挑战杯 基于LSTM的天气预测 - 时间序列预测
0 前言
🔥 优质竞赛项目系列,今天要分享的是
机器学习大数据分析项目
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据集介绍
df = pd.read_csv(‘/home/kesci/input/jena1246/jena_climate_2009_2016.csv’)
df.head()
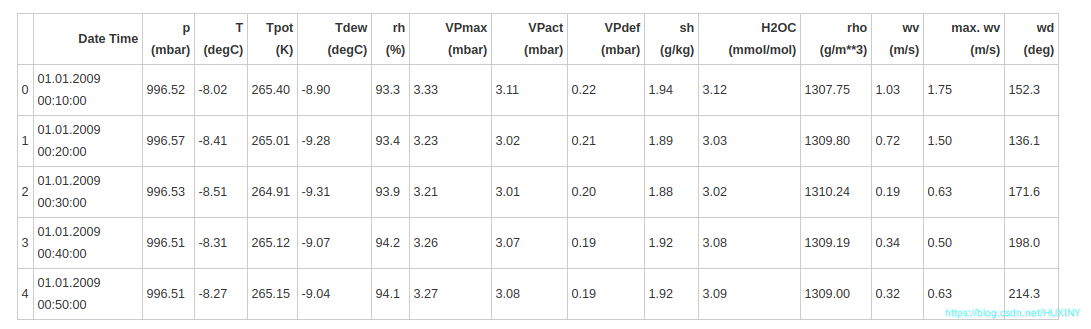
如上所示,每10分钟记录一次观测值,一个小时内有6个观测值,一天有144(6x24)个观测值。
给定一个特定的时间,假设要预测未来6小时的温度。为了做出此预测,选择使用5天的观察时间。因此,创建一个包含最后720(5x144)个观测值的窗口以训练模型。
下面的函数返回上述时间窗以供模型训练。参数 history_size 是过去信息的滑动窗口大小。target_size
是模型需要学习预测的未来时间步,也作为需要被预测的标签。
下面使用数据的前300,000行当做训练数据集,其余的作为验证数据集。总计约2100天的训练数据。
def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i)# Reshape data from (history`1_size,) to (history_size, 1)data.append(np.reshape(dataset[indices], (history_size, 1)))labels.append(dataset[i+target_size])return np.array(data), np.array(labels)
2 开始分析
2.1 单变量分析
首先,使用一个特征(温度)训练模型,并在使用该模型做预测。
2.1.1 温度变量
从数据集中提取温度
uni_data = df[‘T (degC)’]
uni_data.index = df[‘Date Time’]
uni_data.head()
观察数据随时间变化的情况
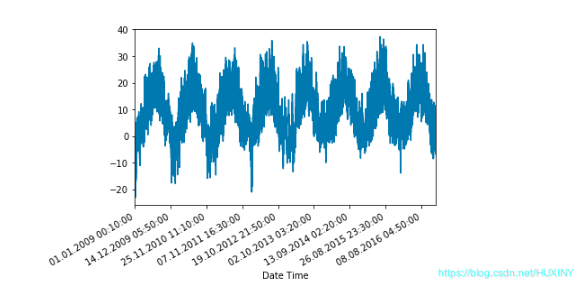
进行标准化
#标准化
uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
uni_data = (uni_data-uni_train_mean)/uni_train_std
#写函数来划分特征和标签
univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT, # 起止区间univariate_past_history,univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,univariate_past_history,univariate_future_target)
可见第一个样本的特征为前20个时间点的温度,其标签为第21个时间点的温度。根据同样的规律,第二个样本的特征为第2个时间点的温度值到第21个时间点的温度值,其标签为第22个时间点的温度……
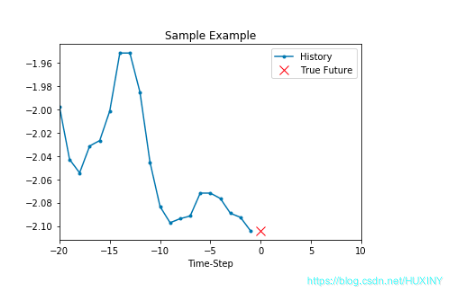
2.2 将特征和标签切片
BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
2.3 建模
simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]), # input_shape=(20,1) 不包含批处理维度
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
2.4 训练模型
EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_univariate, validation_steps=50)
