【python】网络爬虫与信息提取--requests库
导学
当一个软件想获得数据,那么我们只有把网站当成api就可以
requests库:自动爬取HTML页面,自动网络请求提交
robots协议:网络爬虫排除标准(网络爬虫的规则)
beautiful soup库:解析HTML页面
工具:
IDLE:适用于python入门,功能简单直接,300+行代码以内
Sublime Text编译器:专门为程序员开发的第三方专用编程工具,专业编程体验
Wing:公司维护,工具收费;调试功能丰富;版本控制,版本同步;适合多人共同开发
PTVS:微软公司维护、调试功能丰富
PyCharm:简单,集成度高,适合较复杂工程
一、requests库
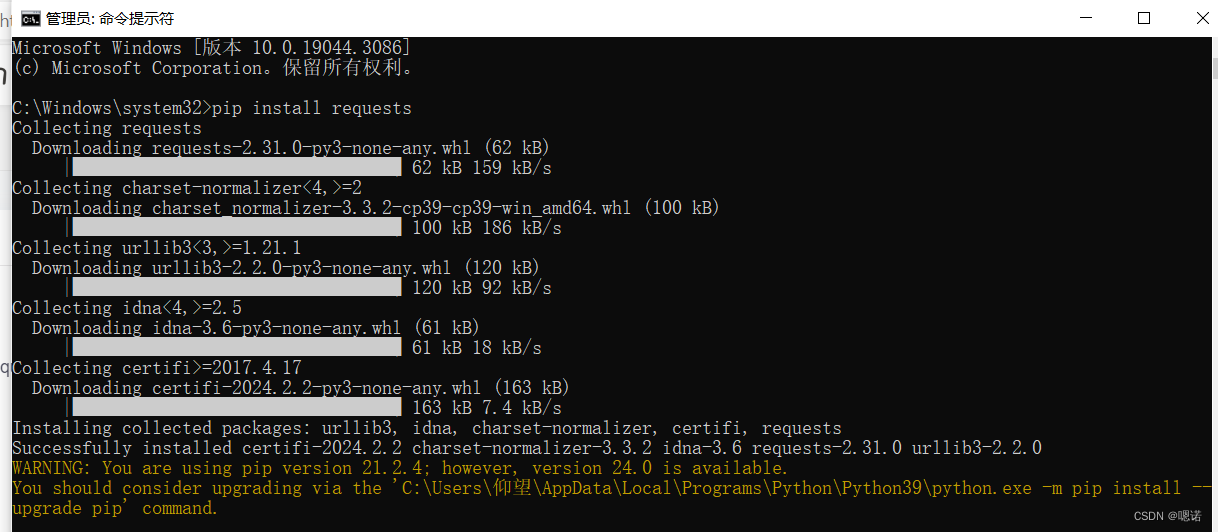
1.安装:
以管理员身份运行命令提示符,输入 pip install requests 后回车
2.使用:
启动idle(IDLE是Python自带的IDE;打开IDLE:按Win键,输入“idle”,回车;运行:F5)
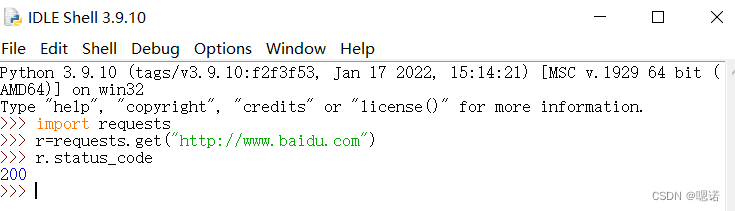
测试一下(以访问百度主页为例子),状态码为200,表示访问成功
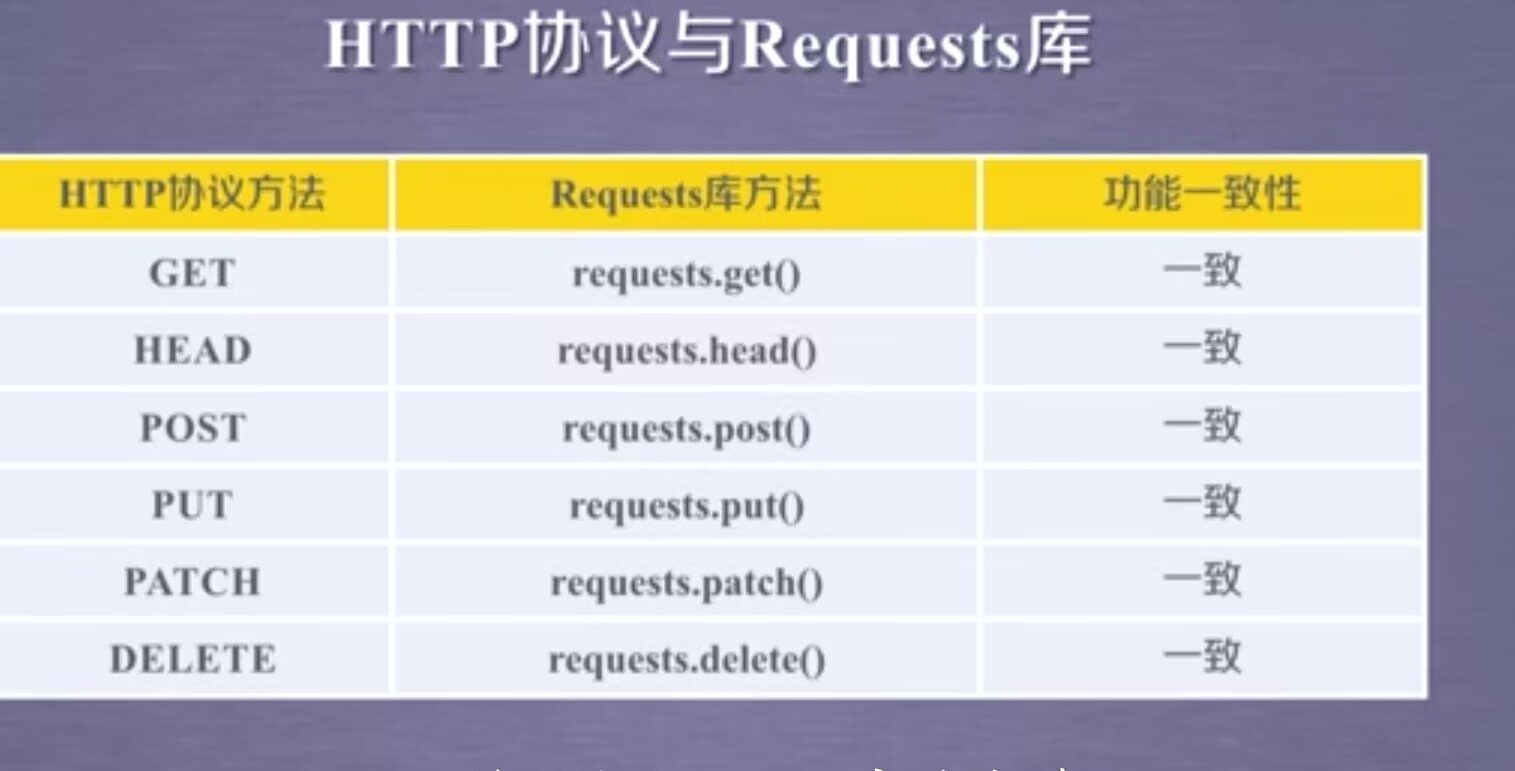
3.requests库的7个主要方法

这7个常用方法,除了第一个requests.request()方法是基础方法外,其他的6个方法都是通过调用requestsequest()方法实现的
4.requests.get(URL)
完整的使用:requests.get(url,params=None,**kwargs);其中url是拟获取页面的url链接,params指的是url中的额外参数,字典或者字节流格式,可选;kwargs是12个控制访问的参数
作用:获取一个网页 r=requests.get(url)
原理:构造一个向服务器请求资源的request对象(这个对象由requests库自动生成),返回的Response对象包含从服务器返回的所有资源.

