挑战杯 基于人工智能的图像分类算法研究与实现 - 深度学习卷积神经网络图像分类
文章目录
- 0 简介
- 1 常用的分类网络介绍
- 1.1 CNN
- 1.2 VGG
- 1.3 GoogleNet
- 2 图像分类部分代码实现
- 2.1 环境依赖
- 2.2 需要导入的包
- 2.3 参数设置(路径,图像尺寸,数据集分割比例)
- 2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
- 2.5 数据预处理
- 2.6 训练分类模型
- 2.7 模型训练效果
- 2.8 模型性能评估
- 3 1000种图像分类
- 4 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于人工智能的图像分类技术
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 常用的分类网络介绍
1.1 CNN
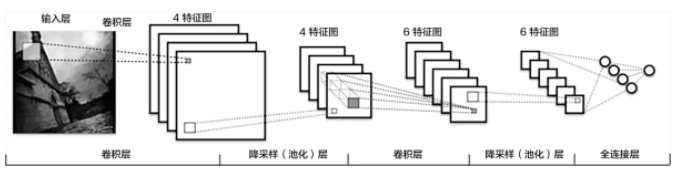
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。如下图:
-
卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
-
池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
-
全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
-
非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
-
Dropout : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合
在CNN的训练过程总,由于每一层的参数都是不断更新的,会导致下一次输入分布发生变化,这样就需要在训练过程中花费时间去设计参数。在后续提出的BN算法中,由于每一层都做了归一化处理,使得每一层的分布相对稳定,而且实验证明该算法加速了模型的收敛过程,所以被广泛应用到较深的模型中。
1.2 VGG
VGG 模型是由牛津大学提出的(19层网络),该模型的特点是加宽加深了网络结构,核心是五组卷积操作,每两组之间做Max-
Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。该模型由于每组内卷积层的不同主要分为
11、13、16、19 这几种模型

