Linux pageset
1. 引言
在用户进程发生缺页异常时,Linux内核需要分配所需物理页面以及建立也表映射,来维持进程的正常内存使用需求。而对于分配物理页面仅依赖于buddy系统,对于小order页面的分配效率较低。因此Linux通过在每个cpu维护一个page链表(percpu page list简称pageset),用来满足小order页面分配请求,提高页面分配效率。
下面我们重点来看一下,pageset的原理是什么,以及在Linux内核中是怎样实现和使用的。
2. pageset定义
struct zone {
......struct pglist_data *zone_pgdat;struct per_cpu_pages __percpu *per_cpu_pageset;struct per_cpu_zonestat __percpu *per_cpu_zonestats;/** the high and batch values are copied to individual pagesets for* faster access*/int pageset_high;int pageset_batch;
......
};
pageset的定义是放在zone里,每个zone里有一个per_cpu_pageset成员,用于这个zone内小order页面的快速分配。
3. pageset的初始化流程
调用流程
start_kernel(void)
---> setup_per_cpu_pageset();
从内核启动流程开始,通过调用setup_per_cpu_pageset()函数完成per_cpu_pageset初始化动作;
/** Allocate per cpu pagesets and initialize them.* Before this call only boot pagesets were available.*/
void __init setup_per_cpu_pageset(void)
{struct pglist_data *pgdat;struct zone *zone;int __maybe_unused cpu;for_each_populated_zone(zone) // 遍历可用的zone,设置zone_pagesetsetup_zone_pageset(zone);#ifdef CONFIG_NUMA/** Unpopulated zones continue using the boot pagesets.* The numa stats for these pagesets need to be reset.* Otherwise, they will end up skewing the stats of* the nodes these zones are associated with.*/for_each_possible_cpu(cpu) {struct per_cpu_zonestat *pzstats = &per_cpu(boot_zonestats, cpu);memset(pzstats->vm_numa_event, 0,sizeof(pzstats->vm_numa_event));}
#endiffor_each_online_pgdat(pgdat)pgdat->per_cpu_nodestats =alloc_percpu(struct per_cpu_nodestat);
}void __meminit setup_zone_pageset(struct zone *zone)
{int cpu;/* Size may be 0 on !SMP && !NUMA */if (sizeof(struct per_cpu_zonestat) > 0)zone->per_cpu_zonestats = alloc_percpu(struct per_cpu_zonestat);zone->per_cpu_pageset = alloc_percpu(struct per_cpu_pages); // 为当前zone的per_cpu_pageset分配percpu内存for_each_possible_cpu(cpu) { // 遍历所有cpustruct per_cpu_pages *pcp;struct per_cpu_zonestat *pzstats;pcp = per_cpu_ptr(zone->per_cpu_pageset, cpu);pzstats = per_cpu_ptr(zone->per_cpu_zonestats, cpu);per_cpu_pages_init(pcp, pzstats); // 初始化per_cpu_pages}zone_set_pageset_high_and_batch(zone, 0);
}/** PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed* costly to service. That is between allocation orders which should* coalesce naturally under reasonable reclaim pressure and those which* will not.*/
#define PAGE_ALLOC_COSTLY_ORDER 3 // 这个是指pageset支持分配的最大order,[0-3]
enum migratetype {MIGRATE_UNMOVABLE,MIGRATE_MOVABLE,MIGRATE_RECLAIMABLE,MIGRATE_PCPTYPES, /* the number of types on the pcp lists */MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,......MIGRATE_TYPES
};
/** One per migratetype for each PAGE_ALLOC_COSTLY_ORDER. One additional list* for THP which will usually be GFP_MOVABLE. Even if it is another type,* it should not contribute to serious fragmentation causing THP allocation* failures.*/
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
#define NR_PCP_THP 1
#else
#define NR_PCP_THP 0
#endif
#define NR_LOWORDER_PCP_LISTS (MIGRATE_PCPTYPES * (PAGE_ALLOC_COSTLY_ORDER + 1))
#define NR_PCP_LISTS (NR_LOWORDER_PCP_LISTS + NR_PCP_THP)static void per_cpu_pages_init(struct per_cpu_pages *pcp, struct per_cpu_zonestat *pzstats)
{int pindex;memset(pcp, 0, sizeof(*pcp));memset(pzstats, 0, sizeof(*pzstats));spin_lock_init(&pcp->lock);for (pindex = 0; pindex < NR_PCP_LISTS; pindex++) // 初始化pcp中不同迁移类型,不同order用来存放页面的链表INIT_LIST_HEAD(&pcp->lists[pindex]);/** Set batch and high values safe for a boot pageset. A true percpu* pageset's initialization will update them subsequently. Here we don't* need to be as careful as pageset_update() as nobody can access the* pageset yet.*/pcp->high = BOOT_PAGESET_HIGH;pcp->batch = BOOT_PAGESET_BATCH;pcp->free_factor = 0;
}