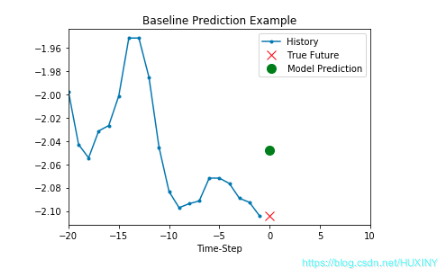
训练过程
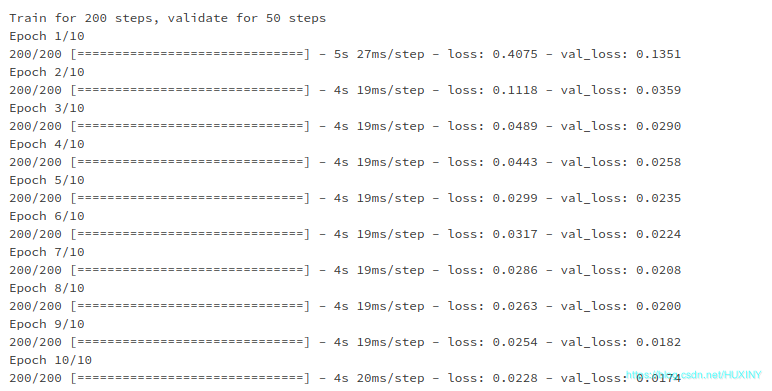
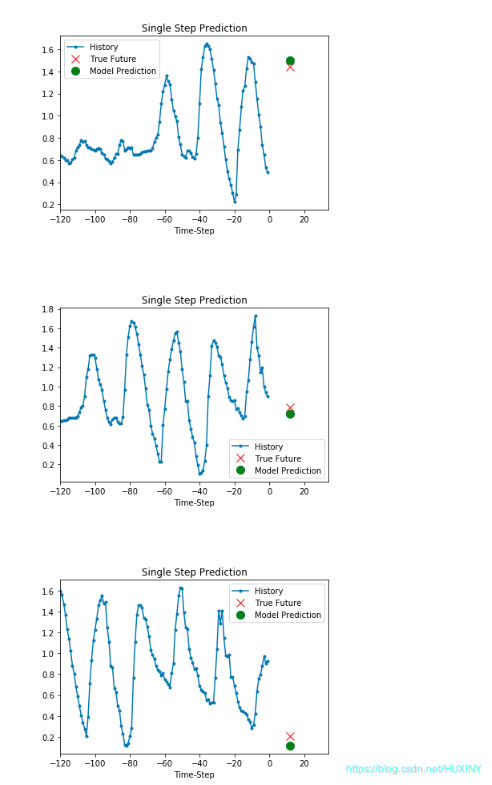
训练结果 - 温度预测结果
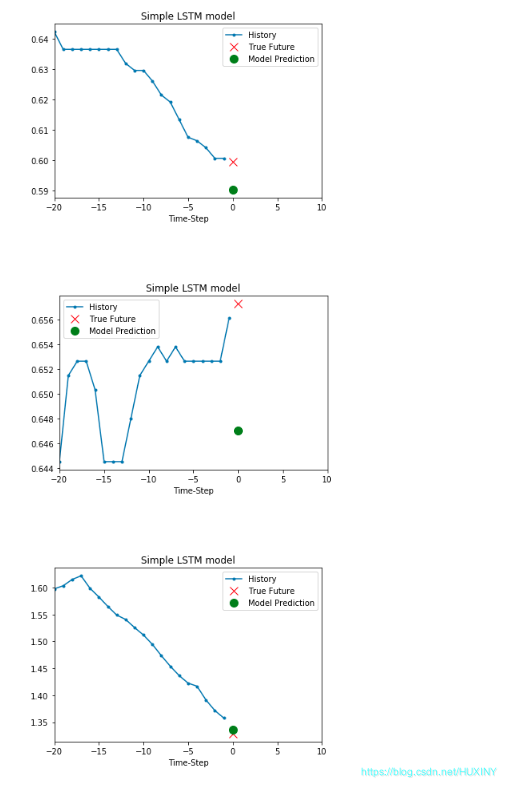
2.5 多变量分析
在这里,我们用过去的一些压强信息、温度信息以及密度信息来预测未来的一个时间点的温度。也就是说,数据集中应该包括压强信息、温度信息以及密度信息。
2.5.1 压强、温度、密度随时间变化绘图
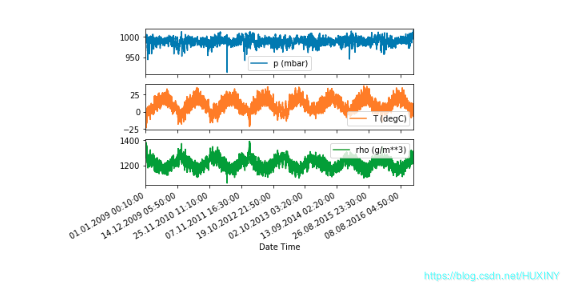
2.5.2 将数据集转换为数组类型并标准化
dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_stddef multivariate_data(dataset, target, start_index, end_index, history_size,target_size, step, single_step=False):data = []labels = []start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i, step) # step表示滑动步长data.append(dataset[indices])if single_step:labels.append(target[i+target_size])else:labels.append(target[i:i+target_size])return np.array(data), np.array(labels)
2.5.3 多变量建模训练训练
single_step_model = tf.keras.models.Sequential()single_step_model.add(tf.keras.layers.LSTM(32,input_shape=x_train_single.shape[-2:]))single_step_model.add(tf.keras.layers.Dense(1))single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_data_single,validation_steps=50)def plot_train_history(history, title):loss = history.history['loss']val_loss = history.history['val_loss']epochs = range(len(loss))plt.figure()plt.plot(epochs, loss, 'b', label='Training loss')plt.plot(epochs, val_loss, 'r', label='Validation loss')plt.title(title)plt.legend()plt.show()plot_train_history(single_step_history,'Single Step Training and validation loss')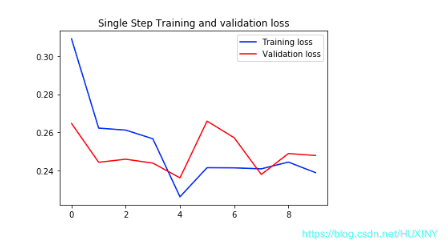
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
挑战杯 基于LSTM的天气预测 - 时间序列预测
0 前言 🔥 优质竞赛项目系列,今天要分享的是 机器学习大数据分析项目 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/po…...
我为什么不喜欢关电脑?
程序员为什么不喜欢关电脑? 你是否注意到,程序员们似乎从不关电脑?别以为他们是电脑上瘾,实则是有他们自己的原因!让我们一起揭秘背后的原因,看看程序员们真正的“英雄”本色! 一、上大学时。 …...

