CTR之行为序列建模用户兴趣:DIN
在前面的文章中,已经介绍了很多关于推荐系统中CTR预估的相关技术,今天这篇文章也是延续这个主题。但不同的,重点是关于用户行为序列建模,阿里出品。
概要
论文:Deep Interest Network for Click-Through Rate Prediction
链接:https://arxiv.org/pdf/1706.06978.pdf
这篇论文是阿里2017年发表在KDD上,提出了一种新的CTR建模方法:Deep Interest Network (DIN),它最大的创新点是引入了局部激活单元(local activation unit,其实是一种Attention机制),对于不同的候选item,可以根据用户的历史行为序列,动态地学习用户的兴趣表征向量。
- 在此之前,在DNN中,对于用户历史行为序列的处理方法一般都是pooling(sum pooling或者mean pooling等),即等同对待历史序列中的所有行为,无关于当前的候选item,如下图所示:
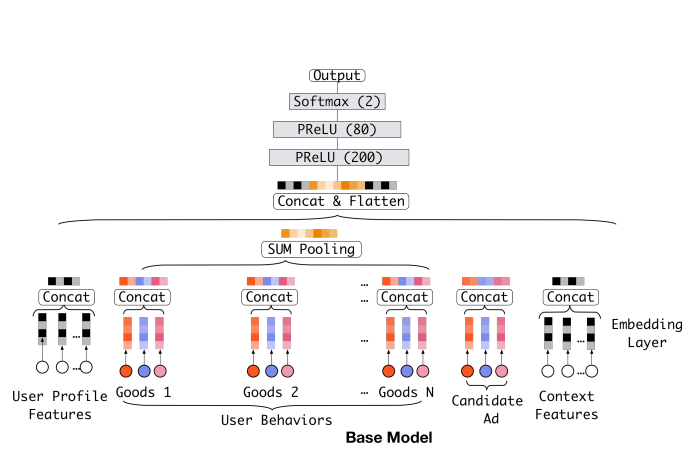
- **但用户当前的兴趣或者说当前对某个特定的item是否感兴趣,实际上应该只与某些行为是相关的。**如下图所示,用户对Candidate的大衣是否感兴趣,其实主要跟用户看过的衣服类型比较有关联,而跟其它如包包和鞋子则基本不相关。

