Encoder-decoder 与Decoder-only 模型之间的使用区别
承接上文:Transformer Encoder-Decoer 结构回顾
笔者以huggingface T5 transformer 对encoder-decoder 模型进行了简单的回顾。
由于笔者最近使用decoder-only模型时发现,其使用细节和encoder-decoder有着非常大的区别;而huggingface的接口为了实现统一化,很多接口的使用操作都是以encoder-decoder的用例为主(如T5),导致在使用hugging face运行decoder-only模型时(如GPT,LLaMA),会遇到很多反直觉的问题。
本篇进一步涉及decoder-only的模型,从技术细节上,简单列举一些和encoder-decoder模型使用上的区别。
以下讨论均以huggingface transformer接口为例。
1. 训练时input与output合并
对于encoder-decoder模型,我们需要把input和output 分别 喂给模型的encoder和decoder。也就是说,像T5这种模型,会有一个单独的encoder编码input的上下文信息,由decoder解码output和计算loss。简而言之,如果是encoder-decoder模型,我们 只把 output喂给decoder(用于计算loss,teacher forcing),这对于我们大多是人来说是符合直觉的。
但decoder-onyl模型,需要你手动地将input和output合并在一起,作为decoder的输入。因为,从逻辑上讲,对于decoder-only模型而言,它们并没有额外的encoder去编码input的上下文,所以需要把input作为“前文”,让decoder基于这一段“前文”,把“后文”的output预测出来(auto regressive)。因此,在训练时,input和output是合并在一起喂给decoder-only 模型的(input这段前文必须要有)。这对于大多数习惯了使用encoder-decoder的人来说,是很违反直觉的。
