手撕扩散模型(一)| 训练部分——前向扩散,反向预测代码全解析
文章目录
- 1 直接使用 核心代码
- 2 工程代码实现
- 2.1 DDPM
- 2.2 训练
三大模型VAE,GAN, DIffusion扩散模型 是生成界的重要模型,但是最近一段时间扩散模型被用到的越来越多的,最近爆火的OpenAI的
Sora文生视频模型其实也是用了这种的方式,因而我打算系统回顾扩散系列知识,并注重代码的分析,感兴趣可以关注这一系列的博客,先介绍基础版本的,之后介绍扩散进阶的相关知识。
扩散模型很多的讲解上来会讲解很多的数学,会让人望而却步,但其实扩散在实际使用的时候并不复杂,我会先从代码的角度告诉大家怎么实操,再介绍数学推理
扩散要弄明白训练和推理两个过程~这节主要分析训练过程
1 直接使用 核心代码
基础版本的扩散核心就两句话
(1) DDPM前向扩散得到加噪后的图片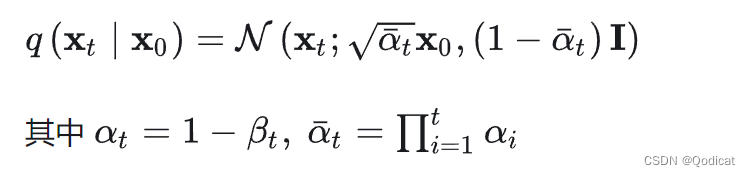
得到标记,对应一个核心公式**
(2) DDPM反向利用Unet网络预测加的噪声
实际上抽象一下,忽略细节,训练部分代码就主要以下部分
import torch
from torch import nn
n_steps=1000#假设我们最大的加噪步数是1000
x0=torch.ones(128,1,28,28) #模拟输入,1个batch有128张图片,通道数1,宽度高度为28
eta = torch.randn_like(x0) #生成初始随机噪声,形状和模拟输入一样
t= torch.randint(0, n_steps, (128,))#t是加噪时间,注意这里的t是随机生成的0到1000的128个随机数
noisy_imgs = ddpm(x0, t, eta) #前向加噪 输入原始输入图片和随机的t,得到128个加噪后的图像,扩散模型核心的第一句话
eta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1)) #反向预测,给定图和t,得到预测噪声,扩散模型核心的第二句话
loss = nn.mse(eta_theta, eta) #计算噪声和实际的噪声之间的差异作为损失
optim.zero_grad()
loss.backward()
optim.step()
2 工程代码实现
当然上面是一个简略版本,实际中肯定要考虑较多的细节问题~
先来实现DDPM
2.1 DDPM
我们申明一个这样一个类MyDDPM
class MyDDPM(nn.Module):def __init__(self, network, n_steps=200, min_beta=10 ** -4, max_beta=0.02, device=None, image_chw=(1, 28, 28)):super(MyDDPM, self).__init__()self.n_steps = n_steps #扩散时间总步数 self.device = device self.image_chw = image_chw #image_chw 用于表示图像的通道数、高度和宽度。这里通道数1,宽度高度为28self.network = network.to(device)self.betas = torch.linspace(min_beta, max_beta, n_steps).to(device) # beta预先算出来了self.alphas = 1 - self.betas #alphas也预先算出来self.alpha_bars = torch.tensor([torch.prod(self.alphas[:i + 1]) for i in range(len(self.alphas))]).to(device) #alphas_bars也预先算出来了 前i个乘积def forward(self, x0, t, eta=None):n, c, h, w = x0.shape #[批大小,通道数,图片高,图片宽]a_bar = self.alpha_bars[t] #t的大小和批大小相等if eta is None:eta = torch.randn(n, c, h, w).to(self.device)noisy_img = a_bar.sqrt().reshape(n, 1, 1, 1) * x0 + (1 - a_bar).sqrt().reshape(n, 1, 1, 1) * etareturn noisy_imgdef backward(self, x, t):# Run each image through the network for each timestep t in the vector t.# The network returns its estimation of the noise that was added.return self.network(x, t)
这段代码定义了一个名为MyDDPM的类,它是nn.Module的子类。
在MyDDPM类的构造函数__init__中,有以下几个重要的属性和操作:
n_steps:扩散时间总步数,表示模型在每个输入上进行的扩散步数。device:设备,表示模型在哪个设备上运行(如CPU或GPU)。image_chw:图像通道数、高度和宽度的元组,用于表示图像的形状。在这里,通道数为1,高度和宽度为28。network:神经网络模型,用于估计添加的噪声。betas:通过使用torch.linspace函数在min_beta和max_beta之间生成n_steps个均匀间隔的值,得到一个表示扩散系数的张量。alphas:通过将1减去betas得到的张量,表示衰减系数。alpha_bars:通过计算alphas的前i+1个元素的乘积,得到一个表示衰减系数累积乘积的张量。
MyDDPM类还定义了两个方法:
forward方法用于前向传播。它接受输入x0、时间步t和可选的噪声eta作为参数。在该方法中,首先获取输入x0的形状,并根据时间步t获取对应的衰减系数a_bar。如果未提供噪声eta,则使用torch.randn函数生成一个与输入形状相同的噪声张量。然后,根据衰减系数和噪声,计算得到带有噪声的图像张量,并返回该张量作为输出。backward方法用于反向传播。它接受输入x和时间步t作为参数,并通过调用network模型对每个时间步t的输入x进行处理,得到估计的添加噪声。最后,返回估计的噪声张量作为输出。
2.2 训练
有了DDPM我们就可以进行训练了(实际上这里的network我们先当做一个黑盒,在下一节讲解结构,network实现的效果就是输入某一时刻的t,和该时刻加噪后的图像,输出预测的噪声结果,该结果和前向生成的噪声做损失函数~优化参数)
