gem5学习(25):用于异构SoC的片上网络模型——Garnet2.0
目录
一、Invocation
二、Configuration
三、Topology
四、Routing
五、Flow Control
六、Router Microarchitecture
七、Buffer Management
八、Lifecycle of a Network Traversal
九、Running Garnet2.0 with Synthetic Traffic
官网教程:gem5: Garnet 2.0
Garnet2.0是gem5内部的一个详细互连网络模型,是在2009年发表的原始Garnet模型的基础上进行构建的。目前正在开发中,并将定期推送具有更多功能的补丁到gem5中。
其他与Garnet相关的额外补丁和工具支持(不属于存储库),可以在佐治亚理工学院的Garnet页面查看:garnet | Synergy Lab。
Garnet2.0是一个在芯片上网络路由器的周期精确微体系结构实现。它通过利用gem5的ruby内存系统模型提供的拓扑和路由基础设施来实现。默认情况下,Garnet2.0采用先进的1周期流水线作为路由器的设计。然而,通过在拓扑中指定任意数量的周期,可以在任何路由器中添加额外的延迟。
此外,Garnet2.0还可以通过在路由器和链路中设置适当的延迟来模拟片外互连网络。这使得Garnet2.0不仅适用于芯片内部的网络模拟,还可以扩展到模拟片外的互连网络。通过调整路由器和链路的延迟,可以模拟片外网络中的传输延迟和信号传播延迟等特性。
相关文件:
- src/mem/ruby/network/Network.py
- src/mem/ruby/network/garnet2.0/GarnetNetwork.py
- src/mem/ruby/network/Topology.cc
一、Invocation
Garnet网络可以通过添加参数“--network=garnet2.0”来实现。
二、Configuration
Garnet2.0使用了Network.py中的通用网络参数:
- number_of_virtual_networks: 这是最大虚拟网络的数量。实际活动虚拟网络的数量由协议确定。
- control_msg_size: 控制消息的大小,以字节为单位。默认为8。
- Network.cc中的m_data_msg_size设置为块大小(以字节为单位)+ control_msg_size。
其他参数在garnet2.0/GarnetNetwork.py中指定:
- ni_flit_size: flit的大小,以字节为单位。Flit是从一个路由器发送到另一个路由器的信息的粒度。默认为16(=> 128位)。[1使用16作为默认值可以确保控制消息适应1个flit内,数据消息适应5个flits内]。Garnet要求ni_flit_size与network/BasicLink.py中的bandwidth_factor(带宽因子)相同,因为它不模拟网络内的可变带宽,这意味着ni_flit_size应与网络中的链路宽度相匹配。也可以通过命令行参数“--link-width-bits”来设置ni_flit_size的值。
- vcs_per_vnet: 每个虚拟网络的虚拟通道(VC)数量。默认为4。也可以通过命令行参数“--vcs-per-vnet”进行设置。
- buffers_per_data_vc: 数据消息类别中每个VC的flit缓冲区数量。由于数据消息占据5个flits,所以该值可以在1到5之间。默认为4,这意味着每个数据VC具有4个flit缓冲区。
- buffers_per_ctrl_vc: 控制消息类别中每个VC的flit缓冲区数量。由于控制消息占据1个flit,并且一个VC一次只能容纳一条消息,所以该值必须为1。默认为1,这意味着每个控制VC具有4个flit缓冲区。
- routing_algorithm:
- 0: 基于权重的表(默认值);
- 1: XY;
- 2: 自定义。
三、Topology
Garnet2.0是建立在gem5的ruby内存系统模型之上的,利用其提供的拓扑基础设施。
Garnet2.0可以对任意异构的拓扑结构进行建模。