于此相对应的,decoder-only 模型计算loss时的“答案”(ground truth reference)也得是input和output的合并(因为计算loss的时候,输入token representation得和输出ground truth reference要对应)。而这样一来,decoder 的loss就既包含output,又会涉及input上的预测error。由于我们大多数情况下不希望去惩罚decoder模型在input上的error,一般的做法是,训练时我们只计算output上的loss ,即,把input token对应的ground truth全部设置为-100(cross entropy ignore idx)。
2. 测试时,手动提取output
encoder-decoder模型的输出就是很“纯粹”的output(模型的预测结果)
但decoder-only模型,在做inference的时候,模型的输出就会既包含output也包含input(因为input也喂给了decoder)
所以这种情况下,decoder-only 模型我们需要手动地把output给分离出来。
如下所示:
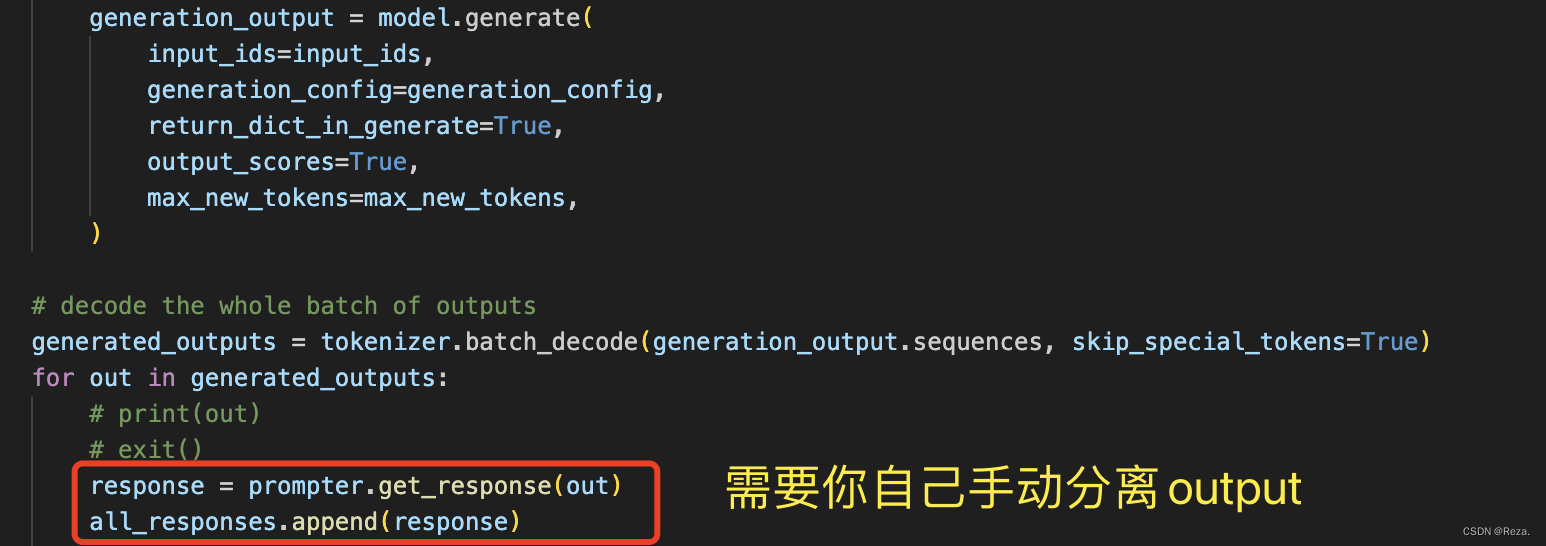
笔者也很无语,huggingface的 model.generate() 接口为什么不考虑一下,对于decoder-only模型,设置一个额外参数,能够自动提取output(用input token的数量就可以自动定位output,不难实现的)
3. batched inference的速度和准确度
如果想要批量地进行预测,简单的做法就是把一个batch的样本,进行tokenization之后,在序列末尾(右边)pad token,补足长度差异。这对于encoder-decoder 模型来说是适用的。
但是对于decoder-only模型,你需要在训练时,额外地将tokenizer的pad 位置设置为左边:

因为你一旦设置为默认的右边,模型在做inference时,一个batch的样本,所有pad token就都在序列末尾。而decoder only模型是auto regressive地生成新token的,最右边的pad token就很容易影响到模型生成的内容。
有人就会问,这个时候和encoder-decoder模型一样,用attention mask把那些pad tokens都遮掉,不就不会影响模型生成的内容了吗?
但是很遗憾,对于decoder-only模型,huggingface model.generate 接口并不支持输入attention mask(如下面官方api所描述):

所以你如果想batched inference,不得不在训练和测试的时候,把tokenizer的pad设置在左手边,以降低pad token对生成内容的影响;或者干脆设置batch size为1 。
经过笔者自己的实验,推理时
batch size==1能够显著提升推理准确度
以下为笔者测试的性能表现排序:
- batch size 为1 (完全没有pad token的影响),性能最好
- batch size不为1,pad token在左侧(pad token影响降低,但还是会损伤推理性能),在部分任务上,性能降低较为明显
- batch size不为1,pad token在右侧(pad token对大量的样本的预测产生极大干扰,模型最后的输出基本都是乱码),性能接近于0
总之,当前huggingface的生成接口对于decoder-only模型的支持度并不是非常高,decoder-only模型推理的速度和精度,以及接口使用的便捷程度,都会逊于encoder-decoder模型。
下面是GPT-4对于为何decoder-only模型做推理时不需要attention mask(最后一句话是亮点。。。):
The instruction from the Hugging Face Transformers documentation regarding the use of
input_idsfor decoder-only models during generation (like GPT-2, GPT-3) stems from the typical use case and architecture of these models.
Whyinput_ids?
Decoder-only models like GPT-2 or GPT-3 are designed to generate text sequentially. When generating text, the model uses its previously generated tokens as context to generate the next token. Since these models are autoregressive, they generate one token at a time, and the sequence of generated tokens grows until it reaches a stopping condition (like themax_lengthoreos_token_id). During this process, the only necessity is to know which tokens have been generated (encoded asinput_ids), so the model knows the context based on which it should generate the subsequent token(s).
Aboutattention_mask
While it’s true that attention masks are used to prevent the model from attending to certain positions within the input sequence (for example, padding tokens in a batched input scenario), during the generation phase, the need to specify anattention_maskexplicitly is not as critical as during training or evaluation. This is because, during generation, the model is focusing on the tokens it has already generated and the positions it needs to fill next – all of which are relevant and none should be masked out.
That said, for certain generation scenarios or model configurations, you might want to control the attention mechanism explicitly. The Hugging Face Transformers library does allow for passing additional arguments likeattention_maskin some contexts, but for the default use case of generating text with decoder-only models, including theattention_maskis not necessary.
Batched Inference
For batched inference,input_idsare necessary to understand the sequence (or sequences) from which to start generating text. If the sequences within a batch have different lengths, padding might be necessary to shape the input tensor appropriately. In such cases, anattention_maskbecomes relevant because it allows the model to distinguish between the actual content and the padding. Therefore, while the generation call as you’ve shown doesn’t explicitly mentionattention_mask, depending on the specifics of your use case and the model’s implementation, you might still need or want to provide it to ensure proper handling of batched inputs.
其他待补充
。。。
总结
总而言之,个人认为 huggingface目前的模型接口,对于decoder-only模型的使用并不是很友好。在使用过程中需要注意很多细节,不然会遇到许多问题,而这些问题,encoder-decoder模型是完全不会有的。
参考:
- 官方接口
- alpaca-lora
相关文章:
Encoder-decoder 与Decoder-only 模型之间的使用区别
承接上文:Transformer Encoder-Decoer 结构回顾 笔者以huggingface T5 transformer 对encoder-decoder 模型进行了简单的回顾。 由于笔者最近使用decoder-only模型时发现,其使用细节和encoder-decoder有着非常大的区别;而huggingface的接口为…...
【STM32备忘录】【STM32WB系列的BLE低功耗蓝牙】一、测试广播配置搜不到信号的注意事项
一、预备知识: WB系列是双核单片机,用户写M4,无线协议栈使用M0新买到手的单片机,需要自己刷入使用的无线协议栈刷入无线协议栈的途径是通过一个叫FUS的东东,类似于bootloader,这个FUS新买的芯片通常已经刷…...

ChatGPT 是什么
文章目录 一、ChatGPT 是什么二、ChatGPT的发明者三、ChatGPT的运作方式四、ChatGPT的技术五、ChatGPT的优势六、ChatGPT的局限性七、ChatGPT的应用八、ChatGPT的未来九、总结 一、ChatGPT 是什么 OpenAI的ChatGPT,即Chat Generative Pre-Trained Transformer&…...
4款好用的ai智能写作软件,为写作排忧解难!
在当今信息爆炸的时代,写作已经成为人们生活和工作中不可或缺的一部分。然而,对于许多人来说,写作可能是一项具有挑战性的任务,需要花费大量的时间和精力。幸运的是,随着人工智能技术的不断发展,ai智能写作…...
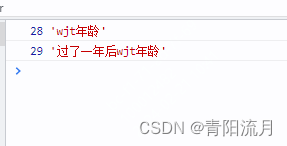
js设计模式:计算属性模式
作用: 将对象中的某些值与其他值进行关联,根据其他值来计算该值的结果 vue中的计算属性就是很经典的例子 示例: let nowDate 2023const wjtInfo {brithDate:1995,get age(){return nowDate-this.brithDate}}console.log(wjtInfo.age,wjt年龄)nowDate 1console.log(wjtInf…...

