} 2.5×10−7 | 鼓励维持低关节速度 | |
| ∣ q t − 1 − q t ∣ 2 |q_{t-1} - q_t|_2 ∣qt−1−qt∣2 | 0.1 | 鼓励机器人的关节位置变化更平滑 | |
| ∑ i = 0 5 min ( τ i , t − 0.5 , 0 ) \sum_{i=0}^5 \min(\tau_{i,t} - 0.5, 0) ∑i=05min(τi,t−0.5,0) | 1.0 | 惩罚大扭矩,鼓励机器人使用较小的扭矩 | |
| 安全性奖励 r t l r_t^l rtl | − n c o l l i s o n -n_{collison} −ncollison | 0.1 | 惩罚碰撞 |
| 风格奖励 r t s r_t^s rts | max [ 0 , 1 − 0.25 ( d score t − 1 ) 2 ] \max \left[ 0, 1 - 0.25 (d_{\text{score}}^t - 1)^2 \right] max[0,1−0.25(dscoret−1)2] | 0.5 | 鼓励机器人产生与参考数据集D中的相同步态风格的行为 |
- Motion Dataset Generation
那么如何得到监督数据集D?
由于只需要状态转换来构建运动数据集 D,采用了之前工作中的单一 TO(轨迹优化)公式来在平坦地面上生成具有小跑步态的四足动物的运动。机器人首先使用简化的质心动力学模型来降低计算复杂性,然后转换成一个具有摩擦锥约束和运动学约束的非线性规划问题。为了加快优化速度并避免调整程序,使用 TOWR来解决 TO 问题,这不需要成本函数。数据集 D 包括前进、后退、向左横移、向右横移、左转向、右转向和组合运动轨迹,总持续时间为30秒。使用 TO 生成运动数据集的好处是它们可以完全匹配模拟代理和示范者的状态空间,避免使用其他运动重定向技术。
训练:
模拟:在不同类型的地形上使用 IsaacGym 训练了4096个并行智能体。教师策略和学生策略分别在4亿和2亿模拟时间步骤中进行训练。两个阶段的总训练时间为实际时间七小时。每个 episode 最多持续1000步,相当于20秒,如果达到终止标准则提前终止。策略的控制频率在模拟中为50Hz。
所有训练都在单个NVIDIA RTX 3090Ti GPU上进行。
终止:当机器人达到终止标准时,我们终止一个 episode 并开始下一个,这些标准包括机身与地面的碰撞、剧烈身体倾斜,以及被困很长一段时间。
动态随机化:为了提高我们策略的鲁棒性,并促进从模拟到真实世界的转移,我们随机化了躯干和腿部的质量、施加在机器人身体上的负载的质量和位置、地面摩擦和恢复系数、电机强度、关节级PD增益以及每个 episode 中的初始关节位置。这些动态参数中的一些被视为特权状态 s p t s_p^t spt,以帮助教师策略训练。另外,在模拟训练阶段,同样的观察噪声被加入。
- Training Curriculum
在这项工作中,我们创建了五种类型的程序生成地形,包括粗糙平地、斜坡、波浪、楼梯和离散台阶。
由于早期阶段强化学习的不稳定性,直接在非常复杂的地形上训练机器人是困难的。我们采用并改进了中的自动化地形课程。我们创建了一个高度场地图,包含20×10网格排列的100种地形。每行都有同类型的地形按难度递增排列,而每种地形的长度和宽度为8米。粗糙平地通过增加的噪声构建,从±1厘米增加到±8厘米。斜坡的倾斜度从0度增加到30度。波浪是由贯穿地形长度的三个正弦波构成,这些波的振幅从20厘米增加到50厘米。楼梯宽度固定为30厘米,台阶高度从5厘米增加到23厘米。离散障碍物只有从±5厘米增加到±15厘米的两个高度等级。训练开始时,所有机器人都平等地被分配到所有类型的最低难度地形。只有当机器人适应了当前地形的难度后,才会被移动到更难的地形。当机器人能够以超过85%的平均线速度跟踪奖励离开当前地形时,就获得了这种适应性。相反,如果它们在一个episode 结束时未能至少走完指令线速度所要求的一半距离,则重置到更容易的地形。为了避免技能遗忘,解决最难地形的机器人将被循环返回到当前地形类型的随机选定难度。
我们的机器人试图通过在训练过程中跟踪不同的速度指令来学习一个条件命令的策略(策略变量包括状态和操作员的速度指令)。在episode 开始时,给机器人一个要跟随的期望指令,这是一个随机生成的向量 v t d e s = ( v x , v y , ω z ) ∈ R 3 v_{t_{des}} = (v_x, v_y, \omega_z) \in \mathbb{R}^3 vtdes=(vx,vy,ωz)∈R3,代表基座框架中的纵向速度、横向速度和偏航速度。在地形课程阶段,偏航速度指令是根据当前航向方向与目标航向方向之间的误差计算出来的,这使我们的机器人能够有效地离开地形。目标航向方向是从[−180°, 180°]均匀采样的。我们在地形课程阶段分别从小范围[−1米/秒,1米/秒]中采样纵向速度指令和横向速度指令。
- Teacher Policy Training and Architecture
