『论文阅读|研究用于视障人士户外障碍物检测的 YOLO 模型』

研究用于视障人士户外障碍物检测的 YOLO 模型
- 摘要
- 1 引言
- 2 相关工作
- 2.1 障碍物检测的相关工作
- 2.2 物体检测和其他基于CNN的模型
- 3 问题的提出
- 4 方法
- 4.1 YOLO
- 4.2 YOLOv5
- 4.3 YOLOv6
- 4.4 YOLOv7
- 4.5 YOLOv8
- 4.6 YOLO-NAS
- 5 实验和结果
- 5.1 数据集和预处理
- 5.2 训练和实现细节
- 5.3 性能指标
- 5.4 性能分析
- 5.4.1 YOLOv5的结果
- 5.4.2 YOLOv6的结果
- 5.4.3 YOLOv7的结果
- 5.4.4 YOLOv8的结果
- 5.4.5 YOLO-NAS的结果
- 5.4.6 总体结果
- 5.5 消融实验
- 6 讨论和总结
论文题目: Investigating YOLO Models Towards Outdoor Obstacle Detection For Visually Impaired People
研究用于视障人士户外障碍物检测的 YOLO 模型
摘要
利用基于深度学习的物体检测是帮助视障人士避开障碍物的有效方法。在本文中,实现了七种不同的 YOLO 物体检测模型,即 YOLO-NAS(小、中、大)、YOLOv8、YOLOv7、YOLOv6 和 YOLOv5,并通过精心调整的超参数进行了综合评估,以分析这些模型在包含道路和人行道上常见日常物体的图像上的表现。经过系统的调查,YOLOv8 被认为是最好的模型,它在著名的障碍物数据集(包括 VOC 数据集、COCO 数据集和 TT100K 数据集的图像以及研究人员在现场收集的图像)上的精确度达到了 80%,召回率为 68.2%。尽管 YOLO-NAS 是最新的模型,并在许多其他应用中表现出更好的性能,但在障碍物检测任务中,YOLO-NAS 仍未达到最佳状态。
关键词: 障碍物检测、YOLO、物体检测、边界框、视障人士
1 引言
视觉是人体最重要的感官之一。它帮助我们识别周围的环境,使我们能够进行日常工作。然而,随着视力的丧失,人们在生活中的基本技能,如识别障碍物、学习、阅读、上学和工作等方面的能力都会受到影响。据世界卫生组织(WHO)统计,全球至少有 22 亿人存在近视或远视障碍[1]。白内障、青光眼、屈光不正、老年性黄斑变性和糖尿病视网膜病变是导致失明和视力受损的主要原因[2]。视力损伤会给个人带来严重后果,包括劳动力参与率和生产率降低[3]、抑郁和焦虑率升高[4]以及遭受暴力和虐待(包括欺凌和性暴力)的比率升高[5]。经济也受到巨大影响,研究表明,中度至重度视力损伤每年造成的损失从洪都拉斯的 1 亿美元到美国的 165 亿美元不等[6]。
有效缓解和解决这一世界性问题的方法之一是利用深度学习方法,特别是通过使用卷积神经网络(CNN)来指导视障人士执行各种日常物体检测任务。由于卷积神经网络具有识别前方障碍物的算法能力,因此视障人士和盲人可以通过卷积神经网络获得帮助。物体检测算法能够告诉人们前方有哪些物体,从而避开它们[7]。有鉴于此,这项工作在一个流行的障碍物数据集上评估和分析了 YOLO 模型的性能,该数据集包含日常街道和人行道上的障碍物和物体。
使用的不同 YOLO 模型包括 YOLO v5、v6、v7、v8 和 NAS。NAS 指的是 “神经架构搜索”(Neural Architecture Search),即由神经网络自动寻找完成任务的最佳架构,而不是由人为来完成[8, 9]。作者对模型进行了全面的测试和调整。
作者的工作旨在具体研究这些不同版本的 YOLO 模型在障碍物检测任务中的性能差异,以及最新架构搜索算法(YOLO-NAS)与早期版本的比较。由于 YOLO 众所周知的快速计算特性,特别选择 YOLO 进行系统的实证研究。
本文接下来的内容安排如下:第 2 节讨论该领域的相关工作;第 3 节讨论问题的提出过程;第 4 节介绍进行分析所使用的方法;第 5 节和第 6 节介绍结果和讨论总结得出的结论。
2 相关工作
2.1 障碍物检测的相关工作
在建立模型以帮助盲人或视障人士方面,已经进行了大量的研究;然而,在系统分析不同物体检测模型的性能方面,却没有做很多工作。这些性能分析非常重要,因为它们提出了有效建立真实世界模型以帮助盲人和视障人士的最佳模式。在[10]中,作者提出了一种基于深度学习的视障人士辅助应用模型,特别是安装在智能手机上的带有 Darknet-53 基础网络的 YOLOv3。该模型使用 Pascal VOC2007 和 Pascal VOC2012 数据集进行训练,在障碍物检测方面实现了高速度和高精度。该应用利用 eSpeak 合成器生成音频输出,使视障人士能够与周围环境进行有效互动。实验结果证明了所提模型在实时障碍物检测和分类方面的有效性,为视障者的日常生活提供了安全性和舒适性。未来的工作包括研究视障人士与障碍物之间的距离,并整合其他理论来改进整体应用。
文献[9]的作者主要关注神经架构搜索(NAS)技术的使用。他们提出了一种利用深度学习和 NAS 技术的视障人士智能导航辅助系统。该系统中使用的深度学习模型通过精心设计的架构取得了巨大成功。该论文还提出了一种快速 NAS 方法,以寻找一种高效的物体检测框架。NAS 基于量身定制的强化学习技术。提出的 NAS 用于探索无锚物体检测模型的特征金字塔网络和预测阶段。搜索到的模型在 Coco 数据集和室内物体检测与识别(IODR)数据集的组合上进行了评估。结果模型的平均精度(AP)比原始模型高出 2.6%,计算复杂度在可接受范围内。所取得的结果证明了所提出的 NAS 在自定义对象检测方面的效率。这促使作者将 YOLO-NAS 模型用于物体检测任务。
