SparkUI任务启动参数介绍(148个参数)
文章目录
- SparkUI任务启动参数介绍(148个参数)
- 1 spark.app.id: Spark 应用程序的唯一标识符。
- 2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。
- 3 spark.app.name: Spark 应用程序的名称。
- 4 spark.app.startTime: Spark 应用程序的启动时间。
- 5 spark.app.submitTime: Spark 应用程序的提交时间。
- 6 spark.blacklist.enabled: 是否启用黑名单机制,用于阻止执行失败的节点。
- 7 spark.buffer.size: 用于 IO 缓冲的大小。
- 8 spark.cleaner.periodicGC.interval: 周期性垃圾回收清理器的间隔。
- 9 spark.driver.appUIAddress: Driver 进程的 UI 地址。
- 10 spark.driver.extraJavaOptions: Driver 进程的额外 Java 选项。
- 11 spark.driver.host: Driver 进程的主机名。
- 12 spark.driver.maxResultSize: Driver 进程可以接收的最大结果大小。
- 13 spark.driver.memory: Driver 进程的内存大小。
- 14 spark.driver.port: Driver 进程的端口号。
- 15 spark.dynamicAllocation.enabled: 是否启用动态资源分配。
- 16 spark.dynamicAllocation.executorIdleTimeout: Executor 空闲超时时
- 17 spark.dynamicAllocation.initialExecutors: 初始 Executor 数量。
- 18 spark.dynamicAllocation.maxExecutors: 最大 Executor 数量。
- 19 spark.dynamicAllocation.minExecutors: 最小 Executor 数量。
- 20 spark.eventLog.compress: 是否压缩事件日志。
- 21 spark.eventLog.dir: 事件日志目录。
- 22 spark.eventLog.enabled: 是否启用事件日志。
- 23 spark.executor.cores: 每个 Executor 的 CPU 核心数。
- 24 spark.executor.extraJavaOptions: 每个 Executor 的额外 Java 选项。
- 25 spark.executor.id: Executor 的唯一标识符。
- 26 spark.executor.instances: Executor 的实例数量。
- 27 spark.executor.memory: 每个 Executor 的内存大小。
- 28 spark.executor.memoryOverhead: 每个 Executor 的内存 overhead。
- 29 spark.extraListeners: 额外的监听器。
- 30 spark.files.ignoreCorruptFiles: 是否忽略损坏的文件。
- 31 spark.hadoop.fs.file.impl.disable.cache: 是否禁用文件系统的缓存。
- 32 spark.hadoop.fs.hdfs.impl.disable.cache: 是否禁用 HDFS 的缓存。
- 33 spark.hadoop.mapreduce.input.fileinputformat.list-status.num-threads: 文件输入格式的线程数。
- 34 spark.hadoopRDD.ignoreEmptySplits: 是否忽略空分片。
- 35 spark.history.fs.cleaner.enabled: 是否启用历史文件系统清理器。
- 36 spark.history.fs.cleaner.interval: 历史文件系统清理器的清理间隔。
- 37 spark.history.fs.cleaner.maxAge: 历史文件系统清理器的最大年龄。
- 38 spark.history.fs.update.interval: 历史文件系统更新间隔。
- 39 spark.history.kerberos.enabled: 是否启用 Kerberos 认证。
- 40 spark.history.provider: 历史记录提供程序。
- 41 spark.history.retainedApplications: 保留的历史应用程序数量。
- 42 spark.history.store.maxDiskUsage: 历史存储的最大磁盘使用量。
- 43 spark.history.ui.maxApplications: 历史 UI 的最大应用程序数量。
- 44 spark.hive.server2.proxy.user: Hive Server2 代理用户。
- 45 spark.jars: Spark 应用程序所需的 Jar 包。
- 46 spark.kerberos.access.hadoopFileSystems: Kerberos 访问 Hadoop 文件系统。
- 47 spark.kryoserializer.buffer.max: Kryo 序列化器的最大缓冲区大小。
- 48 spark.kyuubi.client.ipAddress: Kyuubi 客户端的 IP 地址。
- 49 spark.kyuubi.engine.credentials: Kyuubi 引擎的凭证。
- 50 spark.kyuubi.engine.share.level: Kyuubi 引擎共享级别。
- 51 spark.kyuubi.engine.share.level.subdomain: Kyuubi 引擎共享级别子域。
- 52 spark.kyuubi.engine.submit.time: Kyuubi 引擎提交时间。
- 53 spark.kyuubi.ha.engine.ref.id: Kyuubi HA 引擎引用 ID。
- 54 spark.kyuubi.ha.namespace: Kyuubi HA 命名空间。
- 55 spark.kyuubi.ha.zookeeper.auth.keytab: Kyuubi HA ZooKeeper 认证 keytab。
- 56 spark.kyuubi.ha.zookeeper.auth.principal: Kyuubi HA ZooKeeper 认证 principal。
- 57 spark.kyuubi.ha.zookeeper.auth.type: Kyuubi HA ZooKeeper 认证类型。
- 58 spark.kyuubi.ha.zookeeper.namespace: Kyuubi HA ZooKeeper 命名空间。
- 59 spark.kyuubi.ha.zookeeper.quorum: Kyuubi HA ZooKeeper quorum。
- 60 spark.kyuubi.operation.result.max.rows: Kyuubi 操作结果的最大行数。
- 61 spark.kyuubi.session.engine.idle.timeout: Kyuubi 会话引擎空闲超时时间。
- 62 spark.locality.wait: 本地性等待时间。
- 63 spark.locality.wait.node: 节点本地性等待时间。
- 64 spark.locality.wait.process: 进程本地性等待时间。
- 65 spark.locality.wait.rack: 机架本地性等待时间。
- 66 spark.master: Spark Master 地址。
- 67 spark.maxRemoteBlockSizeFetchToMem: 最大远程块大小从磁盘到内存。
- 68 spark.network.timeout: 网络超时时间。
- 69 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_HOSTS: YARN Web 代理参数。
- 70 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES: YARN Web 代理 URI 基础路径。
- 71 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.RM_HA_URLS: YARN Web 代理 RM HA URLs。
- 72 spark.redaction.regex: 日志内容的正则表达式,用于数据遮蔽。
- 73 spark.reducer.maxBlocksInFlightPerAddress: 每个地址的最大块数。
- 74 spark.reducer.maxReqsInFlight: 最大并行请求数。
- 75 spark.repl.class.outputDir: REPL 类的输出目录。
- 76 spark.repl.class.uri: REPL 类的 URI。
- 77 spark.rpc.askTimeout: RPC 询问超时时间。
- 78 spark.scheduler.mode: Spark 调度模式。
- 79 spark.serializer: 序列化器。
- 80 spark.shuffle.detectCorrupt.useExtraMemory: 是否使用额外内存检测 Shuffle 数据的损坏。
- 81 spark.shuffle.file.buffer: Shuffle 文件的缓冲区大小。
- 82 spark.shuffle.io.maxRetries: Shuffle IO 的最大重试次数。
- 83 spark.shuffle.io.preferDirectBufs: 是否优先使用直接缓冲区。
- 84 spark.shuffle.io.retryWait: Shuffle IO 重试等待时间。
- 85 spark.shuffle.mapOutput.parallelAggregationThreshold: 并行聚合阈值。
- 86 spark.shuffle.readHostLocalDisk: 是否从本地磁盘读取 Shuffle 数据。
- 87 spark.shuffle.registration.maxAttempts: Shuffle 注册的最大尝试次数。
- 88 spark.shuffle.registration.timeout: Shuffle 注册的超时时间。
- 89 spark.shuffle.service.enabled: 是否启用 Shuffle 服务。
- 90 spark.shuffle.spill.diskWriteBufferSize: Shuffle Spill 磁盘写缓冲区大小。
- 91 spark.shuffle.unsafe.file.output.buffer: 不安全 Shuffle 文件输出缓冲区大小。
- 92 spark.shuffle.useOldFetchProtocol: 是否使用旧的 Fetch 协议。
- 93 spark.speculation: 是否启用任务推测执行。
- 94 spark.speculation.interval: 任务推测执行的间隔。
- 95 spark.speculation.multiplier: 任务推测执行的倍数。
- 96 spark.speculation.quantile: 任务推测执行的分位数。
- 97 spark.speculation.task.duration.threshold: 任务推测执行的持续时间阈值。
- 98 spark.sql.access.authorization.enable: 是否启用 SQL 访问授权。
- 99 spark.sql.access.iceberg.enable: 是否启用 Iceberg 表的 SQL 访问。