def training_loop(ddpm, loader, n_epochs, optim, device, display=False, store_path="ddpm_model.pt"):mse = nn.MSELoss()best_loss = float("inf")n_steps = ddpm.n_stepsfor epoch in tqdm(range(n_epochs), desc=f"Training progress", colour="#00ff00"):epoch_loss = 0.0for step, batch in enumerate(tqdm(loader, leave=False, desc=f"Epoch {epoch + 1}/{n_epochs}", colour="#005500")):# Loading datax0 = batch[0].to(device) #[128,1,1,28]n = len(x0)# Picking some noise for each of the images in the batch, a timestep and the respective alpha_barseta = torch.randn_like(x0).to(device)t = torch.randint(0, n_steps, (n,)).to(device) #注意这里的t是随机生成的# Computing the noisy image based on x0 and the time-step (forward process)noisy_imgs = ddpm(x0, t, eta) #经过前向过程 y一次得到一个批次的# Getting model estimation of noise based on the images and the time-stepeta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1)) loss = mse(eta_theta, eta) #预测噪声和给出的噪声之间的差异optim.zero_grad()loss.backward()optim.step()epoch_loss += loss.item() * len(x0) / len(loader.dataset)# Display images generated at this epochif display:show_images(generate_new_images(ddpm, device=device), f"Images generated at epoch {epoch + 1}")log_string = f"Loss at epoch {epoch + 1}: {epoch_loss:.3f}"# Storing the modelif best_loss > epoch_loss:best_loss = epoch_losstorch.save(ddpm.state_dict(), store_path)log_string += " --> Best model ever (stored)"print(log_string)
-
函数定义:
def training_loop(ddpm, loader, n_epochs, optim, device, display=False, store_path="ddpm_model.pt"):- 这个函数接受多个参数:
ddpm是一个对象,loader是一个数据加载器,n_epochs是训练的轮数,optim是优化器,device是设备(如CPU或GPU),display是一个布尔值,用于控制是否显示生成的图像,store_path是模型存储的路径。 - 函数没有返回值。
- 这个函数接受多个参数:
-
导入模块:
mse = nn.MSELoss()- 这里导入了
nn模块,并创建了一个MSELoss的实例对象mse。
- 这里导入了
-
初始化变量:
best_loss = float("inf") n_steps = ddpm.n_stepsbest_loss被初始化为正无穷大,用于跟踪最佳损失值。n_steps从ddpm对象中获取,表示模型的步数。
-
训练循环:
for epoch in tqdm(range(n_epochs), desc=f"Training progress", colour="#00ff00"):epoch_loss = 0.0for step, batch in enumerate(tqdm(loader, leave=False, desc=f"Epoch {epoch + 1}/{n_epochs}", colour="#005500")):# Loading datax0 = batch[0].to(device) #[128,1,1,28]n = len(x0)...- 外部循环是训练的轮数,使用
range(n_epochs)生成一个迭代器,并使用tqdm函数包装,以显示训练进度条。 - 内部循环是对数据加载器中的批次进行迭代,使用
enumerate函数包装,并使用tqdm函数包装,以显示每个批次的进度条。 - 在每个批次中,首先从批次中加载数据,并将其移动到指定的设备上。
x0是批次中的第一个元素,表示输入数据。n是批次的大小。
- 外部循环是训练的轮数,使用
-
数据处理和模型训练:
eta = torch.randn_like(x0).to(device) t = torch.randint(0, n_steps, (n,)).to(device) noisy_imgs = ddpm(x0, t, eta) eta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1)) loss = mse(eta_theta, eta) optim.zero_grad() loss.backward() optim.step()eta是一个与x0形状相同的随机张量,用于添加噪声。t是一个随机生成的整数张量,表示时间步骤。noisy_imgs是通过将x0和t作为输入,使用ddpm对象进行前向传播得到的噪声图像。eta_theta是通过将noisy_imgs和t进行反向传播,使用ddpm对象得到的噪声估计。loss是通过计算eta_theta和eta之间的均方误差(MSE)得到的损失。optim.zero_grad()用于清除优化器的梯度。loss.backward()用于计算损失相对于模型参数的梯度。optim.step()用于更新模型参数。
-
显示生成的图像和存储模型:
if display:show_images(generate_new_images(ddpm, device=device), f"Images generated at epoch {epoch + 1}") ... if best_loss > epoch_loss:best_loss = epoch_losstorch.save(ddpm.state_dict(), store_path)log_string += " --> Best model ever (stored)" ... print(log_string)- 如果
display为True,则调用show_images函数显示生成的图像。 generate_new_images函数用于生成新的图像样本。- 如果当前轮的损失比之前的最佳损失更低,则将模型参数保存到指定的路径。
- 最后,打印训练日志字符串。
- 如果
相关文章:
手撕扩散模型(一)| 训练部分——前向扩散,反向预测代码全解析
文章目录 1 直接使用 核心代码2 工程代码实现2.1 DDPM2.2 训练 三大模型VAE,GAN, DIffusion扩散模型 是生成界的重要模型,但是最近一段时间扩散模型被用到的越来越多的,最近爆火的OpenAI的 Sora文生视频模型其实也是用了这种的方…...