在拓扑文件中,每个路由器都可以被分配一个独立的延迟值,以覆盖默认值。此外,每个链路还有两个可选参数:src_outport和dst_inport,它们是源路由器和目标路由器的输出和输入端口的名称字符串。这些参数可以在garnet2.0内部用于实现自定义的路由算法(例如,在一个网格(Mesh)拓扑中,从西向东的链路的src_outport设置为"west",dst_inport设置为"east")。
以下是一些与网络组件相关的说明:
- GarnetNetwork:这是顶层对象,用于实例化所有的网络接口(NetworkInterface)、路由器(Router)和链路(NetworkLink)。在Topology.cc中调用方法以添加"外部链路"(external links)连接网络接口和路由器,以及添加"内部链路"(internal links)连接路由器之间。
- NetworkInterface:每个网络接口(NI)通过一侧的MsgBuffer接口与一个一致性控制器连接,另一侧连接到路由器。每个协议消息都被放入一个包含一个flit控制消息或多个(默认为5个)flit数据消息的缓冲区,并注入到路由器中。多个网络接口可以连接到同一个路由器,例如,在网格(Mesh)拓扑中,缓存和目录控制器通过各自的网络接口连接到同一个路由器。
- Router:路由器负责输出链路的仲裁和路由器之间的流量控制。
- NetworkLink:网络链路承载flit,可以分为三种类型:EXT_OUT_(路由器到网络接口),EXT_IN_(网络接口到路由器)和INT_(内部路由器到路由器)。
- CreditLink:信用链路在路由器之间携带虚拟通道(VC)/缓冲区的信用,用于流量控制。
四、Routing
Garnet2.0是利用gem5的ruby内存系统模型提供路由基础设施的一个组件。
默认情况下,Garnet2.0使用基于确定性表格的最短路径路由算法作为默认的路由算法。该算法会根据预先定义的路由表来确定数据包应该沿着哪条路径进行转发。链路权重可以用于优先考虑某些链路,以便在路由选择时更加灵活。关于如何填充路由表的详细信息可以参考"src/mem/ruby/network/Topology.cc"文件。
自定义路由(Custom Routing):为了模拟自定义的路由算法,例如自适应路由,提供了一个框架来为每个链路命名源出口(src_outport)和目的入口(dst_inport),并在garnet内部使用它们来实现路由算法。例如,在网格(Mesh)拓扑结构中,可以通过将flit沿着“west”输出端口链路发送,直到flit不再具有任何X方向的跳数,然后随机选择剩余链路之一(或根据下一个路由器的VC可用性选择)(有关该实现方式的详细内容可以参考"src/mem/ruby/network/garnet2.0/RoutingUnit.cc"文件中的outportComputeXY()函数)。类似地,可以实现outportComputeCustom()函数,并通过在命令行中添加--routing-algorithm=2来调用。
多播消息(Multicast messages):需要注意的是,模拟的网络不支持硬件内部的多播消息。多播消息会在网络接口处被分解为多个单播消息进行传输和处理。
五、Flow Control
虚拟通道流量控制是在该设计中使用的一种技术。它将通信通道划分为多个虚拟通道,每个虚拟通道可以独立地容纳一个数据包。
在设计中,存在两种类型的虚拟通道,即控制通道和数据通道。控制通道用于传输控制信息,而数据通道用于传输实际的数据。
每个虚拟通道都有一个与之关联的缓冲区,用于存储待传输的数据包。这些缓冲区的深度可以在GarnetNetwork.py文件中进行独立的控制。默认情况下,控制通道的缓冲区深度为1个flit(流片片段),而数据通道的缓冲区深度为4个flit。
除了缓冲区深度之外,数据包的大小也是虚拟通道流量控制中的一个重要参数。在该设计中,控制包的默认大小为1个flit,而数据包的默认大小为5个flit。
六、Router Microarchitecture
在Garnet2.0路由器中,传入的flit经历以下操作:
-
缓冲写入(Buffer Write,BW):传入的flit被存储在其所属的虚拟通道(VC)中进行缓冲。
-
路由计算(Route Compute,RC):缓冲的flit计算出它应该发送到的输出端口,并将这个信息存储在其VC中。
-