在第一阶段的训练中,我们使用邻近策略优化(PPO)训练教师策略。教师策略和鉴别器的训练过程是同步的。教师在环境中执行推演,生成状态转换 ( s A M P t , s A M P t + 1 ) (s_{AMP}^t, s_{AMP}^{t+1}) (sAMPt,sAMPt+1)。然后将这个状态转换提供给鉴别器 D ϕ D_\phi Dϕ以获得 d s c o r e t d_{score}^t dscoret,该分数用于根据公式(4)计算小跑步态风格奖励 r t s r_t^s rts,并加到教师获得的其他奖励中。收集推演数据后,我们优化教师策略 π θ t e a c h e r \pi_\theta^{teacher} πθteacher的参数 θ \theta θ以最大化公式(1)的总折扣回报,以及每个训练步骤中优化鉴别器 D ϕ D_\phi Dϕ的参数 ϕ \phi ϕ以最小化公式(3)中呈现的目标。
教师策略 π θ t e a c h e r \pi_\theta^{teacher} πθteacher包含三个多层感知器(MLP)组件:地形编码器 E θ e E_{\theta}^e Eθe,特权编码器 E θ p E_{\theta}^p Eθp和低级网络,如图2所示。 E θ e E_{\theta}^e Eθe和 E θ p E_{\theta}^p Eθp将地形信息 i e t ∈ R 187 i_e^t \in \mathbb{R}^{187} iet∈R187和特权状态 s p t ∈ R 30 s_p^t \in \mathbb{R}^{30} spt∈R30压缩成低维潜在表示 l e t ∈ R 16 l_e^t \in \mathbb{R}^{16} let∈R16和 l p t ∈ R 8 l_p^t \in \mathbb{R}^{8} lpt∈R8。虽然这种压缩丢失了一些信息,但它保留了最需要的信息,这有助于学生重建潜在表示。 l e t l_e^t let和 l p t l_p^t lpt首先被合并成一个完整的潜在表示 l t e a c h e r t ∈ R 24 l_{teacher}^t \in \mathbb{R}^{24} lteachert∈R24。然后将 l t e a c h e r t l_{teacher}^t lteachert和本体感知观察 o p t ∈ R 45 o_p^t \in \mathbb{R}^{45} opt∈R45提供给低级网络,并带有一个tanh输出层以输出高斯分布 a t e a c h e r t ∼ N ( μ t , σ ) a_{teacher}^t \sim \mathcal{N}(\mu_t, \sigma) ateachert∼N(μt,σ)的均值 μ t ∈ R 12 \mu_t \in \mathbb{R}^{12} μt∈R12,其中 σ ∈ R 12 \sigma \in \mathbb{R}^{12} σ∈R12表示由PPO确定的动作的方差。教师策略还有一个由MLP提供的评价网络,包含三个隐藏层,以提供广义优势估计的目标值 V t V_t Vt。鉴别器 D ϕ D_\phi Dϕ是一个单一的MLP,带有两个隐藏层和一个线性单元输出层。
- Student Policy Training and Architecture
学生策略的训练目的是在不使用特权状态 s p t s_p^t spt和地形信息 i e t i_e^t iet的情况下复现教师策略的行为。因此,学生的动态被视为一个部分可观测的马尔可夫决策过程,学生需要考虑观察 o p t o_p^t opt的历史来估计不可观测的状态。我们为学生使用一个记忆编码器来编码历史之间的时序关联。
在学生训练期间,我们通过最小化两个损失来利用监督方式,包括一个模仿损失和一个重构损失,如图2所示。模仿损失使学生能够模仿教师的动作 a t e a c h e r t a_{teacher}^t ateachert。重构损失鼓励学生的记忆编码器重现教师的潜在表示 l t e a c h e r t l_{teacher}^t lteachert。我们使用数据集聚合策略(DAgger)通过推演学生策略来生成样本,以增加鲁棒性。与教师训练相同的课程也应用于学生训练,而不训练鉴别器。
学生策略由一个记忆编码器和一个与教师的低级MLP相同结构的网络组成。记忆编码器通常通过将一系列历史观测堆叠到MLP的输入中来实现,或者使用可以捕捉过去信息的架构,如递归神经网络(RNN)或时间卷积神经网络(TCN)。然而,对于MLP和TCN这样的架构,需要留出一部分记忆空间来存储历史观测,这给机载资源使用带来了很大压力。因此,与其存储完整的历史观测,更有效的方式是使用RNN,这可以在隐藏状态中嵌入过去的历史信息。我们使用长短期记忆(LSTM)作为我们的RNN架构。首先,本体感知观测 o p t o_p^t opt与LSTM的过去隐藏状态 h t − 1 h_{t-1} ht−1和细胞状态 c t − 1 c_{t-1} ct−1被编码到LSTM模块的当前隐藏状态 h t ∈ R 256 h_t \in \mathbb{R}^{256} ht∈R256,然后传递给 E θ m E_{\theta}^m Eθm来输出学生的潜在表示 l t s t u d e n t l_t^{student} ltstudent。我们重用教师低级网络的学习权重来初始化学生的低级网络,以加速训练。为了使我们的控制器学习稳健的盲行,我们训练学生策略使用50个 o p t o_p^t opt的序列(对应1秒的记忆)。
实验:
硬件:控制器部署在 Unitree Go1 Edu 机器人上,该机器人站立高度为28厘米,重13公斤。机器人上使用的传感器包括关节位置编码器和一个惯性测量单元(IMU)。通过使用 MNN 框架优化的训练后的学生策略,以提高推理速度,并在机载计算机Jetson TX2 NX上运行。在部署时,控制频率为50Hz。
- 奖励项的消融实验

