Collection集合体系(ArrayList,LinekdList,HashSet,LinkedHashSet,TreeSet,Collections)
目录
一.Collection
二.List集合
三.ArrayList集合
四.LinkedList集合
五.Set集合
六.hashSet集合
七.LinkedHashSet集合
八.TreeSet集合
九.集合工具类Collections

集合体系概述
单列集合:Collection代表单列集合,每个元素(数据)只包含一个值。
双列集合:Map代表双列集合,每个元素包含两个值(键值对)。
单列集合:
List系列集合:添加的元素是有序、可重复、有索引
ArrayList:有序、可重复、有索引
LinekdList:有序、可重复、有索引
Set系列集合:添加的元素是无序、不重复、无索引
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:按照大小默认升序排序、不重复、无索引
一.Collection
为什么要先学Collection的常用方法?
Collection是单列集合的祖宗,它规定的方法(功能)是全部单列集合都会继承的。
Collection的常用方法:
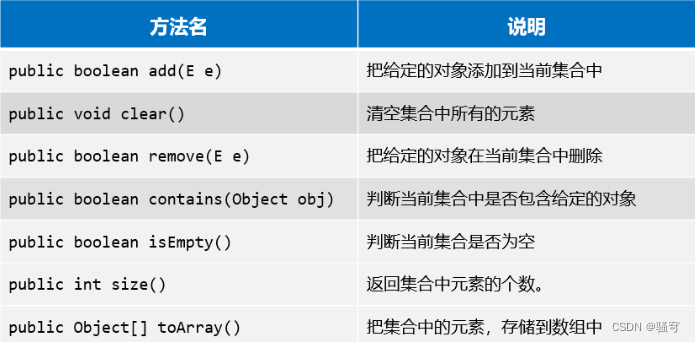
代码展示:
package com.itheima.day06.teacher.g_collection;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;/*** Collection常用方法*/
public class CollectionDemo {public static void main(String[] args) {/*Collection 是 ArrayList祖宗*/
// Collection<String> con = new ArrayList<>();//多态
// ArrayList<String> list = new ArrayList<>();//本态//采用多态?为什么呢? 多态特点 多态下只能调用 父中定义的功能,不会调用子类特有的。// 我们要研究是 共性的功能 使用多态Collection<String> con = new ArrayList<>();//多态// add()con.add("name1");con.add("name2");con.add("name3");con.add("name4");System.out.println(con);//size() 获取集合长度 元素个数System.out.println("集合中有"+con.size()+"个元素");// boolean contains(元素) 判断集合中是否包含指定元素System.out.println("是否包含张三 "+con.contains("张三"));//falseSystem.out.println("是否包含赵四 "+con.contains("赵四"));//true//boolean remove(元素) 删除指定元素 返回 是否删除成功System.out.println("删除一下:王老七 "+con.remove("王老七"));System.out.println(con);//情况集合方法 void clear()con.clear();System.out.println("清空集合之后:"+con);// isEmpty() 判断集合是否为空System.out.println("con当前是空的吗?"+con.isEmpty());// 重写添加数据con.add("谢大脚");con.add("王小蒙");con.add("香秀");con.add("王云");// Object[] toArray() 变成数组Object[] array = con.toArray();System.out.println(Arrays.toString(array));//扩展一个Collection<String> c1 = new ArrayList<>();//多态// add()c1.add("name1");c1.add("name2");c1.add("name3");c1.add("name4");Collection<String> c2 = new ArrayList<>();//多态// add()c2.add("name1");c2.add("name2");c2.add("name3");c2.add("name4");c1.addAll(c2);//c2集合内容 批量添加到c1中System.out.println(c1);}
}
Collection的遍历方式:
1.迭代器:
迭代器是用来遍历集合的专用方式(数组没有迭代器),在Java中迭代器的代表是Iterator。
Collection集合获取迭代器的方法 Iterator<E> iterator() 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的第一个元素
Iterator迭代器中的常用方法:
boolean hasNext():询问当前位置是否有元素存在,存在返回true ,不存在返回false
E next():获取当前位置的元素,并同时将迭代器对象指向下一个元素处。
2.增强for循环:
格式:for (元素的数据类型 变量名 : 数组或者集合) { }
增强for可以用来遍历集合或者数组。
增强for遍历集合,本质就是迭代器遍历集合的简化写法。
3.lambda表达式
得益于JDK 8开始的新技术Lambda表达式,出现了一种更简单、更直接遍历集合的方式-Lambda表达式。
需要使用Collection的如下方法来完成:default void forEach(Consumer<? super T> action)
lists.forEach(s -> {System.out.println(s); });
package com.itheima.day06.teacher.g_collection;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo2 {public static void main(String[] args) {/*Collection 是 ArrayList祖宗*/
// Collection<String> con = new ArrayList<>();//多态
// ArrayList<String> list = new ArrayList<>();//本态//采用多态?为什么呢? 多态特点 多态下只能调用 父中定义的功能,不会调用子类特有的。// 我们要研究是 共性的功能 使用多态Collection<String> con = new ArrayList<>();//多态// add()con.add("name1");con.add("name2");con.add("name3");con.add("name4");System.out.println(con);//size() 获取集合长度 元素个数
// for (int i = 0; i < con.size(); i++) {
// String s = con.get(i);//Conllection 认为无索引
// }// Collection集合的遍历 需要借助一个工具 来完成遍历(迭代)// 迭代器 Interator// 每一个集合对象 都有自己的 迭代器。// 呼叫迭代器 获取迭代器Iterator<String> it = con.iterator();// iterator 可以帮助集合完成 元素的获取// 迭代器指向第一个元素while(it.hasNext()){//询问 当前位置是否有元素 有true false//再去获取String e = it.next();System.out.println(e);}}
}-------------package com.itheima.day06.teacher.g_collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo3 {public static void main(String[] args) {/*Collection 是 ArrayList祖宗*/
