【Linux 内核源码分析】物理内存组织结构
多处理器系统两种体系结构:
-
非一致内存访问(Non-Uniform Memory Access,NUMA):这种体系结构下,内存被划分成多个内存节点,每个节点由不同的处理器访问。访问一个内存节点所需的时间取决于处理器和内存节点之间的距离,因此处理器与内存节点之间的距离会影响内存访问速度。
-
对称多处理器(Symmetric Multi-Processor,SMP):这种体系结构是一致内存访问(Uniform Memory Access,UMA)的一种形式,所有处理器对内存的访问时间是相同的,即无论处理器的位置如何,访问内存的开销是相等的。
内存模型
Linux内核内存模型是从处理器的角度看到的物理内存分布,内核管理不同内存模型的方式存在差异。内存管理子系统支持以下三种内存模型:
-
平坦内存(Flat Memory):在这种模型下,内存的物理地址空间是连续的,且没有空洞。这是最简单的内存模型,因为对于物理内存的管理而言,只需按顺序分配内存即可。
-
不连续内存(Discontiguous Memory):在这种模型下,内存的物理地址空间存在空洞,但是这种模型可以高效地处理空洞。这是因为内存管理子系统可以跟踪哪些物理地址是已经被占用,哪些是空闲的,然后在空闲内存之间分配新的内存。
-
稀疏内存(Sparse Memory):在这种模型下,内存的物理地址空间也存在空洞,但是如果要支持内存热插拔,只能选择稀疏内存模型。这是因为在内存热插拔时,可能会出现大量的空洞,如果采用不连续内存模型,那么在进行内存分配时,需要遍历整个物理地址空间,这样会造成不必要的开销。而稀疏内存模型可以维护一个可扩展的物理地址空间列表,只需在该列表中分配内存即可。
三级结构
内存管理子系统使用节点、区域和页三级结构来描述物理内存的管理。
-
节点:节点是指物理内存的逻辑分组单元,通常对应于具有特定特性或位置的一组物理内存。每个节点包含一个或多个区域,用于管理一定范围内的物理内存。
-
区域:区域是节点内部的一个逻辑划分,用于管理一定范围内的物理内存页。不同的区域可能具有不同的特性,例如可回收内存、不可回收内存等。常见的区域包括高速缓存区、低速缓存区、DMA区等。
-
页:页是内存管理的最小单位,通常是以固定大小(如4KB)划分的内存块。操作系统通过页表来映射虚拟内存和物理内存之间的对应关系,实现内存的管理和地址转换。
内存节点(pglist_data)
内存节点分为两种情况:
-
对于NUMA(非一致性存储访问)体系的内存节点,内存节点根据处理器和内存的距离划分。在NUMA架构中,不同的处理器可能与不同的内存区域相连,因此系统将内存划分为不同的节点,以便更有效地管理和分配内存资源。
-
在具有不连续内存的NUMA系统中,内存节点表示比区域的级别更高的内存区域,根据物理地址是否连续划分。在这种情况下,每块物理地址连续的内存被视为一个内存节点。这种划分方式可以帮助内核更好地管理非连续内存的分配和使用,确保系统能够有效地利用所有可用的物理内存空间。
typedef struct pglist_data {struct zone node_zones[MAX_NR_ZONES]; // 内存区域数组struct zonelist node_zonelists[MAX_ZONELISTS]; // 备用区域列表int nr_zones; // 该节点包含的内存区域数量#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */struct page *node_mem_map; // 内存映射表,存储每个物理页的信息#ifdef CONFIG_PAGE_EXTENSIONstruct page_ext *node_page_ext; // 页的扩展属性
#endif#endifunsigned long node_start_pfn; // 该节点的起始物理页号unsigned long node_present_pages; // 物理页总数,即该节点上存在的物理页数量unsigned long node_spanned_pages; // 物理页范围的总长度,包括空洞,即该节点的物理页范围总大小int node_id; // 节点标识符...
}
pglist_data 结构体定义了一个内存节点的数据结构。
node_zones:内存区域数组,用于存储该节点内每个内存区域的信息。node_zonelists:备用区域列表,用于存储备用的内存区域的信息。nr_zones:记录该节点包含的内存区域的数量。node_mem_map:内存映射表,用于存储每个物理页的信息。仅在没有使用 SPARSEMEM 的情况下有效。node_page_ext:页的扩展属性,用于存储与页相关的额外属性。仅在启用了 CONFIG_PAGE_EXTENSION 的情况下有效。node_start_pfn:该节点的起始物理页号。node_present_pages:该节点上存在的物理页数量。node_spanned_pages:该节点的物理页范围总大小,包括空洞。node_id:节点标识符。
内存区域(zone)
内存区域是将物理内存按照不同属性进行划分的一种方式。每个内存区域都有一个唯一的类型标识,类型包括 ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_HIGHMEM、ZONE_MOVABLE、ZONE_DEVICE 等。
enum zone_type {// DMA区域,直接内存访问。如果有些设备不能直接访问所有内存,需要使用DMA区域
#ifdef CONFIG_ZONE_DMAZONE_DMA,
#endif// DMA32区域64位系统,如果既要支持只能直接访问16MB以下的内存设备,又要支持只能直接访问4GB以下内存的32设备,必须使用此DMA32区域
#ifdef CONFIG_ZONE_DMA32ZONE_DMA32,
