【解决(几乎)任何机器学习问题】:特征选择
from sklearn.feature_selection import VarianceThreshold
data = .
var_thresh = VarianceThreshold(threshold=0.1)
transformed_data = var_thresh.fit_transform(data)import pandas as pd
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
df = pd.DataFrame(X, columns=col_names)
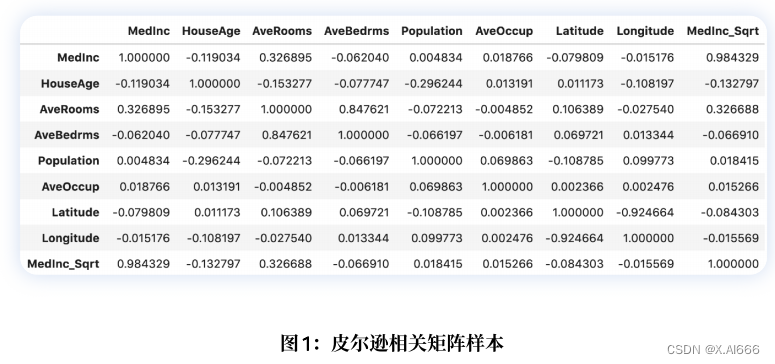
df.loc[:, "MedInc_Sqrt"] = df.MedInc.apply(np.sqrt)
df.corr()得出相关矩阵,如图 1 所⽰。
from sklearn.feature_selection import chi2
from sklearn.feature_selection import f_classif
from sklearn.feature_selection import f_regression
from sklearn.feature_selection import mutual_info_classif
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import SelectPercentileclass UnivariateFeatureSelction:def __init__(self, n_features, problem_type, scoring):if problem_type == "classification":valid_scoring = {"f_classif": f_classif,"chi2": chi2,"mutual_info_classif": mutual_info_classif}else:valid_scoring = {"f_regression": f_regression,"mutual_info_regression": mutual_info_regression}if scoring not in valid_scoring:raise Exception("Invalid scoring function")if isinstance(n_features, int):self.selection = SelectKBest(valid_scoring[scoring],k=n_features)elif isinstance(n_features, float):self.selection = SelectPercentile(valid_scoring[scoring],percentile=int(n_features * 100))else:raise Exception("Invalid type of feature")def fit(self, X, y):return self.selection.fit(X, y)def transform(self, X):return self.selection.transform(X)def fit_transform(self, X, y):return self.selection.fit_transform(X, y)
使⽤该类⾮常简单。
# Example usage:
ufs = UnivariateFeatureSelction(n_features=0.1,problem_type="regression",scoring="f_regression"
)
ufs.fit(X, y)
X_transformed = ufs.transform(X)import pandas as pd
from sklearn import linear_model
from sklearn import metrics
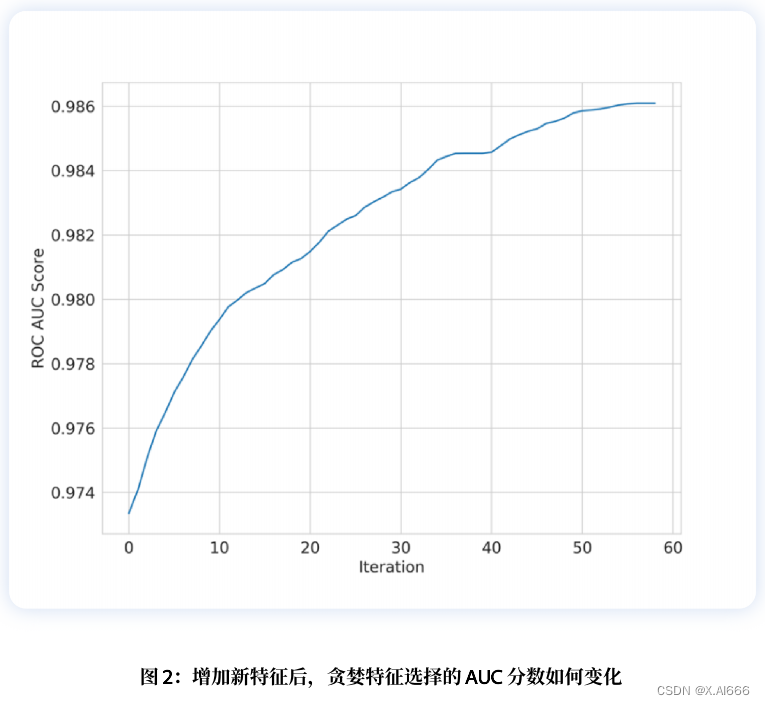