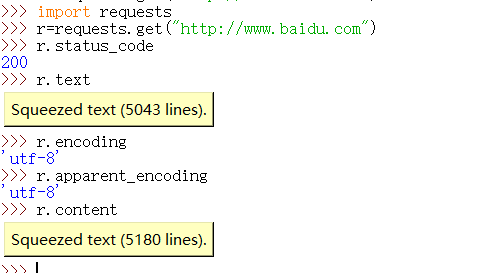
r.encoding的编码方式是从http header中的charset字段获得.如果http header中有这样一个字段,说明我们访问的服务器对它的资源的编码是有要求的,这样的要求会返回回来,存在r.encoding中。但是,不是所有服务器都会对它的资源编码有相关的要求,所以,如果header中不存在charset,则默认编码为ISO-8859-1,但这样的编码并不能解析中文,所以requests库提供了一个备选编码r.apparent_encoding,实际上这个编码做的内容是根据http的内容部分而不是头部分,去分析内容文本中 可能的编码方式。
5.爬取网页的通用代码框架
代码框架其实就是一组代码,它可以准确可靠的爬取网页内容。
我们爬取的时候喜欢用requests.get(url)获取url的相关内容,但是这样的语句并不是一定成立的,因为网络连接有风险,所以这样的语句它的异常处理很重要

补充一个response异常:r.raise_for_status()--判断返回的response的类型,如果不是200,产生异常requests.HTTPError


6.HTTP协议以及Requests库方法
HTTP,超文本传输协议。是一个基于“请求与响应”模式的、无状态(第一次请求与第二次请求之间并没有相关的关联)的应用层协议(指的是该协议工作在TCP协议之上)。HTTP协议采用URL作为定位网络资源的标识。
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,URL对应一个数据资源。
URL格式:http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径



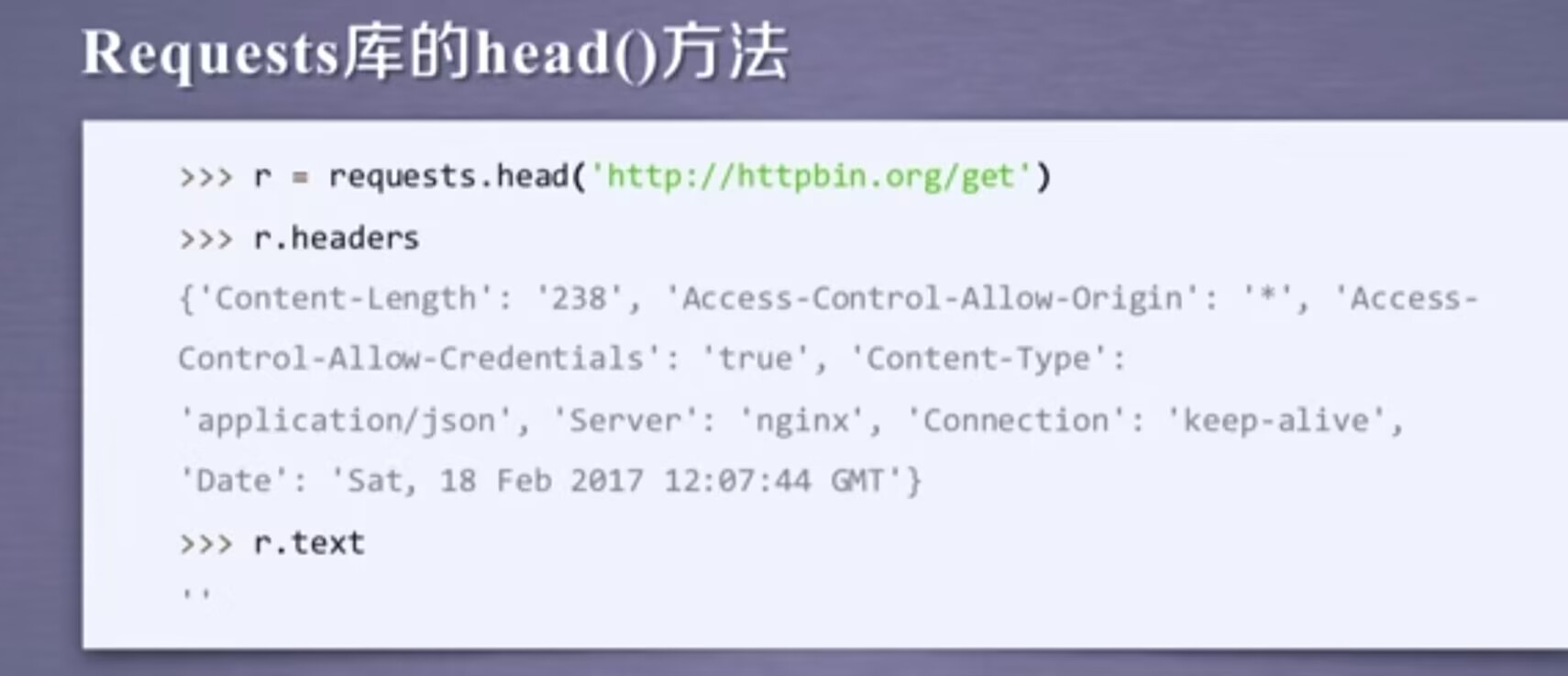
head()方法用来展示反馈的头部信息的内容,当我们想试图用r.text展示它的全部内容,会发现内容是空的。作用:可以用很少的网络流量获取网络资源的概要信息。

post方法可以向服务器提交新数据。这里我们首先建立了一个字典叫payload,它里面包含两个键值对,然后用post方法去提交这样的一个字典,接着看下返回的内容,发现键值对被放在form下,说明当我们post一个字典或者post键值对的时候,那么键值对会默认的被存储在表单的字段下。

当我们post一个字符串的时候,我们会发现字符串被存到了data相关的字段下。
post根据我们提交的内容不同,在服务器上会做数据的相关的整理

put方法与post方法类似。
7.Requests库主要方法解析
事实情况是,由于网络安全的限制,我们很难向一个url去发起post,put,patch,delete请求,因此我们在爬虫时,经常使用的是get和head方法。
7.1 request
完整格式:requests.request(method,url,**kwargs)
method:请求方,对应get/pu/post等七种
url:拟获取页面的url链接
**kwargs:控制访问的参数,共13个

options其实就是向服务器获取一些服务器跟客户端能够打交道的参数,这里面并不与获取资源直接相关,我们平时使用较少。

比如params=kv,可以实现一些键值对增加到url中,那么使得url再去访问时,不只访问的是这个资源,而同时代入了一些参数,那服务器就可以接受这些参数,并根据这些参数筛选部分资源。

data:向服务器提供或提交资源时使用,当构建键值对的时候,把它作为data的一部分去提交。我们所提交的键值对,并不直接放在url链接,而是放在url链接对应位置的地方。
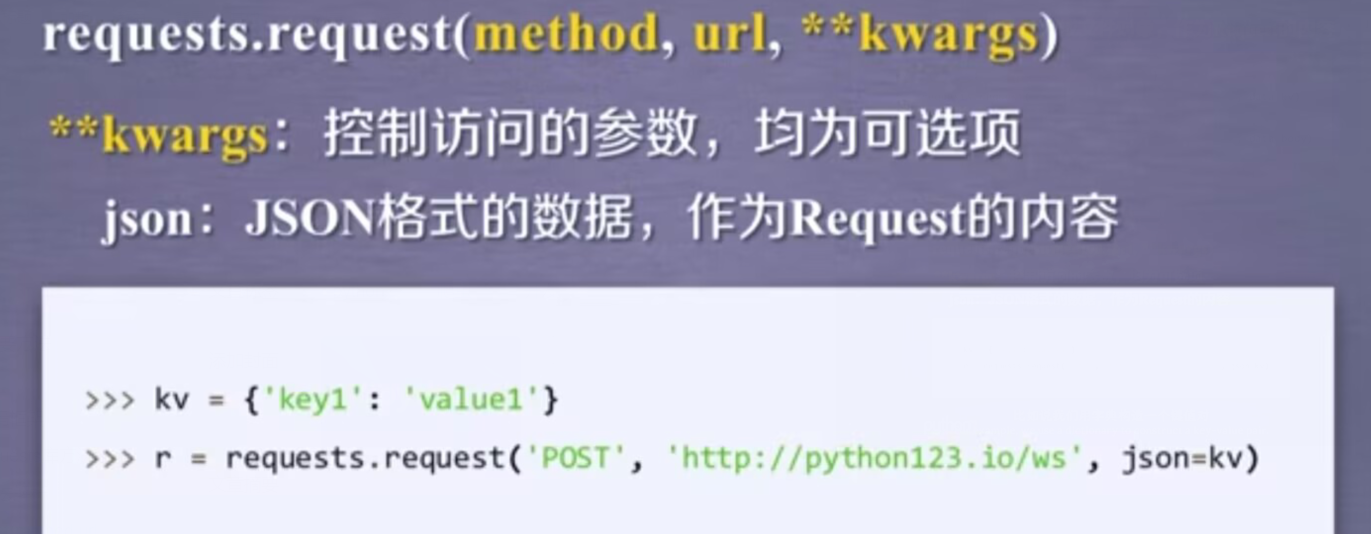
比如,当我们用构建一个键值对,然后我们可以把它的值给json参数,那么这个键值对就复制到服务器的json域上。
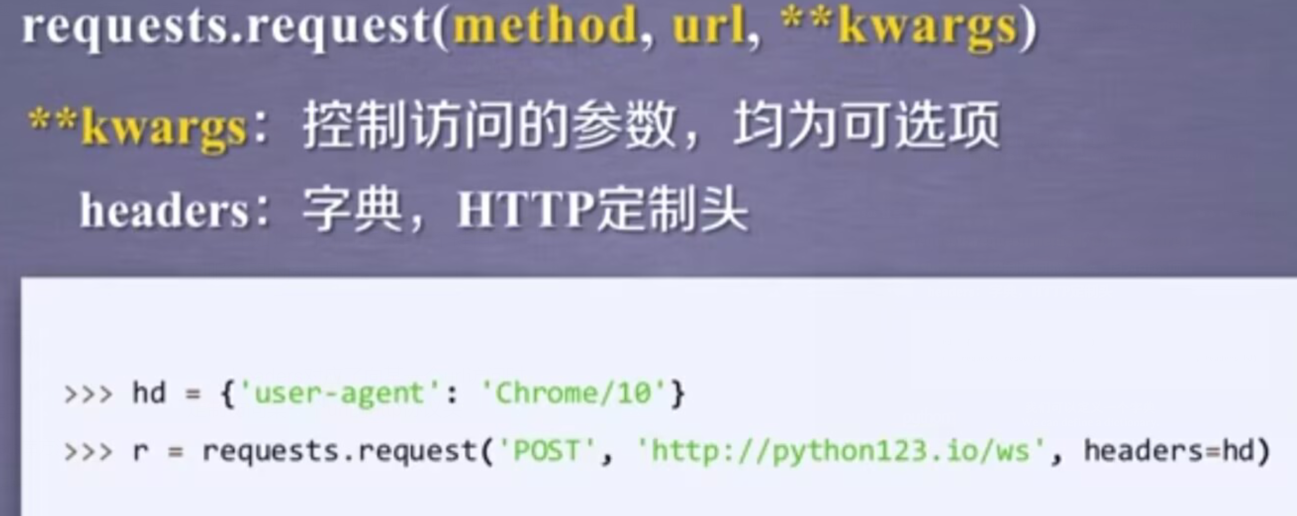
headers对应了向某一个url访问时,所发起的http的头字段。简单说,我们可以用这个字段来定制访问某一个url的http协议头。我们可以定义一个字典,然后去修改HTTP协议中的user-agent字段,那么在访问一个链接时,我们可以把这样的字段赋给header,此时,header再向服务器访问时,服务器看到的user-agent字段就是修改后的内容。