4. pageset的页面分配(用来分配order为[0-3]的页面)
调用流程
alloc_pages()
---> alloc_pages_node()
-------> __alloc_pages_node()
----------> __alloc_pages()
-------------> get_page_from_freelist()
-----------------> rmqueue()
/** Allocate a page from the given zone.* Use pcplists for THP or "cheap" high-order allocations.*//** Do not instrument rmqueue() with KMSAN. This function may call* __msan_poison_alloca() through a call to set_pfnblock_flags_mask().* If __msan_poison_alloca() attempts to allocate pages for the stack depot, it* may call rmqueue() again, which will result in a deadlock.*/
__no_sanitize_memory
static inline
struct page *rmqueue(struct zone *preferred_zone,struct zone *zone, unsigned int order,gfp_t gfp_flags, unsigned int alloc_flags,int migratetype)
{struct page *page;/** We most definitely don't want callers attempting to* allocate greater than order-1 page units with __GFP_NOFAIL.*/WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));if (likely(pcp_allowed_order(order))) { // 检查要分配的页面order是否是pcp允许的order/** MIGRATE_MOVABLE pcplist could have the pages on CMA area and* we need to skip it when CMA area isn't allowed.*/if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||migratetype != MIGRATE_MOVABLE) { // 进行一些参数检查,如果满足条件,则从pageset中分配pagepage = rmqueue_pcplist(preferred_zone, zone, order, // 从pageset中分配页面migratetype, alloc_flags);if (likely(page))goto out;}}page = rmqueue_buddy(preferred_zone, zone, order, alloc_flags,migratetype);out:/* Separate test+clear to avoid unnecessary atomics */if (unlikely(test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags))) {clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);wakeup_kswapd(zone, 0, 0, zone_idx(zone));}VM_BUG_ON_PAGE(page && bad_range(zone, page), page);return page;
}/** PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed* costly to service. That is between allocation orders which should* coalesce naturally under reasonable reclaim pressure and those which* will not.*/
#define PAGE_ALLOC_COSTLY_ORDER 3static inline bool pcp_allowed_order(unsigned int order) // 检查该order页面是否允许从pageset中分配
{if (order <= PAGE_ALLOC_COSTLY_ORDER) // 主要就是判断order是否小于PAGE_ALLOC_COSTLY_ORDER,可以从前面的定义入手,发现order只要在[0-3]范围内就允许从pageset中分配return true;
#ifdef CONFIG_TRANSPARENT_HUGEPAGEif (order == pageblock_order)return true;
#endifreturn false;
}
接下来我们看一下rmqueue_pcplist()是如何从pageset中分配页面的
/* Lock and remove page from the per-cpu list */
static struct page *rmqueue_pcplist(struct zone *preferred_zone,struct zone *zone, unsigned int order,int migratetype, unsigned int alloc_flags)
{struct per_cpu_pages *pcp;struct list_head *list;struct page *page;unsigned long flags;unsigned long __maybe_unused UP_flags;/** spin_trylock may fail due to a parallel drain. In the future, the* trylock will also protect against IRQ reentrancy.*/pcp_trylock_prepare(UP_flags);pcp = pcp_spin_trylock_irqsave(zone->per_cpu_pageset, flags); // 获取当前cpu上的per_cpu_pages对象if (!pcp) {pcp_trylock_finish(UP_flags);return NULL;}/** On allocation, reduce the number of pages that are batch freed.* See nr_pcp_free() where free_factor is increased for subsequent* frees.*/pcp->free_factor >>= 1;list = &pcp->lists[order_to_pindex(migratetype, order)]; // 根据迁移类型和order大小找寻要从哪个页面链表中摘取页面page = __rmqueue_pcplist(zone, order, migratetype, alloc_flags, pcp, list); // 摘取页面pcp_spin_unlock_irqrestore(pcp, flags);pcp_trylock_finish(UP_flags);if (page) { // 如果分配页面成功,做一些统计__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);zone_statistics(preferred_zone, zone, 1);}return page; // 返回从pageset中分配到的页面
}static inline unsigned int order_to_pindex(int migratetype, int order) // 根据迁移类型和要分配的order计算要从哪条页面链表中摘取页面,这个计算index的逻辑和一开始pageset初始化时一致(看不明白,可以往前翻找一下)