#endif/** Normal addressable memory is in ZONE_NORMAL. DMA operations can be* performed on pages in ZONE_NORMAL if the DMA devices support* transfers to all addressable memory.*/// 普通区域:直接映射到内核虚拟地址空间的内存区域,又称为普通区域ZONE_NORMAL,#ifdef CONFIG_HIGHMEM/** A memory area that is only addressable by the kernel through* mapping portions into its own address space. This is for example* used by i386 to allow the kernel to address the memory beyond* 900MB. The kernel will set up special mappings (page* table entries on i386) for each page that the kernel needs to* access.*/// 高端内存区域:内核和用户地址空间按1:3划分,内核地址空间只有1GB,不能把1GB以上的内存直接映射到内核地址ZONE_HIGHMEM,
#endif// 可移动区域:它是一个伪内存区域,用来存放内存碎片ZONE_MOVABLE,#ifdef CONFIG_ZONE_DEVICE// 设备区域:支持持久内存热插拔增加的内存区域,每个内存区域有一个zone结构体来描述ZONE_DEVICE,
#endif__MAX_NR_ZONES
};
这样整理后的代码更加清晰易懂,注释也更容易理解各个内存区域的作用。
ZONE_DMA:适用于 DMA 的内存区域,长度受处理器类型的限制。在 IA-32 计算机上,限制为 16 MiB。ZONE_DMA32:适用于可使用 32 位地址字寻址的 DMA 的内存区域。在 64 位系统上,ZONE_DMA 和 ZONE_DMA32 有所不同。在 32 位计算机上,ZONE_DMA32 区域为空,即长度为 0 MiB。ZONE_NORMAL:直接映射区域,标记了可直接映射到内核段的普通内存区域。这是在所有体系结构上保证都会存在的唯一内存区域。但是,该地址范围并不一定对应实际的物理内存,例如在某些系统中,所有内存都属于 ZONE_DMA32 范围,而 ZONE_NORMAL 区域为空。ZONE_HIGHMEM:该内存区域是早期 32 位体系结构的产物,因为内核和用户地址空间是 1:3 划分的,所以不能将内核 1GB 以上的内存直接映射到内核地址空间。在 64 位系统上,由于地址空间非常大,不存在这种问题。ZONE_MOVABLE:可移动区域,是一个伪内存区域,用于防止内存碎片。可以用于分配无法被移动的内存对象的区域,将该区域中的页框移动到另一个区域,并释放原始区域。ZONE_DEVICE:持久内存热插拔增加的区域,用于支持设备驱动程序动态分配内存。
一个内存节点可能包含多个内存区域,这些区域的类型和数量可以根据系统的需求进行配置。每个内存区域都有一组特定的操作函数集合,用于管理该区域中的页框。通过内存区域的划分,可以更加有效地管理和利用物理内存。
冷热页
-
struct zone的pageset成员用于实现冷热分配器:在Linux内核中,为了提高内存管理的效率和性能,使用了冷热页(Cold and Hot Pages)的概念。具体来说,在每个内存区域(zone)中,定义了一个pageset结构体,用于管理该区域中的冷热页。 -
热页指的是已经加载到CPU的高速缓存中的页面,与内存中的其他页相比,其数据结构可以更快地被访问。冷页则指不在CPU高速缓存中的页面,当需要访问它们时,需要从内存中读取数据,这会导致较高的延迟。
-
在多处理器系统中,每个CPU都有一个或多个高速缓存。由于各个CPU具有独立的高速缓存,因此对冷热页的管理必须是针对每个CPU独立进行的。每个CPU都有自己的冷热分配器(
pageset),用于管理该CPU的热页和冷页。这样可以避免多个CPU之间相互竞争同一份冷热页管理的问题,提高了系统的并发性和性能。
// 每CPU页面结构体定义
struct per_cpu_pages {int count; // 列表中页面数量int high; // 高水位标记,需要清空int batch; // 伙伴系统添加/移除的块大小// 页面列表,每个迁移类型在PCP列表上存储一个struct list_head lists[MIGRATE_PCPTYPES];
};
-
count记录了与该列表相关的页面数量。它表示当前列表中的页的数量。 -
high是一个水印(watermark)。当count的值超过了high时,表示列表中的页太多了,需要进行一些处理。这个水印可以用来判断列表是否过载。 -
batch表示每次添加页的参考值。在填充CPU高速缓存时,通常不是一次只填充一个页面,而是以块为单位填充,batch就是指定每次填充的页数。 -
lists是一个数组,用于存储不同迁移类型的页面列表。每个迁移类型对应一个列表,在PCP(per-CPU Page)列表上存储。
物理页(page)
页是内存管理的最小单位:在内存管理中,页是内存的基本单位,页面中的内存物理地址是连续的。在Linux内核中,物理页被视为内存管理的基本单位,即内核中的内存管理单元MMU将物理页作为基本单位进行管理。
不同体系结构支持不同的页大小:不同的计算机体系结构支持不同大小的页。例如,32位体系结构通常支持4KB的页,而64位体系结构通常支持8KB的页。另外,像MIPS64架构体系可能支持更大的页,比如16KB的页。
每个物理页对应一个page结构体:在Linux内核中,每个物理页都对应一个称为页描述符(page structure)的数据结构,用于描述和管理该物理页的相关信息。每个内存节点的pglist_data实例中的成员node_mem_map指向该内存节点包含的所有物理页的页描述符组成的数组。
struct page {unsigned long flags; // 原子标志,有些情况下会异步更新union {struct { // 页面缓存和匿名页面struct list_head lru;// 如果最低位为0,则指向 inode 的 address_space 或为 NULL// 如果页映射为匿名地址,最低位置位,而且指针指向 anon_vma 对象struct address_space *mapping;pgoff_t index; // 映射中的偏移量// 用于映射私有、不透明数据// 如果设置了 PagePrivate,则通常用于 buffer_heads// 如果设置了 PageSwapCache,则用于 swp_entry_t// 如果设置了 PageBuddy,则用于伙伴系统中的阶unsigned long private;};struct { // slab、slob 和 slubunion {struct list_head slab_list;struct { // 部分页面struct page *next;
