【数据结构】排序(2)
目录
一、快速排序:
1、hoare(霍尔)版本:
2、挖坑法:
3、前后指针法:
4、非递归实现快速排序:
二、归并排序:
1、递归实现归并排序:
2、非递归实现归并排序:
三、排序算法整体总结:
一、快速排序:
基本思想:
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1、hoare(霍尔)版本:
运用递归原理,定义一个keyi(基准值),然后左找大,右找小,然后递归基准值的左右区间。
具体思路:
- 选定一个基准值,可以是a[0] / a[Size-1]。
- 确定两个指针 left 和 right 分别从左边和右边向中间遍历数组。
- 例如:选最左边的为基准值则right先走,遇到比基准值大的就停下,然后left走,遇到比基准值小的就停下,然后交换left与right位置对应的值。(如果以最右边为基准值,则left先走,right后走)
- 重复以上步骤,直到left = right ,最后将基准值与left(right)位置的值交换。
这样下来基准值所在的位置就是它排序后正确所在的位置,因为左边的所有数都比他小,右边的所有数都比他大。
然后再递归以基准值为界限的左右两个区间中的数,当区间中没有元素时,排序完成。
代码实现:
// 三数选中位数返回下标,作为一个快排的小优化,(不用也可以,不影响后面的代码)
int GetMedian(int* a, int begin, int end)
{int midi = (begin + end) / 2;// begin end midi三个数选中位数if (a[begin] < a[midi]){if (a[midi] < a[end])return midi;else if (a[begin] > a[end])return begin;elsereturn end;}else{if (a[end] > a[begin])return begin;else if (a[midi] > a[end])return midi;elsereturn end;}
}// hoare(霍尔)方法
int PartSort1(int* a, int begin, int end)// begin end 为下标
{int median = GetMedian(a, begin, end);// 选中位数返回下标swap(a[median], a[begin]); // 这里的swap使用的是库函数中写好了的,// 使用自己写的注意形参与实参int left = begin, right = end;int keyi = begin;while (left < right){// 右边找小while (left<right && a[right] >= a[keyi]){right--;}// 左边找大while (left < right && a[left] <= a[keyi]){left++;}swap(a[left], a[right]);}// 交换基准值和 left与right 交汇位置的值swap(a[left], a[keyi]);// 返回基准值的下标return left;
}void QuickSort(int* a, int begin, int end) // begin end 为下标
{if (begin >= end){return;}int keyi = PartSort1(a, begin, end); // 继续递归keyi(已排好序的值)的左右区间QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}2、挖坑法:
具体思路:
- 从最左边选定一个基准值取出,然后这个位置就为“坑”。
- 还是运用左右指针,当右指针遇到比基准值小的值时,将该值放入坑中,然后右指针指向的位置就是新的“坑”,然后移动左指针,当左指针遇到比基准值大的值时,同样将该值放入坑中,然后左指针指向的位置就是新的“坑”,然后再移动右指针,以此反复直到左右指针相遇。
- 当左右指针相遇时,将基准值放入最后的“坑”中。
然后再递归以基准值为界限的左右两个区间中的数,当区间中没有元素时,排序完成。
代码实现:
int PartSort1(int* a, int begin, int end)// begin end 为下标
{int median = GetMedian(a, begin, end);// 选中位数返回下标swap(a[median], a[begin]); // 这里的swap使用的是库函数中写好了的,// 使用自己写的注意形参与实参int left = begin, right = end;int keyi = begin;while (left < right){// 右边找小while (left<right && a[right] >= a[keyi]){right--;}// 左边找大while (left < right && a[left] <= a[keyi]){left++;}swap(a[left], a[right]);}// 交换基准值和 left与right 交汇位置的值swap(a[left], a[keyi]);// 返回基准值的下标return left;
}// 挖坑法
int PartSort2(int* a, int begin, int end)
{int median = GetMedian(a, begin, end);// 选中位数返回下标swap(a[median], a[begin]); // 这里的swap使用的是库函数中写好了的,// 使用自己写的注意形参与实参// 定义基准值与“坑位”int keyi = a[begin];int hole = begin;// begin 与 end 充当左右指针while (begin < end){// 右边找小,填到左边的坑while (begin < end && a[end] >= keyi){end--;}// 填坑a[hole] = a[end];hole = end;// 左边找大,填到右边的坑while (begin < end && a[begin] <= keyi){begin++;}// 填坑a[hole] = a[begin];hole = begin;}a[hole] = keyi;return hole;
}void QuickSort(int* a, int begin, int end) // begin end 为下标
{if (begin >= end){return;}int keyi = PartSort2(a, begin, end); // 继续递归keyi(已排好序的值)的左右区间QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}3、前后指针法:
具体思路:
- 定义一个基准值key,指针 prev 和 cur。(cur = prev + 1)
- cur先走,遇到比key大的值,++cur。
- cur遇到比key小的值,++prev,交换prev和cur位置的值。
- 以此反复直到cur走出数组范围。
最后交换key和prev的值
然后再递归以基准值为界限的左右两个区间中的数,当区间中没有元素时,排序完成。