在文献[7]中,研究人员介绍了一种新颖的静态/移动障碍物检测框架,以帮助视障/盲人安全导航,该算法可在智能手机上实时运行,独立提供障碍物检测和分类。该算法可在智能手机上实时运行,独立进行障碍物检测和分类。根据障碍物与目标物的距离和运动矢量方向,将障碍物分为紧急/正常障碍物。在英特尔至强计算机上,障碍物检测的平均处理时间为 18 毫秒/帧,而在三星 Galaxy S4 智能手机上则为 130 毫秒/帧。论文还建议使用物体分类算法扩展该方法,并将突出显示的障碍物转换为语音信息。
文献[11]的作者提出了一种针对视障人士的辅助设备,该设备可提供自动导航和引导、检测障碍物并进行实时图像处理。该设备由一组异构的传感器和计算组件组成,包括超声波传感器、摄像头、单板 DSP 处理器、湿地板传感器和电池,并使用机器学习模型进行物体识别,使用户熟悉周围环境。该设备可以检测各种障碍物,如上楼、下楼、边缘、坑洼、减速带、狭窄通道和潮湿地板。输出以音频提示的形式提供,以确保用户的舒适性和友好性,训练对象的平均精确度(mAP)为 81.11。
2.2 物体检测和其他基于CNN的模型
卷积神经网络(又称 CNN)是一种机器学习算法,广泛应用于处理图像的不同机器学习任务中。其中一项任务是使用边界框检测图像中的物体。通过学习图像数据,计算机能够分析图像,识别图像中的物体并将其分为不同的组。这就是所谓的物体检测。物体检测算法也有多种,例如 R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN、SSD、YOLO 等。
R-CNN,即基于区域的卷积神经网络(Region-based Convolutional Neural Network),是一种计算机视觉算法,通过结合深度学习和区域建议的力量,彻底改变了物体检测。它包括从图像中提取潜在的感兴趣区域,然后使用卷积神经网络对这些区域内的物体进行分类和定位。[15] Fast R-CNN 建立在原始 R-CNN 方法的基础上。它通过在所有提出的区域共享卷积特征,引入了一种更高效的架构,从而消除了冗余计算的需要。[16]Faster R-CNN 通过将区域建议网络(RPN)与Fast R-CNN 相结合来实现高精度的实时物体检测。[17] 另一种模型是Mask R-CNN。Mask R-CNN 的主要思想是利用区域建议网络(RPN)生成高质量的物体建议,然后通过预测物体类别、边界框坐标和像素级掩码来完善这些建议。
[18] 另一种主要算法是 SSD。SSD 背后的主要理念是在神经网络的单次传递中执行物体检测,省去了多个阶段。它通过在不同尺度的多个特征图上利用一组预定义的不同大小和长宽比的锚框来实现这一目标。
[14] CNN 通常由卷积层、池化层和全连接层组成。前两层(卷积层和池化层)执行图像特征提取,第三层(全连接层)将提取的特征映射到最终输出,即不同的类别[19, 20]。CNN 架构有多种类型,包括 AlexNet、VGGNet、GoogLeNet、ResNet 等[20, 21]。它在物体检测方面有多种重要应用,如自动驾驶汽车、人脸识别和医疗保健中的医疗检测等[22-24]。
3 问题的提出
在本节中,作者将从数学角度提出障碍物检测问题。假设:
X X X : 输入的室外障碍物图像, Y Y Y : 物体的真实值的标注集合, y i c l a s s y_i^{class} yiclass :物体 i 的类别标签, y i b o x y_i^{box} yibox:物体 i 的边框坐标, f f f:障碍物检测模型,即 YOLO。
目标是通过最小化损失函数来优化模型 f f f:
L ( f ( X ) , Y ) = λ c l a s s ⋅ L c l a s s ( f c l a s s ( X ) , Y ) + λ b o x ⋅ L b o x ( f b o x ( X ) , Y ) \mathcal{L}(f(X),Y)=\lambda_{\mathrm{class}}\cdot\mathcal{L}_{\mathrm{class}}(f_{\mathrm{class}}(X),Y)+\lambda_{\mathrm{box}}\cdot\mathcal{L}_{\mathrm{box}}(f_{\mathrm{box}}(X),Y) L(f(X),Y)=λclass⋅Lclass(fclass(X),Y)+λbox⋅Lbox(fbox(X),Y)
其中, L c l a s s \mathcal{L}_{class} Lclass:分类损失, L b o x \mathcal{L}_{box} Lbox:边框回归损失, λ c l a s s \lambda_{class} λclass:分类损失权重, λ b o x \lambda_{box} λbox:边框回归损失权重。
优化问题是通过最小化损失函数,找到模型 f f f 的最佳参数:
θ ^ = arg min θ ∑ i L ( f ( X i ; θ ) , Y i ) \hat{\theta}=\arg\min_\theta\sum_i\mathcal{L}(f(X_i;\theta),Y_i) θ^=argθmini∑L(f(Xi;θ),Yi)