// Collection<String> con = new ArrayList<>();//多态
// ArrayList<String> list = new ArrayList<>();//本态//采用多态?为什么呢? 多态特点 多态下只能调用 父中定义的功能,不会调用子类特有的。// 我们要研究是 共性的功能 使用多态Collection<String> con = new ArrayList<>();//多态// add()con.add("name1");con.add("name2");con.add("name3");con.add("name4");System.out.println(con);//因为开发中 大量场景都要使用到 集合 都要去完成遍历 所以jdk 升级的时候 做了一个很高明的操作 就是简化迭代器的使用/*增强for - --单列集合 数组for(数据类型 变量名 :被遍历的集合/数组){}*/
// for(String s:con){
// System.out.println(s);
// }//集合.forfor (String s : con) {System.out.println(s);}//增强for 只适合于获取数据 不适合与修改}
}----------package com.itheima.day06.teacher.g_collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Consumer;public class CollectionDemo4 {public static void main(String[] args) {/*Collection 是 ArrayList祖宗*/
// Collection<String> con = new ArrayList<>();//多态
// ArrayList<String> list = new ArrayList<>();//本态//采用多态?为什么呢? 多态特点 多态下只能调用 父中定义的功能,不会调用子类特有的。// 我们要研究是 共性的功能 使用多态Collection<String> con = new ArrayList<>();//多态// add()con.add("name1");con.add("name2");con.add("name3");con.add("name4");System.out.println(con);/*jdk8提供的 foreach*/con.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {//s 接收每次得到的数据System.out.println(s);}});System.out.println("=================");con.forEach(s -> System.out.println(s));con.forEach(System.out::println);}
}
二.List集合
1.List集合因为支持索引,所以多了很多与索引相关的方法
特有方法:
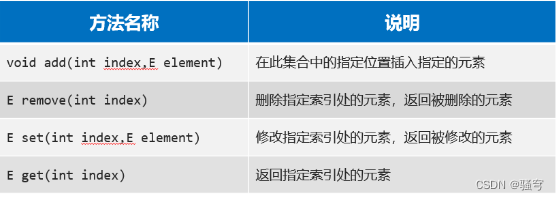
2.遍历方式:
1.for循环(因为List集合有索引)
2.迭代器
3.增强for循环
4.Lambda表达式
package com.itheima.day07.teacher.list01;import java.util.ArrayList;
import java.util.List;public class ListDemo {/*Collection 单列集合顶层接口里面定义关于元素的 一些 获取添加删除的通用方法--- List 子接口 有序集合特点:有序 可以重复 有索引里面 有写特有和索引相关方法增 void add(int index,E e) 往集合指定位置添加元素删 E remove(int index) 根据指定索引进行删除 返回被删除元素改 E set(int index,E e) 根据索引进行元素替换,返回被替换的元素查 E get(int index) 根据索引获取元素*/public static void main(String[] args) {// 这是多态写法 因为在多态下只能使用List 接口定义的方法List<String> list = new ArrayList<>();//添加元素list.add("name1");list.add("name2");list.add("name3");list.add("name4");System.out.println(list);//有序--存取顺序一致。且有索引// 索引为3的位置添加一个 真玲list.add(3,"真玲");System.out.println(list);// 删除// 删除索引为4的元素String remove = list.remove(4);System.out.println("删除索引为4的元素:"+remove);System.out.println("删除后的集合:"+list);
// System.out.println(list.remove(4)); 报错 索引越界//修改 索引为2的 改为狗蛋System.out.println(list.set(2,"狗蛋"));System.out.println("修改后的集合:"+list);// 获取 索引为1的元素System.out.println(list.get(1));}
}-----------
package com.itheima.day07.teacher.list01;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class ListDemo02 {public static void main(String[] args) {/*完成集合的遍历遍历方式 四种*/List<String> list = new ArrayList<>();list.add("name1");list.add("name2");list.add("name3");list.add("name4");//普通for循环 list集合.forifor (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}System.out.println("===============");//迭代器 iterator()Iterator<String> it = list.iterator();while(it.hasNext()){System.out.println(it.next());}System.out.println("===============");//增强for list集合.forfor (String s : list) {System.out.println(s);}// lambda 集合.forEachlist.forEach(s -> System.out.println(s));System.out.println("===============");list.forEach(System.out::println);}
}
三.ArrayList集合
1.ArrayList集合底层是基于数组实现的
2.数组的特点:查询快,增删慢(数组长度固定,增删需要新数组效率低)
3.ArrayList集合对象的创建和扩容过程
1、利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
2、添加第一个元素时,底层会创建一个新的长度为10的数组
3、存满时,会扩容1.5倍
4、如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
4.ArrayList集合适合什么业务场景?不适合什么业务场景?
适合根据索引查询数据的场景或者数据量不是很大的场景
不适合数据量很大时又要频繁地进行增删操作的场景
因为比较常用我单独写了一篇
四.LinkedList集合
1.LinkedList集合底层是基于双链表实现的