cookies:指的是从http协议中解析cookie,那么它可以是字典也可以是cookieJar的形式
auth字段是一个元组类型,与cookies都是高级功能。
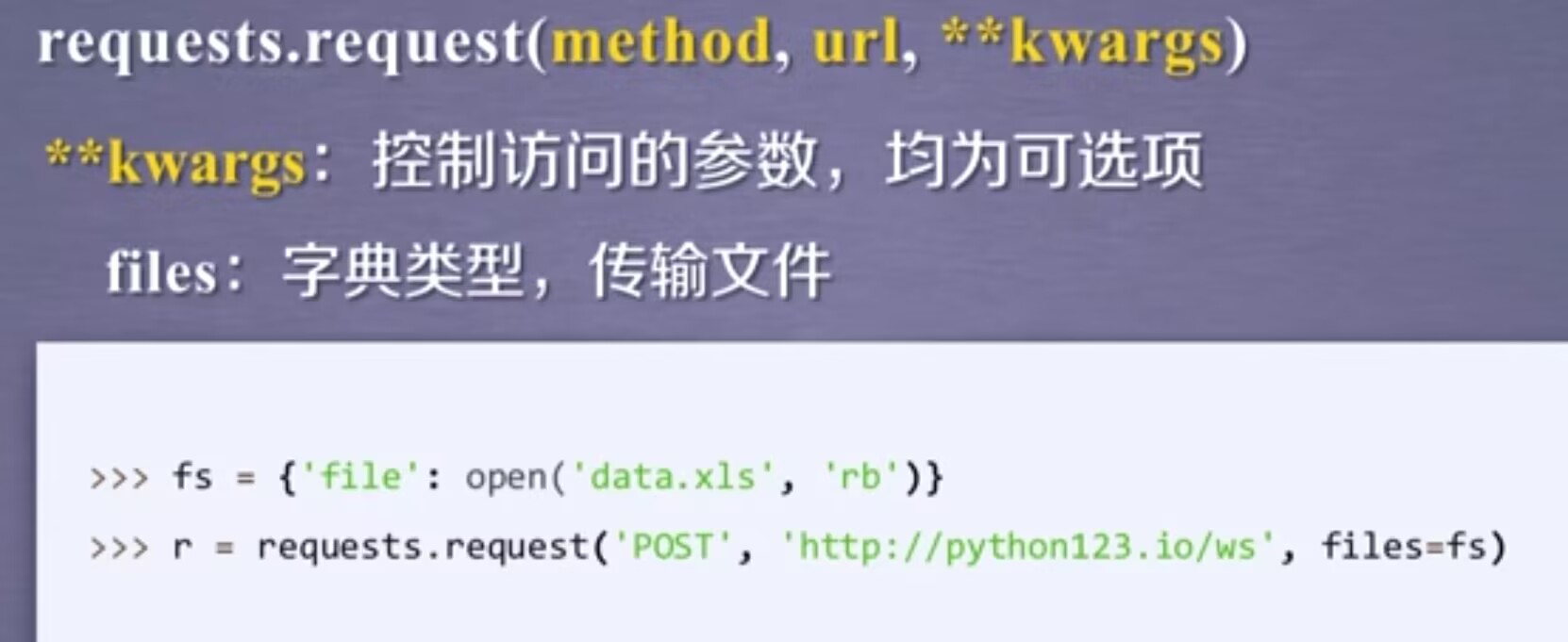
files:字典类型,它是向服务器传输文件时使用的字段。定义一个字典,以对应的文件为键值对,用open的方式打开这个文件,并把这个文件与file做一个关联,同时对应到相关的url上,这样的方法我们可以向某一个链接提交某一个文件。

在规定timeout时间内,我们的请求内容没有反馈回来,那么它将产生一个timeout的异常

proxies:可以为我们爬取网页设定相关的访问代理服务器。在上图中,我们增加了两个代理,一个是http访问时使用的代理,而在这个代理中我们可以增加用户名跟密码的设置,另一个是https的代理服务器,那这样我们在访问百度时,我们所使用的ip地址就是代理服务器的ip地址。使用这个字段可以有效的隐藏用户爬取网页的源ip地址信息,能有效防止对爬虫的逆追踪。

allow_redirects像是一个开关,表示允不允许对url重定向。stream也是一个开关,指对获取的内容是否进行立即下载,默认是立即下载。cert字段是保持本地ssl证书的字段。
7.2 get

7.3 head

7.4 post

7.5 put

7.6 patch

7.7 delete

二、盗亦有道
网络爬虫按尺寸可以分为三类:小规模(占了90%以上)使用requests库即可,中规模使用scrapy库,大规模你只能定制开发,第三方无法实现。

对于服务器来说,它默认是按照人数来约束它的访问能力。但是有爬虫爬取相关的内容,甚至说1秒内可以爬取10万甚至几万的情况下,服务器是很难提供那么高的性能的,因此对于某些爬虫,是受限于爬虫编写者的水平和它的目的,那么这样将会为服务器带来巨大的资源开销,从而对于网站运行着来说,爬虫形成了骚扰。
爬虫引发的问题:骚扰问题,法律风险,隐私泄露

反爬之来源审查:简单来说,作为网站的维护者,可以只响应浏览器或者已知的友好爬虫的访问。这个方法需要对维护网站的技术人员的能力有一定要求。
三、Robots协议
Robots协议:网络爬虫排除标准。
作用:
网站告知网络爬虫哪些页面可以抓取,哪些不行。
形式/使用:
在网站根目录下放置一个robots.txt文件,这个文件写明了在一个网站里的哪些目录是允许爬虫去爬取的,哪些目录是不许爬取的。
语法:
User-agent: ,Disallowed: ,(#注释,*表示所有,/表示根目录)
案例:
京东的Robots协议 https://www.jd.com/robots.txt

User-agent:*,指的是如果你对于任何的网络爬虫来源,都应该遵守如下的协议。
Disallow:/?* 表示任何爬虫都不允许访问,/?* 也就是以问好开头的路径
Disallow:/pop/*.html和 Disallow:/pinpai/*.html表示满足这些个通配符的内容都是不允许访问的。
此外,京东的Robots协议又提供了User-agent:EtaoSpider等,他们后面还跟着 Disallow:/,表示的是这四个网络爬虫是不允许爬取京东的任何资源。(可以理解为这四个是恶意爬虫,被京东发现后,因此拒绝它们对京东的任何数据访问。
其他练习链接:
qq.com/robots.txt QQ
baidu.com/robots.txt 百度
news.sina.com.cn/robots.txt 新浪微博
news.qq.com/robots.txt QQ邮箱
需注意,Robots协议一定是放在网站的根目录下。但是对于新浪来说,www.sina.com.cn和news.sina.com.cn是两个不同的根目录,所以我们看两个网站的Robots协议是不一样的。另外,不是所有网站都具有Robots协议比如我们国家的教育网站.Robots协议规定,如果一个网站不提供robots.txt文件,那么这个网站是允许所有爬虫的。
Robots协议遵守方式:


类人行为可不参照Robots协议: 任何网站提供资源,它都是方便2人类获取相关的信息,如果你的网络爬虫能够和人类获取相关的信息相一致(也就是说每次访问的量很少,访问的量不大,如一天或者一小时才访问一次)
四、实战
案例1:京东商品页面的爬取
我们要做的是,提供写程序获得该商品的信息
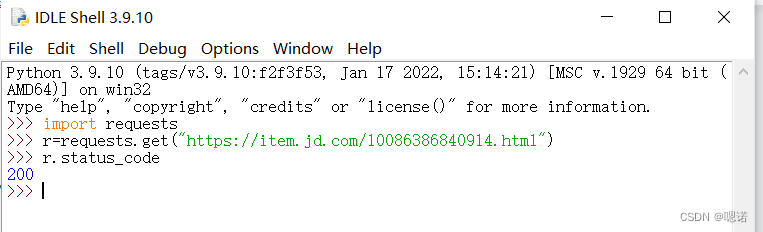
1.首先打开京东页面选取一个商品:https://item.jd.com/10086386840914.html
2.打开idle,get刚刚的链接,查看返回的状态码,200表示链接成功,并且获得了这个链接响应的内容
3.查看encoding,这说明我们已经能从HTTP的头部分解析出这个页面的编码信息,这说明了京东页面显示了相关的编码

4.查看 内容是否正确。

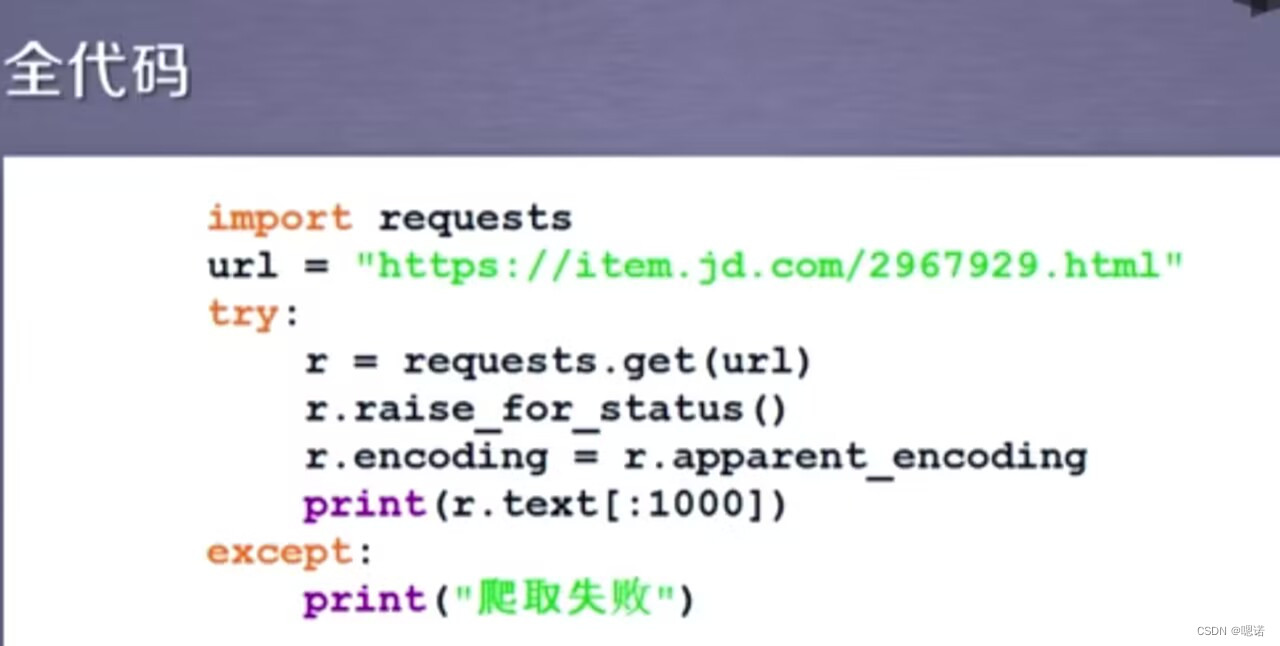
5.以下为京东商品页面的全代码。
案例2:亚马逊商品页面的爬取
https://www.amazon.cn/gp/product/B01M8L5Z3Y