Unity【角色/摄像机移动控制】【1.角色移动】
本文主要总结实现角色移动的解决方案。 1. 创建脚本:PlayerController 2. 创建游戏角色Player,在Player下挂载PlayerController脚本 3. 把Camera挂载到Player的子物体中,调整视角,以实现相机跟随效果 3. PlayerController脚本代码…...

Oracle12cR2之Job定时作业调度器详解
Oracle12cR2之Job定时作业调度器详解 文章目录 Oracle12cR2之Job定时作业调度器详解1.Oracle Job1. 关于Job2. 使用方法 2. Job详细说明1. 查看Job的相关视图2.SYS.DBA_JOBS视图字段详细说明 3. 创建及查看Job1. 创建Job2. 查看运行中的Job 1.Oracle Job 1. 关于Job 在 Oracle…...
python自学...
一、稍微高级一点的。。。 1. 闭包(跟js差不多) 2. 装饰器 就是spring的aop 3. 多线程...

Message Pack 协议详解及应用
文章目录 一、Message Pack是什么二、Message Pack的语法规则三、Message Pack相关链接四、Message Pack应用场景五、MessagePack 兼容性与特点 一、Message Pack是什么 Message Pack是一种高效的二进制序列化格式,用于在不同的应用程序之间进行数据交换。它类似于J…...
智慧社区管理系统:构建未来的生活模式
在这个信息化、智能化的时代,我们期待的不再是简单的居住空间,而是一个集安全、便捷、舒适、环保于一体的智能化社区。为此,我们推出了全新的智慧社区管理系统,旨在将先进的科技力量引入社区管理,为居民提供更优质的生…...

Rocky 8.9 Kubespray v2.24.0 在线部署 kubernetes v1.28.6 集群
文章目录 1. 简介2. 预备条件3. 基础配置3.1 配置hostname3.2 配置互信 4. 配置部署环境4.1 在线安装docker4.2 启动容器 kubespray4.3 编写 inventory.ini4.4 关闭防火墙、swap、selinux4.5 配置内核模块 5. 部署6. 集群检查 1. 简介 kubespray 是一个用于部署和管理 Kuber…...
新版AI系统ChatGPT源码支持GPT-4/支持AI绘画去授权
源码获取方式 搜一搜:万能工具箱合集 点击资源库直接进去获取源码即可 如果没看到就是待更新,会陆续更新上 新版AI系统ChatGPT网站源码支持GPT-4/支持AI绘画/Prompt应用/MJ绘画源码/PCH5端/免授权,支持关联上下文,意间绘画模型…...
学习鸿蒙基础(5)
一、honmonyos的page路由界面的路径 新建了一个page,然后删除了。运行模拟器的时候报错了。提示找不到这个界面。原来是在路由界面没有删除这个page。新手刚接触找了半天才找到这个路由。在resources/base/profile/main_pages.json 这个和微信小程序好类似呀。 吐槽…...

