Python-pdfplumber读取PDF内容
文章目录
- 前言
- 一、pdfplumber模块
- 1.1 pdfplumber的特点
- 1.2 pdfplumber.PDF类
- 1.3pdfplumber.Page类
- 二 pdfplumber的使用
- 2.1 加载PDF
- 2.2 pdfplumber.PDF 类
- 2.3 pdfplumber.Page 类
- 2.4 读取PDF
- 2.5 读取PDF文档信息
- 2.6 查看总页数
- 2.7 查看总页数读取第一页的宽度,页高等信息
- 2.8 读取文本
- 2.9 读取表格
- 3.1 pdfplumber提取表格数据
- 示例
- 读取文字
- 读取表格
前言
PDF是一种编写文档格式,便于跨操作系统传播文档。Python的开源库 pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者、创建时间、修改时间…)及表格、文本、图片等信息,基本可以满足较为简单的格式转换功能。
一、pdfplumber模块
1.1 pdfplumber的特点
- 1、可以轻松访问有关每个PDF对象的详细信息。
- 2、可以提取文本和表格的更高级别,可以自定义的方法。
- 3、支持紧密集成的可视化调试。
- 4、有通过裁剪框过滤对象等实用功能。

pdfplumber中有两个基础类,PDF和Page。PDF用来处理整个文档,Page用来处理整个页面。
1.2 pdfplumber.PDF类
- .metadata: 获取pdf基础信息,返回字典
- pages 一个包含pdfplumber.Page实例的列表,每一个实例代表pdf每一页的信息。
1.3pdfplumber.Page类
pdfplumber核心功能,对PDF的大部分操作都是基于这个类,包括提取文本、表格、尺寸等。
二 pdfplumber的使用
2.1 加载PDF
调用pdfplumber.open(x)加载PDF, 其中x可以有以下几种格式:a、PDF文件路径。b、文件对象, 以字节流形式加载。c、类文件对象, 以字节流形式加载。
读取 PDF代码:pdfplumber.open("路径/文件名.pdf",password="test",laparams={"line_overlap":0.7})
解读:
passworf:加载受密码保护的PDF要传递password关键字参数。
laparams:将布局分析参数设置为pdfminer.six的布局引擎,传递laparams关键字参数。
2.2 pdfplumber.PDF 类
pdfplumber.PDF 类代表一个PDF文件,主要有两个属性。
| 属性 | 说明 |
|---|---|
| .metadata | 元数据键值对字典,摘自PDF的“信息”。通常包括“CreationDate"(创建日期)、“ModDate"(修改日期)、Producer"(创建者)等。 |
| .pages | 包含pdfplumber . Page(页实例)的列表。 |
2.3 pdfplumber.Page 类
pdfplumber.Page是pdfplumber核心,大部分的操作都是围绕此类进行。
| 属性 | 说 |
|---|---|
| .page_number | 页码 |
| .width | 页面宽 |
| .height | 页面长 |
| .objects/ .chars /.lines /. rects /. curves / . images | 属性中的每一个都是一个列表,每个列表都是嵌入在页面上的每个此类对象包含一个字典。 |
2.4 读取PDF
import pdfplumber
import pandas as pdwith pdfplumber.open("ag-energy-round-up-2017-02-24.pdf") as pdf:
2.5 读取PDF文档信息
with pdfplumber.open("ag-energy-round-up-2017-02-24.pdf") as pdf:print(pdf.metadata)结果
{‘Title’: ‘National Ag Energy’, ‘Author’: ‘LGMN, Des Moines, IA’, ‘Keywords’: ‘National Ag Energy ethanol biodiesel bioenergy’, ‘CreationDate’: “D:20170224133144-06’00’”, ‘ModDate’: “D:20170224133144-06’00’”, ‘Producer’: ‘Microsoft® Excel® 2013’, ‘Creator’: ‘Microsoft® Excel® 2013’}
2.6 查看总页数
len(pdf.pages)
2.7 查看总页数读取第一页的宽度,页高等信息
first_page = pdf.pages[0]
# 查看页码
print('页码:', first_page.page_number)# 查看页宽print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)
2.8 读取文本
with pdfplumber.open("继(吊岩坪)110-2018-05(都吊东线2区).pdf") as pdf:# 第一页pdfplumber.Page实例first_page = pdf.pages[0]text = first_page.extract_text()print(text)
2.9 读取表格
import pdfplumber
import pandas as pdwith pdfplumber.open("继(吊岩坪)110-2018-05(都吊东线2区).pdf") as pdf:page_third = pdf.pages[0]table_1 = page_third.extract_table()#table_df = pd.DataFrame(table_1[1:], columns=table_1[0])print(table_1)
##三 、示例
3.1 pdfplumber提取表格数据
提取表格数据主要用到extract_tables()和extract_table()两种方法,这两种提取方式各有不同。
extract_tables()方法——输出文档所有表格,返回一个嵌套列表。
with pdfplumber.open(r'继(吊岩坪)110-2018-05(都吊东线2区).pdf') as pdf_info: # 打开pdfpage_one = pdf_info.pages[0]page_one_table = page_one.extract_tables() # 获取pdf第一页的所有表格数据for row in page_one_table:print('第一页的表格数据:', row)extact_table()方法——不会返回文档的所有表格,仅返回行数最多的表格数据。如存在多个行数相等的表格,则默认输出顶部表格数据。表格的每一行都为一个单独的列表,列表中的元素即为原表格的各个单元格的数据。