代码实现:
int PartSort3(int* a, int begin, int end)
{int median = GetMedian(a, begin, end);// 选中位数返回下标swap(a[median], a[begin]); // 这里的swap使用的是库函数中写好了的,// 使用自己写的注意形参与实参// 定义基准值、前后指针int keyi = begin;int prev = begin, cur = prev + 1;while (cur <= end){// 保留keyi下标的值if (a[cur] < a[keyi] && ++prev != cur)// 避免自己给自己赋值的情况,{swap(a[prev], a[cur]);}++cur;}swap(a[prev], a[keyi]);// 因为交换了位置,所以下标prev的位置才是基准值return prev;
}void QuickSort(int* a, int begin, int end) // begin end 为下标
{if (begin >= end){return;}int keyi = PartSort3(a, begin, end); // 继续递归keyi(已排好序的值)的左右区间QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}4、非递归实现快速排序:
非递归实现快速排序就需要运用到栈,栈中存放的是需要排序的左右区间。其大致思想是与递归实现的思路类似。
具体思路:
- 将待排序数组的左右下标入栈。
- 若栈不为空,分两次取出栈顶元素,分为闭区间的左右界限。
- 将区间中的元素按照【上述三种方法(霍尔、挖坑、前后指针)的任意一种】得到基准值的位置
- 再以基准值为界限,当基准值左右区间中有元素,将区间入栈
然后重复上述步骤直到栈中没有元素时,排序完成。
代码实现:
void QuickSortNonr(int* a, int begin, int end)
{// 这里使用的是C++标准模板库的stack,如果是C语言的话需手搓一个栈出来// 但基本的思路是一样的,这里为了方便就不手搓哩// 定义一个栈并初始化stack<int> s;// 将数组的左右下标入栈s.push(end);s.push(begin);// 当栈不为空时,继续排序while (!s.empty()){int left = s.top();s.pop();int right = s.top();s.pop();// 获取基准值的位置(下标)int keyi = PartSort1(a, left, right);// [left, keyi-1] keyi [keyi+1, right]// 以基准值为界限,若基准值左右区间中有元素,则将区间入栈if (left < keyi - 1){s.push(keyi - 1);s.push(left);}if (keyi + 1 < right){s.push(right);s.push(keyi + 1);}}// 如果是手搓的栈,记得释放内存
