onnx 1.16 doc学习笔记四:python API-If和Scan
onnx作为一个通用格式,很少有中文教程,因此开一篇文章对onnx 1.16文档进行翻译与进一步解释,
onnx 1.16官方文档:https://onnx.ai/onnx/intro/index.html](https://onnx.ai/onnx/intro/index.html),
如果觉得有收获,麻烦点赞收藏关注,目前仅在CSDN发布,本博客会分为多个章节,目前尚在连载中,详见专栏链接:
https://blog.csdn.net/qq_33345365/category_12581965.html
开始编辑时间:2024/2/21;最后编辑时间:2024/2/21
这是本教程的第四篇,其余内容见上述专栏链接。
ONNX with Python
本教程的第一篇:介绍了ONNX的基本概念。
在本教程的第二篇,介绍了ONNX关于Python的API,具体涉及一个简单的线性回归例子和序列化。
本教程的第三篇,包括python API的三个部分:初始化器Initializer;属性Attributes;算子集和元数据Opset和Metadata
在本篇将继续对更多的内容进行介绍。具体介绍子图相关内容。
目录:
- 子图:测试与循环
- If
- Scan
子图:测试与循环 Subgraph: test and loops
通常情况下,这些操作会被归类为控制流。一般来说,最好避免使用它们,因为它们不像矩阵操作那样高效,而且矩阵操作经过高度优化,速度更快。
If
可以使用 if 语句来实现一个test。它根据一个布尔值执行子图 A 或子图 B。这种用法不是很常见,因为一个函数通常需要批处理比较的结果。下面的示例代码:根据符号计算矩阵中所有浮点数的和,并返回 1 或 -1。
import numpy
import onnx
from onnx.helper import (make_node, make_graph, make_model, make_tensor_value_info)
from onnx.numpy_helper import from_array
from onnx.checker import check_model
from onnxruntime import InferenceSession# initializers
value = numpy.array([0], dtype=numpy.float32)
zero = from_array(value, name='zero')# Same as before, X is the input, Y is the output.
X = make_tensor_value_info('X', onnx.TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', onnx.TensorProto.FLOAT, [None])# 第一个节点:对所有轴求和。
rsum = make_node('ReduceSum', ['X'], ['rsum'])
# 第二个节点:将rsum与0比较,输出为cond
cond = make_node('Greater', ['rsum', 'zero'], ['cond'])# 构建if正确时的图
# Input for then
then_out = make_tensor_value_info('then_out', onnx.TensorProto.FLOAT, None)
# 正确返回常数1
then_cst = from_array(numpy.array([1]).astype(numpy.float32))# If正确时的节点,并得到图
then_const_node = make_node('Constant', inputs=[],outputs=['then_out'],value=then_cst, name='cst1')then_body = make_graph([then_const_node], 'then_body', [], [then_out])# 构建If错误时的图
else_out = make_tensor_value_info('else_out', onnx.TensorProto.FLOAT, [5])
else_cst = from_array(numpy.array([-1]).astype(numpy.float32))else_const_node = make_node('Constant', inputs=[],outputs=['else_out'],value=else_cst, name='cst2')else_body = make_graph([else_const_node], 'else_body',[], [else_out])# 最后If节点把两个图当成属性
if_node = onnx.helper.make_node('If', ['cond'], ['Y'],then_branch=then_body, else_branch=else_body)# 最后的图,使用If节点和前两个节点。
graph = make_graph([rsum, cond, if_node], 'if', [X], [Y], [zero])
onnx_model = make_model(graph)
check_model(onnx_model)# 指定算子集
del onnx_model.opset_import[:]
opset = onnx_model.opset_import.add()
opset.domain = ''
opset.version = 15
onnx_model.ir_version = 8# 保存模型
with open("onnx_if_sign.onnx", "wb") as f:f.write(onnx_model.SerializeToString())# 输出
sess = InferenceSession(onnx_model.SerializeToString(),providers=["CPUExecutionProvider"])x = numpy.ones((3, 2), dtype=numpy.float32)
res = sess.run(None, {'X': x})print("result", res)
print()print(onnx_model)
这个代码的核心是构建if使用的两个图,然后用着两个图构建节点,参照输出进行进一步的了解:
result [array([1.], dtype=float32)]ir_version: 8
graph {node {input: "X"output: "rsum"op_type: "ReduceSum"}node {input: "rsum"input: "zero"output: "cond"op_type: "Greater"}node {input: "cond"output: "Y"op_type: "If"attribute {name: "else_branch"g {node {output: "else_out"name: "cst2"op_type: "Constant"attribute {name: "value"t {dims: 1data_type: 1raw_data: "\000\000\200\277"}type: TENSOR}}name: "else_body"output {name: "else_out"type {tensor_type {elem_type: 1shape {dim {dim_value: 5}}}}}}type: GRAPH}attribute {name: "then_branch"g {node {output: "then_out"name: "cst1"op_type: "Constant"attribute {name: "value"t {dims: 1data_type: 1raw_data: "\000\000\200?"}type: TENSOR}}name: "then_body"output {name: "then_out"type {tensor_type {elem_type: 1}}}}type: GRAPH}}name: "if"initializer {dims: 1data_type: 1name: "zero"raw_data: "\000\000\000\000"}input {name: "X"type {tensor_type {elem_type: 1shape {dim {}dim {}}}}}output {name: "Y"type {tensor_type {elem_type: 1shape {dim {}}}}}
}
opset_import {domain: ""version: 15
}
在这个代码里,“else”和“then”分支都非常简单,甚至可以用一个“Where”节点替换“If”节点,这样会更快。有趣的是,当两个分支都比较大,并且跳过一个分支效率更高时,情况就变得复杂了。