{int base = order;#ifdef CONFIG_TRANSPARENT_HUGEPAGEif (order > PAGE_ALLOC_COSTLY_ORDER) {VM_BUG_ON(order != pageblock_order);return NR_LOWORDER_PCP_LISTS;}
#elseVM_BUG_ON(order > PAGE_ALLOC_COSTLY_ORDER);
#endifreturn (MIGRATE_PCPTYPES * base) + migratetype;
}
接下来看看__rmqueue_pcplist()函数内部是如何实现的:
/* Remove page from the per-cpu list, caller must protect the list */
static inline
struct page *__rmqueue_pcplist(struct zone *zone, unsigned int order,int migratetype,unsigned int alloc_flags,struct per_cpu_pages *pcp,struct list_head *list)
{struct page *page;do {if (list_empty(list)) { // 如果当前list中没有页面,则需要从buddy系统中请求页面int batch = READ_ONCE(pcp->batch);int alloced;/** Scale batch relative to order if batch implies* free pages can be stored on the PCP. Batch can* be 1 for small zones or for boot pagesets which* should never store free pages as the pages may* belong to arbitrary zones.*/if (batch > 1)batch = max(batch >> order, 2);alloced = rmqueue_bulk(zone, order, // 从buddy中批量申请batch个order大小、migratetype类型的页面batch, list,migratetype, alloc_flags);pcp->count += alloced << order;if (unlikely(list_empty(list))) // 如果从buddy系统中申请不到页面,则返回NULLreturn NULL;}page = list_first_entry(list, struct page, pcp_list); // 从list中获取页面list_del(&page->pcp_list); // 删除页面pcp->count -= 1 << order; // pcp页面个数更新} while (check_new_pcp(page, order));return page;
}/** Obtain a specified number of elements from the buddy allocator, all under* a single hold of the lock, for efficiency. Add them to the supplied list.* Returns the number of new pages which were placed at *list.*/
static int rmqueue_bulk(struct zone *zone, unsigned int order,unsigned long count, struct list_head *list,int migratetype, unsigned int alloc_flags)
{int i, allocated = 0;/* Caller must hold IRQ-safe pcp->lock so IRQs are disabled. */spin_lock(&zone->lock);for (i = 0; i < count; ++i) { // 重复count次struct page *page = __rmqueue(zone, order, migratetype, // 每次从zone的buddy系统中申请一个对应order和migratetype的页面alloc_flags);if (unlikely(page == NULL)) // 从buddy系统中申请不到内存,则退出,否则继续申请break;if (unlikely(check_pcp_refill(page, order)))continue;/** Split buddy pages returned by expand() are received here in* physical page order. The page is added to the tail of* caller's list. From the callers perspective, the linked list* is ordered by page number under some conditions. This is* useful for IO devices that can forward direction from the* head, thus also in the physical page order. This is useful* for IO devices that can merge IO requests if the physical* pages are ordered properly.*/list_add_tail(&page->pcp_list, list); // 将申请到的页面,挂载到pageset中的页面链表中allocated++; // 已分配的个数加一if (is_migrate_cma(get_pcppage_migratetype(page)))__mod_zone_page_state(zone, NR_FREE_CMA_PAGES,-(1 << order));}/** i pages were removed from the buddy list even if some leak due* to check_pcp_refill failing so adjust NR_FREE_PAGES based* on i. Do not confuse with 'allocated' which is the number of* pages added to the pcp list.*/__mod_zone_page_state(zone, NR_FREE_PAGES, -(i << order));spin_unlock(&zone->lock);return allocated; // 返回已分配页面个数
}
5. pageset的页面释放
调用流程
free_pages()
---> __free_pages()
------> free_the_page()
static inline void free_the_page(struct page *page, unsigned int order)
{if (pcp_allowed_order(order)) /* Via pcp? */ // 检查该order页面是否是从pageset中分配的free_unref_page(page, order); // 如果是的话,则释放到pageset中else__free_pages_ok(page, order, FPI_NONE);
}/** Free a pcp page*/
void free_unref_page(struct page *page, unsigned int order)