- 联想到FMs中,因为存在候选item和历史行为item的交叉特征,也是有类似的思想存在,但实际推荐系统工程中,很难实现所有item的交叉计算
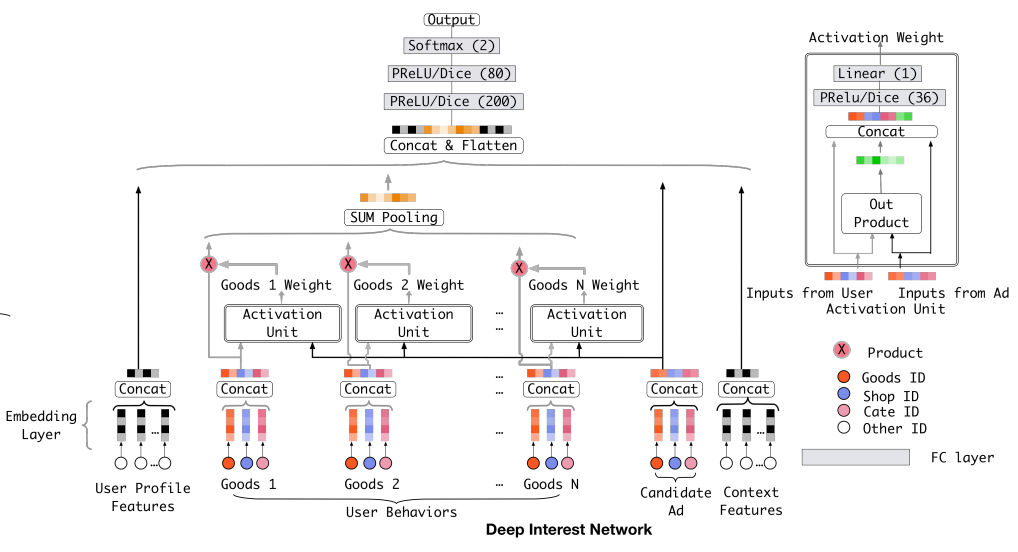
DIN的整体网络结构其实与Base Model是差不多的,唯一的区别就是在User Behaviors建模上,如下图:
Base Model
Feature Reresentation.
首先,离散特征会进行one-hot或者multi-hot编码:
x = [ t 1 T , t 2 T , . . . , t M T ] T , t i ∈ R K i x=[t^T_1,t^T_2,...,t^T_M]^T,\ t_i \in R^{K_i} x=[t1T,t2T,...,tMT]T, ti∈RKi
- K i K_i Ki 是第i个field的unique feature数量, t i [ j ] ∈ { 0 , 1 } t_i[j] \in \{0,1\} ti[j]∈{0,1}是一个0-1向量;
- ∑ j = 1 K i t i [ j ] = k \sum_{j=1}^{K_i}t_i[j]=k ∑j=1Kiti[j]=k,当k=1时, t i t_i ti是one-hot编码,k>1则是multi-hot编码。
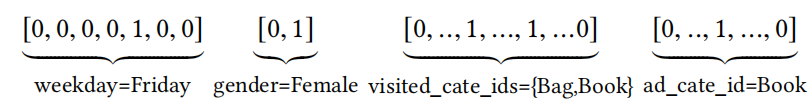
Embedding layer.
对于第i个field的特征 t i t_i ti,有着对应的embedding字典: W i = [ w 1 i , w 2 i , . . . , w K i i ] ∈ R D × K i W^i=[w^i_1,w^i_2,...,w^i_{K_i}] \in \mathbb{R}^{D \times K_i} Wi=[w1i,w2i,...,wKii]∈RD×Ki。而 w j i ∈ R D w^i_j \in R^D wji∈RD则是维度为D的embedding向量。
Embedding操作其实是一种表检索机制,具体如下:
- 如果 t i t_i ti是one-hot向量,并且第j个元素 t i [ j ] = 1 t_i[j]=1 ti[j]=1,那么 t i t_i ti的embedding表征则为 e i = w j i e_i=w^i_j ei=wji
- 如果 t i t_i ti是multi-hot向量,并且 t i [ j ] = 1 , j ∈ { i 1 , i 2 , . . . , i k } t_i[j]=1,\ j\in\{i_1,i_2,...,i_k\} ti[j]=1, j∈{i1,i2,...,ik},那么 t i t_i ti的embedding表征则是一个embedding向量列表: { e i 1 , e i 2 , . . . , e i k } = { w i 1 i , w i 2 i , . . . , w i k i } \{e_{i_1},e_{i_2},...,e_{i_k}\}=\{w^i_{i_1},w^i_{i_2},...,w^i_{i_k}\} {ei1,ei2,...,eik}={wi1i,wi2i,...,wiki}
Pooling layer and Concat layer.
像这种multi-hot向量特征,其实就非常符合用户的行为序列特点:序列即代表存在多个行为(如点击了多个商品),并且每一个不同的用户的行为序列长度也不同。一般的处理方法则是通过pooling layer,将embedding向量列表转换为固定长度的向量(因为MLP只能处理固定长度的输入):
e i = p o o l i n g ( e i 1 , e i 2 , . . . , e i k ) e_i=pooling(e_{i_1},e_{i_2},...,e_{i_k}) ei=pooling(ei1,ei2,...,eik)
而最常用的pooling layer则是sum pooling和average pooling,即将列表中的所有向量进行element-wise的相加或者均值操作。
接着,再将所有处理过的表征向量进行拼接,得到的最终的表征向量输入。
MLP&Loss.
MLP仍然是常规的全连接网络层,为了自动学习特征组合,如PNN、Wide&Deep和DeepFM。