Scan
根据规格描述,Scan操作似乎有些复杂:将张量的一个维度循环遍历并将其结果存储在预分配张量中,这是一种很有用的方法。以下示例实现了经典的回归问题最近邻算法。第一步是计算输入特征 X 和训练集 W 之间的成对距离:KaTeX parse error: Undefined control sequence: \norm at position 21: …X,W)=(M_{ij})=(\̲n̲o̲r̲m̲ ̲X_i-W^2_j)_{ij} . 然后使用一个 TopK 算子提取 k 个最近邻点。
注:在原教程里,此处的公式就是这样的,不保真
ONNX
scan算子可以用于迭代执行一系列操作,类似于 Python 中的for循环。这个算子有些复杂,我会在更多学习后,给出更为简单的例子。
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import (make_model, make_node, set_model_props, make_tensor, make_graph,make_tensor_value_info)
from onnx.checker import check_model# subgraph
initializers = []
nodes = []
inputs = []
outputs = []value = make_tensor_value_info('next_in', 1, [None, 4])
inputs.append(value)
value = make_tensor_value_info('next', 1, [None])
inputs.append(value)value = make_tensor_value_info('next_out', 1, [None, None])
outputs.append(value)
value = make_tensor_value_info('scan_out', 1, [None])
outputs.append(value)node = make_node('Identity', ['next_in'], ['next_out'],name='cdistd_17_Identity', domain='')
nodes.append(node)node = make_node('Sub', ['next_in', 'next'], ['cdistdf_17_C0'],name='cdistdf_17_Sub', domain='')
nodes.append(node)node = make_node('ReduceSumSquare', ['cdistdf_17_C0'], ['cdistdf_17_reduced0'],name='cdistdf_17_ReduceSumSquare', axes=[1], keepdims=0, domain='')
nodes.append(node)node = make_node('Identity', ['cdistdf_17_reduced0'],['scan_out'], name='cdistdf_17_Identity', domain='')
nodes.append(node)graph = make_graph(nodes, 'OnnxIdentity',inputs, outputs, initializers)# main graphinitializers = []
nodes = []
inputs = []
outputs = []opsets = {'': 15, 'ai.onnx.ml': 15}
target_opset = 15 # subgraphs# initializers
list_value = [23.29599822460675, -120.86516699239603, -144.70495899914215, -260.08772982740413,154.65272105889147, -122.23295157108991, 247.45232560871727, -182.83789715805776,-132.92727431421793, 147.48710175784703, 88.27761768038069, -14.87785569894749,111.71487894705504, 301.0518319089629, -29.64235742280055, -113.78493504731911,-204.41218591022718, 112.26561056133608, 66.04032954135549,-229.5428380626701, -33.549262642481615, -140.95737409864623, -87.8145187836131,-90.61397011283958, 57.185488100413366, 56.864151796743855, 77.09054590340892,-187.72501631246712, -42.779503579806025, -21.642642730674076, -44.58517761667535,78.56025104939847, -23.92423223842056, 234.9166231927213, -73.73512816431007,-10.150864499514297, -70.37105466673813, 65.5755688281476, 108.68676290979731, -78.36748960443065]
value = numpy.array(list_value, dtype=numpy.float64).reshape((2, 20))
tensor = numpy_helper.from_array(value, name='knny_ArrayFeatureExtractorcst')
initializers.append(tensor)list_value = [1.1394007205963135, -0.6848101019859314, -1.234825849533081, 0.4023416340351105,0.17742614448070526, 0.46278226375579834, -0.4017809331417084, -1.630198359489441,-0.5096521973609924, 0.7774903774261475, -0.4380742907524109, -1.2527953386306763,-1.0485529899597168, 1.950775384902954, -1.420017957687378, -1.7062702178955078,1.8675580024719238, -0.15135720372200012, -0.9772778749465942, 0.9500884413719177,-2.5529897212982178, -0.7421650290489197, 0.653618574142456, 0.8644362092018127,1.5327792167663574, 0.37816253304481506, 1.4693588018417358, 0.154947429895401,-0.6724604368209839, -1.7262825965881348, -0.35955315828323364, -0.8131462931632996,-0.8707971572875977, 0.056165341287851334, -0.5788496732711792, -0.3115525245666504,1.2302906513214111, -0.302302747964859, 1.202379822731018, -0.38732680678367615,2.269754648208618, -0.18718385696411133, -1.4543657302856445, 0.04575851559638977,-0.9072983860969543, 0.12898291647434235, 0.05194539576768875, 0.7290905714035034,1.4940791130065918, -0.8540957570075989, -0.2051582634449005, 0.3130677044391632,1.764052391052246, 2.2408931255340576, 0.40015721321105957, 0.978738009929657,0.06651721894741058, -0.3627411723136902, 0.30247190594673157, -0.6343221068382263,-0.5108051300048828, 0.4283318817615509, -1.18063223361969, -0.02818222902715206,-1.6138978004455566, 0.38690251111984253, -0.21274028718471527, -0.8954665660858154,0.7610377073287964, 0.3336743414402008, 0.12167501449584961, 0.44386324286460876,-0.10321885347366333, 1.4542734622955322, 0.4105985164642334, 0.14404356479644775,-0.8877857327461243, 0.15634897351264954, -1.980796456336975, -0.34791216254234314]