其中, θ θ θ 表示模型参数, X i X_i Xi 和 Y i Y_i Yi 分别是输入的室外图像实例和第 i 个实例的真实值。优化后的模型 f ^ \hat{f} f^用于检测测试数据集中的障碍物。
4 方法
4.1 YOLO
YOLO 的全称是 “You Only Look Once”,是一种最先进的物体检测算法,早在 2016 年就已问世,它能在一次评估中直接从完整图像中预测边界框和类概率,并能同时预测一张图像中所有类的边界框,速度极快[25]。
该模型将图像划分为不同的网格单元,并检测其中心的物体。如果中心点位于一个网格中,那么该网格就被定义为包含该物体。基本 YOLO 模型以每秒 45 帧的速度实时处理图像,而较小的版本 Fast YOLO 可以达到每秒 155 帧的速度,其 mAP 是其他实时检测器的两倍。当从自然图像扩展到艺术品等其他领域时,它的性能也优于其他检测方法,包括 DPM 和 R-CNN[12]。
本文实施的 YOLO 模型包括 v5、v6、v7、v8 和 NAS。对于 v5 至 v8,作者只实现了每个版本中的一个模型,而对于 YOLO NAS,实现了所有三种尺寸的模型:小型(s)、中型(m)和大型(l)。以下是每种型号的说明。
4.2 YOLOv5
YOLOv5 [26, 27] 是 Ultralytics 于 2020 年推出的 YOLO(只看一次)物体检测模型的一个版本。与之前的模型相比,该模型引入了几个独特的功能。
首先,TensorRT、Edge TPU 和 OpenVINO 的加入使模型推理能够在各种硬件平台上高效进行。通过使用包含新的默认单周期线性 LR 调度器的重新训练模型,训练过程也得到了增强。
对 11 种不同格式的支持不仅限于导出,还有助于推理和验证,以便在导出过程后定性分析平均精度(mAP)和速度结果。在数据输入阶段会应用马赛克数据增强功能。
边界框损失函数已得到增强,从 CIOU 损失过渡到 GIOU 损失,并在预测组件中使用。此外,YOLOv5 还采用了一种名为 “CSPNet”(CrossStage Partial Network,跨阶段部分网络)的新骨干架构,该架构改进了特征提取程序,提高了模型的准确性。此外,YOLOv5 还采用了 PANet 来生成特征金字塔,这有助于模型有效地管理物体尺寸的变化。YOLOv5 中的模型头仍与 YOLOv3 和 v4 版本相似。
4.3 YOLOv6
YOLOv6 [28, 29],又称 MT-YOLOv6,是基于 YOLO 架构的单阶段物体检测模型。该模型由美团公司的研究人员开发,在以 MS COCO 数据集为基准测试时,其性能比 YOLOv5 更强。该模型有几个新功能。
首先,它在检测器的颈部引入了 BiC(Bidirectional Concatenation 双向并列)模块,该模块可改善定位信号,在保持对速度影响最小的情况下提高性能。它还引入了锚点辅助训练(Anchor-Aided Training , AAT)策略,该策略结合了基于锚点和无锚点范例的优点,同时保持了高效推理。为了提高 YOLOv6 中较小模型的性能,采用了一种新的自蒸馏策略。该策略在训练过程中增强了辅助回归分支,但在推理过程中删除了它,以避免速度大幅下降。YOLOv6 还提供了各种不同规模的预训练模型,包括不同精度的量化模型和针对移动平台优化的模型。
4.4 YOLOv7
YOLOv7 [30] 是 2022 年 7 月推出的单阶段实时物体检测模型。与之前的版本相比,它还具有一些新功能和改进。首先,它包含了一个计划中的重参数化模型,这是一种可应用于各种网络层的策略,侧重于梯度传播路径的概念。
同时,该模型还引入了新技术来增强训练过程;一种名为粗到细引导标签分配的新标签分配方法;以及扩展和复合缩放。
此外,YOLOv7 还在姿势估计方面进行了探索。在性能方面,与之前的版本相比,YOLOv7 实现了更快的推理速度和更高的精度。
4.5 YOLOv8
YOLOv8 [31, 32]于 2023 年 1 月 10 日发布,与之前的迭代版本相比,它带来了一系列新功能。
首先,YOLOv8 引入了全新的骨干网络,作为模型的基本架构。这种设计便于将模型性能与 YOLO 系列中的前几个模型进行简单比较。
然后,它采用了一种新的损失函数来计算预测值和真实值之间的差异。此外,它还采用了新颖的无锚点检测头,无需依赖预定义的锚点即可预测边界框。
从性能上看,YOLOv8 与其他物体检测模型相比,推理速度更快,同时还保持了较高的准确性。它已被用于不同的领域,如野生动物检测和小物体检测挑战。
4.6 YOLO-NAS
YOLO-NAS [33, 34]代表了物体检测领域的前沿进展,包含了早期版本所没有的各种新元素。
首先,它引入了一个专门针对量化进行优化的新型基本模块。与之前的版本相比,这一新模块旨在提高量化性能。因此,YOLO-NAS 能够在不牺牲效率的情况下实现更高的精度。
它采用了复杂的训练策略,如训练后量化、AutoNac 优化和在重要数据集上进行预训练。它还利用了伪标签数据,并通过使用预先训练的教师模型从知识提炼中获得洞察力。
YOLO-NAS 在精确检测和定位小型物体方面也有显著提高。凭借出色的性能/计算比,YOLO-NAS非常适合实时边缘设备应用,并在各种数据集上超越了现有的YOLO模型。