#ifdef CONFIG_64BITint pages; // 剩余页面数int pobjects; // 近似计数
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; // 非 slob 时的 kmem_cache 指针/* 双字边界 */void *freelist; // 第一个空闲对象union {void *s_mem; // slab 分配器的第一个对象unsigned long counters; // SLUB 计数器struct { // SLUBunsigned inuse:16;unsigned objects:15;unsigned frozen:1;};};};// 其他字段...};
};
-
flags:表示页的各种状态和属性的标志位。这些标志位在某些情况下会被异步更新。 -
union:使用联合体来存储不同类型的页的信息。-
对于页面缓存和匿名页面(Page cache and anonymous pages):
lru:用于将页面链接到 LRU(Least Recently Used)链表,以进行页面置换。mapping:指向 inode 的 address_space 或为 NULL。如果页面映射为匿名地址,则最低位置位且指针指向anon_vma对象。index:表示页面在映射中的偏移量。private:用于映射私有、不透明数据。根据不同的标志位,可以用于不同的目的,如PagePrivate用于buffer_heads,PageSwapCache用于swp_entry_t,PageBuddy用于伙伴系统中的阶。
-
对于 slab、slob 和 slub:
slab_list或next:用于管理页面的链表结构,对于 slab 和 slob 分配器,用于链接已分配和未分配的页面;对于 slub 分配器,用于链接部分页面。slab_cache:对于 slab 分配器,指向相关的 kmem_cache 结构体;对于 slob 分配器和 slub 分配器,该字段不使用。freelist或s_mem:对于 slab 分配器,指向第一个空闲对象;对于 slob 分配器和 slub 分配器,用于存储其他信息,如计数器、使用中的对象数量等。
-
页表
页表是操作系统中用于实现虚拟内存到物理内存映射的重要数据结构。层次化的页表结构被设计用来支持对大地址空间的快速、高效管理。
-
内存地址的分解:
根据四级页表结构,虚拟内存地址被分解为5部分,其中4个表项用于选择页,1个索引表示页内位置。每个指针末端的几个比特位用于指定所选页帧内部的位置,具体的比特位数由PAGE_SHIFT指定。PMD_SHIFT指定了页内偏移量和最后一级页表项所需比特位的总数。通过减去PAGE_SHIFT,可以得到最后一级页表项索引所需的比特位数。类似地,PUD_SHIFT由PMD_SHIFT加上中间层页表索引所需的比特位长度,而PGDIR_SHIFT由PUD_SHIFT加上上层页表索引所需的比特位长度。计算全局页目录中一项所能寻址的部分地址空间长度,可以通过以2为底的对数计算得到PGDIR_SHIFT。 -
页表的格式:
内核提供了4个数据结构来表示页表项的结构:
- pgd_t用于全局页目录项
- pud_t用于上层页目录项
- pmd_t用于中间页目录项
- pte_t用于直接页表项
- 特定于PTE的信息:
最后一级页表中的项不仅包含了指向页的内存位置的指针,还包含了与页面相关的附加信息。每种体系结构都需要提供两个东西,以便内存管理子系统能够修改pte_t项中额外的比特位。这两个东西分别是保存额外比特位的__pgprot数据类型,以及用于修改这些比特位的pte_modify函数。
通过以上分析,我们可以更好地理解页表的设计原理和结构,以及各个级别的页表项在管理地址空间时的作用和关联。如果您有任何进一步的问题或需要更多解释,请随时提出。
查询和设置内存页与体系结构相关状态的函数
-
查询函数:
pte_present():检查给定页表项是否存在于内存中。pte_write():检查给定页表项是否可写。pte_user():检查给定页表项是否为用户空间可访问。pte_dirty():检查给定页表项是否被修改过。pte_young():检查给定页表项是否被访问过。
-
设置函数:
set_pte():设置给定页表项的内容。set_pte_at():在指定地址处设置页表项的内容。pte_clear():清除给定页表项的内容。pte_mkwrite():将只读页表项转换为可写。pte_mkdirty():标记页表项已被修改。
-
体系结构相关函数:
pgd_index():获取全局页目录项的索引。pmd_offset():获取中间页目录项的指针。pud_offset():获取上层页目录项的指针。pte_offset_kernel():获取内核页表项的指针。pfn_to_page():将物理页框号转换为对应的页结构体。
创建和操作页表项的函数
-
创建页表项:
pte_alloc():分配一个新的页表项。pte_alloc_one():分配一个新的单个页表项。pte_alloc_kernel():分配一个新的内核页表项。
-
释放页表项:
pte_free():释放一个页表项的内存。pte_free_kernel():释放一个内核页表项的内存。
-
操作页表项:
pte_clear():清除给定页表项的内容。pte_val():获取页表项的原始值。set_pte():设置指定页表项的内容。pte_mkclean():将页表项标记为干净(未修改)。pte_mkdirty():将页表项标记为脏(已修改)。pte_present():检查给定页表项是否存在于内存中。pte_write():检查给定页表项是否可写。
参考:Linux内核源码分析(内存调优/文件系统/进程管理/设备驱动/网络协议栈)教程
Linux内核源码系统性学习
>>>
相关文章:

【Linux 内核源码分析】物理内存组织结构
多处理器系统两种体系结构: 非一致内存访问(Non-Uniform Memory Access,NUMA):这种体系结构下,内存被划分成多个内存节点,每个节点由不同的处理器访问。访问一个内存节点所需的时间取决于处理器…...

力扣日记2.21-【回溯算法篇】46. 全排列
力扣日记:【回溯算法篇】46. 全排列 日期:2023.2.21 参考:代码随想录、力扣 46. 全排列 题目描述 难度:中等 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1&…...

[AIGC] Kafka 消费者的实现原理
在 Kafka 中,消费者通过订阅主题来消费数据。每个消费者都属于一个消费者组,消费者组中的多个消费者可以共同消费一个主题,实现分布式消费。每个消费者都会维护自己的偏移量,用于记录已经读取到的消息位置。消费者可以选择手动提交…...
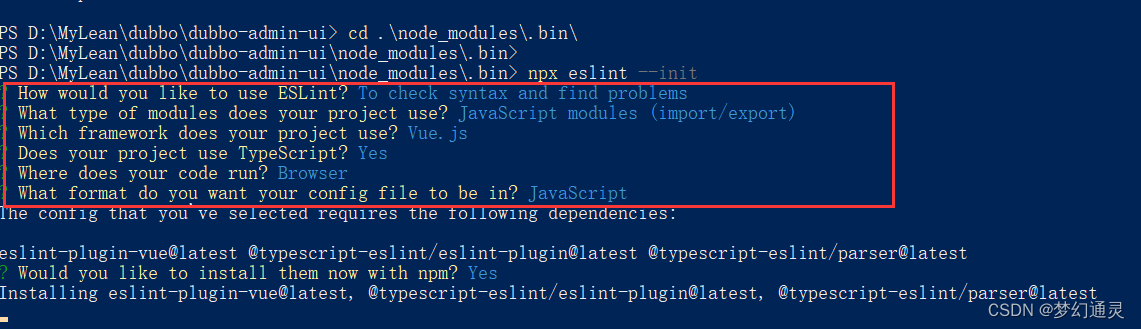
Dubbo框架admin搭建
Dubbo服务监控平台,dubbo-admin是图形化的服务管理界面,从服务注册中心获取所有的提供者和消费者的配置。 dubbo-admin是前后端分离的项目,前端使用Vue,后端使用springboot。因此,前端需要nodejs环境,后端需…...

Linux 内存top命令详解
通过top命令可以监控当前机器的内存实时使用情况,该命令的参数解释如下: 第一行 15:30:14 —— 当前系统时间 up 1167 days, 5:02 —— 系统已经运行的时长,格式为时:分 1 users ——当前有1个用户登录系统 load average: 0.00, 0.01, 0.05…...