value = numpy.array(list_value, dtype=numpy.float32).reshape((20, 4))
tensor = numpy_helper.from_array(value, name='Sc_Scancst')
initializers.append(tensor)value = numpy.array([2], dtype=numpy.int64)
tensor = numpy_helper.from_array(value, name='To_TopKcst')
initializers.append(tensor)value = numpy.array([2, -1, 2], dtype=numpy.int64)
tensor = numpy_helper.from_array(value, name='knny_Reshapecst')
initializers.append(tensor)# inputs
value = make_tensor_value_info('input', 1, [None, 4])
inputs.append(value)# outputs
value = make_tensor_value_info('variable', 1, [None, 2])
outputs.append(value)# nodes
# 这里是scan算子
node = make_node('Scan', ['input', 'Sc_Scancst'], ['UU032UU', 'UU033UU'],name='Sc_Scan', body=graph, num_scan_inputs=1, domain='')
nodes.append(node)node = make_node('Transpose', ['UU033UU'], ['Tr_transposed0'],name='Tr_Transpose', perm=[1, 0], domain='')
nodes.append(node)node = make_node('Sqrt', ['Tr_transposed0'], ['Sq_Y0'],name='Sq_Sqrt', domain='')
nodes.append(node)node = make_node('TopK', ['Sq_Y0', 'To_TopKcst'], ['To_Values0', 'To_Indices1'],name='To_TopK', largest=0, sorted=1, domain='')
nodes.append(node)node = make_node('Flatten', ['To_Indices1'], ['knny_output0'],name='knny_Flatten', domain='')
nodes.append(node)node = make_node('ArrayFeatureExtractor',['knny_ArrayFeatureExtractorcst', 'knny_output0'], ['knny_Z0'],name='knny_ArrayFeatureExtractor', domain='ai.onnx.ml')
nodes.append(node)node = make_node('Reshape', ['knny_Z0', 'knny_Reshapecst'], ['knny_reshaped0'],name='knny_Reshape', allowzero=0, domain='')
nodes.append(node)node = make_node('Transpose', ['knny_reshaped0'], ['knny_transposed0'],name='knny_Transpose', perm=[1, 0, 2], domain='')
nodes.append(node)node = make_node('Cast', ['knny_transposed0'], ['Ca_output0'],name='Ca_Cast', to=TensorProto.FLOAT, domain='')
nodes.append(node)node = make_node('ReduceMean', ['Ca_output0'], ['variable'],name='Re_ReduceMean', axes=[2], keepdims=0, domain='')
nodes.append(node)# graph
graph = make_graph(nodes, 'KNN regressor', inputs, outputs, initializers)# model
onnx_model = make_model(graph)
onnx_model.ir_version = 8
onnx_model.producer_name = 'skl2onnx'
onnx_model.producer_version = ''
onnx_model.domain = 'ai.onnx'
onnx_model.model_version = 0
onnx_model.doc_string = ''
set_model_props(onnx_model, {})# opsets
del onnx_model.opset_import[:]
for dom, value in opsets.items():op_set = onnx_model.opset_import.add()op_set.domain = domop_set.version = valuecheck_model(onnx_model)
with open("knnr.onnx", "wb") as f:f.write(onnx_model.SerializeToString())print(onnx_model)
输出如下所示:
ir_version: 8
producer_name: "skl2onnx"
producer_version: ""
domain: "ai.onnx"
model_version: 0
doc_string: ""
graph {node {input: "input"input: "Sc_Scancst"output: "UU032UU"output: "UU033UU"name: "Sc_Scan"op_type: "Scan"attribute {name: "body"g {node {input: "next_in"output: "next_out"name: "cdistd_17_Identity"op_type: "Identity"domain: ""}node {input: "next_in"input: "next"output: "cdistdf_17_C0"name: "cdistdf_17_Sub"op_type: "Sub"domain: ""}node {input: "cdistdf_17_C0"output: "cdistdf_17_reduced0"name: "cdistdf_17_ReduceSumSquare"op_type: "ReduceSumSquare"attribute {name: "axes"ints: 1type: INTS}attribute {name: "keepdims"i: 0type: INT}domain: ""}node {input: "cdistdf_17_reduced0"output: "scan_out"name: "cdistdf_17_Identity"op_type: "Identity"domain: ""}name: "OnnxIdentity"input {name: "next_in"type {tensor_type {elem_type: 1shape {dim {}dim {dim_value: 4}}}}}input {name: "next"type {tensor_type {elem_type: 1shape {dim {}}}}}output {name: "next_out"type {tensor_type {elem_type: 1shape {dim {}dim {}}}}}output {name: "scan_out"type {tensor_type {elem_type: 1shape {dim {}}}}}}type: GRAPH}attribute {name: "num_scan_inputs"i: 1type: INT}domain: ""}node {input: "UU033UU"output: "Tr_transposed0"name: "Tr_Transpose"op_type: "Transpose"attribute {name: "perm"ints: 1ints: 0type: INTS}domain: ""}node {input: "Tr_transposed0"output: "Sq_Y0"name: "Sq_Sqrt"op_type: "Sqrt"domain: ""}node {input: "Sq_Y0"input: "To_TopKcst"output: "To_Values0"output: "To_Indices1"name: "To_TopK"op_type: "TopK"attribute {name: "largest"i: 0type: INT}attribute {name: "sorted"i: 1type: INT}domain: ""}node {input: "To_Indices1"output: "knny_output0"name: "knny_Flatten"op_type: "Flatten"domain: ""}node {input: "knny_ArrayFeatureExtractorcst"input: "knny_output0"output: "knny_Z0"name: "knny_ArrayFeatureExtractor"op_type: "ArrayFeatureExtractor"domain: "ai.onnx.ml"}node {input: "knny_Z0"input: "knny_Reshapecst"output: "knny_reshaped0"name: "knny_Reshape"op_type: "Reshape"attribute {name: "allowzero"i: 0type: INT}domain: ""}node {input: "knny_reshaped0"output: "knny_transposed0"name: "knny_Transpose"op_type: "Transpose"attribute {name: "perm"ints: 1ints: 0ints: 2type: INTS}domain: ""}node {input: "knny_transposed0"output: "Ca_output0"name: "Ca_Cast"op_type: "Cast"attribute {name: "to"i: 1type: INT}domain: ""}node {input: "Ca_output0"output: "variable"name: "Re_ReduceMean"op_type: "ReduceMean"attribute {name: "axes"ints: 2type: INTS}attribute {name: "keepdims"i: 0type: INT}domain: ""}name: "KNN regressor"initializer {dims: 2dims: 20data_type: 11name: "knny_ArrayFeatureExtractorcst"raw_data: ",\\&\212\306K7@\333z`\345^7^\300\304\312,\006\217\026b\300Z9dWgAp\300.+F\027\343Tc@\203\330\264\255\350\216^\300\260\022\216sy\356n@\237h\263\r\320\332f\300\224\277.;\254\235`\300\336\370lV\226ob@\261\201\362|\304\021V@c,[Mv\301-\300\322\214\240\223\300\355[@)\036\262M\324\320r@nE;\211q\244=\300\021n5`<r\\\300\207\211\201\2400\215i\300H\232p\303\377\020\\@\317K[\302\224\202P@&\306\355\355^\261l\300\301/\377<N\306@\300#w\001\317\242\236a\300$fd\023!\364U\300\204\327LIK\247V\300J\211\366\022\276\227L@\262\345\254\206\234nL@f{\013\201\313ES@\234\343hU3wg\300\3370\367\305\306cE\300\336A\347;\204\2445\300f\374\242\031\347JF\300\325\2557\'\333\243S@\331\354\345{\232\3547\300\307o)\372T]m@#\005\000W\014oR\300\'\025\227\034>M$\300\310\252\022\\\277\227Q\300l_\243\036\326dP@\333kk\354\363+[@\223)\036\363\204\227S\300"}initializer {dims: 20dims: 4data_type: 1name: "Sc_Scancst"raw_data: "\342\327\221?\267O/\277\306\016\236\277\271\377\315>3\2575>\314\361\354>;\266\315\276W\252\320\277\221x\002\277\234\tG?FK\340\276\231[\240\277\3746\206\277\002\263\371?&\303\265\277\020g\332\277$\014\357?b\375\032\276\342.z\277\3778s?/d#\300\207\376=\277\214S\'?\261K]?\0342\304?\205\236\301>\363\023\274?\212\252\036>^&,\277\324\366\334\277Z\027\270\276[*P\277\220\354^\277\241\rf=~/\024\277\320\203\237\276*z\235?m\307\232\276\225\347\231?\263O\306\276\251C\021@ \255?\276\250(\272\277Hm;=\265Dh\277\031\024\004>\262\304T=\256\245:?\374=\277?\005\246Z\277\002\025R\276iJ\240>x\314\341?\313j\017@h\341\314>\223\216z?.:\210=6\271\271\276\231\335\232>\357b\"\277 \304\002\277QN\333>\365\036\227\277k\336\346\2744\224\316\277\026\030\306>\227\330Y\276L=e\277^\323B?]\327\252>\3000\371=\013B\343>hd\323\275\242%\272?\3709\322>(\200\023>\355Ec\277\362\031 >\275\212\375\277\213!\262\276"}initializer {dims: 1data_type: 7name: "To_TopKcst"raw_data: "\002\000\000\000\000\000\000\000"}initializer {dims: 3data_type: 7name: "knny_Reshapecst"raw_data: "\002\000\000\000\000\000\000\000\377\377\377\377\377\377\377\377\002\000\000\000\000\000\000\000"}input {name: "input"type {tensor_type {elem_type: 1shape {dim {}dim {dim_value: 4}}}}}output {name: "variable"type {tensor_type {elem_type: 1shape {dim {}dim {dim_value: 2}}}}}
}
opset_import {domain: ""version: 15
}
opset_import {domain: "ai.onnx.ml"version: 15
}
示意图如下所示:

子图由操作符Scan执行。在本例中,有一个scan输入,这意味着操作符只构建一个输出。
node = make_node('Scan', ['X1', 'X2'], ['Y1', 'Y2'],name='Sc_Scan', body=graph, num_scan_inputs=1, domain='')
在第一步迭代中,子图接收 X1 和 X2 的第一行作为输入。它会产生两个输出:
- 第一个输出用于在下一轮迭代中替换 X1。
- 第二个输出存储在一个容器中,最终形成 Y2。
在第二步迭代中,子图的第二个输入是 X2 的第二行。
以下是用颜色简要说明这个过程:
- 绿色表示第一轮迭代。
- 蓝色表示第二轮迭代。

相关文章:
onnx 1.16 doc学习笔记四:python API-If和Scan
onnx作为一个通用格式,很少有中文教程,因此开一篇文章对onnx 1.16文档进行翻译与进一步解释, onnx 1.16官方文档:https://onnx.ai/onnx/intro/index.html](https://onnx.ai/onnx/intro/index.html), 如果觉得有收获&am…...

如何构建企业专属GPT
大语言模型(LLM)具有令人印象深刻的自然语言理解和生成能力, 2022年11月底OpenAI发布了ChatGPT,一跃成为人工智能AI领域的现象级应用。但由于LLM的训练数据集主要来源于互联网数据,企业私域信息并未被LLM所训练&#x…...