YOLO-NAS 支持训练后量化,可在训练过程后简化模型,从而提高效率。
它旨在与高性能推理引擎(如英伟达™ TensorRT™)无缝集成。它还支持 INT8 量化,将运行时性能提升到前所未有的水平。
5 实验和结果
5.1 数据集和预处理
在这次系统性实证评估中,使用了 Wu 等人[35] 1 的障碍数据集,其中包括 5066 张训练图像、1583 张测试图像和 1266 张验证图像。所有图像均为日常人行道、街道和道路上拍摄的照片。大部分图片的大小分布在 1500 × 1500 之间,少数图片超过 3000 × 3000。之所以特别选择这个数据集,是因为它是一个综合性数据集,其中还包含来自 VOC 数据集、COCO 数据集和 TT100K 数据集的图片。它还包含作者团队在实地收集的一些图片。因此,该数据集可用于验证模型在多个领域的适用性和可靠性。
该数据集中有 15 种障碍物,分为 15 个类别:停车标志、人、自行车、公共汽车、卡车、汽车、摩托车、反光锥、灰罐、警示柱、球形路障、电线杆、狗、三轮车和消防栓。数据集中的一些样本图像如图 2 所示。
5.2 训练和实现细节
使用英伟达 Tesla T4 GPU 对所有模型进行了 25 个epoches的训练,批量大小为 8。使用 专门开展机器学习项目的热门平台 Google Colaboratory 和 Kaggle进行实现和模型训练。[36, 37]
在这项工作中,对各种超参数进行了调整。将 "平均最佳模型 "设置为 True,热身模式为线性 epoch 步长,热身初始学习率为 1e-6,热身 epoch 期间学习率衰减因子为 3,初始学习率为 5e-4,学习率衰减模式为余弦,余弦最终学习率比率为 0.1,优化器为 Adam,优化器参数中的权重衰减为 0.0001。对偏差和批量归一化使用了零权重衰减,并利用指数移动平均法,衰减系数为 0.9,衰减类型为阈值,"混合精度 "设置为 True。
5.3 性能指标
在研究中使用的指标包括混淆矩阵、精确度、召回率和平均精确度 (mAP)。此外,还使用 F1 分数来进一步评估 YOLO-NAS 模型,并分析其性能不佳的原因。
精确度衡量的是在预测的正面类中正确预测的百分比,精确度的计算公式如公式 3所示。
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
其中 TP 和 FP 分别表示真阳性和假阳性。
召回率衡量的是在所有这些真实实例中预测的正确率。计算公式如公式 4所示:
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
其中 FN 表示假阴性。
不过,它们并不局限于二元分类,也可用于多类分类,如公式 5和 6所示。
P r e c i s i o n i n M u l t i − c l a s s = T P i n a l l c l a s s T P + F P i n a l l c l a s s e s Precision~in~Multi-class=\frac{TP~in~all~class}{TP+FP~in~all~classes} Precision in Multi−class=TP+FP in all classesTP in all class
R e c a l l i n M u l t i − c l a s s = T P i n a l l c l a s s e s T P + F N i n a l l c l a s s e s RecallinMulti-class=\frac{TP~in~all~classes}{TP+FN~in~all ~classes} RecallinMulti−class=TP+FN in all classesTP in all classes
平均精确度 (mAP) 也是分析模型性能的一个指标,要计算这个指标,首先需要绘制精确度与召回率的曲线图,然后求出曲线下的面积。这将是一个类别的平均精确度。因此,求出所有类别的曲线下面积的平均值就可以得到 mAP。
对于 YOLO-NAS,还使用 F1 分数。通常情况下,精确度和召回率需要权衡取舍,即一方要以另一方为代价。因此,F1 分数结合了这两个值的调和平均值,以获得更准确的性能评估,同时最大限度地提高精确度和召回率。F1 分数的计算公式如公式7 所示。
F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F1=2*\frac{Precision*Recall}{Precision+Recall} F1=2∗Precision+RecallPrecision∗Recall
所有这些关系都可以通过混淆矩阵直观地显示出来。
5.4 性能分析
在本节中,将描述所有 YOLO 模型所取得的性能。
5.4.1 YOLOv5的结果
YOLOv5 的总体精确度为 78.1%,召回率为 68.2%,mAP@0.5 为 74.2%。表 1 显示了 YOLOv5 的分类性能。精确度最高的类别是反光锥Reflective Cone,精确度达到 90.4%,而球形路障Spherical Roadblock是召回率和 mAP@0.5 最高的类别,分别达到 91.8% 和 93%。精确度和 mAP 最低的类别是 “卡车Truck”,分别为 58.5% 和 51.1%;召回率最低的类别是 “电线杆Pole”,仅为 41.1%。