linux 防火墙
防火墙分类 按保护范围划分 主机防火墙:服务服务为当前一台主机 网络防火墙:服务服务为防火墙一侧的局域网 按实现方式分类划分 硬件防火墙:在专用硬件级别实现部分功能的防火墙;另一部分基于软件的实现 如:华为&#…...
Go应用性能分析实战
Go很适合用来开发高性能网络应用,但仍然需要借助有效的工具进行性能分析,优化代码逻辑。本文介绍了如何通过go test benchmark和pprof进行性能分析,从而实现最优的代码效能。原文: Profiling Go Applications in the Right Way with Examples…...

MySQL的索引类型
目录 1. 主键索引 (PRIMARY KEY) 2. 唯一索引 (UNIQUE) 3. 普通索引 (INDEX) 4. 全文索引 (FULLTEXT) 5. 空间索引 (SPATIAL) 6. 组合索引 (COMPOSITE INDEX) 7. 前缀索引 (PREFIX INDEX) 8. 覆盖索引 (COVERING INDEX) 1. 主键索引 (PRIMARY KEY) 描述:表…...

picker选择器-年月日选择
从底部弹起的滚动选择器。支持五种选择器,通过mode来区分,分别是普通选择器,多列选择器,时间选择器,日期选择器,省市区选择器,默认是普通选择器。 学习一下日期选择器 平台差异说明 日期选择默…...
)
【LeetCode-494】目标和(回溯动归)
目录 LeetCode494.目标和 题目描述 解法1:回溯法 代码实现 解法2:动态规划 代码实现 LeetCode494.目标和 题目链接 题目描述 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 和 -。对于数组中…...