2015-2024年考研数学(一)真题练习和解析——选择题
各个大学已经陆陆续续开学了,备考2025年考研的同学也要紧锣密鼓地开始备考,尤其是三门公共课——政治、英语、数学,备考的时间和周期都比较长,每一门都是难啃的硬骨头。 在这三门公共课中,数学的灵活性是最大的&#x…...
Git合并固定分支的某一部分至当前分支
在 Git 中,通常使用 git merge 命令来将一个分支的更改合并到另一个分支。如果你只想合并某个分支的一部分代码,可以使用以下两种方法: 1.批量文件合并 1.1.创建并切换到一个新的临时分支 首先,从要合并的源分支(即要…...
 (A-E))
Codeforces Round 928 (Div. 4) (A-E)
比赛地址 : https://codeforces.com/contest/1926 A 遍历每一个字符串,比较1和0的数量即可,那个大输出那个; #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define endl \n #define lowbit(x) (x&am…...

git远程操控gitee
配置SSH公钥 首先,在本地计算机上生成SSH公钥。打开终端或命令提示符窗口,并执行以下命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com"按照提示操作,生成SSH密钥对。默认情况下,公钥将保存在~…...
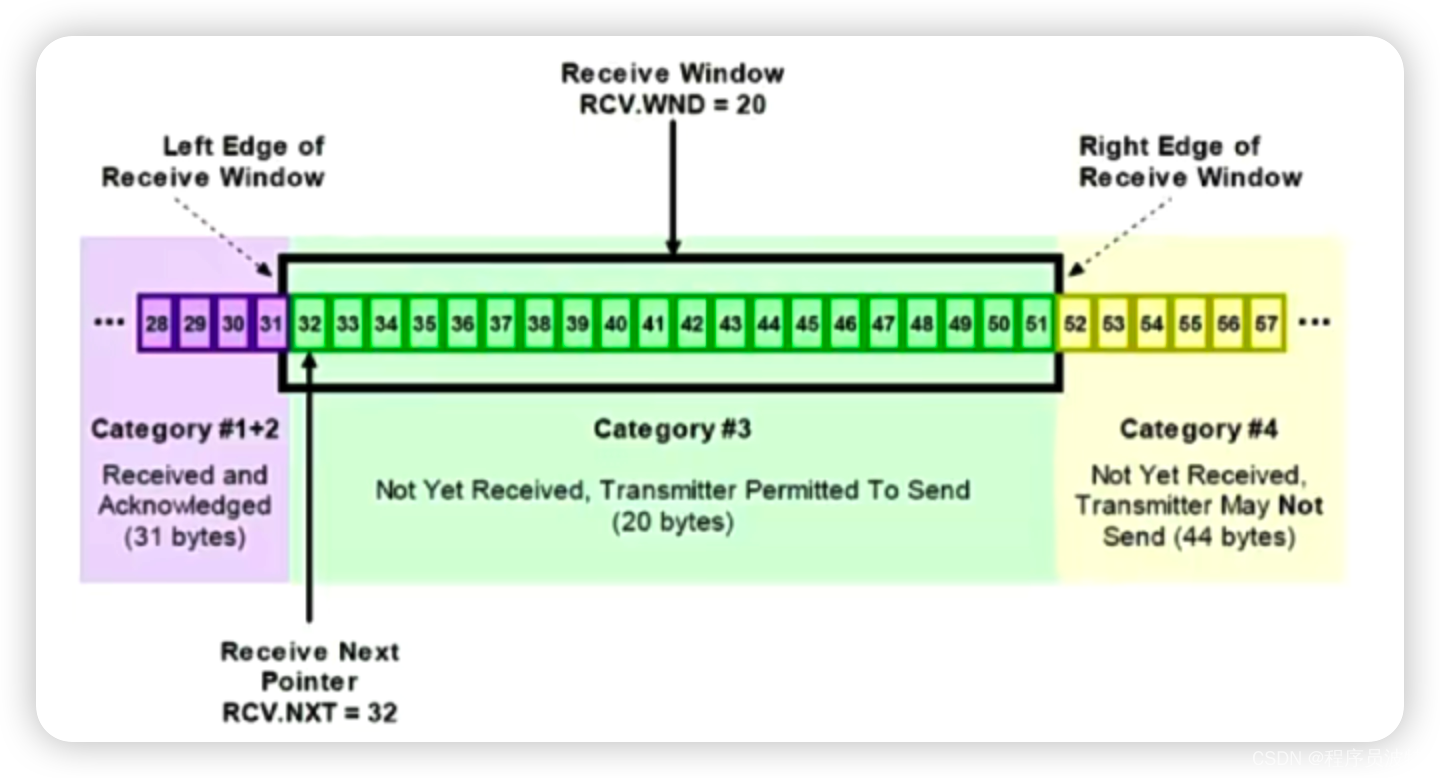
常见面试题:TCP的四次挥手和TCP的滑动窗口
说一说 TCP 的四次挥手。 挥手即终止 TCP 连接,所谓的四次挥手就是指断开一个 TCP 连接时。需要客户端和服务端总共发出四个包,已确认连接的断开在 socket 编程中,这一过程由客户端或服务端任意一方执行 close 来触发。这里我们假设由客户端…...