5.4.2 YOLOv6的结果
IoU@0.5:0.95 和 Area of “All” 的 YOLOv6 平均精确度为 59%。IoU@0.5-0.95 和 Area of “All” 的平均召回率为 71.7%。更多详情见表 2。

5.4.3 YOLOv7的结果
总体而言,在所有类别中,YOLOv7 的精确度为 78.6%,召回率为 77.8%,mAP@0.5 为 81.7%。表 3 显示了 YOLOv7 的分类性能。精确度最高的类别是 "Ashcan "类别,达到 91.5%。召回率和 mAP@0.5 最高的类别也是球形路障,召回率达到 95.2%,mAP@0.5 达到 95.8%。表现最差的类别是 “Truck”,其精确度仅为 54.9%,召回率为 62.9%,mAP@0.5 为 62.6%。

5.4.4 YOLOv8的结果
图 3、图 4、图 5 和表 4 展示了 YOLOv8 模型的实验结果。图 4显示了 YOLOv8 的混淆矩阵。在这个混淆矩阵中,从左上角到右下角对角线上的数字是预测正确的数字。行代表机器预测的类别,列代表基本真实类别。YOLOv8 所有类别的总体结果是:精确度为 80%,召回率为 68.3%,mAP@0.5 为 75.8%,mAP@0.5-0.95 为 56.1%。表现最好的类别是 “Speherical Roadblock”,精确度达到 91.3%,召回率为 92.9%,mAP@0.5 为 95.3%,mAP@0.5-0.95 的 78.9%。精确度最低的类别是 Pole,仅达到 63.6%;召回率和 mAP@0.5 最低的类别是 Truck,召回率为 47.3%,mAP@0.5 为 54.2%。mAP@0.5-0.95 最低的类别是 Pole 类别,仅达到 33.9%。




5.4.5 YOLO-NAS的结果
YOLO-NAS 有三种型号:大型、中型和小型。精度最高的模型是 NAS-S,精度达到 78.8%。召回率、mAP 和 F1 最高的模型是 NAS-M,召回率为 62.7%,mAP@0.5 为 69.8%,F1@0.5 为 67.85%。表 5 列出了全部结果,包括不同损失函数计算出的损失。

5.4.6 总体结果
表 6 显示了每个模型的性能。精确度最高的模型是 YOLOv8,精确度达到 80%;召回率和 mAP 最高的模型是 YOLOv7,召回率和 mAP 分别达到 77.8%和 81.7%。F1 分数只有 YOLO-NAS 可用,最高的是 NAS-L,为 67.85%。精确度最低的模型是 YOLOv5,为 78.1%;召回率、mAP 和 F1 最低的是 YOLO-NAS-S,召回率为 59.41%,mAP 为 66.73%,F1 为 65.23%。

5.5 消融实验
通过对不同超参数进行网格搜索的综合实验,发现 YOLO-NAS 模型对阈值得分非常敏感。因此,通过改变阈值得分来调整模型,分析其性能。通过测试发现,该参数与精确度呈正相关,而与召回率呈负相关。阈值越高,精确度越高,而召回率则越低,反之亦然。表 7 显示了使用三个阈值进行消融分析的结果:0.3、0.5 和 0.7。当阈值为 0.7 时,YOLO-NAS 中型模型的精确度最高,为 93.16%,而小型模型的召回率最低,为 42.46%。阈值为 0.3 时,大型模型的召回率最高,为 78.48%,而中型模型的精确率为 44.87%。这表明精确度和召回率之间存在权衡,因此需要根据给定的数据集和任务仔细设计阈值。

6 讨论和总结
在本文中,研究了用;检测人行道上室外障碍物的七个 YOLO 模型。发现精度最高的模型是 YOLOv8,精度高达 80% 左右。召回率和 mAP 最高的模型是 YOLOv7,分别达到 77.8% 和 81.7%。精确度最低的 YOLO 模型是 YOLOv5,但其精确度仍达到了 78.1%。召回率和 mAP 最低的是 YOLO-NAS-S,召回率为 59.41%,mAP 为 66.73%。还对 YOLO-NAS 模型进行了一些消融研究,揭示了基于阈值分数的精确度和召回率之间的权衡。当阈值分数增加时(从 0.5 到 0.7),精确度增加,而召回率降低,反之亦然。因此,阈值得分与精确度呈正相关,而与召回率呈负相关,需要仔细调整。
作为本研究的扩展,有几个方面可以进一步修改和研究。首先,即使经过微调、调整和消融分析,YOLO-NAS 的性能也不是最佳的。未来的研究可以对其进行更深入的研究,并使其适用于障碍物检测应用。
其次,既然已经知道了性能最好的 YOLO 模型,那么就可以将这项工作扩展到其他物体检测模型,并与最好的 YOLO 模型进行比较,以研究不同物体检测算法系列在人行道室外障碍物检测方面的性能比较。最后,可以使用 YOLOv8 建立实时物体检测设备,帮助视障人士在现实世界中导航。
相关文章:
『论文阅读|研究用于视障人士户外障碍物检测的 YOLO 模型』
研究用于视障人士户外障碍物检测的 YOLO 模型 摘要1 引言2 相关工作2.1 障碍物检测的相关工作2.2 物体检测和其他基于CNN的模型 3 问题的提出4 方法4.1 YOLO4.2 YOLOv54.3 YOLOv64.4 YOLOv74.5 YOLOv84.6 YOLO-NAS 5 实验和结果5.1 数据集和预处理5.2 训练和实现细节5.3 性能指…...