力扣 188. 买卖股票的最佳时机 IV
题目来源:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iv/description/ C题解:动态规划 思路同力扣 123. 买卖股票的最佳时机 III-CSDN博客,只是把最高2次换成k次。如果思路不清晰,可以将k从0写到4等找找规律…...

【Go语言】Go项目工程管理
GO 项目工程管理(Go Modules) Go 1.11 版本开始,官方提供了 Go Modules 进行项目管理,Go 1.13开始,Go项目默认使用 Go Modules 进行项目管理。 使用 Go Modules的好处是不再需要依赖 GOPATH,可以在任意位…...
美容小程序:让预约更简单,服务更贴心
在当今繁忙的生活节奏中,美容预约常常令人感到繁琐和疲惫。为了解决这个问题,许多美容院和SPA中心已经开始采用美容小程序来简化预约流程,并提供更加贴心的服务。在这篇文章中,我们将引导您了解如何制作一个美容小程序,…...

【递归】:原理、应用与案例解析 ,助你深入理解递归核心思想
递归 1.基础简介 递归在计算机科学中,递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集 例如 递归遍历环形链表 基本情况(Base Case):基本情况是递归函数中最简单的情况,它们通常是递…...
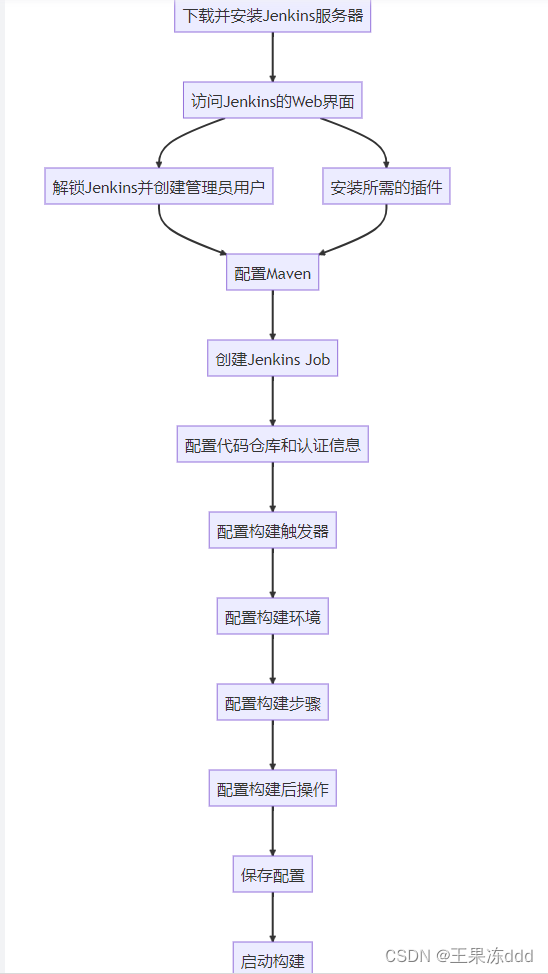
【 Maven 】花式玩法之多模块项目
目录 一、认识Maven多模块项目 二、maven如何定义项目的发布策略 2.1 版本管理 2.2 构建配置 2.3 部署和发布 2.4 依赖管理 2.5 发布流程 三、使用Jenkins持续集成Maven项目 四、总结 如果你有一个多模块项目,并且想将这些模块发布到不同的仓库或目标位置&…...