发现返回的是503 ,查看编码
![]()
将编码改成可以阅读的相关编码后查看文本

目前,全部代码如下

事实上,当我们能从服务器上获得相关信息回来,那么这个错误已经不是网络出现的错误了。网站一般接受的是浏览器的请求,而对爬虫的请求是拒绝的。
通过r.request.headers查看我们请求的request长什么样。
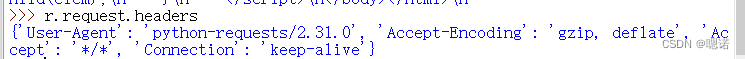
通过上图,可以看见头部中的user-agent 显示的是python-requests/2.31.0,这说明我们的爬虫忠实的告诉了亚马逊的服务器,这次访问是由一个python的requests库的程序产生的,如果亚马逊提供了来源审查(反爬虫手段),它就可以使这样的访问变得错误,或者说它不支持这样的访问。
接下来尝试一下,模拟浏览器向亚马逊发送请求。
首先构造一个键值对,这样的一个键值对信息说明的是,我们重新定义了user-agent的内容。Mozilla/5.0(很标准的浏览器身份标识的字段)说明这个时候的user-agent可能是一个浏览器,这个浏览器可能是火狐,可能是Mozilla,甚至可能是IE10的浏览器。
然后我们找到刚才的url链接,修改headers后再次访问status_code,发现返回的不是503,是200,这是说明我们真真正正的获得了一个产品的页面。
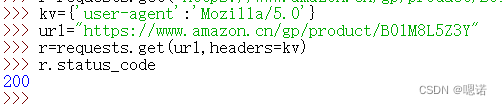
再次查看user-agent的内容,发现user-agent的内容已经修改。
 此时再去访问r.text就是真正的页面内容了
此时再去访问r.text就是真正的页面内容了
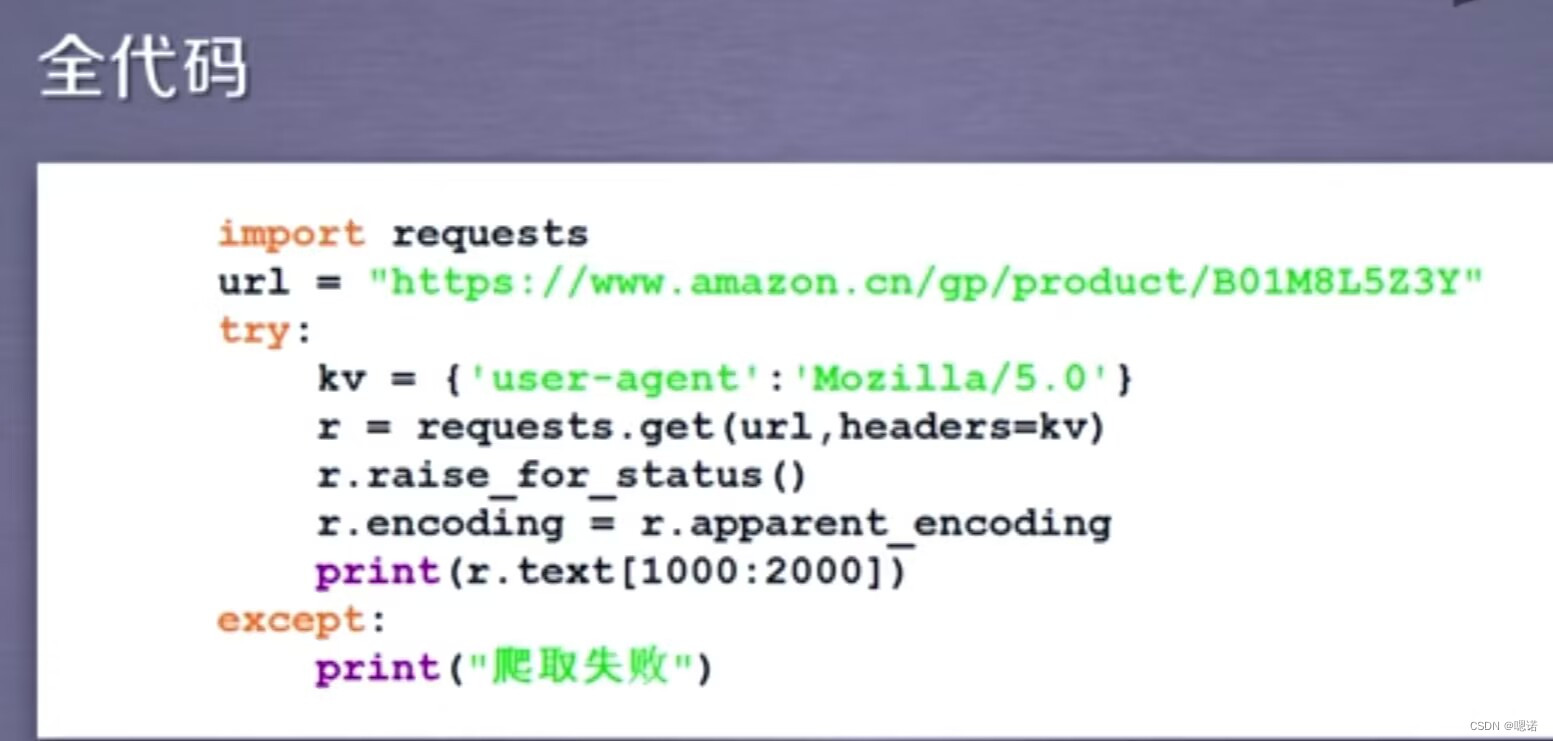
下面给出访问亚马逊产品的全部代码。在这个代码中与访问京东商品代码不同,我们需要通过headers字段让我们的代码模拟浏览器向亚马逊服务器提供HTTP请求。
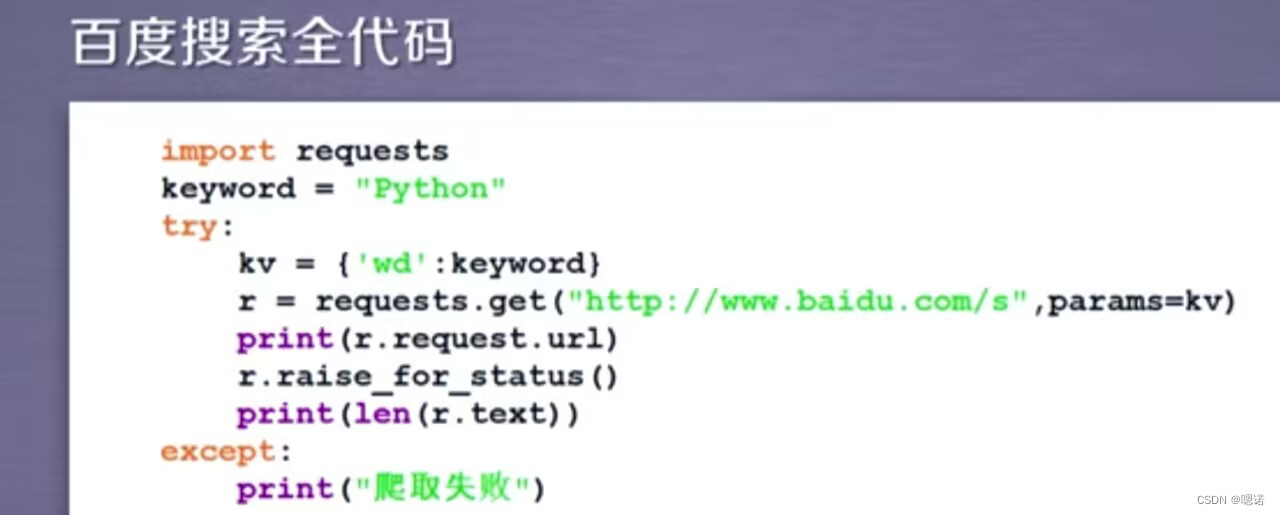
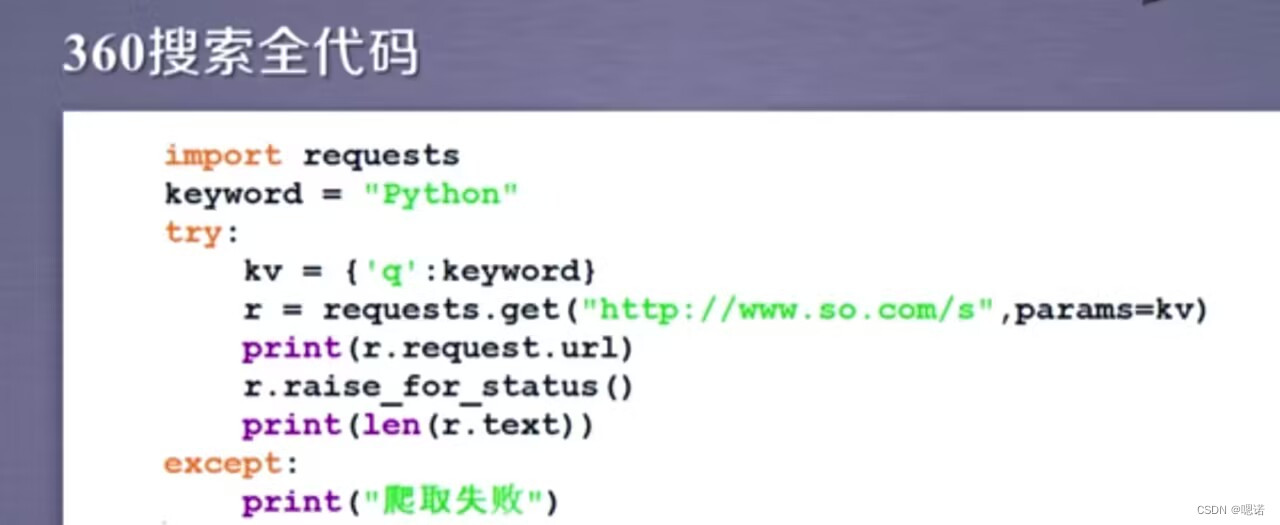
案例3:百度360搜索关键词提交
目的:用程序自动的向百度和360这俩个搜索引擎提交关键词并且获得它的搜索结果。

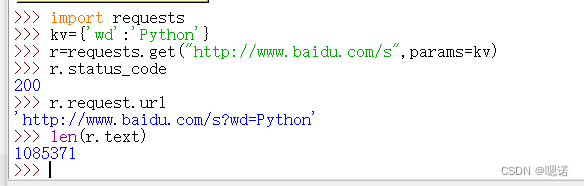
百度和360的区别主要在键不一样,百度是wd,360是q
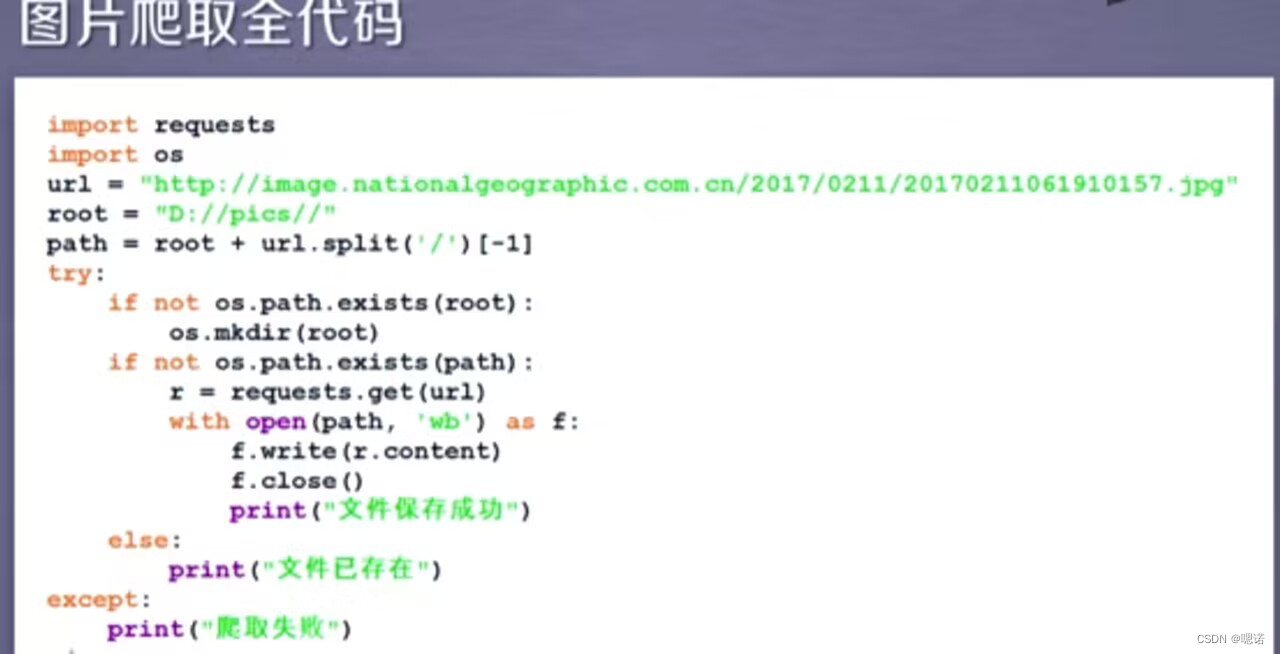
案例4:网络图片的爬取和存储
(该方式不止针对图片,对二进制的资源格式比如 图片、视频、动画等,都可以用同样的代码获取它。)