知识积累(二):损失函数正则化与权重衰减
文章目录 1. 欧氏距离与L2范数1.1 常用的相似性度量 2. 什么是正则化?参考资料 本文只介绍 L2 正则化。 1. 欧氏距离与L2范数 欧氏距离也就是L2范数 1.1 常用的相似性度量 1)点积 2)余弦相似度 3)L1和L2 2. 什么是正则化&…...
消息中间件-面试题
MQ选择 一、Kafka 1、消息队列如何保证消息可靠性 消息不重复 生产者控制消费者幂等消息不丢失 生产者发送,要确认broker收到并持久化broker确认消费者消费完,再删除消息2、kafka是什么 Kafka是一种高吞吐量、分布式、基于发布/订阅的消息中间件,是Apache的开源项目。broke…...

Python 将二维数组或矩阵变为三维
Python 将二维数组或矩阵变为三维 引言正文基础 拓展 引言 之前,我们已经介绍过了 Python 将一维数组或矩阵变为三维。然而,很多时候,我们也需要对二维矩阵进行操作,这里特来介绍一下如何将二维矩阵扩展为三维。 阅读这一篇前推…...

区块链与Solidity详细介绍及基本语法使用
一、区块链简介 区块链是一种分布式数据库技术,它以块的形式存储数据,并通过加密算法确保数据的安全性。每个块包含一系列交易,并通过哈希值与前一个块相连接,形成一个链式结构。这种结构使得数据难以被篡改,因为任何对…...

题目 1253: 老王赛马
题目描述: 赛马是一古老的游戏,早在公元前四世纪的中国,处在诸侯割据的状态,历史上称为“战国时期”。在魏国作官的孙膑,因为受到同僚庞涓的迫害,被齐国使臣救出后,到达齐国国都。 赛马是当时最受齐国贵族…...
【MATLAB源码-第144期】基于matlab的蝴蝶优化算法(BOA)无人机三维路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 蝴蝶优化算法(Butterfly Optimization Algorithm, BOA)是基于蝴蝶觅食行为的一种新颖的群体智能算法。它通过模拟蝴蝶个体在寻找食物过程中的嗅觉导向行为以及随机飞行行为,来探索解空间…...
地下管线管网三维建模工具MagicPipe3D V3.4.2发布
经纬管网建模系统MagicPipe3D,本地离线参数化构建地下管网三维模型(包括管道、接头、附属设施等),输出标准3DTiles服务、Obj模型等格式,支持Cesium、Unreal、Unity、Osg等引擎加载进行三维可视化、语义查询、专题分析&…...
糖尿病性视网膜病变(DR)的自动化检测和分期
糖尿病性视网膜病变(DR)的自动化检测和分期 提出背景DR的阶段及其特征 历年解法计算机视觉方法多分类方法 新的解法深度学习方法迁移学习大模型多模型集成全流程分析 总结特征1:图像分割特征2:疾病分级特征3:治疗建议生…...
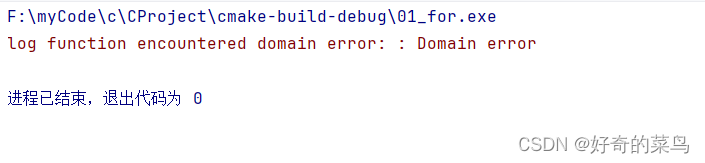
C 标准库 - <errno.h>
在C语言编程中,<errno.h> 头文件扮演着至关重要的角色,它提供了一个全局变量 errno 以及一系列预定义宏,用于指示系统调用或库函数执行过程中发生的错误。这些宏有助于程序员诊断和处理运行时错误。 errno 变量 extern int errno;err…...
基于springboot+vue的房屋租赁管理系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...
Sora----打破虚实之间的最后一根枷锁----这扇门的背后是人类文明的晟阳还是最后的余晖
目录 一.Sora出道即巅峰 二.为何说Sora是该领域的巨头 三.Sora无敌的背后究竟有怎样先进的处理技术 1.Spacetime Latent Patches 潜变量时空碎片,建构视觉语言系统 2.扩散模型与Diffusion Transformer,组合成强大的信息提取器 3.DiT应用于潜变量时…...

C语言之static关键字详解
C语言之static关键字详解_c语言static-CSDN博客 1.变量 2.局部变量和全局变量 3.变量的作用域 4.变量的生命周期 二、static关键字的作用 三、static关键字修饰局部变量 四、static关键字修饰全局变量 五、static关键字修饰函数...
Redis高性能原理
redis大家都知道拥有很高的性能,每秒可以支持上万个请求,这里探讨下它高性能的原理。单线程架构和io多路复用技术。 一,单线程架构 单线程架构指的是命令执行核心线程是单线程的,数据持久化、同步、异步删除是其他线程在跑的。re…...
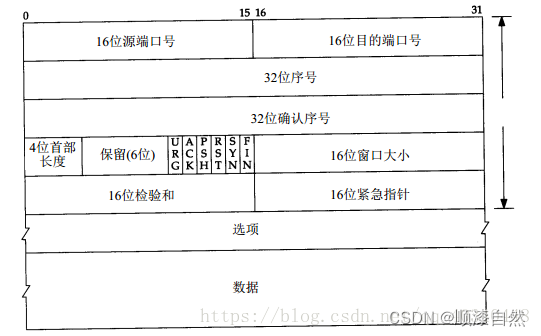
MSS与cwnd的关系,rwnd又是什么?
慢启动算法是指数递增的 这种指数增长的方式是慢启动算法的一个核心特点,它确保了TCP连接在开始传输数据时能够快速地探测网络的带宽容量,而又不至于过于激进导致网络拥塞。具体来说: 初始阶段:当TCP连接刚建立时,拥…...
解决两个MySQL5.7报错
目录 1.启动不了MySQL,报错缺少MSVCR120.dll去官网下载vcredist_x64.exe运行安装进入管理员CMD 2.本地计算机 上的 mysql 服务启动后停止。某些服务在未由其他服务或程序使用时将自动停止,Fatal error: Can‘t open and lock privilege tables: Table ‘…...