LeetCode 热题 100 Day01
哈希模块 哈希结构: 哈希结构,即hash table,哈希表|散列表结构。 图摘自《代码随想录》 哈希表本质上表示的元素和索引的一种映射关系。 若查找某个数组中第n个元素,有两种方法: 1.从头遍历,复杂度…...
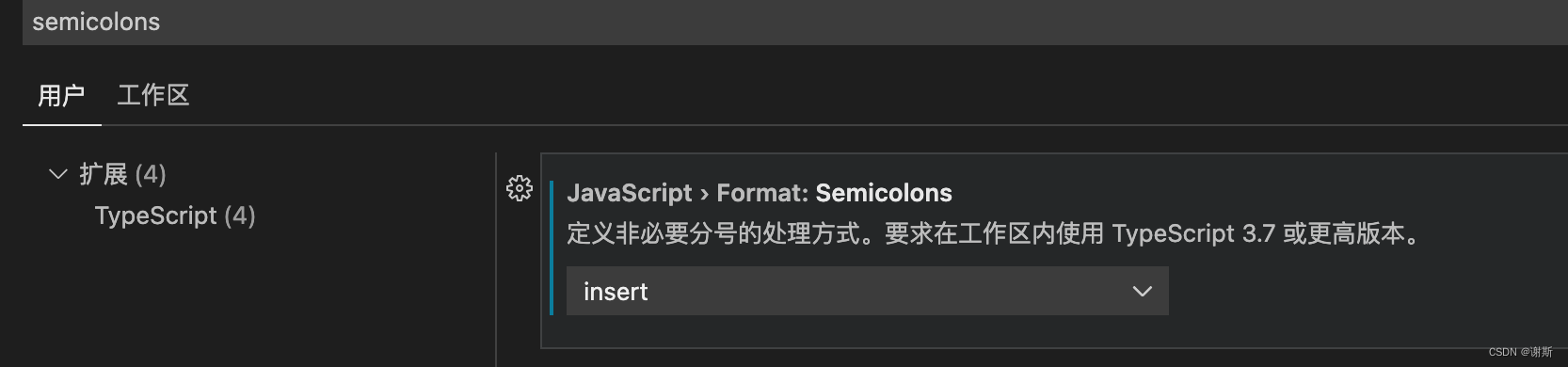
[vscode]vue js部分结尾加分号
设置中寻找 semicolons确定在TypeScript的这个扩展中设置选项为insert...
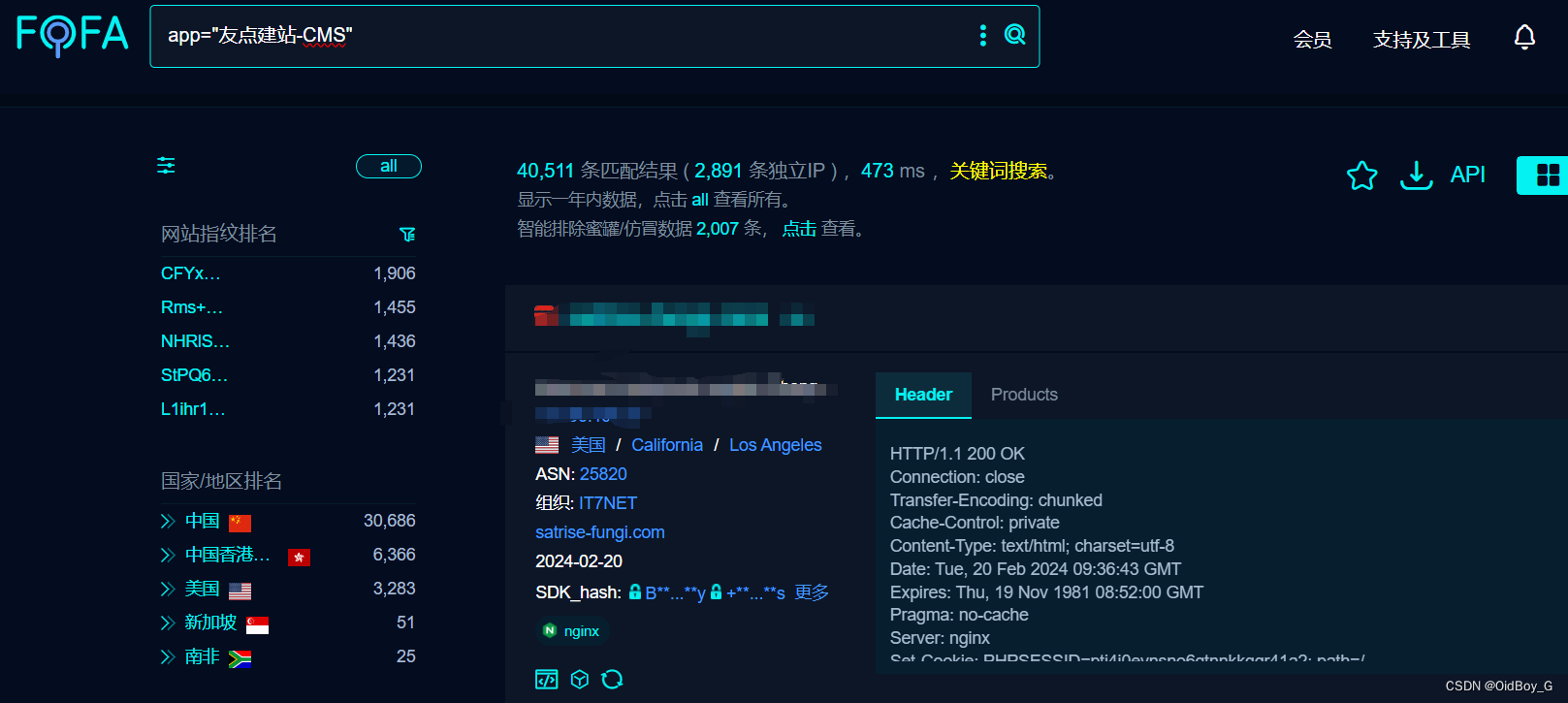
友点CMS image_upload.php 文件上传漏洞复现
0x01 产品简介 友点CMS是一款高效且灵活的网站管理系统,它为用户提供了简单易用的界面和丰富的功能。无论是企业还是个人,都能通过友点CMS快速搭建出专业且美观的网站。该系统支持多种内容类型和自定义模板,方便用户按需调整。同时,它具备强大的SEO功能,能提升网站在搜索…...