LeetCode--1445. 苹果和桔子
文章目录 1 题目描述2 测试用例3 解题思路 1 题目描述 表: Sales ------------------------ | Column Name | Type | ------------------------ | sale_date | date | | fruit | enum | | sold_num | int | ------------------------(sale…...
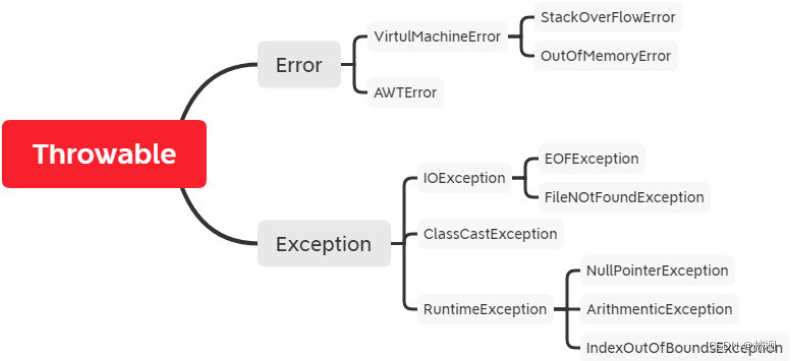
Java基础知识
一、标识符规范 标识符必须以字母(汉字)、下划线、美元符号开头,其他部分可以是字母、下划线、美元符号,数字的任意组合。谨记不能以数字开头。java使用unicode字符集,汉字也可以用该字符集表示。因此汉字也可以用作变量名。 关键字不能用作…...
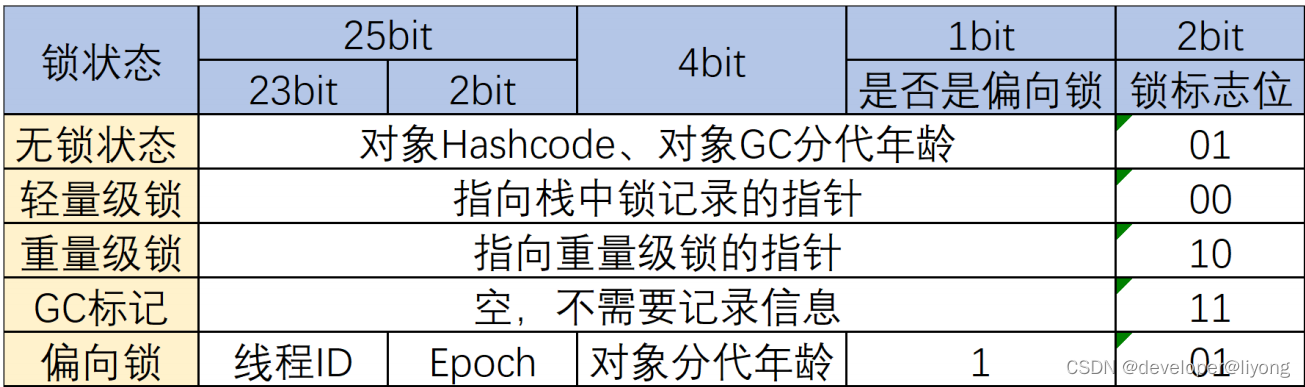
并发编程-Synchronized
什么是Synchronized synchronized是Java提供的一个关键字,Synchronized可以保证并发程序的原子性,可见性,有序性。 我们会把synchronized称为重量级锁。主要原因,是因为JDK1.6之前,synchronized是一个重量级锁相比于J…...
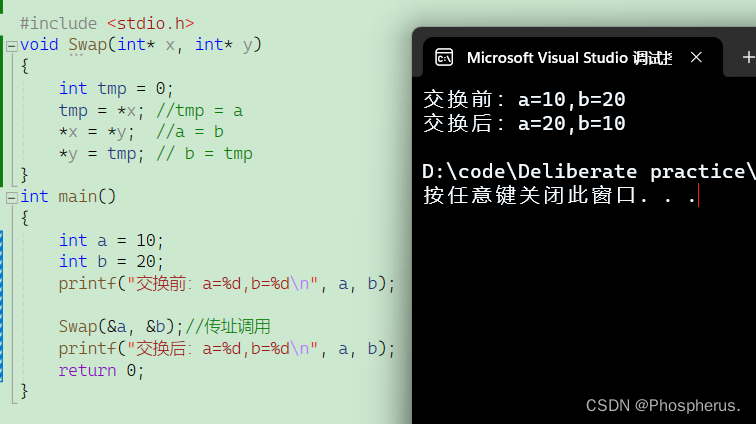
C语言——从头开始——深入理解指针(1)
一.内存和地址 我们知道计算上CPU(中央处理器)在处理数据的时候,是通过地址总线把需要的数据从内存中读取的,后通过数据总线把处理后的数据放回内存中。如下图所示: 计算机把内存划分为⼀个个的内存单元,每…...
微信小程序-绑定数据并在后台获取它
如图 遍历列表的过程中需要绑定数据,点击时候需要绑定数据 这里是源代码 <block wx:for"{{productList}}" wx:key"productId"><view class"product-item" bindtap"handleProductClick" data-product-id"{{i…...

