【AGI视频】Sora的奇幻之旅:未来影视创作的无限可能
在五年后的未来,科技的发展为影视创作带来了翻天覆地的变化。其中,Sora视频生成软件成为了行业的翘楚,引领着全新的创作潮流。Sora基于先进的Transformer架构,将AI与人类的创造力完美结合,为观众带来了前所未有的视听盛宴。
Sora原理及代码
Sora的核心原理基于先进的扩散模型。它的工作方式就像一位画家从一张白纸开始,逐步添加细节,最终完成一幅精美的画作。这种转变在Sora中是通过深度学习架构和Transformer技术实现的。
以下是Sora扩散模型的核心代码简化版:
import torch
import torch.nn as nn
from diffusers import DiffusionModel class SoraModel(DiffusionModel): def __init__(self, config): super(SoraModel, self).__init__(config) # 定义模型的各个组件 self.u_net = nn.Sequential( # ... 后面实例补全:U-Net架构的具体细节 ) def forward(self, x_t, t, reverse=False): # x_t: 噪声视频,t: 时间步 # 在正向过程中,模型从噪声中学习;在反向过程中,模型生成视频 if reverse: # 反向过程:从噪声生成视频 x0_prediction = self.u_net(x_t, t) # ... 可能还有其他的后处理步骤 return x0_prediction else: # 正向过程:学习噪声的分布 # ... 此处省略了正向过程的代码 pass # 实例化模型
model = SoraModel(config) # 假设我们有一个噪声视频x_t和一个时间步t
x_t = torch.randn(1, 3, 64, 64) # 示例数据,真实情况下会有具体的噪声视频
t = torch.tensor([0.5]) # 示例时间步 # 使用模型生成视频
generated_video = model(x_t, t, reverse=True)
U-Net架构的具体细节
import torch
import torch.nn as nn
import torch.nn.functional as F# UNetBlock模块
class UNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super(UNetBlock, self).__init__()# 第一个卷积层,输入通道数为in_channels,输出通道数为out_channels,卷积核大小为3,填充为1self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)# 第二个卷积层,输入和输出通道数均为out_channels,卷积核大小为3,填充为1self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)# 上采样层,放大倍数为2,使用双线性插值进行上采样,对角线上的像素点进行对齐self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)# 前向传播方法def forward(self, x):# 第一个卷积层,使用ReLU激活函数x1 = F.relu(self.conv1(x))# 第二个卷积层,使用ReLU激活函数x2 = F.relu(self.conv2(x1))# 上采样层,将x2放大2倍并与x1相加x3 = self.up(x2)# 将x3和x1相加得到输出结果return x3 + x1# SoraModel模型
class SoraModel(nn.Module):def __init__(self, num_classes):super(SoraModel, self).__init__()# 编码器部分,包括一个卷积层、一个ReLU激活函数和一个最大池化层self.encoder = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1), # 输入通道数为3,输出通道数为64,卷积核大小为3,填充为1nn.ReLU(inplace=True), # 使用ReLU激活函数nn.Conv2d(64, 64, kernel_size=3, padding=1), # 输入和输出通道数均为64,卷积核大小为3,填充为1nn.ReLU(inplace=True), # 使用ReLU激活函数nn.MaxPool2d(kernel_size=2, stride=2) # 最大池化层,池化核大小为2,步长为2)# 中间部分,使用UNetBlock模块self.middle = UNetBlock(64, 128)# 解码器部分,包括两个卷积层和一个ReLU激活函数self.decoder = nn.Sequential(nn.Conv2d(128, 64, kernel_size=3, padding=1), # 输入通道数为128,输出通道数为64,卷积核大小为3,填充为1nn.ReLU(inplace=True), # 使用ReLU激活函数nn.Conv2d(64, num_classes, kernel_size=1) # 输入通道数为64,输出通道数为num_classes,卷积核大小为1)# 前向传播方法def forward(self, x):# 通过编码器部分得到x1x1 = self.encoder(x)# 通过中间部分得到x2x2 = self.middle(x1)# 通过解码器部分得到最终的输出结果x3并返回它x3 = self.decoder(x2)return x3
为了实现这一过程,Sora使用了一种称为时空patchs的数据结构。这些patchs在模型中充当了类似于Transformer Tokens的角色,使Sora能够模拟出三维空间的连贯性和长期物体持久性。通过训练,模型逐渐学会了如何从噪声中生成具有真实感和动态感的视频内容。