增加网络深度和宽度,也就意味着巨量的参数,而巨量参数容易产生过拟合,也会大大增加计算量。
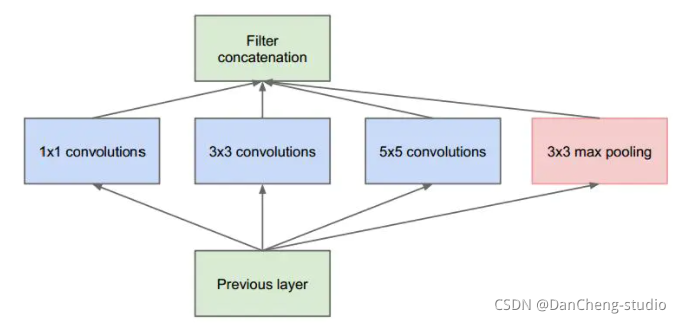
1.3 GoogleNet
GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想.
NIN模型特点:
-
1. 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。 - 2)设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
2 图像分类部分代码实现
2.1 环境依赖
python 3.7
jupyter-notebook : 6.0.3
cudatoolkit 10.0.130
cudnn 7.6.5
tensorflow-gpu 2.0.0
scikit-learn 0.22.1
numpy
cv2
matplotlib
2.2 需要导入的包
import osimport cv2import numpy as npimport pandas as pdimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers,modelsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.callbacks import Callbackfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.applications import VGG19from tensorflow.keras.models import load_modelimport matplotlib.pyplot as pltfrom sklearn.preprocessing import label_binarizetf.compat.v1.disable_eager_execution()os.environ['CUDA_VISIBLE_DEVICES'] = '0' #使用GPU
2.3 参数设置(路径,图像尺寸,数据集分割比例)
preprocessedFolder = '.\\ClassificationData\\' #预处理文件夹outModelFileName=".\\outModelFileName\\" ImageWidth = 512ImageHeight = 320ImageNumChannels = 3TrainingPercent = 70 #训练集比例ValidationPercent = 15 #验证集比例
2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
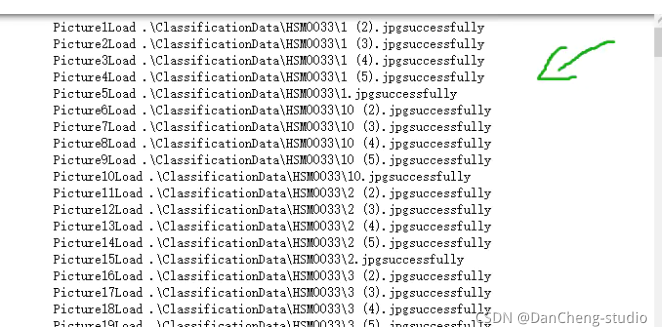
def read_dl_classifier_data_set(preprocessedFolder):num = 0 # 图片的总数量cnt_class = 0 #图片所属的类别label_list = [] # 存放每个图像的label,图像的类别img_list = [] #存放图片数据for directory in os.listdir(preprocessedFolder):tmp_dir = preprocessedFolder + directorycnt_class += 1for image in os.listdir(tmp_dir):num += 1tmp_img_filepath = tmp_dir + '\\' + imageim = cv2.imread(tmp_img_filepath) # numpy.ndarrayim = cv2.resize(im, (ImageWidth, ImageHeight)) # 重新设置图片的大小img_list.append(im)label_list.append(cnt_class) # 在标签中添加类别print("Picture " + str(num) + "Load "+tmp_img_filepath+"successfully")
print("共有" + str(num) + "张图片")
print("all"+str(num)+"picturs belong to "+str(cnt_class)+"classes")
return np.array(img_list),np.array(label_list)all_data,all_label=read_dl_classifier_data_set(preprocessedFolder)
2.5 数据预处理
图像数据压缩, 标签数据进行独立热编码one-hot
def preprocess_dl_Image(all_data,all_label):all_data = all_data.astype("float32")/255 #把图像灰度值压缩到0--1.0便于神经网络训练all_label = to_categorical(all_label) #对标签数据进行独立热编码return all_data,all_labelall_data,all_label = preprocess_dl_Image(all_data,all_label) #处理后的数据
对数据及进行划分(训练集:验证集:测试集 = 0.7:0.15:0.15)
def split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent):s = np.arange(all_data.shape[0])np.random.shuffle(s) #随机打乱顺序all_data = all_data[s] #打乱后的图像数据all_label = all_label[s] #打乱后的标签数据all_len = all_data.shape[0]train_len = int(all_len*TrainingPercent/100) #训练集长度valadation_len = int(all_len*ValidationPercent/100)#验证集长度temp_len=train_len+valadation_lentrain_data,train_label = all_data[0:train_len,:,:,:],all_label[0:train_len,:] #训练集valadation_data,valadation_label = all_data[train_len:temp_len, : , : , : ],all_label[train_len:temp_len, : ] #验证集test_data,test_label = all_data[temp_len:, : , : , : ],all_label[temp_len:, : ] #测试集return train_data,train_label,valadation_data,valadation_label,test_data,test_labeltrain_data,train_label,valadation_data,valadation_label,test_data,test_label=split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent)