交换机分配(Switch Allocation,SA):所有缓冲的flit尝试在下一个周期中为交换机端口预留位置。这个分配过程是可分离的,首先每个输入端使用输入仲裁器选择一个输入VC,并发出一个交换机请求。然后,每个输出端通过输出仲裁器解决冲突,确定哪些请求可以成功分配。在有序虚拟网络中,所有的仲裁器都以队列方式工作,以维持点对点的顺序。对于其他类型的网络,仲裁器采用轮询方式。
-
VC选择(VC Selection,VS):在交换机分配过程中胜出的flit从其所属的输出端口中选择一个空闲的虚拟通道(VC),如果该flit是一个头部(HEAD)或头尾(HEAD_TAIL)flit。
-
交换机遍历(Switch Traversal,ST):在交换机分配成功后,胜出的flit通过交换机进行遍历,从输入端口转发到输出端口。
-
链路遍历(Link Traversal,LT):经过交换机遍历后,flit通过链路传输到达下一个路由器。
在默认设计中,缓冲写入(BW)、路由计算(RC)、交换机分配(SA)、VC选择(VS)和交换机遍历(ST)都在同一个周期内完成。链路遍历(LT)则在下一个周期中进行。
注意:如果需要模拟多周期路由器(Multi-cycle Router),可以在拓扑文件中指定每个路由器的延迟,或者修改src/mem/ruby/network/BasicRouter.py中的默认路由器延迟。这样做会使缓冲的flit在路由器中等待(延迟-1)个周期,然后才能参与交换机分配过程。
七、Buffer Management
在每个路由器的输入端口中,存在number_of_virtual_networks个虚拟网络(Vnets),每个虚拟网络包含vcs_per_vnet个虚拟通道(VC)。虚拟通道(VC)可以被认为是在同一输入端口上的不同逻辑通道,用于在路由器内部缓存和传输数据。
对于控制虚拟网络,每个VC具有buffers_per_ctrl_vc(默认为1)个缓冲深度。这意味着每个VC可以同时缓存1个控制消息。
对于数据虚拟网络,每个VC具有buffers_per_data_vc(默认为4)个缓冲深度。这意味着每个VC可以同时缓存4个数据包。
为了维护关于可用VC和每个VC内缓冲区数量的信息,使用信用(Credits)进行传递。Credits是一种表示可用资源的计数器,用于指示虚拟通道中可供使用的空闲VC数量以及每个VC中剩余的缓冲区数量。路由器通过在传输过程中更新Credits来跟踪可用资源的状态,并根据Credits的值进行决策,例如选择可用的VC进行传输。这样可以避免拥塞和资源竞争,以提高网络性能和可靠性。
八、Lifecycle of a Network Traversal
组件之间的交互过程:
- NetworkInterface.cc::wakeup()
- 每个网络接口(NI)一端连接着一个一致性协议控制器,另一端连接着一个路由器。
- 接收来自虚拟网络的一致性协议缓冲区的消息,并将其转换为网络数据包发送到网络中【Garnet2.0在此时添加了捕获网络跟踪的功能(正在开发中)】。
- 从网络接收flit,提取协议消息,并将其发送到相应虚拟网络的一致性协议缓冲区。
- 与所连接的路由器一起管理流量控制(即信用)。
- NI的消费flit/credit输出链路将在全局事件队列中放置,并设置时间戳为下一个周期。事件队列调用消费者的wakeup函数。
- NetworkLink.cc::wakeup()
- 从NI/路由器接收flit,并在m_latency个周期的延迟后将其发送到NI/路由器。
- 每个链路的默认延迟值可以从命令行设置(参见configs/network/Network.py)。
- 可以在拓扑文件中覆盖每个链路的延迟值。
- 链路的消费者(NI/路由器)将在全局事件队列中放置,并设置时间戳为m_latency个周期后。事件队列调用消费者的wakeup函数。
- Router.cc::wakeup()
- 循环遍历所有的输入单元(InputUnit)并调用它们的wakeup函数。
- 循环遍历所有的输出单元(OutputUnit)并调用它们的wakeup函数。
- 调用SwitchAllocator的wakeup函数。
- 调用CrossbarSwitch的wakeup函数。
- 当路由器的任何模块【InputUnit(输入单元)、OutputUnit(输出单元)、SwitchAllocator(交换分配器)、CrossbarSwitch(交叉开关)】在本周期内有准备好的flit/credit时,会调用路由器的wakeup函数。