- 100 spark.sql.adaptive.advisoryPartitionSizeInBytes: 自适应执行中分区大小的建议值。
- 101 spark.sql.adaptive.autoBroadcastJoinThreshold: 自适应执行中自动广播连接的阈值。
- 102 spark.sql.adaptive.enabled: 是否启用自适应执行。
- 103 spark.sql.adaptive.fetchShuffleBlocksInBatch: 自适应执行中每批次获取 Shuffle 块的数量。
- 104 spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold: 自适应执行中本地 Map 阈值。
- 105 spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin: 自适应执行中非空分区比例的广播连接阈值。
- 106 spark.sql.adaptive.skewJoin.enabled: 自适应执行中是否启用倾斜连接。
- 107 spark.sql.adaptive.skewJoin.skewedPartitionFactor: 自适应执行中倾斜连接的分区因子。
- 108 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: 自适应执行中倾斜连接的分区阈值。
- 109 spark.sql.autoBroadcastJoinThreshold: 自动广播连接的阈值。
- 110 spark.sql.broadcastTimeout: 广播连接的超时时间。
- 111 spark.sql.catalog.hive_catalog: Hive Catalog 名称。
- 112 spark.sql.catalog.hive_catalog.type: Hive Catalog 类型。
- 113 spark.sql.catalog.hive_catalog.url: Hive Catalog URL。
- 114 spark.sql.catalog.spark_catalog: Spark Catalog 名称。
- 115 spark.sql.catalog.spark_catalog.type: Spark Catalog 类型。
- 116 spark.sql.catalogImplementation: SQL Catalog 实现。
- 117 spark.sql.crossJoin.enabled: 是否启用跨连接。
- 118 spark.sql.execution.topKSortFallbackThreshold: 执行中 Top-K 排序的阈值。
- 119 spark.sql.extensions: SQL 扩展。
- 120 spark.sql.files.ignoreCorruptFiles: 是否忽略损坏的文件。
- 121 spark.sql.files.ignoreMissingFiles: 是否忽略缺失的文件。
- 122 spark.sql.finalStage.adaptive.advisoryPartitionSizeInBytes: 最终阶段执行中分区大小的建议值。
- 123 spark.sql.finalStage.adaptive.coalescePartitions.minPartitionNum: 最终阶段执行中合并分区的最小分区数。
- 124 spark.sql.finalStage.adaptive.skewJoin.skewedPartitionFactor: 最终阶段执行中倾斜连接的分区因子。
- 125 spark.sql.finalStage.adaptive.skewJoin.skewedPartitionThresholdInBytes: 最终阶段执行中倾斜连接的分区阈值。
- 126 spark.sql.hive.convertInsertingPartitionedTable: Hive 表插入分区的转换。
- 127 spark.sql.hive.verifyPartitionPath: Hive 表分区路径验证。
- 128 spark.sql.legacy.castComplexTypesToString.enabled: 是否启用将复杂类型强制转换为字符串的遗留行为。
- 129 spark.sql.legacy.setCommandRejectsSparkCoreConfs: 是否拒绝设置 Spark Core 配置的遗留 set 命令。
- 130 spark.sql.legacy.timeParserPolicy: 时间解析策略。
- 131 spark.sql.optimizer.finalStageConfigIsolation.enabled: 是否启用最终阶段配置隔离。
- 132 spark.sql.parquet.recordLevelFilter.enabled: 是否启用 Parquet 记录级别过滤。
- 133 spark.sql.queryExecutionListeners: 查询执行监听器。
- 134 spark.sql.runSQLOnFiles: 是否在文件上运行 SQL 查询。
- 135 spark.sql.shuffle.partitions: Shuffle 阶段的分区数。
- 136 spark.sql.statistics.fallBackToHdfs: 是否回退到 HDFS 统计信息。
- 137 spark.sql.storeAssignmentPolicy: 存储分配策略。
- 138 spark.submit.deployMode: Spark 应用程序的部署模式。
- 139 spark.submit.pyFiles: 提交给 Spark 应用程序的 Python 文件。
- 140 spark.ui.filters: Spark UI 的过滤器。
- 141 spark.ui.port: Spark UI 的端口。
- 142 spark.yarn.am.cores: YARN ApplicationMaster 的 CPU 核心数。
- 143 spark.yarn.am.memory: YARN ApplicationMaster 的内存大小。
- 144 spark.yarn.am.memoryOverhead: YARN ApplicationMaster 的内存 overhead。
- 145 spark.yarn.am.waitTime: YARN ApplicationMaster 的等待时间。
- 146 spark.yarn.historyServer.address: YARN 历史服务器地址。
- 147 spark.yarn.queue: YARN 队列。
- 148 spark.yarn.tags: YARN 标签。
SparkUI任务启动参数介绍(148个参数)
1 spark.app.id: Spark 应用程序的唯一标识符。
2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。
3 spark.app.name: Spark 应用程序的名称。
4 spark.app.startTime: Spark 应用程序的启动时间。
5 spark.app.submitTime: Spark 应用程序的提交时间。
6 spark.blacklist.enabled: 是否启用黑名单机制,用于阻止执行失败的节点。
- spark.blacklist.enabled 是 Spark 中用于控制 executor 黑名单(executor blacklist)的配置参数。此参数用于启用或禁用 executor 黑名单的功能。
- 当启用了 executor 黑名单时,Spark 会监测任务执行的失败情况,并在某个 executor 上连续发生多次任务失败时,将该 executor 加入到黑名单。被列入黑名单的 executor 在一段时间内不会被分配新的任务,以避免在该 executor 上持续发生故障的影响。
- 这个功能的主要目的是增强 Spark 应用程序的稳定性。如果一个 executor 处于不稳定状态,可能由于硬件故障、资源问题或其他原因导致任务失败,executor 黑名单机制可以防止 Spark 继续将任务分配给这个不稳定的 executor,从而减少整体应用程序的故障风险。
7 spark.buffer.size: 用于 IO 缓冲的大小。
- 在 Spark 中,spark.buffer.size 是用于配置网络缓冲区大小的参数。这个参数控制 Spark 执行器(executors)之间传输数据时使用的缓冲区的大小。
- 具体而言,spark.buffer.size 用于控制数据在网络传输时的缓冲区大小,以优化数据传输性能。较大的缓冲区可以降低网络传输的开销,特别是在大规模数据移动时。然而,需要注意,设置过大的缓冲区也可能导致一些资源使用方面的问题,因为每个任务都可能分配这么大的缓冲区。
- spark.buffer.size 参数设置的是每个 Executor 中用于数据缓冲的大小。具体来说,它影响了在 Executor 之间进行数据传输时使用的缓冲区大小,如 Shuffle 操作中的数据传输、网络传输和磁盘写入等。
- 当设置了 spark.buffer.size 后,所有的 Executor 都会使用相同的缓冲区大小,而不是每个任务或操作使用不同的大小。这样的一致性可以确保在整个 Spark 应用程序中,数据传输时使用的缓冲区大小是相同的
8 spark.cleaner.periodicGC.interval: 周期性垃圾回收清理器的间隔。
-
spark.cleaner.periodicGC.interval 参数是用于配置 Spark 的内存清理(garbage collection)机制的间隔时间。这个参数定义了 Spark 内部周期性执行的垃圾回收操作的时间间隔。
-
具体来说,spark.cleaner.periodicGC.interval 参数表示了在执行垃圾回收之前等待的时间。Spark 的垃圾回收机制主要用于释放不再使用的内存,以防止应用程序因为内存泄漏而耗尽内存。
-
默认值:如果未显式设置,该参数的默认值为 30s,表示 Spark 将每隔 30 秒执行一次周期性的垃圾回收。
-
作用:周期性的垃圾回收有助于释放不再使用的内存,保持应用程序的内存稳定性。这对于长时间运行的 Spark 应用程序尤其重要,以防止内存泄漏问题。
9 spark.driver.appUIAddress: Driver 进程的 UI 地址。
10 spark.driver.extraJavaOptions: Driver 进程的额外 Java 选项。
-
spark.driver.extraJavaOptions 是 Spark 中用于设置驱动程序(Driver)的额外 Java 选项的配置参数。驱动程序是 Spark 应用程序的主节点,负责协调和监控整个应用程序的执行。
-
具体来说,spark.driver.extraJavaOptions 允许您向 Spark 驱动程序的 Java 虚拟机(JVM)添加额外的 Java 选项。这可以用于调整 JVM 的行为、设置系统属性、添加 Java 库的路径等。通常情况下,您可以使用该参数来进行一些与 Spark 驱动程序相关的高级配置。
设置内存参数:
--conf spark.driver.extraJavaOptions="-Xms512m -Xmx1024m"
上述配置设置了 Spark 驱动程序的初始堆大小为 512MB,最大堆大小为 1024MB。
11 spark.driver.host: Driver 进程的主机名。
12 spark.driver.maxResultSize: Driver 进程可以接收的最大结果大小。
-
spark.driver.maxResultSize 是 Spark 中用于设置驱动程序(Driver)端返回给用户的结果的最大大小的配置参数。该参数限制了 Spark 应用程序中可以由单个操作生成的结果的大小。如果操作的结果超过了此限制,Spark 将尝试将其截断或分割为适当大小的部分。
-