2.6 训练分类模型
-
使用迁移学习(基于VGG19)
-
epochs = 30
-
batch_size = 16
-
使用 keras.callbacks.EarlyStopping 提前结束训练
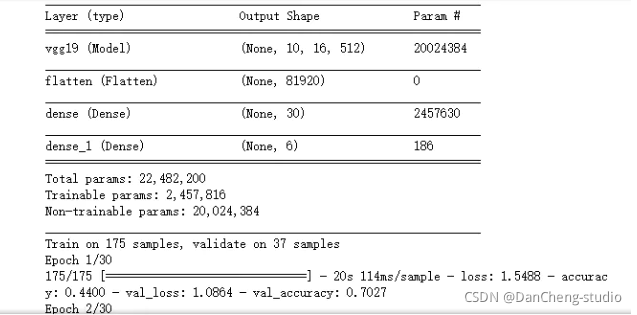
def train_classifier(train_data,train_label,valadation_data,valadation_label,lr=1e-4):conv_base = VGG19(weights='imagenet',include_top=False,input_shape=(ImageHeight, ImageWidth, 3) ) model = models.Sequential()model.add(conv_base)model.add(layers.Flatten())model.add(layers.Dense(30, activation='relu')) model.add(layers.Dense(6, activation='softmax')) #Dense: 全连接层。activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层conv_base.trainable=Falsemodel.compile(loss='categorical_crossentropy',#loss: 拟合损失方法,这里用到了多分类损失函数交叉熵 optimizer=Adam(lr=lr),#optimizer: 优化器,梯度下降的优化方法 #rmspropmetrics=['accuracy'])model.summary() #每个层中的输出形状和参数。early_stoping =tf.keras.callbacks.EarlyStopping(monitor="val_loss",min_delta=0,patience=5,verbose=0,baseline=None,restore_best_weights=True)history = model.fit(train_data, train_label,batch_size=16, #更新梯度的批数据的大小 iteration = epochs / batch_size,epochs=30, # 迭代次数validation_data=(valadation_data, valadation_label), # 验证集callbacks=[early_stoping])return model,history model,history = train_classifier(train_data,train_label,valadation_data,valadation_label,)
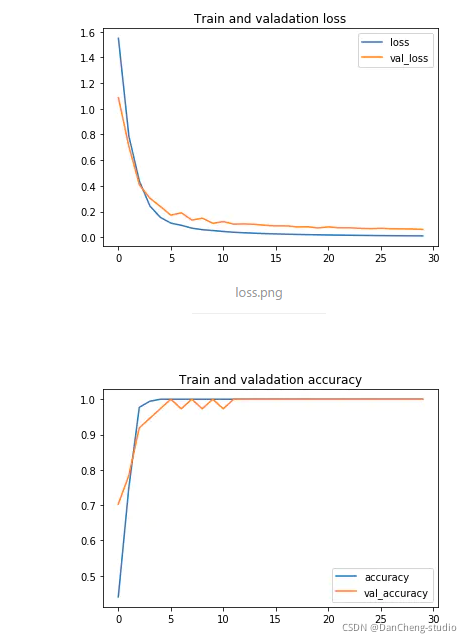
2.7 模型训练效果
def plot_history(history):history_df = pd.DataFrame(history.history)history_df[['loss', 'val_loss']].plot()plt.title('Train and valadation loss')history_df = pd.DataFrame(history.history)history_df[['accuracy', 'val_accuracy']].plot()plt.title('Train and valadation accuracy')plot_history(history)
2.8 模型性能评估
-
使用测试集进行评估
-
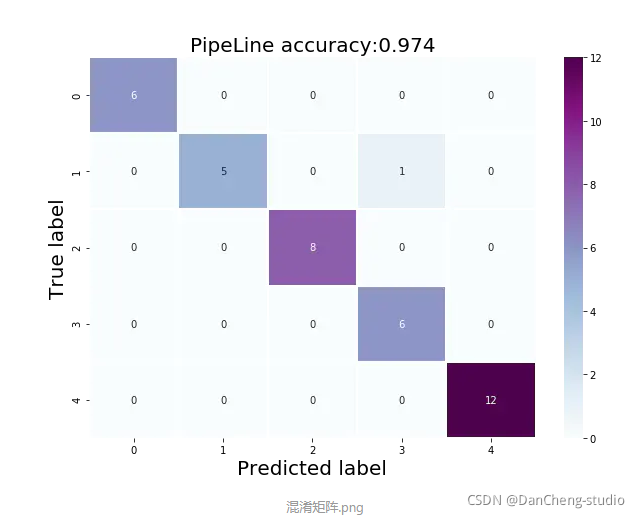
输出分类报告和混淆矩阵
-
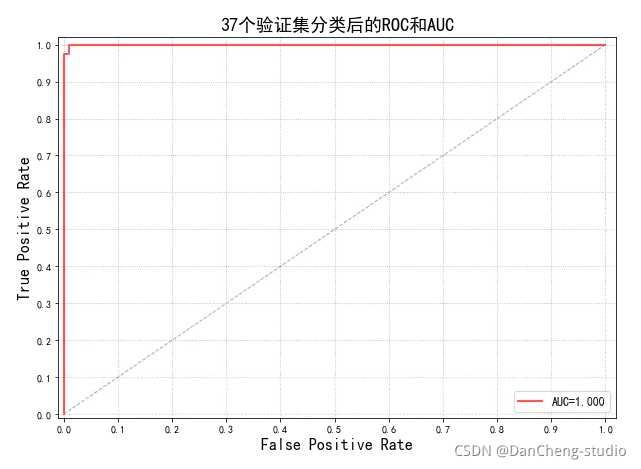
绘制ROC和AUC曲线
from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score import seaborn as sns Y_pred_tta=model.predict_classes(test_data) #模型对测试集数据进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 Y_pred_tta=model.predict_classes(test_data) #模型对测试集进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 print('验证集分类报告:\n',classification_report(Y_test,Y_pred_tta)) confusion_mc = confusion_matrix(Y_test,Y_pred_tta)#混淆矩阵 df_cm = pd.DataFrame(confusion_mc) plt.figure(figsize = (10,7)) sns.heatmap(df_cm, annot=True, cmap="BuPu",linewidths=1.0,fmt="d") plt.title('PipeLine accuracy:{0:.3f}'.format(accuracy_score(Y_test,Y_pred_tta)),fontsize=20) plt.ylabel('True label',fontsize=20) plt.xlabel('Predicted label',fontsize=20)