- InputUnit.cc::wakeup()
- 如果来自上游路由器的输入flit在本周期准备好,则读取它。
- 对于头部(HEAD)/头尾(HEAD_TAIL)flit,执行路由计算,并更新虚拟通道(VC)中的路由。
- 将flit缓冲m_latency-1个周期,并标记为从那个周期起对SwitchAllocation有效。
- 每个路由器的默认延迟可以从命令行设置(参见configs/network/Network.py)。
- 可以在拓扑文件中设置每个路由器的延迟(即流水线阶段数)。
- OutputUnit.cc::wakeup()
- 如果来自下游路由器的输入credit在本周期准备好,则读取它。
- 增加相应输出VC状态中的credit。
- 如果credit携带is_free_signal为true,则将输出VC标记为空闲状态。
- SwitchAllocator.cc::wakeup()
- 注意:SwitchAllocator执行VC仲裁和选择。
- SA-I(或SA-i):循环遍历每个输入端口的所有输入VC,并以轮换的方式选择一个。
- 对于头部(HEAD)/头尾(HEAD_TAIL)flit,选择一个输入虚拟通道(VC),该输入VC连接的输出端口至少有一个空闲的输出虚拟通道(VC)。
- 对于BODY/TAIL flit,只选择其输出VC中有credit的输入VC。
- 为该VC放置一个对输出端口的请求。
- SA-II(或SA-o):循环遍历所有输出端口,并以轮换的方式,在每个输出端口上选择一个合适的输入VC,并将该VC标记为获胜者。
- 对于头部(HEAD)/头尾(HEAD_TAIL)flit,执行输出VC分配(outvc allocation),即从输出端口选择一个空闲VC。
- 对于BODY/TAIL flit,在输出VC中减少一个credit。
- 从输入VC读取flit,并将其发送到CrossbarSwitch中。
- 在网络通信中,路由器之间通过发送信号来管理虚拟通道(VC)的流量控制。增加credit的信号是一种用于向上游路由器发送的信号,用于表示该输入虚拟通道(VC)中的可用资源。
- 对于头尾(HEAD_TAIL)/尾部(TAIL)flit,在credit中标记is_free_signal为true。
- 输入单元将credit通过credit链路发送给上游路由器。
- CrossbarSwitch.cc::wakeup()
- 循环遍历所有输入端口,并将获胜的flit发送到其输出端口的输出链路上。
- 路由器的消费flit输出链路将在全局事件队列中放置,并设置时间戳为下一个周期。事件队列调用消费者的wakeup函数。
- NetworkLink.cc::wakeup()
- 从NI/路由器接收flit,并在m_latency个周期的延迟后将其发送到NI/路由器。
- 每个链路的默认延迟值可以从命令行设置(参见configs/network/Network.py)。
- 可以在拓扑文件中覆盖每个链路的延迟值。
- 链路的消费者(NI/路由器)将在全局事件队列中放置,并设置时间戳为m_latency个周期后。事件队列调用消费者的wakeup函数。
九、Running Garnet2.0 with Synthetic Traffic
(使用合成流量运行Garnet2.0)
Garnet2.0可以独立运行,并通过合成流量进行测试:Garnet合成流量。
相关文章:
:用于异构SoC的片上网络模型——Garnet2.0)
gem5学习(25):用于异构SoC的片上网络模型——Garnet2.0
目录 一、Invocation 二、Configuration 三、Topology 四、Routing 五、Flow Control 六、Router Microarchitecture 七、Buffer Management 八、Lifecycle of a Network Traversal 九、Running Garnet2.0 with Synthetic Traffic 官网教程:gem5: Garnet 2…...
康威生命游戏
康威生命游戏 康威生命游戏(Conway’s Game of Life)是康威发明的细胞自动机。 生命游戏有几个简单的规则: 细胞有两种状态,存活或死亡,每个细胞以自身为中心与周围的八格细胞互动。 对于存活的细胞: 当周围的细胞过少(<2)或…...