练习链接如下:
http://img0.dili360.com/ga/M02/33/7C/wKgBzFSbqQyAJVAuAARB8cSWH_w695.tub.jpg@!rw14
设定保存下来的图片名字为abc.jpg,方便我们后期处理
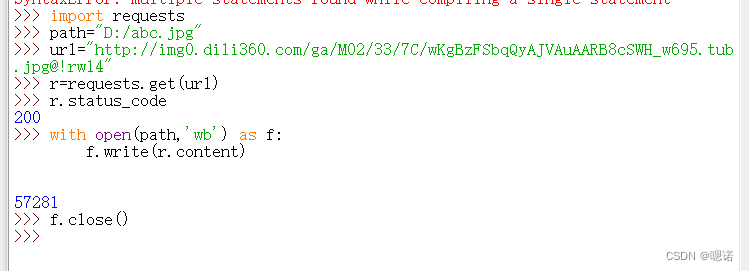
with open(path,'wb') as f:
f.write(r.content)这串代码表示先打开我们要存储的abc.jpg文件,并且把它定义为一个文件标识符f,然后我们将返回的内容(response返回的格式是二进制)写到这个文件中,即利用f.write(r.content)将返回的二进制形式写到文件中。
f.close()表示关闭这个文件
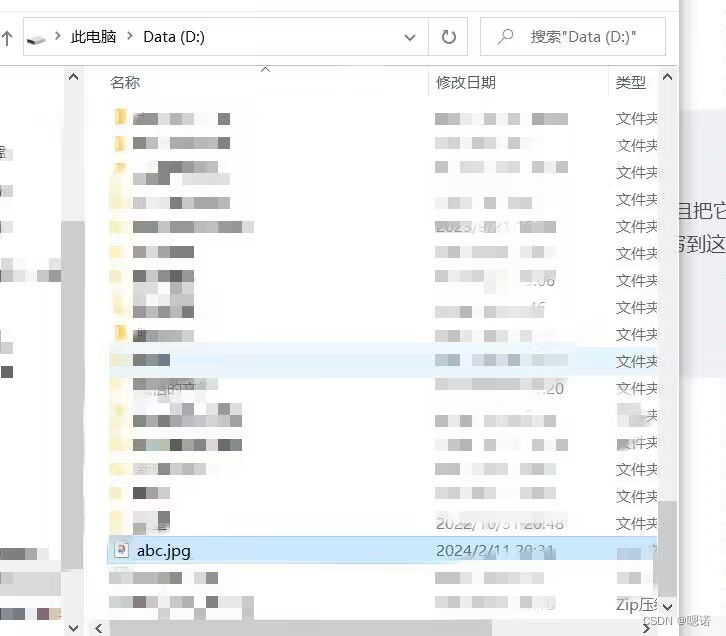
接着我们去D盘看一下这个abc.jpg文件
图片爬取全代码:
!案例5:IP地址归属地的自动查询(之前可以成功,现会报错)
现成的查ip网站 :

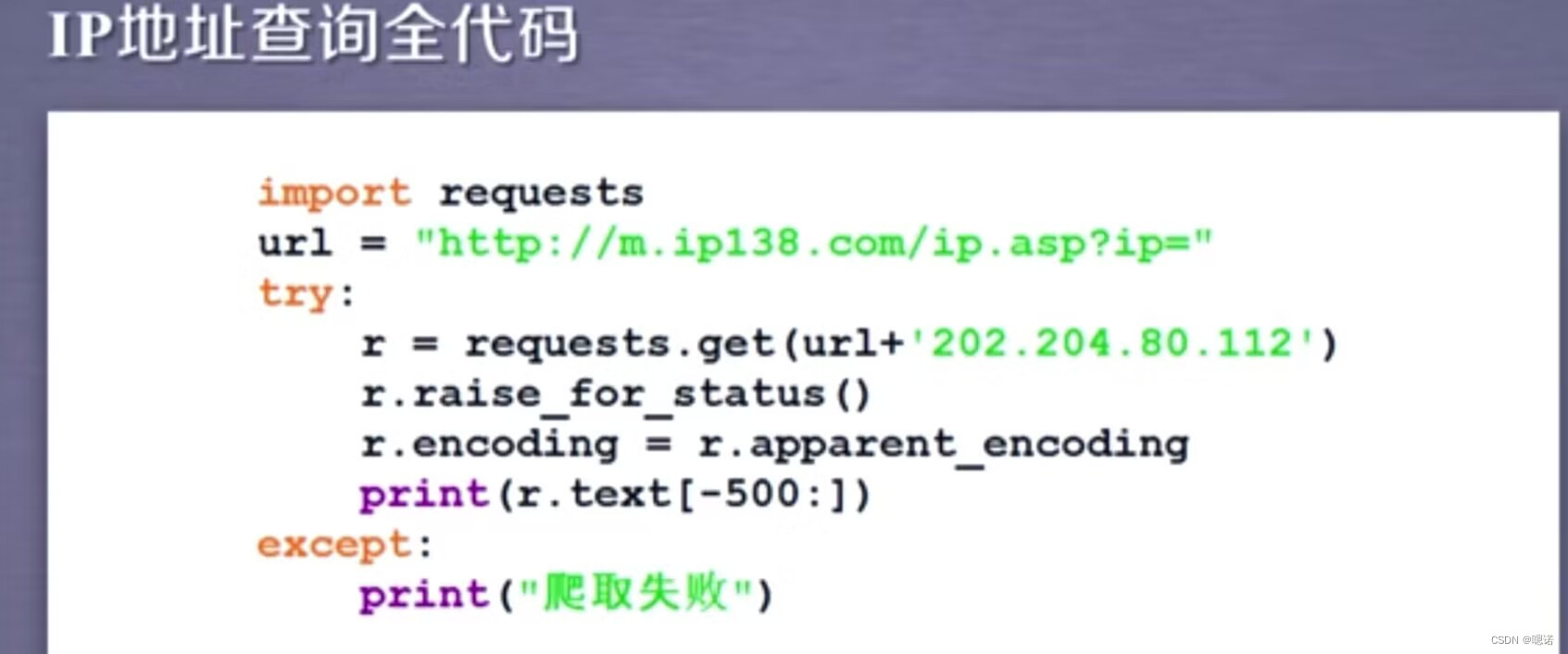
我们有的时候在网站看到的人机交互方式,比如说图形与文本框的、需要点击按钮的这种方式,在正式地向后台服务器提交的时候,其实都是以链接的形式提交的,只要我们能够通过浏览器的解析,知道向后台去提交的链接形式,那 就可以用python代码模拟。
相关文章:
【python】网络爬虫与信息提取--requests库
导学 当一个软件想获得数据,那么我们只有把网站当成api就可以 requests库:自动爬取HTML页面,自动网络请求提交 robots协议:网络爬虫排除标准(网络爬虫的规则) beautiful soup库:解析HTML页面 工具&…...
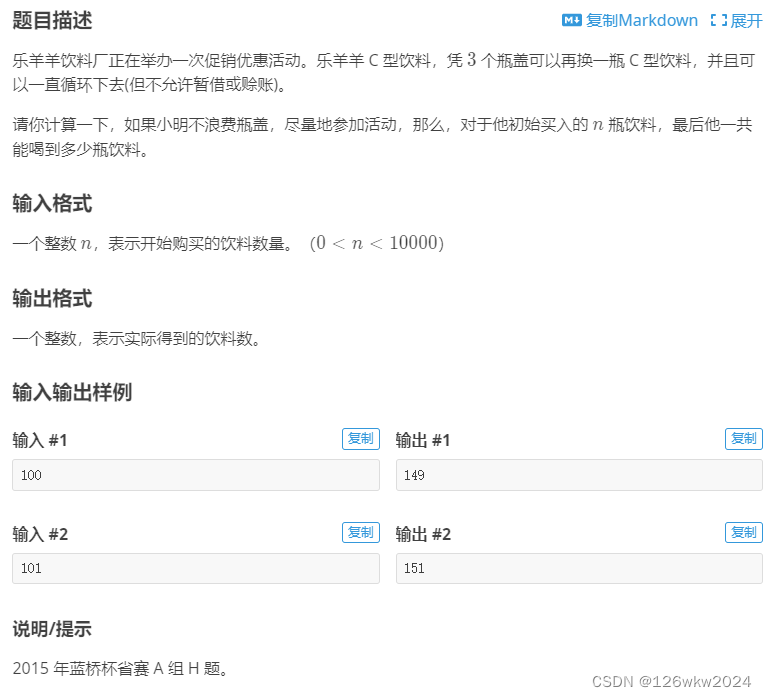
洛谷 P8627 [蓝桥杯 2015 省 A] 饮料换购
参考代码and代码解读 #include <bits/stdc.h> using namespace std; int main() { int n; scanf("%d", &n); int dr;//drdrink; dr n;//把drink赋值于n; while (n > 2) {//剩余的总瓶盖数要大于二,才能换得下一瓶饮料; dr n…...