{unsigned long flags;unsigned long __maybe_unused UP_flags;struct per_cpu_pages *pcp;struct zone *zone;unsigned long pfn = page_to_pfn(page);int migratetype;if (!free_unref_page_prepare(page, pfn, order))return;/** We only track unmovable, reclaimable and movable on pcp lists.* Place ISOLATE pages on the isolated list because they are being* offlined but treat HIGHATOMIC as movable pages so we can get those* areas back if necessary. Otherwise, we may have to free* excessively into the page allocator*/migratetype = get_pcppage_migratetype(page);if (unlikely(migratetype >= MIGRATE_PCPTYPES)) {if (unlikely(is_migrate_isolate(migratetype))) {free_one_page(page_zone(page), page, pfn, order, migratetype, FPI_NONE);return;}migratetype = MIGRATE_MOVABLE;}zone = page_zone(page);pcp_trylock_prepare(UP_flags);pcp = pcp_spin_trylock_irqsave(zone->per_cpu_pageset, flags); // 获取当前cpu的pageset对象if (pcp) {free_unref_page_commit(zone, pcp, page, migratetype, order); // 调用该函数将页面释放到pageset中pcp_spin_unlock_irqrestore(pcp, flags);} else {free_one_page(zone, page, pfn, order, migratetype, FPI_NONE);}pcp_trylock_finish(UP_flags);
}static void free_unref_page_commit(struct zone *zone, struct per_cpu_pages *pcp,struct page *page, int migratetype,unsigned int order)
{int high;int pindex;bool free_high;__count_vm_events(PGFREE, 1 << order);pindex = order_to_pindex(migratetype, order); // 计算该migratetype和order应该对应pageset哪条页面链表list_add(&page->pcp_list, &pcp->lists[pindex]); // 将该页面重新挂载到该链表中,用于后续分配pcp->count += 1 << order; // 更新pageset页面个数/** As high-order pages other than THP's stored on PCP can contribute* to fragmentation, limit the number stored when PCP is heavily* freeing without allocation. The remainder after bulk freeing* stops will be drained from vmstat refresh context.*/free_high = (pcp->free_factor && order && order <= PAGE_ALLOC_COSTLY_ORDER);high = nr_pcp_high(pcp, zone, free_high);if (pcp->count >= high) { // 计算当前pageset保存的页面数量是否超过high值int batch = READ_ONCE(pcp->batch); // 如果超过,则需要将batch个页面返还给buddy系统free_pcppages_bulk(zone, nr_pcp_free(pcp, high, batch, free_high), pcp, pindex); // 将多余页面返还给buddy系统}
}/** Frees a number of pages from the PCP lists* Assumes all pages on list are in same zone.* count is the number of pages to free.*/
static void free_pcppages_bulk(struct zone *zone, int count,struct per_cpu_pages *pcp,int pindex)
{int min_pindex = 0;int max_pindex = NR_PCP_LISTS - 1;unsigned int order;bool isolated_pageblocks;struct page *page;/** Ensure proper count is passed which otherwise would stuck in the* below while (list_empty(list)) loop.*/count = min(pcp->count, count);/* Ensure requested pindex is drained first. */pindex = pindex - 1;/* Caller must hold IRQ-safe pcp->lock so IRQs are disabled. */spin_lock(&zone->lock);isolated_pageblocks = has_isolate_pageblock(zone);while (count > 0) { // 不断地将页面返还给buddy系统struct list_head *list;int nr_pages;/* Remove pages from lists in a round-robin fashion. */do {if (++pindex > max_pindex)pindex = min_pindex;list = &pcp->lists[pindex]; // 获取到页面所在链表if (!list_empty(list)) // 如果链表不为空,则跳出循环break;if (pindex == max_pindex)max_pindex--;if (pindex == min_pindex)min_pindex++;} while (1);order = pindex_to_order(pindex);nr_pages = 1 << order;do {int mt;page = list_last_entry(list, struct page, pcp_list); // 获取当前list中最后一个页面mt = get_pcppage_migratetype(page); // 获取页面的迁移类型/* must delete to avoid corrupting pcp list */list_del(&page->pcp_list); // 将页面从list中删除count -= nr_pages; // 减少要释放到页面数量pcp->count -= nr_pages; // 更新pageset页面个数if (bulkfree_pcp_prepare(page))continue;/* MIGRATE_ISOLATE page should not go to pcplists */VM_BUG_ON_PAGE(is_migrate_isolate(mt), page);/* Pageblock could have been isolated meanwhile */if (unlikely(isolated_pageblocks))mt = get_pageblock_migratetype(page);__free_one_page(page, page_to_pfn(page), zone, order, mt, FPI_NONE); // 释放页面trace_mm_page_pcpu_drain(page, order, mt);} while (count > 0 && !list_empty(list));}spin_unlock(&zone->lock);
}
至此Linux pageset初始化和使用流程介绍完毕,感谢各位读者浏览!
相关文章:

Linux pageset
1. 引言 在用户进程发生缺页异常时,Linux内核需要分配所需物理页面以及建立也表映射,来维持进程的正常内存使用需求。而对于分配物理页面仅依赖于buddy系统,对于小order页面的分配效率较低。因此Linux通过在每个cpu维护一个page链表ÿ…...

【C++之语法篇003】
C学习笔记---003 C知识开篇1、内联函数1.1、什么是内联函数?1.2、解决外部头文件,重复定义问题1.3、内联函数的总结 2、auto关键字2.1、auto的作用2.2、auto的总结 3、范围for3.1、什么是范围for?3.2、范围for的循环应用 4、指针空值关键字nullptr4.1、…...
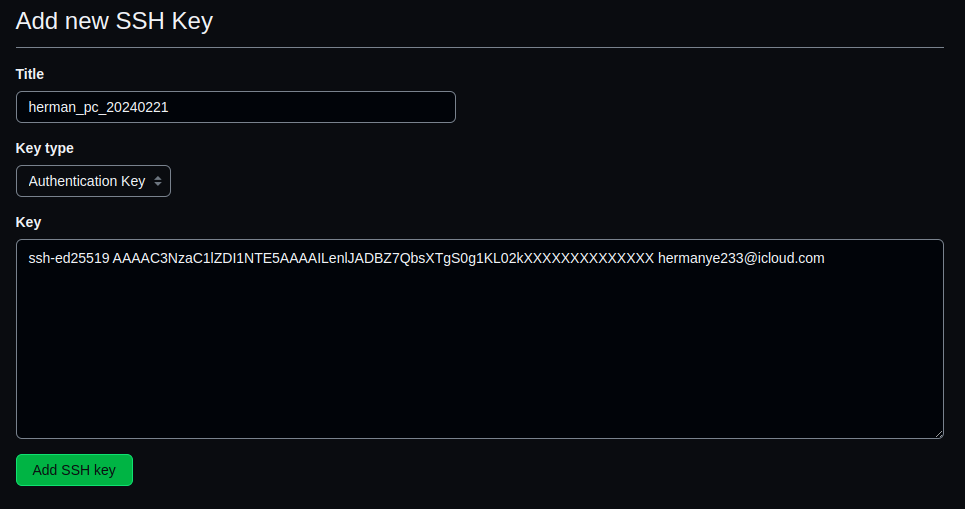
Github代码仓库SSH配置流程
作者: Herman Ye Auromix 测试环境: Ubuntu20.04 更新日期: 2024/02/21 注1: Auromix 是一个机器人爱好者开源组织。 注2: 由于笔者水平有限,以下内容可能存在事实性错误。 相关背景 在为Github代码仓库配…...
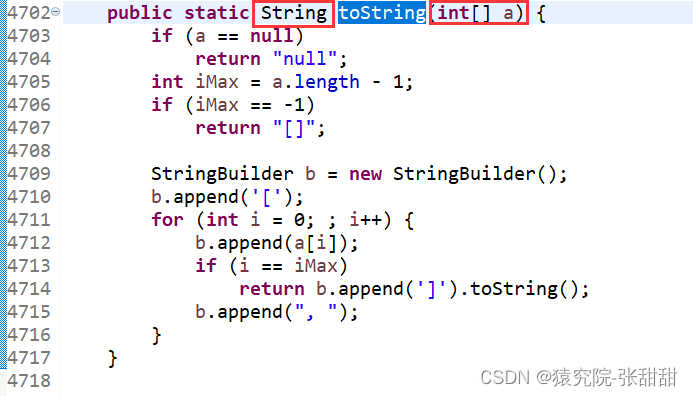
Arrays工具类的常见方法总结
一、Arrays.asList( ) 1.作用:Arrays.asList( )方法的作用是将数组转换成List,将List中的全部集合对象添加至ArrayList集合中 2.参数:动态参数 (T... a) 3.返回值:List 集合 List<T> 4.举例: package com…...