2.链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址。
3.链表的特点:查询慢,都要从头开始找,增删快
4.双链表的特点:
每个节点包含数据值和上一个节点的地址以及下一个节点的地址
查询慢,增删相对较快,但对首尾元素进行增删改查的速度是极快的
5.LinkedList新增了:很多首尾操作的特有方法。
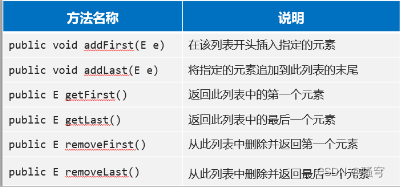
6.LinkedList集合适合需要频繁操作首尾元素的场景,比如栈和队列
package com.itheima.day07.teacher.list02;import java.util.LinkedList;public class LikendListDemo01 {public static void main(String[] args) {/*用LinkedList模拟 小火车过山洞...模拟 队列结构队列结构先进先出 FIFO*/LinkedList<String> list = new LinkedList<>();//入队 进山洞list.addLast("火车头");list.addLast("第一节车厢");list.addLast("第二节车厢");list.addLast("第三节车厢");list.addLast("火车尾");//出山洞System.out.println(list.removeFirst());System.out.println(list.removeFirst());System.out.println(list.removeFirst());System.out.println(list.removeFirst());System.out.println(list.removeFirst());}
}------------package com.itheima.day07.teacher.list02;import java.util.LinkedList;public class LinkedListDemo02 {public static void main(String[] args) {/*模拟弹夹 发射子弹栈结构特点 先进后出 FILO*/LinkedList<String> danJia = new LinkedList<>();// 压 子弹danJia.addFirst("第一颗子弹");//每次都在最上面danJia.addFirst("第二颗子弹");//每次都在最上面danJia.addFirst("第三颗子弹");//每次都在最上面danJia.addFirst("第四颗子弹");//每次都在最上面// 射子弹System.out.println(danJia.removeFirst());//每次射最上面的System.out.println(danJia.removeFirst());System.out.println(danJia.removeFirst());System.out.println(danJia.removeFirst());}
}
五.Set集合
整体特点: 无序 ,存取顺序不保证一致; 不重复; 无索引;
HashSet: 无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
六.hashSet集合
1.哈希值:
1.就是一个int类型的数值,Java中每个对象都有一个哈希值
2.Java中的所有对象,都可以调用Obejct类提供的hashCode方法,返回该对象自己的哈希值
2.对象哈希值的特点:
同一个对象多次调用hashCode()方法返回的哈希值是相同的。
不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)。
3.HashSet底层基于哈希表实现
JDK8之前,哈希表 = 数组+链表:
1.创建一个默认长度16的数组,默认加载因子为0.75,数组名table
2.使用元素的哈希值对数组的长度求余计算出应存入的位置
3.判断当前位置是否为null,如果是null直接存入
4.如果不为null,表示有元素,则调用equals方法比较
JDK8开始,哈希表 = 数组+链表+红黑树(一种平衡的二叉树)
JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树
JDK8开始后,哈希表中引入了红黑树后,进一步提高了操作数据的性能。
哈希表是一种增删改查数据性能都较好的结构。
4.数据结构:树
二叉查找树:规则:小的往左存,大的往右存,一样的不存
可能存在的问题:当数据已经是排好序的,导致查询的性能与单链表一样,查询速度变慢!
平衡二叉树:在满足二叉查找树的大小规则下,让树尽可能矮小,以此提高查数据的性能。
红黑树:是一种可以自平衡的二叉树,红黑树是一种增删改查数据性能相对都较好的结构
5.如何让HashSet集合能够实现对内容一样的两个不同对象也能去重复?
重写hashCode()和equals()方法
package com.itheima.day07.teacher.set02;import java.util.Objects;/*** 学术类*/
public class Student {private String name;private int age;private double height;public Student() {}public Student(String name, int age, double height) {this.name = name;this.age = age;this.height = height;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}/*** 获取* @return height*/public double getHeight() {return height;}/*** 设置* @param height*/public void setHeight(double height) {this.height = height;}public String toString() {return "Student{name = " + name + ", age = " + age + ", height = " + height + "}";}//利用idea快捷键 hashCode equals/*比较两个对象的内容*/@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);}/*根据属性算哈希值 尽量不一样的属性 值不同 减少哈希碰撞*/@Overridepublic int hashCode() {return Objects.hash(name, age, height);}
}------------
package com.itheima.day07.teacher.set02;import java.util.HashSet;public class HashSetDemo {public static void main(String[] args) {/*创建一个学生集合 用来存储不同 学生对象*/HashSet<Student> set = new HashSet<>();//创建学生对象Student stu1 = new Student("小磊",18,1.88);Student stu2 = new Student("小鑫",28,1.38);Student stu3 = new Student("小哲",22,1.78);Student stu4 = new Student("小鑫",28,1.38);set.add(stu1);set.add(stu2);set.add(stu3);set.add(stu2);set.add(stu4);//我们没有重写 hashCode equals的时候可以存储进去的,// 原因是 存的时候先调用 hashCode方法(Object--根地址有一定关系) 哈希code不一样.// 即使哈希一样,也能存!!没有重写equals 比较的是地址值 不是一个元素。/*在开发过程中是地址值不一样就是不同对象吗?其实不尽然,我们开发中认为 两个对象如果 所有属性值都一样 认为是 同一个对象。在我们观点里面 stu2 stu4是同一个对象。默认情况下没有当成 同一个对象 并没有完成 元素的去重如果 想要达到开发标准 两个对象属性值都一样 就是同一个对象怎么做?重写hashCode() -- 目的 是要根据内容算哈希值。equals() -- 目的 是进行内容比较。重写之后stu2 stu4 先算出哈希值 哈希碰撞 位置一样 再进行equals比较 内容一样不存*/for (Student student : set) {System.out.println(student);}/*存储元素原理先根据hashcode算出 存储位置位置上有元素 就进行equals比较。*/}