vscode与vue环境配置
一、下载并安装VScode 安装VScode 官网下载 二、配置node.js环境 安装node.js 官网下载 会自动配置环境变量和安装npm包(npm的作用就是对Node.js依赖的包进行管理),此时可以执行 node -v 和 npm -v 分别查看node和npm的版本号: 配置系统变量 因为在执…...
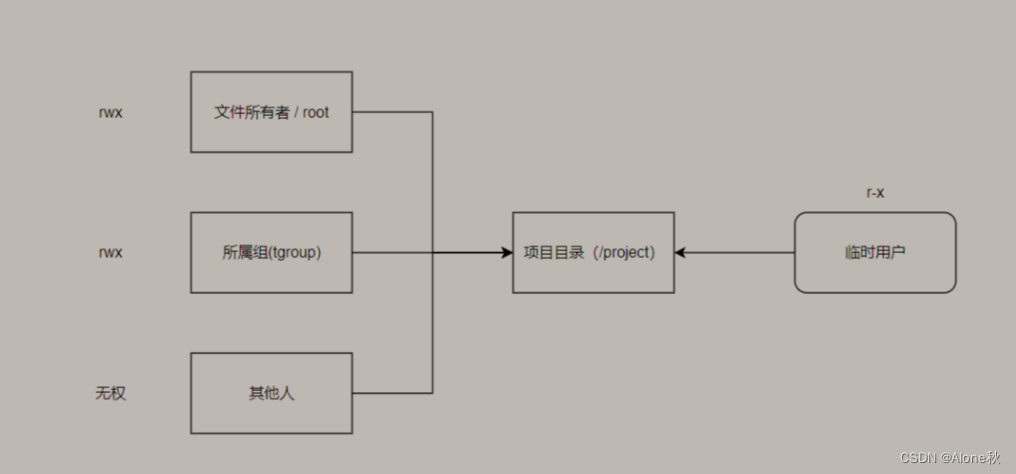
Linux的ACL权限以及特殊位和隐藏属性
前言: ACL是什么? ACL(Access Control List)是一种权限控制机制,用于在Linux系统中对文件和目录进行细粒度的访问控制。传统的Linux权限控制机制基于所有者、所属组和其他用户的三个权限类别(读、写、执行…...
使用openai-whisper实现语音转文字
使用openai-whisper实现语音转文字 1 安装依赖 1.1 Windows下安装ffmpeg FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。 # ffmpeg官网 https://ffm…...