物联网和人工智能的融合
物联网和人工智能的融合 1. 物联网和人工智能的融合2. 芯片技术的进步3. 安全和隐私保护挑战4. 软件开发和调试技术的创新5. 自动化和智能化趋势 1. 物联网和人工智能的融合 随着物联网和人工智能技术的快速发展,嵌入式系统将更多地与物联网设备和人工智能算法相结…...

【微信小程序】wxss 和 css 、wxml 和 html 区别
wxss 和 css 区别 wxss 支持小程序特有的选择器和 样式属性 scroll-into-view cover-view 等wxss 引入了 rpx 单位,可以根据屏幕宽度进行自适应,使得开发者可以更方便的处理不同尺寸屏幕的适配问题。wxss 背景图片只能引入外链,不能使用本地…...

python统计分析——使用AIC进行模型选择
参考资料:用python动手学统计学 1、导入库 # 导入库 # 用于数值计算的库 import numpy as np import pandas as pd import scipy as sp from scipy import stats # 用于绘图的库 import matplotlib.pyplot as plt import seaborn as sns sns.set() # 用于估计统计…...
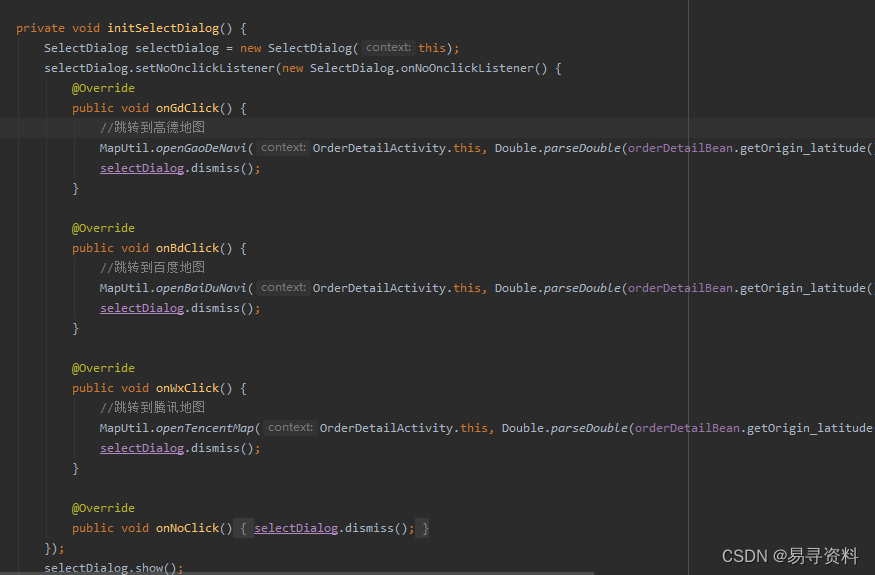
Android 11以上获取不到第三方app是否安装
开年第一篇,处理了一下年前的小问题。 问题:本地app跳转到第三方app地图进行导航,获取不到第三方地图是否安装。 解决: 1.添加包名 This can be done by adding a <queries> element in the Android manifest.在app下的…...
Java的编程之旅24——private私有方法
1.private的介绍 在面向对象编程中,private是一种访问修饰符,用于限制成员的访问范围。私有成员只能在所属的类内部访问,对外部的类或对象是不可见的。 private的使用可以带来以下几个好处: 封装实现细节:私有成员可…...
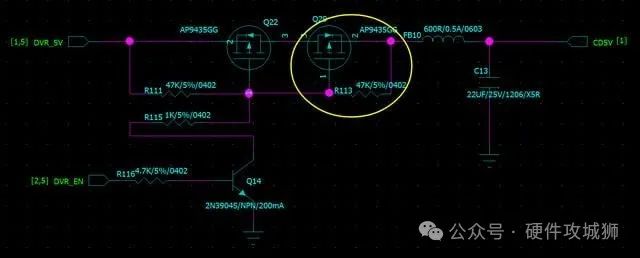
为什么在MOS管开关电路设计中使用三极管容易烧坏?
MOS管作为一种常用的开关元件,具有低导通电阻、高开关速度和低功耗等优点,因此在许多电子设备中广泛应用。然而,在一些特殊情况下,我们需要在MOS管控制电路中加入三极管来实现一些特殊功能。然而,不同于MOS管ÿ…...

