kafka的安装,用于数据库同步数据
1.0 背景调研
因业务需求,需要查询其他部门的数据库数据,不方便直连数据库,所以要定时将他们的数据同步到我们的环境中,技术选型选中了kafka+CDC
Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久性、分布式的发布订阅的消息队列系统。 它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份开源,成为Apache的顶级子项目。 它主要用于处理消费者规模网站中的所有动作流数据。动作指(网页浏览、搜索和其它用户行动所产生的数据)。
1.1 kafka核心
Kafka 的核心概念是消息系统,其中包含以下几个重要组件:
Topic(主题):消息的分类或者说是逻辑上的区域。数据被发布到 Kafka 集群的 Topic 中,并且消费者对特定 Topic 进行订阅来消费这些数据。
Producer(生产者):负责向 Kafka 集群中的 Topic 发布消息,可以是任何发送数据的应用程序。
Consumer(消费者):订阅一个或多个 Topic,从 Broker 中拉取数据并进行处理。消费者可以以组的形式组织,每个组只能有一个 Consumer 对 Topic 的每个分区进行消费。
Broker(代理服务器):Kafka 集群中的每个节点都是一个 Broker,负责管理数据的存储和传输,处理生产者和消费者的请求。
1.2 技术比对
相比于 Cattle,Kafka 具备以下优势:
高吞吐量和低延迟:Kafka 使用简单而高效的数据存储机制,具备高度可伸缩性,能够处理大规模的数据流。它的设计目标是支持每秒数百万条消息的处理。
分布式和可扩展:Kafka 可以在多个 Broker 节点上进行水平扩展,通过分区机制实现负载均衡和容错性。
持久化存储:Kafka 使用日志结构存储消息,提供了高效的磁盘持久化功能,确保数据的可靠性和持久性。
多语言支持:Kafka 提供丰富的客户端库,支持多种编程语言,包括 Java、Python、Go、C++ 等,方便开发者进行集成和使用。
生态系统丰富:Kafka 生态系统提供了许多与之配套的工具和服务,例如 Kafka Connect 用于数据集成,KSQL 实现流处理,以及一些第三方工具用于监控、管理和运维等。
总的来说,Kafka 是一个高性能、可靠性强且具备良好扩展性的分布式流处理平台,适用于实时数据流处理、消息队列、日志收集等各种场景。相比之下,Cattle 在数据传输和流处理方面的功能可能较为有限,但具体选择还需根据业务需求和技术栈来进行评估和决策。
2.0 安装环境
Linux服务器
Xshell工具
Jdk
Kafka
Docker
Windows服务器
消费者系统(我们用的是.net,可使用其他语言代替)
。。。。。。
3.0 目标源数据库配置步骤
需要在目标源数据库增加个账号给maxwell使用,这里以mysql为例
新建mysql的帐号
CREATE USER ' maxwell用户名'@'%' IDENTIFIED BY '密码';
CREATE USER 'maxwell用户名'@'localhost' IDENTIFIED BY '密码';
给新账号赋权限(这个是全部权限)
GRANT ALL ON maxwell用户名.* TO 'maxwell用户名'@'%';
GRANT ALL ON maxwell用户名.* TO 'maxwell用户名'@'localhost';
给新账号赋权限(这个是指定权限,两个执行一个就行)
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell用户名'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell用户名'@'localhost';
4.0 Linux服务器配置步骤
4.1 安装基础工具
4.1.1 lrzsz(文件传输工具)
第1步:安装lrzsz,这个工具可以直接拖拽文件上传到服务器
yum install lrzsz –y
执行结果示例

第2步:新建目录,用来存储安装包
mkdir /home/software
第3步:把安装包传输到linux服务器上,拖拽到/home/software
CD /home/software
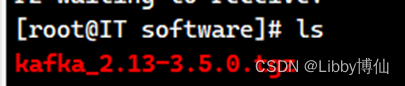
Kafka安装包本次使用的是2.13版本,开始拖拽文件到Xshell窗口下
kafka_2.13-3.5.0.tgz
执行结果示例


执行ls查看目录下是否有文件
Ls
执行结果示例
4.1.2 vim(文本编辑器)
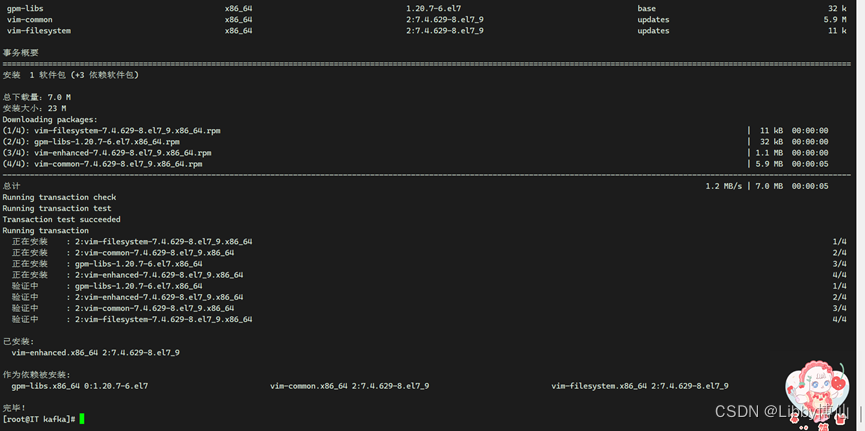
第1步:安装vim,这个是文本编辑器
yum install vim –y
执行结果示例
可通过vim命令打开文本,配置文件等
4.2 安装Java
第1步:安装jdk,执行命令,*代表安装所有相关的包,yum install -y java-1.8.0-openjdk.x86_64如果执行这个命令,则只安装jdk本身,后续的软件安装运行会出现依赖包不全等问题,建议使用*来安装
yum install -y java-1.8.0-openjdk*
执行结果示例