力扣随笔之两数之和 Ⅱ -输入有序数组(中等167)
思路:在递增数组中找出满足相加之和等于目标数 定义左右两个指针(下标)从数组两边开始遍历,若左右指针所指数字之和大于目标数,则将右指针自减,若左右指针所指数字之和小于目标数,则左指针自加&…...
最优传输(Optimal Transport)
最优传输(Optimal Transport)是一种数学理论和计算方法,用于描述两个概率分布之间的距离或者对应关系。它的核心概念是如何以最佳方式将一组资源(如质量、能量等)从一个位置传输到另一个位置。 基本概念: …...
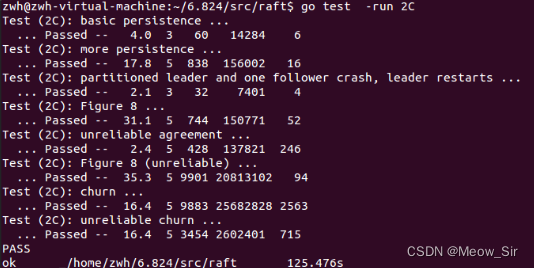
MIT-6.824-Lab2,Raft部分笔记|Use Go
文章目录 前记Paper6:RaftLEC5、6:RaftLAB22AtaskHintlockingstructureguide设计与编码 2BtaskHint设计与编码 2CtaskHint question后记 LEC5:GO, Threads, and Raftgo threads技巧raft实验易错点debug技巧 前记 趁着研一考完期末有点点空余…...
使用openeuler 22.03替代CentOS 7.9,建立虚拟机详细步骤
进入浏览器搜索网址下载openeuler 22.03镜像文件 https://mirrors.huaweicloud.com/openeuler/openEuler-22.03-LTS-SP3/ISO/x86_64/openEuler-22.03-LTS-SP3-x86_64-dvd.iso 打开VMware Workstation新建一个虚拟机: 自定义虚拟机位置 加入下载好的openeuler镜像文件…...