为了评估不同奖励项对步态运动的影响,我们额外训练了两个消融策略,考虑了两种类型奖励的组合( r t g + r t s r_t^g + r_t^s rtg+rts和 r t g + r l t r_t^g + r_l^t rtg+rlt)。所有三个策略都有相同的训练时间和随机种子。图3显示了在模拟中在平坦地面上给定0.6米/秒向前移动指令时,前右腿(大腿和小腿)的位置和速度。使用全部奖励项( r t g + r l t + r t s r_t^g + r_l^t + r_t^s rtg+rlt+rts)训练的策略的关节状态(紫色线条)更接近于轨迹优化(TO)生成的关节状态(红色线条),而不是其他两种。只使用两种奖励( r t g + r t s r_t^g + r_t^s rtg+rts和 r t g + r l t r_t^g + r_l^t rtg+rlt)训练的策略产生了急促的速度和位置(橙色和蓝色线条)。更重要的是,使用全部奖励项( r t g + r l t + r t s r_t^g + r_l^t + r_t^s rtg+rlt+rts)训练的策略表现出自然而平稳的步态风格,如附件视频所示。这表明,使用基于AMP的预定义步态先验确实可以让机器人学习自然步态,而不限制克服复杂地形的能力。
- 鲁棒运动的评价
和几个baselines进行比较:
-
RMA:一个类似的教师-学生训练框架,其中学生策略包含一个一维CNN(卷积神经网络)适应模块和从教师策略复制的低级网络。
-
Concurrent:策略与显式估计身体状态的状态估计网络一起并发训练。考虑到策略的最终收敛性,在训练过程中没有提供地形信息。
-
域随机化:策略直接训练,没有任何特权状态或地形信息。
-
内置MPC:MPC(模型预测控制)控制器内置于Unitree Go1 Edu中。
在每次测试中,机器人被给予了一个10秒钟的0.4米/秒的前进命令。如果机器人能够用前后腿越过台阶,则测试成功并通过。我们对每个台阶高度进行了10次测试,并计算了成功率。如图5所示,我们的方法在上下台阶方面胜过了所有其他方法,能够成功地越过高达25厘米的所有台阶。教师-学生训练框架(ours,RMA)因其能够隐式估计地形信息而有效穿越大台阶,而没有地形信息访问权限的控制器(Concurrent,域随机化,内置MPC)在台阶高度超过13厘米时经常导致跌落。然而,当台阶高度超过15厘米时,RMA的性能迅速下降。这种性能差异很可能是由于在训练期间对学生策略的低级网络的不同处理。我们的学生策略重用了教师低级网络的学习权重,并继续使用教师的动作对其进行训练,而RMA则冻结了学生的低级网络。随着地形变得更加困难, l e t l_e^t let的重构误差会变大,且从教师那里复制的固定权重的学生低级网络的输出会不稳定。
我们进一步评估了在多样化环境中所呈现控制器的鲁棒性,如图1和附件视频所示。这些环境包括大型路缘、密集植被、中度岩石、松散瓦砾和草地。其中一些地形可以变形和破碎,表面上的材料属性有着显著的变化。然而,该策略基于本体感知观察的历史学习了鲁棒的运动,并展示了从模拟到在训练期间从未经历过的特征地形的 zero-shot泛化。
- 敏捷运动的评价
快,见视频。
总结:
通过强化学习(RL)训练的单一策略可以使用简洁的奖励函数和并行训练程序获得既稳健又敏捷的运动。从AMP学习的步态风格展示了从平坦地形的运动数据集到现实世界中的具有挑战性地形的zero-shot泛化。
相关文章:
论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors 进一步学习:AMP,baseline方法,TO 摘要: 介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地…...
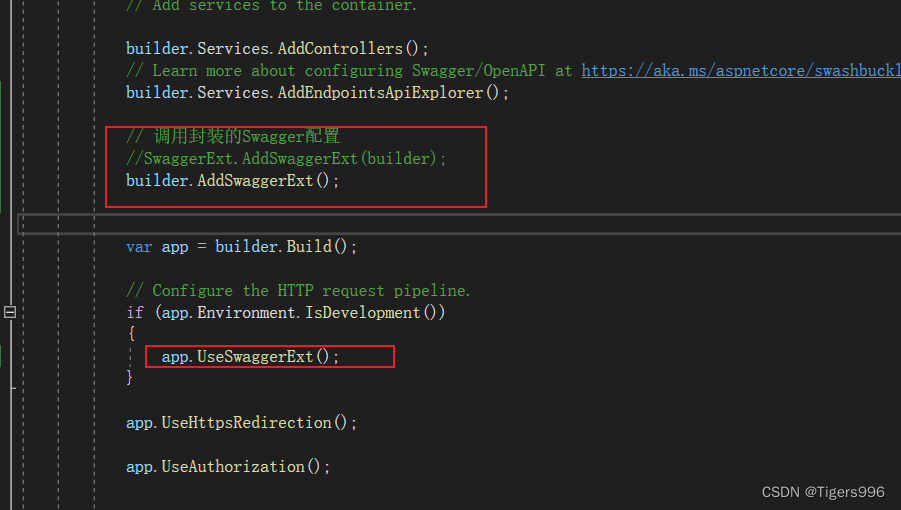
.NET Core WebAPI中封装Swagger配置
一、创建相关文件 创建一个Utility/SwaggerExt文件夹,添加一个类 二、在Program中找到Swagger相关配置信息 三、添加方法,在Program中调用 在SwaggerExt类中添加方法,将相关配置添写入 /// <summary> /// swagger配置 /// </sum…...