第2步:查询java版本,检验第一步是否安装成功,同时查出java版本号,为后面配置环境变量做准备
rpm -qa | grep java
执行结果示例

第3步:配置java环境变量
输入以下命令打开配置文件
vi /etc/profile
按键pgdn跳到最后一行 按键O 新插下一行
将下面文件添加到配置文件中 注意:替换java版本号
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
export JRE_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
export CLASSPATH=.:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
按键esc切换命令模式,输入:wq退出保存
第4步:刷新环境变量,让新加的java配置生效
source /etc/profile
第5步:检查java是否安装成功,输入后会提示java版本号,如果第3步配置错误,会提示java命令不存在
java –version
执行结果示例

4.3 安装kafka
第1步:新建目录,用来存储kafka
mkdir /home/kafka
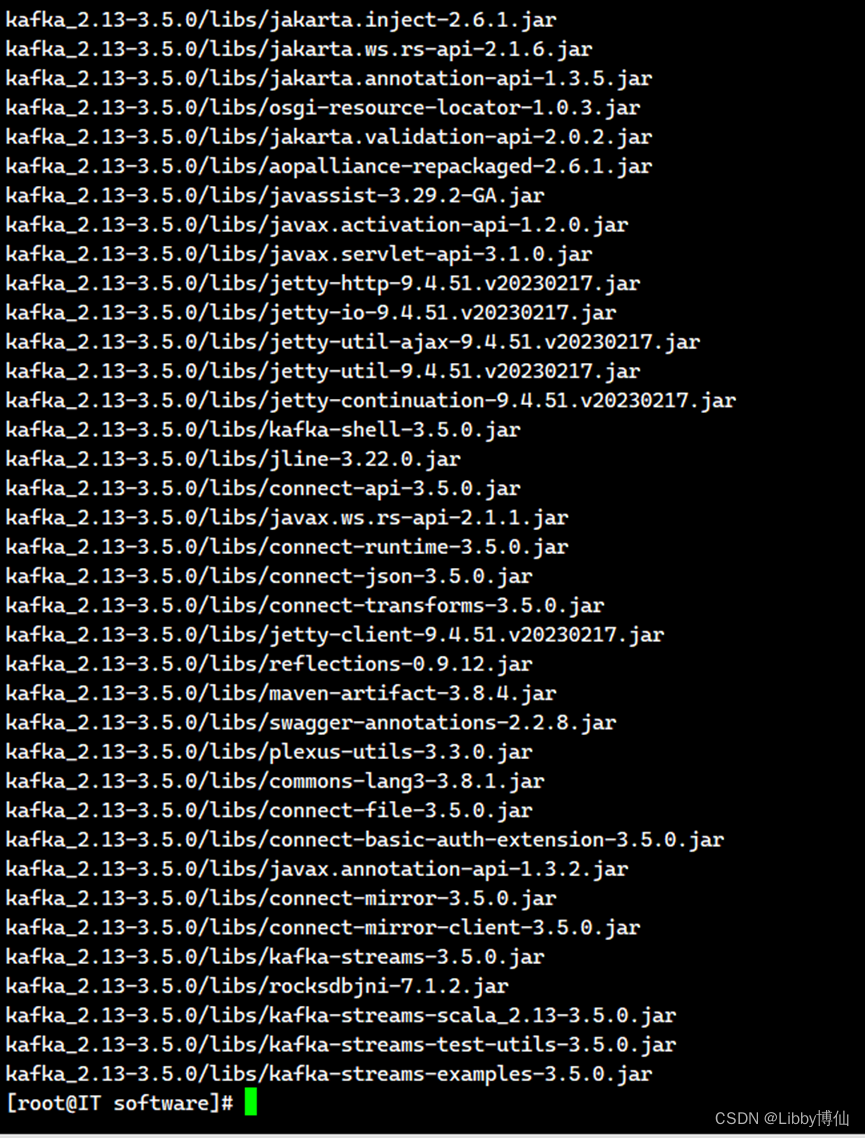
第2步:要解压 tgz 文件,可以使用 Linux 系统自带的 tar 命令。文件在4.1.1中上传到了服务器
tar –xzvf kafka_2.13-3.5.0.tgz -C /home/kafka
执行结果示例
tar命令解释(无特殊情况不需要第3步后续操作,了解就好):
tar -xzvf kafka_2.13-3.5.0.tgz
x:表示解压
z:表示使用 gzip 压缩
v:表示显示详细的解压过程
f:表示指定要解压的文件
解压完成后,解压出来的文件会放在当前目录下。如果要将解压出来的文件放在其他目录,可以在命令中使用 -C 选项指定目录,例如:
tar -xzvf kafka_2.13-3.5.0.tgz -C /home/kafka
这样就可以将解压出来的文件放在 /home/kafka 目录下。
第4步:因为解压后,多了一层目录【mv kafka_2.13-3.5.0】,所以要移动目录
mv kafka_2.13-3.5.0/* ./
然后删除空目录
rmdir kafka_2.13-3.5.0
第3步:配置kafka,打开kafka配置文件
vim /home/kafka/config/server.properties
修改一下配置,注释掉的要打开注释,删除掉#
socket服务端地址
listeners=PLAINTEXT://【本机IP自行替换】:9092
侦听器名称、主机名和端口代理将通知给客户端。
advertised.listeners=PLAINTEXT:// 【本机IP自行替换】:9092
日志文件路径
log.dirs=/home/kafka_data/logs
zookeeper地址,zookeeper是用来监听kafka源数据变化
zookeeper.connect=【本机IP自行替换】:2181
第4步:创建日志的文件夹,如果有就不用创建了
mkdir -p /home/kafka_data/logs
-p 是创建多级目录
4.4 安装docker
sudo是一个用于在Linux系统上获得超级用户权限的命令。它允许普通用户以超级用户身份执行特权命令。
第1步:安装yum-utils,yum-utils是yum的一个附加软件包,提供了一些额外的功能和工具。
sudo yum install -y yum-utils
执行结果示例