代理技术引领出海征程
在数字娱乐的繁荣时代,游戏开发者和发行商们意识到,要在全球市场立足,必须迈向国际化的出海之路。然而,这一旅程面临着跨越网络壁垒、适应多元文化和提升全球连接性的巨大挑战。本文将深入探讨代理技术在游戏行业出海过程中的创新…...
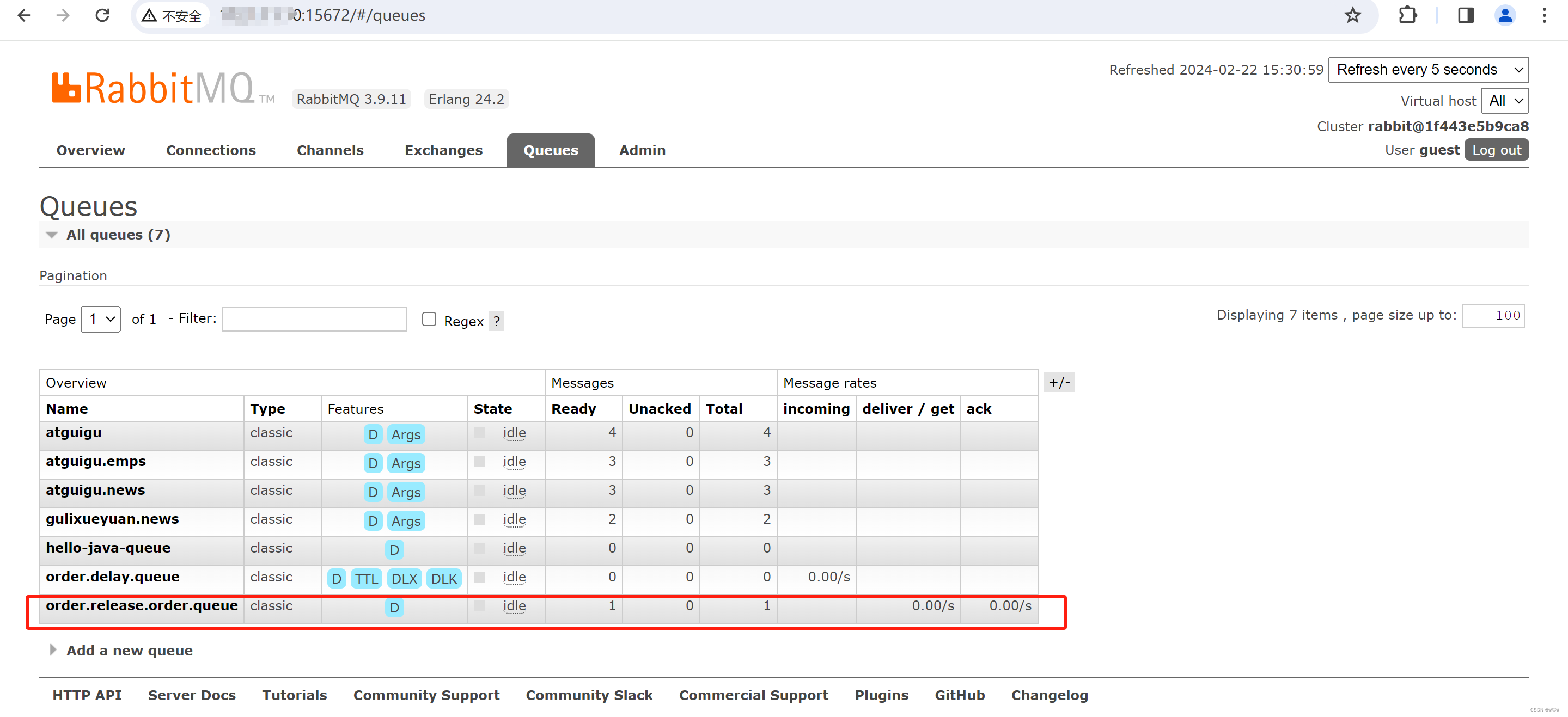
谷粒商城篇章9 ---- P248-P261/P292-P294 ---- 消息队列【分布式高级篇六】
目录 1 消息队列(Message Queue)简介 1.1 概述 1.2 消息服务中两个重要概念 1.3 消息队列主要有两种形式的目的地 1.4 JMS和AMQP对比 1.5 应用场景 1.6 Spring支持 1.7 SpringBoot自动配置 1.7 市面上的MQ产品 2 RabbitMQ 2.1 RabbitMQ简介 2.1.1 RabbitMQ简介 2…...
----生命周期事件)
【Spring连载】使用Spring Data访问 MongoDB(五)----生命周期事件
【Spring连载】使用Spring Data访问 MongoDB(五)----生命周期事件Lifecycle Events 一、实体回调Entity Callbacks1.1 实现实体回调1.2 注册实体回调 二、特定存储的实体回调 一、实体回调Entity Callbacks 1.1 实现实体回调 1.2 注册实体回调 二、特…...