28. 找出字符串中第一个匹配项的下标
Problem: 28. 找出字符串中第一个匹配项的下标 文章目录 思路解题方法复杂度Code 思路 这个问题可以通过使用KMP(Knuth-Morris-Pratt)算法来解决。KMP算法是一种改进的字符串匹配算法,它的主要思想是当子串与目标字符串不匹配时,能…...

宿舍|学生宿舍管理小程序|基于微信小程序的学生宿舍管理系统设计与实现(源码+数据库+文档)
学生宿舍管理小程序目录 目录 基于微信小程序的学生宿舍管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员模块的实现 (1)学生信息管理 (2)公告信息管理 (3)宿舍信息管理 &am…...
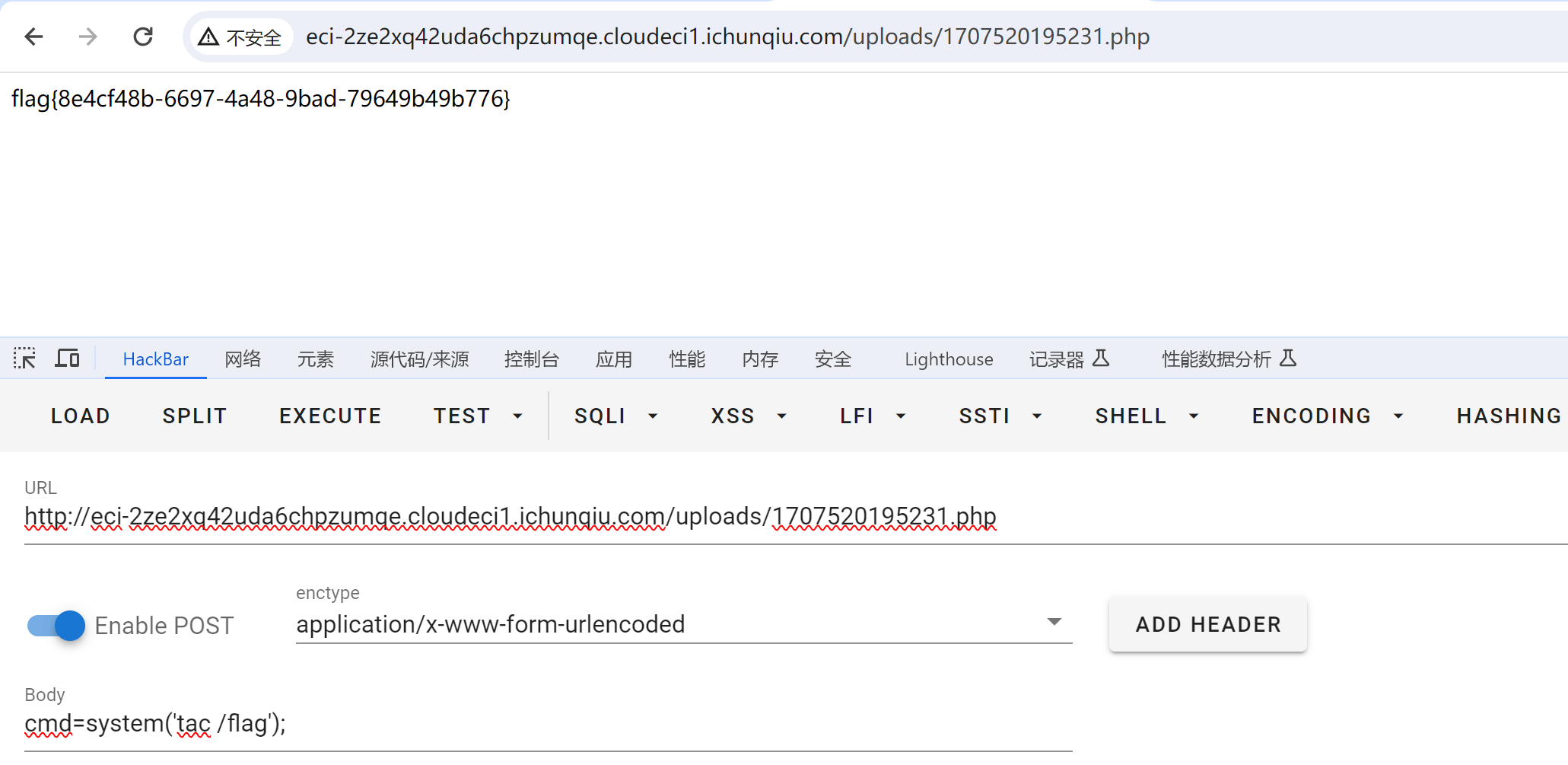
CVE-2022-25487 漏洞复现
漏洞描述:Atom CMS 2.0版本存在远程代码执行漏洞,该漏洞源于/admin/uploads.php 未能正确过滤构造代码段的特殊元素。攻击者可利用该漏洞导致任意代码执行。 其实这就是一个文件上传漏洞罢了。。。。 打开之后,/home路由是个空白 信息搜集&…...