C++模板为什么不能声明和定义分离
首先我们要直到C程序运行需要进行的四个阶段。 预处理->编译->汇编->链接 编译:对语法语义分析,分析无误生成汇编,头文件不参加编译,多个源文件是分开单独编译的。 链接:将多个obj文件链接合成一个&#x…...
啊丢的刷题记录手册
1.洛谷题P1923 求第k小的数 题目描述 输入 n(1≤n<5000000 且 n 为奇数)个数字ai(1≤ai<109),输出这些数字的第 k 小的数。最小的数是第 0 小。 请尽量不要使用 nth_element 来写本题,因为本题…...

用nginx正向代理https网站
目录 1. 缘起2. 部署nginx3. 测试3.1 http测试3.2 https测试4 给centos设置代理访问外网 1. 缘起 最近碰到了一个麻烦事情,就是公司的centos测试服务器放在内网环境,而且不能直接上外网,导致无法通过yum安装软件,非常捉急。 幸…...

面向对象设计模式
一、单例 一个类只能创建唯一一个对象 利用限制构造、static完成 二、工厂模式 优势:规范接口(纯虚函数);实现多态(虚函数表);继承 1、简单工厂 一个工厂创建所有产品。 返回基类指针可…...

人工智能_CPU微调ChatGLM大模型_使用P-Tuning v2进行大模型微调_007_微调_002---人工智能工作笔记0102
这里我们先试着训练一下,我们用官方提供的训练数据进行训练. 也没有说使用CPU可以进行微调,但是我们先执行一下试试: https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e 可以看到说INT4量化级别最低需要7GB显存可以启动微调,但是 并没有说CPU可以进行微调.我们…...
Android自编译Pixel3内核加入KernelSU
背景 让Pixel3 AOSP Android10 4.9内核用上Kernel SU 环境: Ubuntu 18.04 vm aosp10r2 移植参考官方,和github项目 Commits OnlyTomInSecond/android_kernel_xiaomi_sdm845 (github.com) 这个项目是 LineageOS/android_kernel_xiaomi_sdm845 编译的前提 已经有完整…...

Go 数据库编程精粹:database/sql 实用技巧解析
Go 数据库编程精粹:database/sql 实用技巧解析 简介database/sql 库的基础知识核心概念连接池驱动事务 环境配置 建立数据库连接连接到数据库示例:连接 MySQL 数据库连接池管理 执行查询和处理结果基本查询执行多行查询执行单行查询 结果处理处理多行结果…...

AI-Gateway:一款整合了OpenAI、Anthropic、LLama2等大语言模型的统一API接口
关于AI-Gateway AI-Gateway是一款针对大语言模型的统一API接口,该接口可以用在应用程序和托管的大语言模型(LLM)之间,该工具可以允许我们通过一个统一的API接口将API请求转发给OpenAI、Anthropic、Mistral、LLama2、Anyscale、Go…...
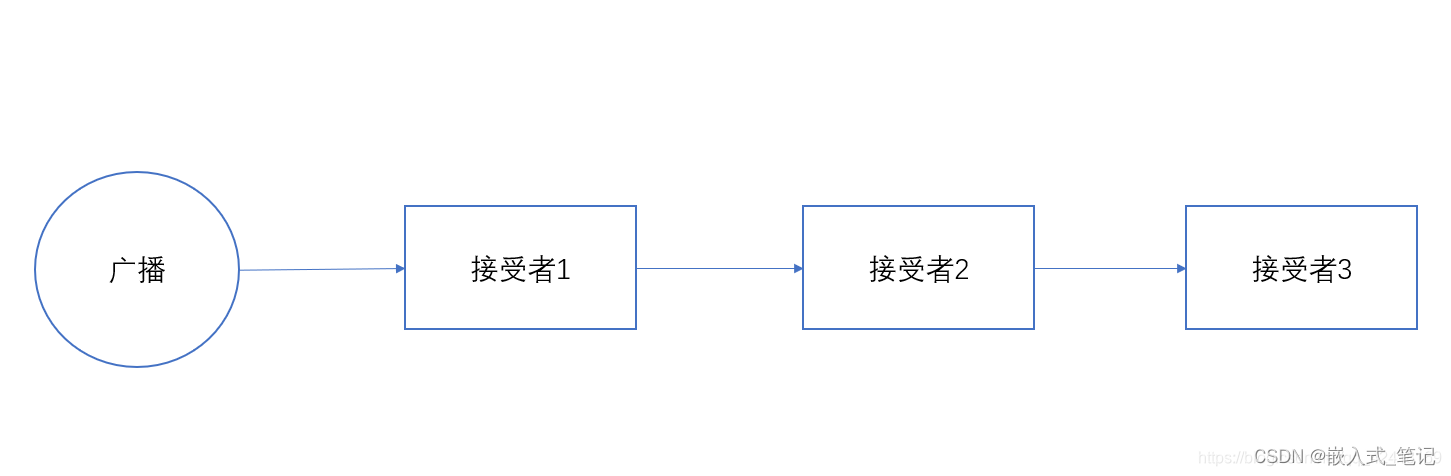
Android 广播的基本概念
一.广播简介 Broadcast是安卓四大组件之一。安卓为了方便进行系统级别的消息通知,引入了一套广播消息机制。打个比方,记得原来在上课的时候,每个班级的教室里都会装有一个喇叭,这些喇叭都是接入到学校的广播室的,一旦…...
【Docker实操】部署php项目
概述 最终达成的容器部署结构和原理如下图: 一、获取nginx、php官方镜像 docker pull nginx //拉取nginx官方镜像 docker pull php:7.4-fpm //拉取php官方镜像需要获取其他可用的php版本,可以上【docker hub】搜索【php】,所有的【xxx-fp…...