OCP使用CLI创建和构建应用
文章目录 环境登录创建project赋予查看权限部署第一个image创建route检查pod扩展应用 部署一个Python应用连接数据库创建secret加载数据并显示国家公园地图 清理参考 环境 RHEL 9.3Red Hat OpenShift Local 2.32 登录 通过 crc console --credentials 可以查看登录信息&…...
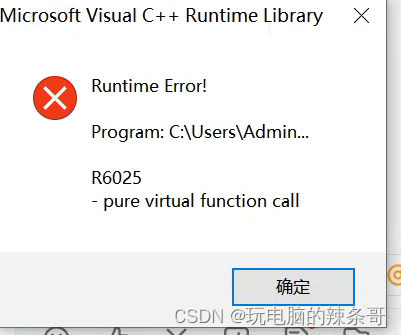
Chrome关闭时出现弹窗runtime error c++R6052,且无法关闭
环境: Chrome 版本121 Win10专业版 问题描述: Chrome关闭时出现弹窗runtime error cR6052,且无法关闭 解决方案: 1.任务管理器打开,强制结束进程 2.再次打开谷歌浏览器,打开设置关于Chrome࿰…...
【动态规划专栏】专题二:路径问题--------6.地下城游戏
本专栏内容为:算法学习专栏,分为优选算法专栏,贪心算法专栏,动态规划专栏以及递归,搜索与回溯算法专栏四部分。 通过本专栏的深入学习,你可以了解并掌握算法。 💓博主csdn个人主页:小…...

flink operator 1.7 更换日志框架log4j 到logback
更换日志框架 flink 1.18 1 消除基础flink框架log4j 添加logback jar 1-1 log4j log4j-1.2-api-2.17.1.jar log4j-api-2.17.1.jar log4j-core-2.17.1.jar log4j-slf4j-impl-2.17.1.jar 1-2 logback logback-core-1.2.3.jar logback-classic-1.2.3.jar slf4j-api-1.7.25.jar2 …...
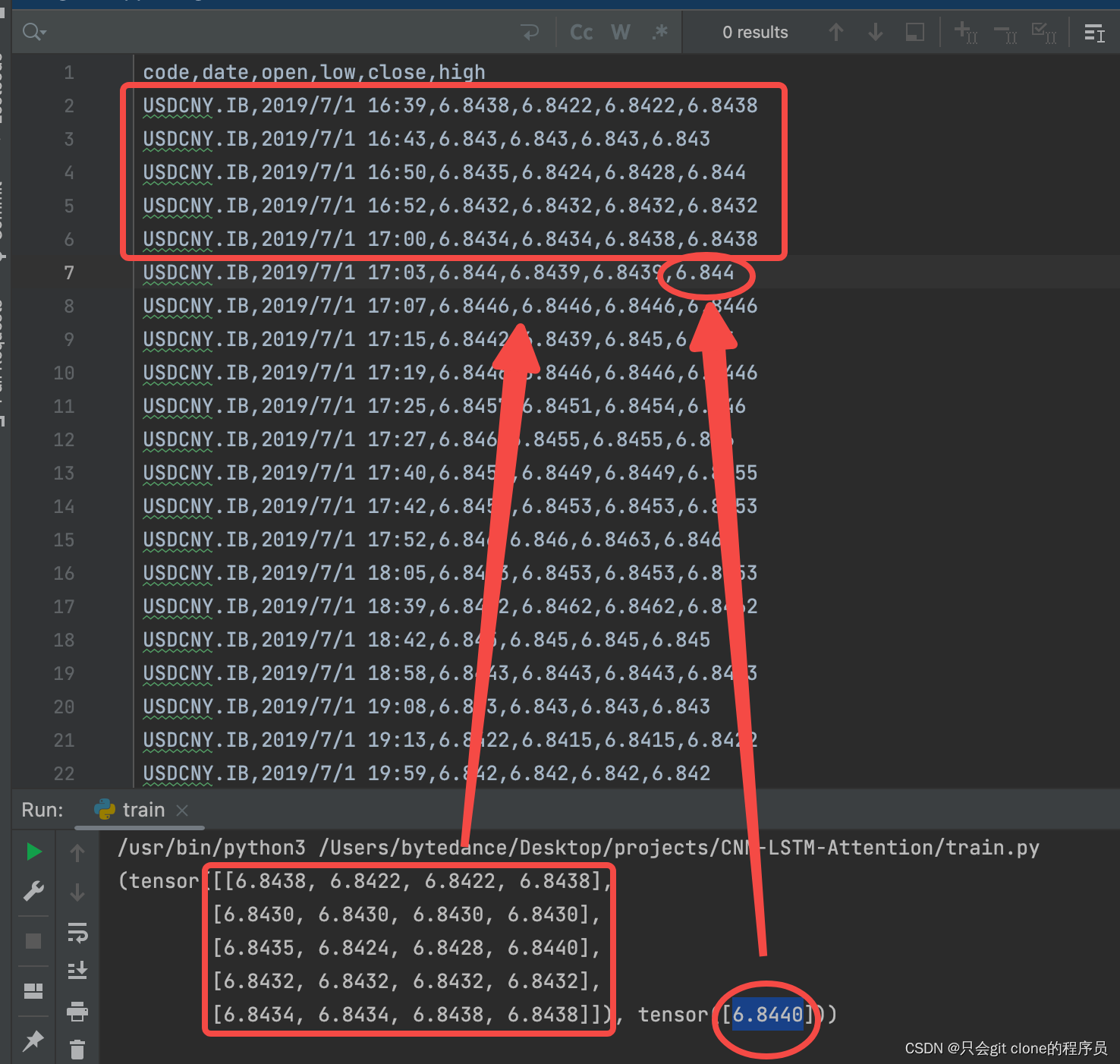
算法项目(1)—— LSTM+CNN+四种注意力对比的股票预测
本文包含什么? 项目运行的方式(包教会)项目代码(在线运行免环境配置)不通注意力的模型指标对比一些效果图运行有问题? csdn上后台随时售后.项目说明 本项目实现了基于CNN+LSTM构建模型,然后对比不同的注意力机制预测股票走势的效果。首先看一下模型结果的对比: 模型MS…...
Qt C++春晚刘谦魔术约瑟夫环问题的模拟程序
什么是约瑟夫环问题? 约瑟夫问题是个有名的问题:N个人围成一圈,从第一个开始报数,第M个将被杀掉,最后剩下一个,其余人都将被杀掉。例如N6,M5,被杀掉的顺序是:5ÿ…...
Typora+PicGO+腾讯云COS做图床
文章目录 Typora+PicGO+腾讯云COS做图床一、为什么使用图床二、Typora、PicGO和腾讯云COS介绍三、下载Typora和PicGOTyporaPicGO 四、配置Typora、PicGO和腾讯云COS腾讯云COS配置PicGO配置Typora配置 Typora+PicGO+腾讯云COS做图床…...