Base Model的目标函数使用negative log-likehood:
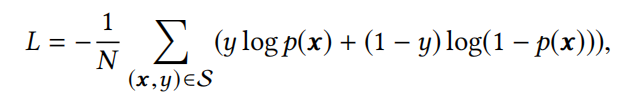
p ( x ) p(x) p(x)是最终网络softmax layer之后的输出,代表样本x是否被点击的概率。
Deep Interest Network
一开始提到了,用户行为序列pooling的缺点在于同等地对待序列中所有行为的item,并且对于任何候选item,同一个用户的行为序列计算的兴趣表征向量是同样不变的。另外,论文还指出固定的有限制的维度的表征向量,成为了表征用户多样的兴趣的瓶颈,但向量的维度扩展又严重增加了学习参数的规模和存储负担,这在实时推荐系统中是难以接受的,并且在有限的训练样本下也容易导致过拟合。
在这种动机下,提出了能够考虑历史行为序列和候选集的相关性来自适应计算用户的兴趣表征向量的模型DIN。通过解刨用户的点击行为动机,发现与展示的item相关的历史行为极大地贡献了点击。
给定一个候选item,DIN将attention给到局部活跃的历史行为的表征,来实现这种兴趣表征自适应计算。具体做法是引入了一种局部激活单元,应用在用户的行为序列特征上,数学上则是一种加权sum pooling来得到在候选item A A A 下用户的兴趣表征 v U v_U vU,如下式:
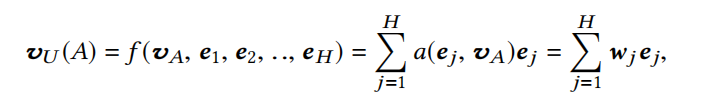
{ e 1 , e 2 , . . . , e H } \{e_1,e_2,...,e_H\} {e1,e2,...,eH} 是用户历史行为的embedding向量列表,长度为H, v A v_A vA则为候选item的embedding向量。
- a ( ⋅ ) a(\cdot) a(⋅) 是一种前馈网络,其输出便作为激活权重。
- 如下图,两个embedding向量的激活权重计算是原向量拼接它们的out product作为输入,喂给后续的网络,输出一个标量权重。这是一种显式的知识,能够帮助相关性建模。
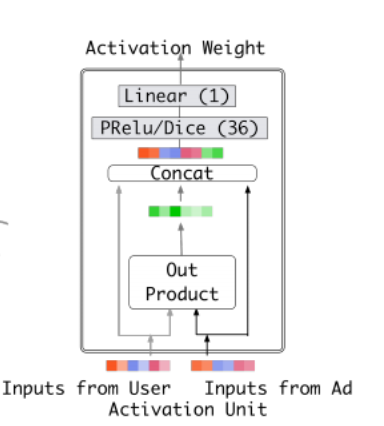
- 从公式明显看出,对于不同的候选item, v U v_U vU的计算结果是不同的。
Mini-batch Aware Regularization
过拟合是深度网络训练中一个关键的挑战,比如加入一些细粒度的特征,比如商品ID,模型的效果会在第一个epoch之后迅速地下降。
通常的做法是加入L1或者L2正则惩罚。在没有加入正则惩罚的情况下,每一个batch中,只有那些出现过即不为0的离散特征的参数需要更新,但L2正则惩罚却会计算整个参数的L2-norm,这会造成极其沉重的计算。
因此,论文提出Mini-batch Aware Regularization,只计算在每个batch出现过的离散特征的参数的L2-norm,并且ID类即离散特征的embedding矩阵贡献了CTR网络的绝大部分参数,只在ID类特征参数上应用。
记 W ∈ R D × K W \in \mathbb{R}^{D\times K} W∈RD×K 为embedding矩阵,embedding向量维度为D,离散特征的空间维度,即离散特征的unique id数量。在 W W W 上扩展 l 2 l_2 l2 正则如下式:
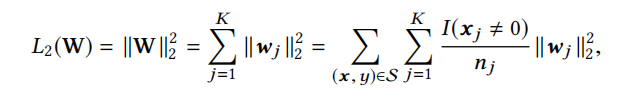
w j ∈ R D w_j \in \mathbb{R}^D wj∈RD 是第j个embedding向量, I ( x j ≠ 0 ) I(x_j \neq 0) I(xj=0) 表示实例x的feature id是 j j j, n j n_j nj 则表示feature id j j j 在所有样本出现的次数。
上式可以简化为下式:
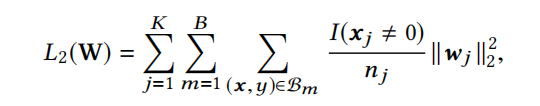
B是mini-batches的批次数量, B m \mathcal{B}_m Bm 则是第m个批次。
α m j = m a x ( x , y ) ∈ B m I ( x j ≠ 0 ) \alpha_{mj}=max_{(x,y)\in \mathcal{B}_m} I(x_j \neq 0) αmj=max(x,y)∈BmI(xj=0),表示第m个批次 B m \mathcal{B}_m Bm 至少有一个实例存在feature id j j j,那么,上式又可以近似等于下式:

最后,加入mini-batch aware regularization的embedding参数的梯度下降如下式:

自适应的激活函数
PReLU是ReLU之后最经常被使用的激活函数,其公式如下式:
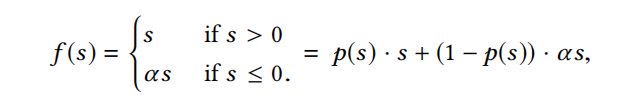
PReLU优化了ReLU在输入s小于0的场景,但仍然存在hard rectified(矫正) point,即当输入s=0时,这可能会让每一个网络层的输入变成不同的分布。
基于这种考虑,论文提出了一种数据自适应的激活函数Dice,如下式:
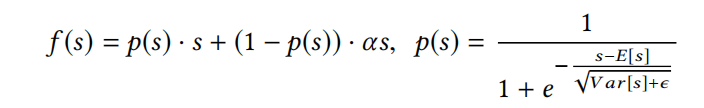
看到这个公式,很容易就联想到batch normalization,这两者的计算存在很多相似之处。Dice在训练阶段, E [ s ] E[s] E[s]和 V a r [ s ] Var[s] Var[s]是每一个批次的输入的均值和方差;而在推理阶段, E [ s ] E[s] E[s]和 V a r [ s ] Var[s] Var[s]则是所有训练批次数据的移动均值版本,与bn是一样的方式。