第2步:添加存储库的地址
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
执行结果示例

第3步:安装docker相关程序
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
docker-ce是Docker的主要软件包,包含了Docker的核心功能;
docker-ce-cli是Docker的命令行界面工具;
containerd.io是Docker的底层容器运行时,负责管理容器的生命周期;
docker-buildx-plugin是Docker的多平台构建插件,可以跨多种平台构建容器镜像;
docker-compose-plugin是Docker的应用程序容器编排工具,可以快速构建、启动和管理多个Docker容器应用。
执行结果示例
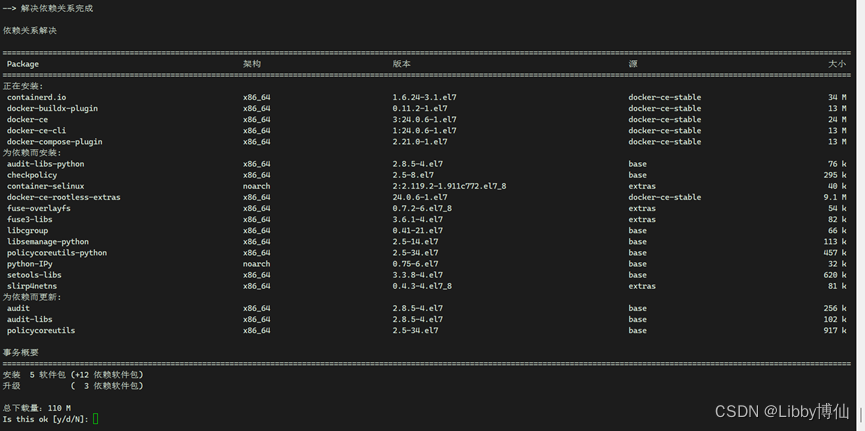
输入y继续
输入y继续

安装完成!!!
第4步:配置docker
vi /etc/docker/daemon.json
添加配置项文件
{
"registry-mirrors": ["https://5twf62k1.mirror.aliyuncs.com"],
"insecure-registries": ["sinoeyes.io","hub.sinoeyes.com"]
}
按键esc切换命令模式,输入:wq退出保存,保存后会生成文件
registry-mirrors属性用于指定Docker镜像的加速器地址。由于Docker镜像可能分布在全球不同的地方,而各地的网络环境和速度也不同,因此使用镜像加速器可以显著提高拉取镜像的速度和稳定性。例如,将registry-mirrors属性设置为http://f1361db2.m.daocloud.io即可使用DaoCloud镜像加速器。
insecure-registries属性用于指定Docker容器镜像的非安全注册表地址。如果您使用的是私有Docker注册表,并且此注册表的TLS证书未经过验证或过期,则可以添加该注册表的URL以允许使用不安全的HTTP协议进行拉取和推送镜像。例如,将insecure-registries属性设置为["myregistry.example.com:5000"]即可允许使用不安全的HTTP协议访问myregistry.example.com:5000注册表。
第5步:输入ls查看是否有文件生成
CD /etc/docker/
Ls
执行结果示例
第6步:docker-compose部署,使用curl工具下载Docker Compose程序,并将其保存到/usr/local/bin/docker-compose路径下。
curl -L https://github.com/docker/compose/releases/download/1.21.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
执行结果示例

这里我因网络原因,下载失败,如果命令正常执行,不用进行第6步的后续。
手动上传文件到目录下,将docker-compose里面的文件全部上传到这个路径下【/usr/local/bin】。

第7步:该命令的作用就是将/usr/local/bin/docker-compose文件的权限设置为可执行权限,以便用户可以直接运行这个文件并使用Docker Compose的功能。
chmod +x /usr/local/bin/docker-compose
第8步:检查Docker Compose是否安装成功
docker-compose -v
执行结果示例