}
七.LinkedHashSet集合
依然是基于哈希表(数组、链表、红黑树)实现的
但是,它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置
八.TreeSet集合
1. 特点:不重复、无索引、可排序(默认升序排序 ,按照元素的大小,由小到大排序)
对于数值类型:Integer , Double,默认按照数值本身的大小进行升序排序。
对于字符串类型:默认按照首字符的编号升序排序。
2.底层是基于红黑树实现的排序。
3.TreeSet集合中对自定义类型元素排序方案:
方式一:让自定义的类(如学生类)实现Comparable接口,重写里面的compareTo方法来指定比较规则。
方式二:通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象,用于指定比较规则)
package com.itheima.day07.teacher.set03;/**学生类
*/public class Student implements Comparable<Student> {private String name;private int age;private double height;public Student() {}public Student(String name, int age, double height) {this.name = name;this.age = age;this.height = height;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}/*** 获取* @return height*/public double getHeight() {return height;}/*** 设置* @param height*/public void setHeight(double height) {this.height = height;}public String toString() {return "Student{name = " + name + ", age = " + age + ", height = " + height + "}";}@Overridepublic int compareTo(Student o) {return this.age-o.age;//前-后 升序}
}-------------
package com.itheima.day07.teacher.set03;import java.util.Comparator;
import java.util.TreeSet;public class TreeSetDemo {/*TreeSet底层是一个 二叉排序树遵循特点小的存左边 大的存右边 一样的不存里面的存储的元素必须具备 !!排序功能!! 元素之间有大小关系*/public static void main(String[] args) {TreeSet<Integer> set1 = new TreeSet<>();set1.add(13);set1.add(15);set1.add(12);set1.add(33);set1.add(26);set1.add(13);set1.add(14);System.out.println(set1);/*TreeSet去重原则 一样的不存存完之后元素进行排序是因为 存储的元素类型有排序规则implements Comparable<Integer>实现 Comparable 代表有了排序的规则 所以可以使用TreeSet存储TreeSet 去重的原理是排序的规则 如果一样就不存。*/System.out.println("==========");TreeSet<String> set2 = new TreeSet<>();set2.add("cba");set2.add("cbb");set2.add("aba");set2.add("bbb");set2.add("cbb");System.out.println(set2);}
}-------------
package com.itheima.day07.teacher.set03;import java.util.Comparator;
import java.util.TreeSet;public class TreeSetDemo01 {/*开发中不建议 用TreeSet存储自定义类型,因为会根据只定义排序内容进行去重,与实际开发不符。如果执意要用 你就得对所有的 属性进行排序比较 规则如果要用TreeSet存自定义类型1:自定义类型 实现 Comparable接口 实现排序规则。2:在 TreeSet 构造中 写出临时的排序规则 传递规则Comparator接口。*/public static void main(String[] args) {//创建学生对象Student stu1 = new Student("小磊",18,1.88);Student stu2 = new Student("小鑫",28,1.38);Student stu3 = new Student("小哲",22,1.78);Student stu4 = new Student("小迪",28,1.68);//创建 TreeSet集合TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o2.getAge()-o1.getAge();//按照年龄降序}});//存元素set.add(stu1);set.add(stu2);set.add(stu3);set.add(stu4);for (Student student : set) {System.out.println(student);}}
}Collection集合使用小结:
1、如果希望记住元素的添加顺序,需要存储重复的元素,又要频繁的根据索引查询数据?
用ArrayList集合(有序、可重复、有索引),底层基于数组的。(常用)
2、如果希望记住元素的添加顺序,且增删首尾数据的情况较多?
用LinkedList集合(有序、可重复、有索引),底层基于双链表实现的。
3.如果不在意元素顺序,也没有重复元素需要存储,只希望增删改查都快?
用HashSet集合(无序,不重复,无索引),底层基于哈希表实现的。(常用)
4.如果希望记住元素的添加顺序,也没有重复元素需要存储,且希望增删改查都快?
用LinkedHashSet集合(有序,不重复,无索引),底层基于哈希表和双链表,
5.如果要对元素进行排序,也没有重复元素需要存储?且希望增删改查都快?
用Treeset集合,基于红黑树实现。
集合的并发修改异常:
使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误"王麻子”);("小李子");由于增强for循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强for循环遍历("李爱花");在同时("张全蛋");("晓李");删除集合中的数据时,程序也会出现并发修改异常的错误。("李玉刚");
怎么保证遍历集合同时删除数据时不出bug?
使用迭代器遍历集合,但用迭代器自己的删除方法删除数据即可
如果能用for循环遍历时:可以倒着遍历并删除;或者从前往后遍历,但删除元素后做i--操作
九.集合工具类Collections
Collections代表集合工具类,提供的都是静态方法,用来操作集合元素的。
常用静态方法:

public static <T> void sort(List<T> list):
数值型的List集合,按照值特性排序,默认升序
字符串的List集合,按照字符串元素的首字母编号排序。默认升序
对于自定义类型的集合,List<Student> ,默认报错的解决方法
解决方式一:让学生类实现比较规则Comparable接口。重写比较方法。
解决方式二:可以让sort方法自带一个比较器
package com.itheima.day07.teacher.other;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class EditException {/*并发修改异常什么是并发修改异常:ConcurrentModificationException在使用迭代器(增强for) 遍历元素的同时,通过集合对象删除了集合中的指定数据,这个时候就会出现并发修改异常。原因是什么:迭代器里面 元素个数 和 集合中元素个数不一致了。怎么避免并发修改异常:在开发中不在迭代器 迭代过程中 使用集合删除对象。使用迭代器去删 迭代器删除的同时会给集合进行同步。*/public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("name1");list.add("name2");list.add("name3");list.add("name3");list.add("name4");list.add("name5");System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]//需求:找出集合中带"李"字的姓名,并从集合中删除Iterator<String> it = list.iterator();while(it.hasNext()){String name = it.next();if(name.contains("李")){
// list.remove(name);不用集合删 用迭代器删除it.remove();//迭代器删除 会同步给集合}}System.out.println(list);}
}-------------
package com.itheima.day07.teacher.other;import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;public class CollenctionsDemo {/*集合工具类使用*/public static void main(String[] args) {//ArrayList集合 是Collection子类 也是List子类List<String> list = new ArrayList<>();//
// list.add("a"); 一个一个元素添加//批量添加 Collections.addAll(Collection集合,T...t)//T 泛型的意思 集合里面是什么类型 泛型就是什么类型Collections.addAll(list,"nba","cba","qba","abc");System.out.println("查看集合内容:"+list);// 打乱顺序方法 --针对有序集合的(List)// Collections.shuffle(List集合)Collections.shuffle(list);System.out.println("打乱后集合内容:"+list);// 对集合元素排序 --针对有序集合(List)// Collections.sort(List集合) 有前提 元素类型 具备排序规则 需要实现Comparable接口Collections.sort(list); //按照默认顺序 升序System.out.println("排序之后:"+list);// 临时改变排序规则// Collections.sort(List集合,Comparator接口实现类对象) 按照当前自己定义的排序规则排序Collections.sort(list, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return o2.compareTo(o1);//字符串进行 降序 后面比较前面}});System.out.println("自定义排序规则后:"+list);}
}
相关文章:
Collection集合体系(ArrayList,LinekdList,HashSet,LinkedHashSet,TreeSet,Collections)
目录 一.Collection 二.List集合 三.ArrayList集合 四.LinkedList集合 五.Set集合 六.hashSet集合 七.LinkedHashSet集合 八.TreeSet集合 九.集合工具类Collections 集合体系概述 单列集合:Collection代表单列集合,每个元素&#…...