}快速排序的特性总结:
快速排序整体的综合性能和使用场景都是比较好的。
时间复杂度:O(N*logN)
空间复杂度:O(logN)
稳定性:不稳定
二、归并排序:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,采用分治法(Divide and Conquer)的一个非常典型的应用。
基本思想:
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
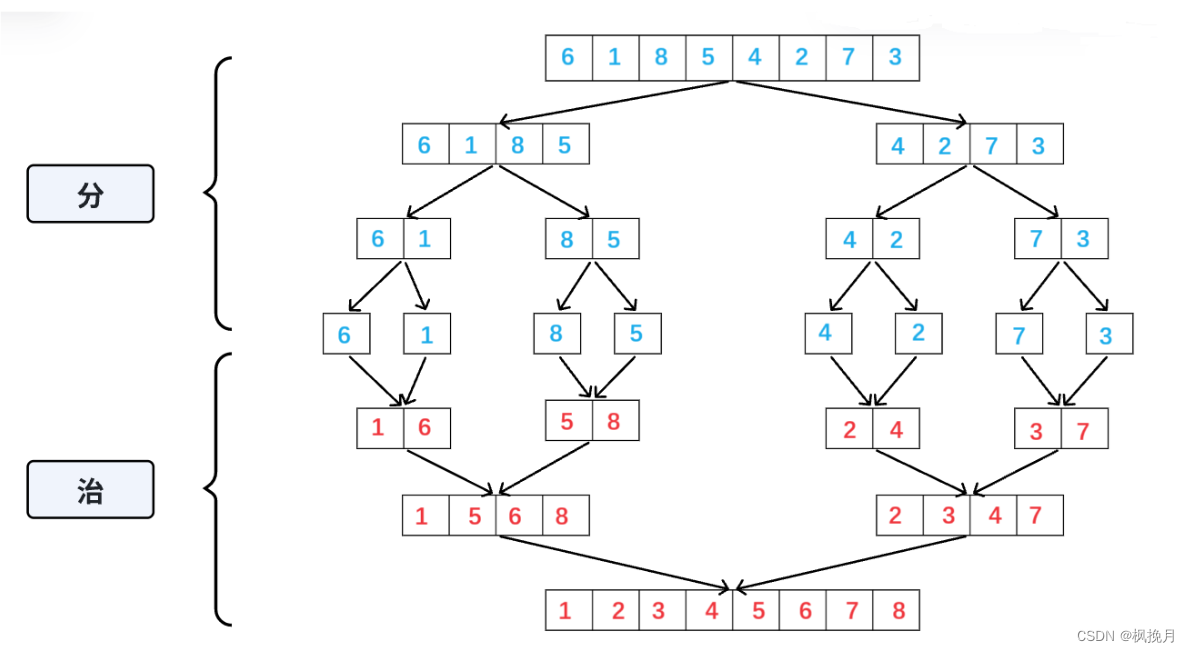
本质为:
依次将数组划分,直到每个序列中只有一个数字。一个数字默认有序,然后再依次合并排序。
1、递归实现归并排序:
代码实现:
void _MergeSort(int* a, int begin, int end, int* tmp)
{// 当区间中没有元素时将不再进行合并if (begin >= end){return;}// 划分数组,进行递归操作int mid = (begin + end) / 2;_MergeSort(a, begin, mid, tmp); // 划分左区间_MergeSort(a, mid + 1, end, tmp); // 划分右区间// 两个有序序列进行合并int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2)// 结束条件为一个序列为空就停止。{if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}// 进行上一步的操作后会有一个有序序列不为空,将其合并进tmpwhile (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//将合并后的序列拷贝到原数组中memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));}void MergeSort(int* a, int Size)
{//因为需要将两个有序序列进行合并,所以需要开辟相同空间int* tmp = (int*)malloc(sizeof(int) * Size);assert(tmp);_MergeSort(a, 0, Size - 1, tmp);free(tmp);
}2、非递归实现归并排序:
非递归实现的思想与递归实现的思想是类似的,但序列划分过程和递归是相反的,并不是每次一分为二, 而是先拆分为一个元素一组、再两个元素一组进行排序、再四个元素一组进行排序....以此类推,直到将所有的元素排序完。
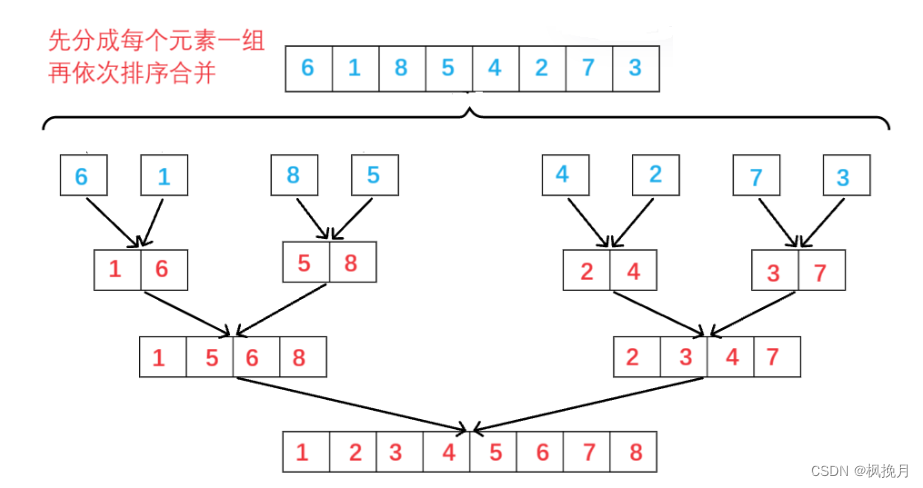
代码实现:
void MergeSortNonR(int* a, int Size)