Sora使用时空patchs的数据结构
import torch
from torchvision import transforms# 假设我们有预定义的函数来读取视频帧
def load_video_frames(video_path):# 实际代码会读取视频并返回帧序列passclass SpaceTimePatchTransform:def __init__(self, spatial_patch_size, temporal_patch_size, num_frames):self.spatial_patch_size = spatial_patch_sizeself.temporal_patch_size = temporal_patch_sizeself.num_frames = num_framesself.to_tensor = transforms.ToTensor()def __call__(self, video_path):frames = load_video_frames(video_path)[:self.num_frames]patches = []for t in range(0, len(frames) - self.temporal_patch_size + 1, self.temporal_patch_size):temporal_patch = frames[t:t+self.temporal_patch_size]for frame in temporal_patch:# 对每一帧应用空间patch操作height, width = frame.shape[:2]h_patches = (height // self.spatial_patch_size) * self.spatial_patch_sizew_patches = (width // self.spatial_patch_size) * self.spatial_patch_sizeframe_patches = frame[:h_patches, :w_patches].reshape(-1, self.spatial_patch_size, self.spatial_patch_size)patches.extend(self.to_tensor(frame_patches))# 将所有patches堆叠成(batch_size, patch_num, spatial_patch_size, spatial_patch_size)patches = torch.stack(patches)return patches# 示例使用
transform = SpaceTimePatchTransform(spatial_patch_size=16, temporal_patch_size=4, num_frames=32)
video_patches = transform("path_to_your_video.mp4")# 进一步对patches进行嵌入操作(通常是一个线性层)
patch_embeddings = MyEmbeddingLayer(video_patches) # 这里需要自定义嵌入层MyEmbeddingLayer
在这个代码中,我们定义了一个名为SoraModel的类,它继承了DiffusionModel。SoraModel使用U-Net架构(在此处省略了具体细节)来逐步从噪声中预测和生成视频。通过调整reverse参数,我们可以控制模型是进行正向学习还是反向生成。
import torch.nn as nn# 假设已经有一个实现了扩散模型基本功能的基础类
class DiffusionModel(nn.Module):def __init__(self, *args, **kwargs):super(DiffusionModel, self).__init__()def forward(self, *args, reverse=False, **kwargs):# 在实际的DiffusionModel中,会包含正向传播(添加噪声)和反向传播(从噪声中恢复数据)的过程passclass SoraModel(DiffusionModel):def __init__(self, in_channels, num_frames, spatial_patch_size, temporal_patch_size, hidden_channels, num_blocks, out_channels):super(SoraModel, self).__init__()# 定义U-Net架构,这里仅作示意,具体实现取决于你的需求self.unet = UNet(in_channels=in_channels,spatial_patch_size=spatial_patch_size,temporal_patch_size=temporal_patch_size,hidden_channels=hidden_channels,num_blocks=num_blocks,out_channels=out_channels)def forward(self, video_patches, timesteps, reverse=False):if reverse:# 反向过程:逐步从噪声中预测并生成视频return self.unet(video_patches, timesteps, reverse=True)else:# 正向过程:模拟噪声扩散过程,通常在训练阶段使用raise NotImplementedError("正向过程需要在DiffusionModel的基础上实现")在这片充满无限可能的土地上,一个名叫李阳的年轻人怀揣着成为富一代的梦想,踏上了创业之路。李阳从小就痴迷于影视创作,他深知Sora的潜力,决定投身其中,开启自己的创业之旅。