WebStorm | 如何修改webstorm中新建html文件默认生成模板中title的初始值
在近期的JS的学习中,使用webstorm,总是要先新建一个html文件,然后再到里面书写<script>标签,真是麻烦,而且标题也是默认的title,想改成文件名还总是需要手动去改 经过小小的研究,找到了修…...
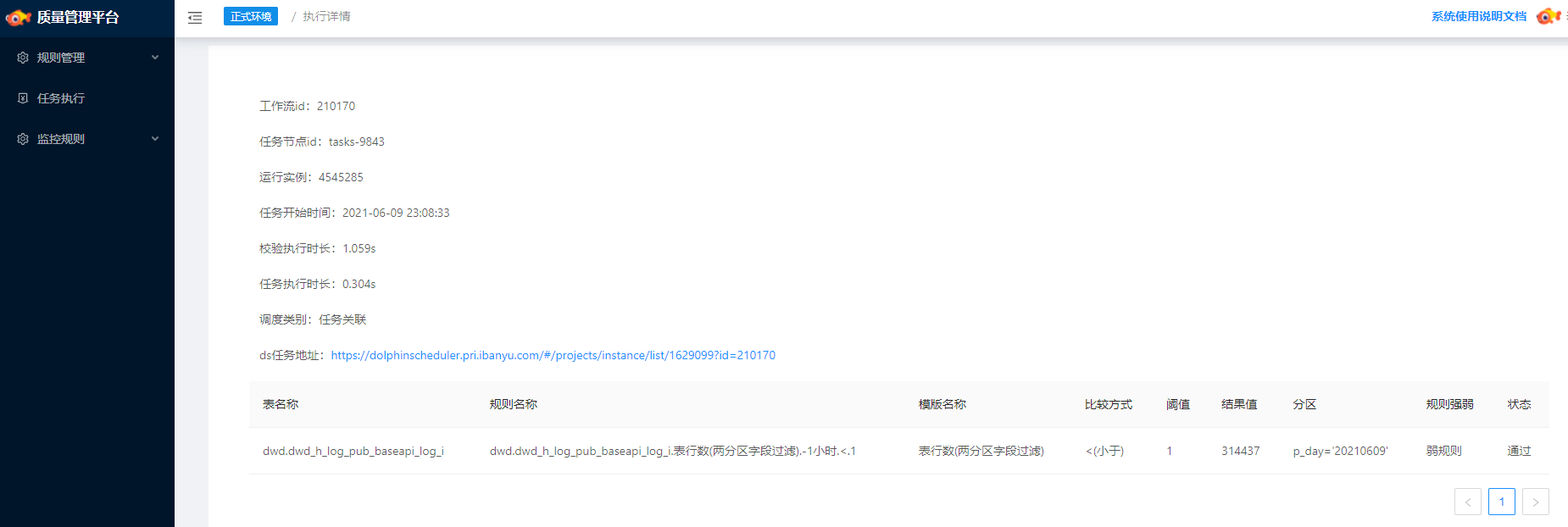
大厂的数据质量中心系统设计
日常工作中,数据开发上线完一个任务后并不是就可以高枕无忧,时常因上游链路数据异常或者自身处理逻辑的 BUG 导致产出的数据结果不可信。而问题发现可经历较长周期(尤其离线场景),往往是业务方通过上层数据报表发现数据…...
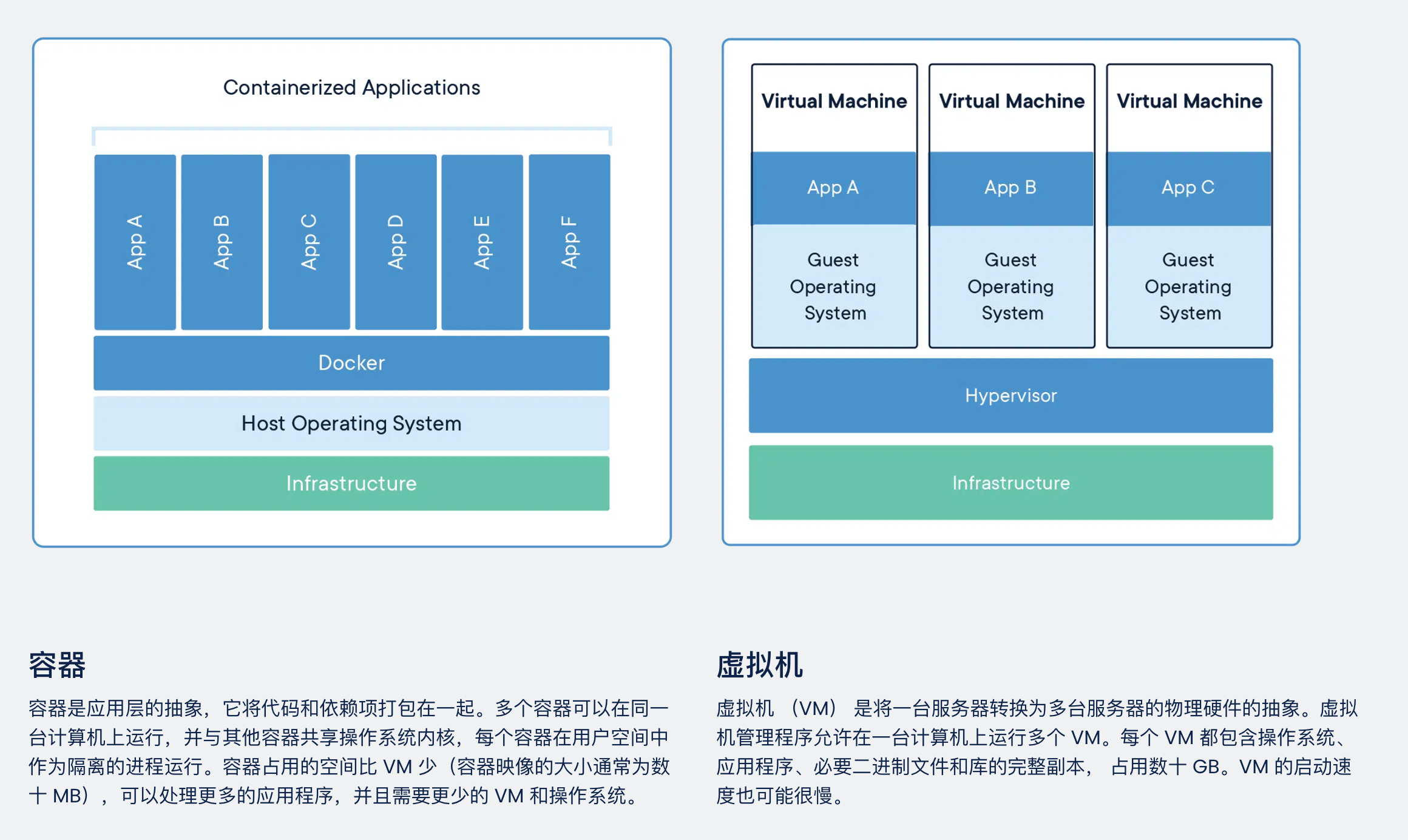
docker (一)-简介
1.什么是docker Docker 是一个开源的应用容器引擎,由于docker影响巨大,今天也用"Docker" 指代容器化技术。 2.docker的优势 一键部署,开箱即用 容器使用基于image镜像的部署模式,image中包含了运行应用程序所需的一…...