C#面:强类型和弱类型
强类型 强类型是指在编程语言中,变量必须明确声明其数据类型,并且在编译时会进行类型检查的特性。它可以提高代码的可读性和可维护性,但有时需要显式地进行类型转换。换句话说,强类型语言要求变量的类型在编译时就要确定…...

nodejs和npm和vite
Nodejs 简单的说 Node.js 就是运行在服务端的 JavaScript。 Node.js 是一个基于 Chrome JavaScript 运行时建立的一个平台。 Node.js 是一个事件驱动 I/O 服务端 JavaScript 环境 用途: Node.js 可以被看作是一个 JavaScript 运行时环境,专门用于在服务…...
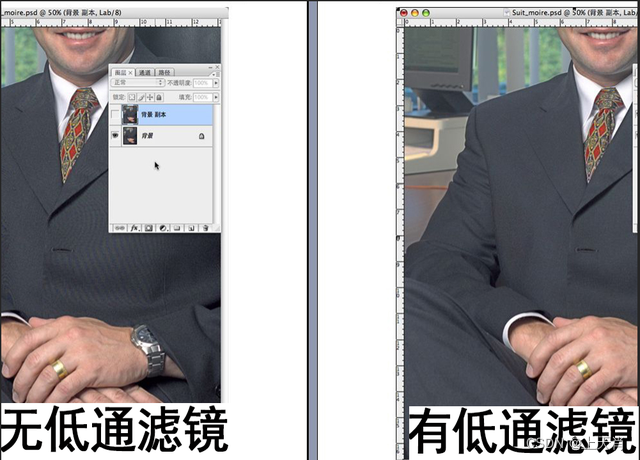
相机图像质量研究(24)常见问题总结:CMOS期间对成像的影响--摩尔纹
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...

Redis -- 数据库管理
目录 前言 切换数据库(select) 数据库中key的数量(dbsize) 清除数据库(flushall flushdb) 前言 MySQL有一个很重要的概念,那就是数据库database,一个MySQL里面有很多个database,一个datab…...
2023省赛真题:视频弹幕)
蓝桥杯(Web大学组)2023省赛真题:视频弹幕
思路: 主要是要仔细阅读题目以及理解给出的已有代码,进行函数间的调用、定时器的使用、元素移除、清除定时器等,注意细节。 笔记: height不要写成hight设置left时,记得加单位px可以获取left的值进行计算,但要注意sp…...