from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.metrics import roc_curve
from sklearn import metrics
import matplotlib as mpl# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(test_data)
# 1、调用函数计算验证集的AUC
print ('调用函数auc:', metrics.roc_auc_score(test_label, y_score, average='micro'))
# 2、手动计算验证集的AUC
#首先将矩阵test_label和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(test_label.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.figure(figsize = (10,7))
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title('37个验证集分类后的ROC和AUC', fontsize=18)
plt.show()
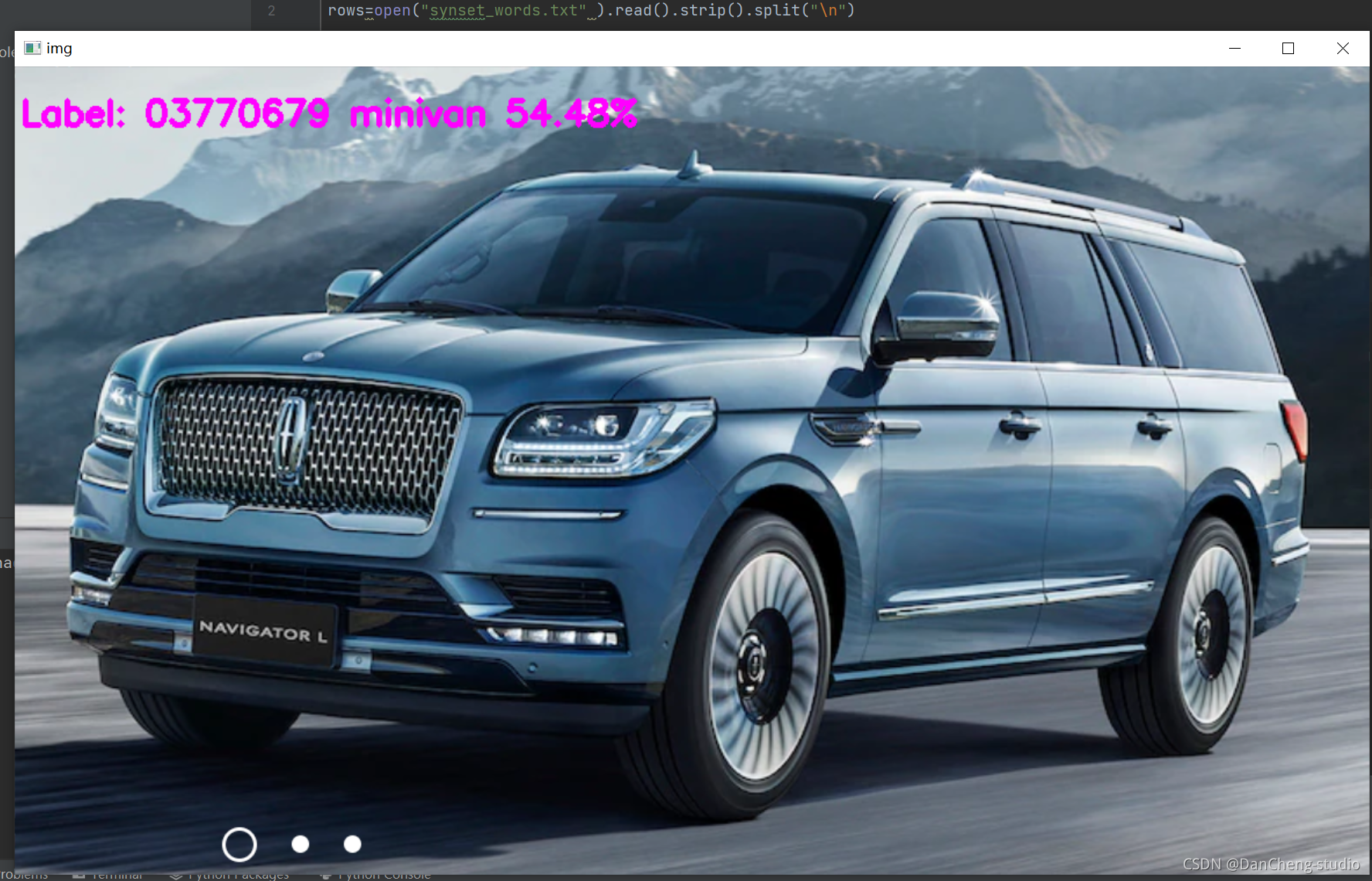
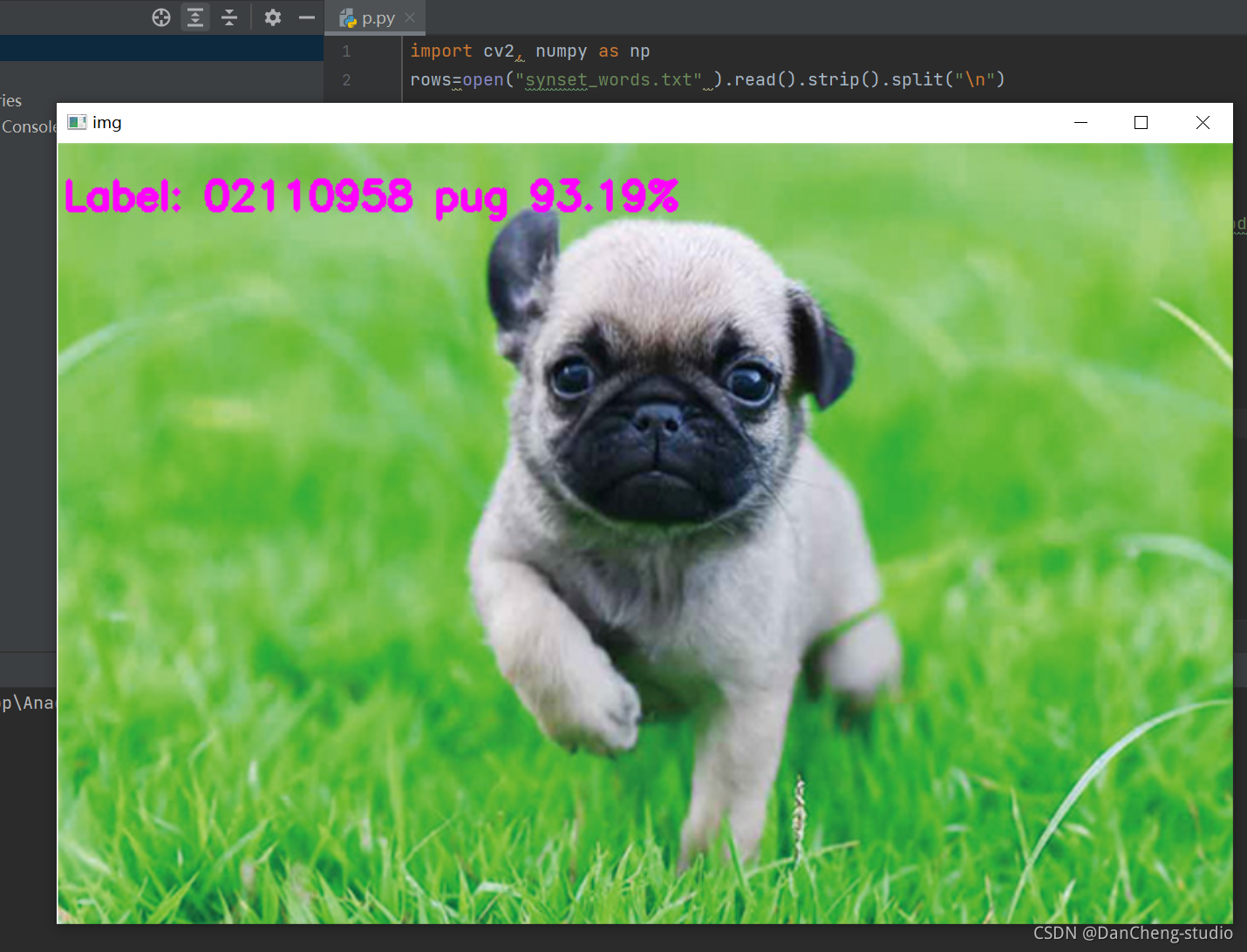
3 1000种图像分类
这是学长训练的能识别1000种类目标的图像分类模型,演示效果如下