{int* tmp = (int*)malloc(sizeof(int) * Size);assert(tmp);// 先将元素拆为一个一组int gap = 1;while (gap < Size) // 当gap=Size时就是一组序列{// 每两组进行一个合并排序int index = 0; // 记录tmp数组中元素的下标for (int i = 0; i < Size; i += 2 * gap)// 两组中元素的个数为2*gap{// 控制两组的边界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 当原数组中元素个数不是2^n时,最后两组会出现元素不匹配的情况// 情况1: 当 end1 >= Size 或 begin2 >= Size 时即最后两组元素只剩下一组时不需要进行合并排序if (end1 >= Size || begin2 >= Size){break;}// 情况2: end2 >= Size 时,即最后两组中,第二组的元素个数小于第一组,则需要调整第二组的边界if (end2 >= Size){end2 = Size - 1;}// 进行合并排序while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}//一趟排序完后,将有序序列拷贝到原数组中memcpy(a, tmp, sizeof(int) * index);}// 更新gap变为二倍gap *= 2;}free(tmp);tmp = NULL;
}归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
三、排序算法整体总结:
稳定性:指数组中相同元素在排序后相对位置不发生变化。
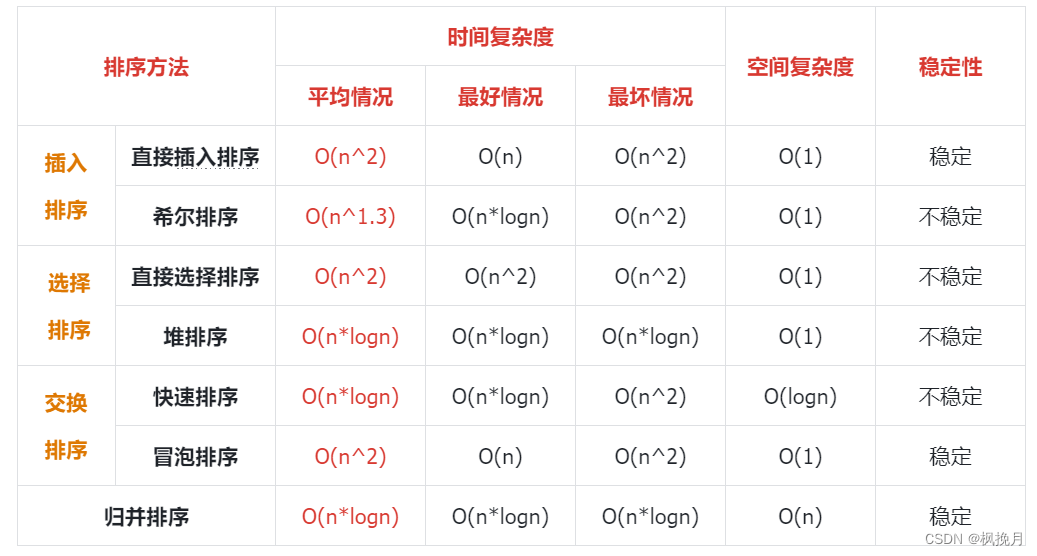
补充:
1、在希尔排序中,增量的选择会影响其时间复杂度。
2、序列初始顺序在一些算法中也会影响其时间复杂度。
相关文章:
【数据结构】排序(2)
目录 一、快速排序: 1、hoare(霍尔)版本: 2、挖坑法: 3、前后指针法: 4、非递归实现快速排序: 二、归并排序: 1、递归实现归并排序: 2、非递归实现归并排序: 三、排序算法…...
HarmonyOS开发行业前景就业分析与实例解析
HarmonyOS的简介 鸿蒙系统(HarmonyOS)是华为公司自主研发的一种全场景分布式操作系统,旨在为各种设备提供统一的开发和运行环境。它的编程基础主要建立在多种技术和语言之上,包括鸿蒙系统的核心框架和应用程序开发框架。 本章将…...
Elasticsearch:创建自定义 ES Rally tracks 的分步指南
作者:Alejandro Snchez 按照这个综合教程学习如何制作个性化的 Rally tracks ES Rally 是什么?它的用途是什么? ES Rally 是一个用于在 Elasticsearch 上测试性能的工具,允许你运行和记录比较测试。 做出决策可能很困难&#x…...