具体来说,spark.driver.maxResultSize 用于控制驱动程序端执行的操作的结果在内存中的最大大小。如果某个操作的结果超过了这个大小,可能会导致驱动程序端的内存溢出或性能问题。这个参数的设置是为了防止驱动程序端由于大量数据结果而耗尽内存。
-
spark.driver.maxResultSize 的注意事项和用法:
默认值:如果未显式设置,spark.driver.maxResultSize 的默认值是 1g,表示默认情况下驱动程序端可以处理最大为 1GB 的结果。 -
设置方式:可以通过 Spark 应用程序的配置文件或通过 Spark 提交命令行参数进行设置。例如:
--conf spark.driver.maxResultSize=2g
上述命令将 spark.driver.maxResultSize 设置为 2GB。
- 适用场景:这个参数通常在执行需要返回大量数据给驱动程序的操作时使用,比如在执行 collect 操作时。要注意,如果将这个值设置得太小,可能会导致无法返回大型结果集,从而影响应用程序的正常运行。
13 spark.driver.memory: Driver 进程的内存大小。
-
spark.driver.memory 是 Spark 中用于设置驱动程序(Driver)的内存大小的配置参数。这个参数定义了 Spark 应用程序的主节点(驱动程序)的堆内存大小。驱动程序是整个 Spark 应用程序的控制中心,负责协调和监控任务的执行。
-
具体来说,spark.driver.memory 用于指定驱动程序的 Java 虚拟机(JVM)的堆内存大小。这个堆内存大小影响着驱动程序端可以处理的任务数量和驱动程序本身的性能。
-
spark.driver.memory 的注意事项和用法:
默认值:如果未显式设置,spark.driver.memory 的默认值是 1g,表示默认情况下驱动程序的堆内存大小为 1GB。
设置方式:可以通过 Spark 应用程序的配置文件或通过 Spark 提交命令行参数进行设置。例如:
--conf spark.driver.memory=2g
上述命令将 spark.driver.memory 设置为 2GB。
-
内存分配:驱动程序的堆内存主要用于存储应用程序的元数据、任务状态信息、作业计划等,以及在执行一些操作时需要缓存的数据。较大的 spark.driver.memory 可以为应用程序提供更多的内存资源,但要注意不要设置得太大以至于超过可用的物理内存。
-
适用场景:通常情况下,适当调整 spark.driver.memory 的大小可以提高驱动程序的性能,特别是当应用程序需要处理大量元数据或需要执行大规模操作时。但请注意,如果设置得过大,可能会导致驱动程序端的内存溢出。
14 spark.driver.port: Driver 进程的端口号。
15 spark.dynamicAllocation.enabled: 是否启用动态资源分配。
-
spark.dynamicAllocation.enabled 是 Spark 中用于配置动态资源分配(Dynamic Allocation)是否启用的配置参数。动态资源分配是一种机制,允许 Spark 应用程序根据实际的资源需求来动态地调整执行器(executors)的数量,以更有效地利用集群资源。
-
具体来说,spark.dynamicAllocation.enabled 用于启用或禁用动态资源分配。如果将其设置为 true,则启用动态资源分配;如果设置为 false,则禁用。
-
以下是一些关于 spark.dynamicAllocation.enabled 的注意事项:
默认值:如果未显式设置,spark.dynamicAllocation.enabled 的默认值是 false,表示默认情况下动态资源分配是禁用的。 -
设置方式:可以通过 Spark 应用程序的配置文件或通过 Spark 提交命令行参数进行设置。例如:
--conf spark.dynamicAllocation.enabled=true
上述命令将启用动态资源分配。
-
动态资源分配:启用动态资源分配后,Spark 应用程序可以根据实际的任务负载来增加或减少执行器的数量。这使得 Spark 应用程序更加灵活,可以适应不同的工作负载。
-
资源调整策略:与动态资源分配一起使用的还有其他一些配置参数,如 spark.dynamicAllocation.minExecutors、spark.dynamicAllocation.maxExecutors、spark.dynamicAllocation.initialExecutors 等,用于配置执行器数量的上下限和初始数量。
16 spark.dynamicAllocation.executorIdleTimeout: Executor 空闲超时时
-
spark.dynamicAllocation.executorIdleTimeout 是 Spark 中用于配置动态资源分配(Dynamic Allocation)中执行器(executor)的空闲超时时间的配置参数。这个参数定义了一个执行器在空闲一段时间后会被终止并释放的时间阈值。
-
具体来说,spark.dynamicAllocation.executorIdleTimeout 用于控制执行器在没有任务执行的情况下保持空闲的最长时间。如果一个执行器在这个时间段内没有被分配任务,那么它将被认为是空闲的,并可能被终止,以释放资源。
-
spark.dynamicAllocation.executorIdleTimeout 的一些注意事项:
默认值:如果未显式设置,spark.dynamicAllocation.executorIdleTimeout 的默认值是 60s,表示默认情况下,一个空闲的执行器在 60 秒内没有被分配任务时可能会被终止。 -
设置方式:可以通过 Spark 应用程序的配置文件或通过 Spark 提交命令行参数进行设置。例如:
--conf spark.dynamicAllocation.executorIdleTimeout=120s
上述命令将 spark.dynamicAllocation.executorIdleTimeout 设置为 120 秒。
-
动态资源分配:此参数是动态资源分配机制的一部分,用于调整执行器数量以适应实际的工作负载。通过终止空闲的执行器,Spark 可以有效地释放资源,并在负载轻时减少集群资源的占用。
-
空闲执行器终止:在启用动态资源分配的情况下,当执行器处于空闲状态并且达到了指定的空闲超时时间时,该执行器可能会被终止。这样可以在不需要太多资源的情况下释放资源。
17 spark.dynamicAllocation.initialExecutors: 初始 Executor 数量。
- 这个参数用于设置 Spark 应用程序启动时的初始执行器数量。
初始执行器数量是在应用程序启动时分配的执行器的数量,这是动态分配的起点。
18 spark.dynamicAllocation.maxExecutors: 最大 Executor 数量。
- 这个参数用于设置 Spark 应用程序允许的最大执行器数量。
动态分配可以根据负载自动增加执行器数量,但不会超过此配置的最大值。
19 spark.dynamicAllocation.minExecutors: 最小 Executor 数量。
- 这个参数用于设置 Spark 应用程序保持的最小执行器数量。
即使负载较轻,动态分配也不会减少执行器数量到低于此配置的最小值。 - 这三个参数都与 Spark 中的动态资源分配(Dynamic Allocation)有关,用于配置执行器(executors)的数量。
- 这些参数允许 Spark 应用程序根据负载动态地调整执行器的数量,以更好地利用集群资源。动态资源分配机制允许 Spark 根据实际的工作负载自动调整执行器数量,以确保资源的最佳利用和任务的及时执行。
20 spark.eventLog.compress: 是否压缩事件日志。
21 spark.eventLog.dir: 事件日志目录。
22 spark.eventLog.enabled: 是否启用事件日志。
23 spark.executor.cores: 每个 Executor 的 CPU 核心数。
24 spark.executor.extraJavaOptions: 每个 Executor 的额外 Java 选项。
25 spark.executor.id: Executor 的唯一标识符。
26 spark.executor.instances: Executor 的实例数量。
27 spark.executor.memory: 每个 Executor 的内存大小。
28 spark.executor.memoryOverhead: 每个 Executor 的内存 overhead。
29 spark.extraListeners: 额外的监听器。
30 spark.files.ignoreCorruptFiles: 是否忽略损坏的文件。
31 spark.hadoop.fs.file.impl.disable.cache: 是否禁用文件系统的缓存。
32 spark.hadoop.fs.hdfs.impl.disable.cache: 是否禁用 HDFS 的缓存。
33 spark.hadoop.mapreduce.input.fileinputformat.list-status.num-threads: 文件输入格式的线程数。
34 spark.hadoopRDD.ignoreEmptySplits: 是否忽略空分片。
35 spark.history.fs.cleaner.enabled: 是否启用历史文件系统清理器。
36 spark.history.fs.cleaner.interval: 历史文件系统清理器的清理间隔。
37 spark.history.fs.cleaner.maxAge: 历史文件系统清理器的最大年龄。
38 spark.history.fs.update.interval: 历史文件系统更新间隔。
39 spark.history.kerberos.enabled: 是否启用 Kerberos 认证。
40 spark.history.provider: 历史记录提供程序。
41 spark.history.retainedApplications: 保留的历史应用程序数量。
42 spark.history.store.maxDiskUsage: 历史存储的最大磁盘使用量。
43 spark.history.ui.maxApplications: 历史 UI 的最大应用程序数量。
44 spark.hive.server2.proxy.user: Hive Server2 代理用户。
45 spark.jars: Spark 应用程序所需的 Jar 包。
46 spark.kerberos.access.hadoopFileSystems: Kerberos 访问 Hadoop 文件系统。
47 spark.kryoserializer.buffer.max: Kryo 序列化器的最大缓冲区大小。
48 spark.kyuubi.client.ipAddress: Kyuubi 客户端的 IP 地址。
49 spark.kyuubi.engine.credentials: Kyuubi 引擎的凭证。
50 spark.kyuubi.engine.share.level: Kyuubi 引擎共享级别。
51 spark.kyuubi.engine.share.level.subdomain: Kyuubi 引擎共享级别子域。
52 spark.kyuubi.engine.submit.time: Kyuubi 引擎提交时间。
53 spark.kyuubi.ha.engine.ref.id: Kyuubi HA 引擎引用 ID。
54 spark.kyuubi.ha.namespace: Kyuubi HA 命名空间。
55 spark.kyuubi.ha.zookeeper.auth.keytab: Kyuubi HA ZooKeeper 认证 keytab。
56 spark.kyuubi.ha.zookeeper.auth.principal: Kyuubi HA ZooKeeper 认证 principal。
57 spark.kyuubi.ha.zookeeper.auth.type: Kyuubi HA ZooKeeper 认证类型。