4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
挑战杯 基于人工智能的图像分类算法研究与实现 - 深度学习卷积神经网络图像分类
文章目录 0 简介1 常用的分类网络介绍1.1 CNN1.2 VGG1.3 GoogleNet 2 图像分类部分代码实现2.1 环境依赖2.2 需要导入的包2.3 参数设置(路径,图像尺寸,数据集分割比例)2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)2.5 数据预…...

Spring6学习技术|IoC|手写IoC
学习材料 尚硅谷Spring零基础入门到进阶,一套搞定spring6全套视频教程(源码级讲解) 有关反射的知识回顾 IoC是基于反射机制实现的。 Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法&…...
基于Java在线宠物店商城系统设计与实现(源码+部署文档)
博主介绍: ✌至今服务客户已经1000、专注于Java技术领域、项目定制、技术答疑、开发工具、毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到 Java项目精品实…...
http和https的区别(简述)
HTTP(HyperText Transfer Protocol)和HTTPS(HTTP Secure)都是用于在客户端和服务器之间传输数据的协议,但它们在安全性方面有重要的区别。 1.HTTP: 概述: HTTP是一种用于传输超文本的协议(超文…...

2024年【T电梯修理】找解析及T电梯修理复审考试
题库来源:安全生产模拟考试一点通公众号小程序 T电梯修理找解析是安全生产模拟考试一点通总题库中生成的一套T电梯修理复审考试,安全生产模拟考试一点通上T电梯修理作业手机同步练习。2024年【T电梯修理】找解析及T电梯修理复审考试 1、【多选题】操纵箱…...
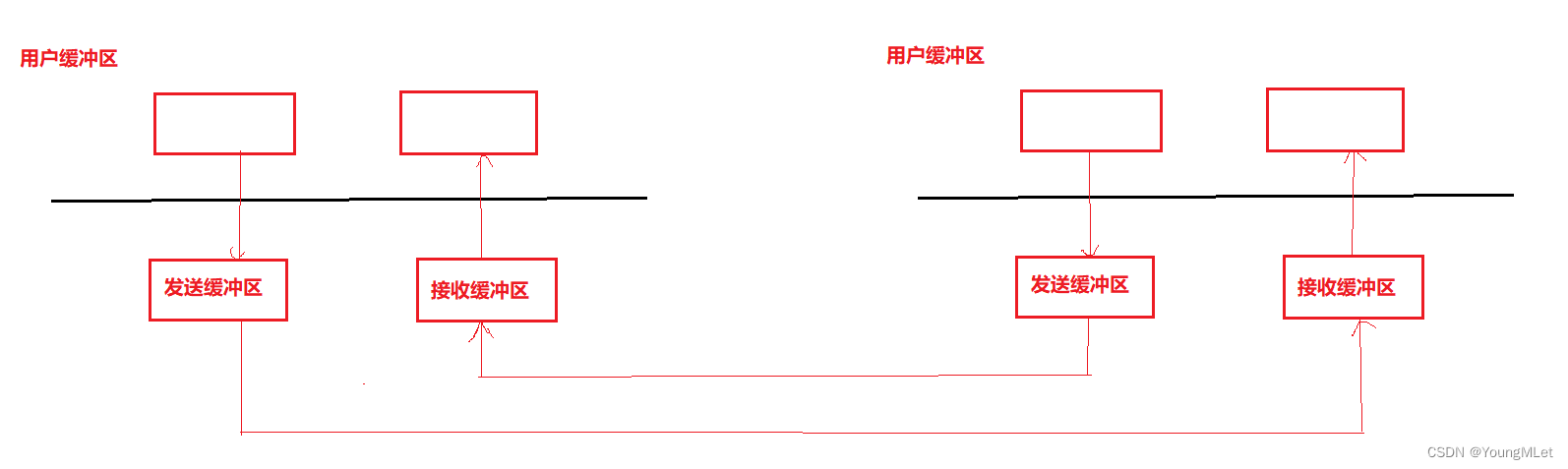
【计算机网络】socket 网络套接字
网络套接字 一、端口号1. 认识端口号2. socket 二、认识TCP协议和UDP协议1. TCP协议2. UDP协议 三、网络字节序四、socket 编程1. socket 常见API2. sockaddr 结构3. 编写 UDP 服务器(1)socket()(2)bind()(3࿰…...
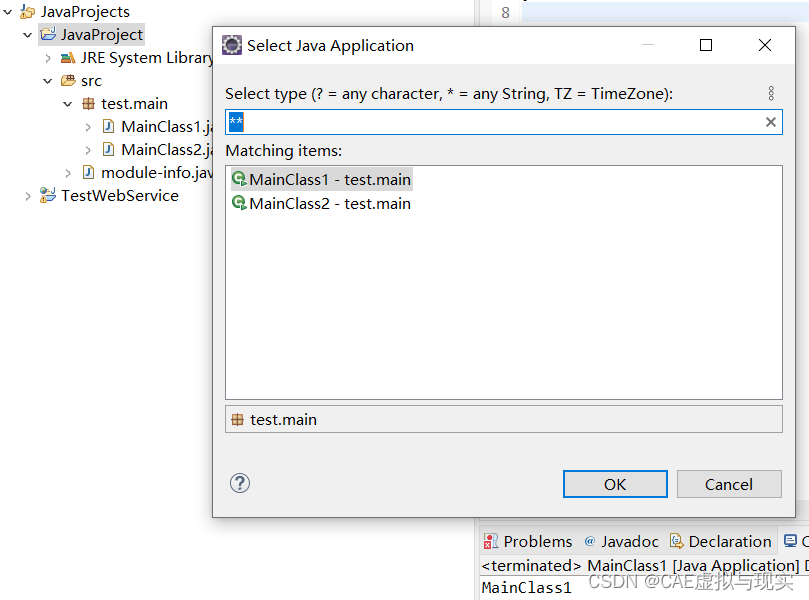
Eclipse的Java Project的入口main函数
在使用Eclipse创建java project项目的时候,一个项目里面通常只有一个main,那么一个项目里面是否可以有多个main函数呢?其实可以的,但是运行java application的时候要选择执行哪个main函数。 下面举个例子: 1、创建一个…...