全国乙卷高考理科数学近年真题的选择题练一练和解析
虽然很多中小学才陆陆续续开学,但是高三的学子们一定是过年的时候也在抓紧备考,毕竟,距离2024年高考只剩下不到四个月了。 如何在最后四个月的时间提高成绩?以高考真题为抓手是一个不错的方法,因为真题都是严格遵循考试…...
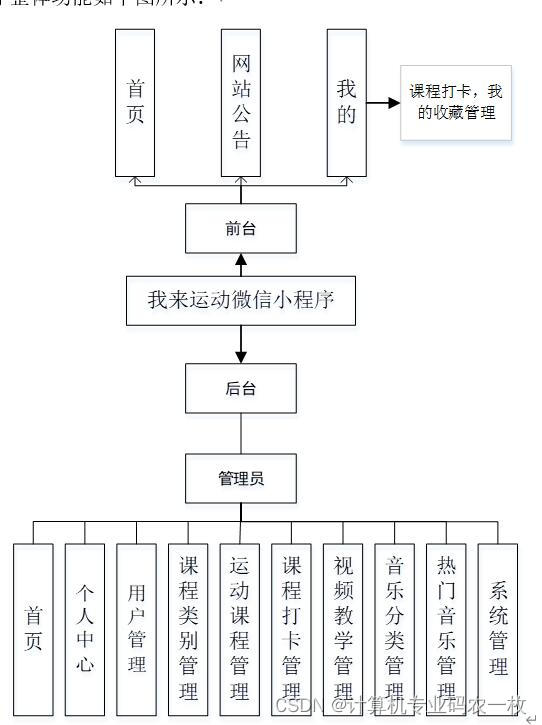
uniapp运动课程健身打卡系统微信小程序
考虑到实际生活中在我来运动管理方面的需要以及对该系统认真的分析,将系统分为小程序端模块和后台管理员模块,权限按管理员和用户这两类涉及用户划分。 (a) 管理员;管理员使用本系统涉到的功能主要有:首页、个人中心、用户管理、课程类别管理…...