58 spark.kyuubi.ha.zookeeper.namespace: Kyuubi HA ZooKeeper 命名空间。
59 spark.kyuubi.ha.zookeeper.quorum: Kyuubi HA ZooKeeper quorum。
60 spark.kyuubi.operation.result.max.rows: Kyuubi 操作结果的最大行数。
61 spark.kyuubi.session.engine.idle.timeout: Kyuubi 会话引擎空闲超时时间。
62 spark.locality.wait: 本地性等待时间。
63 spark.locality.wait.node: 节点本地性等待时间。
64 spark.locality.wait.process: 进程本地性等待时间。
65 spark.locality.wait.rack: 机架本地性等待时间。
66 spark.master: Spark Master 地址。
67 spark.maxRemoteBlockSizeFetchToMem: 最大远程块大小从磁盘到内存。
68 spark.network.timeout: 网络超时时间。
69 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_HOSTS: YARN Web 代理参数。
70 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES: YARN Web 代理 URI 基础路径。
71 spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.RM_HA_URLS: YARN Web 代理 RM HA URLs。
72 spark.redaction.regex: 日志内容的正则表达式,用于数据遮蔽。
73 spark.reducer.maxBlocksInFlightPerAddress: 每个地址的最大块数。
74 spark.reducer.maxReqsInFlight: 最大并行请求数。
75 spark.repl.class.outputDir: REPL 类的输出目录。
76 spark.repl.class.uri: REPL 类的 URI。
77 spark.rpc.askTimeout: RPC 询问超时时间。
78 spark.scheduler.mode: Spark 调度模式。
79 spark.serializer: 序列化器。
80 spark.shuffle.detectCorrupt.useExtraMemory: 是否使用额外内存检测 Shuffle 数据的损坏。
81 spark.shuffle.file.buffer: Shuffle 文件的缓冲区大小。
82 spark.shuffle.io.maxRetries: Shuffle IO 的最大重试次数。
83 spark.shuffle.io.preferDirectBufs: 是否优先使用直接缓冲区。
84 spark.shuffle.io.retryWait: Shuffle IO 重试等待时间。
85 spark.shuffle.mapOutput.parallelAggregationThreshold: 并行聚合阈值。
86 spark.shuffle.readHostLocalDisk: 是否从本地磁盘读取 Shuffle 数据。
87 spark.shuffle.registration.maxAttempts: Shuffle 注册的最大尝试次数。
88 spark.shuffle.registration.timeout: Shuffle 注册的超时时间。
89 spark.shuffle.service.enabled: 是否启用 Shuffle 服务。
90 spark.shuffle.spill.diskWriteBufferSize: Shuffle Spill 磁盘写缓冲区大小。
91 spark.shuffle.unsafe.file.output.buffer: 不安全 Shuffle 文件输出缓冲区大小。
92 spark.shuffle.useOldFetchProtocol: 是否使用旧的 Fetch 协议。
93 spark.speculation: 是否启用任务推测执行。
94 spark.speculation.interval: 任务推测执行的间隔。
95 spark.speculation.multiplier: 任务推测执行的倍数。
96 spark.speculation.quantile: 任务推测执行的分位数。
97 spark.speculation.task.duration.threshold: 任务推测执行的持续时间阈值。
98 spark.sql.access.authorization.enable: 是否启用 SQL 访问授权。
99 spark.sql.access.iceberg.enable: 是否启用 Iceberg 表的 SQL 访问。
100 spark.sql.adaptive.advisoryPartitionSizeInBytes: 自适应执行中分区大小的建议值。
101 spark.sql.adaptive.autoBroadcastJoinThreshold: 自适应执行中自动广播连接的阈值。
102 spark.sql.adaptive.enabled: 是否启用自适应执行。
103 spark.sql.adaptive.fetchShuffleBlocksInBatch: 自适应执行中每批次获取 Shuffle 块的数量。
104 spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold: 自适应执行中本地 Map 阈值。
105 spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin: 自适应执行中非空分区比例的广播连接阈值。
106 spark.sql.adaptive.skewJoin.enabled: 自适应执行中是否启用倾斜连接。
107 spark.sql.adaptive.skewJoin.skewedPartitionFactor: 自适应执行中倾斜连接的分区因子。
108 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: 自适应执行中倾斜连接的分区阈值。
109 spark.sql.autoBroadcastJoinThreshold: 自动广播连接的阈值。
110 spark.sql.broadcastTimeout: 广播连接的超时时间。
111 spark.sql.catalog.hive_catalog: Hive Catalog 名称。
112 spark.sql.catalog.hive_catalog.type: Hive Catalog 类型。
113 spark.sql.catalog.hive_catalog.url: Hive Catalog URL。
114 spark.sql.catalog.spark_catalog: Spark Catalog 名称。
115 spark.sql.catalog.spark_catalog.type: Spark Catalog 类型。
116 spark.sql.catalogImplementation: SQL Catalog 实现。
117 spark.sql.crossJoin.enabled: 是否启用跨连接。
118 spark.sql.execution.topKSortFallbackThreshold: 执行中 Top-K 排序的阈值。
119 spark.sql.extensions: SQL 扩展。
120 spark.sql.files.ignoreCorruptFiles: 是否忽略损坏的文件。
121 spark.sql.files.ignoreMissingFiles: 是否忽略缺失的文件。
122 spark.sql.finalStage.adaptive.advisoryPartitionSizeInBytes: 最终阶段执行中分区大小的建议值。
123 spark.sql.finalStage.adaptive.coalescePartitions.minPartitionNum: 最终阶段执行中合并分区的最小分区数。
124 spark.sql.finalStage.adaptive.skewJoin.skewedPartitionFactor: 最终阶段执行中倾斜连接的分区因子。
125 spark.sql.finalStage.adaptive.skewJoin.skewedPartitionThresholdInBytes: 最终阶段执行中倾斜连接的分区阈值。
126 spark.sql.hive.convertInsertingPartitionedTable: Hive 表插入分区的转换。
127 spark.sql.hive.verifyPartitionPath: Hive 表分区路径验证。
128 spark.sql.legacy.castComplexTypesToString.enabled: 是否启用将复杂类型强制转换为字符串的遗留行为。
129 spark.sql.legacy.setCommandRejectsSparkCoreConfs: 是否拒绝设置 Spark Core 配置的遗留 set 命令。
130 spark.sql.legacy.timeParserPolicy: 时间解析策略。
131 spark.sql.optimizer.finalStageConfigIsolation.enabled: 是否启用最终阶段配置隔离。
132 spark.sql.parquet.recordLevelFilter.enabled: 是否启用 Parquet 记录级别过滤。
133 spark.sql.queryExecutionListeners: 查询执行监听器。
134 spark.sql.runSQLOnFiles: 是否在文件上运行 SQL 查询。
135 spark.sql.shuffle.partitions: Shuffle 阶段的分区数。
136 spark.sql.statistics.fallBackToHdfs: 是否回退到 HDFS 统计信息。
137 spark.sql.storeAssignmentPolicy: 存储分配策略。
138 spark.submit.deployMode: Spark 应用程序的部署模式。
139 spark.submit.pyFiles: 提交给 Spark 应用程序的 Python 文件。
140 spark.ui.filters: Spark UI 的过滤器。
141 spark.ui.port: Spark UI 的端口。
142 spark.yarn.am.cores: YARN ApplicationMaster 的 CPU 核心数。
143 spark.yarn.am.memory: YARN ApplicationMaster 的内存大小。
144 spark.yarn.am.memoryOverhead: YARN ApplicationMaster 的内存 overhead。
145 spark.yarn.am.waitTime: YARN ApplicationMaster 的等待时间。
146 spark.yarn.historyServer.address: YARN 历史服务器地址。
147 spark.yarn.queue: YARN 队列。
148 spark.yarn.tags: YARN 标签。
相关文章:
)
SparkUI任务启动参数介绍(148个参数)
文章目录 SparkUI任务启动参数介绍(148个参数)1 spark.app.id: Spark 应用程序的唯一标识符。2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。3 spark.app.name: Spark 应用程序的名称。4 spark.app.startTime: Spark 应用程序的启动…...