多线程-初阶
1. 认识线程( Thread ) 1.1 概念 1) 线程是什么 一个线程就是一个 " 执行流 ". 每个线程之间都可以按照顺讯执行自己的代码 . 多个线程之间 " 同时 " 执行 着多份代码 . 还是回到我们之前的银行的例子中。之前我们主要描…...

Object和Function是函数,函数都有一个prototype属性
Object 和 Function 都是 JavaScript 自带的函数对象 在 JavaScript 中,万物皆对象,你要一个吗?new Object() 啊! 当然,就好比同样为人,也区分普通人和天才。 对象也是有分类的,分为 普通对象…...
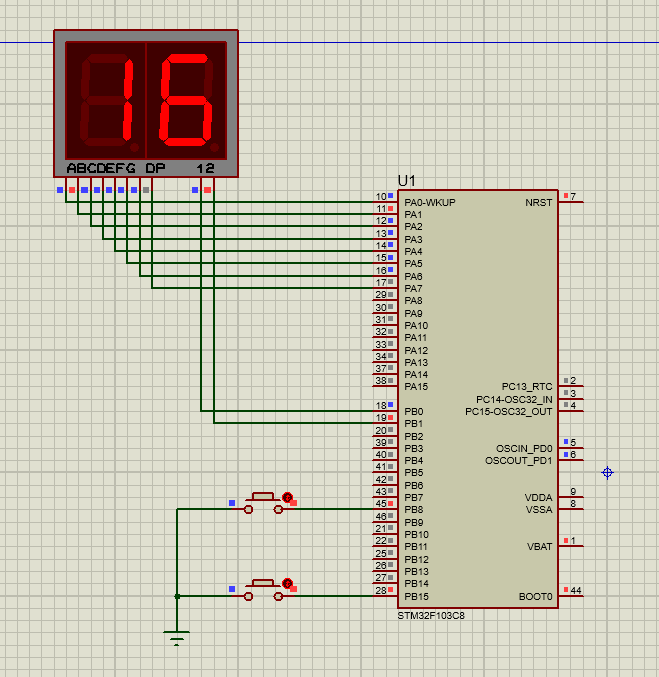
stm32利用CubeMX按键控制数码管加减数
首先画电路图: 接下来配置CubeMX: 设置好后生成MDK工程文件: 用keil打开工程: 添加部分代码: /* USER CODE BEGIN Includes */ uint16_t duan[]{0xC0, 0xf9, 0xa4, 0xb0, 0x99, 0x92, 0x82, 0xf8, 0x80, 0x90}; uint1…...

前端页面生成条形码,借助layui打印标签
借助JsBarcode生成条形码 官网:https://lindell.me/JsBarcode/ github: https://github.com/lindell/JsBarcode <div class"table-div" style"display: block;width: 300px; height: 241px; margin: auto;"><table border"1&quo…...