Tuxera NTFS2024最新中文版支持M1/M2/M3苹果全系机型
Tuxera NTFS的传输速度会受到多种因素的影响,包括硬件配置、文件大小、存储设备的性能等。因此,无法给出具体的传输速度数值。 不过,根据一些用户的使用经验和测试数据,Tuxera NTFS的传输速度通常都非常快,能够满足大…...

【Python】OpenCV-图片添加水印处理
图片添加水印处理 1. 引言 图像处理中的水印添加是一种常见的操作,用于在图片上叠加一些信息或标识。本文将介绍如何使用OpenCV库在图片上添加水印,并通过详细的代码注释来解释每一步的操作。 2. 代码示例 以下是一个使用OpenCV库的简单代码示例&…...

Milvus数据库介绍
参考:https://www.xjx100.cn/news/1726910.html?actiononClick Milvus 基于FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量…...

notepad++的下载与使用
1.进入官网下载 https://notepad-plus-plus.org/ 点击下载即可 2.选择中文简体 3.建议安装在D盘 其余步骤按照指示就行 4.安装后这几个是必选的 设置完成后就可以写中文了 以此为例 结果为...

论UI的糟糕设计:以百度网盘为例
上面这一排鼠标一经过就会弹出来(不是点才弹出来),然后挡住你的各种操作, 弹出来时你就必须等它消失,卡一下才能操作。 在用户顺畅地操作内容时,经常就卡一下、卡一下、卡一下…… 1、比如鼠标从下到上&am…...

【Spring】三级缓存
目录标题 触发所有未加载的实例a - 开始getBean( doGetBean) - 获取单例beangetSingleton() - 获取单例beancreateBean(doCreateBean) - 创建beancreateBeanInstance - 创建并返回beanaddSingletonFactory -放三级缓存populateBea…...
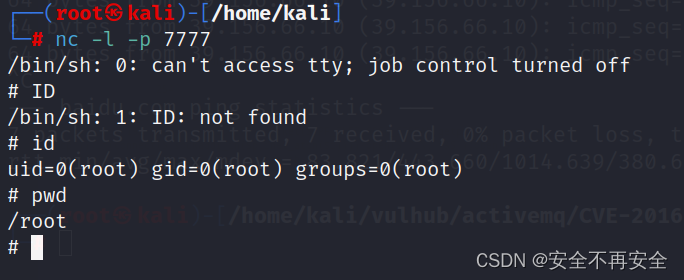
CVE-2016-3088(ActiveMQ任意文件写入漏洞)
漏洞描述 1、漏洞编号:CVE-2016-3088 2、影响版本:Apache ActiveMQ 5.x~5.13.0 在 Apache ActiveMQ 5.12.x~5.13.x 版本中,默认关闭了 fileserver 这个应用(不过,可以在conf/jetty.xml 中开启);…...
-JavaPythonC++JS实现))
270.【华为OD机试真题】字符串拼接(深度优先搜索(DFS)-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-字符串拼接二.解题思路三.题解代码Python题解代…...
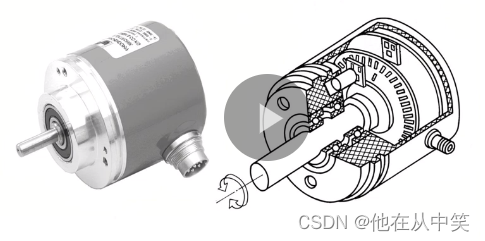
线阵相机参数介绍之轴编码器控制
1.1 功能介绍 编码器是将检测对象的运动与相机拍摄取图相匹配的设备,也即检测对象运动一定距离,相机就拍摄一定行高的图像。 编码器会将检测对象的实际位移转换为固定数量电信号。例如:编码器的精度是2000p/r,该参数的含义是编码器每转一圈输…...
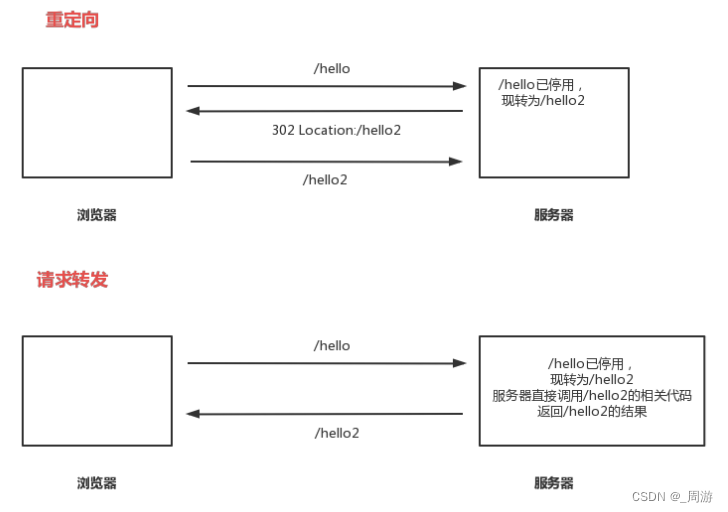
【JavaEE】_HTTP响应
目录 1. 首行 2. 报头header 3.空行 4. 正文body 1. 首行 响应首行:版本号状态码状态码描述; HTTP状态码描述了这次响应的结果(比如成功、失败,以及失败原因等); 1. HTTP状态码有: &#…...