李阳通过自学迅速掌握了Sora的使用技巧。他深入挖掘软件的功能,不断尝试与创新。在探索的过程中,李阳结识了一群志同道合的伙伴。他们共同分享创意、交流经验,携手前行。
李阳学习Sora的底层原理
import cv2
import numpy as npclass VideoExtender:def __init__(self, target_duration):self.target_duration = target_duration # 目标视频总秒数self.frame_rate = None # 视频帧率(初始化为空,在读取视频时获取)def extend_and_fill(self, input_video_path, output_video_path):# 打开视频文件并获取视频属性cap = cv2.VideoCapture(input_video_path)self.frame_rate = cap.get(cv2.CAP_PROP_FPS)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))original_duration = frame_count / self.frame_rate# 计算需要循环多少次以达到目标长度loop_count = int(np.ceil(self.target_duration / original_duration))# 初始化输出视频文件fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 或者使用其他编码器out = cv2.VideoWriter(output_video_path, fourcc, self.frame_rate, (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))# 遍历输入视频,并根据需要进行扩展和填充last_frame = Nonefor _ in range(frame_count * loop_count):ret, frame = cap.read()if not ret: # 如果已无更多帧可读if last_frame is None: # 如果第一遍循环就无法读取到帧,则跳过continueframe = last_frame # 使用上一帧进行填充else:last_frame = frame # 更新最后一帧out.write(frame)cap.release()out.release()# 使用示例
extender = VideoExtender(target_duration=60.0) # 希望扩展到1分钟
extender.extend_and_fill("input.mp4", "output.mp4")
李阳意识到Sora不仅仅是一个工具,更是一个能激发创意的平台。他开始尝试用Sora创作自己的短片,将脑海中天马行空的想象变为生动的画面。这些短片展现了他对未来的独特见解和对科幻、奇幻题材的热爱。李阳的作品很快在网络上走红,吸引了一大批粉丝。

一次偶然的机会,李阳的作品被一位知名导演发现。这位导演对他的创意和才华给予了高度评价,并决定与他合作。两人联手打造了一部科幻大片,凭借着Sora的强大功能,他们将天马行空的想象变为生动的画面,吸引了无数观众的目光。随着作品的热播,李阳的名声逐渐传开。他不仅获得了商业上的成功,还得到了业界的认可。他的故事激励着更多的人投身于影视创作,共同探寻未来的无限可能。
在这个充满奇幻色彩的世界里,Sora成为了梦想与现实之间的桥梁。它激发了人们的创造力,让每一个平凡的梦想都变得触手可及。而李阳则是这个时代的一名勇敢的探索者,他用自己的努力和才华证明了:只要有梦想、坚持不懈,每个人都有可能成为富一代。
Sora横空出世引发的思考
Sora的科学原理基于先进的神经网络架构和深度学习技术,通过时空patchs的数据结构模拟三维空间的连贯性和长期物体持久性,将无到有地创造出令人惊叹的视觉效果。这就像是一种魔法,将一张白纸逐渐渲染成一幅令人叹为观止的画卷。