第1~8章 综合复习
1. 重置root密码 1. 重启服务器(虚拟机)2. 快速选择第二项,然后按 e 键3. 在linux这一行的最后加上一个空格,然后输入 rd.break,然后按 ctrl x 来重启服务4. 在提示符所在位置输入 mount -o remount,rw /sysroot5. 在…...

如何自动化监控线上问题
要实现线上问题的自动化监控,不能仅停留在工具的堆砌,而需要从体系规划、数据采集、智能告警、动态诊断到流程规范进行全盘设计。以下是基于行业最佳实践的自动化监控构建指南:一、 体系规划与监控点梳理构建自动化监控的第一步是明确“监控什…...

机器人全身控制与SLAM系统核心技术解析
1. 机器人全身控制技术解析Sprout机器人采用的全身控制策略(Whole-Body Policy)通过分层控制架构实现了稳定运动与精准操作的平衡。该系统将控制分为三个主要层级:骨盆姿态控制、上肢柔顺控制和高度调节。这种分层设计使得机器人能够在保持上…...

Go语言微服务架构设计:从理论到实践
Go语言微服务架构设计:从理论到实践 引言 微服务架构已经成为现代软件架构的主流模式。Go语言凭借其高性能、轻量级和并发能力,成为构建微服务的理想选择。本文将深入探讨微服务架构的核心概念、Go语言实现策略,以及如何构建可扩展、高可用的…...
)
保姆级教程:用ADAMS 2023复现人体行走与跌倒仿真(附完整模型参数与源文件)
ADAMS 2023生物力学仿真实战:从人体步态建模到跌倒临界点分析 在工程仿真领域,人体运动动力学一直是极具挑战性的研究方向。ADAMS作为多体动力学仿真软件的标杆,其2023版本在生物力学仿真方面新增了多项实用功能。本文将带您从零开始…...

Linux服务器文件传输服务搭建:从FTP协议到vsftpd实战部署
1. 项目概述:为什么要在Linux上搭建FTP服务器?很多刚接触Linux的朋友,尤其是从Windows转过来的,一提到搭建服务器,特别是像FTP这种“古老”但依然实用的文件传输服务,第一反应可能就是“头大”。在Windows上…...

Loop窗口管理:5个高效工作流提升你的Mac生产力
Loop窗口管理:5个高效工作流提升你的Mac生产力 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop Loop是一款为macOS设计的优雅窗口管理工具,通过径向菜单、快捷键绑定和智能窗口操…...

终极无人机仿真平台XTDrone:从入门到精通的完整指南
终极无人机仿真平台XTDrone:从入门到精通的完整指南 【免费下载链接】XTDrone UAV Simulation Platform based on PX4, ROS and Gazebo 项目地址: https://gitcode.com/gh_mirrors/xt/XTDrone XTDrone是一款基于PX4飞控、ROS机器人操作系统和Gazebo物理引擎的…...

基于ESP32与电子墨水屏的低功耗物联网信息终端开发实战
1. 项目概述:打造你的专属韦伯望远镜状态看板 如果你和我一样,对浩瀚宇宙充满好奇,同时又是个喜欢动手鼓捣硬件的极客,那么这个项目绝对能让你兴奋起来。想象一下,在你的书桌或工作台上,有一个巴掌大的设备…...

猫抓浏览器扩展:三步实现网页视频自由下载的完整指南
猫抓浏览器扩展:三步实现网页视频自由下载的完整指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到这样的情况&#x…...

Chiplet技术与全相干扩展架构解析
1. Chiplet技术概述与全相干扩展架构在现代计算架构中,Chiplet技术正在彻底改变传统单片SoC的设计范式。这种模块化设计方法允许将不同功能单元分解为独立的硅片,通过先进封装技术互连。全相干扩展(远程翻译)Chiplet作为其中的关键…...