JavaSec 之 SQL 注入简单了解
文章目录 JDBC 注入语句拼接(Statement)修复方案 语句拼接(PrepareStatement)修复方案 预编译 JdbcTemplate修复方案 MyBatisLike 注入Order By 注入In 注入 寒假学了一个月 pwn,真心感觉这玩意太底层学的我生理不适应了,接下来学一段时间 java 安全缓一…...

第十一章——期约与异步函数
ECMAScript 6及之后的几个版本逐步加大了对异步编程机制的支持,提供了令人眼前一亮的新特性。ECMAScript 6新增了正式的Promise(期约)引用类型,支持优雅地定义和组织异步逻辑。接下来几个版本增加了使用async和await关键字定义异步…...

工具方法合集-utils.js
通用 import get from lodash.get import cloneDeep from lodash.clonedeep // 深度clone export function deepClone(obj) {return obj ? cloneDeep(obj) : obj } export function lodashGet(obj, key, defaultValue = ) {//这个 defaultValue 不能给默认 值 会报错;retur…...

LRC Maker终极指南:零基础打造完美同步歌词的免费工具
LRC Maker终极指南:零基础打造完美同步歌词的免费工具 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为喜欢的歌曲找不到准确歌词而烦恼吗…...

发掘Python之魂:探索数据结构与算法的宝典
发掘Python之魂:探索数据结构与算法的宝典 【下载地址】Python数据结构与算法教程及代码 本资源文件《Python数据结构与算法教程及代码》是一份精心整理的教程,旨在帮助学习者深入理解Python中的数据结构与算法。算法(Algorithm)是…...

语义搜索失效?NotebookLM这4类文档结构陷阱正悄悄拖垮你的研究效率,立即排查!
更多请点击: https://intelliparadigm.com 第一章:语义搜索失效?NotebookLM这4类文档结构陷阱正悄悄拖垮你的研究效率,立即排查! NotebookLM 的语义搜索能力依赖于底层文档的语义连贯性与结构清晰度。当文档存在隐性结…...

【linux学习】linux的一些奇怪知识,方便日常使用
我是程序员小青蛙,下面介绍关于linux的知识。前言一些基本知识,方便利用,比如热键[tab],[ctrl]-c,[ctrl]-d,粘滞位,权限等;xshell中的复制粘贴,Ctrlinsert,复制shiftinsert->粘贴一、重要的几…...

猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载
猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想保存网页上…...

遗传算法调参避坑指南:交叉率、变异率怎么设?种群大小多少合适?
遗传算法参数调优实战手册:从理论到工程落地的关键策略 当你在深夜盯着屏幕上迟迟不收敛的遗传算法结果时,是否曾怀疑过那些默认参数值是否真的适合你的问题?遗传算法作为经典的优化工具,其参数设置往往决定了算法是高效找到全局最…...

别再手动改参数了!用Fluent 2023R1的Parametric模块,5分钟搞定N个工况的批量仿真
Fluent 2023R1参数化模块实战:从单点仿真到智能设计空间探索 在计算流体动力学(CFD)领域,工程师们常常需要面对一个现实困境:如何高效完成数十种工况的参数扫描?传统手动修改边界条件的方式不仅耗时费力&am…...

QT无边框窗口实战:从圆角绘制到自定义标题栏与拖拽交互
1. 为什么需要无边框窗口? 现代桌面应用越来越注重视觉体验,传统的系统标题栏往往与整体设计风格格格不入。想象一下,你精心设计了一款深色主题的音乐播放器,顶部却突兀地挂着Windows默认的白色标题栏——这种割裂感正是无边框窗口…...

Analog Discovery 2:口袋实验室如何用FPGA重塑硬件调试体验
1. 口袋里的实验室:为什么我们需要Analog Discovery 2?作为一名在硬件开发一线摸爬滚打了十多年的工程师,我太熟悉那种面对复杂项目时,被实验室设备“卡脖子”的窘迫感了。你想验证一个想法,或者排查一个棘手的信号问题…...

2025届学术党必备的六大降AI率助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 身处人工智能生成内容也就是AIGC越来越普遍的大背景当中,怎样去有效地降低它被检…...