Academic Inquiry|投稿状态分享(ACS,Wiley,RSC,Elsevier,MDPI,Springer Nature出版社)
作为科研人员,我们经常会面临着向学术期刊投稿的问题。一般来说,期刊的投稿状态会在官方网站上进行公示,我们可以通过期刊的官方网站或者投稿系统查询到我们投稿的论文的状态,对于不同的期刊在投稿系统中会有不同的显示。 说明&am…...
)
1+X运维试题样卷C卷(初级)
云计算C卷 单选题(200分) 1.在OSI模型中,HTTP协议工作在第()层,交换机工作在第()层。(10分) (答案未做:0分) A、7/3 B、7/2 (正确答案) C、6/3 D、6/2 2.Linux有三个查看文件的命令,若希望在查看文件内容过程中可以用光标上下移动来查看文件内容,应使用命令。(10分…...
Spring的控制反转(设计原则)与依赖注入(设计模式))
Spring学习笔记(二)Spring的控制反转(设计原则)与依赖注入(设计模式)
一、控制反转:缩写IoC 是一种设计原则,降低程序代码之间的耦合度 对象由Ioc容器统一管理,当程序需要使用对象时直接从IoC容器中获取。这样对象的控制权就从应用程序转移到了IoC容器 二、依赖注入:缩写DI 依赖注入是一种消除类之…...
MySQL 基础知识(四)之表操作
目录 1 约束 2 查看已有表 3 创建表 4 查看表结构 5 修改表 6 删除表 1 约束 主键约束 primary key:唯一,标识表中的一行数据,此列的值不可重复,且不能为 NULL,此外,可以多个列组成主键唯一约束 uniq…...

计算机网络——10FTP
FTP FTP:文件传输协议 向远程主机上传输文件或从远程主机接收文件客户/服务器模式 客户端:发起传输的一方服务器:远程主机 ftp:RFC 959ftp服务器:端口号为21 FTP:控制连接与数据连接分开 控制连接 FTP客户端与FTP服…...

javascript中的this指向
文章目录 探索 JavaScript 中的神奇之谜:this关键字解析this 是什么?为何 this如此重要?this 的工作原理实例解析默认绑定隐式绑定显式绑定new 绑定 探索 JavaScript 中的神奇之谜:this关键字解析 JavaScript,作为一门…...
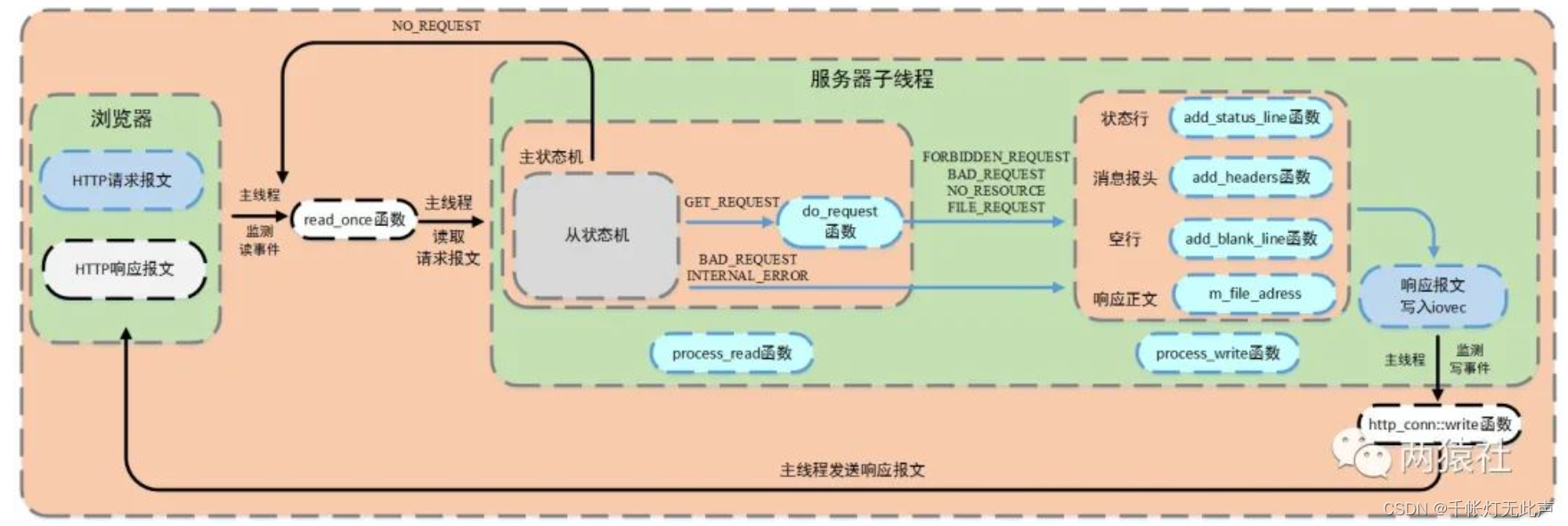
WebServer 之 http连接处理(下)
目录 ✊请求报文--解析 流程图 && 状态机 状态机 -- 状态转移图 主状态机 从状态机 http 报文解析 HTTP_CODE 含义 从状态机 逻辑 主状态机 逻辑 🐞请求报文--响应 基础API stat mmap iovec writev 流程图 HTTP_CODE 含义(2) 代码分析 …...

Android电量相关知识
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、 查看耗电情况3.1 注册广播 ACTION…...
【Java多线程】线程中几个常见的属性以及状态
目录 Thread的几个常见属性 1、Id 2、Name名称 3、State状态 4、Priority优先级 5、Daemon后台线程 6、Alive存活 Thread的几个常见属性 1、Id ID 是线程的唯一标识,由系统自动分配,不同线程不会重复。 2、Name名称 用户定义的名称。该名称在各种…...

鸿蒙OS跨进程IPC与RPC通信
一、IPC与RPC通信概述 基本概念 IPC(Inter-Process Communication)与RPC(Remote Procedure Call)用于实现跨进程通信,不同的是前者使用Binder驱动,用于设备内的跨进程通信,后者使用软总线驱动…...
)
Effective Objective-C 学习(三)
理解引用计数 Objective-C 使用引用计数来管理内存:每个对象都有个可以递增或递减的计数器。如果想使某个对象继续存活,那就递增其引用计数:用完了之后,就递减其计数。计数变为 0时,就可以把它销毁。 在ARC中…...

蓝桥杯备赛攻略
背景 第十五届蓝桥杯大赛快要到比赛的时间了,按照惯例省赛就在4月9号开赛。有很多的小伙伴都报名了这次比赛,也有很多的同学问我应该怎么训练,什么水平可以拿奖。我自己也已经参加过两届蓝桥杯大赛了,拿到过国赛三等奖࿰…...

react反向代理
http-proxy-middleware 使用npm安装 npm i -D http-proxy-middleware 文档 点击查看 关键代码 const { createProxyMiddleware } require(http-proxy-middleware);module.exports function(app) {app.use(/api, // api开头的地址的请求createProxyMiddleware({target: ht…...

债券专题二:可转债估值-二叉树模型
1. 模型背景 由于可转债自身的属性较多,因此对其定价的难度也会加大,在诸多影响因素中,未来的股价占比最高。由于股价的不可预测性,导致了可转债的定价在实际交易中作用非常有限。随着可转债发行数量和规模的增大,越…...