真假难辨 - Sora(OpenAI)/世界模拟器的技术报告
目录 引言技术报告汉译版英文原版 引言 Sora是OpenAI在2024年2月15日发布的世界模拟器,功能是通过文本可以生成一分钟的高保真视频。由于较高的视频质量,引起了巨大关注。下面是三个示例,在示例之后给出了其技术报告: tokyo-wal…...
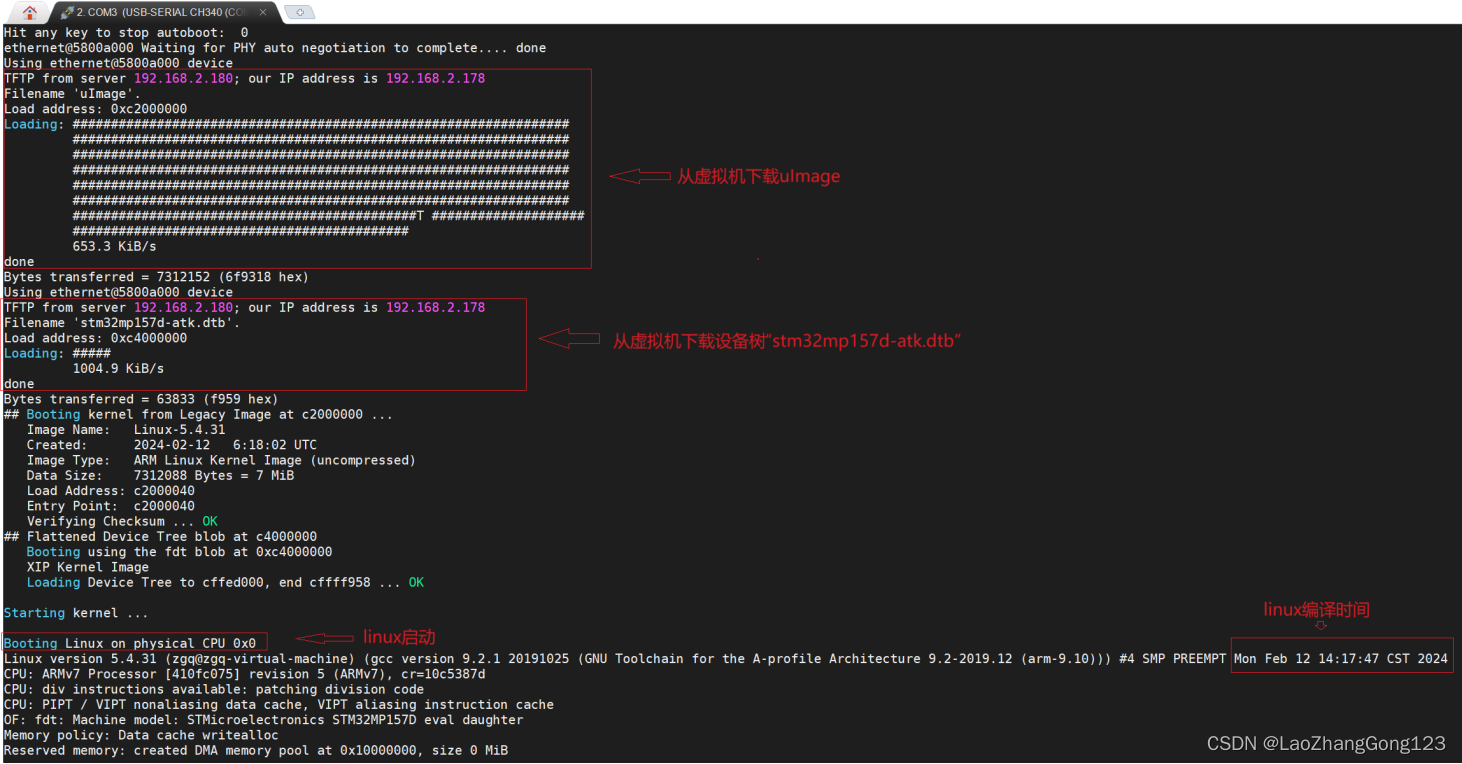
Linux第52步_移植ST公司的linux内核第4步_关闭内核模块验证和log信息时间戳_编译_并通过tftp下载测试