C语言—指针(3)
嘿嘿嘿嘿,你看我像指针吗? 不会写,等我啥时候会写了再说吧,真的累了,倦了 1.面试题 1)定义整形变量i; 2)p为指向整形变量的指针变量; 3)定…...
【八股文】面向对象基础
【八股文】面向对象基础 面向对象和面向过程的区别 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。 创建一个对象用什么运算符?对象实体与对象引用有何不同? …...

Day49 647 回文子串 516 最长回文子序列
647 回文子串 给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。 方法一:动态规划: 采用一个二维的dp数组…...

探秘GNU/Linux Shell:命令行的魔法世界
GNU/Linux的Shell是一种特殊的交互式工具,为用户提供了强大的控制和管理Linux系统的方式。在这个博客中,我们将深入了解Shell的基本概念、功能以及不同类型的Shell。 Shell的本质 Shell的核心是命令行提示符,它是用户与Linux系统进行交互的…...
基于STM32F407的coreJSON使用教程
目录 概述 工程建立 代码集成 函数介绍 使用示例 概述 coreJSON是FreeRTOS中的一个组件库,支持key查找的解析器,他只是一个解析器,不能生成json数据。同时严格执行 ECMA-404 JSON 标准。该库用 C 语言编写,设计符合 ISO C90…...
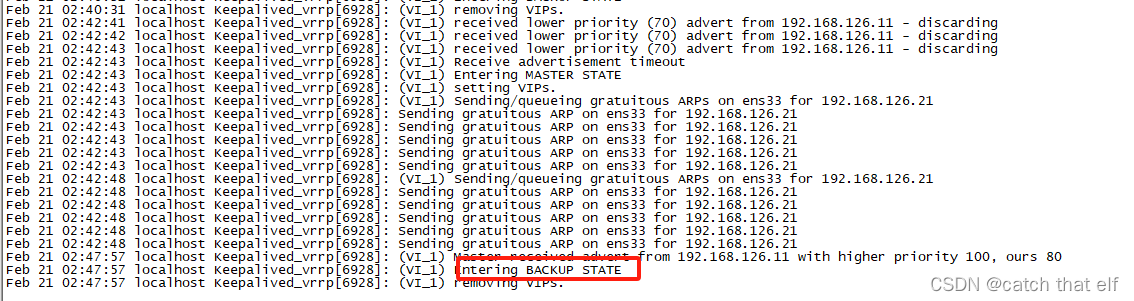
keepalived双主模式测试
文章目录 环境准备部署安装keepavlived配置启动测试模拟Nginx宕机重新启动问题分析 环境准备 测试一下keepalived的双主模式,所谓双主模式就是两个keepavlied节点各持有一个/组虚IP,默认情况下,二者互为主备,同时对外提供服务&am…...