【闲谈】开源软件的崛起与影响
随着信息技术的快速发展,开源软件已经成为软件开发的趋势,并产生了深远的影响。开源软件的低成本、可协作性和透明度等特点,使得越来越多的企业和个人选择使用开源软件,促进了软件行业的繁荣。然而,在使用开源软件的过…...
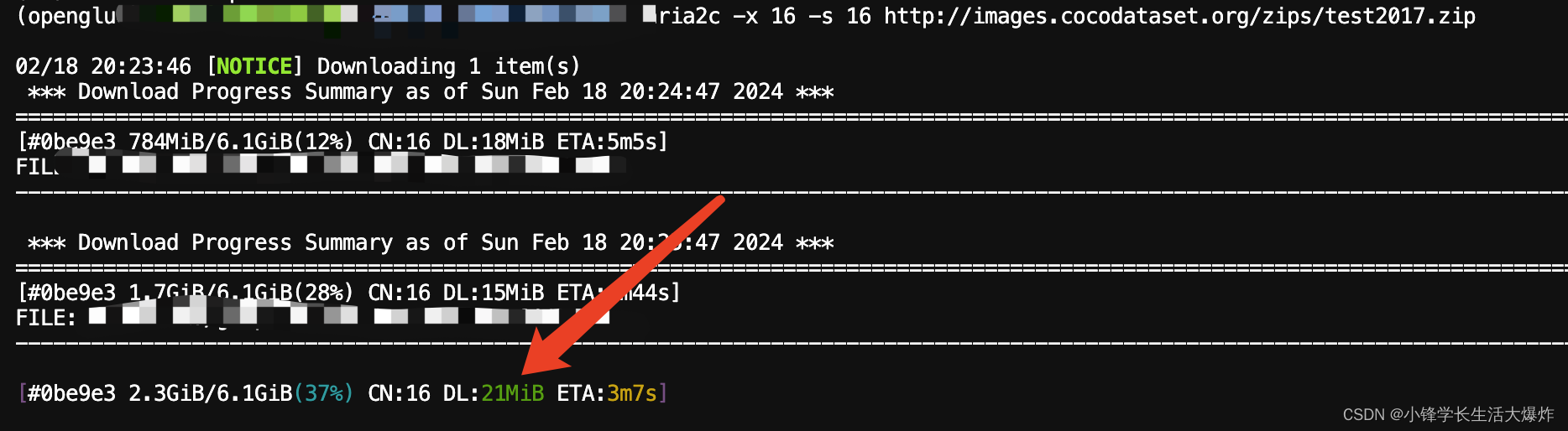
【教程】Linux使用aria2c多线程满速下载
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 安装aria2c: sudo apt-get install aria2多线程下载: aria2c -x 16 -s 16 <url> 比如: aria2c -x 16 -s 16 http://images.cocodataset.org/zips/test2017.zip...
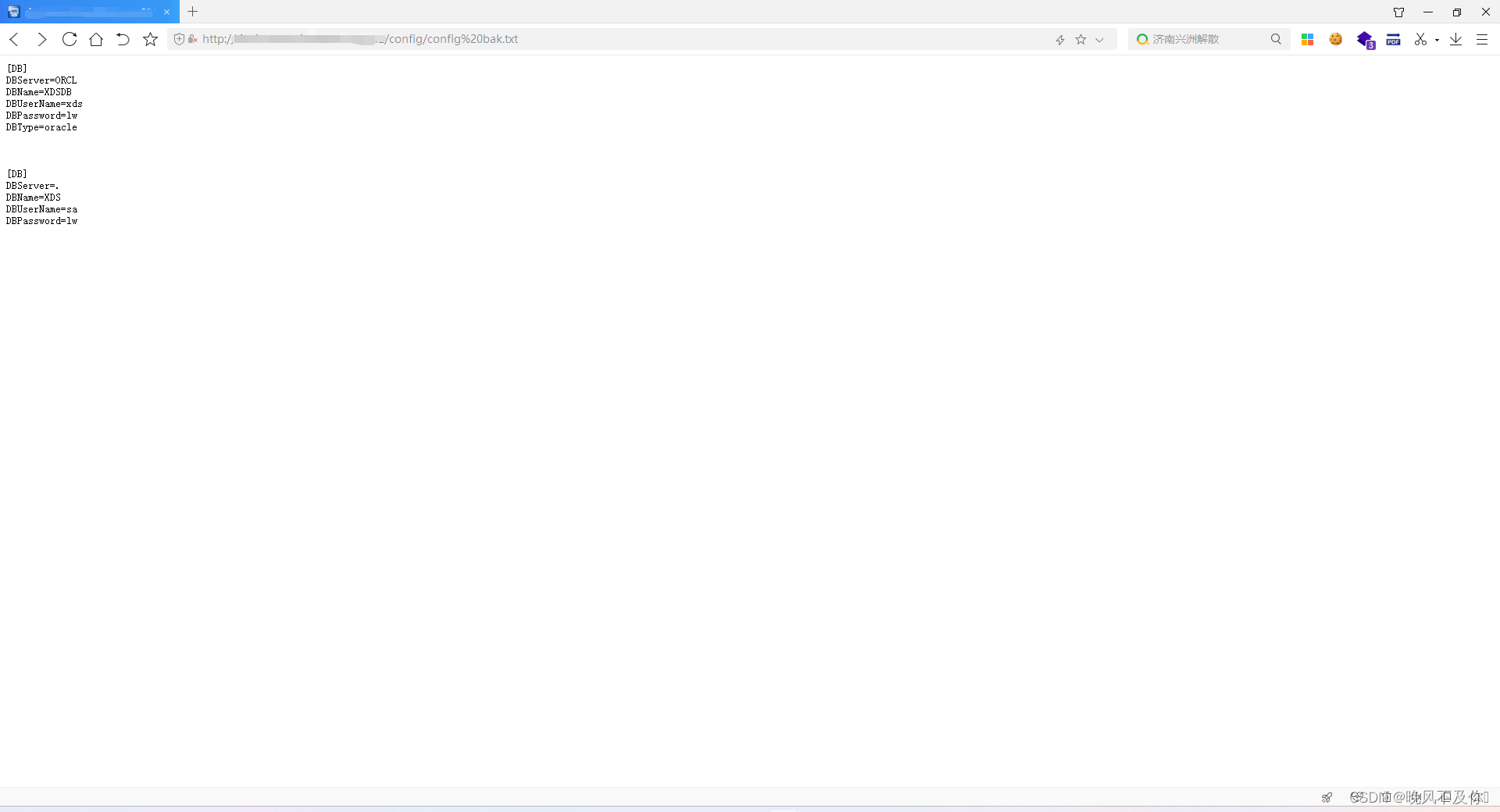
【漏洞复现】蓝网科技临床浏览系统信息泄露漏洞
Nx01 产品简介 蓝网科技临床浏览系统是一个专门用于医疗行业的软件系统,主要用于医生、护士和其他医疗专业人员在临床工作中进行信息浏览、查询和管理。 Nx02 漏洞描述 蓝网科技临床浏览系统存在信息泄露漏洞,攻击者可以利用该漏洞获取敏感信息。 Nx03…...

JSON转换List<Map<String, Object>>、Map<String, Object>
废话就不说了 早上10点研究到现在 获取redis的JSON字符串 String getPalletListNew redisService.getRedis(“getPalletListNew”, abroad “” goodsLevel “” startPort “” destinationPort “” maxTon “” minTon); 转换Map<String,Object> public …...

Linux驱动调试利器:debugfs接口设计与实现详解
1. 项目概述:为什么我们需要debugfs?在Linux内核驱动的开发与调试过程中,我们常常面临一个核心痛点:如何在不重启系统、不重新编译驱动、甚至不借助复杂外部工具的情况下,实时地窥探驱动内部的状态、修改关键参数&…...

构建一个基于YOLOv8的打架检测系统,包括环境设置、数据准备、模型训练、评估和推理部署。Yolov8训练打架斗殴数据集
构建一个基于YOLOv8的打架检测系统,包括环境设置、数据准备、模型训练、评估和推理部署。Yolov8训练打架斗殴数据集 文章目录1. 环境设置2. 数据准备2.1 数据集结构2.2 类别映射3. 文件内容3.1 Config.py3.2 train.py3.3 detect_tools.py3.4 UIProgram/MainProgram.…...

开发团队如何利用Taotoken实现API Key的统一管理与访问审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发团队如何利用Taotoken实现API Key的统一管理与访问审计 对于中大型开发团队而言,大模型API的引入在提升效率的同时…...

Draft-classic:云原生开发中Kubernetes部署的快速原型工具
1. 项目概述:从零到一的云原生应用部署加速器 如果你和我一样,长期在云原生和Kubernetes领域摸爬滚打,一定经历过这样的场景:一个应用的核心代码逻辑早已写完,但为了让它能在Kubernetes集群里跑起来,你不得…...
)
Shell 相关基础入门,在 Ubuntu 与 CentOS Shell 中的语法差异总结(bash、dash、sh)
新建的test.sh文件,vim进去,每行开头都默认有一个~符号,是什么意思,而且在里面鼠标也失效了? 你问的这两个问题,恰好是初学者刚接触 vim 编辑器时最常遇到的两个困惑。它们完全正常,不是系统出错…...

从零搭建自托管AI实验室:基于Docker Compose的完整实践指南
1. 项目概述:从零搭建一个属于自己的AI实验室最近在GitHub上看到一个挺有意思的项目,叫self-hosted-ai-lab。这个名字本身就很有吸引力,直译过来就是“自托管的AI实验室”。作为一个在AI和系统运维领域摸爬滚打多年的从业者,我第一…...

Loop窗口管理:5个高效工作流提升你的Mac生产力
Loop窗口管理:5个高效工作流提升你的Mac生产力 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop Loop是一款为macOS设计的优雅窗口管理工具,通过径向菜单、快捷键绑定和智能窗口操…...

通过curl命令调试与验证大模型API连接状态
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令调试与验证大模型API连接状态 基础教程类,针对需要在无SDK环境或快速排错的开发者,详细说明如…...
)
别再死磕公式了!用Python动手实现Turbo码的Max-Log-MAP译码(附完整代码)
用Python实战Turbo码:Max-Log-MAP译码的工程实现指南 在通信系统的纠错编码领域,Turbo码因其接近香农极限的性能而闻名。但对于大多数工程师和开发者而言,Turbo码译码算法中复杂的概率公式和递推关系往往成为理解障碍。本文将带你绕过数学推导…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...