from sklearn.datasets import make_classificationclass GreedyFeatureSelection:def evaluate_score(self, X, y):model = linear_model.LogisticRegression()model.fit(X, y)predictions = model.predict_proba(X)[:, 1]auc = metrics.roc_auc_score(y, predictions)return aucdef _feature_selection(self, X, y):good_features = []best_scores = []num_features = X.shape[1]while True:this_feature = Nonebest_score = 0for feature in range(num_features):if feature in good_features:continueselected_features = good_features + [feature]xtrain = X[:, selected_features]score = self.evaluate_score(xtrain, y)if score > best_score:this_feature = featurebest_score = scoreif this_feature is None:breakgood_features.append(this_feature)best_scores.append(best_score)if len(best_scores) > 1:if best_scores[-1] < best_scores[-2]:breakreturn best_scores[:-1], good_features[:-1]def __call__(self, X, y):scores, features = self._feature_selection(X, y)return X[:, features], scoresif __name__ == "__main__":X, y = make_classification(n_samples=1000, n_features=100)X_transformed, scores = GreedyFeatureSelection()(X, y)
import pandas as pd
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housingdata = fetch_california_housing()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]model = LinearRegression()
rfe = RFE(estimator=model,n_features_to_select=3
)
rfe.fit(X, y)
X_transformed = rfe.transform(X)
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
data = load_diabetes()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
model = RandomForestRegressor()
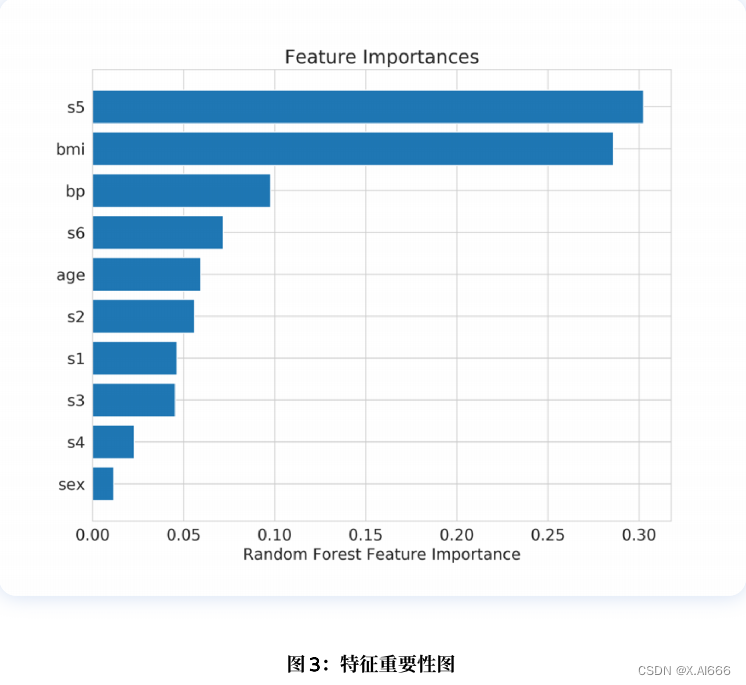
model.fit(X, y)随机森林(或任何模型)的特征重要性可按如下⽅式绘制。
importances = model.feature_importances_
idxs = np.argsort(importances)
plt.title('Feature Importances')
plt.barh(range(len(idxs)), importances[idxs], align='center')
plt.yticks(range(len(idxs)), [col_names[i] for i in idxs])
plt.xlabel('Random Forest Feature Importance')
plt.show()结果如图 3 所⽰。
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectFromModel
data = load_diabetes()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
model = RandomForestRegressor()
sfm = SelectFromModel(estimator=model)
X_transformed = sfm.fit_transform(X, y)
support = sfm.get_support()
print([x for x, y in zip(col_names, support) if y = True ])相关文章:
【解决(几乎)任何机器学习问题】:特征选择
当你创建了成千上万个特征后,就该从中挑选出⼏个了。但是,我们绝不应该创建成百上千个⽆⽤的特征。特征过多会带来⼀个众所周知的问题,即 "维度诅咒"。如果你有很多特征,你也必须有很多训练样本来捕捉所有特征。什么是 …...