5分钟JavaScript快速入门
目录 一.JavaScript基础语法 二.JavaScript的引入方式 三.JavaScript中的数组 四.BOM对象集合 五.DOM对象集合 六.事件监听 使用addEventListener()方法添加事件监听器 使用onX属性直接指定事件处理函数 使用removeEventListener()方法移除事件监听器 一.JavaScript基础…...
如何使用IP代理解决亚马逊账号IP关联问题?
亚马逊账号IP关联问题是指当同一个IP地址下有多个亚马逊账号进行活动时,亚马逊会将它们关联在一起,从而可能导致账号被封禁或限制。 为了避免这种情况,许多人选择使用IP代理。 IP代理为什么可以解决亚马逊IP关联问题? IP代理是…...

opencv之cvScalar
CV_INLINE CvScalar cvScalar( double val0, double val1 CV_DEFAULT(0), double val2 CV_DEFAULT(0), double val3 CV_DEFAULT(0)) { CvScalar scalar; scalar.val[0] val0; scalar.val[1] val1; scalar.val[2] val2; scalar.val[3] val3; return scalar; } 该函数的…...

通过 GithubActions 实现自动化部署 Hexo
一、在自己电脑上新建一个文件夹,打开 git bash here,输入以下命令 # 生成秘钥 ssh-keygen -f github-deploy-key之后会生成两个文件, 一个私钥文件为:github-deploy-key; 另一个公钥文件为:github-deploy-key.pub …...

如何快速导出vercel project中的环境变量
我在vercel中集成了某些插件或者链接了数据库,要如何快速的导出这些环境变量呢? 具体方法如下: npm i -g vercelvercel linkvercel env pull .env.local首先是安装vercel然后登录vercel 最后拉取环境变量到.env.local...

Java-8函数式编程设计-Functional-Interface
Java 8函数式编程设计-Functional-Interface 我自己的理解,函数式编程对用户最大的价值是促使开发者养成模块化编程的习惯,代码可读性和维护性提高很多。 通过阅读JDK 8的 java.util.function 和 java.util.stream 包源码,意在理解Java的函数…...

Linux TCP 参数设置
文章目录 Linux TCP 参数设置参考 Linux TCP 参数设置 查询tcp相关内核参数 sysctl -a|grep ipv4|grep -i --color tcp[rootlocalhost ~]# sysctl -a|grep ipv4|grep -i --color tcp sysctl: reading key "net.ipv6.conf.all.stable_secret" sysctl: reading key &…...