[OpenAI]继ChatGPT后发布的Sora模型原理与体验通道
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言OpenAI体验通道Spacetime Latent Patches 潜变量时空碎片, 建构视觉语言系统…...

机器人初识 —— 电机传动系统
一、背景 波士顿动力公司开发的机器人,其电机传动系统是其高性能和动态运动能力的核心部分。电机传动系统通常包括以下几个关键组件: 1. **电动马达**:波士顿动力的机器人采用了先进的电动马达作为主要的动力源,如伺服电机或步进…...
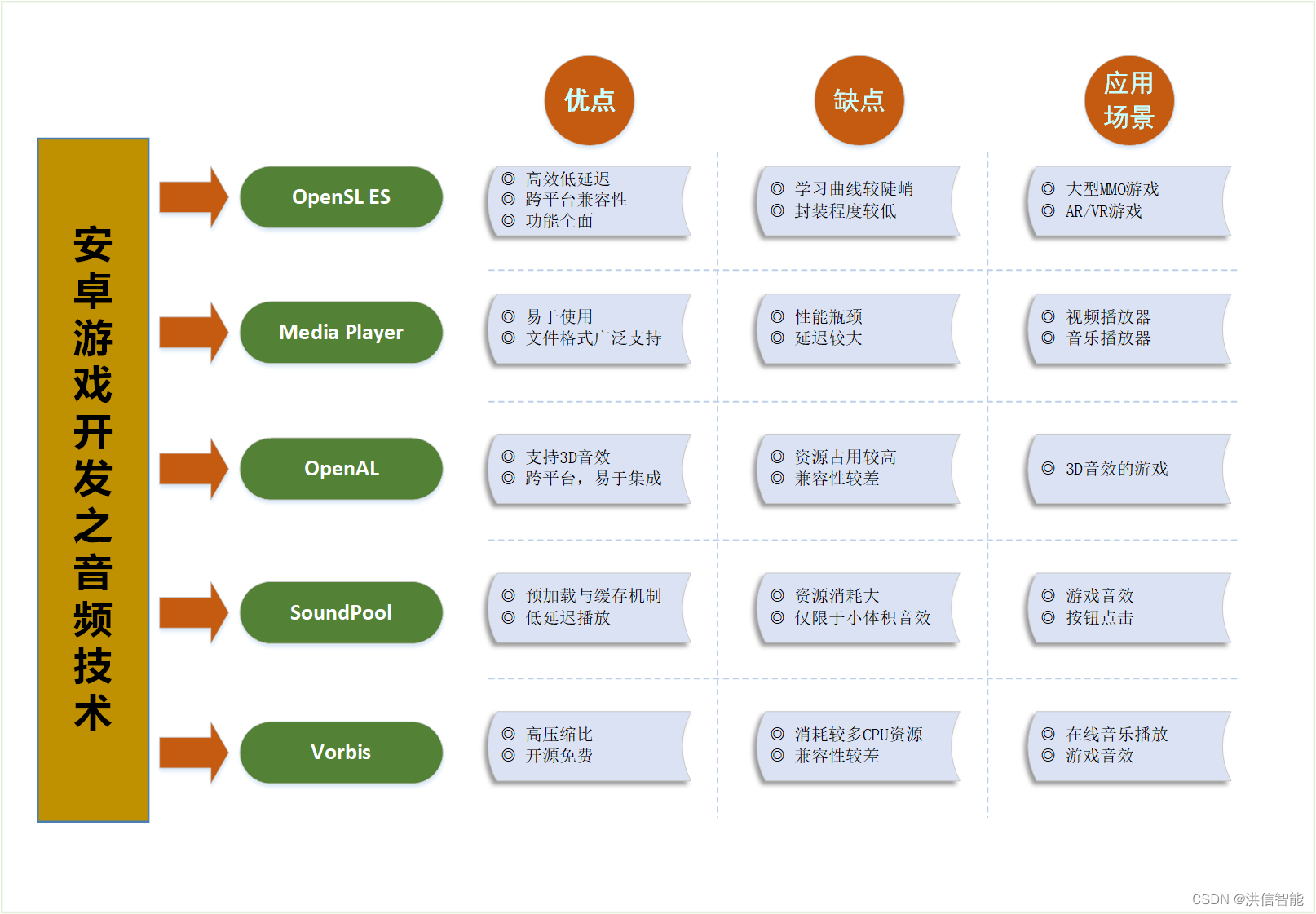
安卓游戏开发之音频技术优劣分析
一、引言 在安卓游戏开发中,音频处理技术扮演着至关重要的角色,它不仅能够增强游戏的沉浸感和玩家体验,还能通过声音效果传达关键的游戏信息。以下将对几种常见的安卓游戏音频处理技术进行优劣分析,并结合应用场景来阐述其特点。 …...