24 双非计算机秋招总结
引言 我整理了一份 10w 字数的前端技术文档(飞书),地址:https://qx8wba2yxsl.feishu.cn/docx/Vb5Zdq7CGoPAsZxMLztc53E1n0k?fromfrom_copylink,欢迎对前端感兴趣的同学查看、共建、分享。 PS:我是一名大四…...

用友NC65与用友NCC对接集成NC65-凭证列表查询打通凭证新增
用友NC65与用友NCC对接集成NC65-凭证列表查询打通凭证新增 数据源平台:用友NC65 用友NC是为集团与行业企业提供的全线管理软件产品,由亚太本土最大的企业管理软件提供商用友公司研发提供,用友NC率先采用J2EE架构和先进开放的集团级开发平台UAP࿰…...

【初中生讲机器学习】12. 似然函数和极大似然估计:原理、应用与代码实现
创建时间:2024-02-23 最后编辑时间:2024-02-24 作者:Geeker_LStar 你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~ 我是 Geeker_LStar,一名初三学生,热爱计算机和数学,我们一起加…...

【达梦数据库】查看pesg回滚段信息的视图和SQL
一些达梦回滚段是使用情况的查询SQL,供排查“回滚记录版本太旧,无法获取用户记录” 等类似问题时使用 视图名说明主库备库v$pseg_items显示回滚系统中当前回滚项信息(回滚线程的工作信息)总行数WORKER_THREADS1查询 no rowsv$pseg…...
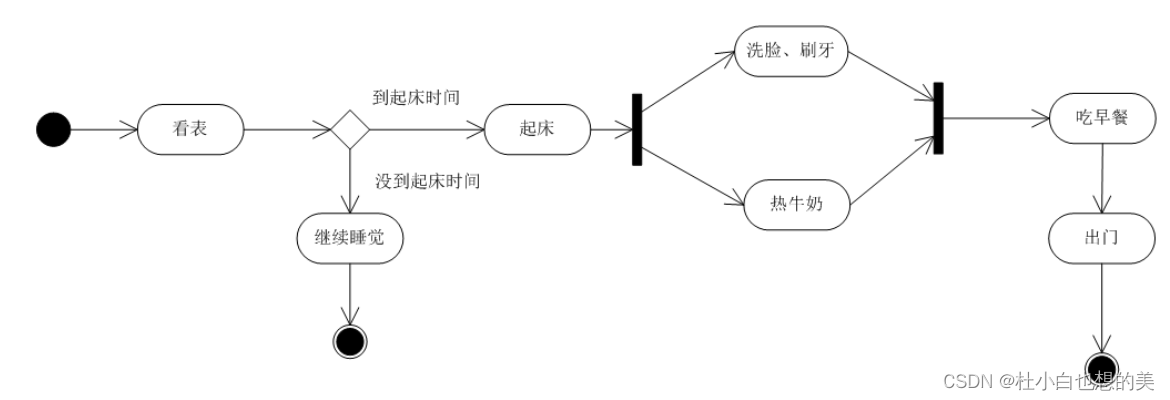
UML---活动图
活动图概述 活动图(Activity Diagram)是UML(Unified Modeling Language,统一建模语言)中的一种行为建模工具,主要用于描述系统或业务流程中的一系列活动或操作。活动图通常用于描述用例中的行为,…...

编程笔记 Golang基础 018 常量与变量
编程笔记 Golang基础 018 常量与变量 一、常量常量的定义iota特性 二、变量变量定义变量作用域零值与初始化类型转换注意事项 三、重要性 常量,就是在程序编译阶段就确定下来的值,而程序在运行时则无法改变该值。变量是程序的基本组成单位,用…...
如何使用Douglas-042为威胁搜索和事件应急响应提速
关于Douglas-042 Douglas-042是一款功能强大的PowerShell脚本,该脚本可以提升数据分类的速度,并辅助广大研究人员迅速从取证数据中筛选和提取出关键数据。 该工具能够搜索和识别Windows生态系统中潜在的安全漏洞,Douglas-042会将注意力放在…...
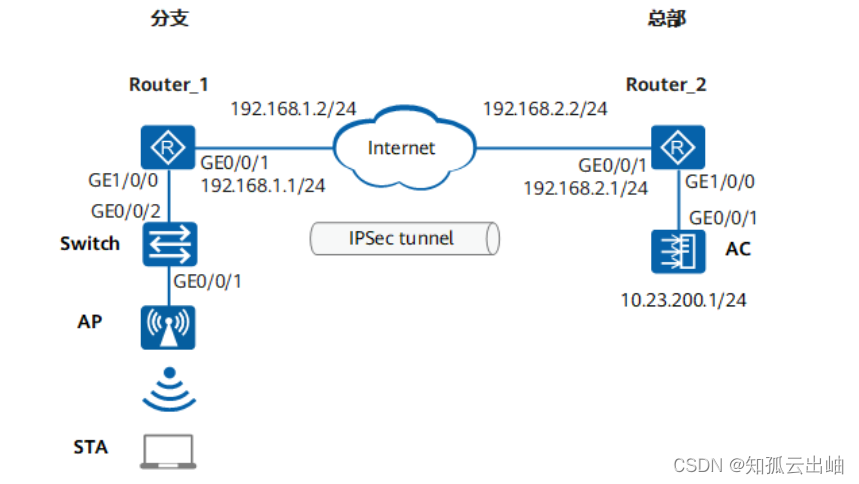
华为配置WLAN AC和AP之间VPN穿越示例
配置WLAN AC和AP之间VPN穿越示例 组网图形 图1 配置WLAN AC和AP之间VPN穿越示例组网图 业务需求组网需求数据规划配置思路配置注意事项操作步骤配置文件 业务需求 企业用户接入WLAN网络,以满足移动办公的最基本需求。且在覆盖区域内移动发生漫游时,不影响…...