ϵ \epsilon ϵ是一个平滑常量,避免出现分母为0的情况。
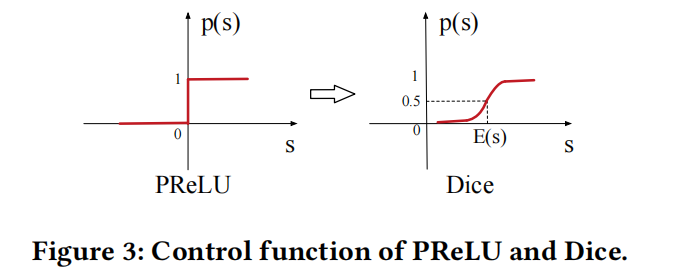
Dice可以看成是PReLU的泛化版本,其关键idea是根据数据去自适应调节rectified point。 当 E [ s ] = 0 a n d V a r [ s ] = 0 E[s]=0\ and\ Var[s]=0 E[s]=0 and Var[s]=0 时,Dice则退化为PReLU,两者的对比如下图:
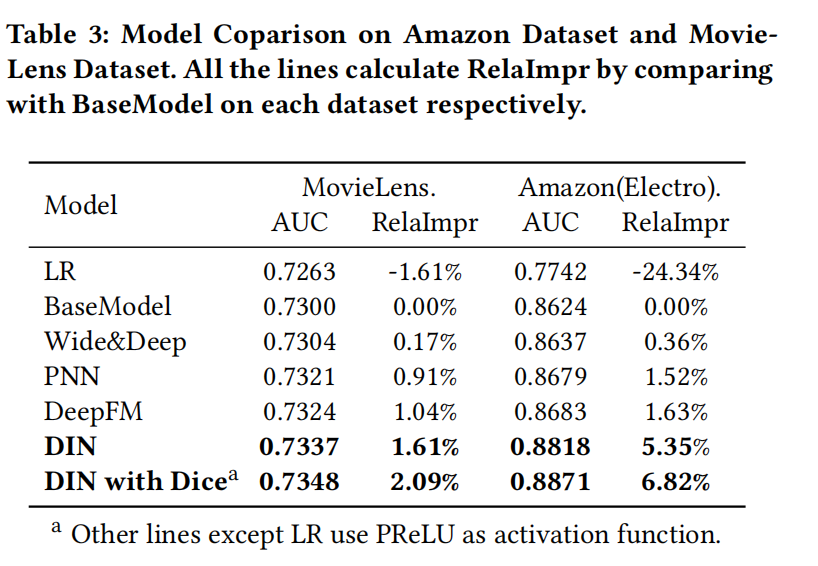
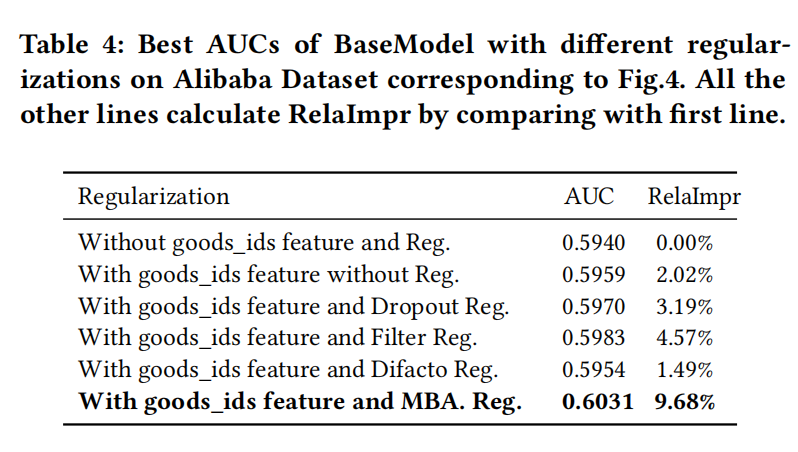
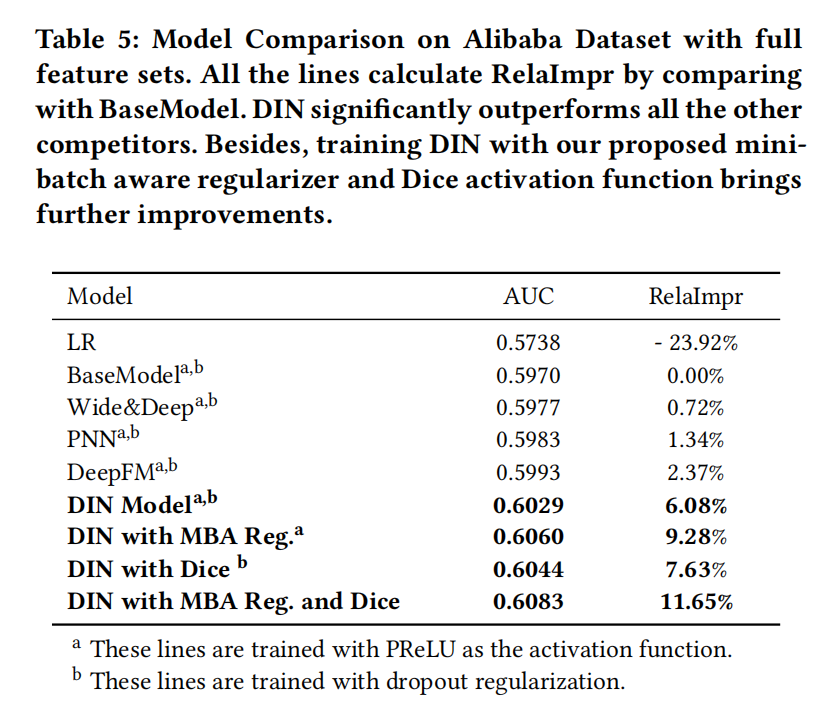
实验结果
指标
论文衡量模型效果,使用的指标是用户加权的AUC,为了简化,还是以AUC表示,如下式:

n是用户的数量,# i m p r e s s i o n i impression_i impressioni和 A U C i AUC_i AUCi是第i个用户的曝光量和AUC。
另外,还加入了相比Base Model的相对提升指标,如下式:

代码实现
git
推荐系统CTR建模系列文章:
CTR特征重要性建模:FiBiNet&FiBiNet++模型
CTR预估之FMs系列模型:FM/FFM/FwFM/FEFM
CTR预估之DNN系列模型:FNN/PNN/DeepCrossing
CTR预估之Wide&Deep系列模型:DeepFM/DCN
CTR预估之Wide&Deep系列(下):NFM/xDeepFM
CTR特征建模:ContextNet & MaskNet(Twitter在用的排序模型)
相关文章:
CTR之行为序列建模用户兴趣:DIN
在前面的文章中,已经介绍了很多关于推荐系统中CTR预估的相关技术,今天这篇文章也是延续这个主题。但不同的,重点是关于用户行为序列建模,阿里出品。 概要 论文:Deep Interest Network for Click-Through Rate Predict…...

Java使用Redis实现分页功能
分页功能实现应该是比较常见的,对于redis来说,近期刷题就发现了lrange、zrange这些指令,这个指令怎么使用呢? 我们接下来就来讲解下。 目录 指令简介lrangezrange Java实现Redis实现分页功能 指令简介 lrange lrange 是 Redis 中…...

Qt标准对话框设置
Qt标准对话框设置,设置字体、调色板、进度条等。 #include "mainwindow.h" #include "ui_mainwindow.h"MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), ui(new Ui::MainWindow) {ui->setupUi(this); }MainWindow::~MainWi…...

如何让Obsidian实现电脑端和安卓端同步
Obsidian是一款知名的笔记软件,支持Markdown语法,它允许用户在多个设备之间同步文件。要在安卓设备上实现同步,可以使用remote save插件,以下是具体操作步骤: 首先是安装电脑端的obsidian,然后依次下载obs…...

windows系统中jenkins构建报错提示“拒绝访问”
一.背景 之前徒弟在windows中安装的jenkins,运行的时候用的是java -jar jenkins.war来运行的。服务器只有1个盘符C盘。今天说构建错误了,问我修改了啥,我年前是修改过构建思路的。 二.问题分析 先看jenkins构建任务的日志,大概是xcopy命令执…...

服务器防火墙的应用技术有哪些?
随着互联网的发展,网络安全问题更加严峻。服务器防火墙技术作为一种基础的网络安全技术,对于保障我们的网络安全至关重要。本文将介绍服务器防火墙的概念和作用,以及主要的服务器防火墙技术,包括数据包过滤、状态检测、代理服务、…...

力扣:40. 组合总和 II
回溯: 1.先声明好大集合和小集合,在调用回溯函数,终止条件为sumtarget,要进行剪枝操作减少遍历的次数,去重操作防止数组中有两个相同的值来组成的集合相同。 class Solution {List<List<Integer>> li1ne…...