示例
# 提取pdf表格数据并保存到excel中
import pdfplumber
from openpyxl import Workbookclass PDF(object):def __init__(self, file_path):self.pdf_path = file_path# 读取pdftry:self.pdf_info = pdfplumber.open(self.pdf_path)print('读取文件完成!')except Exception as e:print('读取文件失败:', e)# 打印pdf的基本信息、返回字典,作者、创建时间、修改时间/总页数def get_pdf(self):pdf_info = self.pdf_info.metadatapdf_page = len(self.pdf_info.pages)print('pdf共%s页' % pdf_page)print("pdf文件基本信息:\n", pdf_info)self.close_pdf()# 提取表格数据,并保存到excel中def get_table(self):wb = Workbook() # 实例化一个工作簿对象ws = wb.active # 获取第一个sheetcon = 0try:# 获取每一页的表格中的文字,返回table、row、cell格式:[[[row1],[row2]]]for page in self.pdf_info.pages:for table in page.extract_tables():for row in table:# 对每个单元格的字符进行简单清洗处理row_list = [cell.replace('\n', ' ') if cell else '' for cell in row]ws.append(row_list) # 写入数据con += 1print('---------------分割线,第%s页---------------' % con)except Exception as e:print('报错:', e)finally:wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx')print('写入完成!')self.close_pdf()# 关闭文件def close_pdf(self):self.pdf_info.close()if __name__ == "__main__":file_path = input('请输入pdf文件路径:')pdf_info = PDF(file_path)pdf_info.get_pdf() # 打印pdf基础信息# 提取pdf表格数据并保存到excel中,文件保存到跟pdf同一文件路径下pdf_info.get_table()
import pdfplumber
text_path = r"D:\Project\MyData\Study\GUI\6_GUI编程(第三部分)\第十一章GUI图形用户界面编程.pdf"with pdfplumber.open(text_path) as pdf:print(pdf.pages)#获取pdf文档所有的页,类型是dicttotal_pages = len(pdf.pages)print("total_pages: ",total_pages)page = pdf.pages[0] #获取第一页print(type(page)) #<class 'pdfplumber.page.Page'># print(page.extract_text()) #获取第一页的内容#fitz读取pdf全文content=""for i in range(0,len(pdf.pages)):# page=content += pdf.pages[i].extract_text()# print(page.extract_text())# print(page.extract_tables())# print(content)
读取文字
import pdfplumber
import pandas as pdwith pdfplumber.open("E:\\600aaa_2.pdf") as pdf:page_count = len(pdf.pages)print(page_count) # 得到页数for page in pdf.pages:print('---------- 第[%d]页 ----------' % page.page_number)# 获取当前页面的全部文本信息,包括表格中的文字print(page.extract_text())读取表格
import pdfplumber
import pandas as pd
import rewith pdfplumber.open("E:\\600aaa_1.pdf") as pdf:page_count = len(pdf.pages)print(page_count) # 得到页数for page in pdf.pages:print('---------- 第[%d]页 ----------' % page.page_number)for pdf_table in page.extract_tables(table_settings={"vertical_strategy": "text","horizontal_strategy": "lines","intersection_tolerance":20}): # 边缘相交合并单元格大小# print(pdf_table)for row in pdf_table:# 去掉回车换行print([re.sub('\s+', '', cell) if cell is not None else None for cell in row])相关文章:
Python-pdfplumber读取PDF内容
文章目录 前言一、pdfplumber模块1.1 pdfplumber的特点1.2 pdfplumber.PDF类1.3pdfplumber.Page类 二 pdfplumber的使用2.1 加载PDF2.2 pdfplumber.PDF 类2.3 pdfplumber.Page 类2.4 读取PDF2.5 读取PDF文档信息2.6 查看总页数2.7 查看总页数读取第一页的宽度,页高等…...

js设计模式汇总
目录 前言: 单篇目录: 工厂模式 单例模式 发布订阅模式 观察者模式 中介者模式 建造者模式 解释器模式 依赖注入模式 享元模式 路由模式 计算属性模式 委托者模式 访问者模式 外观模式 备忘录模式 过滤器模式 模板方法模式 状态模式 桥接模式 原型模式 组…...