Dubbo之消费端服务RPC调用
在消费端服务是基于接口调用Provider端提供的服务,所以在消费端并没有服务公共接口的实现类。 使用过程中利用注解DubboReference将目标接口作为某个类的字段属性,在解析该类时获取全部字段属性并单独关注解析存在注解DubboReference的字段属性。通过步…...
报表控件Stimulsoft 新版本2024.1中,功能区工具栏新功能
今天,我们将讨论Stimulsoft Reports、Dashboards 和 Forms 2024.1版本中的一项重要创新 - 在一行中使用功能区工具栏的能力。 Stimulsoft Ultimate (原Stimulsoft Reports.Ultimate)是用于创建报表和仪表板的通用工具集。该产品包括用于WinF…...
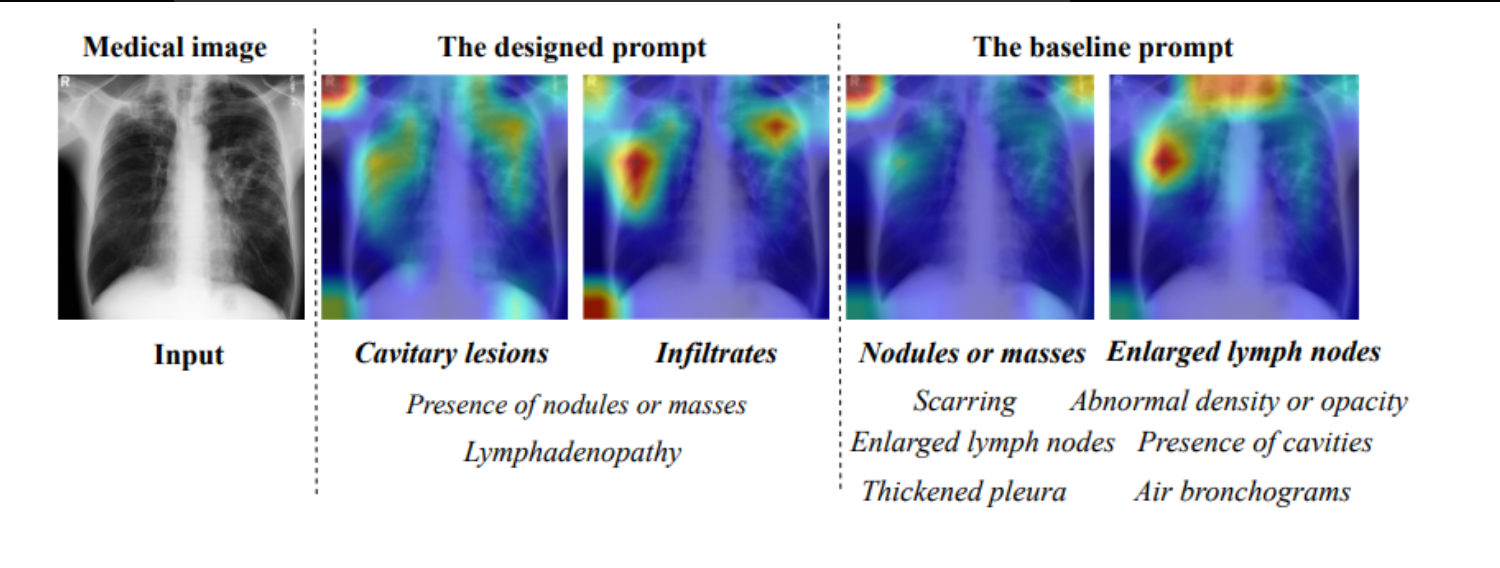
零样本带解释性的医学大模型
带解释性的医学大模型 提出背景解法拆解方法的原因对比以前解法 零样本带解释性的医学大模型如何使用CLIP模型和ChatGPT来进行零样本医学图像分类用特定提示查询ChatGPT所生成的医学视觉特征描述相似性得分在不同症状上的可视化,用于解释模型的预测注意力图的可视化…...

英文输入法(C 语言)
题目来自于博主算法大师的专栏:最新华为OD机试C卷AB卷OJ(CJavaJSPy) https://blog.csdn.net/banxia_frontend/category_12225173.html 题目 主管期望你来实现英文输入法单词联想功能,需求如下: 依据用户输入的单词前…...