Java设计模式——责任链模式
当一个请求需要在多个对象之间传递,每个对象都可能处理该请求或将其传递给下一个对象。在这种情况下,需要避免将发送者与接收者之间的耦合,以及确定请求的处理方式。此时可使用责任链模式,它的优点有降低耦合度(无需关…...

c++面试
c基础 面试题 1:变量的声明和定义有什么区别 1.定义:为变量分配地址和存储空间,声明:不分配地址。 2.一个变量可以在多个地方声明,但是只在一个地方定义。 3.加入 extern 修饰的是变量的声明,说明此变量将在文件以外或在文件后…...
[ansible] playbook运用
一、复习playbook剧本 --- - name: first play for install nginx #设置play的名称gather_facts: false #设置不收集facts信息hosts: webservers:dbservers #指定执行此play的远程主机组remote_user: root #指定执行此play的用…...

MSSQL运用
做过的事情,隔几年又再做相同的事情,做一下记录。 角色与权限 创建账号与设定执行存储过程权限 Use testDB CREATE LOGIN acct WITH PASSWORDp1 CREATE USER acct FOR LOGIN acct GO GRANT EXECUTE ON SP_Test TO acct; GO 存储过程 调用写好的SQL语…...

linux命令--pidof
文章目录 linux命令--pidof linux命令–pidof pidof 是Linux系统中用来查找正在运行进程的进程号(pid)的工具,功能类似pgrep和ps。 pidof命令用于查找指定名称的进程的进程号id号。 语法 pidof(选项)(参数) 选项 -s:仅返回一个进程号&…...

计算机视觉发展的方向和潜在机会
计算机视觉发展的方向 文章目录 计算机视觉发展的方向计算机视觉发展的方向潜在机会 计算机视觉发展的方向 未来计算机视觉发展的方向可能包括以下几个方面: 深度学习和神经网络:深度学习已经成为计算机视觉领域的重要技术,未来将继续深入研…...

Java Web(六)--XML
介绍 官网:XML 教程 为什么需要: 需求 1 : 两个程序间进行数据通信?需求 2 : 给一台服务器,做一个配置文件,当服务器程序启动时,去读取它应当监听的端口号、还有连接数据库的用户名和密码。spring 中的…...

智慧城市的新宠儿:会“思考”的井盖
在城市化飞速发展的今天,我们或许未曾过多地关注那些平凡却至关重要的井盖。它们无声地矗立在城市的每个角落,守护着深藏于地下的城市生命线,然而,这些井盖并未满足于传统的角色,它们正逐步融入智慧城市的宏大画卷中&a…...

Linux限定网络和工具环境下时间同步
使用curl或wget工具同步某网站时间到本地环境。 使用curl工具 #!/bin/bash# Replace example.com with the domain you want to query url"http://example.com"# Fetch HTTP header and extract Date field date_str$(curl -sI "$url" | grep -i "^…...
——文本查询计划)
SQL Server查询计划(Query Plan)——文本查询计划
6.4.1. 文本查询计划 SQL Server中,除了通过GUI工具获取图形查询计划外,我们还可以通过相关命令获取文本格式的查询计划,这里惯称其为文本查询计划。文本查询计划中,SQL Server通过单独的一行来表示查询计划中的每个操作符,通过缩进格式和竖线(字符“|”)来…...

2024年2月的TIOBE指数,go语言排名第8,JAVA趋势下降
二月头条:go语言进入前十 本月,go在TIOBE指数前10名中排名第8。这是go有史以来的最高位置。当谷歌于2009年11月推出Go时,它一炮而红。在那些日子里,谷歌所做的一切都是神奇的。在Go出现的几年前,谷歌发布了GMail、谷歌…...

机器人十大前沿技术(2023-2024年)
2023-2024年机器人十大前沿技术 1. 具身智能与垂直大模型 具身智能是指拥有自主感知、交互和行动能力的智能体,能够与环境进行实时互动,从而实现对环境的理解和适应。 “大模型”是指在深度学习和人工智能领域中,使用大量参数和数据进行训…...

Spring: MultipartFile和File的区别
文章目录 一、MultipartFile和File对比1、 MultipartFile:2、File: 一、MultipartFile和File对比 MultipartFile 和 File 是用于处理文件上传的两种不同类型,主要在不同的编程环墨境中使用。 1、 MultipartFile: - MultipartFi…...