在这个充满无限可能的领域里,Sora成为了梦想与现实之间的桥梁。它不仅为影视创作者提供了强大的工具,激发他们的创造力,还让那些曾经遥不可及的梦想变得触手可及。就像一位神奇的画师,用一支魔笔在画布上绘制出绚丽的未来世界。
OpenAI的Sora模型关键领域进行分析:
内容创作与娱乐产业:
Sora可能会在电影、电视和广告制作中扮演重要角色,通过生成高质量的视频内容,降低制作成本,提高创作效率。这可能会对编剧、导演、摄影师等传统影视行业从业者的工作方式产生重大影响。
社交媒体与个人创作:
Sora的易用性和创意能力可能会推动社交媒体内容的创新,使得普通用户能够制作出专业级别的视频内容,这可能会改变内容创作者和观众之间的互动方式。
教育与培训:
在教育领域,Sora可以用来创建教学视频,模拟复杂的场景和实验,为学生提供更直观的学习体验。同时,它也可以用于模拟紧急情况的应对训练,如医疗急救、灾难响应等。
新闻与报道:
Sora可以用于生成新闻报道的背景视频,尤其是在现场报道资源有限的情况下,通过文本描述生成相应的视频内容,提高新闻报道的丰富性和吸引力。
游戏开发:
在游戏行业,Sora可以用于快速生成游戏场景和角色动画,加速游戏开发流程,降低成本,同时为玩家提供更加丰富和逼真的游戏体验。
虚拟现实(VR)与增强现实(AR):
Sora的技术可以与VR和AR技术结合,创造出更加沉浸式和交互式的虚拟环境,为用户带来全新的体验。
法律与伦理挑战:
随着Sora等技术的发展,如何确保内容的真实性和防止滥用(如DeepFake)将成为一个重要的议题。这将推动相关法律法规的制定和更新,以及技术伦理的讨论。
就业市场变革:
Sora可能会改变视频制作行业的就业结构,一方面创造新的职业机会,如AI视频编辑和内容策划,另一方面也可能导致某些传统岗位的需求减少。
这些爆发点不仅展示了Sora技术的潜力,也提示了未来可能面临的挑战和机遇。随着技术的不断进步和应用场景的拓展,Sora可能会在多个领域产生深远的影响。
相关文章:
【AGI视频】Sora的奇幻之旅:未来影视创作的无限可能
在五年后的未来,科技的发展为影视创作带来了翻天覆地的变化。其中,Sora视频生成软件成为了行业的翘楚,引领着全新的创作潮流。Sora基于先进的Transformer架构,将AI与人类的创造力完美结合,为观众带来了前所未有的视听盛…...

Docker部署nginx
搜索镜像 docker search nginx 下载拉取nginx镜像 docker pull nginx 查看镜像 docker images 启动容器 docker run -d --name nginx01 -p 3344:80 nginx 外部端口需要在服务器安全组中设置,使用docker镜像nginx以后台模式启动一个容器,并将容器…...

C++Qt——自定义信号与槽
自定义信号与槽 自定义信号与槽是实现对象间通信的一种机制,比如按钮和窗口间的通信。 一、定义信号 Signal关键字声明的类成员函数。不需要实现,只需要声明。 signals:void mySignals();//定义信号,不用实现二、定义槽 可以使任何普通成员函数&…...

提高项目的性能和响应速度的方法
目录 引言 一、代码优化 二、数据库优化 三、缓存技术: 四、异步处理 1. 将耗时的操作改为异步处理 1.1 文件上传 1.2 邮件发送 2. 使用消息队列实现异步处理 2.1 配置消息队列 2.2 发送消息 2.3 接收消息并处理 五、负载均衡和集群 1. 负载均衡 1.1 …...