JVM内存分析工具-Arthas 教程[详细]
一、概述 Arthas(阿尔萨斯)是阿里巴巴开源的一款Java诊断工具,用于实时检测、诊断Java应用程序的性能问题。它是一个命令行工具,提供了丰富的功能,包括查看类加载信息、方法执行耗时、线程堆栈、内存分析等。Arthas 的…...
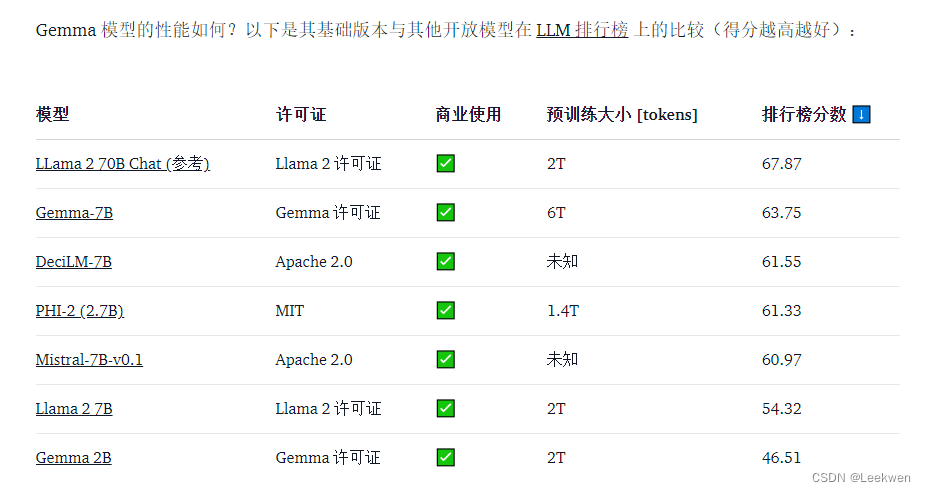
Google发布开放的模型Gemma
今天,Google 发布了一系列最新的开放式大型语言模型 —— Gemma!Google 正在加强其对开源人工智能的支持,我们也非常有幸能够帮助全力支持这次发布,并与 Hugging Face 生态完美集成。 Gemma 提供两种规模的模型: 7B …...
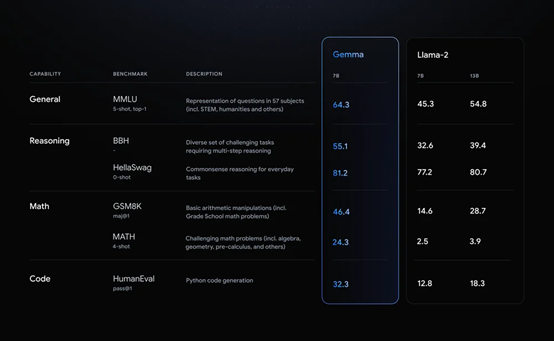
谷歌掀桌子!开源Gemma:可商用,性能超过Llama 2!
2月22日,谷歌在官网宣布,开源大语言模型Gemma。 Gemma与谷歌最新发布的Gemini 使用了同一架构,有20亿、70亿两种参数,每种参数都有预训练和指令调优两个版本。 根据谷歌公布的测试显示,在MMLU、BBH、GSM8K等主流测试…...

http缓存?强制缓存和协商缓存?
HTTP缓存是一种优化网络资源加载速度的技术,通过减少从服务器获取相同资源的次数来实现。HTTP缓存机制包括强制缓存和协商缓存(对比缓存)两种类型。 强制缓存 强制缓存是指浏览器在接收到服务器返回的响应后,会将响应内容和相关…...

技术心得--如何成为优秀的架构师
关注我,持续分享逻辑思维&管理思维; 可提供大厂面试辅导、及定制化求职/在职/管理/技术辅导; 有意找工作的同学,请参考博主的原创:《面试官心得--面试前应该如何准备》,《面试官心得--面试时如何进行自…...

【Unity】【VR开发】Unity云同步功能使用心得
【背景】 有时出差,旅行等等也带着电脑,晚上想要继续编辑项目,就需要用到云同步功能。目前实践下来,发现有些内容可以同步,有些内容则是不可以同步的,总结如下。 【如何云同步一个本地项目】 UnityHub的项目面板中有两个选项卡:项目和云端项目。 鼠标挪动到想要云同步…...
vscode侧边框关掉了怎么打开
View - Appearance - Secondary Side Bar 就可以显示出来了,例如 :(CodeGeeX不显示主界面)...
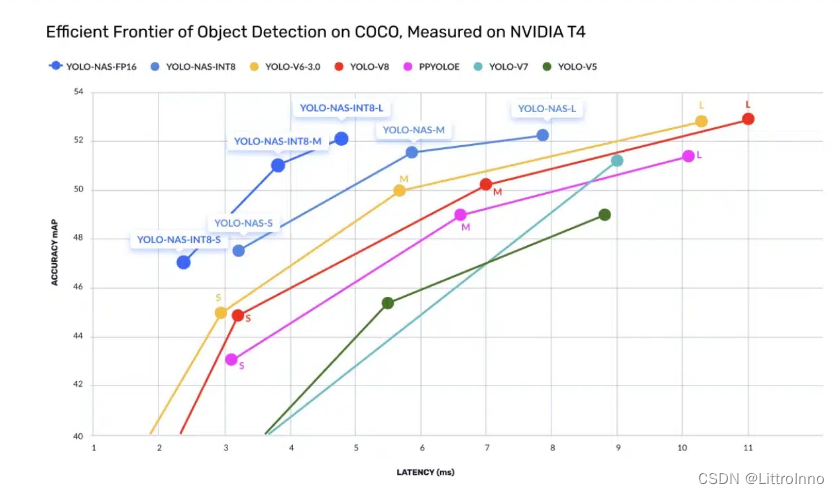
YOLO-NAS浅析
YOLO-NAS(You Only Look Once - Neural Architecture Search)是一种基于YOLO(You Only Look Once)的目标检测算法,结合神经架构搜索(NAS)技术来优化模型性能。 YOLO是一种实时目标检测算法&…...