CSS的注释:以“ /* ”开头,以“ */ ”结尾
CSS的注释:以“ /* ”开头,以“*/”结尾 CSS的注释: 以“ /* ”开头,以“ */ ”结尾 在CSS中,注释是一种非常重要的工具,它们可以帮助开发者记录代码的功能、用法或其他重要信息。这些信息对于理解代码、维护代码以及与他人合作都…...

MySQL中常见的几种日志类型【重点】
在MySQL中,有几种不同类型的日志,用于记录数据库的活动和操作,以便于故障排查、性能调优和数据恢复等目的。以下是MySQL中常见的几种日志类型: 错误日志(Error Log): 错误日志记录了MySQL服务器…...
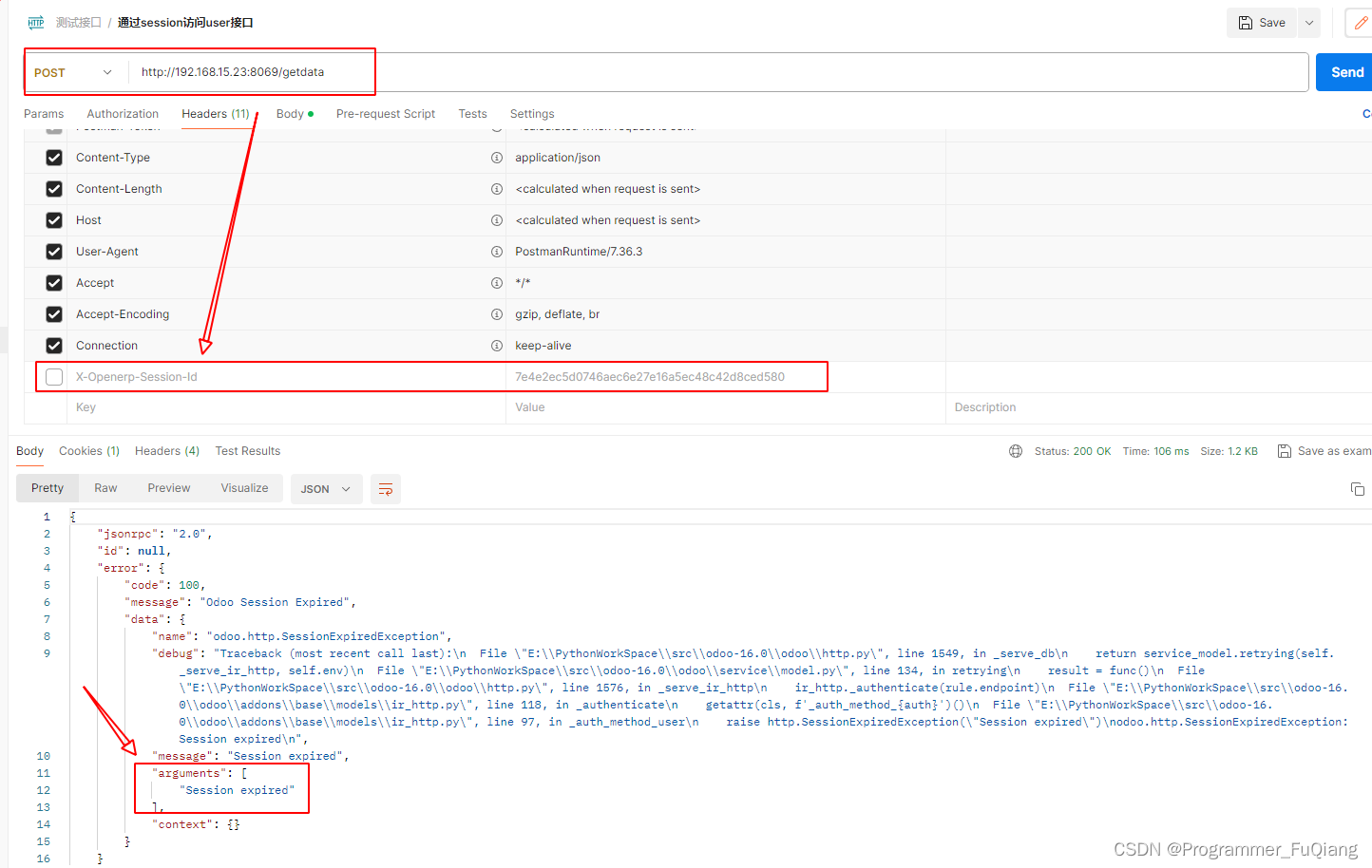
odoo16-API(Controller)带有验证访问的接口
odoo16-API(Controller)带有验证访问的接口 目前我使用odoo原生的登录token来验证登陆的有效性 废话不多说直接上代码 # 测试获取session_id import requests class GetOdooData(http.Controller):def getOdooToken(self):# http://localhost:8123访问…...
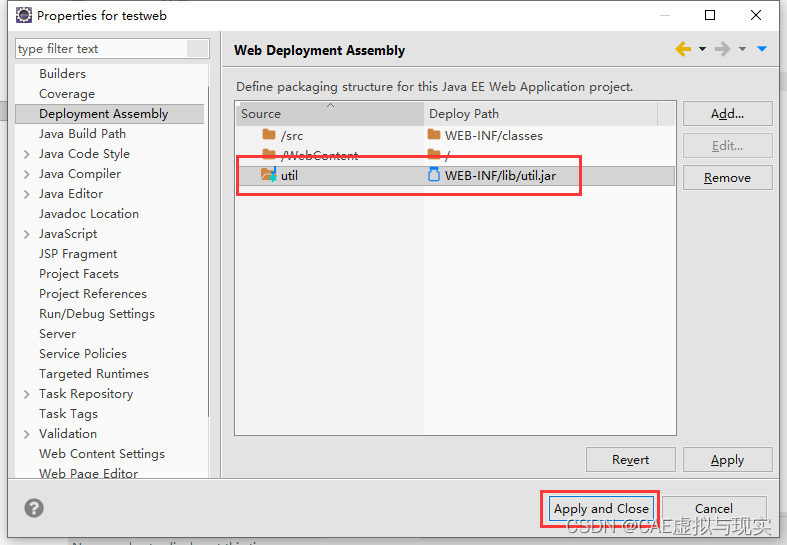
Eclipse项目间的引用
我们在开发的时候,有时候需要把一个大的项目打散,尤其是现在微服务的架构很流行,一个大的项目往往被拆成很多小的项目,而有的项目作为公共工程被独立出来,比如有个工程专门提供各种Util工具类,有的工程专门…...
的排列)
matplotlib使用案例3:通过自定义图例类实现图例的任意方向(行 or 列)的排列
这个方法的核心依然是基于matplotlib.legend._get_legend_handles_labels函数。然后将得到的handlers, labels进行重排,使得即使再调用Legend类的绘制方法对图例进行列排列,最终的效果也是图例的行显示,如[1、2、3、4、5、6],当指定ncols=2,Legend类的绘制方法得到的图例如…...