QT学习事件
一、事件处理过程 众所周知 Qt 是一个基于 C 的框架,主要用来开发带窗口的应用程序(不带窗口的也行,但不是主流)。 我们使用的基于窗口的应用程序都是基于事件,其目的主要是用来实现回调(因为只有这样程序…...
)
第13章 网络 Page818 UDP(和TCP的比较)
TCP核心类 asio::ip::tcp::socket;//网络套接字 asio::ip::tcp::endpoint;//边接端地址 asio::ip::tcp::resolver;//地址解析器 asio::ip::tcp::acceptor;//连接接受器 UPD核心类 asio::ip::udp::socket;//网络套接字 asio::ip::udp::endpoint;//边接端地址 asio::ip::udp::…...
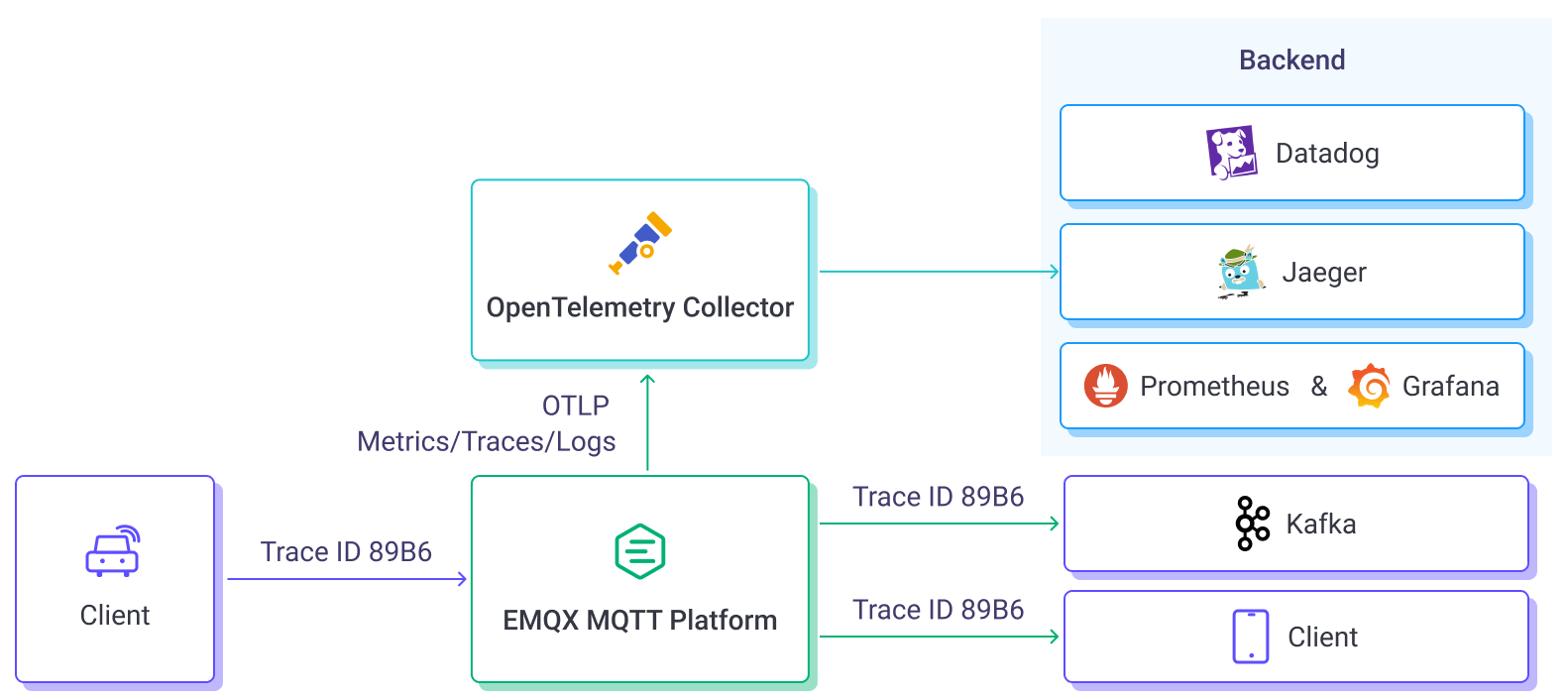
EMQX Enterprise 5.4 发布:OpenTelemetry 分布式追踪、OCPP 网关、Confluent 集成支持
EMQX Enterprise 5.4.0 版本已正式发布! 新版本提供 OpenTelemetry 分布式追踪与日志集成功能,新增了开放充电协议 OCPP 协议接入能力,并为数据集成添加了 Confluent 支持。此外,新版本还进行了多项改进以及 BUG 修复,…...
)
记录 | C++ cout.setf(ios::fixed)
cout.setf(ios::fixed); 是在 C 中使用的一个标准库函数,用于将流的输出格式设置为"fixed" "fixed"格式指定输出浮点数时,小数点后的位数是固定的。这意味着,无论输出的数字有多少位小数,小数点后都会保留相…...

Eclipse 创建 Hello World 工程
Eclipse 创建 Hello World 工程 1. Hello WorldReferences Download and install the Eclipse IDE. 1. Hello World Eclipse -> double click -> Launch 单击蓝色方框 (右上角) 最大化 IDE File -> New -> C Project -> Finish Project name:工程名…...