nginx 安装
Nginx 简介 nginx一种十分轻量级的http服务器一种高性能的HTTP和反向代理服务器,同时是一个IMAP/POP3/SMTP 代理服务器其中官网网站 安装Nginx 使用源码编辑安装 #提前安装相关工具软件包 yum -y install net-tools tar unzip gcc make pcre-devel openssl-devel httpd-too…...
手撕扩散模型(一)| 训练部分——前向扩散,反向预测代码全解析
文章目录 1 直接使用 核心代码2 工程代码实现2.1 DDPM2.2 训练 三大模型VAE,GAN, DIffusion扩散模型 是生成界的重要模型,但是最近一段时间扩散模型被用到的越来越多的,最近爆火的OpenAI的 Sora文生视频模型其实也是用了这种的方…...

linux 防火墙
防火墙分类 按保护范围划分 主机防火墙:服务服务为当前一台主机 网络防火墙:服务服务为防火墙一侧的局域网 按实现方式分类划分 硬件防火墙:在专用硬件级别实现部分功能的防火墙;另一部分基于软件的实现 如:华为&#…...
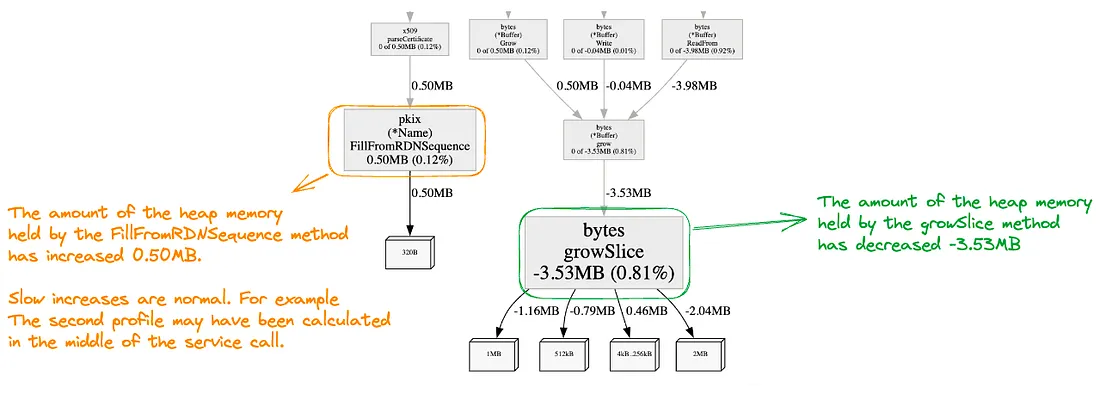
Go应用性能分析实战
Go很适合用来开发高性能网络应用,但仍然需要借助有效的工具进行性能分析,优化代码逻辑。本文介绍了如何通过go test benchmark和pprof进行性能分析,从而实现最优的代码效能。原文: Profiling Go Applications in the Right Way with Examples…...