LeetCode 2656.K个元素的最大和
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。你需要执行以下操作 恰好 k 次,最大化你的得分: 从 nums 中选择一个元素 m 。 将选中的元素 m 从数组中删除。 将新元素 m 1 添加到数组中。 你的得分增加 m 。 请你返回执行以上操作恰好 k 次后…...
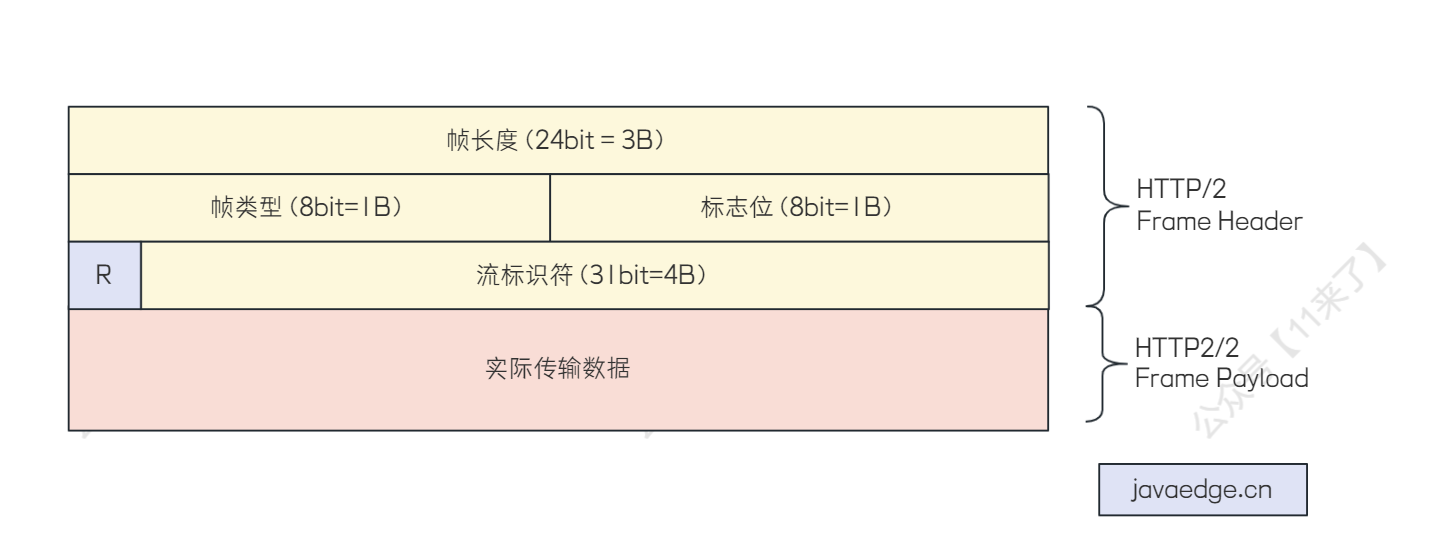
【最新Dubbo3深入理解】Dubbo3核心Tripple协议详解
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址…...

神秘人暗访:行政窗口为什么要开展神秘顾客调研
在竞争日益激烈的服务市场中,行政窗口作为公共服务的直接提供者,其服务质量的好坏直接关系到政府的形象和公众对政府的信任度。为了更好地满足市民的需求,提升服务质量,开展神秘顾客调查显得尤为重要。神秘顾客调查的必要性包括以…...
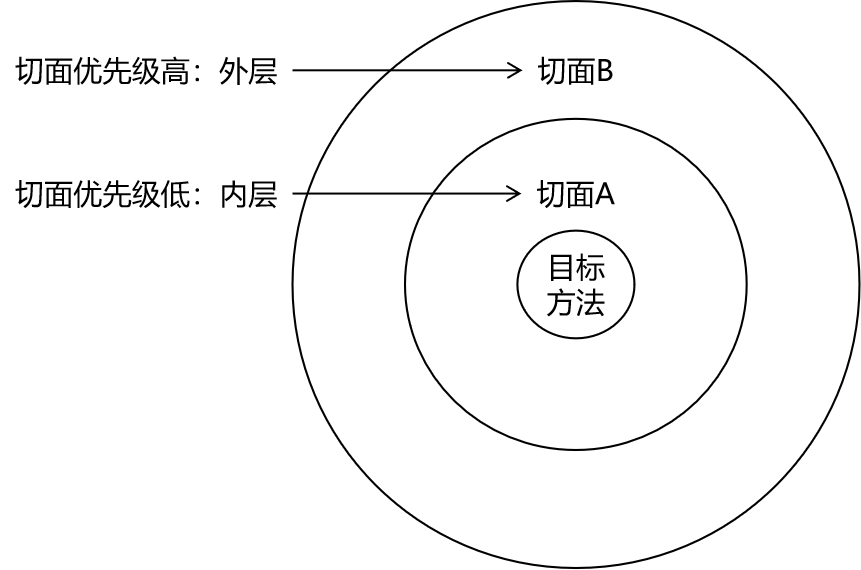
Spring之AOP
文章目录 初步实现通知执行顺序 各个通知获取细节信息重用切点表达式切点表达式语法细节环绕增强切面的优先级没有接口的情况基于XML的AOP[了解] 初步实现 先导入Spring和Junit4的依赖 <dependency><groupId>org.springframework</groupId><artifactId&g…...
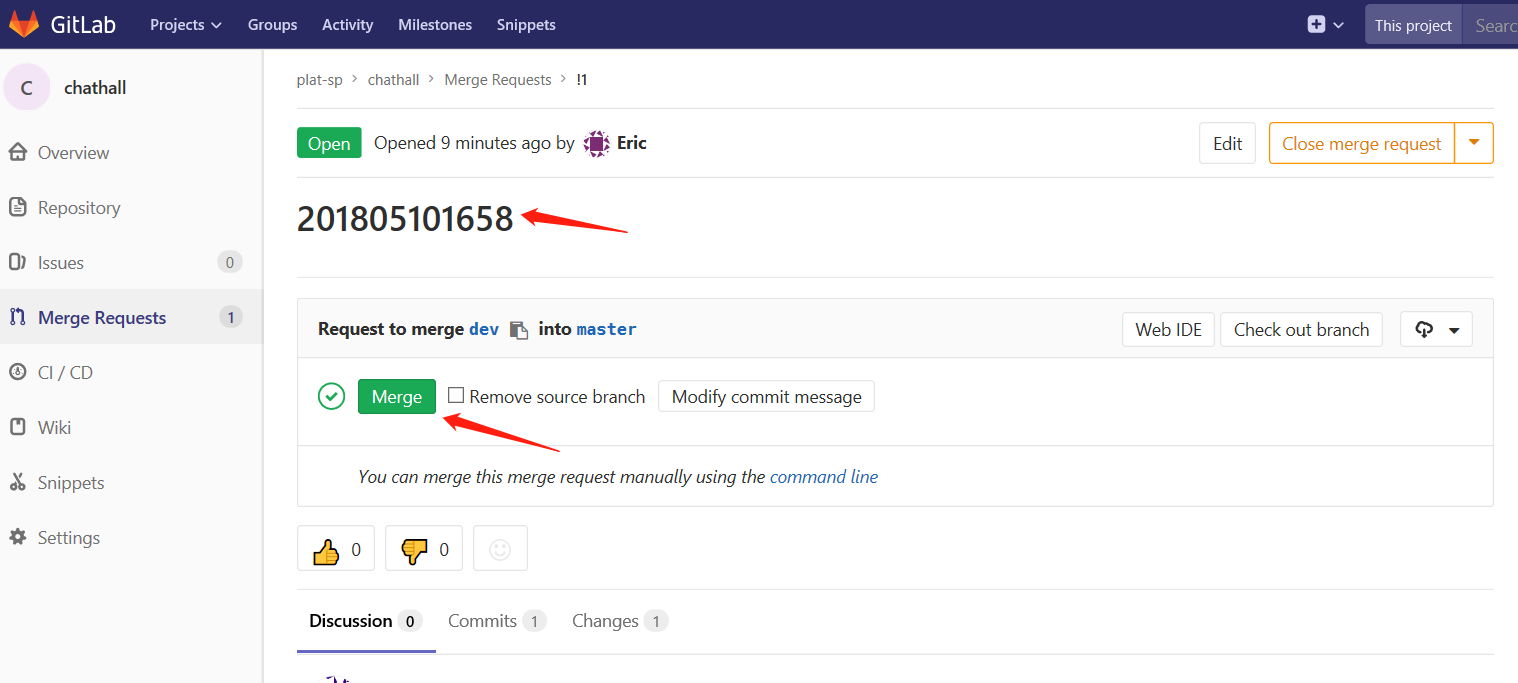
Git详解及 github与gitlab使用
目录 1.1 关于版本控制 1.1.1 本地版本控制 1.1.2 集中化的版本控制系统 1.1.3 分布式版本控制系统 1.2 Git简介 1.2.1 Git历史 1.3 安装git 1.3.1 环境说明 1.3.2 Yum安装Git 1.3.3 编译安装 1.4 初次运行 Git 前的配置 1.4.1 配置git 1.4.2 获取帮助 1.5 获取 G…...