4.5 运行kafka
第1步:新建目录
mkdir -p /home/app/maxwell/conf
第2步:在/home/app/maxwell下创建文件docker-compose.yml
vim docker-compose.yml
按键I进入编辑模式输入以下文件内容
version: '3.5'
services:
maxwell:
restart: always
image: zendesk/maxwell
container_name: maxwell
network_mode: "host"
command: bin/maxwell --config /etc/maxwell/config.properties
#command: bin/maxwell-bootstrap --config /etc/maxwell/config.properties
volumes:
- ./conf:/etc/maxwell/
environment:
- "TZ=Asia/Shanghai"
按键esc切换命令模式,输入:wq退出保存,保存后会生成文件
maxwell容器的编排文件,以后启动maxwell时更方便
第3步:在/home/app/maxwell/conf下创建文件config.properties
vim config.properties
按键I进入编辑模式,输入以下内容,根据情况替换信息,关键信息红色标出
daemon=true
# 第一次启动时建议改为debug,可以开到mysql数据与kafka请求,稳定后再改为info
#log_level=info
log_level=info
producer=kafka
kafka.bootstrap.servers=【本机IP自行替换】:9092
# 会往 kafka下主题为'test'的分区下推送数据
kafka_topic=maxwell
#当producer_partition_by设置为table时,Maxwell会将生成的消息根据表名称进行分区,不同的表将会被分配到不同的分区中,默认为database
producer_partition_by=table
# client_id=maxwell_1
client_id=sddi-consumer-group-1-client-1
# mysql login info 需要先在mysql创建maxwell用户
host=【目标源数据库IP】
# port=33066
port=3306
user=【数据库账号】
password=【数据库密码】
schema_database=maxwell
replication_host=【目标源数据库IP】
replication_user=【数据库账号】
replication_password=【数据库密码】
replication_port=3306
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
# exclude_dbs=*
# 同步的数据表
include_dbs=【sddi 数据库名】
inlcude_tables=【sddi.b_missfile_info,sddi.b_pharm_info, e,sddi.f_pbt_file,同步的表,逗号隔开】
#inlcude_tables=sddi.b_missfile_info,sddi.b_pharm_info
~
按键esc切换命令模式,输入:wq退出保存,保存后会生成文件
第4步:启动docker
systemctl start docker
第5步:启动zookeeper,以守护线程的方式,这个是kafka集成的消息队列
bin/zookeeper-server-start.sh -daemon /home/kafka/config/zookeeper.properties
如果出现错误,没有那个文件或目录,则进行一下操作

先把zookeeper-server-start.sh添加到环境变量
echo "export PATH=$PATH:/home/kafka/bin" >> /root/.bash_profile
source /root/.bash_profile
然后执行zookeeper命令
zookeeper-server-start.sh -daemon /home/kafka/config/zookeeper.properties
第6步:启动kafka,以守护线程的方式
kafka-server-start.sh -daemon /home/kafka/config/server.properties
第7步:在 Kafka 中创建一个名为 maxwell 的新主题(Topic)
kafka-topics.sh --bootstrap-server 192.168.180.31:9092 --create --topic maxwell
第8步:启动maxwell
cd /home/app/maxwell
因为第1步和第2步创建了配置文件,所以这里可以省略很多参数,直接启动maxwell
docker-compose up -d
执行结果示例
第9步:查看docker的maxwell容器
列出所有容器
docker ps
查询指定容器的日志
docker logs --tail 100 -f 51b978d72157
第10步:查看maxwell的下发消息(数据量大慎用)
kafka-console-consumer.sh --topic maxwell --from-beginning --bootstrap-server 192.168.180.31:9092
5.0 后期运维
查询所有的消费组
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --list
查看某个消费组的消费情况
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --describe --group sddi-consumer-group-1