Job 和 DaemonSet
一、Job 1、Job 背景问题 K8s 里,最小的调度单元是 Pod,如果直接通过 Pod 来运行任务进程,会产生以下几种问题: ① 如何保证 Pod 内进程正确的结束? ② 如何保证进程运行失败后重试? ③ 如何管理多个任…...

C++ 二维前缀和 子矩阵的和
输入一个 n 行 m 列的整数矩阵,再输入 q 个询问,每个询问包含四个整数 x1,y1,x2,y2 ,表示一个子矩阵的左上角坐标和右下角坐标。 对于每个询问输出子矩阵中所有数的和。 输入格式 第一行包含三个整数 n,m,q 。 接下…...

第六届计算机科学与技术在教育中的应用国际会议(CSTE 2024)
2024年第六届计算机科学与技术在教育中的应用国际会议(CSTE 2024)将于4月19-21日在中国西安举行。此次会议由陕西师范大学主办,陕西师范大学教育学部承办。在前五届成功举办的基础上,CSTE 2024将继续关注计算机科学与技术在教育领…...

Vue3学习——标签的ref属性
在HTML标签上,可以使用相同的ref名称,得到DOM元素ref放在组件上时,拿到的是组件实例(组件defineExpose暴露谁,ref才可以看到谁) <script setup lang"ts"> import RefPractice from /compo…...
数字化转型导师坚鹏:政府数字化转型之数字化技术
政府数字化转型之数字化技术 ——物联网、云计算、大数据、人工智能、虚拟现实、区块链、数字孪生、元宇宙等综合解析及应用 课程背景: 数字化背景下,很多政府存在以下问题: 不清楚新技术的发展现状? 不清楚新技术的重要应…...

go build
go build 作用:将Go语言程序和相关依赖编译成可执行文件 go build 无参数编译 生成当前目录名的可执行文件并放置于当前目录下,如: go build go build文件列表 编译同目录的多个源码文件时,可以在 go build 的后面提供多个文件…...

力扣238和169
一:238. 除自身以外数组的乘积 1.1题目 1.2思路 1.3代码 //左右乘表 int* productExceptSelf(int* nums, int numsSize, int* returnSize) {int* answer (int*)malloc(numsSize*sizeof(int));int i 0;int left[numsSize],right[numsSize];left[0] 1;for(i 1;…...

Android 基础技术——Framework
笔者希望做一个系列,整理 Android 基础技术,本章是关于 Framework 简述 Android 系统启动流程 当按电源键触发开机,首先会从 ROM 中预定义的地方加载引导程序 BootLoader 到 RAM 中,并执行 BootLoader 程序启动 Linux Kernel&…...