1、采用程序配置关闭“内核模块验证” 默认配置文件“stm32mp1_atk_defconfig”路径为“arch/arm/configs”; 使用VSCode打开默认配置文件“stm32mp1_atk_defconfg”,然后将下面的4条语句屏蔽掉,如下: CONFIG_MODULE_SIGy CONFIG_MODULE_…...
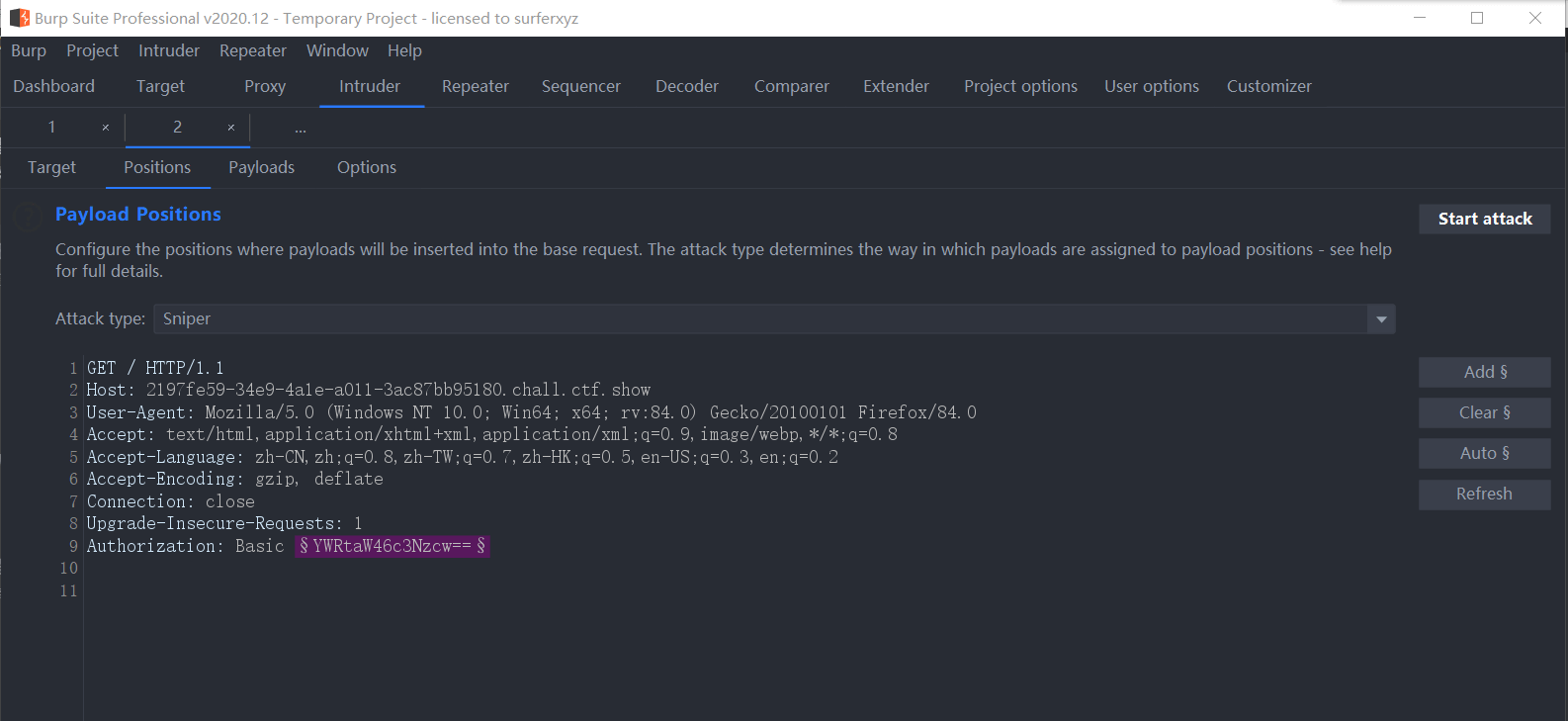
ctfshow-web21~28-WP
爆破(21-28) web21 题目给了一个zip文件,打开后解压是爆破的字典,我们抓包一下网址看看 发现账号和密码都被base64了,我们发送到intruder模块,给爆破的位置加上$符圈住 去base64解码一下看看格式...