pycharm接入AI大模型测试脚本费用说明
费用说明 阿里云通义千问提供: 新用户免费额度:注册即送一定额度的免费 tokens 按量付费:用多少付多少,无最低消费 价格透明:详见 官方定价 示例成本(以 qwen-plus 为例) 解析-个 100页 PDF≈ 50,000 tokens ≈0.4 生成 100 个问答对≈20,000 tokens ≈0.16 下一步 …...

植物树枝叶片果实检测数据集7220张VOC+YOLO格式
植物树枝叶片果实检测数据集7220张VOCYOLO格式数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):7220 标注数量(xml文件个数):7220…...

别再为485传感器没文档发愁了!一个USB转485模块+两款免费软件,5分钟搞定Modbus通信测试
5分钟极简方案:用USB转485模块与开源工具破解Modbus传感器通信 当你拿到一个没有文档的485温湿度传感器时,是否曾为如何读取数据而头疼?本文将分享一套经过实战验证的极简工具组合——仅需一个常见的USB转485转换器和两款免费软件,…...

通过用量看板与账单追溯实现团队 AI 成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与账单追溯实现团队 AI 成本精细化管理 对于技术团队而言,将大模型能力集成到产品与研发流程中已成为常态…...

别再手动拖元件了!Cadence Allegro SPB17.4的Room功能,让你的PCB布局效率翻倍
别再手动拖元件了!Cadence Allegro SPB17.4的Room功能,让你的PCB布局效率翻倍 面对包含数十个子电路的新项目,传统PCB布局方式往往让人陷入"元件海洋"的困境。工程师们不得不花费大量时间在杂乱无章的元件堆中寻找目标器件…...

SAP UI5 里没有 BehaviorSubject,但有更贴近企业 UI 的状态流
问题: SAP UI5 的开发技术里,有类似 Angular 中 BehaviorSubject 的概念和用法? 我今天理解这个问题时,不能直接问 SAP UI5 里有没有一个类叫 BehaviorSubject,因为这个问法会把 Angular 和 SAP UI5 的编程范式强行拉到同一个坐标系里。更准确的问题应该是,SAP UI5 里有…...

从码农到技术总监:10年程序员的职业进化史
一、初入职场:在代码与bug中蹒跚学步2016年的夏天,我背着双肩包,攥着毕业证,走进了一家中型软件公司的大门,成为了一名Java开发程序员,也就是别人口中的“码农”。那时候,我的生活被代码和bug填…...

Hermes 的核心架构 Harness:上下文、工具、权限与执行控制
上一篇写 Hermes-Agent,我们选了一条比较笨但好用的路:跟一条消息走一遍。 从终端里敲下一句话,到 Agent 把最后一个字回到屏幕上,中间其实绕了很长一圈: 消息先被入口收进去,变成内部统一的消息…...

3步高效部署AutoJs6:Android自动化开发实战指南
3步高效部署AutoJs6:Android自动化开发实战指南 【免费下载链接】AutoJs6 安卓平台 JavaScript 自动化工具 (Auto.js 二次开发项目) 项目地址: https://gitcode.com/gh_mirrors/au/AutoJs6 AutoJs6作为Android平台领先的JavaScript自动化工具,为开…...

Ghost区块链集成:NFT内容所有权与分发方案
Ghost区块链集成:NFT内容所有权与分发方案 内容创作者的数字版权困境 传统内容发布平台存在严重的数字版权问题:文章被随意转载、原创收益被平台抽成、作品归属权难以证明。根据2024年《数字内容版权报告》,78%的独立创作者曾遭遇内容侵权&…...