【前端工程化面试题】vite热更新原理
vite 在开发阶段,运行 vite 命令,会启动一个开发服务器,vite 在开发阶段是一个服务器 依赖 esm: vite 在开发阶段使用 esm 作为开发时的模块系统。esm 具有动态导入的能力,这使得在代码中引入模块时可以动态地加载新的…...

【leetcode】判断二叉树是否完全二叉树
递归方式判断二叉树是否完全二叉树 bool TreeComplete(TreeNode* root) {if (root ! NULL) {if (root->left NULL && root->right ! NULL) {return false; // 左子树空}else if (root->left NULL && root->right NULL) {return true; // 左右子…...

Java多线程系列——内存模型JMM
目录 核心思想 关键概念 1. 可见性 2. 原子性 3. 有序性 工作原理 并发工具类 对并发编程的影响 同步策略 JMM的实践意义 结语 Java内存模型(Java Memory Model, JMM)是Java并发编程中的核心概念,其定义了Java虚拟机(JV…...
深入理解 Vue3 中的 setup 函数
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...

【QT+QGIS跨平台编译】之三十六:【RasterLite2+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、RasterLite2介绍二、文件下载三、文件分析四、pro文件五、编译实践一、RasterLite2介绍 RasterLite2是一个开源的轻量级栅格数据库,可以用于存储和管理各种类型的栅格数据,包括卫星遥感图像、数字高程模型等。 与传统的GIS数据存储方式不同,RasterLite2采用基…...

java面试题:分布式和微服务的区别
1 分布式和微服务概念不同 微服务架构是架构设计方式,是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分。 分布式系统是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机…...

GO语言的变量与常量
1.变量 go是一个静态语言 变量必须先定义后使用变量必须要有类型 定义变量的方式: var 名称 类型 var 名称 值 名称 :值 例如: var num int 这样就存了一个num类型为int的变量 var num 1 上面使用简化的定义通过num自动判断后面的类型为int并…...

java面试多线程篇
文章说明 在文章中对所有的面试题都进行了难易程度和出现频率的等级说明 星数越多代表权重越大,最多五颗星(☆☆☆☆☆) 最少一颗星(☆) 1.线程的基础知识 1.1 线程和进程的区别? 难易程度:☆☆…...

Anaconda + VS Code 的安装与使用
目录 一. Anaconda 是什么二. Anaconda 的安装1. 下载安装包2. 安装3. 检查 三. Anaconda 的使用1. 创建虚拟环境2. 激活虚拟环境3. 包管理4. 列举虚拟环境5. 退出虚拟环境6. 删除虚拟环境 四. VS Code 开发1. 安装插件2. 打开工作区3. 选择解释器 五. VS Code 个性化设置1. 切…...

Python爬虫html网址实战笔记
仅供学习参考 一、获取文本和链接 import requests from lxml import htmlbase_url "https://abcdef自己的网址要改" response requests.get(base_url) response.encoding utf-8 # 指定正确的编码方式tree html.fromstring(response.content, parserhtml.HTML…...
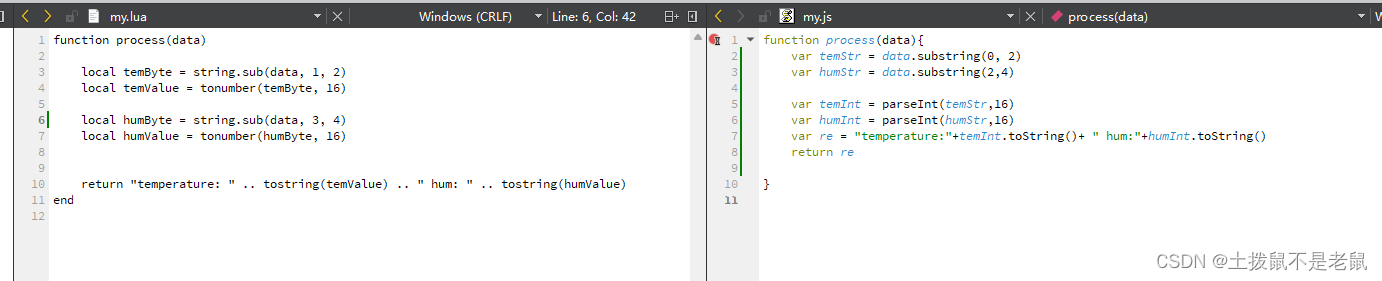
C++ 调用js 脚本
需求: 使用Qt/C 调用js 脚本。Qt 调用lua 脚本性能应该是最快的,但是需要引入第三方库,虽然也不是特别麻烦,但是调用js脚本,确实内置的功能(C 调用lua 脚本-CSDN博客) 步骤: 1&…...