JavaWeb 中的静态资源访问
文章目录 JavaWeb 中的静态资源访问1. Tomcat 中的两个默认 ServletJSPServletDefaultServlet配置引起的 bug情况一情况二情况三 2. 总结3. 如何允许静态资源访问 JavaWeb 中的静态资源访问 1. Tomcat 中的两个默认 Servlet Tomcat 有两个默认的 Servlet,你的 Web…...

asp.net web api 用户身份验证
前后端分离的开发中,应用服务需要进行用户身份的验证才允许访问数据。实现的方法很简单。创建一个webapi项目。在App_Start目录下找到WebApiConfig.cs, 在里面增加一个实现类。 public static class WebApiConfig{public static void Register(HttpConfi…...

3DTile是不是没有坐标的选择?
可参考以下内容: 一、坐标参考系统(CRS) 3D Tiles 使用右手笛卡尔坐标系;也就是说,x和y的叉积产生z。3D Tiles 将z轴定义为局部笛卡尔坐标系的向上。tileset的全局坐标系通常位于WGS 84地心固定(ECEF)参考系(EPSG4978)中,但它不是必须的&am…...

数据采集三防平板丨三防平板电脑丨停车场应用
随着现代科技的不断发展,三防平板已经成为许多人工作和生活的必备工具。在停车场这个场景中,三防平板的应用可以大大提高停车场管理的效率和安全性。 停车场是现代城市交通管理的重要组成部分,它直接关系到城市交通的流畅和公共安全。停车场…...
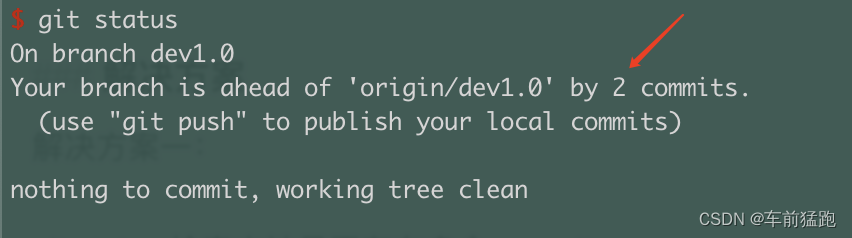
解决git push时的too_many_commits提示
解决git push时的too_many_commits提示 提示内容 push时报错如下: Sorry, you were trying to upload xxxxxx commits in one push 原因分析 这个应该是因为在提交规则里配置了 一次只允许提交一个 commit,这样当 icode 上有 commit 没有合入时&…...

GPT-4助力我们突破思维定势
GPT-4在突破思维局限、激发灵感和促进知识交叉融合方面的作用不可小觑,它正逐渐成为一种有力的工具,助力各行业和研究领域的创新与发展。 GPT-4在突破传统思维模式、拓宽创新视野和促进跨学科知识融合方面扮演着越来越重要的角色: 突破思维…...

【前端工程化面试题】什么是 CI/CD
CI/CD 是软件开发中的两个重要实践,分别代表持续集成(Continuous Integration)和持续交付/持续部署(Continuous Delivery/Continuous Deployment)。 持续集成 (Continuous Integration, CI):持续集成是一种…...

kafka的安装,用于数据库同步数据
1.0 背景调研 因业务需求,需要查询其他部门的数据库数据,不方便直连数据库,所以要定时将他们的数据同步到我们的环境中,技术选型选中了kafkaCDC Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久…...

Bean 的作用域你知道么 ?
Bean 的作用域有哪些? 所谓的作用域,其实就是说这个东西在哪个范围内可以被使用 , 如我们定义类的成员变量的时候使用的public,private等这些也是作用域的概念 Spring的Bean的作用域, 描述的就是这个Bean在哪个范围内可以被使用. 不同的作用域决定了Bean的创建, 管理和销毁的…...
Windows 使设置更改立即生效——并行发送广播消息
目录 前言 1 遍历窗口句柄列表 2 使用 SendMessageTimeout 发送延时消息 3 并行发送消息实现模拟广播消息 4 修改 UIPI 消息过滤器设置 5 托盘图标刷新的处理 6 完整代码和测试 本文属于原创文章,转载请注明出处: https://blog.csdn.net/qq_5907…...
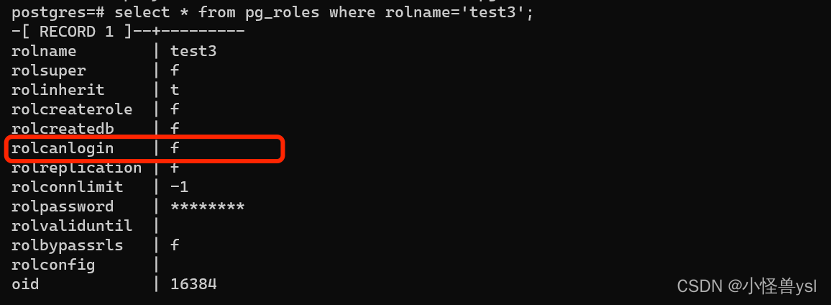
PostgreSQL使用session_exec和file_fdw实现失败次数锁定用户策略
使用session_exec 、file_fdw以及自定义函数实现该功能。 缺陷:实测发现锁用户后,进去解锁特定用户。只能允许一次登陆,应该再次登陆的时候,触发函数,把之前的日志里的错误登陆的信息也计算到登录次数里了。而且foreig…...