【删除数组用delete和Vue.delete有什么区别】
删除数组用delete和Vue.delete有什么区别? 在 JavaScript 中,delete 和 Vue.js 中的 Vue.delete 是两个完全不同的概念,它们在删除数组元素时的作用和效果也有所不同。 JavaScript 中的 delete 关键字: 在原生 JavaScript 中&a…...
)
【QT+QGIS跨平台编译】之四十二:【QWT+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、QWT介绍二、QWT下载三、文件分析四、pro文件五、编译实践5.1 Windows下编译4.2 Linux下编译5.3 MacOS下编译一、QWT介绍 QWT是一个基于Qt框架的开源C++库,用于创建交互式的图形用户界面。它提供了丰富的绘图和交互功能,可以用于快速开发图形化应用程序。 QWT包…...

yum方式快速安装mysql
问题描述 使用yum的方式简单安装了一下mysql,对过程进行简单记录。 步骤 ①安装wget和vim sudo yum -y install wget vim②下载mysql的rpm包 sudo wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm③升级和更新rpm包 sudo rpm -Uv…...

基于Java的家政预约管理平台
功能介绍 平台采用B/S结构,后端采用主流的Springboot框架进行开发,前端采用主流的Vue.js进行开发。 整个平台包括前台和后台两个部分。 前台功能包括:首页、家政详情、家政入驻、用户中心模块。后台功能包括:家政管理、分类管理…...
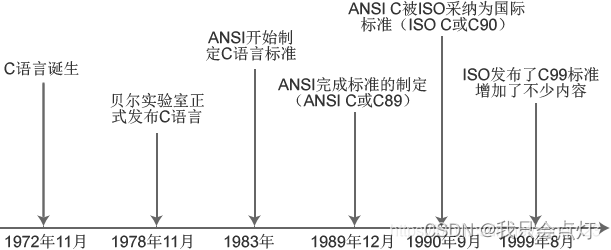
C语言前世今生
C语言前世今生 C语言的发展历史 C语言于1972年11月问世,1978年美国电话电报公司(AT&T)贝尔实验室正式发布C语言,1983年由美国国家标准局(American National Standards Institute,简称ANSI)…...

android aidl进程间通信封装通用实现-用法说明
接上一篇:android aidl进程间通信封装通用实现-CSDN博客 该aar包的使用还是比较方便的 一先看客户端 1 初始化 JsonProtocolManager.getInstance().init(mContext, "com.autoaidl.jsonprotocol"); //客户端监听事件实现 JsonProtocolManager.getInsta…...

【Java中23种设计模式-单例模式2--懒汉式线程不安全】
加油,新时代打工人! 今天,重新回顾一下设计模式,我们一起变强,变秃。哈哈。 23种设计模式定义介绍 Java中23种设计模式-单例模式 package mode;/*** author wenhao* date 2024/02/19 09:16* description 单例模式--懒…...

【后端高频面试题--Linux篇】
🚀 作者 :“码上有前” 🚀 文章简介 :后端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 后端高频面试题--Linux篇 往期精彩内容Windows和Linux的区别?Unix和Linux有什么区别…...
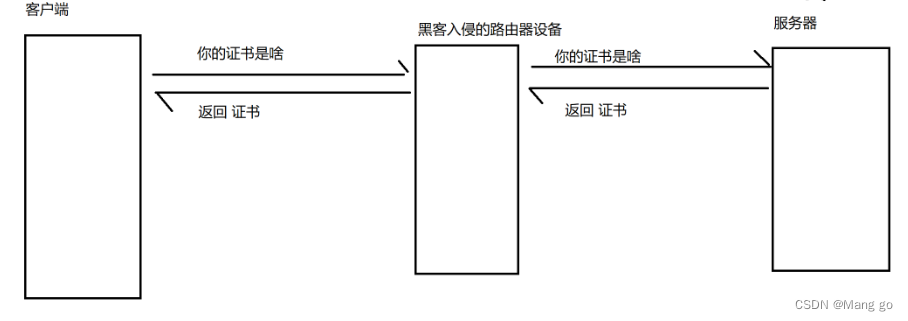
网络原理HTTP/HTTPS(2)
文章目录 HTTP响应状态码200 OK3xx 表示重定向4xx5xx状态码小结 HTTPSHTTPS的加密对称加密非对称加密 HTTP响应状态码 状态码表⽰访问⼀个⻚⾯的结果.(是访问成功,还是失败,还是其他的⼀些情况…).以下为常见的状态码. 200 OK 这是⼀个最常⻅的状态码,表⽰访问成功 2xx都表示…...
【Java中23种设计模式-单例模式2--懒汉式2线程安全】
加油,新时代打工人! 简单粗暴,学习Java设计模式。 23种设计模式定义介绍 Java中23种设计模式-单例模式 Java中23种设计模式-单例模式2–懒汉式线程不安全 package mode;/*** author wenhao* date 2024/02/19 09:38* description 单例模式…...
由LeetCode541引发的java数组和字符串的转换问题
起因是今天在刷下面这个力扣题时的一个报错 541. 反转字符串 II - 力扣(LeetCode) 这个题目本身是比较简单的,所以就不讲具体思路了。问题出在最后方法的返回值处,要将字符数组转化为字符串,第一次写的时候也没思考直…...