题解:AcWing 1054 股票买卖
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲
QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支…...

子黎曼几何与庞特里亚金原理:约束系统时间最优控制
1. 从黎曼到子黎曼:当几何遇见约束 在物理和工程的世界里,我们常常需要为系统寻找一条“最优”的路径。无论是让量子比特以最快的速度演化到目标态,还是规划机器人在复杂地形中的最短时间轨迹,其背后都隐藏着一个深刻的几何问题&a…...

基于CNN的口腔鳞状细胞癌智能检测系统开发
1. 口腔鳞状细胞癌检测的技术挑战与解决方案口腔鳞状细胞癌(OCSCC)作为头颈部最常见的恶性肿瘤,其早期诊断面临三大技术瓶颈:首先是病灶的隐蔽性,早期病变常表现为微小白色斑块或溃疡,与普通口腔炎症难以区…...

计算材料学驱动新型硅光伏材料发现:进化算法与机器学习融合设计
1. 项目概述:当计算材料学遇上光伏革命在光伏领域,硅材料长期占据着主导地位,这得益于其储量丰富、工艺成熟和稳定性好。然而,传统晶体硅(金刚石结构)一个众所周知的“阿喀琉斯之踵”是其间接带隙特性。这意…...

机器学习与模拟退火算法优化TPMS结构材料力学性能
1. 项目概述与核心价值在材料科学与先进制造领域,三周期极小曲面(Triply Periodic Minimal Surfaces, TPMS)结构正掀起一场设计革命。这类结构以其在三维空间内周期性重复、且具有极小表面积的特点,展现出传统实体材料难以企及的优…...

机器学习地球系统模型评估:从物理一致性到标准化框架
1. 项目概述:为什么我们需要重新审视机器学习地球系统模型的评估? 作为一名长期从事气候模式开发与评估的研究者,我亲眼见证了机器学习(ML)技术如何以惊人的速度渗透到地球系统科学领域。从几年前Pangu-Weather、Graph…...
)
WSL2 2023史诗级更新实测:你的.wslconfig文件真的配对了吗?(从版本检查到稀疏VHD全流程)
WSL2 2023史诗级更新实战:从版本适配到性能调优全解析如果你最近尝试在WSL2中配置网络功能时遇到各种"玄学问题",比如代理失效、端口转发异常或是磁盘空间莫名被占满,很可能是因为忽略了版本兼容性这个关键前提。2023年9月后&#…...

Herqles架构:量子比特读取的硬件高效判别器设计与FPGA实现
1. 项目概述:量子比特读取的精度与速度困局在量子计算的世界里,有一个操作看似基础,却直接决定了整个系统的上限:量子比特的读取。你可以把它想象成计算机的“内存读取”指令,但这里读取的不是0或1的确定性电压&#x…...

LLM可观测性实战:生产环境AI应用的监控体系建设
为什么LLM应用的监控与传统软件完全不同 传统软件监控关注的核心指标很清晰:响应时间、错误率、吞吐量、CPU/内存使用率。这些指标背后的系统行为是确定性的——同样的输入,永远产生同样的输出。LLM应用打破了这个假设。面对同样的用户输入:-…...