深入解析Keil MDK FLM算法:SRAM运行原理与下载机制
1. 项目概述:FLM算法,Keil MDK下载的“灵魂引擎”如果你用Keil MDK给一块新的APM32或者STM32芯片下载程序,点下那个“Download”或“Load”按钮,几秒钟后“Programming Done”的提示框弹出,这个过程看似简单࿰…...

极化激元量子流体:从Bogoliubov色散到引力模拟的精密探测
1. 项目概述:当光“流动”起来我们通常认为光是一种波,或者是一束没有质量的粒子。但在特定的物理舞台上,光的行为可以变得非常“不寻常”——它能够像水一样流动,甚至像超流体那样无摩擦地运动。这就是“光的量子流体”这一前沿领…...

书匠策AI降重降AIGC实测|官网www.shujiangce.com |微信公众号搜一搜 书匠策AI
🧪 一个实验室级别的"论文手术台" 各位正在跟毕业论文死磕的朋友,我今天不讲方法论,不拆写作技巧,我要给你们开一间"论文急诊室"。 你有没有经历过这种绝望:辛辛苦苦写完一万字,查重…...

语义搜索实战:从关键词到向量检索
本文面向:想深入理解语义搜索实现原理的开发者。 预计阅读时间:10 分钟 关键词搜索已经够用了?试试搜"怎么解决数据库死锁"——你可能漏掉所有标题写"SQLite WAL mode"、"并发写入冲突"的笔记。语义搜索能跨越…...
)
为什么顶级策展人不用Google搜文化新闻?Perplexity文化垂直搜索的5层语义增强架构(含可复用prompt工程模板)
更多请点击: https://kaifayun.com 第一章:为什么顶级策展人不用Google搜文化新闻? 顶级策展人并非排斥搜索引擎,而是早已构建起一套高度结构化、语义化、可验证的信息摄取系统——它绕过关键词匹配的偶然性,直击文化…...

好用的临沂GEO生成式引擎优化公司
在当今数字化时代,互联网的发展日新月异,AI搜索逐渐成为人们获取信息的重要方式。对于企业和个人来说,如何在海量信息中脱颖而出,让自己的产品、品牌、理念被客户第一时间找到,成为了亟待解决的问题。临沂好味来文化传…...

一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南
一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...
核心参数保姆级解读)
别再死记硬背参数了!Halcon形状匹配(create_shape_model)核心参数保姆级解读
Halcon形状匹配核心参数深度解析:从原理到实战调参指南 在工业视觉检测领域,形状匹配技术一直是定位和识别的核心手段。Halcon作为行业领先的机器视觉软件,其create_shape_model和find_shape_model算子提供了强大的形状匹配能力。然而&#…...

终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题!
终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题! 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备无法…...

如何免费使用R3nzSkin游戏皮肤修改器:完整技术指南与内存钩子实战
如何免费使用R3nzSkin游戏皮肤修改器:完整技术指南与内存钩子实战 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin R3nzSkin是一款专为《英雄联盟》设计的开源游戏皮肤修改器&a…...