js设计模式:依赖注入模式
作用: 在对象外部完成两个对象的注入绑定等操作 这样可以将代码解耦,方便维护和扩展 vue中使用use注册其他插件就是在外部创建依赖关系的 示例: class App{constructor(appName,appFun){this.appName appNamethis.appFun appFun}}class Phone{constructor(app) {this.nam…...

【性能最佳实践】事务处理和读写策略原来这么关键!
MongoDB针对初级,中级及熟练的技术开发人员推出系列技术文章与行业案例。深入浅出地剖析MongoDB产品基础原理,使用技巧,典型行业场景及应用,还有Code Demo及线上线下活动推荐! 欢迎阅读有关MongoDB性能最佳实践的系列…...

【广度优先搜索】【网格】【割点】【 推荐】1263. 推箱子
作者推荐 视频算法专题 涉及知识点 广度优先搜索 网格 割点 并集查找 LeetCode:1263. 推箱子 「推箱子」是一款风靡全球的益智小游戏,玩家需要将箱子推到仓库中的目标位置。 游戏地图用大小为 m x n 的网格 grid 表示,其中每个元素可以是墙、地板或…...
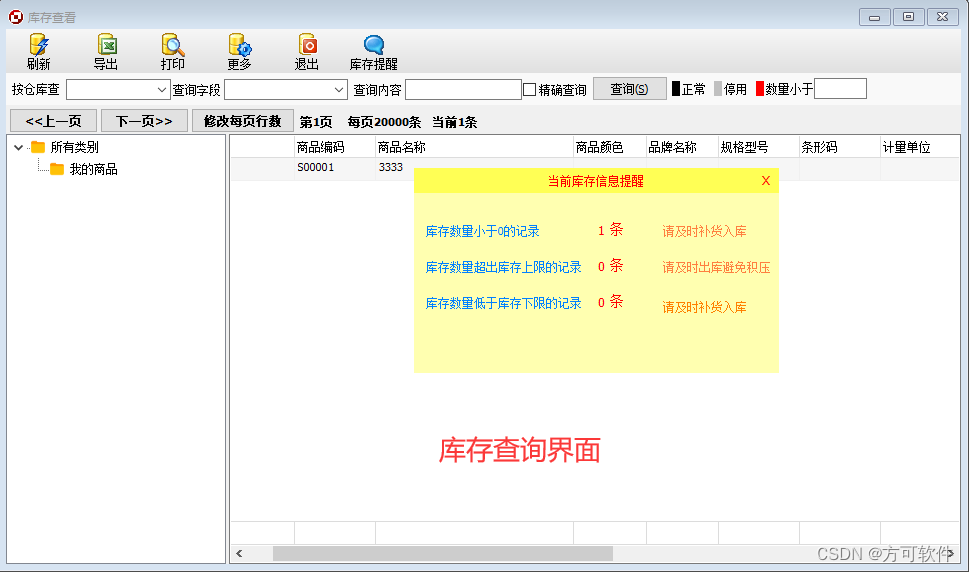
开店怎么做进销存
开设一家店铺,无论是实体店还是网店,进销存管理都是确保店铺正常运营和盈利的关键环节。一款良好的进销存管理软件可以帮助你更好地掌握库存情况、优化采购策略、提高销售效率,并最终实现盈利目标。那么,开店怎么做进销存管理呢&a…...
UE4 C++联网RPC教程笔记(三)(第8~9集)完结
UE4 C联网RPC教程笔记(三)(第8~9集)完结 8. exe 后缀实现监听服务器9. C 实现监听服务器 8. exe 后缀实现监听服务器 前面我们通过蓝图节点实现了局域网连接的功能,实际上我们还可以给项目打包后生成的 .exe 文件创建…...
)
Codesys ST语言实战:手把手教你读写XML配置文件(附完整工程源码)
Codesys ST语言实战:工业级XML配置文件读写全解析 在工业自动化领域,设备参数配置与数据交换一直是工程师们面临的日常挑战。想象一下这样的场景:深夜的生产线上,一台关键设备突然需要更新200多个工艺参数,而传统的HMI…...
)
给嵌入式Web服务器加个“胃”:手把手教你用lwIP-2.1.3的httpd处理POST表单数据(含内存管理避坑)
嵌入式Web服务器的"消化系统":lwIP-2.1.3 POST数据处理深度解析 在资源受限的嵌入式设备中实现Web表单交互,就像为设备安装了一个精密的"消化系统"。这个系统需要高效处理来自外部的数据"营养",同时避免因&quo…...

AI测试的现状与未来:AI会取代人工测试吗
在软件测试领域,AI技术的崛起正掀起一场深刻变革。从自动化测试用例生成到智能缺陷检测,AI的应用场景不断拓展,效率提升显著。这让众多软件测试从业者不禁心生焦虑:AI是否会彻底取代人工测试?要解答这个问题࿰…...
)
从串行通信到SerDes:深入聊聊CDR电路的那些‘辅助’设计(频率捕获篇)
从串行通信到SerDes:深入解析CDR电路中的频率捕获设计 在高速串行通信系统中,时钟和数据恢复(CDR)电路扮演着至关重要的角色。当数据速率突破10Gbps甚至更高时,传统的锁相环(PLL)设计面临着前所未有的挑战——如何在随机数据流中快速准确地锁…...

MifareOneTool完全指南:零基础掌握Windows最强NFC卡片管理工具
MifareOneTool完全指南:零基础掌握Windows最强NFC卡片管理工具 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 你是否曾经面对…...
)
麒麟系统离线部署OnlyOffice,我踩过的那些坑(附Docker镜像包和完整配置)
麒麟系统离线部署OnlyOffice实战避坑指南 在国产化替代浪潮中,麒麟系统作为主流国产操作系统,正逐步应用于各类关键信息基础设施领域。而办公软件作为日常刚需,如何在麒麟系统上实现高效、安全的文档协作成为许多技术团队面临的挑战。OnlyOff…...

企业级部署警告:Perplexity事实核查功能未开启溯源审计模式的5大合规风险,GDPR/CCPA双认证团队紧急通告
更多请点击: https://codechina.net 第一章:Perplexity事实核查功能的核心机制与合规定位 Perplexity 的事实核查功能并非依赖单一模型输出,而是构建于多层验证架构之上:实时检索增强生成(RAG)、跨源可信度…...

cstore_fdw迁移指南:从传统表到列式存储的无缝切换
cstore_fdw迁移指南:从传统表到列式存储的无缝切换 【免费下载链接】cstore_fdw Columnar storage extension for Postgres built as a foreign data wrapper. Check out https://github.com/citusdata/citus for a modernized columnar storage implementation bui…...

解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘
解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘 【免费下载链接】ditaa ditaa is a small command-line utility that can convert diagrams drawn using ascii art (drawings that contain characters that resemble lines like | / - ), into proper…...

CANN/asc-devkit队列屏障API
QueueBarrier 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...