为openclaw配置taotoken作为其ai供应商的详细步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为其AI供应商的详细步骤指南 OpenClaw是一款流行的AI智能体开发工具,它允许开发者通过配置来…...
)
高通8650 AudioReach实战:手把手调试GSL-Passthru-GPR数据流(附动态调试脚本)
高通8650 AudioReach实战:GSL-Passthru-GPR数据流调试全指南 当你在深夜的实验室里盯着示波器上那条毫无波动的音频信号线时,手机突然响起一阵刺耳的电流噪声——这可能是每位音频驱动工程师都经历过的噩梦时刻。高通AudioReach架构作为现代移动音频系统…...

BinaryBomb通关后,我总结了这6个Linux调试与逆向的‘骚操作’
BinaryBomb通关后,我总结了这6个Linux调试与逆向的‘骚操作’ 在计算机系统基础课程中,BinaryBomb实验堪称是检验学生调试与逆向能力的"试金石"。作为一位刚刚通关的"拆弹专家",我想分享那些教科书上不会教、却能让你效率…...

FSearch:Linux终极文件搜索工具完全指南 - 如何实现毫秒级文件查找
FSearch:Linux终极文件搜索工具完全指南 - 如何实现毫秒级文件查找 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 你是否曾在Linux系统中为寻找一个文件而…...

OpenClaw 用户通过 Taotoken 快速接入并启用 Agent 工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw 用户通过 Taotoken 快速接入并启用 Agent 工作流 对于使用 OpenClaw 框架构建 AI Agent 的开发者而言,能够灵…...

AI教材编写必备:低查重AI工具,助力快速完成教材创作!
教材编写工具的选择与使用 在开始写教材之前,选择合适的工具几乎就像是一场“纠结大赛”!如果使用办公软件,功能通常很有限,框架和格式都需要手动去调整;而使用专业的编写工具,又往往因操作繁琐和学习曲线…...

企业级应用如何利用 Taotoken 实现多模型智能路由与成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何利用 Taotoken 实现多模型智能路由与成本控制 对于需要稳定、高效调用大模型的企业开发团队而言,直接对…...

Unity半透明模型单面显示问题的四大解决方案
1. 这个问题到底在烦谁?——从美术交接现场说起Unity里模型导入后“只有一面能看见,翻过去就变透明”,这事儿我见过太多次了。不是程序员写错了Shader,也不是美术导出时漏了法线,而是Unity默认的Front Face Culling&am…...

快速原型开发中如何通过Taotoken灵活试验不同模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速原型开发中如何通过Taotoken灵活试验不同模型效果 在AI应用的原型开发阶段,工程师常常面临一个核心挑战࿱…...

DataRoom:企业级数据可视化大屏设计器的架构创新与实践价值
DataRoom:企业级数据可视化大屏设计器的架构创新与实践价值 【免费下载链接】DataRoom 🔥基于SpringBoot、MyBatisPlus、ElementUI、G2Plot、Echarts等技术栈的大屏设计器,具备目录管理、DashBoard设计、预览能力,支持MySQL、Orac…...