鸿蒙开发系列教程(二十四)--List 列表操作(3)
列表编辑 1、新增列表项 定义列表项数据结构和初始化列表数据,构建列表整体布局和列表项。 提供新增列表项入口,即给新增按钮添加点击事件。 响应用户确定新增事件,更新列表数据。 2、删除列表项 列表的删除功能一般进入编辑模式后才可…...

线性代数笔记2--矩阵消元
0. 简介 矩阵消元 1. 消元过程 实例方程组 { x 2 y z 2 3 x 8 y z 12 4 y z 2 \begin{cases} x2yz2\\ 3x8yz12\\ 4yz2 \end{cases} ⎩ ⎨ ⎧x2yz23x8yz124yz2 矩阵化 A [ 1 2 1 3 8 1 0 4 1 ] X [ x y z ] A \begin{bmatrix} 1 & 2 & 1 \\ 3 & …...

透光力之珠——光耦固态继电器的独特特点解析
光耦固态继电器作为现代电子控制领域中的重要组件,以其独特的特点在工业、通信、医疗等多个领域得到广泛应用。本文将深入剖析光耦固态继电器的特点,揭示其在电子控制中的卓越性能。 光耦固态继电器的光电隔离技术 光耦固态继电器以其光电隔离技术而脱颖…...
C#系列-EntityFrameworkCore.Transactions.Abstractions应用场景+实例(38)
EntityFrameworkCore.Transactions.Abstractions应用场景 EntityFrameworkCore.Transactions.Abstractions 并不是一个官方的或广泛认可的 NuGet 包名称。在 Entity Framework Core (EF Core) 中,事务管理通常是通过 DbContext 的内置方法来实现的,如 Sa…...

PMDG 737
在Simbrief中生成计划后下载两个文件 放到C:\Users\32497\AppData\Local\Packages\Microsoft.FlightSimulator_8wekyb3d8bbwe\LocalState\packages\pmdg-aircraft-737(微软商店版本) 加油 先在飞行计划中查看计划燃油数量 MCDU中, AIRPLANE SEVICE 第二页, REQUEST FUEL TR…...

深入探索Midjourney:领航人工智能的新征程
深入探索Midjourney:领航人工智能的新征程 引言 在这个数据驱动、以技术创新为核心的时代,Midjourney以其独特的特性在人工智能领域中崭露头角。作为一款前沿的人工智能工具,它不仅重新定义了人机交互的方式,而且为各行各业提供…...
ChatGPT高效提问—prompt实践(漏洞风险分析-重构建议-识别内存泄漏)
ChatGPT高效提问—prompt实践(漏洞风险分析-重构建议-识别内存泄漏) 1.1 漏洞和风险分析 ChatGPT还可以帮助开发人员预测代码的潜在风险,识别其中的安全漏洞,而不必先运行它,这可以让开发人员及早发现错误࿰…...

如何完全掌握微信聊天数据:WeChatMsg免费工具的终极指南
如何完全掌握微信聊天数据:WeChatMsg免费工具的终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeC…...

为什么你的Zotero无法正确处理中文文献?Jasminum给出完美答案
为什么你的Zotero无法正确处理中文文献?Jasminum给出完美答案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 在学术研…...

PromptSource与环保科技NLP:环境数据分析的提示工程指南
PromptSource与环保科技NLP:环境数据分析的提示工程指南 【免费下载链接】promptsource Toolkit for creating, sharing and using natural language prompts. 项目地址: https://gitcode.com/gh_mirrors/pr/promptsource 在当今环保科技领域,自然…...

如何快速入门WebGL:10个实用技巧带你玩转3D图形
如何快速入门WebGL:10个实用技巧带你玩转3D图形 【免费下载链接】WebGL The Official Khronos WebGL Repository 项目地址: https://gitcode.com/gh_mirrors/we/WebGL WebGL(Web Graphics Library)是用于在网页浏览器中渲染交互式2D和…...

Unity网格变形系统深度解析:从基础架构到高级应用实践
Unity网格变形系统深度解析:从基础架构到高级应用实践 【免费下载链接】Deform A fully-featured deformer system for Unity that lets you stack effects to animate models in real-time 项目地址: https://gitcode.com/gh_mirrors/de/Deform Deform是一个…...

如何快速评估网络性能:Windows平台iperf3完整指南
如何快速评估网络性能:Windows平台iperf3完整指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3是一款专业的网络性能测试工具&…...
 uniapp中使用vuex)
【uniapp】(6) uniapp中使用vuex
uniapp内置了vuex,不需要通过npm重新安装,直接引用即可1、创建 Vuex Store(1)在uniapp项目根目录下创建 store/index.jsimport Vue from vue import Vuex from vuexVue.use(Vuex)const store new Vuex.Store({//存放状态state: …...

每日一书⑩ | AI 未来:未来不属于 AI,属于会用 AI 的人
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”01 开篇:AI 不是科幻,是正在发生的现实你可能觉得 AI 还很遥远,但它已经渗透进生活的每个角落:…...

javaweb摄影约拍系统的设计与实现聊天
目录同行可拿货,招校园代理 ,本人源头供货商聊天功能需求分析技术实现方案后端设计前端实现扩展功能建议性能优化项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 聊天功能需求分析 在摄…...

3个专业技巧:BilibiliDown跨平台B站视频下载器的完整应用指南
3个专业技巧:BilibiliDown跨平台B站视频下载器的完整应用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...