【Java面试】MongoDB
目录 1、mongodb是什么?2、mongodb特点什么是NoSQL数据库?NoSQL和RDBMS有什么区别?在哪些情况下使用和不使用NoSQL数据库?NoSQL数据库有哪些类型?启用备份故障恢复需要多久什么是master或primary什么是secondary或slave系列文章版…...
在苹果电脑MAC上安装Windows10(双系统安装的详细图文步骤教程)
在苹果电脑MAC上安装Windows10(双系统安装的详细图文步骤教程) 一、准备工作准备项1:U盘作为系统安装盘准备项2:您需要安装的系统镜像 二、启动转换助理步骤1:找到启动转换助理步骤2:启动转换助理步骤3&…...
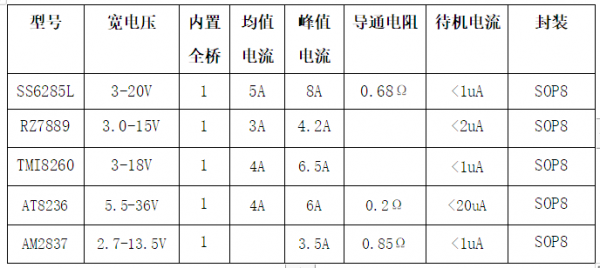
18V/5A桥式驱动芯片-SS6285L兼容替代RZ7889
SS6285L是一款由工采网代理的率能DC双向马达驱动电路芯片;该芯片采用SOP8封装,符合ROHS规范,引脚框架100%无铅;它适用于玩具等类的电机驱动、自动阀门电机驱动、电磁门锁驱动等应用。 (1)产品描述ÿ…...

C++ Primer 笔记(总结,摘要,概括)——第3章 字符串、向量和数组
目录 3.1 命名空间的using声明 3.2 标准库类型string 3.2.1 定义和初始化string对象 3.2.2 string对象上的操作 3.2.3 处理string对象中的字符 3.3 标准库类型vector 3.3.1 定义和初始化vector对象 3.3.2 向vector对象中添加元素 3.3.3 其他vector操作 3.4 迭代器介绍 3.4.…...
Sora:OpenAI引领AI视频新时代
Sora - 探索AI视频模型的无限可能 随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着AI视频领域的创新发展。让我们将一起探讨…...

[FPGA开发工具使用总结]VIVADO在线调试(1)-信号抓取工具的使用
目录 1简介2 添加观测信号的几种方法2.1 通过定制IP核添加2.2 通过约束文件添加2.3 通过GUI生成DEBUG约束文件2.4 两种方法的优点与缺点 3在线调试方法3.1 器件扫描设置3.2 触发条件设置3.3 触发窗口设置3.4 采样过程控制 4常见问题4.1 时钟域的选择4.2 缺少LTX文件4.3 ILA无时…...

Linux ip route命令
理解ip route命令 ip route是Linux系统中的一个非常常用的命令,它用于配置和管理Linux的路由表。通过ip route命令,管理员可以查看、添加、删除或修改Linux系统的路由表,从而决定数据包如何在网络中传输。例如,当一台Linux机器需要…...

WordPress有没有必要选择付费主题
有必要。 能用付费的,就尽量别用免费的。 付费主题,情况也比较复杂,先讲一下付费主题的几种情况 1、是原创付费主题。是主题制作者原创的主题。 2、是把别人的主题二次开发的付费主题。这个有些是有原始开发者授权的,有些就是…...

软考-中级-系统集成2023年综合知识(一)
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 软考中级专栏回顾 专栏…...
Flutter NestedScrollView 内嵌视图滚动行为一致
Flutter NestedScrollView 内嵌视图滚动行为一致 视频 https://youtu.be/_h7CkzXY3aM https://www.bilibili.com/video/BV1Gh4y1571p/ 前言 上一节讲了 CustomScrollView ,可以发现有的地方滚动并不是很连贯。 这时候就需要 NestedScrollView 来处理了。 今天会写…...

展示用HTML编写的个人简历信息
展示用HTML编写的个人简历信息 相关代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document…...
PostgreSQL 实体化视图的使用
上周的教程中,通过 DVD Rental Database 示例,让我们了解了在 PostgreSQL 中创建实体化视图的过程。正如我们所了解的,PostgreSQL 实体化视图提供了一种强大的机制,通过预计算和存储查询结果集为物理表来提高查询性能。接下来的内…...

【MySQL】数据库索引详解 | 聚簇索引 | 最左匹配原则 | 索引的优缺点
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c系列专栏:C/C零基础到精通 🔥 给大…...