IP详细地理位置查询:技术原理与应用实践
IP地址是互联网上设备的唯一标识,在网络安全、个性化服务等领域具有重要意义。通过IP详细地理位置查询,可以获取到IP地址所在地的具体信息,为网络管理、定位服务等提供支持。IP数据云将深入探讨IP详细地理位置查询的技术原理、应用实践以及相…...

SpringBoot2整合支付宝进行沙箱支付
目录 1. 进入支付宝的开放平台 2. 导入Maven依赖 3. 配置application.yml文件 NATAPP.cn(内网穿透工具) 注册登录 下载 4. 后端配置 5. 测试 1. 进入支付宝的开放平台 开发平台: 支付宝开放平台 登录后,点击控制台 点击最下面的沙箱 2. 导入Maven依赖 <dependency…...

世界顶级名校计算机专业,都在用哪些书当教材?
清华、北大、MIT、CMU、斯坦福的学霸们在新学期里要学什么?今天我们来盘点一下那些世界名校计算机专业采用的教材。 欢迎来到英杰社区: https://bbs.csdn.net/topics/617804998 欢迎来到阿Q社区: https://bbs.csdn.net/topics/617897397 &…...

2026年同步网盘哪个好?10款支持本地文件夹自动同步与实时备份工具盘点
在 2026 年,数据即资产。传统“手动上传”已难以满足高频办公:文件一多就容易漏传、版本混乱、协作效率下降。本地文件夹自动同步(落盘即上云)正在成为衡量网盘生产力的核心指标——既能防止硬盘故障导致的数据丢失,也…...

Themes 与 Styles
Themes 与 Styles 主题目录:Source/Themes项目说明H.Theme主题核心。H.Themes.Colors.Accent强调色。H.Themes.Colors.Blue蓝色。H.Themes.Colors.Copper铜色/复古。H.Themes.Colors.Gray灰色。H.Themes.Colors.Industrial工业风。H.Themes.Colors.Mineral矿物色。H…...

Sunshine游戏串流平台:打造你的私人云游戏服务器
Sunshine游戏串流平台:打造你的私人云游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,专为Moonlight…...

为什么我强烈推荐大学生打CTF!看完你就懂了!
前言 写这个文章是因为我很多粉丝都是学生,经常有人问: 感觉大一第一个学期忙忙碌碌的过去了,啥都会一点,但是自己很难系统的学习到整个知识体系,很迷茫,想知道要如何高效学习。 这篇文章我主要就围绕两点…...

3分钟彻底清理Windows系统:Win11Debloat让你的电脑重获新生
3分钟彻底清理Windows系统:Win11Debloat让你的电脑重获新生 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...

硬件工程师效率翻倍:我是如何让Cadence OrCAD导出的PDF自动生成清晰书签目录的
硬件工程师效率革命:用OrCAD打造智能PDF文档工作流 在硬件设计领域,一份结构清晰的原理图PDF文档往往能大幅提升团队协作效率。想象一下这样的场景:当你将精心设计的电路方案交付给客户或跨部门同事时,对方打开的是一个带有智能书…...

Whisky革新指南:在macOS上优雅运行Windows程序的全新体验
Whisky革新指南:在macOS上优雅运行Windows程序的全新体验 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经在macOS上渴望运行某个Windows专用软件,却…...

Apache APISIX Dashboard完全指南:5分钟掌握可视化API网关管理
Apache APISIX Dashboard完全指南:5分钟掌握可视化API网关管理 【免费下载链接】apisix-dashboard Dashboard for Apache APISIX 项目地址: https://gitcode.com/gh_mirrors/ap/apisix-dashboard Apache APISIX Dashboard是Apache APISIX API网关的可视化控制…...
步骤)
【文档编辑】打印小册子(一张A4纸4页内容)步骤
效果如下,使用“A4纸”打印变成“每一页是A5大小的翻页小册子”1、打开word格式说明书,另存为pdf格式(如果文件是pdf格式忽略步骤1) 2、用wps打开pdf文件 3、打印→打印方式:小册子→小册子子集:仅正面→装…...

语音修复终极指南:如何用VoiceFixer在3分钟内拯救受损音频
语音修复终极指南:如何用VoiceFixer在3分钟内拯救受损音频 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 在数字时代,音频质量问题困扰着无数内容创作者、历史档案工作者和普…...