属性介绍
| 列头 | 实例值 | 描述 |
| GROUP | sddi-consumer-group-1 | 消费者组的名称 |
| TOPIC | maxwell | 所订阅的主题。 |
| PARTITION | 0 | 主题的分区编号。 |
| CURRENT-OFFSET | 666520 | 消费者当前的偏移量(已经消费到的消息的偏移量)。 |
| LOG-END-OFFSET | 698913 | 当前分区日志的最新偏移量(该分区中的消息总数)。 |
| LAG | 32393 | 当前落后的偏移量数量(LAG = LOG-END-OFFSET - CURRENT-OFFSET),表示消费者还未消费的消息数量。 |
| CONSUMER-ID | sddi-consumer-group-1-client-1-8cc14037-bf1c-43eb-8094-2c4e45e5cc04 | 消费者的唯一标识符。 |
| HOST | /192.168.180.18 | 消费者所在的主机名。 |
| CLIENT-ID | sddi-consumer-group-1-client-1 | 消费者的客户端标识符。 |
这些信息对于监控和管理 Kafka 消费者组以及消费状态非常有用。可以根据需要使用不同的选项来查看和管理消费者组的状态。
初始化maxwell 测试环境 命令是单个表初始化同步
docker run -it --network host --rm zendesk/maxwell bin/maxwell-bootstrap --user=maxwell --password=rPq60r4BUA19@ --host=192.168.17.22 -database sddi --table b_business_info --client_id=sddi-consumer-group-1-client-1
停止maxwell (只是记录命令,可以不执行)
cd /home/app/maxwell
docker-compose down
停止kafka
kafka-server-stop.sh
停止zookeeper
zookeeper-server-stop.sh
查看容器的配置
docker inspect maxwell
查看主题列表
kafka-topics.sh --list --bootstrap-server 192.168.180.31:9092
创建主题
kafka-topics.sh --bootstrap-server 192.168.180.31:9092 --create --topic maxwell --replication-factor 1 --partitions 3
查看主题信息
kafka-topics.sh --bootstrap-server 192.168.180.31:9092 --describe --topic maxwell
使用生产者发送消息
kafka-console-producer.sh --broker-list 192.168.180.31:9092 --topic maxwell
使用消息者接受消息(从起始位置开始查看)
kafka-console-consumer.sh --bootstrap-server 192.168.180.31:9092 --topic maxwell --from-beginning
使用消息者接受消息(从当前位置开始查看)
kafka-console-consumer.sh --bootstrap-server 192.168.180.31:9092 --topic maxwell
查看kafka的所有消费组
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --list
查看kafka日志
tail -10000f /home/kafka/logs/server.log
查看zookeeper日志
tail -1000f /home/kafka/logs/zookeeper.out
查看maxwell日志
cd /home/app/maxwell
docker-compose logs -f --tail 100
Earliest 策略直接指定**–to-earliest**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --all-topics --to-earliest –execute
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --topics maxwell --to-earliest –execute
Latest 策略直接指定**–to-latest**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --all-topics --to-latest --execute
Current 策略直接指定**–to-current**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --all-topics --to-current --execute
Specified-Offset 策略直接指定**–to-offset**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --all-topics --to-offset 51691 --execute
Shift-By-N 策略直接指定**–shift-by N**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --topic maxwell --shift-by 1 --execute
DateTime 策略直接指定**–to-datetime**。
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --to-datetime 2019-06-20T20:00:00.000 --execute
最后是实现 Duration 策略,我们直接指定**–by-duration**
kafka-consumer-groups.sh --bootstrap-server 192.168.180.31:9092 --group sddi-consumer-group-1 --reset-offsets --by-duration PT0H30M0S --execute
Earliest 策略表示将位移调整到主题当前最早位移处。这个最早位移不一定就是 0,因为在生产环境中,很久远的消息会被 Kafka 自动删除,所以当前最早位移很可能是一个大于 0 的值。如果你想要重新消费主题的所有消息,那么可以使用 Earliest 策略。
Latest 策略表示把位移重设成最新末端位移。如果你总共向某个主题发送了 15 条消息,那么最新末端位移就是 15。如果你想跳过所有历史消息,打算从最新的消息处开始消费的话,可以使用 Latest 策略。
Current 策略表示将位移调整成消费者当前提交的最新位移。有时候你可能会碰到这样的场景:你修改了消费者程序代码,并重启了消费者,结果发现代码有问题,你需要回滚之前的代码变更,同时也要把位移重设到消费者重启时的位置,那么,Current 策略就可以帮你实现这个功能。
表中第 4 行的 Specified-Offset 策略则是比较通用的策略,表示消费者把位移值调整到你指定的位移处。这个策略的典型使用场景是,消费者程序在处理某条错误消息时,你可以手动地“跳过”此消息的处理。在实际使用过程中,可能会出现 corrupted 消息无法被消费的情形,此时消费者程序会抛出异常,无法继续工作。一旦碰到这个问题,你就可以尝试使用 Specified-Offset 策略来规避。
如果说 Specified-Offset 策略要求你指定位移的绝对数值的话,那么 Shift-By-N 策略指定的就是位移的相对数值,即你给出要跳过的一段消息的距离即可。这里的“跳”是双向的,你既可以向前“跳”,也可以向后“跳”。比如,你想把位移重设成当前位移的前 100 条位移处,此时你需要指定 N 为 -100。
刚刚讲到的这几种策略都是位移维度的,下面我们来聊聊从时间维度重设位移的 DateTime 和 Duration 策略。
DateTime 允许你指定一个时间,然后将位移重置到该时间之后的最早位移处。常见的使用场景是,你想重新消费昨天的数据,那么你可以使用该策略重设位移到昨天 0 点。
Duration 策略则是指给定相对的时间间隔,然后将位移调整到距离当前给定时间间隔的位移处,具体格式是 PnDTnHnMnS。如果你熟悉 Java 8 引入的 Duration 类的话,你应该不会对这个格式感到陌生。它就是一个符合 ISO-8601 规范的 Duration 格式,以字母 P 开头,后面由 4 部分组成,即 D、H、M 和 S,分别表示天、小时、分钟和秒。举个例子,如果你想将位移调回到 15 分钟前,那么你就可以指定 PT0H15M0S。
6.0 消费者系统
我们这里采用的是.net平台的c#语言,编写了windows server程序,来处理队列数据
使用的类库是Confluent.Kafka
6.1 Confluent.Kafka
Confluent.Kafka是一个流行的开源Kafka客户端库,它提供了在.NET应用程序中与Apache Kafka进行交互的功能。下面是对Confluent.Kafka类库的介绍:
高级API:Confluent.Kafka为开发人员提供了一组简单易用的高级API,用于连接到Kafka集群、读取和写入消息、管理消费者组等。你可以方便地使用它来发送消息到Kafka主题或从主题中消费消息。
完全支持Kafka协议:Confluent.Kafka完全支持Kafka协议,包括Kafka 1.0.0及更高版本。它与最新的Kafka版本保持同步,并提供了一致性和稳定性。
高性能:Confluent.Kafka经过优化,具有出色的性能表现。它采用了异步、无锁的设计,支持高并发的消息处理。
配置灵活:Confluent.Kafka提供了丰富的配置选项,可以根据实际需求进行调整。你可以配置消息的传递语义、消费者的批量读取、消息序列化和反序列化方式等。
支持消息引擎扩展:Confluent.Kafka还支持通过插件机制扩展消息引擎,例如支持Avro、Protobuf等消息格式的插件。
社区活跃:Confluent.Kafka是一个受欢迎且活跃的开源项目,拥有强大的社区支持。你可以在社区中获得帮助、提出问题或提交改进建议。
总之,Confluent.Kafka是一个功能强大、性能优越的Kafka客户端库,为.NET开发人员提供了与Apache Kafka无缝集成的能力,使他们能够轻松地构建可靠的消息流应用程序。
6.2 相关连接
https://github.com/confluentinc/confluent-kafka-dotnet/
http://www.bilibili996.com/Course?id=1159444000368
https://zhuanlan.zhihu.com/p/139101754?utm_id=0
相关文章:
kafka的安装,用于数据库同步数据
1.0 背景调研 因业务需求,需要查询其他部门的数据库数据,不方便直连数据库,所以要定时将他们的数据同步到我们的环境中,技术选型选中了kafkaCDC Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久…...