万众一心 · 喜赢未来,2023宇凡微年会暨阳朔之旅
宇凡微 万众一心 喜赢未来 2024宇凡微年会暨阳朔之旅 在一起,做时间的朋友,迈向第一 前言 INTRODUCTION 感恩宇凡微过去七年砥砺路,携手宇凡微未来七年新征程。2024年1月24日~1月27日,宇凡微在广西桂林阳朔举办了以“感恩有…...
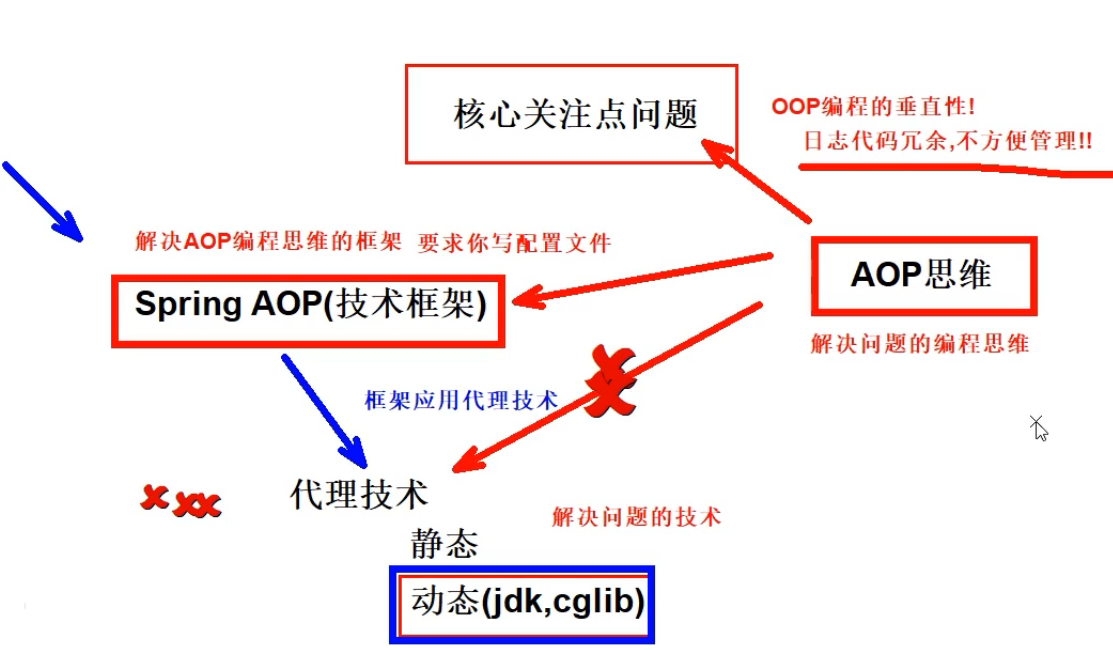
【Spring】 AOP面向切面编程
文章目录 AOP是什么?一、AOP术语名词介绍二、Spring AOP框架介绍和关系梳理三、Spring AOP基于注解方式实现和细节3.1 Spring AOP底层技术组成3.2 初步实现3.3 获取通知细节信息3.4 切点表达式语法3.5 重用(提取)切点表达式3.6 环绕通知3.7 切…...
R语言入门笔记2.6
描述统计 分类数据与顺序数据的图表展示 为了下面代码便于看出颜色参数所对应的值,在这里先集中介绍, col1是黑色,2是粉红,3是绿色,4是天蓝,5是浅蓝,6是紫红,7是黄色,…...