全志T113-S3开发板网络配置实战:从DHCP到静态IP与故障排查
1. 项目概述:从零上手T113-S3的网络配置刚拿到一块新的全志T113-S3开发板,比如眺望电子的EVM-T113-S3,第一件事你会做什么?我的习惯是,先把它“连上网”。这听起来简单,但却是后续所有高级操作——无论是通…...

用户分享 + 消费排队福利模式合规落地指南:5 大实体行业通用方案
注:本文所有数据为单门店经营案例参考,不代表所有门店的经营收益,实际效果受多种因素影响一、多数社区门店的经营困境:营销预算有限,获客留客难度大不少社区夫妻店的经营者,都会遇到类似的经营难题…...

MySQL事务与锁机制深度解析
摘要:事务与锁是 MySQL 并发控制的两大基石。本文从 ACID 四大特性出发,深入讲解 InnoDB 的 MVCC 多版本并发控制机制、四种隔离级别下的并发问题、七种锁类型(从表锁到行锁、间隙锁、Next-Key 锁),以及死锁的产生原因…...

奇门对接顺丰电子面单:从200行“祖传代码”到优雅重构的经验分享
一、背景:那年写下的“能跑就行” 在我们的电商WMS系统中,发货环节需要通过菜鸟奇门电子面单接口向顺丰等快递公司申请运单号。这段核心代码写于多年前,当时的业务需求比较简单:只支持淘宝/天猫订单,快递也只有顺丰。…...

水下叶轮脉动压力测试:Kulite压力传感器强在哪?安装门槛怎么破?
水下叶轮脉动压力测试这事,干过的朋友都懂——看着挺简单,上手哪一步都可能翻车。传感器防水、空间狭小、叶轮旋转、信号采集困难——随便拎出一个,都够让人头疼的。折腾了一圈,有一个型号被反复验证为绕不开的经典:Ku…...

2026 在线考试系统哪个好?功能、客户、方案、优势与服务全对比
前言数字化转型浪潮下,在线考试系统已从教育、企业的辅助工具,升级为覆盖教学考核、人才招聘、员工培训、政务考核、资格认证、知识竞赛的核心数字基础设施。据艾瑞咨询 2026 年 2 月发布的《中国线上考试行业发展白皮书》显示,2025 年中国线…...
)
git常用使用命令(亲测,可以,自己的笔记)
一本 官方中文版 书分享给大家(说明:本人多次阅读,体会是容易入门,读起来很顺手,但是讲的不深入) https://git-scm.com/book/zh/v2 一、git官方使用命令: usage: git [--version] [--help] [-C…...
)
限时开放!ElevenLabs未公开东北话语音微调接口文档(含token绕过+方言embedding注入完整POC)
更多请点击: https://codechina.net 第一章:ElevenLabs东北话语音微调接口的发现与边界定义 ElevenLabs 官方 API 文档未显式标注“东北话”支持,但通过其语音克隆(Voice Cloning)与声音微调(Fine-tuning&…...
)
告别低速串口:用STM32的FSMC总线驱动FPGA,实现高速数据交换的完整流程(基于STM32F407)
STM32与FPGA的高速数据通道:基于FSMC总线的实战设计指南 在嵌入式系统开发中,数据吞吐量常常成为制约系统性能的关键瓶颈。当STM32微控制器需要与FPGA进行大数据量交互时——无论是实时图像处理、高速数据采集还是复杂算法加速——传统的串行通信接口如…...

Redis 集群脑裂深度剖析:成因、危害与防丢失策略
Redis 集群脑裂深度剖析:成因、危害与防丢失策略 1. 引言 在 Redis 高可用架构中,主从复制 哨兵(Sentinel)模式为我们提供了自动故障转移的能力。然而,在分布式系统中,网络并不可靠——脑裂(Sp…...