轻松实现颜色与数字的映射:Python 数据处理实战
在数据分析与日常数据处理中,我们经常需要将文本信息转换为数值型数据,尤其在颜色编码、分类标签等场景中尤为常见。 今天,我将分享一个简单实用的 Python 示例,演示如何利用 pandas 库将颜色名称映射为对应的数字,并将…...

LoRA参数高效微调:低秩适配原理与可视化实战
1. 项目概述:这不是调参,是给大模型“打补丁”的手艺活LoRA(Low-Rank Adaptation)不是什么新潮概念,它本质上是一种参数高效微调(PEFT)的工程实践智慧——当你要让一个百亿参数的GPT或BERT模型去…...

Unity串口通信实战:线程安全与跨平台解决方案
1. 这不是“调个串口”那么简单:Unity里做串口通信的真实战场很多人第一次在Unity里尝试串口通信,是被一个硬件交互需求推着走的——比如要读取温湿度传感器数据、控制步进电机转速、或者让Arduino小车响应Unity场景里的按钮点击。他们搜到“Unity 串口 …...

2026网盘怎么选:别只盯“不限速”,更该看同步稳定性与数据安全
很多人换网盘的导火索是“限速”,但真正拉开体验差距的,往往是:同步是否稳定、复杂网络下是否容易失败、多人协作有没有权限与版本控制、数据安全与合规是否站得住脚。下面这篇不再只比较“快不快”,而是用更贴近长期使用的维度&a…...

智慧巡检-基于深度学习的指针式压力表读数识别【YOLO+OpenCv+TensorRT+ROS+Python】
智慧巡检-基于深度学习的指针式压力表读数识别【YOLOOpenCvTensorRTROSPython】 1指针式压力表读数识别系统(YOLOOpenCVTensorRTROS)一、系统整体架构 ┌──────────────────────────────────────────────…...

小白程序员必看:收藏这份分词知识框架,轻松入门大模型!
分词是NLP和大型语言模型处理文本的第一步。本文系统介绍了分词的基本概念,详细解析了英文和中文的分词方法,包括词级、字符级和子词级分词的原理与区别。特别强调了子词级分词(如BPE、WordPiece)在解决OOV问题和保留语义结构方面…...

STM32 HAL库驱动DS18B20避坑指南:单总线时序不准?试试用定时器精准延时
STM32 HAL库驱动DS18B20避坑指南:单总线时序不准?试试用定时器精准延时 在嵌入式开发中,温度传感器DS18B20因其单总线接口和数字输出特性广受欢迎。然而,许多开发者在使用STM32 HAL库驱动DS18B20时,常遇到温度读取失败…...

企业级实时数据采集方案:构建高性能直播弹幕监控系统
企业级实时数据采集方案:构建高性能直播弹幕监控系统 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播电商、游戏…...

STC8A8K64S4A12单片机PWM调速实战:手把手教你搞定循迹小车的电机驱动与速度控制
STC8A8K64S4A12单片机PWM调速实战:从原理到电机精准控制 当你想让一个小车平稳地沿着黑线行驶,或者在转弯时保持优雅的姿态,PWM调速技术就是那个藏在幕后的魔术师。STC8A8K64S4A12这颗国产单片机内置的硬件PWM模块,正是实现这一切…...

Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞
Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞 【免费下载链接】Sub-Zero.bundle Subtitles for Plex, as good you would expect them to be. 项目地址: https://gitcode.com/gh_mirrors/su/Sub-Zero.bundle Sub-Zero是Plex媒体服务器最强大的字幕插件之…...