HTTP 头部- Origin Referer
Origin & Referer Origin Header 示例 Origin 请求头部是一个 HTTP 头部,它提供了发起请求的网页的源(协议、域名和端口)信息。它通常在进行跨域资源共享(CORS)请求时使用,以便服务器可以决定是否接受…...

Python 实现Excel 文件合并
Excel 文件合并方法较多,前面文章有通过Uipath RPA 对文件进行合并,也可以通过Python或VBA写脚本合并。 通常写脚本维护性更加简洁,本文提供Python 脚本对Excel 文件进行合并,参考Uipath 调用Python 文章,Uipath 调用Python 脚本程序详解-CSDN博客 便能快速实现。代码如…...
)
ECMAScript 6+ 新特性 ( 一 )
2.1.let关键字 为了解决之前版本中 var 关键字存在存在着越域, 重复声明等多种问题, 在 ES6 以后推出 let 这个新的关键字用来定义变量 //声明变量 let a; let b,c,d; let e 100; let f 123, g hello javascript, h [];let 关键字用来声明变量,使用 let 声明的…...

AR眼镜主板与光机定制开发:从核心需求到软硬件协同的工程实践
1. 项目概述:从“主板”与“光机”看AR眼镜的核心最近和几个做AR硬件和方案的朋友聊得比较多,大家普遍有个感觉:市面上关于AR眼镜的讨论,要么是概念满天飞,要么是成品评测,但真正深入到硬件底层,…...

XZ62N,0.7uA静态电流,NMOS输出电压检测芯片
产品概述 这系列芯片是使用 CMOS 技术开发的高精度、低功耗、小封装电压检测芯片。检测电压在小温度漂移的情况下保持极高的精度。输出配置是N-channel open drai 输出。 产品特点 ● 封装:SOT23-3 ● 输出配置:N-channel open drain ● 工作电压&a…...

戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进
戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 在戴森球计划的工厂建设中,蓝图设计…...

VideoDownloadHelper:打破视频下载壁垒的智能解析引擎
VideoDownloadHelper:打破视频下载壁垒的智能解析引擎 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾遇到这样的情况&am…...

选型必读丨高温定向传感器采购与使用的真实成本分析
在定向钻井设备采购决策中,价格往往不是唯一的考量因素。很多用户关注的是高温定向传感器的全生命周期总成本(TCO, Total Cost of Ownership)以及最终能带来怎样的投资回报(ROI)。本文将从专业角度,系统分析…...

超聚变冲刺创业板:年营收582亿,净利10亿 拟募资80亿,估值超400亿
雷递网 雷建平 5月22日超聚变数字技术股份有限公司(简称:“超聚变”)日前递交招股书,准备在深交所创业板上市。超聚变计划募资80亿。其中,40.8亿用于新一代算力基础设施研发及产业化项目,20.3亿用于超聚变智…...

5步解锁Total War模组制作:用RPFM编辑器从新手到专家的完整指南
5步解锁Total War模组制作:用RPFM编辑器从新手到专家的完整指南 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: ht…...

3步掌握React Easy Crop:从零到精通的图像裁剪完整指南
3步掌握React Easy Crop:从零到精通的图像裁剪完整指南 【免费下载链接】react-easy-crop A React component to crop images/videos with easy interactions 项目地址: https://gitcode.com/gh_mirrors/re/react-easy-crop 你是否在为React应用中的图片裁剪…...

别再硬扛了!书匠策AI把毕业论文拆成了“填空题“,2025届必看科普
各位被毕业论文逼到怀疑人生的朋友们,今天这期内容,我想用一种你从没听过的方式,给你拆解一个工具——书匠策AI( 官网直达:www.shujiangce.com微信搜一搜"书匠策AI"可关注公众号)。 先抛一个扎心…...

攻克葫芦科转化难题:甜瓜高效遗传转化体系构建与服务实践
一、 引言 甜瓜(Cucumis meloL.)作为重要的葫芦科经济作物,其遗传转化是开展基因功能验证、分子育种及品质改良的关键技术瓶颈。由于甜瓜普遍存在基因型依赖性强、再生频率低等问题,建立一套稳定、高效的遗传转化体系对科研工作至…...