Bean 的作用域你知道么 ?
Bean 的作用域有哪些? 所谓的作用域,其实就是说这个东西在哪个范围内可以被使用 , 如我们定义类的成员变量的时候使用的public,private等这些也是作用域的概念 Spring的Bean的作用域, 描述的就是这个Bean在哪个范围内可以被使用. 不同的作用域决定了Bean的创建, 管理和销毁的…...
Windows 使设置更改立即生效——并行发送广播消息
目录 前言 1 遍历窗口句柄列表 2 使用 SendMessageTimeout 发送延时消息 3 并行发送消息实现模拟广播消息 4 修改 UIPI 消息过滤器设置 5 托盘图标刷新的处理 6 完整代码和测试 本文属于原创文章,转载请注明出处: https://blog.csdn.net/qq_5907…...
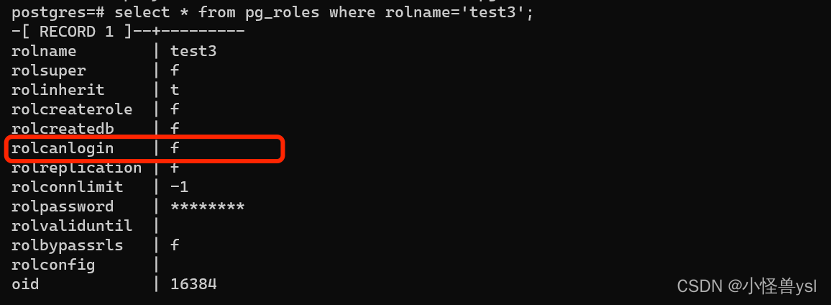
PostgreSQL使用session_exec和file_fdw实现失败次数锁定用户策略
使用session_exec 、file_fdw以及自定义函数实现该功能。 缺陷:实测发现锁用户后,进去解锁特定用户。只能允许一次登陆,应该再次登陆的时候,触发函数,把之前的日志里的错误登陆的信息也计算到登录次数里了。而且foreig…...
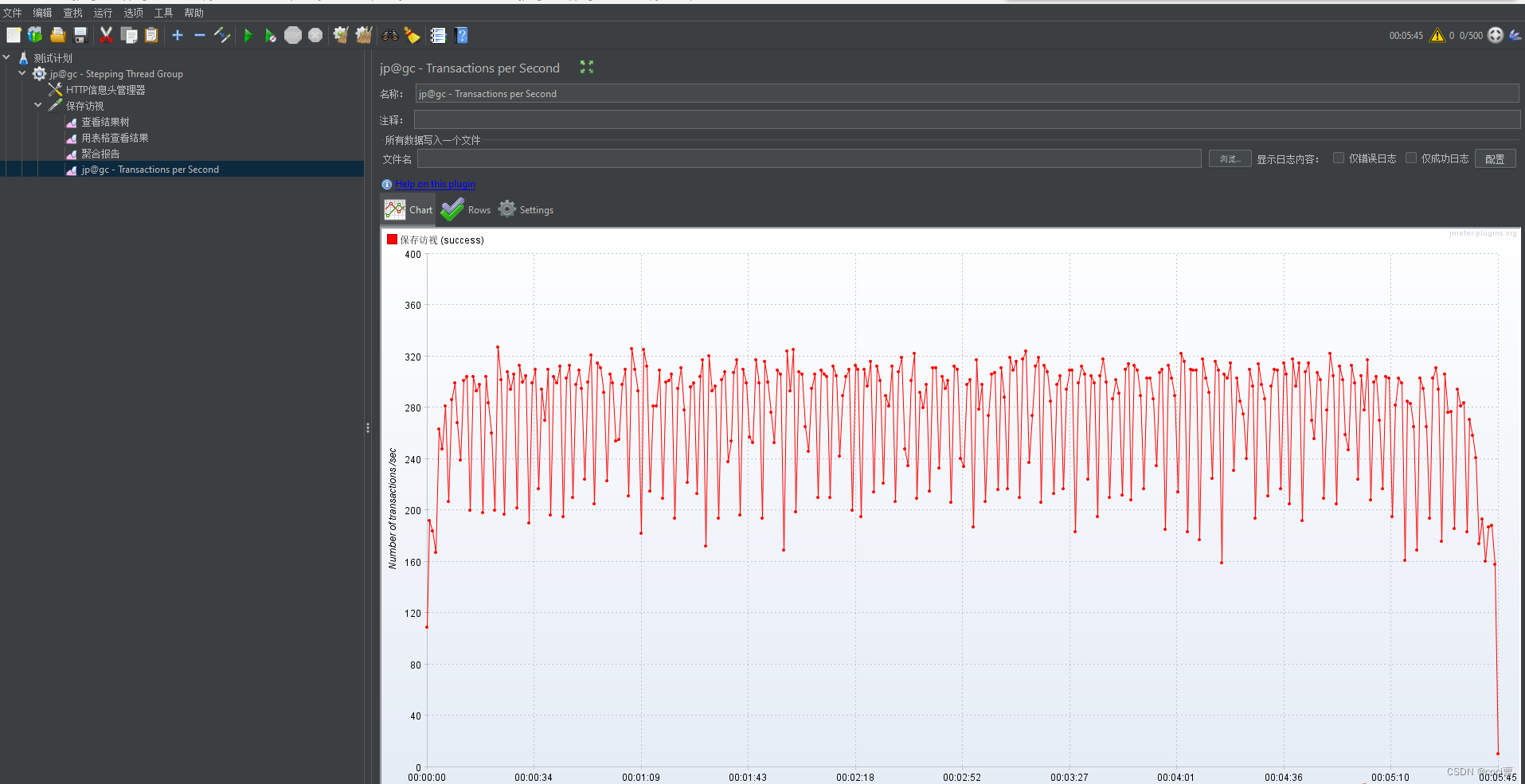
Jmeter实现阶梯式线程增加的压测
安装相应jmeter 插件 1:安装jmeter 管理插件: 下载地址:https://jmeter-plugins.org/install/Install/,将下载下来的jar包放到jmeter文件夹下的lib/ext路径下,然后重启jmeter。 2:接着打开 选项-Plugins Ma…...