跨语言的序列化与反序列化
在Java中实现跨语言的序列化与反序列化通常可以采用以下几种方式 使用标准的跨语言序列化格式 可以选择使用一些标准的跨语言序列化格式,例如JSON、XML、Protocol Buffers(ProtoBuf)等。这些格式都是跨语言的,可以方便地在不同的编程语言之间进行数据交换。在Java中,可以…...

软考-中级-系统集成2023年综合知识(三)
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 软考中级专栏回顾 专栏…...

五、使用脚手架
五、使用脚手架 5.1 简单的实现 创建一个 School 组件 <template> <div><h2>学校名称:{{name}}</h2><h2>学校地址:{{address}}</h2> </div> </template><script> export default {name: "S…...

抛弃chatgpt,使用微软的Cursor提升coding效率
Whats Cursor? Cursor编辑器是一个基于GPT-4的代码编辑器,它可以根据用户的自然语言指令或者正在编辑的代码上下文为用户提供代码建议,支持多种编程语言,如Python、Java、C/C#、go等。Cursor编辑器还可以帮助用户重构、理解和优化代码&…...
)
uniapp插件uViewplus的使用(涉及TS下的问题)
在技术选型后最后定了使用有团队维护的uview-plus3.0,官方文档 配置参考:https://juejin.cn/post/7169875753100640270 ts配置参考:https://blog.csdn.net/m0_70027114/article/details/132957426 引入 在项目文件的pages.json中的"easycom"…...
google浏览器chrome无法访问localhost等本地虚拟域名的解决方法
场景一: 谷歌浏览器访问出现:forbbiden 403 问题,或者直接跳转到正式域名(非本地虚拟域名) 访问本地的虚拟域名http://www.hd.com/phpinfo.php?p1发生了302 条状 火狐浏览器正常访问; 解决方法: 方法1:在谷歌浏览器…...
前端单元测试之Jest详解篇)
(2.2w字)前端单元测试之Jest详解篇
Jest Jest 概述 Jest是一个领先的JavaScript测试框架,特别适用于React和Node.js环境。由Facebook开发,它以简单的配置、高效的性能和易用性而闻名。Jest支持多种类型的测试,包括单元测试、集成测试和快照测试,后者用于捕获组件或…...

【C++私房菜】面向对象中的多态
文章目录 一、多态二、对象的静态类型和动态类型三、虚函数和纯虚函数1、虚函数2、虚析构函数3、抽象基类和纯虚函数4、多态的原理 四、重载、覆盖(重写)、隐藏(重定义)的对比 一、多态 OOP的核心思想是多态性(polymorphism)。多态性这个词源自希腊语,其含义是“多…...