HarmonyOS 自定义进度条 Stage模型
通过onTouch监听滑动,动态改变圆角 let radius 0Entry Component struct TestPage {State flip: boolean falseState progress:number 20build() {Row() {Column() {RelativeContainer(){Rect({ width: 100%, height: 40 }).radius(10).fill("#505050"…...
Flink双流(join)
一、介绍 Join大体分类只有两种:Window Join和Interval Join Window Join有可以根据Window的类型细分出3种:Tumbling(滚动) Window Join、Sliding(滑动) Window Join、Session(会话) Widnow Join。 🌸Window 类型的join都是利用window的机制…...

使用Nginx或者Fiddler快速代理调试
1 背景问题 在分析业务系统程序问题时,存在服务系统环境是其它部门或者其它小组搭建或运维的,并且现在微服务时代,服务多且复杂,在个人机器上搭建起如此环境,要么费事费力,要么不具备充足条件。 急需有一种方法或者工具可以快速辅助调试定位分析问题。本文下面介绍代理方…...
-全文检索的实现与优化)
MySQL高级特性篇(3)-全文检索的实现与优化
MySQL数据库全文检索是指对数据库中的文本字段进行高效地搜索和匹配。在MySQL数据库中,可以使用全文检索来实现快速的文本搜索功能,并且可以通过一些优化手段提高全文检索的性能。 一、MySQL全文检索的基本概念 全文检索是一种将关键字搜索与自然语言处…...

MySQL加锁策略详解
我们主要从三个方面来讨论这个问题: 啥时候加?如何加?什么时候该加什么时候不该加? 1、啥时候加 1.1 显式锁 MySQL 的加锁可以分为显式加锁和隐式加锁,显式加锁我们比较好识别的,因为他往往直接体现在 S…...

Taotoken助力边缘计算场景下的智能应用开发与模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力边缘计算场景下的智能应用开发与模型调用 在工业控制、物联网网关或移动机器人等边缘计算场景中,开发者常…...

Qt新手也能搞定的GPU加速图片渲染:用QOpenGLWidget和QImage实现高性能显示
Qt新手也能搞定的GPU加速图片渲染:用QOpenGLWidget和QImage实现高性能显示 在Qt应用开发中,处理高分辨率图片或序列帧(如医学影像、地图切片)时,传统的QLabel显示方式常会遇到性能瓶颈。当图片尺寸超过1080P或需要快速…...

Perplexity症状查询功能突然失效?排查清单来了:从OpenID Connect令牌过期、UMLS MetaMap服务中断到本地缓存污染的6层故障树分析
更多请点击: https://codechina.net 第一章:Perplexity症状查询功能突然失效?排查清单来了:从OpenID Connect令牌过期、UMLS MetaMap服务中断到本地缓存污染的6层故障树分析 当Perplexity的症状查询接口返回 401 Unauthorized 或…...

观察使用Token Plan套餐前后月度AI调用成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Token Plan套餐前后月度AI调用成本的变化趋势 对于频繁调用大模型API的开发者或团队而言,成本的可预测性与可控…...

压接 vs 焊接:高速连接器组装工艺的选型指南与实战对比
摘要/前言在通信设备、工业控制及数据中心硬件设计中,连接器的组装工艺选择直接影响产品的可靠性、可维护性与生产良率。压接(Press-Fit)与焊接(Soldering)是当前通孔连接器最主要的两种电气互连方式。压接依靠过盈配合…...
:使用指南)
One API 部署教程(下):使用指南
导读:前面两篇讲了本地和线上部署,现在 One API 已经跑起来了,接下来就是真正的使用环节! 理解核心概念 在开始之前,咱们先搞清楚几个关键概念,不然后面容易晕。 渠道(Channel):就是你的各个 AI 平台的 API Key。比如你有 DeepSeek 的 Key、OpenAI 的 Key、通义千问…...

3个高效方法解决抖音素材管理难题:从零散文件到有序素材库
3个高效方法解决抖音素材管理难题:从零散文件到有序素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

从OpenMV2到4代,我踩过的那些坑:画面变绿、传感器接触不良与内存擦除的避坑实录
从OpenMV2到4代:硬件升级中的稳定性挑战与实战解决方案 作为一名长期使用OpenMV系列开发视觉项目的工程师,我从OpenMV2一路升级到4代,见证了硬件性能的飞跃,也深刻体会到稳定性问题带来的困扰。其中最令人头疼的莫过于"画面变…...
)
零基础想学挖漏洞?普通人也能看懂的网络安全入门学习路线(建议收藏)
很多人对网络安全的第一印象:黑客、代码、入侵、黑框代码疯狂滚动、随手就能让ATM吐钱,随手一个漏洞几千上万,日进斗金!!! 但真实情况是:90%零基础新人不会挖漏洞,不是天赋不够&…...

实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s
实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s 当Meta开源Llama3大模型的消息席卷AI社区时,一个更实际的问题浮出水面:如何让这个性能怪兽在边缘设备上真正跑起来?我们拿到搭载算丰SG2300x芯片的Radx…...