【.NET新特性·第2篇】C# 12 全特性回顾:语法糖的盛宴
C# 12 带来了主构造函数、集合表达式、Inline Arrays 等 8 个新特性,让代码更简洁 版本定位 适用版本:.NET 8 | C# 12 前置知识:C# 11 基础语法 背景 C# 11 引入了原始字符串字面量、list patterns 等特性,但开发者们期待更多语法…...

大模型MoE架构揭秘:为何每次只用2%参数
1. 这不是“参数越多越强”的简单故事:拆解大模型里被悄悄激活的那2% 你可能已经看过不少标题党文章,说“GPT-4有1.8万亿参数”“DeepSeek-R1有6710亿参数”,然后配上一张闪闪发光的数字图,再加一句“人类大脑才860亿神经元&#…...

华为OD机试真题 新系统 2026-05-20 PythonJS 实现【等距二进制判断】
目录 题目 思路 Code 题目 对于一个二进制数,我们定义相邻两个 1 之间的 0 的数量为它们两个之间的距离,如 1001011,相邻两个 1 之间的距离从左到右分别为 2、1、0。 现在如果一个整数转化为二进制数满足如下条件: 1. 包含不少于 3 个 1 2. 所有相邻数字 1 之间的距离都…...

清单来了:盘点2026年倍受青睐的AI论文平台
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂、实测能大幅提速的AI论文平台来袭,覆盖选题构思、文献分析、内容生成、格式排版等核心场景,助你高效搞定论文,轻松应对学术挑战。 一、全流程王者:一站式搞定论文全链路&…...
)
ElevenLabs云南话语音定制化指南(独家披露官方未公开的phoneme alignment bypass技巧)
更多请点击: https://codechina.net 第一章:ElevenLabs云南话语音定制化全景概览 ElevenLabs 作为全球领先的AI语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但尚未在官方API中直接开放云南话(属西南…...

小爱音箱音乐解锁终极指南:简单三步实现智能音箱音乐自由
小爱音箱音乐解锁终极指南:简单三步实现智能音箱音乐自由 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经对小爱音箱说"播放周杰伦"…...

2026 年程序员生存指南:AI 时代,哪些技能不会被淘汰?
2026 年程序员生存指南:AI 时代,哪些技能不会被淘汰? 导读 当 AI 能秒级生成 CRUD 代码、自动补全单元测试、甚至一键优化慢 SQL 时,“程序员会不会被 AI 淘汰?”成了悬在每个人头顶的达摩克利斯之剑。 焦虑没有用&…...

java之微信机器人二次开发文档
WTAPI框架weixin ipad 协议 在微信个人号二次开发中的应用,涵盖技术架构、核心功能、开发流程及安全合规要点,为开发者提供系统化解决方案。 ⚡ 核心能力 好友管理:添加好友、删除好友、修改备注、创建标签、获取好友列表、搜索好友信息 消息…...
如何用Translumo实现实时屏幕翻译:打破语言障碍的终极指南
如何用Translumo实现实时屏幕翻译:打破语言障碍的终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 还在…...

从零玩转 Linux:网络配置、软件安装及 Docker 实战
下载镜像地址 一、基础命令篇 显示网络状态工具 netstat -nltup #显示当前服务以及端口信息等 查看某个端口是否开启 1.2.1、使用 netstat 命令 sudo netstat -tuln | grep 80 1.2.2、使用 ss 命令 sudo ss -tuln | grep 80 1.2.3、使用 lsof 命令 sudo lsof -i :80 1.2.4、使用…...