Linux----防火墙之保存规则
一、关于iptables规则的保存 之前写的iptables的设置,但是都是临时生效的,一旦电脑重启,那么就会失效,如何永久保存,需要借助iptables-save命令,开机生效需要借助iptables-restore命令,并写入规…...

spring-orm:6 HibernateJpaVendorAdapter源码解析
版本 spring-orm:6.1.3 源码 org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter public class HibernateJpaVendorAdapter extends AbstractJpaVendorAdapter {// 旧版本Hibernate的方言类是否存在标识private static final boolean oldDialectsPresent Clas…...

php捕获Fatal error错误与异常处理
在php5的版本中,如果出现致命错误是无法被 try {} catch 捕获的,如下所示: <?phperror_reporting(E_ALL); ini_set(display_errors, on);try {hello(); } catch (\Exception $e) {echo $e->getMessage(); } 运行脚本,最终…...

PyCharm 调试过程中控制台 (Console) 窗口内运行命令 - 实时获取中间状态
PyCharm 调试过程中控制台 [Console] 窗口内运行命令 - 实时获取中间状态 1. yongqiang.py2. Debugger -> Console3. Show Python PromptReferences 1. yongqiang.py #!/usr/bin/env python # -*- coding: utf-8 -*- # yongqiang chengfrom __future__ import absolute_imp…...

MacBook Pro如何安装rust编程环境
安装过程分为以下几步: 1. 安装Homebrew。Homebrew是一个流行的MacOS的包管理器,可用于方便地安装各种软件。打开终端,运行以下命令: /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD…...
)
SparkUI任务启动参数介绍(148个参数)
文章目录 SparkUI任务启动参数介绍(148个参数)1 spark.app.id: Spark 应用程序的唯一标识符。2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。3 spark.app.name: Spark 应用程序的名称。4 spark.app.startTime: Spark 应用程序的启动…...

nginx 安装
Nginx 简介 nginx一种十分轻量级的http服务器一种高性能的HTTP和反向代理服务器,同时是一个IMAP/POP3/SMTP 代理服务器其中官网网站 安装Nginx 使用源码编辑安装 #提前安装相关工具软件包 yum -y install net-tools tar unzip gcc make pcre-devel openssl-devel httpd-too…...
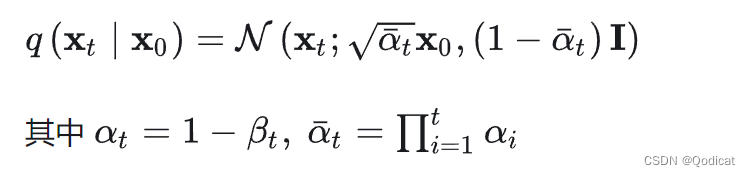
手撕扩散模型(一)| 训练部分——前向扩散,反向预测代码全解析
文章目录 1 直接使用 核心代码2 工程代码实现2.1 DDPM2.2 训练 三大模型VAE,GAN, DIffusion扩散模型 是生成界的重要模型,但是最近一段时间扩散模型被用到的越来越多的,最近爆火的OpenAI的 Sora文生视频模型其实也是用了这种的方…...

linux 防火墙
防火墙分类 按保护范围划分 主机防火墙:服务服务为当前一台主机 网络防火墙:服务服务为防火墙一侧的局域网 按实现方式分类划分 硬件防火墙:在专用硬件级别实现部分功能的防火墙;另一部分基于软件的实现 如:华为&#…...
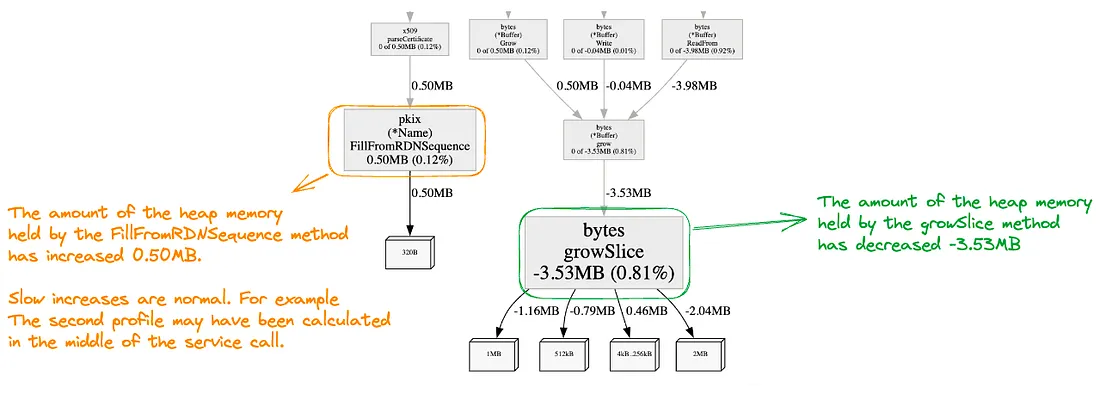
Go应用性能分析实战
Go很适合用来开发高性能网络应用,但仍然需要借助有效的工具进行性能分析,优化代码逻辑。本文介绍了如何通过go test benchmark和pprof进行性能分析,从而实现最优的代码效能。原文: Profiling Go Applications in the Right Way with Examples…...