MySQL的索引类型
目录 1. 主键索引 (PRIMARY KEY) 2. 唯一索引 (UNIQUE) 3. 普通索引 (INDEX) 4. 全文索引 (FULLTEXT) 5. 空间索引 (SPATIAL) 6. 组合索引 (COMPOSITE INDEX) 7. 前缀索引 (PREFIX INDEX) 8. 覆盖索引 (COVERING INDEX) 1. 主键索引 (PRIMARY KEY) 描述:表…...

picker选择器-年月日选择
从底部弹起的滚动选择器。支持五种选择器,通过mode来区分,分别是普通选择器,多列选择器,时间选择器,日期选择器,省市区选择器,默认是普通选择器。 学习一下日期选择器 平台差异说明 日期选择默…...
)
【LeetCode-494】目标和(回溯动归)
目录 LeetCode494.目标和 题目描述 解法1:回溯法 代码实现 解法2:动态规划 代码实现 LeetCode494.目标和 题目链接 题目描述 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 和 -。对于数组中…...

力扣 188. 买卖股票的最佳时机 IV
题目来源:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iv/description/ C题解:动态规划 思路同力扣 123. 买卖股票的最佳时机 III-CSDN博客,只是把最高2次换成k次。如果思路不清晰,可以将k从0写到4等找找规律…...