PS人像处理磨皮插件
PS人像处理插件 Portraiture 人像照片进行自动磨皮和平滑处理Arcsoft Portrait 3 自动化人像磨皮软件 批量处理功能DR增强插件 含有磨皮滤镜Beautify Panel 高级质感磨皮插件PT Portrait 人像检测自动完成磨皮优化Retouch4me AI智能人能磨皮美容软件 1、Retouch4me_Heal…...
类型转换(C++)
一、C语言中的类型转换 在C语言中,如果赋值运算符左右两侧类型不同,或者形参与实参类型不匹配,或者返回值类型与 接收返回值类型不一致时,就需要发生类型转化,C语言中总共有两种形式的类型转换:隐式类型 …...
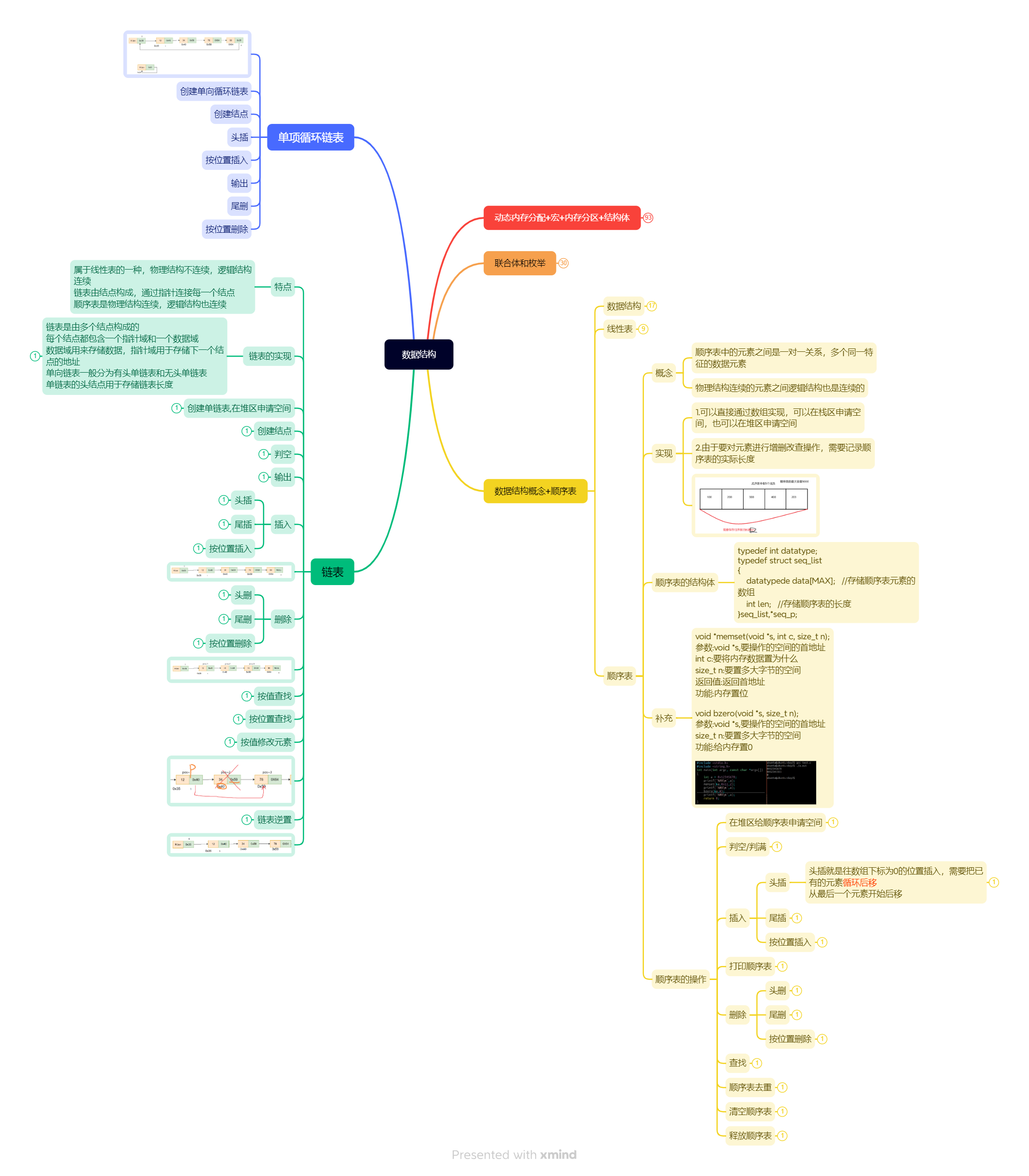
2.23数据结构
单向循环链表 创建单向循环链表,创建节点 ,头插,按位置插入,输出,尾删,按位置删除功能 //main.c #include "loop_list.h" int main() {loop_p Hcreate_head();insert_head(H,12);insert_head(…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

如何3步获取百度网盘真实下载地址实现满速下载
如何3步获取百度网盘真实下载地址实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的非会员下载速度困扰?当下载重要的工作文件、学…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

基于 Next.js 的无头电商架构实战:从 Vercel Commerce 看现代全栈开发
1. 项目概述:一个面向未来的全栈电商起点如果你最近在琢磨着用 Next.js 搞一个电商网站,或者想找一个现代、开箱即用的全栈电商模板来启动项目,那你大概率已经听说过vercel/commerce这个仓库了。它不是某个具体的电商平台,而是一个…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第二题- 坏掉的键盘】(题目+思路+JavaC++Python解析+在线测试)
题目内容 小明准备输入一个仅由小写英文字母组成的字符串,但他的键盘在一开始就有且仅有一个按键失灵,导致该字母在原串中的所有出现都没有被输入,最终得到的字符串为 sss。小明还告诉你:原本要输入的完整字符串中任意相邻两个字符都不相同。 请你计算,对于每一个可能的…...

KMS智能激活终极指南:如何一键永久激活Windows和Office
KMS智能激活终极指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次重装系统后都要重新激活Office&…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

FeFET时间域内存计算宏:突破AI边缘计算能效瓶颈
1. 项目概述:FeFET时间域内存计算宏的创新实现在人工智能和边缘计算蓬勃发展的当下,传统冯诺依曼架构面临着一个根本性挑战:数据在处理器和存储器之间的频繁搬运导致的高能耗和延迟瓶颈。这个问题在需要大量并行乘累加(MAC)运算的神经网络应用…...