(done) 什么是特征值和特征向量?如何求特征值的特征向量 ?如何判断一个矩阵能否相似对角化?
什么是齐次方程? https://blog.csdn.net/shimly123456/article/details/136198159 行列式和是否有解的关系? https://blog.csdn.net/shimly123456/article/details/136198215 特征值和特征向量 参考视频:https://www.bilibili.com/video/BV…...
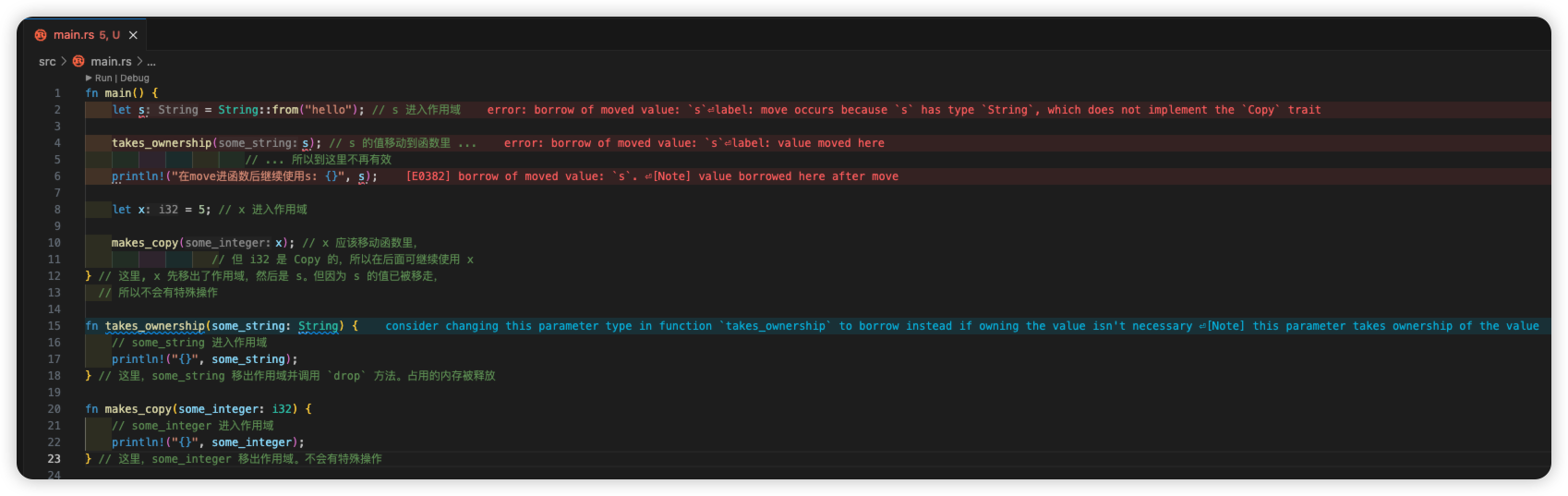
[rust] 11 所有权
文章目录 一 背景二 Stack 和 Heap2.1 Stack2.2 Heap2.3 性能区别2.4 所有权和堆栈 三 所有权原则3.1 变量作用域3.2 String 类型示例 四 变量绑定背后的数据交互4.1 所有权转移4.1.1 基本类型: 拷贝, 不转移所有权4.1.2 分配在 Heap 的类型: 转移所有权 4.2 Clone(深拷贝)4.3 …...
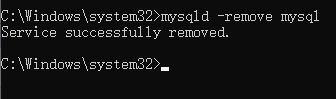
MySQL安装
文章目录 MYSQL安装一、下载二、解压三、配置1. 添加环境变量2. 初始化MySQL3. 注册MySQL服务4. 启动MySQL服务5. 修改默认账户密码 四、登录MySQL五、卸载MySQL MYSQL安装 一、下载 点开下面的链接:https://dev.mysql.com/downloads/mysql/ 点击Download 就可以下…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

VR头显立体视觉姿态估计技术解析
1. 自我中心姿态估计的技术挑战与创新思路在虚拟现实和增强现实应用中,准确估计用户在三维空间中的身体姿态是实现自然交互的基础。传统基于外部摄像头的动作捕捉系统虽然精度较高,但存在设备复杂、使用场景受限等问题。相比之下,基于头戴设备…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...

【Clickhouse从入门到精通】第03篇:ClickHouse适用场景深度剖析
上一篇【第02篇】ClickHouse横空出世——天下武功唯快不破 下一篇【第04篇】ClickHouse生态全景与生产实践者巡礼 摘要 技术选型是数据架构设计的核心命题。再优秀的工具,若用错了场景,也会事倍功半。ClickHouse 以"极速分析查询"著称&#x…...

Go语言轻量级规则引擎Airules:高性能架构与微服务实践
1. 项目概述:从“Airules”看现代规则引擎的轻量化实践最近在GitHub上看到一个挺有意思的项目,叫“Airules”。光看名字,你可能会联想到“AI规则”或者“空气规则”,其实它的全称是“Air Rules”,直译过来就是“空气规…...