【Go语言】Go项目工程管理
GO 项目工程管理(Go Modules) Go 1.11 版本开始,官方提供了 Go Modules 进行项目管理,Go 1.13开始,Go项目默认使用 Go Modules 进行项目管理。 使用 Go Modules的好处是不再需要依赖 GOPATH,可以在任意位…...
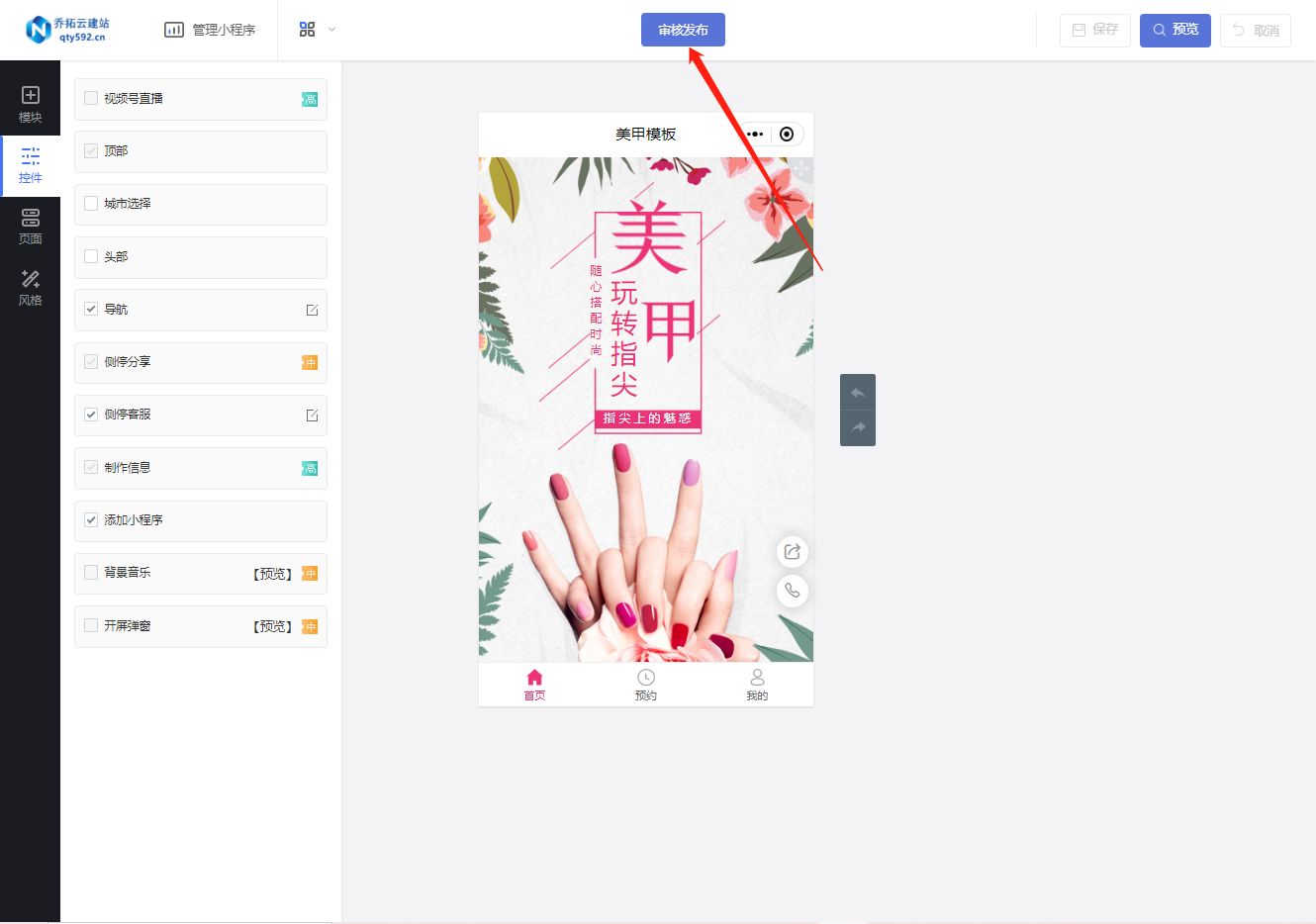
美容小程序:让预约更简单,服务更贴心
在当今繁忙的生活节奏中,美容预约常常令人感到繁琐和疲惫。为了解决这个问题,许多美容院和SPA中心已经开始采用美容小程序来简化预约流程,并提供更加贴心的服务。在这篇文章中,我们将引导您了解如何制作一个美容小程序,…...

【递归】:原理、应用与案例解析 ,助你深入理解递归核心思想
递归 1.基础简介 递归在计算机科学中,递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集 例如 递归遍历环形链表 基本情况(Base Case):基本情况是递归函数中最简单的情况,它们通常是递…...
【 Maven 】花式玩法之多模块项目
目录 一、认识Maven多模块项目 二、maven如何定义项目的发布策略 2.1 版本管理 2.2 构建配置 2.3 部署和发布 2.4 依赖管理 2.5 发布流程 三、使用Jenkins持续集成Maven项目 四、总结 如果你有一个多模块项目,并且想将这些模块发布到不同的仓库或目标位置&…...

LeetCode 热题 100 Day01
哈希模块 哈希结构: 哈希结构,即hash table,哈希表|散列表结构。 图摘自《代码随想录》 哈希表本质上表示的元素和索引的一种映射关系。 若查找某个数组中第n个元素,有两种方法: 1.从头遍历,复杂度…...
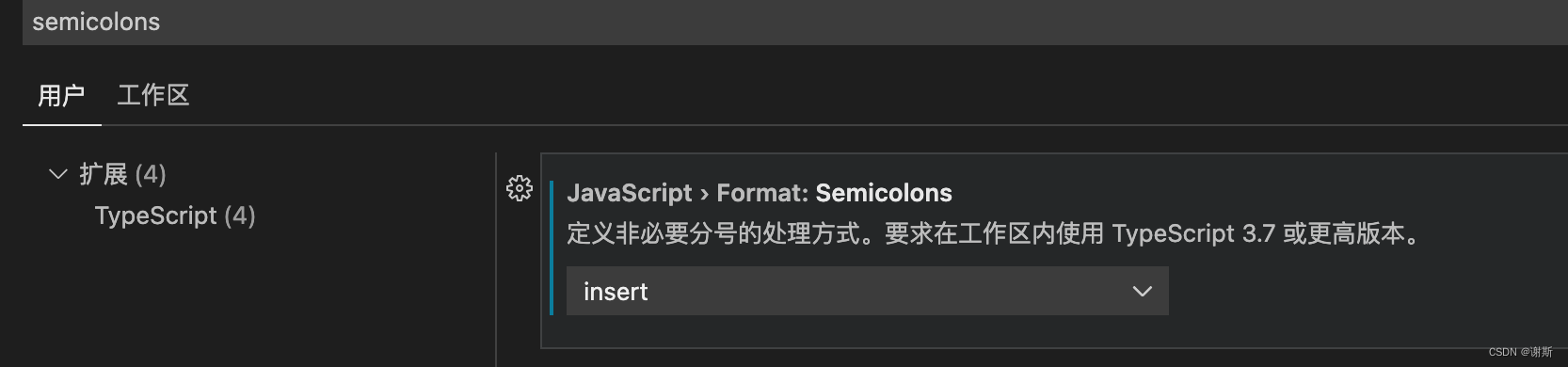
[vscode]vue js部分结尾加分号
设置中寻找 semicolons确定在TypeScript的这个扩展中设置选项为insert...
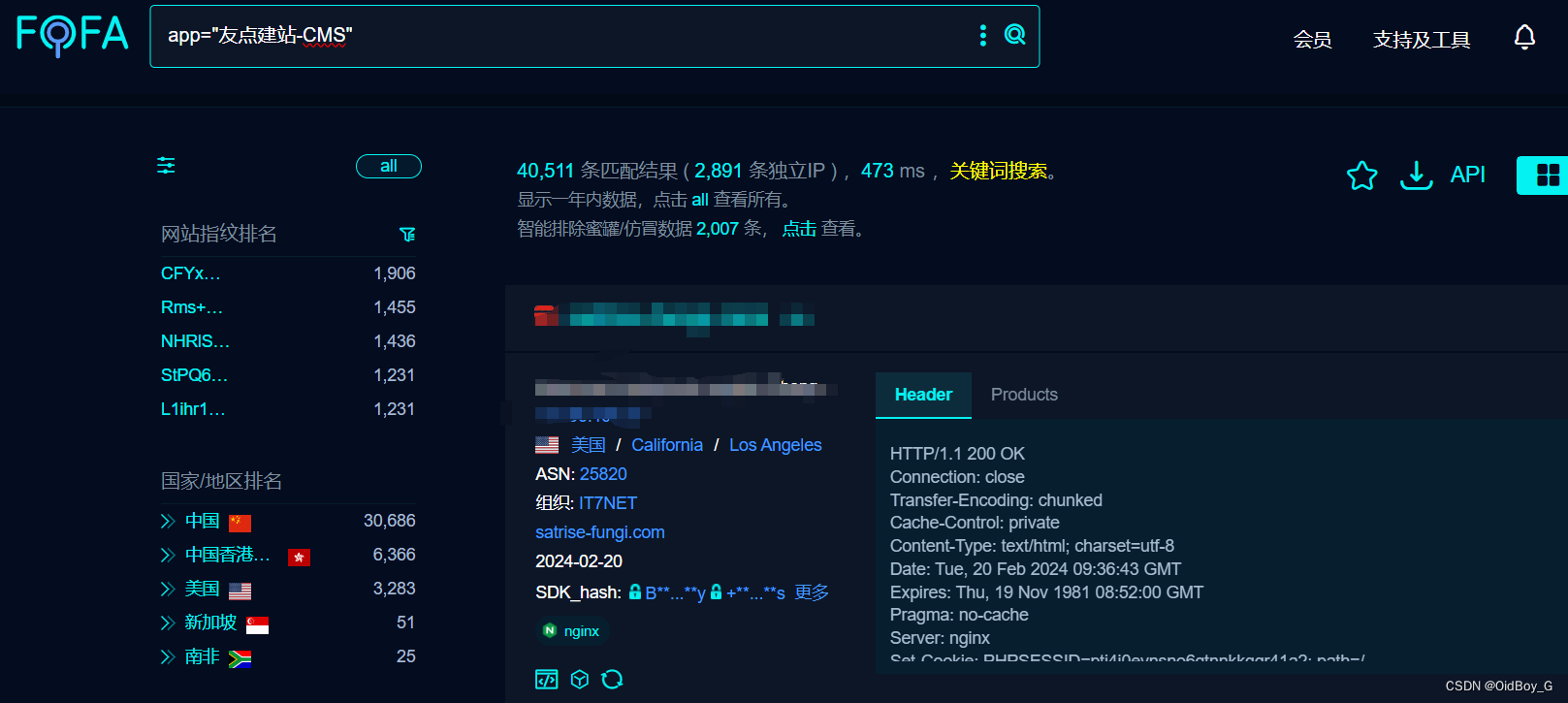
友点CMS image_upload.php 文件上传漏洞复现
0x01 产品简介 友点CMS是一款高效且灵活的网站管理系统,它为用户提供了简单易用的界面和丰富的功能。无论是企业还是个人,都能通过友点CMS快速搭建出专业且美观的网站。该系统支持多种内容类型和自定义模板,方便用户按需调整。同时,它具备强大的SEO功能,能提升网站在搜索…...