MySQL的索引类型
目录 1. 主键索引 (PRIMARY KEY) 2. 唯一索引 (UNIQUE) 3. 普通索引 (INDEX) 4. 全文索引 (FULLTEXT) 5. 空间索引 (SPATIAL) 6. 组合索引 (COMPOSITE INDEX) 7. 前缀索引 (PREFIX INDEX) 8. 覆盖索引 (COVERING INDEX) 1. 主键索引 (PRIMARY KEY) 描述:表…...

picker选择器-年月日选择
从底部弹起的滚动选择器。支持五种选择器,通过mode来区分,分别是普通选择器,多列选择器,时间选择器,日期选择器,省市区选择器,默认是普通选择器。 学习一下日期选择器 平台差异说明 日期选择默…...
)
【LeetCode-494】目标和(回溯动归)
目录 LeetCode494.目标和 题目描述 解法1:回溯法 代码实现 解法2:动态规划 代码实现 LeetCode494.目标和 题目链接 题目描述 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 和 -。对于数组中…...

力扣 188. 买卖股票的最佳时机 IV
题目来源:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iv/description/ C题解:动态规划 思路同力扣 123. 买卖股票的最佳时机 III-CSDN博客,只是把最高2次换成k次。如果思路不清晰,可以将k从0写到4等找找规律…...

【Go语言】Go项目工程管理
GO 项目工程管理(Go Modules) Go 1.11 版本开始,官方提供了 Go Modules 进行项目管理,Go 1.13开始,Go项目默认使用 Go Modules 进行项目管理。 使用 Go Modules的好处是不再需要依赖 GOPATH,可以在任意位…...

终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破
终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破 【免费下载链接】TexasSolver 🚀 A very efficient Texas Holdem GTO solver :spades::hearts::clubs::diamonds: 项目地址: https://gitcode.com/gh_mirrors/te/TexasSolver …...

哪个工具能降重降AI?亲测知网维普aigc检测效果,重复率和ai率不到10%!
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

MultiHighlight智能高亮插件架构解析与性能优化实践
MultiHighlight智能高亮插件架构解析与性能优化实践 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight 在复杂的代码阅读场景…...
)
终极指南:如何快速构建中文手写识别AI系统(免费数据集)
终极指南:如何快速构建中文手写识别AI系统(免费数据集) 【免费下载链接】Traditional-Chinese-Handwriting-Dataset Open source traditional chinese handwriting dataset. 项目地址: https://gitcode.com/gh_mirrors/tr/Traditional-Chin…...
)
Lovable前端不是UI美化,而是工程决策——看头部电商如何用2周将NPS提升37%(含埋点与归因模型)
更多请点击: https://kaifayun.com 第一章:Lovable前端开发实战案例 在现代前端工程中,“Lovable”不仅指界面美观、交互愉悦,更强调可维护性、可测试性与开发者体验的统一。本章通过一个轻量级待办事项(Todo…...

Wot Design Uni 文件上传组件:如何实现异步上传的强大功能
Wot Design Uni 文件上传组件:如何实现异步上传的强大功能 【免费下载链接】wot-design-uni 一个基于Vue3TS开发的uni-app组件库,提供70高质量组件,支持暗黑模式、国际化和自定义主题。 项目地址: https://gitcode.com/gh_mirrors/wo/wot-d…...

李力/张明亮/周雍进等合作Nat Com | 山梨酸的高效异源生物合成
近日,福建师范大学李力教授团队与中国科学院大连化学物理研究所周雍进合作在天然产物生物合成与合成生物学领域取得重要突破,相关研究成果以“Toward sustainable food preservatives: high-level production of sorbic acid in engineered Saccharomyce…...

基准测试结果刚出炉,DeepSeek在医疗/法律/金融三大垂直领域事实准确率对比,谁在说真话?
更多请点击: https://intelliparadigm.com 第一章:基准测试结果刚出炉,DeepSeek在医疗/法律/金融三大垂直领域事实准确率对比,谁在说真话? 我们基于权威垂直领域评测集——MedMCQA(医疗)、Case…...

对比直接使用官方api与通过taotoken接入后的网络连接稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 与通过 Taotoken 接入后的网络连接稳定性体验 1. 引言 在开发基于大语言模型的应用程序时,一个…...

知识产权管理中的流程自动化:从人工操作到系统智能
企业知识产权部门日常工作中,最耗费时间的往往不是策略制定,而是重复性的事务处理:收到官方来文后手动解压、分类、重命名、上传到对应案件;收到审查意见后人工计算答复期限并设置提醒;案件状态变化后逐个更新Excel记录…...