C语言—指针(3)
嘿嘿嘿嘿,你看我像指针吗? 不会写,等我啥时候会写了再说吧,真的累了,倦了 1.面试题 1)定义整形变量i; 2)p为指向整形变量的指针变量; 3)定…...
【八股文】面向对象基础
【八股文】面向对象基础 面向对象和面向过程的区别 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。 创建一个对象用什么运算符?对象实体与对象引用有何不同? …...

Day49 647 回文子串 516 最长回文子序列
647 回文子串 给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。 方法一:动态规划: 采用一个二维的dp数组…...

探秘GNU/Linux Shell:命令行的魔法世界
GNU/Linux的Shell是一种特殊的交互式工具,为用户提供了强大的控制和管理Linux系统的方式。在这个博客中,我们将深入了解Shell的基本概念、功能以及不同类型的Shell。 Shell的本质 Shell的核心是命令行提示符,它是用户与Linux系统进行交互的…...

FastAdmin任意文件读取漏洞CVE-2024-7928深度解析与三阶段修复
1. 这个漏洞不是“能读任意文件”那么简单,而是整个FastAdmin旧版本的信任基石崩塌了你可能在安全通报里看到过CVE-2024-7928的简短描述:“FastAdmin框架存在任意文件读取漏洞”,甚至有些文章直接写成“可读取服务器任意配置文件”。但我在给…...

基于PSOC62 CAPSENSE的远程空调遥控器:物联网与红外控制实践
1. 项目概述:当传统遥控器遇上物联网你有没有遇到过这样的场景:大夏天回到家,一身汗,还得在包里翻箱倒柜找空调遥控器;或者冬天窝在被窝里,发现遥控器在客厅茶几上,得鼓起勇气离开温暖的被窝去拿…...
-透射(TEM)-原子力(AFM)的比较)
扫描(SEM)-透射(TEM)-原子力(AFM)的比较
SEM: 扫描电子显微镜扫描电镜成像是利用细聚焦高能电子束在样件表面激发各种物理信号,如二次电子、背散射电子等,通过相应的检测器来检测这些信号,信号的强度与样品表面形貌有一定的对应关系,因此,可将其转…...

写给前端的 CANN-ops-rand:昇腾随机数生成算子库到底是啥?
之前做强化学习,兄弟问我:“哥,我想在昇腾上做蒙特卡洛模拟,随机数生成有现成的库吗?” 好问题。今天一次说清楚。 ops-rand 是啥? ops-rand Operations for Random,昇腾随机数生成算子库。 一…...

如何快速掌握CircuitJS1桌面版的3个核心秘诀
如何快速掌握CircuitJS1桌面版的3个核心秘诀 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1 CircuitJS1 Desktop …...

百考通:AI一键生成论文降重与去AI痕迹,提供双重优化保障,让学术成果更合规
在学术写作与论文发表的过程中,重复率过高、AI生成痕迹明显,是困扰无数学生与科研工作者的核心难题。不仅可能导致查重不通过,更会影响学术诚信与成果认可度。百考通(https://www.baikaotongai.com) 凭借智能文本优化技…...

ElevenLabs支持贵州话吗?2024最新实测结果+3种绕过官方限制的合规接入方案
更多请点击: https://codechina.net 第一章:ElevenLabs对贵州话的原生支持现状与底层语音技术解析 ElevenLabs当前官方模型库中尚未提供针对贵州话(含贵阳话、遵义话等主要方言变体)的独立语言选项或预训练语音模型。其公开支持的…...
》)
如何用Python自动识别ElevenLabs输出语音是否触发青少年保护机制?开源检测脚本+实时响应策略(限24小时领取)》
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs青少年语音保护机制的技术本质与合规边界 ElevenLabs 的青少年语音保护机制并非简单的年龄声明开关,而是一套融合前端约束、后端策略引擎与联邦学习辅助验证的多层技术栈。其核心…...

后端架构:事件驱动架构设计与实现
后端架构:事件驱动架构设计与实现 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊事件驱动架构这个重要话题。作为一个全栈开发者,事件驱动架构已经成为现代后端系统的重要设计模式。今天就来分享一下事件驱动架构的设…...

从账单明细看Taotoken按Token计费模式如何帮助用户精确定位高消耗场景
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken按Token计费模式如何帮助用户精确定位高消耗场景 在构建基于大模型的应用时,成本控制是一个持续性…...